rv_histogram#
- класс scipy.stats.rv_histogram(гистограмма, *args, плотность=None, **kwargs)[источник]#
Генерирует распределение, заданное гистограммой. Это полезно для создания шаблонного распределения из бинированной выборки данных.
Как подкласс
rv_continuousкласс,rv_histogramнаследует от него набор общих методов (см.rv_continuousдля полного списка) и реализует их на основе свойств предоставленного бинированного набора данных.- Параметры:
- гистограммакортеж из array_like
Кортеж, содержащий два объекта array_like. Первый содержит содержимое n бинов, второй содержит (n+1) границ бинов. В частности, возвращаемое значение
numpy.histogramпринимается.- плотностьbool, необязательно
Если False, предполагает, что гистограмма пропорциональна количеству на бине; в противном случае предполагает, что она пропорциональна плотности. Для постоянной ширины бинов они эквивалентны, но различие важно, когда ширина бинов варьируется (см. Примечания). Если None (по умолчанию), устанавливает
density=Trueдля обратной совместимости, но предупреждает, если ширина бинов переменная. Установите плотность явно чтобы отключить предупреждение.Добавлено в версии 1.10.0.
- Атрибуты:
random_stateПолучить или установить объект-генератор для генерации случайных величин.
Методы
__call__(*args, **kwds)Зафиксировать распределение для заданных аргументов.
cdf(x, *args, **kwds)Функция кумулятивного распределения заданной случайной величины.
entropy(*args, **kwds)Дифференциальная энтропия случайной величины.
expect([func, args, loc, scale, lb, ub, ...])Вычислить математическое ожидание функции относительно распределения методом численного интегрирования.
fit(data, *args, **kwds)Вернуть оценки параметров формы (если применимо), местоположения и масштаба из данных.
fit_loc_scale(data, *args)Оценить параметры loc и scale из данных, используя 1-й и 2-й моменты.
freeze(*args, **kwds)Зафиксировать распределение для заданных аргументов.
interval(confidence, *args, **kwds)Доверительный интервал с равными площадями вокруг медианы.
isf(q, *args, **kwds)Обратная функция выживания (обратная к
sf) при q заданного случайного распределения.logcdf(x, *args, **kwds)Логарифм функции кумулятивного распределения в точке x для заданного случайного распределения.
logpdf(x, *args, **kwds)Логарифм функции плотности вероятности в x для данного случайного распределения.
logsf(x, *args, **kwds)Логарифм функции выживания данного случайного вектора.
mean(*args, **kwds)Среднее распределения.
median(*args, **kwds)Медиана распределения.
moment(order, *args, **kwds)нецентральный момент распределения указанного порядка.
nnlf(theta, x)Функция отрицательного логарифма правдоподобия.
pdf(x, *args, **kwds)Функция плотности вероятности в точке x для заданной случайной величины.
ppf(q, *args, **kwds)Процентная точка функции (обратная
cdf) при q заданного случайного распределения.rvs(*args, **kwds)Случайные величины заданного типа.
sf(x, *args, **kwds)Функция выживания (1 -
cdf) в точке x заданного случайного распределения.stats(*args, **kwds)Некоторые статистики заданного случайного вектора.
std(*args, **kwds)Стандартное отклонение распределения.
support(*args, **kwargs)Носитель распределения.
var(*args, **kwds)Дисперсия распределения.
Примечания
Когда гистограмма имеет неравные ширины бинов, существует различие между гистограммами, пропорциональными количеству на бин, и гистограммами, пропорциональными плотности вероятности в бине. Если
numpy.histogramвызывается со значением по умолчаниюdensity=False, результирующая гистограмма - это количество отсчётов на бине, поэтомуdensity=Falseдолжен быть передан вrv_histogram. Еслиnumpy.histogramвызывается сdensity=True, полученная гистограмма выражена в терминах плотности вероятности, поэтомуdensity=Trueдолжен быть передан вrv_histogram. Чтобы избежать предупреждений, всегда передавайтеdensityявно, когда входная гистограмма имеет неравные ширины бинов.Нет дополнительных параметров формы, кроме loc и scale. Функция плотности вероятности определена как кусочно-постоянная функция на основе предоставленной гистограммы. Функция распределения является линейной интерполяцией функции плотности вероятности.
Добавлено в версии 0.19.0.
Примеры
Создание распределения scipy.stats из гистограммы numpy
>>> import scipy.stats >>> import numpy as np >>> data = scipy.stats.norm.rvs(size=100000, loc=0, scale=1.5, ... random_state=123) >>> hist = np.histogram(data, bins=100) >>> hist_dist = scipy.stats.rv_histogram(hist, density=False)
Ведёт себя как обычное распределение scipy rv_continuous
>>> hist_dist.pdf(1.0) 0.20538577847618705 >>> hist_dist.cdf(2.0) 0.90818568543056499
PDF равен нулю выше (ниже) самого высокого (низкого) бина гистограммы, определённого максимумом (минимумом) исходного набора данных
>>> hist_dist.pdf(np.max(data)) 0.0 >>> hist_dist.cdf(np.max(data)) 1.0 >>> hist_dist.pdf(np.min(data)) 7.7591907244498314e-05 >>> hist_dist.cdf(np.min(data)) 0.0
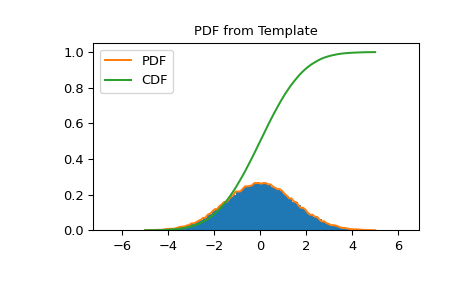
PDF и CDF следуют гистограмме
>>> import matplotlib.pyplot as plt >>> X = np.linspace(-5.0, 5.0, 100) >>> fig, ax = plt.subplots() >>> ax.set_title("PDF from Template") >>> ax.hist(data, density=True, bins=100) >>> ax.plot(X, hist_dist.pdf(X), label='PDF') >>> ax.plot(X, hist_dist.cdf(X), label='CDF') >>> ax.legend() >>> fig.show()