kmeans#
- scipy.cluster.vq.kmeans(obs, k_or_guess, iter=20, порог=1e-05, check_finite=True, *, rng=None, seed=None)[источник]#
Выполняет k-средних на наборе векторов наблюдений, формируя k кластеров.
Алгоритм k-means корректирует классификацию наблюдений по кластерам и обновляет центроиды кластеров до тех пор, пока положение центроидов не стабилизируется за несколько последовательных итераций. В этой реализации алгоритма стабильность центроидов определяется путем сравнения абсолютного значения изменения среднего евклидова расстояния между наблюдениями и соответствующими им центроидами с порогом. Это дает кодбук, отображающий центроиды в коды и наоборот.
- Параметры:
- obsndarray
Каждая строка массива M на N является вектором наблюдения. Столбцы — это признаки, наблюдаемые в каждом наблюдении. Признаки должны быть сначала отбелены с помощью
whitenфункция.- k_or_guessint или ndarray
Количество центроидов для генерации. Каждому центроиду присваивается код, который также является индексом строки центроида в сгенерированной матрице code_book.
Начальные k центроидов выбираются случайным образом из матрицы наблюдений. Альтернативно, передача массива размером k на N задает начальные k центроидов.
- iterint, необязательный
Количество запусков k-means, возвращающее код с наименьшим искажением. Этот аргумент игнорируется, если начальные центроиды указаны массивом для
k_or_guessпараметр. Этот параметр не представляет количество итераций алгоритма k-means.- порогfloat, опционально
Завершает алгоритм k-средних, если изменение искажения с последней итерации k-средних меньше или равно порогу.
- check_finitebool, необязательно
Проверять ли, что входные матрицы содержат только конечные числа. Отключение может дать прирост производительности, но может привести к проблемам (сбои, незавершение) если входные данные содержат бесконечности или NaN. По умолчанию: True
- rng{None, int,
numpy.random.Generator, опционально Если rng передается по ключевому слову, типы, отличные от
numpy.random.Generatorпередаются вnumpy.random.default_rngдля создания экземпляраGenerator. Если rng уже являетсяGeneratorэкземпляр, то предоставленный экземпляр используется. Укажите rng для повторяемого поведения функции.Если этот аргумент передаётся по позиции или seed передается по ключевому слову, устаревшее поведение для аргумента seed применяется:
Если seed равно None (или
numpy.random),numpy.random.RandomStateиспользуется синглтон.Если seed является int, новый
RandomStateиспользуется экземпляр, инициализированный с seed.Если seed уже является
GeneratorилиRandomStateэкземпляр, тогда этот экземпляр используется.
Изменено в версии 1.15.0: В рамках SPEC-007 переход от использования
numpy.random.RandomStatetonumpy.random.Generator, этот ключевое слово было изменено с seed to rng. В переходный период оба ключевых слова будут продолжать работать, хотя только одно может быть указано за раз. После переходного периода вызовы функций, использующие seed ключевое слово будет выдавать предупреждения. Поведение обоих seed и rng описаны выше, но только rng ключевое слово должно использоваться в новом коде.
- Возвращает:
- codebookndarray
Массив k на N из k центроидов. i-й центроид codebook[i] представлен кодом i. Сгенерированные центроиды и коды представляют наименьшее искажение, которое было замечено, не обязательно глобально минимальное искажение. Обратите внимание, что количество центроидов не обязательно совпадает с
k_or_guessпараметр, потому что центроиды, не назначенные ни одному наблюдению, удаляются во время итераций.- distortionfloat
Среднее (не возведённое в квадрат) евклидово расстояние между переданными наблюдениями и сгенерированными центроидами. Обратите внимание на отличие от стандартного определения искажения в контексте алгоритма k-средних, которое представляет собой сумму квадратов расстояний.
Смотрите также
Примечания
Для расширенной функциональности или оптимальной производительности вы можете использовать sklearn.cluster.KMeans. Это является результатом тестирования нескольких реализаций.
kmeansимеет экспериментальную поддержку совместимых с Python Array API Standard бэкендов в дополнение к NumPy. Пожалуйста, рассмотрите тестирование этих функций, установив переменную окруженияSCIPY_ARRAY_API=1и предоставление массивов CuPy, PyTorch, JAX или Dask в качестве аргументов массива. Поддерживаются следующие комбинации бэкенда и устройства (или других возможностей).Библиотека
CPU
GPU
NumPy
✅
н/д
CuPy
н/д
⛔
PyTorch
✅
⛔
JAX
⚠️ нет JIT
⛔
Dask
⚠️ вычисляет граф
н/д
См. Поддержка стандарта array API для получения дополнительной информации.
Примеры
>>> import numpy as np >>> from scipy.cluster.vq import vq, kmeans, whiten >>> import matplotlib.pyplot as plt >>> features = np.array([[ 1.9,2.3], ... [ 1.5,2.5], ... [ 0.8,0.6], ... [ 0.4,1.8], ... [ 0.1,0.1], ... [ 0.2,1.8], ... [ 2.0,0.5], ... [ 0.3,1.5], ... [ 1.0,1.0]]) >>> whitened = whiten(features) >>> book = np.array((whitened[0],whitened[2])) >>> kmeans(whitened,book) (array([[ 2.3110306 , 2.86287398], # random [ 0.93218041, 1.24398691]]), 0.85684700941625547)
>>> codes = 3 >>> kmeans(whitened,codes) (array([[ 2.3110306 , 2.86287398], # random [ 1.32544402, 0.65607529], [ 0.40782893, 2.02786907]]), 0.5196582527686241)
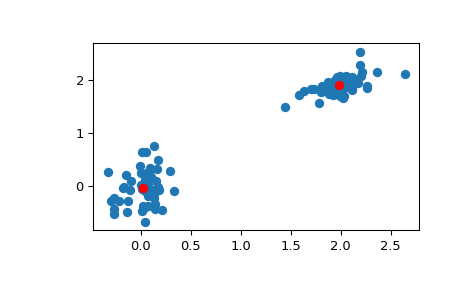
>>> # Create 50 datapoints in two clusters a and b >>> pts = 50 >>> rng = np.random.default_rng() >>> a = rng.multivariate_normal([0, 0], [[4, 1], [1, 4]], size=pts) >>> b = rng.multivariate_normal([30, 10], ... [[10, 2], [2, 1]], ... size=pts) >>> features = np.concatenate((a, b)) >>> # Whiten data >>> whitened = whiten(features) >>> # Find 2 clusters in the data >>> codebook, distortion = kmeans(whitened, 2) >>> # Plot whitened data and cluster centers in red >>> plt.scatter(whitened[:, 0], whitened[:, 1]) >>> plt.scatter(codebook[:, 0], codebook[:, 1], c='r') >>> plt.show()