scipy.special.kolmogorov#
-
scipy.special.kolmogorov(y, выход=None) =
Дополнительная кумулятивная функция распределения (функция выживания) распределения Колмогорова.
Возвращает дополнительную кумулятивную функцию распределения предельного распределения Колмогорова (
D_n*\sqrt(n)при n, стремящемся к бесконечности) двустороннего теста на равенство между эмпирическим и теоретическим распределением. Это равно (пределу при n->бесконечности) вероятности того, чтоsqrt(n) * max absolute deviation > y.- Параметры:
- yfloat array_like
Абсолютное отклонение между эмпирической функцией распределения (ECDF) и целевой функцией распределения, умноженное на sqrt(n).
- выходndarray, необязательно
Необязательный выходной массив для результатов функции
- Возвращает:
- скаляр или ndarray
Значение(я) kolmogorov(y)
Смотрите также
kolmogiОбратная функция выживания для распределения
scipy.stats.kstwobignПредоставляет функциональность как непрерывное распределение
smirnov,smirnoviФункции для одностороннего распределения
Примечания
kolmogorovиспользуется stats.kstest в применении критерия согласия Колмогорова-Смирнова. По историческим причинам эта функция доступна в scpy.special, но рекомендуемый способ для получения наиболее точных вычислений CDF/SF/PDF/PPF/ISF — использовать stats.kstwobign распределение.Примеры
Показать вероятность разрыва не менее 0, 0.5 и 1.0.
>>> import numpy as np >>> from scipy.special import kolmogorov >>> from scipy.stats import kstwobign >>> kolmogorov([0, 0.5, 1.0]) array([ 1. , 0.96394524, 0.26999967])
Сравнить выборку размером 1000, взятую из распределения Лапласа(0, 1), с целевым распределением, нормальным распределением(0, 1).
>>> from scipy.stats import norm, laplace >>> rng = np.random.default_rng() >>> n = 1000 >>> lap01 = laplace(0, 1) >>> x = np.sort(lap01.rvs(n, random_state=rng)) >>> np.mean(x), np.std(x) (-0.05841730131499543, 1.3968109101997568)
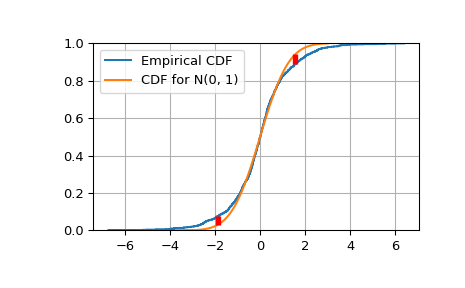
Построить эмпирическую CDF и статистику K-S Dn.
>>> target = norm(0,1) # Normal mean 0, stddev 1 >>> cdfs = target.cdf(x) >>> ecdfs = np.arange(n+1, dtype=float)/n >>> gaps = np.column_stack([cdfs - ecdfs[:n], ecdfs[1:] - cdfs]) >>> Dn = np.max(gaps) >>> Kn = np.sqrt(n) * Dn >>> print('Dn=%f, sqrt(n)*Dn=%f' % (Dn, Kn)) Dn=0.043363, sqrt(n)*Dn=1.371265 >>> print(chr(10).join(['For a sample of size n drawn from a N(0, 1) distribution:', ... ' the approximate Kolmogorov probability that sqrt(n)*Dn>=%f is %f' % ... (Kn, kolmogorov(Kn)), ... ' the approximate Kolmogorov probability that sqrt(n)*Dn<=%f is %f' % ... (Kn, kstwobign.cdf(Kn))])) For a sample of size n drawn from a N(0, 1) distribution: the approximate Kolmogorov probability that sqrt(n)*Dn>=1.371265 is 0.046533 the approximate Kolmogorov probability that sqrt(n)*Dn<=1.371265 is 0.953467
Построить эмпирическую CDF против целевой N(0, 1) CDF.
>>> import matplotlib.pyplot as plt >>> plt.step(np.concatenate([[-3], x]), ecdfs, where='post', label='Empirical CDF') >>> x3 = np.linspace(-3, 3, 100) >>> plt.plot(x3, target.cdf(x3), label='CDF for N(0, 1)') >>> plt.ylim([0, 1]); plt.grid(True); plt.legend(); >>> # Add vertical lines marking Dn+ and Dn- >>> iminus, iplus = np.argmax(gaps, axis=0) >>> plt.vlines([x[iminus]], ecdfs[iminus], cdfs[iminus], ... color='r', linestyle='dashed', lw=4) >>> plt.vlines([x[iplus]], cdfs[iplus], ecdfs[iplus+1], ... color='r', linestyle='dashed', lw=4) >>> plt.show()