scipy.special.tklmbda#
-
scipy.special.tklmbda(x, lmbda, выход=None) =
Функция кумулятивного распределения распределения Тьюки-Лямбда.
- Параметры:
- x, lmbdaarray_like
Параметры
- выходndarray, необязательно
Необязательный выходной массив для результатов функции
- Возвращает:
- функция распределенияскаляр или ndarray
Значение CDF распределения Тьюки-Ламбда
Смотрите также
scipy.stats.tukeylambdaРаспределение Тьюки-лямбда
Примеры
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy.special import tklmbda, expit
Вычислить функцию кумулятивного распределения (CDF) распределения Тьюки-Лямбда в нескольких
xзначения дляlmbda= -1.5.>>> x = np.linspace(-2, 2, 9) >>> x array([-2. , -1.5, -1. , -0.5, 0. , 0.5, 1. , 1.5, 2. ]) >>> tklmbda(x, -1.5) array([0.34688734, 0.3786554 , 0.41528805, 0.45629737, 0.5 , 0.54370263, 0.58471195, 0.6213446 , 0.65311266])
Когда
lmbdaравно 0, функция является логистической сигмоидной функцией, которая реализована вscipy.specialкакexpit.>>> tklmbda(x, 0) array([0.11920292, 0.18242552, 0.26894142, 0.37754067, 0.5 , 0.62245933, 0.73105858, 0.81757448, 0.88079708]) >>> expit(x) array([0.11920292, 0.18242552, 0.26894142, 0.37754067, 0.5 , 0.62245933, 0.73105858, 0.81757448, 0.88079708])
Когда
lmbdaесли значение равно 1, распределение Тьюки-Ламбда равномерно на интервале [-1, 1], поэтому функция распределения (CDF) возрастает линейно.>>> t = np.linspace(-1, 1, 9) >>> tklmbda(t, 1) array([0. , 0.125, 0.25 , 0.375, 0.5 , 0.625, 0.75 , 0.875, 1. ])
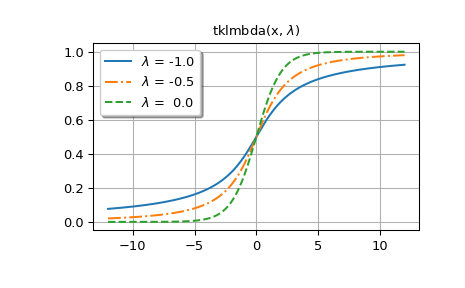
Ниже мы генерируем графики для нескольких значений
lmbda.Первый рисунок показывает графики для
lmbda<= 0.>>> styles = ['-', '-.', '--', ':'] >>> fig, ax = plt.subplots() >>> x = np.linspace(-12, 12, 500) >>> for k, lmbda in enumerate([-1.0, -0.5, 0.0]): ... y = tklmbda(x, lmbda) ... ax.plot(x, y, styles[k], label=rf'$\lambda$ = {lmbda:-4.1f}')
>>> ax.set_title(r'tklmbda(x, $\lambda$)') >>> ax.set_label('x') >>> ax.legend(framealpha=1, shadow=True) >>> ax.grid(True)
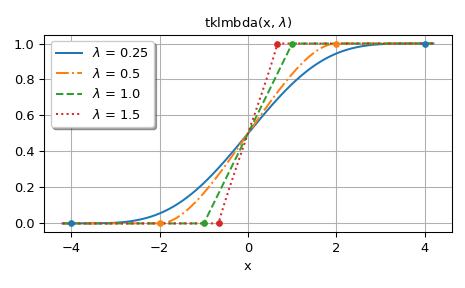
Второй рисунок показывает графики для
lmbda> 0. Точки на графиках показывают границы носителя распределения.>>> fig, ax = plt.subplots() >>> x = np.linspace(-4.2, 4.2, 500) >>> lmbdas = [0.25, 0.5, 1.0, 1.5] >>> for k, lmbda in enumerate(lmbdas): ... y = tklmbda(x, lmbda) ... ax.plot(x, y, styles[k], label=fr'$\lambda$ = {lmbda}')
>>> ax.set_prop_cycle(None) >>> for lmbda in lmbdas: ... ax.plot([-1/lmbda, 1/lmbda], [0, 1], '.', ms=8)
>>> ax.set_title(r'tklmbda(x, $\lambda$)') >>> ax.set_xlabel('x') >>> ax.legend(framealpha=1, shadow=True) >>> ax.grid(True)
>>> plt.tight_layout() >>> plt.show()
CDF распределения Тьюки-лямбда также реализована как
cdfметодscipy.stats.tukeylambda. В следующем,tukeylambda.cdf(x, -0.5)иtklmbda(x, -0.5)вычисляет те же значения:>>> from scipy.stats import tukeylambda >>> x = np.linspace(-2, 2, 9)
>>> tukeylambda.cdf(x, -0.5) array([0.21995157, 0.27093858, 0.33541677, 0.41328161, 0.5 , 0.58671839, 0.66458323, 0.72906142, 0.78004843])
>>> tklmbda(x, -0.5) array([0.21995157, 0.27093858, 0.33541677, 0.41328161, 0.5 , 0.58671839, 0.66458323, 0.72906142, 0.78004843])
Реализация в
tukeylambdaтакже предоставляет параметры положения и масштаба, и другие методы, такие какpdf()(функция плотности вероятности) иppf()(обратная функция CDF), поэтому для работы с распределением Тьюки-лямбда,tukeylambdaявляется более универсальным. Основное преимуществоtklmbdaзаключается в том, что он значительно быстрее, чемtukeylambda.cdf.