scipy.special.stdtrit#
-
scipy.special.stdtrit(df, p, выход=None) =
The p-й квантиль распределения Стьюдента.
Эта функция является обратной к функции кумулятивного распределения (CDF) распределения Стьюдента, возвращая t такой, что stdtr(df, t) = p.
Возвращает аргумент t такой, что stdtr(df, t) равен p.
- Параметры:
- dfarray_like
Степени свободы
- parray_like
Вероятность
- выходndarray, необязательно
Необязательный выходной массив для результатов функции
- Возвращает:
- tскаляр или ndarray
Значение t такой, что
stdtr(df, t) == p
Смотрите также
stdtrCDF распределения Стьюдента
stdtridfобратная функция stdtr относительно df
scipy.stats.tРаспределение Стьюдента
Примечания
Распределение Стьюдента также доступно как
scipy.stats.t. Вызовstdtritнапрямую может улучшить производительность по сравнению сppfметодscipy.stats.t(см. последний пример ниже).stdtritимеет экспериментальную поддержку совместимых с Python Array API Standard бэкендов в дополнение к NumPy. Пожалуйста, рассмотрите тестирование этих функций, установив переменную окруженияSCIPY_ARRAY_API=1и предоставление массивов CuPy, PyTorch, JAX или Dask в качестве аргументов массива. Поддерживаются следующие комбинации бэкенда и устройства (или других возможностей).Библиотека
CPU
GPU
NumPy
✅
н/д
CuPy
н/д
✅
PyTorch
✅
⛔
JAX
⛔
⛔
Dask
✅
н/д
См. Поддержка стандарта array API для получения дополнительной информации.
Примеры
stdtritпредставляет обратную функцию распределения Стьюдента, которая доступна какstdtr. Здесь мы вычисляем функцию распределения дляdfвx=1.stdtritзатем возвращает1с точностью до ошибок округления при том же значении для df и вычисленное значение CDF.>>> import numpy as np >>> from scipy.special import stdtr, stdtrit >>> import matplotlib.pyplot as plt >>> df = 3 >>> x = 1 >>> cdf_value = stdtr(df, x) >>> stdtrit(df, cdf_value) 0.9999999994418539
Постройте график функции для трех различных степеней свободы.
>>> x = np.linspace(0, 1, 1000) >>> parameters = [(1, "solid"), (2, "dashed"), (5, "dotted")] >>> fig, ax = plt.subplots() >>> for (df, linestyle) in parameters: ... ax.plot(x, stdtrit(df, x), ls=linestyle, label=f"$df={df}$") >>> ax.legend() >>> ax.set_ylim(-10, 10) >>> ax.set_title("Student t distribution quantile function") >>> plt.show()
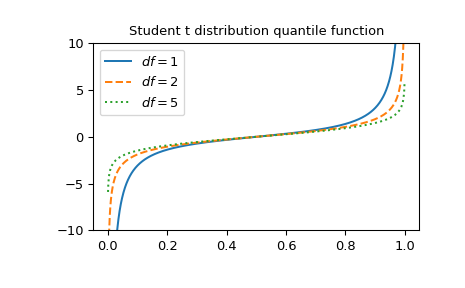
Функцию можно вычислить для нескольких степеней свободы одновременно, предоставив массив NumPy или список для df:
>>> stdtrit([1, 2, 3], 0.7) array([0.72654253, 0.6172134 , 0.58438973])
Можно вычислить функцию в нескольких точках для нескольких различных степеней свободы одновременно, предоставив массивы для df и p с формами, совместимыми для трансляции. Вычислить
stdtritв 4 точках для 3 степеней свободы, что приводит к массиву формы 3x4.>>> dfs = np.array([[1], [2], [3]]) >>> p = np.array([0.2, 0.4, 0.7, 0.8]) >>> dfs.shape, p.shape ((3, 1), (4,))
>>> stdtrit(dfs, p) array([[-1.37638192, -0.3249197 , 0.72654253, 1.37638192], [-1.06066017, -0.28867513, 0.6172134 , 1.06066017], [-0.97847231, -0.27667066, 0.58438973, 0.97847231]])
Распределение t также доступно как
scipy.stats.t. Вызовstdtritнапрямую может быть намного быстрее, чем вызовppfметодscipy.stats.t. Чтобы получить те же результаты, необходимо использовать следующую параметризацию:scipy.stats.t(df).ppf(x) = stdtrit(df, x).>>> from scipy.stats import t >>> df, x = 3, 0.5 >>> stdtrit_result = stdtrit(df, x) # this can be faster than below >>> stats_result = t(df).ppf(x) >>> stats_result == stdtrit_result # test that results are equal True