In [1]: import pandas as pd
In [2]: import matplotlib.pyplot as plt
-
Данные о качестве воздуха
Для этого руководства, данные о качестве воздуха о \(NO_2\) и используется частиц размером менее 2,5 микрометров, предоставленных OpenAQ и загруженное с помощью py-openaq пакет. The
К исходным даннымair_quality_no2_long.csv"набор данных предоставляет \(NO_2\) значения для измерительных станций FR04014, BETR801 и Лондон Вестминстер соответственно в Париже, Антверпене и Лондоне.In [3]: air_quality = pd.read_csv("data/air_quality_no2_long.csv") In [4]: air_quality = air_quality.rename(columns={"date.utc": "datetime"}) In [5]: air_quality.head() Out[5]: city country datetime location parameter value unit 0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0 µg/m³ 1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8 µg/m³ 2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5 µg/m³ 3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9 µg/m³ 4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4 µg/m³
In [6]: air_quality.city.unique() Out[6]: array(['Paris', 'Antwerpen', 'London'], dtype=object)
Как легко работать с данными временных рядов#
Использование свойств даты и времени pandas#
Я хочу работать с датами в столбце
datetimeкак объекты datetime вместо обычного текстаIn [7]: air_quality["datetime"] = pd.to_datetime(air_quality["datetime"]) In [8]: air_quality["datetime"] Out[8]: 0 2019-06-21 00:00:00+00:00 1 2019-06-20 23:00:00+00:00 2 2019-06-20 22:00:00+00:00 3 2019-06-20 21:00:00+00:00 4 2019-06-20 20:00:00+00:00 ... 2063 2019-05-07 06:00:00+00:00 2064 2019-05-07 04:00:00+00:00 2065 2019-05-07 03:00:00+00:00 2066 2019-05-07 02:00:00+00:00 2067 2019-05-07 01:00:00+00:00 Name: datetime, Length: 2068, dtype: datetime64[ns, UTC]
Изначально значения в
datetimeявляются символьными строками и не предоставляют никаких операций с датой и временем (например, извлечение года, дня недели,…). Применяяto_datetimeфункция, pandas интерпретирует строки и преобразует их в datetime (т.е.datetime64[ns, UTC]) объекты. В pandas мы называем эти объекты datetime аналогичноdatetime.datetimeиз стандартной библиотеки какpandas.Timestamp.
Примечание
Поскольку многие наборы данных содержат информацию о дате и времени в одном из столбцов, входные функции pandas, такие как pandas.read_csv() и pandas.read_json()
можно выполнить преобразование в даты при чтении данных с помощью
parse_dates параметр со списком столбцов для чтения как
Timestamp:
pd.read_csv("../data/air_quality_no2_long.csv", parse_dates=["datetime"])
Почему эти pandas.Timestamp объекты полезны? Давайте проиллюстрируем добавленную
ценность на некоторых примерах.
Каковы начальная и конечная даты набора данных временных рядов, с которым мы работаем?
In [9]: air_quality["datetime"].min(), air_quality["datetime"].max()
Out[9]:
(Timestamp('2019-05-07 01:00:00+0000', tz='UTC'),
Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
Используя pandas.Timestamp для дат позволяет нам выполнять вычисления с информацией о датах
и делать их сравнимыми. Следовательно, мы можем использовать это для получения
длины нашего временного ряда:
In [10]: air_quality["datetime"].max() - air_quality["datetime"].min()
Out[10]: Timedelta('44 days 23:00:00')
Результатом является pandas.Timedelta объект, аналогичный datetime.timedelta
из стандартной библиотеки Python и определения временной продолжительности.
Различные концепции времени, поддерживаемые pandas, объясняются в разделе руководства пользователя о понятия, связанные со временем.
Я хочу добавить новый столбец в
DataFrameсодержащий только месяц измеренияIn [11]: air_quality["month"] = air_quality["datetime"].dt.month In [12]: air_quality.head() Out[12]: city country datetime ... value unit month 0 Paris FR 2019-06-21 00:00:00+00:00 ... 20.0 µg/m³ 6 1 Paris FR 2019-06-20 23:00:00+00:00 ... 21.8 µg/m³ 6 2 Paris FR 2019-06-20 22:00:00+00:00 ... 26.5 µg/m³ 6 3 Paris FR 2019-06-20 21:00:00+00:00 ... 24.9 µg/m³ 6 4 Paris FR 2019-06-20 20:00:00+00:00 ... 21.4 µg/m³ 6 [5 rows x 8 columns]
Используя
Timestampобъекты для дат, множество временных свойств предоставляется pandas. Например,month, но такжеyear,quarter,… Все эти свойства доступны черезdtаксессор.
Обзор существующих свойств даты приведен в
таблица обзора компонентов времени и даты. Подробнее о dt аксессор
для возврата свойств, подобных datetime, объясняется в специальном разделе о доступ dt.
Каково среднее \(NO_2\) концентрация для каждого дня недели для каждого из мест измерений?
In [13]: air_quality.groupby( ....: [air_quality["datetime"].dt.weekday, "location"])["value"].mean() ....: Out[13]: datetime location 0 BETR801 27.875000 FR04014 24.856250 London Westminster 23.969697 1 BETR801 22.214286 FR04014 30.999359 ... 5 FR04014 25.266154 London Westminster 24.977612 6 BETR801 21.896552 FR04014 23.274306 London Westminster 24.859155 Name: value, Length: 21, dtype: float64
Помните шаблон разделение-применение-объединение, предоставляемый
groupbyиз руководство по статистическим вычислениям? Здесь мы хотим вычислить заданную статистику (например, среднее \(NO_2\)) для каждого буднего дня и для каждого места измерения. Для группировки по дням недели мы используем свойство datetimeweekday(с Monday=0 и Sunday=6) в pandasTimestamp, который также доступен черезdtаксессор. Группировка по местоположениям и дням недели может быть выполнена для разделения вычисления среднего по каждой из этих комбинаций.Danger
Поскольку мы работаем с очень коротким временным рядом в этих примерах, анализ не дает репрезентативного результата в долгосрочной перспективе!
Построение типичного \(NO_2\) шаблон в течение дня нашего временного ряда всех станций вместе. Другими словами, каково среднее значение для каждого часа дня?
In [14]: fig, axs = plt.subplots(figsize=(12, 4)) In [15]: air_quality.groupby(air_quality["datetime"].dt.hour)["value"].mean().plot( ....: kind='bar', rot=0, ax=axs ....: ) ....: Out[15]:
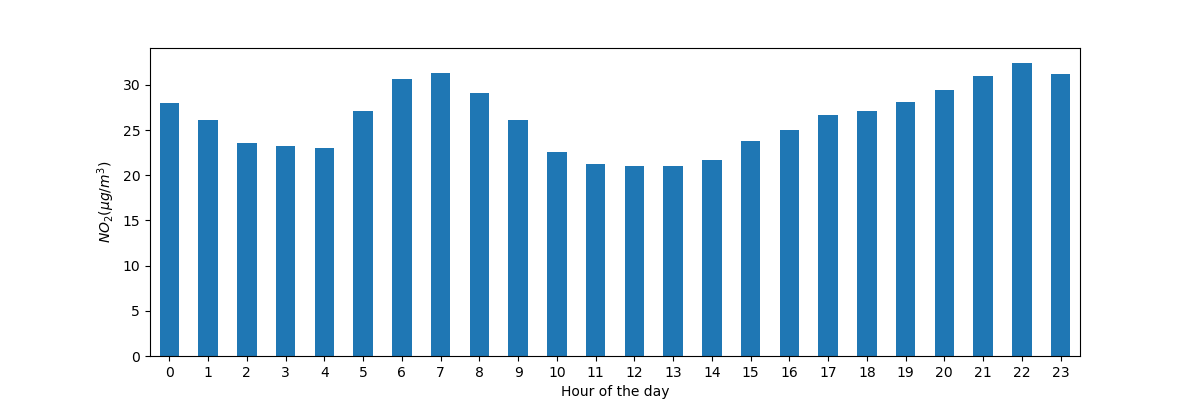
Аналогично предыдущему случаю, мы хотим вычислить заданную статистику (например, среднее значение \(NO_2\)) для каждого часа дня и мы можем снова использовать подход split-apply-combine. В этом случае мы используем свойство datetime
hourpandasTimestamp, который также доступен черезdtаксессор.
Дата и время в качестве индекса#
В руководство по преобразованию структуры данных,
pivot() был введён для преобразования таблицы данных с каждым из
мест измерений в отдельный столбец:
In [18]: no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
In [19]: no_2.head()
Out[19]:
location BETR801 FR04014 London Westminster
datetime
2019-05-07 01:00:00+00:00 50.5 25.0 23.0
2019-05-07 02:00:00+00:00 45.0 27.7 19.0
2019-05-07 03:00:00+00:00 NaN 50.4 19.0
2019-05-07 04:00:00+00:00 NaN 61.9 16.0
2019-05-07 05:00:00+00:00 NaN 72.4 NaN
Примечание
При сводке данных информация о дате и времени стала индексом таблицы. В общем случае, установка столбца в качестве индекса может быть достигнута с помощью set_index функция.
Работа с datetime индексом (т.е. DatetimeIndex) предоставляет мощные
возможности. Например, нам не нужен dt аксессор для получения
свойств временных рядов, но эти свойства доступны
непосредственно в индексе:
In [20]: no_2.index.year, no_2.index.weekday
Out[20]:
(Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
...
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int32', name='datetime', length=1033),
Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
dtype='int32', name='datetime', length=1033))
Другие преимущества включают удобное выделение временных периодов или адаптированную временную шкалу на графиках. Применим это к нашим данным.
Создайте график \(NO_2\) значения на разных станциях с 20 мая до конца 21 мая
In [21]: no_2["2019-05-20":"2019-05-21"].plot();
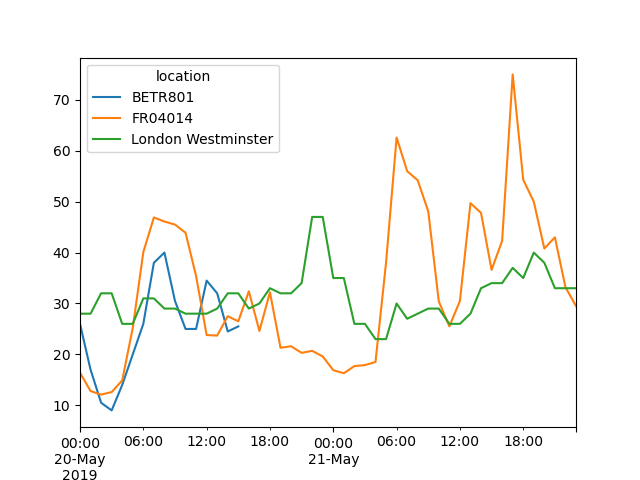
Предоставляя строка, которая парсится в datetime, определённое подмножество данных может быть выбрано на
DatetimeIndex.
Дополнительная информация о DatetimeIndex и срез с использованием строк представлен в разделе о индексация временных рядов.
Передискретизация временного ряда на другую частоту#
Агрегировать текущие почасовые значения временных рядов до максимального месячного значения на каждой из станций.
In [22]: monthly_max = no_2.resample("ME").max() In [23]: monthly_max Out[23]: location BETR801 FR04014 London Westminster datetime 2019-05-31 00:00:00+00:00 74.5 97.0 97.0 2019-06-30 00:00:00+00:00 52.5 84.7 52.0
Очень мощный метод для временных рядов с индексом datetime — это возможность
resample()преобразование временных рядов в другую частоту (например, преобразование секундных данных в 5-минутные данные).
The resample() метод аналогичен операции groupby:
он обеспечивает группировку по времени, используя строку (например,
M,5H,…) определяет целевую частотутребуется агрегирующая функция, такая как
mean,max,…
Обзор псевдонимов, используемых для определения частот временных рядов, приведен в таблица обзора псевдонимов смещений.
При определении, частота временного ряда предоставляется
freq attribute:
In [24]: monthly_max.index.freq
Out[24]: Постройте график среднесуточного \(NO_2\) значение в каждой из станций.
In [25]: no_2.resample("D").mean().plot(style="-o", figsize=(10, 5));
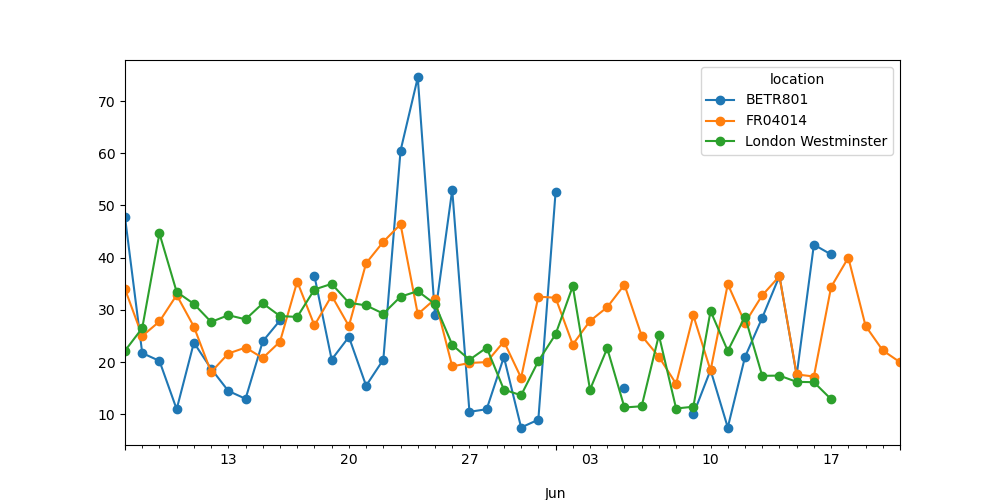
Подробнее о возможностях временных рядов resampling представлено в разделе руководства пользователя ресемплинг.
ПОМНИТЕ
Допустимые строки дат могут быть преобразованы в объекты datetime с помощью
to_datetimefunction или как часть функций чтения.Объекты Datetime в pandas поддерживают вычисления, логические операции и удобные свойства, связанные с датами, с использованием
dtаксессор.A
DatetimeIndexсодержит эти свойства, связанные с датами, и поддерживает удобное срезы.Resampleявляется мощным методом для изменения частоты временного ряда.
Полный обзор временных рядов приведен на страницах о временные ряды и функциональность дат.