linkage#
- scipy.cluster.hierarchy.linkage(y, метод='single', метрика='euclidean', optimal_ordering=False)[источник]#
Выполнить иерархическую/агломеративную кластеризацию.
Входной y может быть либо 1-D сжатой матрицей расстояний, либо 2-D массивом векторов наблюдений.
Если y является 1-D сжатой матрицей расстояний, то y должен быть \(\binom{n}{2}\) вектор размера n, где n — количество исходных наблюдений, сгруппированных в матрице расстояний. Поведение этой функции очень похоже на функцию linkage в MATLAB.
A \((n-1)\) на 4 матрицу
Zвозвращается. В \(i\)-я итерация, кластеры с индексамиZ[i, 0]иZ[i, 1]объединяются для формирования кластера \(n + i\). Кластер с индексом меньше \(n\) соответствует одному из \(n\) исходные наблюдения. Расстояние между кластерамиZ[i, 0]иZ[i, 1]задается формулойZ[i, 2]. Четвертое значениеZ[i, 3]представляет количество исходных наблюдений во вновь образованном кластере.Следующие методы связывания используются для вычисления расстояния \(d(s, t)\) между двумя кластерами \(s\) и \(t\). Алгоритм начинается с леса кластеров, которые еще не использовались в формируемой иерархии. Когда два кластера \(s\) и \(t\) из этого леса объединяются в один кластер \(u\), \(s\) и \(t\) удаляются из леса, и \(u\) добавляется в лес. Когда в лесу остаётся только один кластер, алгоритм останавливается, и этот кластер становится корнем.
Матрица расстояний поддерживается на каждой итерации.
d[i,j]запись соответствует расстоянию между кластерами \(i\) и \(j\) в исходном лесу.На каждой итерации алгоритм должен обновлять матрицу расстояний, чтобы отразить расстояние вновь образованного кластера u с оставшимися кластерами в лесу.
Предположим, есть \(|u|\) исходные наблюдения \(u[0], \ldots, u[|u|-1]\) в кластере \(u\) и \(|v|\) исходные объекты \(v[0], \ldots, v[|v|-1]\) в cluster \(v\). Напомним, \(s\) и \(t\) объединяются для формирования кластера \(u\). Пусть \(v\) может быть любым оставшимся кластером в лесу, который не \(u\).
Ниже приведены методы вычисления расстояния между вновь образованным кластером \(u\) и каждый \(v\).
method=’single’ назначает
\[d(u,v) = \min(dist(u[i],v[j]))\]для всех точек \(i\) в кластере \(u\) и \(j\) в кластере \(v\). Это также известно как Алгоритм ближайшей точки.
method=’complete’ назначает
\[d(u, v) = \max(dist(u[i],v[j]))\]для всех точек \(i\) в кластере u и \(j\) в cluster \(v\). Это также известно как Алгоритм Наиболее Удаленной Точки или Алгоритм Вор Хиса.
method='average' назначает
\[d(u,v) = \sum_{ij} \frac{d(u[i], v[j])} {(|u|*|v|)}\]для всех точек \(i\) и \(j\) где \(|u|\) и \(|v|\) являются мощности кластеров \(u\) и \(v\), соответственно. Это также называется алгоритмом UPGMA.
method='weighted' назначает
\[d(u,v) = (dist(s,v) + dist(t,v))/2\]где кластер u был образован из кластеров s и t, а v — оставшийся кластер в лесу (также называемый WPGMA).
method='centroid' назначает
\[dist(s,t) = ||c_s-c_t||_2\]где \(c_s\) и \(c_t\) — это центроиды кластеров \(s\) и \(t\), соответственно. Когда два кластера \(s\) и \(t\) объединяются в новый кластер \(u\), новый центроид вычисляется по всем исходным объектам в кластерах \(s\) и \(t\). Затем расстояние становится евклидовым расстоянием между центроидом \(u\) и центроид оставшегося кластера \(v\) в лесу. Это также известно как алгоритм UPGMC.
method='median' присваивает \(d(s,t)\) как
centroidметод. Когда два кластера \(s\) и \(t\) объединяются в новый кластер \(u\), среднее центроидов s и t даёт новый центроид \(u\). Это также известно как алгоритм WPGMC.method='ward' использует алгоритм минимизации дисперсии Уорда. Новая запись \(d(u,v)\) вычисляется следующим образом,
\[d(u,v) = \sqrt{\frac{|v|+|s|} {T}d(v,s)^2 + \frac{|v|+|t|} {T}d(v,t)^2 - \frac{|v|} {T}d(s,t)^2}\]где \(u\) — это новый объединенный кластер, состоящий из кластеров \(s\) и \(t\), \(v\) является неиспользуемым кластером в лесу, \(T=|v|+|s|+|t|\), и \(|*|\) является мощностью его аргумента. Это также известно как инкрементальный алгоритм.
Предупреждение: При выборе пары с минимальным расстоянием в лесу может быть две или более пар с одинаковым минимальным расстоянием. Эта реализация может выбрать другой минимум, чем версия MATLAB.
- Параметры:
- yndarray
Сжатая матрица расстояний. Сжатая матрица расстояний — это плоский массив, содержащий верхний треугольник матрицы расстояний. Это форма, которую
pdistвозвращает. Альтернативно, коллекция \(m\) векторы наблюдений в \(n\) размерности могут быть переданы как \(m\) by \(n\) массив. Все элементы сжатой матрицы расстояний должны быть конечными, т.е. без NaN или inf.- методstr, optional
Алгоритм связывания для использования. См.
Linkage Methodsразделу ниже для полных описаний.- метрикаstr или функция, опционально
Метрика расстояния для использования в случае, когда y — это коллекция векторов наблюдений; в противном случае игнорируется. См.
pdistфункция для списка допустимых метрик расстояния. Также может использоваться пользовательская функция расстояния.- optimal_orderingbool, необязательно
Если True, матрица связей будет переупорядочена так, чтобы расстояние между последовательными листьями было минимальным. Это даёт более интуитивно понятную структуру дерева при визуализации данных. По умолчанию False, потому что этот алгоритм может быть медленным, особенно на больших наборах данных [2]. Смотрите также
optimal_leaf_orderingфункция.Добавлено в версии 1.0.0.
- Возвращает:
- Zndarray
Иерархическая кластеризация, закодированная как матрица связей.
Смотрите также
scipy.spatial.distance.pdistметрики попарных расстояний
Примечания
Для метода ‘single’ реализован оптимизированный алгоритм на основе минимального остовного дерева. Он имеет временную сложность \(O(n^2)\). Для методов 'complete', 'average', 'weighted' и 'ward' реализован алгоритм под названием цепочка ближайших соседей. Он также имеет временную сложность \(O(n^2)\). Для других методов реализован наивный алгоритм с \(O(n^3)\) временная сложность. Все алгоритмы используют \(O(n^2)\) память. См. [1] подробности об алгоритмах.
Методы 'centroid', 'median' и 'ward' корректно определены только если используется евклидова попарная метрика. Если y передается как предвычисленные попарные расстояния, тогда ответственность пользователя - убедиться, что эти расстояния фактически евклидовы, иначе полученный результат будет некорректным.
linkageимеет экспериментальную поддержку совместимых с Python Array API Standard бэкендов в дополнение к NumPy. Пожалуйста, рассмотрите тестирование этих функций, установив переменную окруженияSCIPY_ARRAY_API=1и предоставление массивов CuPy, PyTorch, JAX или Dask в качестве аргументов массива. Поддерживаются следующие комбинации бэкенда и устройства (или других возможностей).Библиотека
CPU
GPU
NumPy
✅
н/д
CuPy
н/д
⛔
PyTorch
✅
⛔
JAX
✅
⛔
Dask
⚠️ объединяет блоки
н/д
См. Поддержка стандарта array API для получения дополнительной информации.
Ссылки
[1]Daniel Mullner, “Современные иерархические, агломеративные алгоритмы кластеризации”, arXiv:1109.2378v1.
[2]Ziv Bar-Joseph, David K. Gifford, Tommi S. Jaakkola, "Fast optimal leaf ordering for hierarchical clustering", 2001. Bioinformatics DOI:10.1093/bioinformatics/17.suppl_1.S22
Примеры
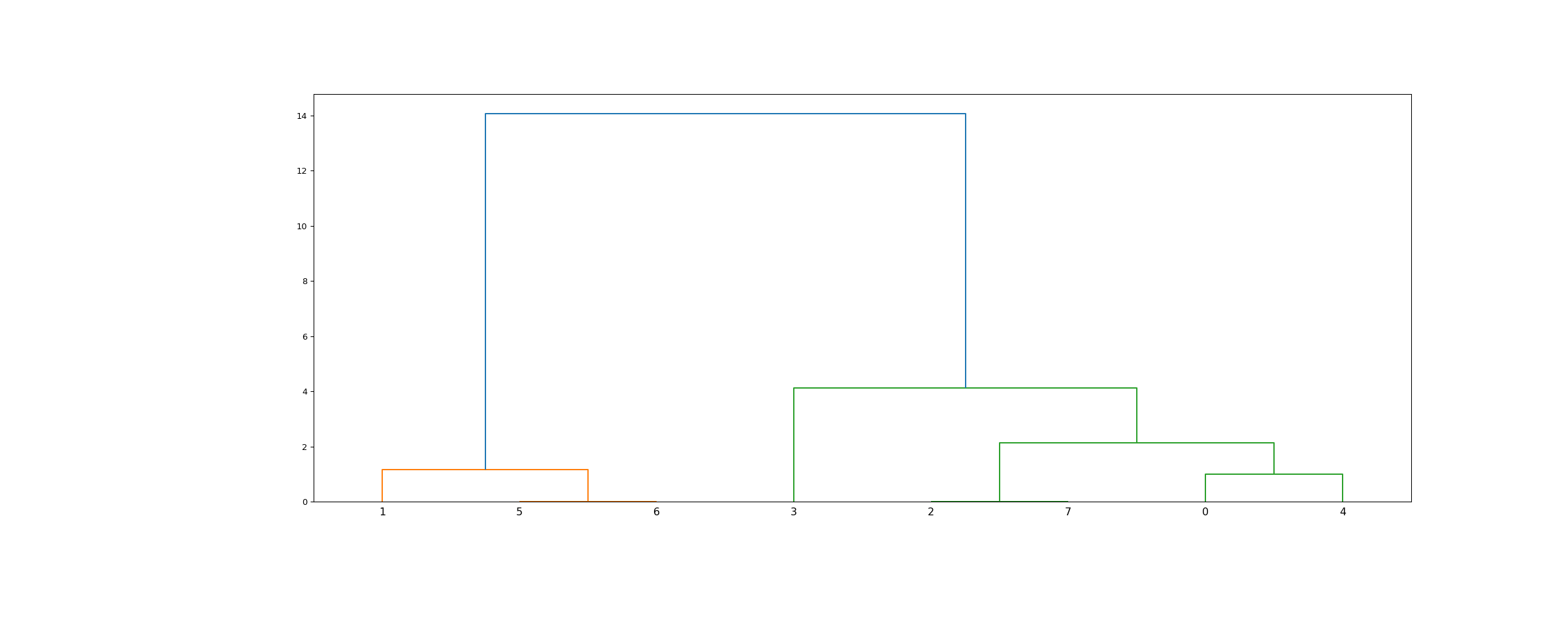
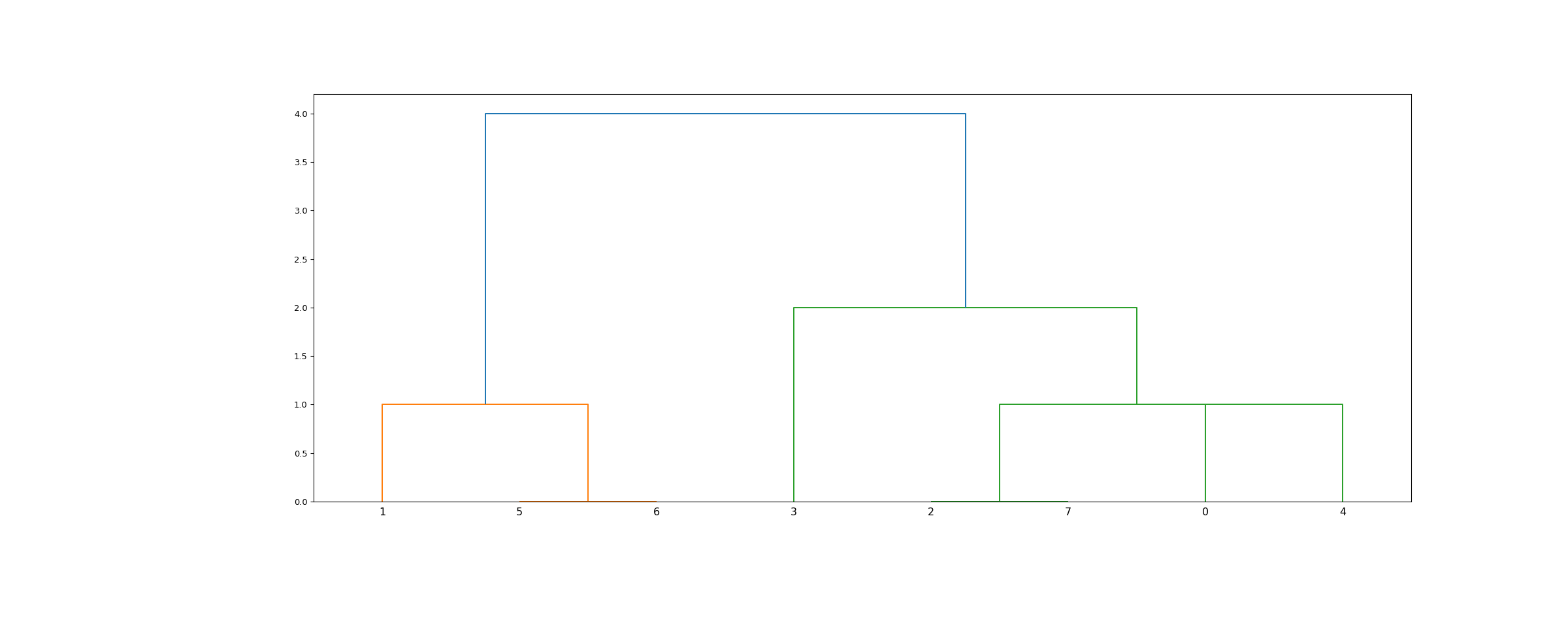
>>> from scipy.cluster.hierarchy import dendrogram, linkage >>> from matplotlib import pyplot as plt >>> X = [[i] for i in [2, 8, 0, 4, 1, 9, 9, 0]]
>>> Z = linkage(X, 'ward') >>> fig = plt.figure(figsize=(25, 10)) >>> dn = dendrogram(Z)
>>> Z = linkage(X, 'single') >>> fig = plt.figure(figsize=(25, 10)) >>> dn = dendrogram(Z) >>> plt.show()