scipy.stats.hypergeom#
-
scipy.stats.hypergeom =
Гипергеометрическая дискретная случайная величина.
Гипергеометрическое распределение моделирует извлечение объектов из корзины. M общее количество объектов, n является общим числом объектов Типа I. Случайная величина представляет количество объектов Типа I в N выбранных без возвращения из общей популяции.
Как экземпляр
rv_discreteкласс,hypergeomобъект наследует от него коллекцию общих методов (см. ниже полный список), и дополняет их деталями, специфичными для этого конкретного распределения.Методы
rvs(M, n, N, loc=0, size=1, random_state=None)
Случайные величины.
pmf(k, M, n, N, loc=0)
Функция вероятности массы.
logpmf(k, M, n, N, loc=0)
Логарифм функции вероятности.
cdf(k, M, n, N, loc=0)
Интегральная функция распределения.
logcdf(k, M, n, N, loc=0)
Логарифм функции кумулятивного распределения.
sf(k, M, n, N, loc=0)
Функция выживания (также определяется как
1 - cdf, но sf иногда более точный).logsf(k, M, n, N, loc=0)
Логарифм функции выживания.
ppf(q, M, n, N, loc=0)
Процентная точка функции (обратная
cdf— процентили).isf(q, M, n, N, loc=0)
Обратная функция выживания (обратная к
sf).stats(M, n, N, loc=0, moments='mv')
Среднее ('m'), дисперсия ('v'), асимметрия ('s') и/или эксцесс ('k').
entropy(M, n, N, loc=0)
(Дифференциальная) энтропия случайной величины.
expect(func, args=(M, n, N), loc=0, lb=None, ub=None, conditional=False)
Ожидаемое значение функции (одного аргумента) относительно распределения.
median(M, n, N, loc=0)
Медиана распределения.
mean(M, n, N, loc=0)
Среднее распределения.
var(M, n, N, loc=0)
Дисперсия распределения.
std(M, n, N, loc=0)
Стандартное отклонение распределения.
interval(confidence, M, n, N, loc=0)
Доверительный интервал с равными площадями вокруг медианы.
Смотрите также
Примечания
Символы, используемые для обозначения параметров формы (M, n, и N) не являются общепринятыми. См. Примеры для уточнения определений, используемых здесь.
Функция вероятности массы определяется как,
\[p(k, M, n, N) = \frac{\binom{n}{k} \binom{M - n}{N - k}} {\binom{M}{N}}\]для \(k \in [\max(0, N - M + n), \min(n, N)]\), где биномиальные коэффициенты определяются как,
\[\binom{n}{k} \equiv \frac{n!}{k! (n - k)!}.\]Это распределение использует процедуры из библиотеки Boost Math C++ для вычисления
pmf,cdf,sfиstatsметоды. [1]Функция вероятности массы выше определена в «стандартизированной» форме. Для сдвига распределения используйте
locпараметра. В частности,hypergeom.pmf(k, M, n, N, loc)тождественно эквивалентноhypergeom.pmf(k - loc, M, n, N).Ссылки
[1]Разработчики Boost. «Boost C++ Libraries». https://www.boost.org/.
Примеры
>>> import numpy as np >>> from scipy.stats import hypergeom >>> import matplotlib.pyplot as plt
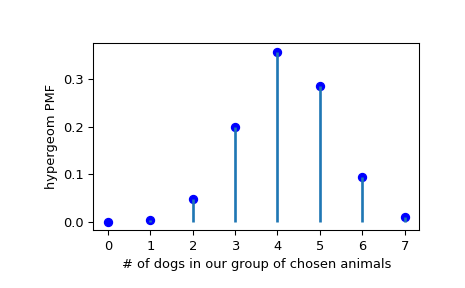
Предположим, у нас есть коллекция из 20 животных, из которых 7 — собаки. Тогда если мы хотим узнать вероятность найти заданное количество собак, если мы выберем случайным образом 12 из 20 животных, мы можем инициализировать замороженное распределение и построить функцию вероятности массы:
>>> [M, n, N] = [20, 7, 12] >>> rv = hypergeom(M, n, N) >>> x = np.arange(0, n+1) >>> pmf_dogs = rv.pmf(x)
>>> fig = plt.figure() >>> ax = fig.add_subplot(111) >>> ax.plot(x, pmf_dogs, 'bo') >>> ax.vlines(x, 0, pmf_dogs, lw=2) >>> ax.set_xlabel('# of dogs in our group of chosen animals') >>> ax.set_ylabel('hypergeom PMF') >>> plt.show()
Вместо использования замороженного распределения мы также можем использовать
hypergeomметоды напрямую. Например, чтобы получить функцию кумулятивного распределения, используйте:>>> prb = hypergeom.cdf(x, M, n, N)
И для генерации случайных чисел:
>>> R = hypergeom.rvs(M, n, N, size=10)