scipy.special.fdtri#
-
scipy.special.fdtri(dfn, dfd, p, выход=None) =
The p-й квантиль F-распределения.
Эта функция является обратной к CDF F-распределения,
fdtr, возвращая x такой, что fdtr(dfn, dfd, x) = p.- Параметры:
- dfnarray_like
Первый параметр (положительное число с плавающей точкой).
- dfdarray_like
Второй параметр (положительное число с плавающей запятой).
- parray_like
Кумулятивная вероятность, в диапазоне [0, 1].
- выходndarray, необязательно
Необязательный выходной массив для значений функции
- Возвращает:
- xскаляр или ndarray
Квантиль, соответствующий p.
Смотрите также
fdtrФункция кумулятивного распределения распределения Фишера
fdtrcФункция выживания распределения F
scipy.stats.fF-распределение
Примечания
Вычисление выполняется с использованием связи с обратной регуляризованной бета-функцией, \(I^{-1}_x(a, b)\). Пусть \(z = I^{-1}_p(d_d/2, d_n/2).\) Затем,
\[x = \frac{d_d (1 - z)}{d_n z}.\]Если p такой, что \(x < 0.5\), вместо этого используется следующее соотношение для улучшения стабильности: пусть \(z' = I^{-1}_{1 - p}(d_n/2, d_d/2).\) Затем,
\[x = \frac{d_d z'}{d_n (1 - z')}.\]Обертка для Cephes [1] рутина
fdtri.F-распределение также доступно как
scipy.stats.f. Вызовfdtriнапрямую может улучшить производительность по сравнению сppfметодscipy.stats.f(см. последний пример ниже).Ссылки
[1]Библиотека математических функций Cephes, http://www.netlib.org/cephes/
Примеры
fdtriпредставляет обратную функцию распределения F, которая доступна какfdtr. Здесь мы вычисляем функцию распределения дляdf1=1,df2=2вx=3.fdtriзатем возвращает3при одинаковых значениях для df1, df2 и вычисленное значение CDF.>>> import numpy as np >>> from scipy.special import fdtri, fdtr >>> df1, df2 = 1, 2 >>> x = 3 >>> cdf_value = fdtr(df1, df2, x) >>> fdtri(df1, df2, cdf_value) 3.000000000000006
Вычислить функцию в нескольких точках, предоставив массив NumPy для x.
>>> x = np.array([0.1, 0.4, 0.7]) >>> fdtri(1, 2, x) array([0.02020202, 0.38095238, 1.92156863])
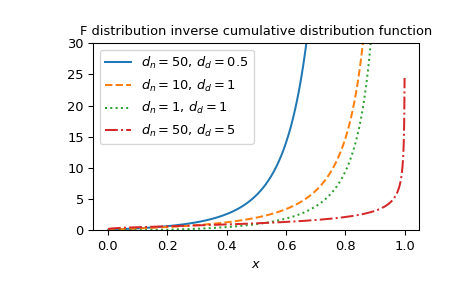
Построить график функции для нескольких наборов параметров.
>>> import matplotlib.pyplot as plt >>> dfn_parameters = [50, 10, 1, 50] >>> dfd_parameters = [0.5, 1, 1, 5] >>> linestyles = ['solid', 'dashed', 'dotted', 'dashdot'] >>> parameters_list = list(zip(dfn_parameters, dfd_parameters, ... linestyles)) >>> x = np.linspace(0, 1, 1000) >>> fig, ax = plt.subplots() >>> for parameter_set in parameters_list: ... dfn, dfd, style = parameter_set ... fdtri_vals = fdtri(dfn, dfd, x) ... ax.plot(x, fdtri_vals, label=rf"$d_n={dfn},\, d_d={dfd}$", ... ls=style) >>> ax.legend() >>> ax.set_xlabel("$x$") >>> title = "F distribution inverse cumulative distribution function" >>> ax.set_title(title) >>> ax.set_ylim(0, 30) >>> plt.show()
F-распределение также доступно как
scipy.stats.f. Использованиеfdtriнапрямую может быть намного быстрее, чем вызовppfметодscipy.stats.f, особенно для небольших массивов или отдельных значений. Для получения одинаковых результатов необходимо использовать следующую параметризацию:stats.f(dfn, dfd).ppf(x)=fdtri(dfn, dfd, x).>>> from scipy.stats import f >>> dfn, dfd = 1, 2 >>> x = 0.7 >>> fdtri_res = fdtri(dfn, dfd, x) # this will often be faster than below >>> f_dist_res = f(dfn, dfd).ppf(x) >>> f_dist_res == fdtri_res # test that results are equal True