yeojohnson_llf#
- scipy.stats.yeojohnson_llf(lmb, данные)[источник]#
Функция правдоподобия логарифма yeojohnson.
- Параметры:
- lmbскаляр
Параметр для преобразования Йео-Джонсона. См.
yeojohnsonдля подробностей.- данныеarray_like
Данные для вычисления логарифмического правдоподобия Йео-Джонсона. Если данные является многомерным, логарифмическое правдоподобие вычисляется вдоль первой оси.
- Возвращает:
- llffloat
Логарифмическое правдоподобие Йео-Джонсона для данные задан lmb.
Смотрите также
Примечания
Функция правдоподобия Йео-Джонсона \(l\) определяется здесь как
\[l = -\frac{N}{2} \log(\hat{\sigma}^2) + (\lambda - 1) \sum_i^N \text{sign}(x_i) \log(|x_i| + 1)\]где \(N\) это количество точек данных \(x`=``data`\) и \(\hat{\sigma}^2\) это оцененная дисперсия преобразованных по Йео-Джонсону входных данных \(x\). Это соответствует профиль логарифмического правдоподобия исходных данных \(x\) с некоторыми опущенными постоянными членами.
Добавлено в версии 1.2.0.
Примеры
>>> import numpy as np >>> from scipy import stats >>> import matplotlib.pyplot as plt >>> from mpl_toolkits.axes_grid1.inset_locator import inset_axes
Сгенерировать несколько случайных величин и вычислить значения логарифмического правдоподобия Йео-Джонсона для них для диапазона
lmbdaзначения:>>> x = stats.loggamma.rvs(5, loc=10, size=1000) >>> lmbdas = np.linspace(-2, 10) >>> llf = np.zeros(lmbdas.shape, dtype=float) >>> for ii, lmbda in enumerate(lmbdas): ... llf[ii] = stats.yeojohnson_llf(lmbda, x)
Также найдите оптимальное значение lmbda с помощью
yeojohnson:>>> x_most_normal, lmbda_optimal = stats.yeojohnson(x)
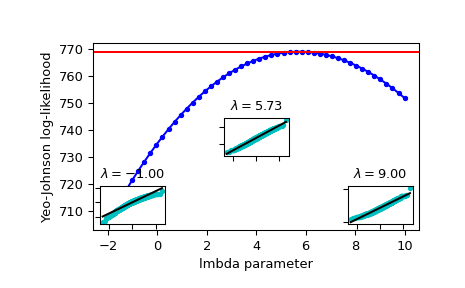
Построить лог-правдоподобие как функцию lmbda. Добавить оптимальную lmbda как горизонтальную линию для проверки, что это действительно оптимум:
>>> fig = plt.figure() >>> ax = fig.add_subplot(111) >>> ax.plot(lmbdas, llf, 'b.-') >>> ax.axhline(stats.yeojohnson_llf(lmbda_optimal, x), color='r') >>> ax.set_xlabel('lmbda parameter') >>> ax.set_ylabel('Yeo-Johnson log-likelihood')
Теперь добавьте несколько графиков вероятности, чтобы показать, что там, где логарифмическое правдоподобие максимизировано, данные, преобразованные с
yeojohnsonнаиболее близко к нормальному:>>> locs = [3, 10, 4] # 'lower left', 'center', 'lower right' >>> for lmbda, loc in zip([-1, lmbda_optimal, 9], locs): ... xt = stats.yeojohnson(x, lmbda=lmbda) ... (osm, osr), (slope, intercept, r_sq) = stats.probplot(xt) ... ax_inset = inset_axes(ax, width="20%", height="20%", loc=loc) ... ax_inset.plot(osm, osr, 'c.', osm, slope*osm + intercept, 'k-') ... ax_inset.set_xticklabels([]) ... ax_inset.set_yticklabels([]) ... ax_inset.set_title(r'$\lambda=%1.2f$' % lmbda)
>>> plt.show()