scipy.stats.truncnorm#
-
scipy.stats.truncnorm =
Усеченная нормальная непрерывная случайная величина.
Как экземпляр
rv_continuousкласс,truncnormобъект наследует от него коллекцию общих методов (см. ниже полный список), и дополняет их деталями, специфичными для этого конкретного распределения.Методы
rvs(a, b, loc=0, scale=1, size=1, random_state=None)
Случайные величины.
pdf(x, a, b, loc=0, scale=1)
Функция плотности вероятности.
logpdf(x, a, b, loc=0, scale=1)
Логарифм функции плотности вероятности.
cdf(x, a, b, loc=0, scale=1)
Интегральная функция распределения.
logcdf(x, a, b, loc=0, scale=1)
Логарифм функции кумулятивного распределения.
sf(x, a, b, loc=0, scale=1)
Функция выживания (также определяется как
1 - cdf, но sf иногда более точный).logsf(x, a, b, loc=0, scale=1)
Логарифм функции выживания.
ppf(q, a, b, loc=0, scale=1)
Процентная точка функции (обратная
cdf— процентили).isf(q, a, b, loc=0, scale=1)
Обратная функция выживания (обратная к
sf).moment(order, a, b, loc=0, scale=1)
Нецентральный момент указанного порядка.
stats(a, b, loc=0, scale=1, moments='mv')
Среднее ('m'), дисперсия ('v'), асимметрия ('s') и/или эксцесс ('k').
entropy(a, b, loc=0, scale=1)
(Дифференциальная) энтропия случайной величины.
fit(data)
Оценки параметров для общих данных. См. scipy.stats.rv_continuous.fit для подробной документации по ключевым аргументам.
expect(func, args=(a, b), loc=0, scale=1, lb=None, ub=None, conditional=False, **kwds)
Ожидаемое значение функции (одного аргумента) относительно распределения.
median(a, b, loc=0, scale=1)
Медиана распределения.
mean(a, b, loc=0, scale=1)
Среднее распределения.
var(a, b, loc=0, scale=1)
Дисперсия распределения.
std(a, b, loc=0, scale=1)
Стандартное отклонение распределения.
interval(confidence, a, b, loc=0, scale=1)
Доверительный интервал с равными площадями вокруг медианы.
Примечания
Это распределение является нормальным распределением, центрированным на
loc(по умолчанию 0), со стандартным отклонениемscale(по умолчанию 1), и усечённый наaиbстандартные отклонения изloc. Для произвольныхlocиscale,aиbявляются не абсциссы, в которых усекается сдвинутое и масштабированное распределение.Примечание
Если
a_truncиb_truncявляются абсциссами, в которых мы хотим усечь распределение (в отличие от количества стандартных отклонений отloc), тогда мы можем вычислить параметры распределенияaиbследующим образом:a, b = (a_trunc - loc) / scale, (b_trunc - loc) / scale
Это распространённый источник путаницы. Для дополнительного разъяснения, пожалуйста, смотрите пример ниже.
Примеры
>>> import numpy as np >>> from scipy.stats import truncnorm >>> import matplotlib.pyplot as plt >>> fig, ax = plt.subplots(1, 1)
Получить поддержку:
>>> a, b = 0.1, 2 >>> lb, ub = truncnorm.support(a, b)
Вычислить первые четыре момента:
>>> mean, var, skew, kurt = truncnorm.stats(a, b, moments='mvsk')
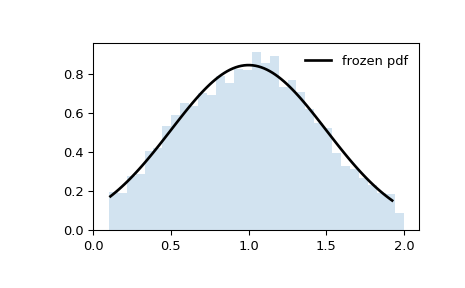
Отображение функции плотности вероятности (
pdf):>>> x = np.linspace(truncnorm.ppf(0.01, a, b), ... truncnorm.ppf(0.99, a, b), 100) >>> ax.plot(x, truncnorm.pdf(x, a, b), ... 'r-', lw=5, alpha=0.6, label='truncnorm pdf')
Альтернативно, объект распределения может быть вызван (как функция) для фиксации параметров формы, местоположения и масштаба. Это возвращает «замороженный» объект RV с заданными фиксированными параметрами.
Зафиксировать распределение и отобразить зафиксированное
pdf:>>> rv = truncnorm(a, b) >>> ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen pdf')
Проверить точность
cdfиppf:>>> vals = truncnorm.ppf([0.001, 0.5, 0.999], a, b) >>> np.allclose([0.001, 0.5, 0.999], truncnorm.cdf(vals, a, b)) True
Генерировать случайные числа:
>>> r = truncnorm.rvs(a, b, size=1000)
И сравните гистограмму:
>>> ax.hist(r, density=True, bins='auto', histtype='stepfilled', alpha=0.2) >>> ax.set_xlim([x[0], x[-1]]) >>> ax.legend(loc='best', frameon=False) >>> plt.show()
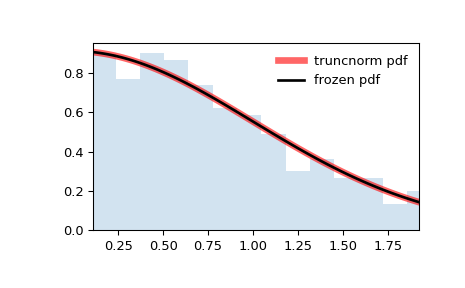
В приведённых выше примерах
loc=0иscale=1, поэтому график обрезается наaслева иbсправа. Однако предположим, что мы хотим создать ту же гистограмму сloc = 1иscale=0.5.>>> loc, scale = 1, 0.5 >>> rv = truncnorm(a, b, loc=loc, scale=scale) >>> x = np.linspace(truncnorm.ppf(0.01, a, b), ... truncnorm.ppf(0.99, a, b), 100) >>> r = rv.rvs(size=1000)
>>> fig, ax = plt.subplots(1, 1) >>> ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen pdf') >>> ax.hist(r, density=True, bins='auto', histtype='stepfilled', alpha=0.2) >>> ax.set_xlim(a, b) >>> ax.legend(loc='best', frameon=False) >>> plt.show()
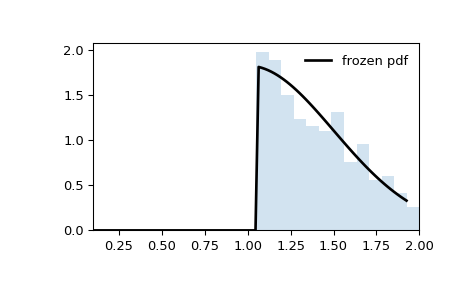
Обратите внимание, что распределение больше не кажется усечённым на абсциссах
aиb. Это потому, что стандартный нормальное распределение сначала усекается наaиb, затем результирующее распределение масштабируется наscaleи сдвинуты наloc. Если мы вместо этого хотим, чтобы сдвинутое и масштабированное распределение было усечено наaиbнам нужно преобразовать эти значения перед передачей их в качестве параметров распределения.>>> a_transformed, b_transformed = (a - loc) / scale, (b - loc) / scale >>> rv = truncnorm(a_transformed, b_transformed, loc=loc, scale=scale) >>> x = np.linspace(truncnorm.ppf(0.01, a, b), ... truncnorm.ppf(0.99, a, b), 100) >>> r = rv.rvs(size=10000)
>>> fig, ax = plt.subplots(1, 1) >>> ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen pdf') >>> ax.hist(r, density=True, bins='auto', histtype='stepfilled', alpha=0.2) >>> ax.set_xlim(a-0.1, b+0.1) >>> ax.legend(loc='best', frameon=False) >>> plt.show()