

NumPy: абсолютные основы для начинающих#
Добро пожаловать в руководство для абсолютных новичков по NumPy!
NumPy (Numerical Python) — это библиотека Python с открытым исходным кодом, широко используемая в науке и технике. Библиотека NumPy содержит многомерные структуры данных массивов, такие как однородные, N-мерные
ndarray, и обширную библиотеку функций, которые эффективно работают с этими структурами данных. Узнайте больше о NumPy на Что такое NumPy, и если у вас есть комментарии или предложения, пожалуйста,
обратиться!
Как импортировать NumPy#
После установка NumPy, он может быть импортирован в код Python как:
import numpy as np
Это широко распространённое соглашение позволяет получить доступ к функциям NumPy с коротким,
узнаваемым префиксом (np.) при этом различая особенности NumPy от других, имеющих то же имя.
Чтение примера кода#
Во всей документации NumPy вы найдете блоки, которые выглядят как:
>>> a = np.array([[1, 2, 3],
... [4, 5, 6]])
>>> a.shape
(2, 3)
Текст, предшествующий >>> или ... является входные данные, код, который вы введёте в скрипте или в Python-консоли. Всё остальное вывод, результаты
запуска вашего кода. Обратите внимание, что >>> и ... не являются частью кода и могут вызвать ошибку при вводе в командной строке Python.
Чтобы запустить код из примеров, вы можете скопировать и вставить его в скрипт Python или REPL, либо использовать экспериментальные интерактивные примеры в браузере, предоставленные в различных местах документации.
Зачем использовать NumPy?#
Списки Python — отличные универсальные контейнеры. Они могут быть «гетерогенными», что означает, что они могут содержать элементы различных типов, и они довольно быстры при выполнении отдельных операций с небольшим количеством элементов.
В зависимости от характеристик данных и типов операций, которые необходимо выполнить, другие контейнеры могут быть более подходящими; используя эти характеристики, мы можем улучшить скорость, уменьшить потребление памяти и предложить высокоуровневый синтаксис для выполнения различных общих задач обработки. NumPy превосходно работает, когда имеются большие объемы "однородных" (одного типа) данных для обработки на CPU.
Что такое «массив»?#
В компьютерном программировании массив — это структура для хранения и извлечения данных. Мы часто говорим о массиве как о сетке в пространстве, где каждая ячейка хранит один элемент данных. Например, если каждый элемент данных является числом, мы можем визуализировать «одномерный» массив как список:
Двумерный массив будет похож на таблицу:
Трёхмерный массив был бы похож на набор таблиц, возможно, сложенных, как если бы они были напечатаны на отдельных страницах. В NumPy эта идея обобщена на произвольное количество измерений, поэтому основной класс массива называется ndarray: представляет собой «N-мерный массив».
Большинство массивов NumPy имеют некоторые ограничения. Например:
Все элементы массива должны быть одного типа данных.
После создания общий размер массива не может изменяться.
Форма должна быть «прямоугольной», а не «рваной»; например, каждая строка двумерного массива должна иметь одинаковое количество столбцов.
Когда эти условия выполняются, NumPy использует эти характеристики, чтобы сделать массив быстрее, более эффективным по памяти и более удобным в использовании, чем менее ограничительные структуры данных.
В оставшейся части этого документа мы будем использовать слово «массив» для обозначения экземпляра ndarray.
Основы массивов#
Один из способов инициализации массива — использование последовательности Python, такой как список. Например:
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a
array([1, 2, 3, 4, 5, 6])
Элементы массива могут быть доступны в различными способами. Например, мы можем получить доступ к отдельному элементу этого массива так же, как к элементу в исходном списке: используя целочисленный индекс элемента в квадратных скобках.
>>> a[0]
1
Примечание
Как и встроенные последовательности Python, массивы NumPy «индексируются с 0»: первый
элемент массива доступен с использованием индекса 0, а не 1.
Как и исходный список, массив является изменяемым.
>>> a[0] = 10
>>> a
array([10, 2, 3, 4, 5, 6])
Также, как и в исходном списке, для индексации можно использовать нотацию срезов Python.
>>> a[:3]
array([10, 2, 3])
Одно из основных различий заключается в том, что срез индексации списка копирует элементы в новый список, но срез массива возвращает представление: объект, который ссылается на данные в исходном массиве. Исходный массив можно изменять с помощью представления.
>>> b = a[3:]
>>> b
array([4, 5, 6])
>>> b[0] = 40
>>> a
array([ 10, 2, 3, 40, 5, 6])
См. Копии и представления для более полного объяснения того, когда операции с массивами возвращают представления, а не копии.
Двух- и более мерные массивы могут быть инициализированы из вложенных Python последовательностей:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
>>> a
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
В NumPy измерение массива иногда называют «осью». Эта терминология может быть полезна для различения размерности массива и размерности данных, представленных массивом. Например, массив a может представлять три точки, каждая из которых лежит в
четырёхмерном пространстве, но a имеет только две "оси".
Еще одно различие между массивом и списком списков заключается в том, что элемент массива может быть доступен путем указания индекса вдоль каждой оси в пределах одиночный набор квадратных скобок, разделенных запятыми. Например, элемент 8 находится в строке 1 и столбец 3:
>>> a[1, 3]
8
Примечание
В математике принято ссылаться на элементы матрицы сначала по индексу строки, а затем по индексу столбца. Это верно для двумерных массивов, но лучшая мысленная модель - считать, что индекс столбца приходит last и индекс строки как предпоследнийЭто обобщается на массивы с любой количество измерений.
Примечание
Вы можете услышать, что 0-D (нуль-мерный) массив называют 'скаляром', 1-D (одномерный) массив — 'вектором', 2-D (двумерный) массив — 'матрицей' или N-D (N-мерный, где 'N' — обычно целое число больше 2) массив — 'тензором'. Для ясности лучше избегать математических терминов при ссылке на массив, потому что математические объекты с этими именами ведут себя иначе, чем массивы (например, 'матричное' умножение принципиально отличается от 'массивного' умножения), и есть другие объекты в экосистеме научного Python, которые имеют эти имена (например, фундаментальная структура данных PyTorch — 'тензор').
Атрибуты массива#
Этот раздел охватывает ndim, shape, size, и dtype
атрибуты массива.
Количество измерений массива содержится в ndim атрибут.
>>> a.ndim
2
Форма массива — это кортеж неотрицательных целых чисел, которые указывают количество элементов вдоль каждого измерения.
>>> a.shape
(3, 4)
>>> len(a.shape) == a.ndim
True
Фиксированное, общее количество элементов в массиве содержится в size
атрибут.
>>> a.size
12
>>> import math
>>> a.size == math.prod(a.shape)
True
Массивы обычно «однородны», что означает, что они содержат элементы только одного «типа данных». Тип данных записывается в dtype атрибут.
>>> a.dtype
dtype('int64') # "int" for integer, "64" for 64-bit
Подробнее об атрибутах массива читайте здесь и узнать о объекты массивов здесь.
Как создать базовый массив#
Этот раздел охватывает np.zeros(), np.ones(),
np.empty(), np.arange(), np.linspace()
Помимо создания массива из последовательности элементов, вы можете легко создать массив, заполненный 0’s:
>>> np.zeros(2)
array([0., 0.])
Или массив, заполненный 1’s:
>>> np.ones(2)
array([1., 1.])
Или даже пустой массив! Функция empty создаёт массив, начальное содержимое которого случайно и зависит от состояния памяти. Причина использования
empty над zeros (или что-то подобное) — это скорость — просто убедитесь, что
заполняете каждый элемент впоследствии!
>>> # Create an empty array with 2 elements
>>> np.empty(2)
array([3.14, 42. ]) # may vary
Вы можете создать массив с диапазоном элементов:
>>> np.arange(4)
array([0, 1, 2, 3])
И даже массив, содержащий диапазон равномерно распределенных интервалов. Для этого вы укажете первое число, последнее числодолжны быть включены в старые категории. Значения, которые были в удаленных категориях, будут установлены в NaN шаг.
>>> np.arange(2, 9, 2)
array([2, 4, 6, 8])
Вы также можете использовать np.linspace() для создания массива со значениями, равномерно распределёнными в указанном интервале:
>>> np.linspace(0, 10, num=5)
array([ 0. , 2.5, 5. , 7.5, 10. ])
Указание типа данных
Хотя тип данных по умолчанию — с плавающей точкой (np.float64), вы можете явно указать, какой тип данных вы хотите, используя dtype ключевое слово.
>>> x = np.ones(2, dtype=np.int64)
>>> x
array([1, 1])
Добавление, удаление и сортировка элементов#
Этот раздел охватывает np.sort(), np.concatenate()
Сортировка массива проста с помощью np.sort(). Вы можете указать ось, вид и порядок при вызове функции.
Если вы начнете с этого массива:
>>> arr = np.array([2, 1, 5, 3, 7, 4, 6, 8])
Вы можете быстро отсортировать числа в порядке возрастания с помощью:
>>> np.sort(arr)
array([1, 2, 3, 4, 5, 6, 7, 8])
В дополнение к sort, который возвращает отсортированную копию массива, вы можете использовать:
argsort, который является косвенной сортировкой по указанной оси,lexsort, который является косвенной устойчивой сортировкой по нескольким ключам,searchsorted, который найдет элементы в отсортированном массиве, иpartition, который является частичной сортировкой.
Чтобы узнать больше о сортировке массива, см.: sort.
Если вы начнете с этих массивов:
>>> a = np.array([1, 2, 3, 4])
>>> b = np.array([5, 6, 7, 8])
Вы можете объединить их с np.concatenate().
>>> np.concatenate((a, b))
array([1, 2, 3, 4, 5, 6, 7, 8])
Или, если вы начинаете с этих массивов:
>>> x = np.array([[1, 2], [3, 4]])
>>> y = np.array([[5, 6]])
Вы можете объединить их с:
>>> np.concatenate((x, y), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
Чтобы удалить элементы из массива, достаточно использовать индексацию для выбора элементов, которые вы хотите оставить.
Чтобы узнать больше о concatenate, см.: concatenate.
Как узнать форму и размер массива?#
Этот раздел охватывает ndarray.ndim, ndarray.size, ndarray.shape
ndarray.ndim покажет количество осей или измерений массива.
ndarray.size покажет общее количество элементов массива. Это product из элементов формы массива.
ndarray.shape отобразит кортеж целых чисел, указывающих количество
элементов, хранящихся вдоль каждого измерения массива. Если, например, у вас есть
2-D массив с 2 строками и 3 столбцами, форма вашего массива (2, 3).
Например, если вы создадите этот массив:
>>> array_example = np.array([[[0, 1, 2, 3],
... [4, 5, 6, 7]],
...
... [[0, 1, 2, 3],
... [4, 5, 6, 7]],
...
... [[0 ,1 ,2, 3],
... [4, 5, 6, 7]]])
Чтобы найти количество измерений массива, выполните:
>>> array_example.ndim
3
Чтобы найти общее количество элементов в массиве, выполните:
>>> array_example.size
24
И чтобы найти форму вашего массива, выполните:
>>> array_example.shape
(3, 2, 4)
Можно ли изменить форму массива?#
Этот раздел охватывает arr.reshape()
Да!
Используя arr.reshape() придаст новую форму массиву без изменения
данных. Просто помните, что при использовании метода reshape массив, который вы хотите
создать, должен иметь то же количество элементов, что и исходный массив. Если вы
начинаете с массива из 12 элементов, вам нужно убедиться, что ваш новый
массив также имеет в общей сложности 12 элементов.
Если вы начнете с этого массива:
>>> a = np.arange(6)
>>> print(a)
[0 1 2 3 4 5]
Вы можете использовать reshape() для изменения формы вашего массива. Например, вы можете изменить форму этого массива на массив с тремя строками и двумя столбцами:
>>> b = a.reshape(3, 2)
>>> print(b)
[[0 1]
[2 3]
[4 5]]
С np.reshape, вы можете указать несколько необязательных параметров:
>>> np.reshape(a, shape=(1, 6), order='C')
array([[0, 1, 2, 3, 4, 5]])
a — это массив, который нужно преобразовать.
shape это новая форма, которую вы хотите. Вы можете указать целое число или кортеж целых чисел. Если вы укажете целое число, результатом будет массив такой длины. Форма должна быть совместима с исходной формой.
order: C означает чтение/запись элементов с использованием порядка индексов, подобного C,
F означает чтение/запись элементов с использованием порядка индексов, подобного Fortran, A
означает чтение/запись элементов в порядке индексов, подобном Fortran, если a является Fortran
непрерывным в памяти, в противном случае — в порядке, подобном C. (Это необязательный параметр и
не требует указания.)
Если вы хотите узнать больше о порядке C и Fortran, вы можете подробнее о внутренней организации массивов NumPy читайте здесь. По сути, порядки C и Fortran связаны с тем, как индексы соответствуют порядку хранения массива в памяти. В Fortran, при перемещении по элементам двумерного массива, как он хранится в памяти, первый индекс является наиболее быстро изменяющимся индексом. Поскольку первый индекс переходит к следующей строке при изменении, матрица хранится по одному столбцу за раз. Вот почему Fortran считается Язык с порядком столбцов. В C, с другой стороны, last индекс изменяется наиболее быстро. Матрица хранится по строкам, что делает её Язык с порядком строк. Что делать для C или Fortran зависит от того, что важнее: сохранить соглашение об индексации или не переупорядочивать данные.
Как преобразовать одномерный массив в двумерный (как добавить новую ось к массиву)#
Этот раздел охватывает np.newaxis, np.expand_dims
Вы можете использовать np.newaxis и np.expand_dims для увеличения размерности
существующего массива.
Используя np.newaxis увеличит размерность вашего массива на одно измерение
при однократном использовании. Это означает, что 1D массив станет 2D массив, a
2D массив станет 3D массива и так далее.
Например, если вы начинаете с этого массива:
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a.shape
(6,)
Вы можете использовать np.newaxis добавить новую ось:
>>> a2 = a[np.newaxis, :]
>>> a2.shape
(1, 6)
Вы можете явно преобразовать одномерный массив либо в вектор-строку, либо в вектор-столбец, используя np.newaxis. Например, вы можете преобразовать 1D массив в вектор-строку,
вставив ось вдоль первого измерения:
>>> row_vector = a[np.newaxis, :]
>>> row_vector.shape
(1, 6)
Или, для вектор-столбца, можно вставить ось вдоль второго измерения:
>>> col_vector = a[:, np.newaxis]
>>> col_vector.shape
(6, 1)
Вы также можете расширить массив, вставив новую ось в указанную позицию
с помощью np.expand_dims.
Например, если вы начинаете с этого массива:
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a.shape
(6,)
Вы можете использовать np.expand_dims добавить ось на позиции индекса 1 с:
>>> b = np.expand_dims(a, axis=1)
>>> b.shape
(6, 1)
Вы можете добавить ось в позицию индекса 0 с помощью:
>>> c = np.expand_dims(a, axis=0)
>>> c.shape
(1, 6)
Найдите больше информации о newaxis здесь и
expand_dims в expand_dims.
Индексирование и срезы#
Вы можете индексировать и срезать массивы NumPy теми же способами, что и списки Python.
>>> data = np.array([1, 2, 3])
>>> data[1]
2
>>> data[0:2]
array([1, 2])
>>> data[1:]
array([2, 3])
>>> data[-2:]
array([2, 3])
Вы можете визуализировать это так:

Возможно, вы захотите взять часть массива или определенные элементы массива для использования в дальнейшем анализе или дополнительных операциях. Для этого вам потребуется выполнить подмножество, срез и/или индексацию массивов.
Если вы хотите выбрать значения из вашего массива, удовлетворяющие определенным условиям, это просто сделать с помощью NumPy.
Например, если вы начинаете с этого массива:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Вы можете легко вывести все значения в массиве, которые меньше 5.
>>> print(a[a < 5])
[1 2 3 4]
Вы также можете выбрать, например, числа, которые равны или больше 5, и использовать это условие для индексирования массива.
>>> five_up = (a >= 5)
>>> print(a[five_up])
[ 5 6 7 8 9 10 11 12]
Вы можете выбрать элементы, которые делятся на 2:
>>> divisible_by_2 = a[a%2==0]
>>> print(divisible_by_2)
[ 2 4 6 8 10 12]
Или вы можете выбрать элементы, удовлетворяющие двум условиям, используя & и |
операторы:
>>> c = a[(a > 2) & (a < 11)]
>>> print(c)
[ 3 4 5 6 7 8 9 10]
Вы также можете использовать логические операторы & и | чтобы возвращать логические значения, указывающие, выполняются ли значения в массиве определенное условие. Это может быть полезно с массивами, содержащими имена или другие категориальные значения.
>>> five_up = (a > 5) | (a == 5)
>>> print(five_up)
[[False False False False]
[ True True True True]
[ True True True True]]
Вы также можете использовать np.nonzero() для выбора элементов или индексов из массива.
Начиная с этого массива:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Вы можете использовать np.nonzero() для вывода индексов элементов, которые, например, меньше 5:
>>> b = np.nonzero(a < 5)
>>> print(b)
(array([0, 0, 0, 0]), array([0, 1, 2, 3]))
В этом примере возвращается кортеж массивов: по одному для каждого измерения. Первый массив представляет индексы строк, где найдены эти значения, а второй массив представляет индексы столбцов, где найдены значения.
Если вы хотите сгенерировать список координат, где существуют элементы, вы можете объединить массивы, перебрать список координат и вывести их. Например:
>>> list_of_coordinates= list(zip(b[0], b[1]))
>>> for coord in list_of_coordinates:
... print(coord)
(np.int64(0), np.int64(0))
(np.int64(0), np.int64(1))
(np.int64(0), np.int64(2))
(np.int64(0), np.int64(3))
Вы также можете использовать np.nonzero() для вывода элементов в массиве, которые меньше 5, с помощью:
>>> print(a[b])
[1 2 3 4]
Если элемент, который вы ищете, не существует в массиве, то возвращаемый массив индексов будет пустым. Например:
>>> not_there = np.nonzero(a == 42)
>>> print(not_there)
(array([], dtype=int64), array([], dtype=int64))
Узнать больше о индексирование и срезы здесь и здесь.
Подробнее об использовании функции nonzero: nonzero.
Как создать массив из существующих данных#
Этот раздел охватывает slicing and indexing, np.vstack(), np.hstack(),
np.hsplit(), .view(), copy()
Вы можете легко создать новый массив из части существующего массива.
Допустим, у вас есть такой массив:
>>> a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Вы можете создать новый массив из части вашего массива в любое время, указав где вы хотите выполнить срез массива.
>>> arr1 = a[3:8]
>>> arr1
array([4, 5, 6, 7, 8])
Здесь вы взяли часть вашего массива от позиции индекса 3 до позиции индекса 8, но не включая саму позицию 8.
Напоминание: Индексы массива начинаются с 0. Это означает, что первый элемент массива находится по индексу 0, второй элемент - по индексу 1 и так далее.
Вы также можете объединить два существующих массива, как вертикально, так и горизонтально. Допустим,
у вас есть два массива, a1 и a2:
>>> a1 = np.array([[1, 1],
... [2, 2]])
>>> a2 = np.array([[3, 3],
... [4, 4]])
Вы можете сложить их вертикально с помощью vstack:
>>> np.vstack((a1, a2))
array([[1, 1],
[2, 2],
[3, 3],
[4, 4]])
Или сложить их горизонтально с hstack:
>>> np.hstack((a1, a2))
array([[1, 1, 3, 3],
[2, 2, 4, 4]])
Вы можете разделить массив на несколько меньших массивов с помощью hsplit. Вы можете
указать либо количество одинаковых по форме массивов для возврата, либо столбцы
после в котором должно происходить деление.
Допустим, у вас есть такой массив:
>>> x = np.arange(1, 25).reshape(2, 12)
>>> x
array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]])
Если вы хотите разделить этот массив на три массива одинаковой формы, вы должны выполнить:
>>> np.hsplit(x, 3)
[array([[ 1, 2, 3, 4],
[13, 14, 15, 16]]), array([[ 5, 6, 7, 8],
[17, 18, 19, 20]]), array([[ 9, 10, 11, 12],
[21, 22, 23, 24]])]
Если вы хотели разделить массив после третьего и четвертого столбца, вы бы запустили:
>>> np.hsplit(x, (3, 4))
[array([[ 1, 2, 3],
[13, 14, 15]]), array([[ 4],
[16]]), array([[ 5, 6, 7, 8, 9, 10, 11, 12],
[17, 18, 19, 20, 21, 22, 23, 24]])]
Узнайте больше о стекировании и разделении массивов здесь.
Вы можете использовать view метод для создания нового объекта массива, который ссылается на
те же данные, что и исходный массив (a поверхностная копия).
Представления — важная концепция NumPy! Функции NumPy, а также операции, такие как индексирование и срезы, будут возвращать представления, когда это возможно. Это экономит память и работает быстрее (не нужно создавать копию данных). Однако важно помнить об этом — изменение данных в представлении также изменяет исходный массив!
Допустим, вы создаете этот массив:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Теперь мы создаём массив b1 с помощью среза a и изменить первый элемент
b1. Это изменит соответствующий элемент в a а также!
>>> b1 = a[0, :]
>>> b1
array([1, 2, 3, 4])
>>> b1[0] = 99
>>> b1
array([99, 2, 3, 4])
>>> a
array([[99, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
Используя copy метод создаст полную копию массива и его данных (
глубокое копирование). Чтобы использовать это на вашем массиве, вы можете запустить:
>>> b2 = a.copy()
Базовые операции с массивами#
Этот раздел охватывает сложение, вычитание, умножение, деление и многое другое
После создания массивов можно начать с ними работать. Допустим, например, что вы создали два массива: один называется "data", а другой "ones"
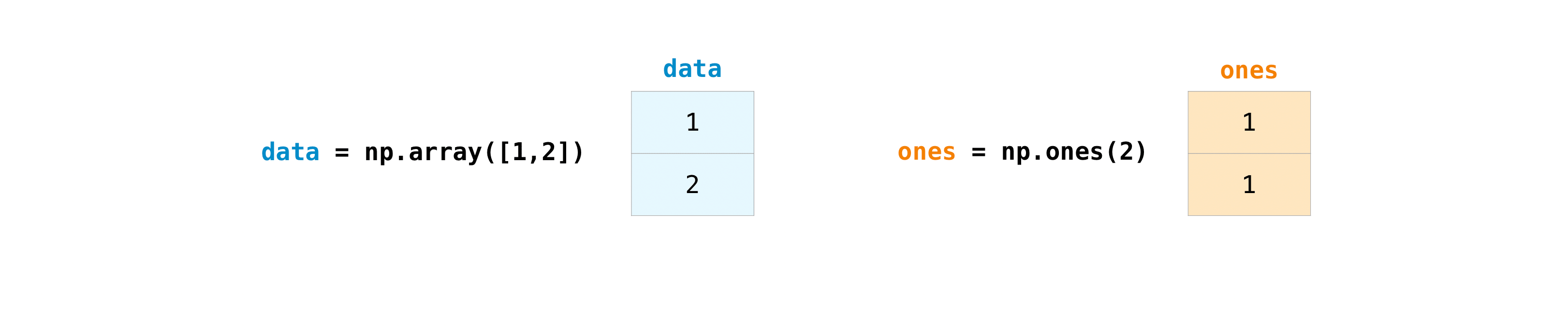
Вы можете складывать массивы с помощью знака плюс.
>>> data = np.array([1, 2])
>>> ones = np.ones(2, dtype=int)
>>> data + ones
array([2, 3])
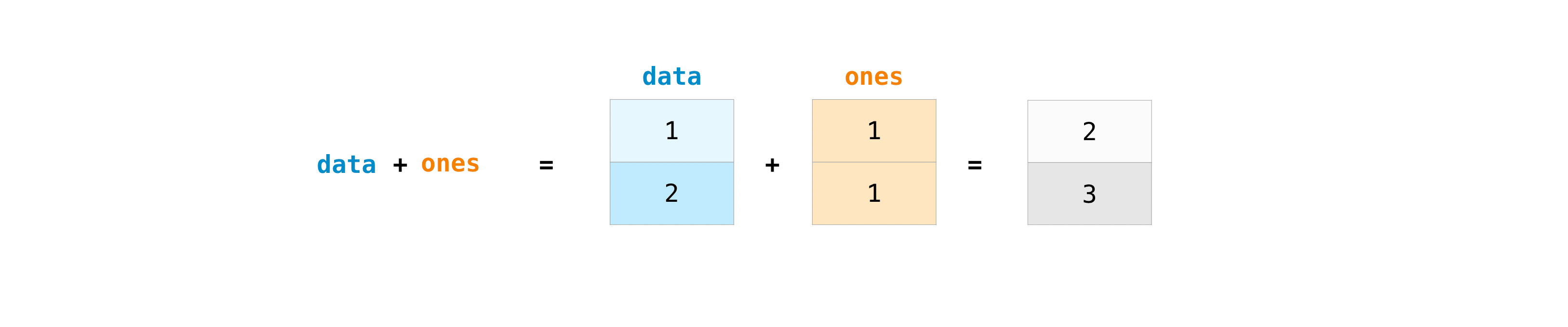
Вы, конечно, можете делать больше, чем просто сложение!
>>> data - ones
array([0, 1])
>>> data * data
array([1, 4])
>>> data / data
array([1., 1.])
Базовые операции просты в NumPy. Если нужно найти сумму элементов массива, используйте sum(). Это работает для 1D массивов, 2D массивов
и массивов более высоких размерностей.
>>> a = np.array([1, 2, 3, 4])
>>> a.sum()
10
Чтобы добавить строки или столбцы в двумерном массиве, вы должны указать ось.
Если вы начнете с этого массива:
>>> b = np.array([[1, 1], [2, 2]])
Вы можете суммировать по оси строк с помощью:
>>> b.sum(axis=0)
array([3, 3])
Вы можете суммировать по оси столбцов с:
>>> b.sum(axis=1)
array([2, 4])
Трансляция (Broadcasting)#
Бывают случаи, когда может потребоваться выполнить операцию между массивом и одним числом (также называемым операция между вектором и скаляром) или между массивами двух разных размеров. Например, ваш массив (назовём его «data») может содержать информацию о расстоянии в милях, но вы хотите преобразовать её в километры. Вы можете выполнить эту операцию с помощью:
>>> data = np.array([1.0, 2.0])
>>> data * 1.6
array([1.6, 3.2])
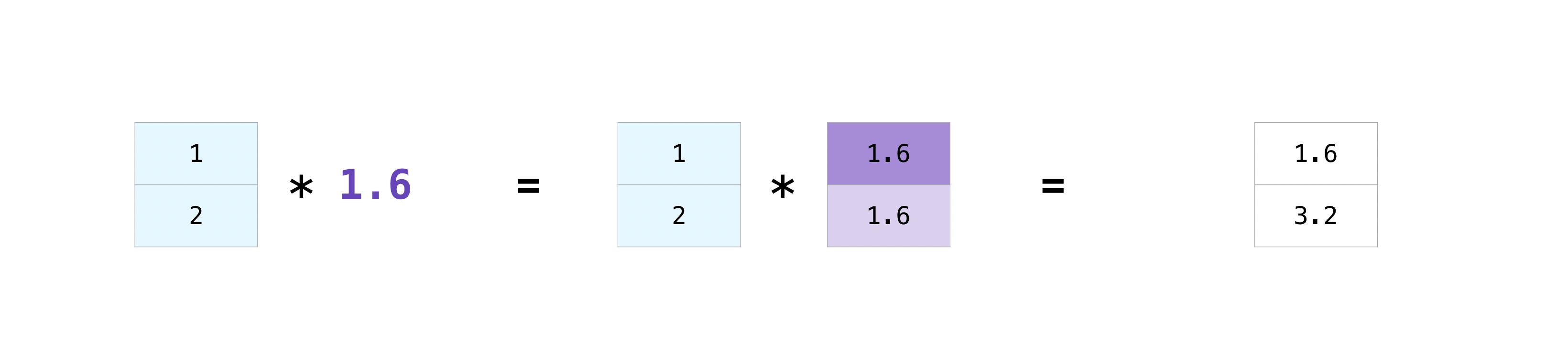
NumPy понимает, что умножение должно происходить с каждой ячейкой. Эта концепция называется вещание. Broadcasting — это механизм, который позволяет NumPy выполнять операции над массивами разных форм. Размерности вашего массива должны быть совместимы, например, когда размерности обоих массивов равны или когда одна из них равна 1. Если размерности не совместимы, вы получите ValueError.
Более полезные операции с массивами#
Этот раздел охватывает максимум, минимум, сумму, среднее значение, произведение, стандартное отклонение и многое другое
NumPy также выполняет агрегационные функции. В дополнение к min, max, и
sum, вы можете легко запустить mean чтобы получить среднее значение, prod чтобы получить результат умножения элементов, std чтобы получить стандартное отклонение и многое другое.
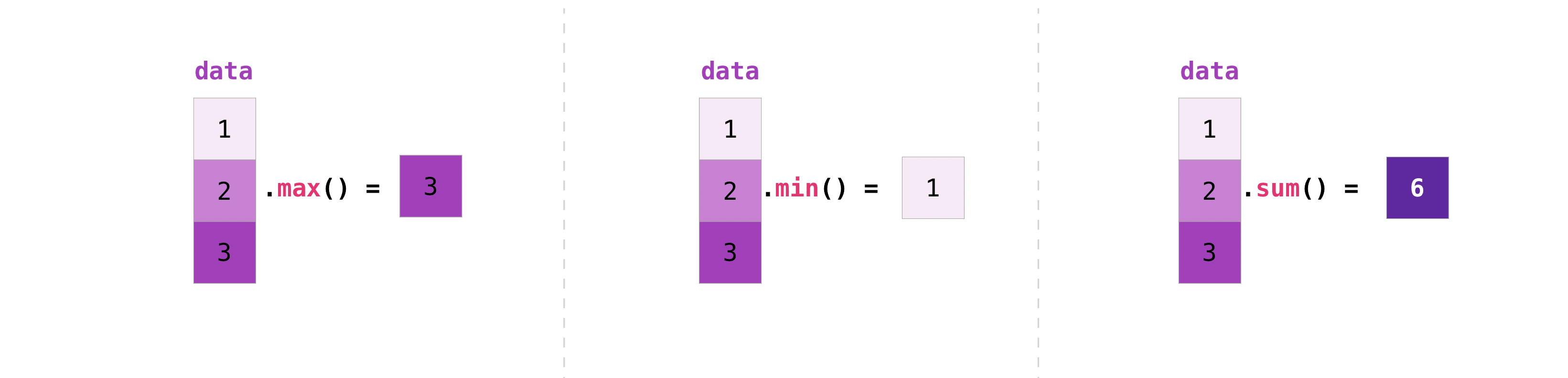
>>> data = np.array([1, 2, 3])
>>> data.max()
3
>>> data.min()
1
>>> data.sum()
6
PyArray_ContiguousFromAny (C-функция)
>>> a = np.array([[0.45053314, 0.17296777, 0.34376245, 0.5510652],
... [0.54627315, 0.05093587, 0.40067661, 0.55645993],
... [0.12697628, 0.82485143, 0.26590556, 0.56917101]])
Очень часто требуется агрегировать вдоль строки или столбца. По умолчанию каждая агрегационная функция NumPy вернет агрегат всего массива. Чтобы найти сумму или минимум элементов в массиве, выполните:
>>> a.sum()
4.8595784
Или:
>>> a.min()
0.05093587
Вы можете указать, по какой оси должна вычисляться агрегирующая функция.
Например, можно найти минимальное значение в каждом столбце, указав
axis=0.
>>> a.min(axis=0)
array([0.12697628, 0.05093587, 0.26590556, 0.5510652 ])
Четыре значения, перечисленные выше, соответствуют количеству столбцов в вашем массиве. С массивом из четырёх столбцов вы получите четыре значения в результате.
Подробнее о методы массива здесь.
Создание матриц#
Вы можете передавать списки списков Python для создания 2-D массива (или "матрицы"), чтобы представлять их в NumPy.
>>> data = np.array([[1, 2], [3, 4], [5, 6]])
>>> data
array([[1, 2],
[3, 4],
[5, 6]])

Операции индексирования и среза полезны при работе с матрицами:
>>> data[0, 1]
2
>>> data[1:3]
array([[3, 4],
[5, 6]])
>>> data[0:2, 0]
array([1, 3])

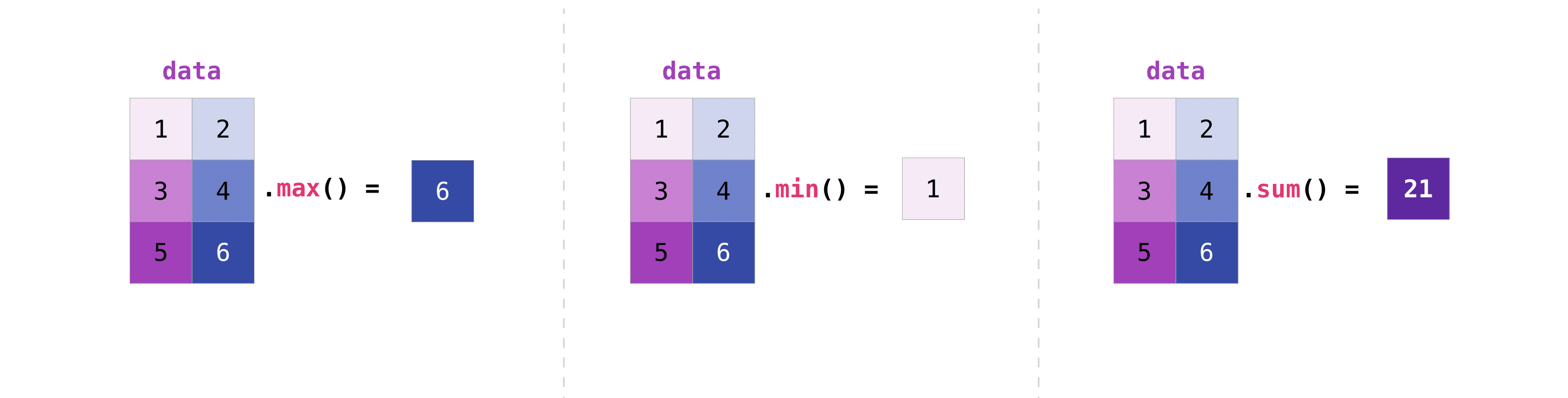
Вы можете агрегировать матрицы так же, как агрегировали векторы:
>>> data.max()
6
>>> data.min()
1
>>> data.sum()
21
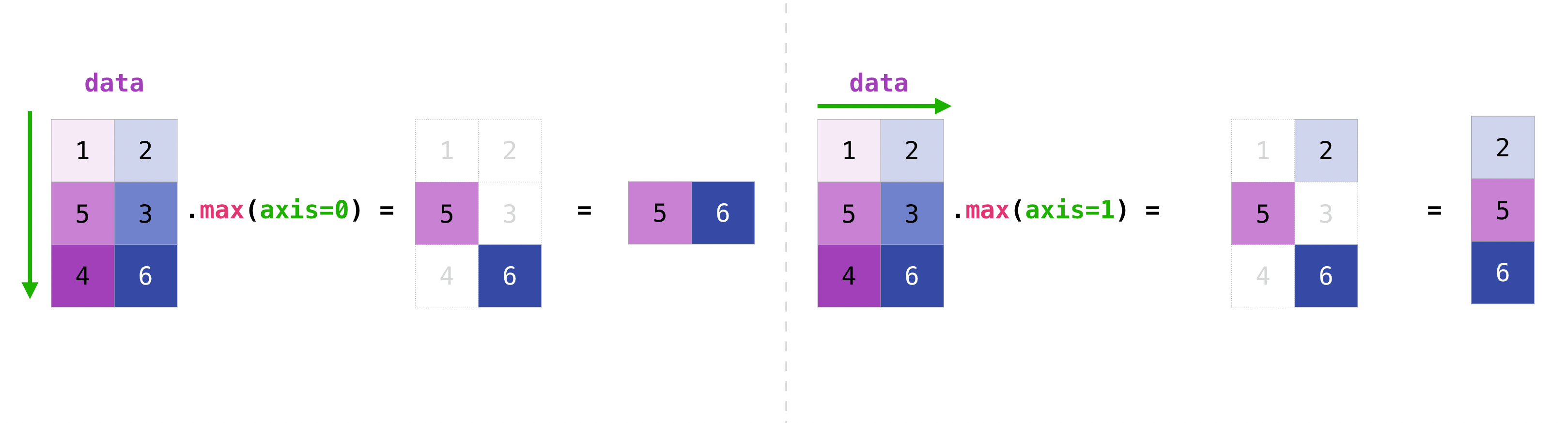
Вы можете агрегировать все значения в матрице и можете агрегировать их по столбцам или строкам, используя axis параметр. Чтобы проиллюстрировать этот момент, давайте
посмотрим на слегка измененный набор данных:
>>> data = np.array([[1, 2], [5, 3], [4, 6]])
>>> data
array([[1, 2],
[5, 3],
[4, 6]])
>>> data.max(axis=0)
array([5, 6])
>>> data.max(axis=1)
array([2, 5, 6])
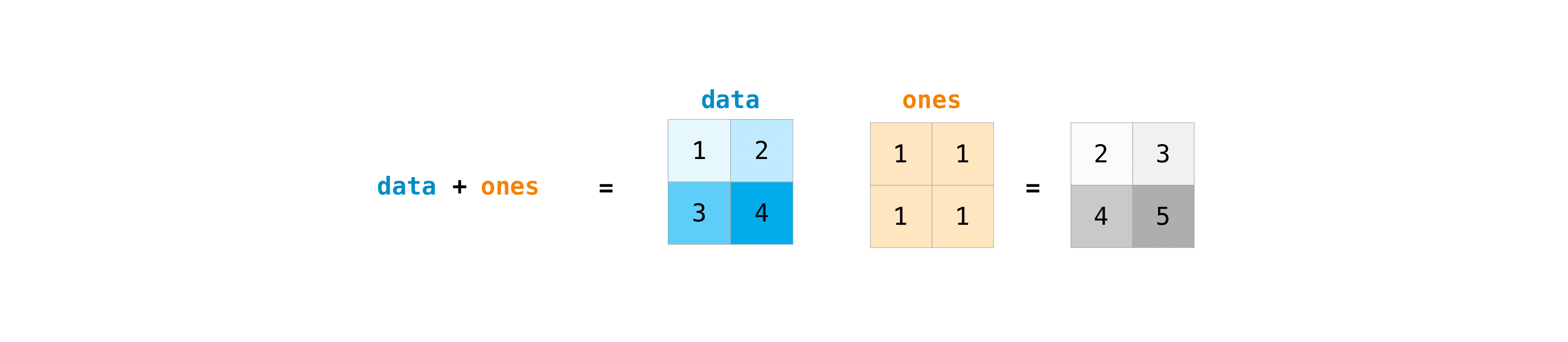
После создания матриц вы можете складывать и умножать их с помощью арифметических операторов, если у вас есть две матрицы одинакового размера.
>>> data = np.array([[1, 2], [3, 4]])
>>> ones = np.array([[1, 1], [1, 1]])
>>> data + ones
array([[2, 3],
[4, 5]])
Вы можете выполнять эти арифметические операции над матрицами разных размеров, но только если одна матрица имеет только один столбец или одну строку. В этом случае NumPy будет использовать свои правила трансляции для операции.
>>> data = np.array([[1, 2], [3, 4], [5, 6]])
>>> ones_row = np.array([[1, 1]])
>>> data + ones_row
array([[2, 3],
[4, 5],
[6, 7]])
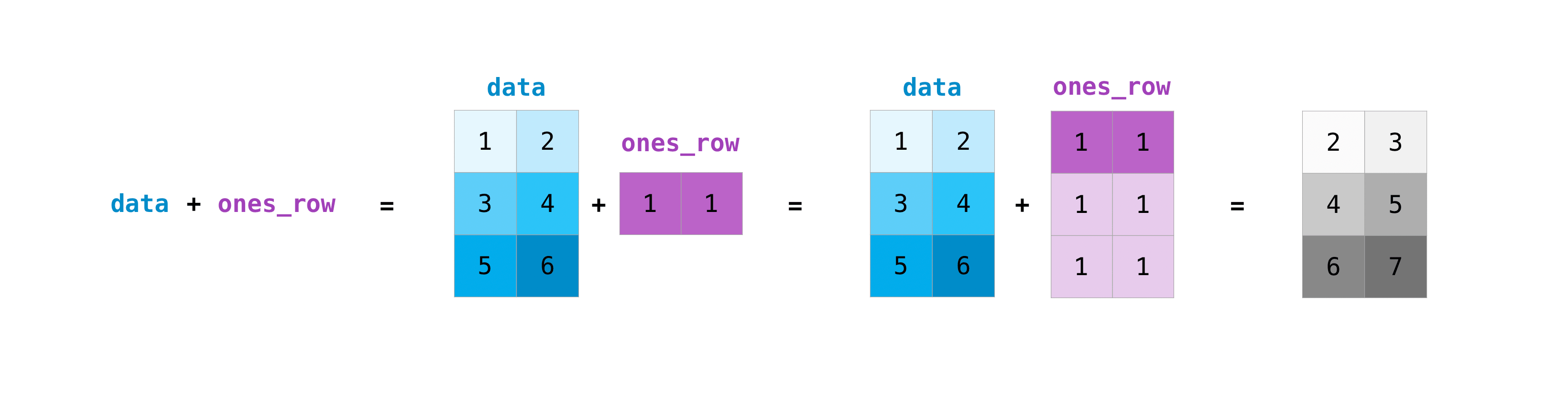
Имейте в виду, что когда NumPy выводит N-мерные массивы, последняя ось перебирается быстрее всего, а первая ось — медленнее всего. Например:
>>> np.ones((4, 3, 2))
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
Часто возникают случаи, когда мы хотим, чтобы NumPy инициализировал значения массива. NumPy предлагает функции, такие как ones() и zeros()должны быть включены в старые категории. Значения, которые были в
удаленных категориях, будут установлены в NaN
random.Generator класс для генерации случайных чисел для этого.
Все, что вам нужно сделать, — это передать количество элементов, которые вы хотите сгенерировать:
>>> np.ones(3)
array([1., 1., 1.])
>>> np.zeros(3)
array([0., 0., 0.])
>>> rng = np.random.default_rng() # the simplest way to generate random numbers
>>> rng.random(3)
array([0.63696169, 0.26978671, 0.04097352])
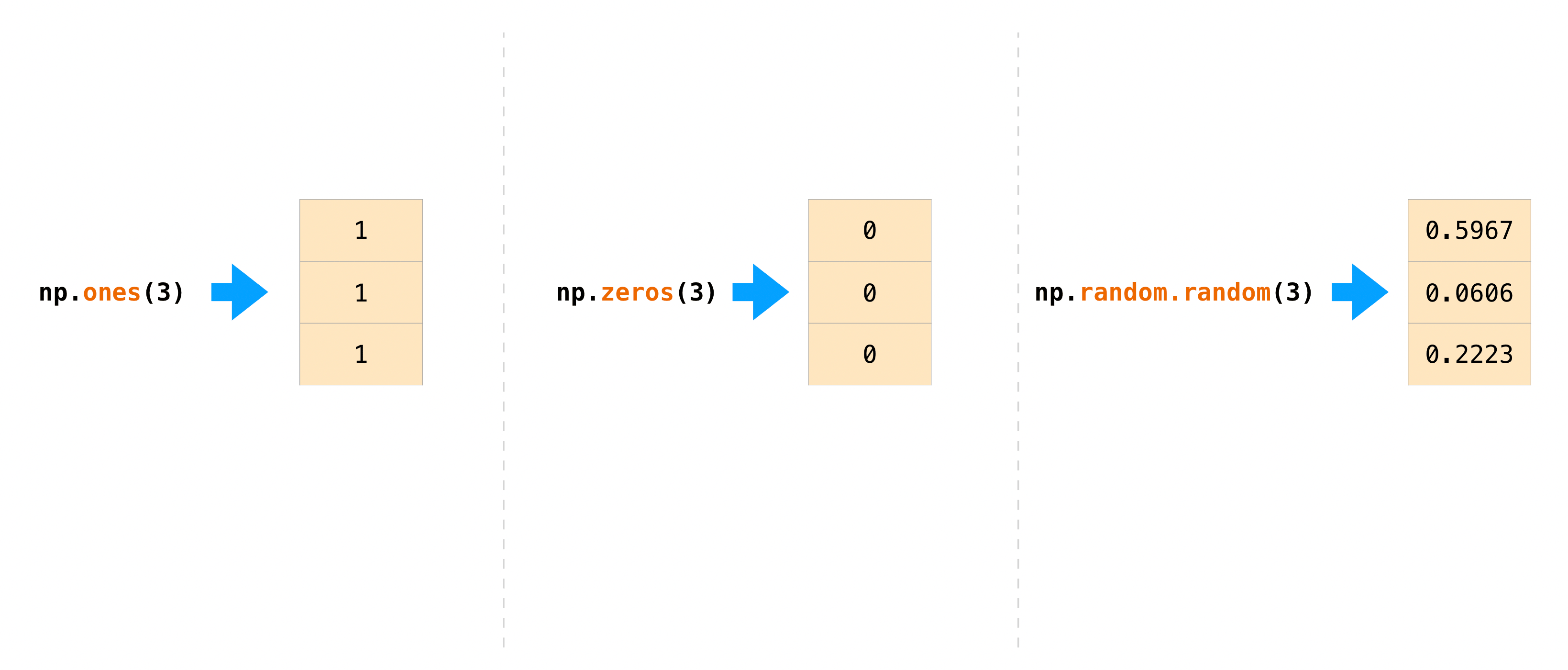
Вы также можете использовать ones(), zeros(), и random() создать
2D массив, если вы дадите ему кортеж, описывающий размеры матрицы:
>>> np.ones((3, 2))
array([[1., 1.],
[1., 1.],
[1., 1.]])
>>> np.zeros((3, 2))
array([[0., 0.],
[0., 0.],
[0., 0.]])
>>> rng.random((3, 2))
array([[0.01652764, 0.81327024],
[0.91275558, 0.60663578],
[0.72949656, 0.54362499]]) # may vary
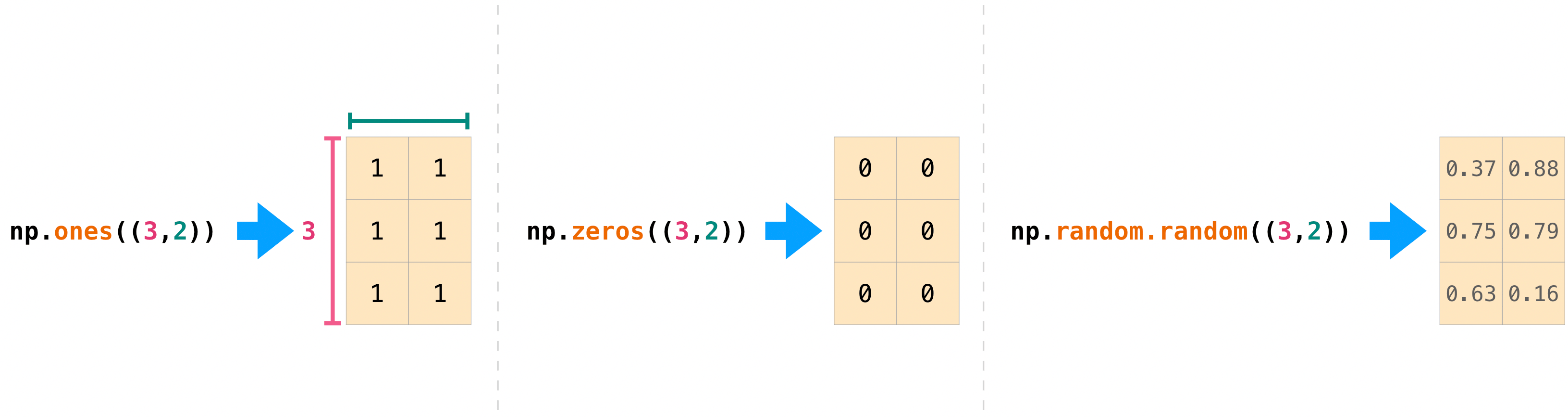
Подробнее о создании массивов, заполненных 0's, 1’s, другие значения или
неинициализированные, в функции создания массивов.
Генерация случайных чисел#
Использование генерации случайных чисел является важной частью конфигурации и оценки многих численных алгоритмов и алгоритмов машинного обучения. Независимо от того, нужно ли вам случайным образом инициализировать веса в искусственной нейронной сети, разделить данные на случайные наборы или случайным образом перемешать ваш набор данных, возможность генерировать случайные числа (на самом деле, повторяемые псевдослучайные числа) является необходимой.
С Generator.integers, вы можете генерировать случайные целые числа от low (помните,
что в NumPy это включительно) до high (исключительно). Вы можете установить
endpoint=True чтобы сделать верхнее число включительным.
Вы можете сгенерировать массив 2 x 4 случайных целых чисел от 0 до 4 с помощью:
>>> rng.integers(5, size=(2, 4))
array([[2, 1, 1, 0],
[0, 0, 0, 4]]) # may vary
Как получить уникальные элементы и подсчеты#
Этот раздел охватывает np.unique()
Вы можете легко найти уникальные элементы в массиве с помощью np.unique.
Например, если вы начинаете с этого массива:
>>> a = np.array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
вы можете использовать np.unique чтобы вывести уникальные значения в вашем массиве:
>>> unique_values = np.unique(a)
>>> print(unique_values)
[11 12 13 14 15 16 17 18 19 20]
Чтобы получить индексы уникальных значений в массиве NumPy (массив первых позиций индексов
уникальных значений в массиве), просто передайте return_index
аргумент в np.unique() а также ваш массив.
>>> unique_values, indices_list = np.unique(a, return_index=True)
>>> print(indices_list)
[ 0 2 3 4 5 6 7 12 13 14]
Вы можете передать return_counts аргумент в np.unique() вместе с вашим массивом, чтобы получить частотный подсчет уникальных значений в массиве NumPy.
>>> unique_values, occurrence_count = np.unique(a, return_counts=True)
>>> print(occurrence_count)
[3 2 2 2 1 1 1 1 1 1]
Это также работает с 2D массивами! Если вы начнёте с этого массива:
>>> a_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [1, 2, 3, 4]])
Вы можете найти уникальные значения с помощью:
>>> unique_values = np.unique(a_2d)
>>> print(unique_values)
[ 1 2 3 4 5 6 7 8 9 10 11 12]
Если аргумент axis не передан, ваш 2D массив будет сведен в одномерный.
Если вы хотите получить уникальные строки или столбцы, убедитесь, что передали axis
аргумент. Чтобы найти уникальные строки, укажите axis=0 а для столбцов укажите
axis=1.
>>> unique_rows = np.unique(a_2d, axis=0)
>>> print(unique_rows)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
Чтобы получить уникальные строки, позицию индекса и количество вхождений, можно использовать:
>>> unique_rows, indices, occurrence_count = np.unique(
... a_2d, axis=0, return_counts=True, return_index=True)
>>> print(unique_rows)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(indices)
[0 1 2]
>>> print(occurrence_count)
[2 1 1]
Чтобы узнать больше о поиске уникальных элементов в массиве, см. unique.
Транспонирование и изменение формы матрицы#
Этот раздел охватывает arr.reshape(), arr.transpose(), arr.T
Часто требуется транспонировать матрицы. Массивы NumPy обладают свойством
T который позволяет транспонировать матрицу.
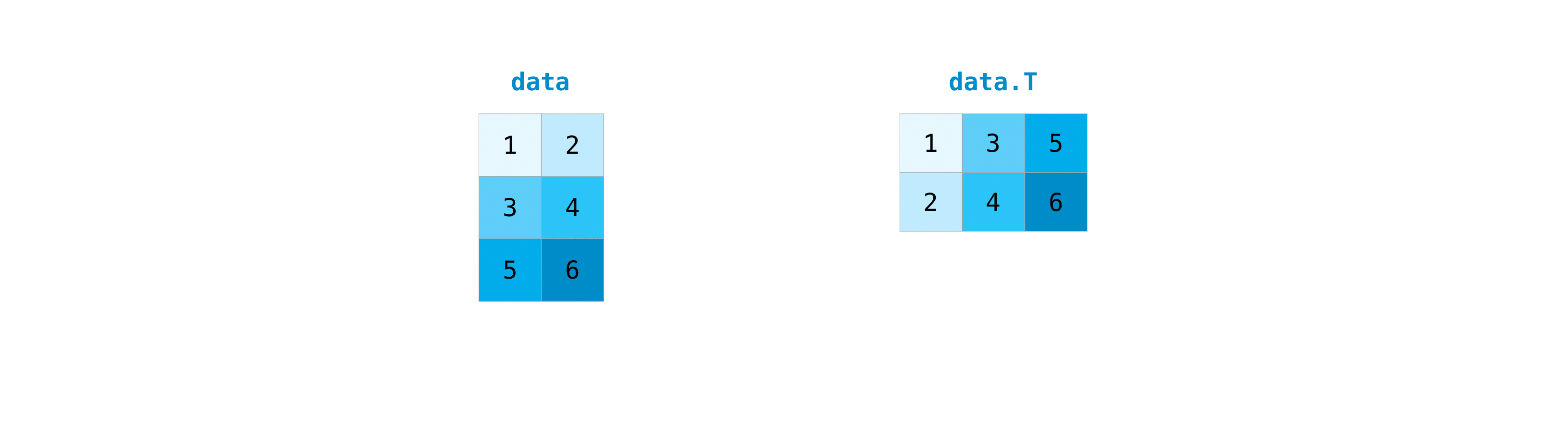
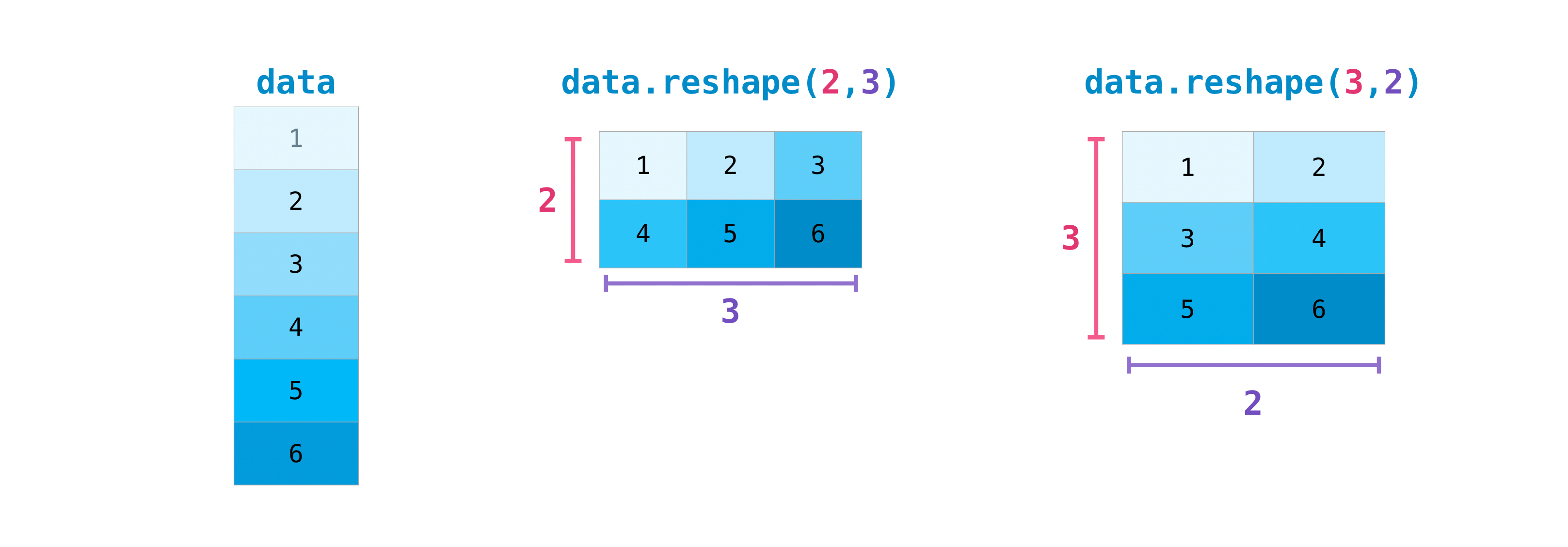
Вам также может потребоваться изменить размеры матрицы. Это может произойти, например, когда у вас есть модель, которая ожидает определенную форму ввода, отличную от вашего набора данных. Здесь reshape метод может быть полезен. Вам просто нужно передать новые размеры, которые вы хотите для матрицы.
>>> data.reshape(2, 3)
array([[1, 2, 3],
[4, 5, 6]])
>>> data.reshape(3, 2)
array([[1, 2],
[3, 4],
[5, 6]])
Вы также можете использовать .transpose() чтобы изменить или поменять оси массива
в соответствии с указанными значениями.
Если вы начнете с этого массива:
>>> arr = np.arange(6).reshape((2, 3))
>>> arr
array([[0, 1, 2],
[3, 4, 5]])
Вы можете транспонировать свой массив с помощью arr.transpose().
>>> arr.transpose()
array([[0, 3],
[1, 4],
[2, 5]])
Вы также можете использовать arr.T:
>>> arr.T
array([[0, 3],
[1, 4],
[2, 5]])
Чтобы узнать больше о транспонировании и изменении формы массивов, см. transpose и
reshape.
Как перевернуть массив#
Этот раздел охватывает np.flip()
NumPy np.flip() Функция позволяет перевернуть или обратить содержимое
массива вдоль оси. При использовании np.flip(), укажите массив, который вы хотите
перевернуть, и ось. Если вы не укажете ось, NumPy перевернёт
содержимое по всем осям входного массива.
Обращение одномерного массива
Если вы начинаете с одномерного массива, такого как этот:
>>> arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
Вы можете обратить его с помощью:
>>> reversed_arr = np.flip(arr)
Если вы хотите вывести перевёрнутый массив, вы можете выполнить:
>>> print('Reversed Array: ', reversed_arr)
Reversed Array: [8 7 6 5 4 3 2 1]
Обращение двумерного массива
Двумерный массив работает примерно так же.
Если вы начнете с этого массива:
>>> arr_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Вы можете обратить содержимое во всех строках и всех столбцах с помощью:
>>> reversed_arr = np.flip(arr_2d)
>>> print(reversed_arr)
[[12 11 10 9]
[ 8 7 6 5]
[ 4 3 2 1]]
Вы можете легко обратить только строки с:
>>> reversed_arr_rows = np.flip(arr_2d, axis=0)
>>> print(reversed_arr_rows)
[[ 9 10 11 12]
[ 5 6 7 8]
[ 1 2 3 4]]
Или обратить только столбцы с:
>>> reversed_arr_columns = np.flip(arr_2d, axis=1)
>>> print(reversed_arr_columns)
[[ 4 3 2 1]
[ 8 7 6 5]
[12 11 10 9]]
Вы также можете обратить содержимое только одного столбца или строки. Например, вы можете обратить содержимое строки с индексом 1 (второй строки):
>>> arr_2d[1] = np.flip(arr_2d[1])
>>> print(arr_2d)
[[ 1 2 3 4]
[ 8 7 6 5]
[ 9 10 11 12]]
Вы также можете обратить столбец по индексу позиции 1 (второй столбец):
>>> arr_2d[:,1] = np.flip(arr_2d[:,1])
>>> print(arr_2d)
[[ 1 10 3 4]
[ 8 7 6 5]
[ 9 2 11 12]]
Подробнее о реверсировании массивов читайте в flip.
Изменение формы и сглаживание многомерных массивов#
Этот раздел охватывает .flatten(), ravel()
Существует два популярных способа сглаживания массива: .flatten() и .ravel(). Основное различие между ними заключается в том, что новый массив, созданный с использованием
ravel() фактически является ссылкой на родительский массив (т.е., «представлением»). Это означает, что любые изменения в новом массиве повлияют и на родительский массив. Поскольку ravel не создает копию, это эффективно по памяти.
Если вы начнете с этого массива:
>>> x = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Вы можете использовать flatten для преобразования массива в одномерный массив.
>>> x.flatten()
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
Когда вы используете flatten, изменения в вашем новом массиве не изменят родительский
массив.
Например:
>>> a1 = x.flatten()
>>> a1[0] = 99
>>> print(x) # Original array
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(a1) # New array
[99 2 3 4 5 6 7 8 9 10 11 12]
Но когда вы используете ravel, изменения, внесенные в новый массив, повлияют на родительский массив.
Например:
>>> a2 = x.ravel()
>>> a2[0] = 98
>>> print(x) # Original array
[[98 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(a2) # New array
[98 2 3 4 5 6 7 8 9 10 11 12]
Подробнее о flatten в ndarray.flatten и ravel в ravel.
Как получить доступ к строке документации для получения дополнительной информации#
Этот раздел охватывает help(), ?, ??
Когда речь идёт об экосистеме data science, Python и NumPy созданы с учётом
пользователя. Один из лучших примеров этого — встроенный доступ к
документации. Каждый объект содержит ссылку на строку, которая известна
как docstring. В большинстве случаев эта строка документации содержит краткое и сжатое описание объекта и способов его использования. Python имеет встроенную help()
функция, которая может помочь вам получить эту информацию. Это означает, что почти в любое
время, когда вам нужно больше информации, вы можете использовать help() быстро найти информацию, которая вам нужна.
Например:
>>> help(max)
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
Поскольку доступ к дополнительной информации так полезен, IPython использует ?
символ как сокращение для доступа к этой документации вместе с другой соответствующей информацией. IPython — это командная оболочка для интерактивных вычислений на нескольких языках.
Вы можете найти больше информации об IPython здесь.
Например:
In [0]: max?
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
Type: builtin_function_or_method
Вы даже можете использовать эту нотацию для методов объектов и самих объектов.
Допустим, вы создаете этот массив:
>>> a = np.array([1, 2, 3, 4, 5, 6])
Затем вы можете получить много полезной информации (сначала подробности о a сам, за которым следует строка документации ndarray из которых a является экземпляром):
In [1]: a?
Type: ndarray
String form: [1 2 3 4 5 6]
Length: 6
File: ~/anaconda3/lib/python3.9/site-packages/numpy/__init__.py
Docstring: Это также работает для функций и других объектов, которые вы создать. Просто
помните, что нужно включить строку документации в вашу функцию, используя строковый литерал
(""" """ или ''' ''' вокруг вашей документации).
Например, если вы создадите эту функцию:
>>> def double(a):
... '''Return a * 2'''
... return a * 2
Вы можете получить информацию о функции:
In [2]: double?
Signature: double(a)
Docstring: Return a * 2
File: ~/Desktop/Вы можете достичь другого уровня информации, читая исходный код объекта, который вас интересует. Используя двойной вопросительный знак (??) позволяет вам получить доступ к исходному коду.
Например:
In [3]: double??
Signature: double(a)
Source:
def double(a):
'''Return a * 2'''
return a * 2
File: ~/Desktop/Если рассматриваемый объект скомпилирован на языке, отличном от Python, используя
?? вернёт ту же информацию, что и ?. Вы найдете это во многих
встроенных объектах и типах, например:
In [4]: len?
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
и :
In [5]: len??
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
имеют одинаковый вывод, потому что они были скомпилированы на языке программирования, отличном от Python.
Работа с математическими формулами#
Лёгкость реализации математических формул, работающих с массивами, — одна из причин, почему NumPy так широко используется в научном сообществе Python.
Например, это формула среднеквадратичной ошибки (центральная формула, используемая в моделях машинного обучения с учителем, работающих с регрессией):
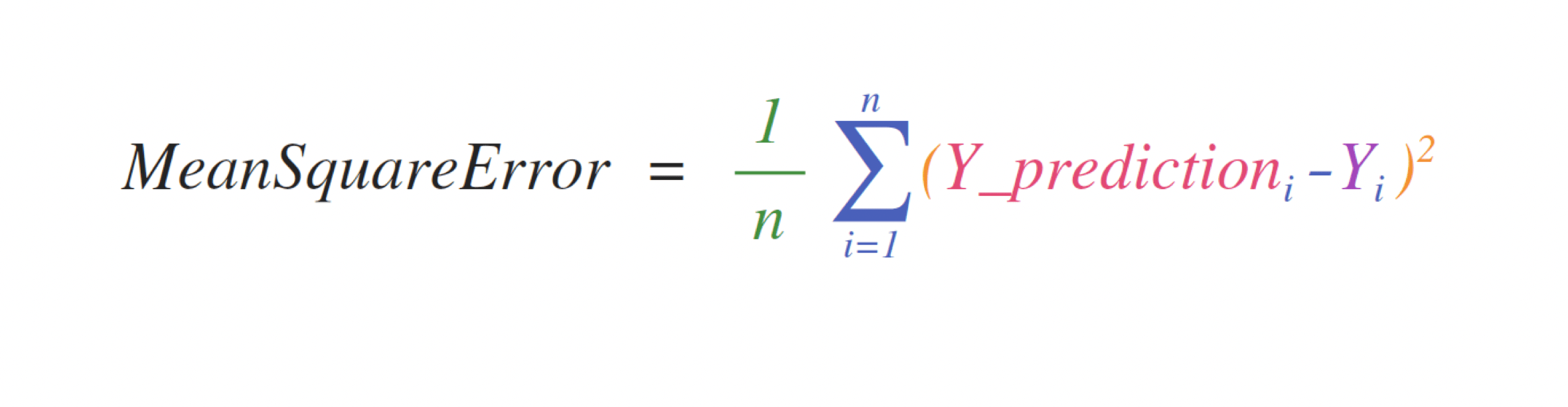
Реализация этой формулы проста и прямолинейна в NumPy:
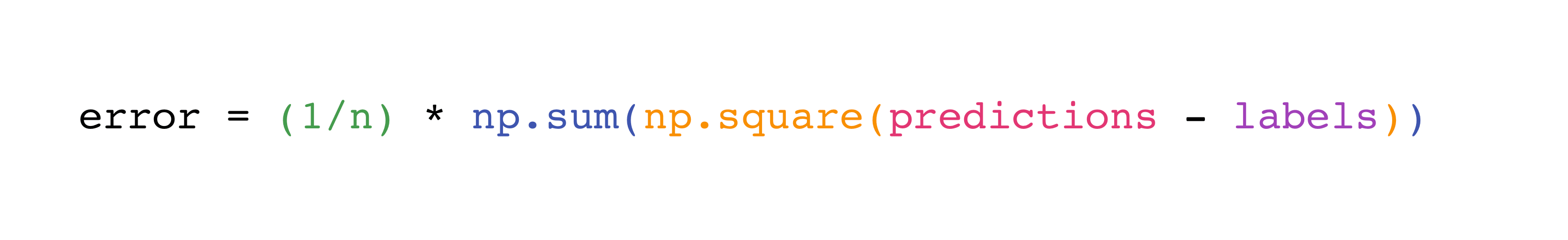
Что делает это таким эффективным, так это то, что predictions и labels может содержать
одно или тысячу значений. Они должны быть только одинакового размера.
Вы можете визуализировать это так:

В этом примере и векторы предсказаний, и векторы меток содержат три значения,
что означает n имеет значение три. После выполнения вычитаний значения в векторе возводятся в квадрат. Затем NumPy суммирует значения, и ваш результат — это значение ошибки для этого прогноза и оценка качества модели.

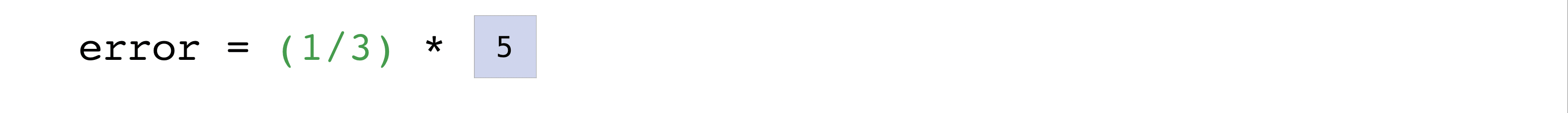
Как сохранять и загружать объекты NumPy#
Этот раздел охватывает np.save, np.savez, np.savetxt,
np.load, np.loadtxt
В какой-то момент вы захотите сохранить свои массивы на диск и загрузить их обратно без необходимости повторного запуска кода. К счастью, есть несколько способов сохранения и загрузки объектов с NumPy. Объекты ndarray могут быть сохранены на дисковые файлы и загружены из них с помощью loadtxt и savetxt функции, которые обрабатывают обычные текстовые файлы, load и save функции, которые обрабатывают бинарные файлы NumPy с .npy расширение файла, и savez функция, которая обрабатывает файлы NumPy с .npz расширение файла.
The .npy и .npz файлы хранят данные, форму, тип данных и другую информацию, необходимую для восстановления ndarray таким образом, чтобы массив можно было корректно извлечь, даже если файл находится на другой машине с другой архитектурой.
Если вы хотите сохранить один объект ndarray, сохраните его как файл .npy с помощью
np.save. Если вы хотите сохранить более одного объекта ndarray в одном файле, сохраните его как файл .npz, используя np.savez. Вы также можете сохранить несколько массивов в один файл в сжатом формате npz с помощью savez_compressed.
Легко сохранить и загрузить массив с помощью np.save(). Просто убедитесь, что указали массив, который хотите сохранить, и имя файла. Например, если вы создадите этот массив:
>>> a = np.array([1, 2, 3, 4, 5, 6])
Вы можете сохранить его как “filename.npy” с помощью:
>>> np.save('filename', a)
Вы можете использовать np.load() для восстановления вашего массива.
>>> b = np.load('filename.npy')
Если вы хотите проверить свой массив, вы можете запустить:
>>> print(b)
[1 2 3 4 5 6]
Вы можете сохранить массив NumPy как простой текстовый файл, например .csv или .txt файл с np.savetxt.
Например, если вы создадите этот массив:
>>> csv_arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
Вы можете легко сохранить его как файл .csv с именем "new_file.csv" следующим образом:
>>> np.savetxt('new_file.csv', csv_arr)
Вы можете быстро и легко загрузить сохраненный текстовый файл с помощью loadtxt():
>>> np.loadtxt('new_file.csv')
array([1., 2., 3., 4., 5., 6., 7., 8.])
The savetxt() и loadtxt() функции принимают дополнительные необязательные параметры, такие как header, footer и delimiter. Хотя текстовые файлы могут быть удобнее для обмена, файлы .npy и .npz меньше и быстрее читаются. Если вам нужна более сложная обработка вашего текстового файла (например, если вам нужно работать со строками, содержащими пропущенные значения), вам следует использовать genfromtxt
функция.
С savetxt, вы можете указать заголовки, нижние колонтитулы, комментарии и другое.
Узнать больше о входные и выходные процедуры здесь.
Импорт и экспорт CSV#
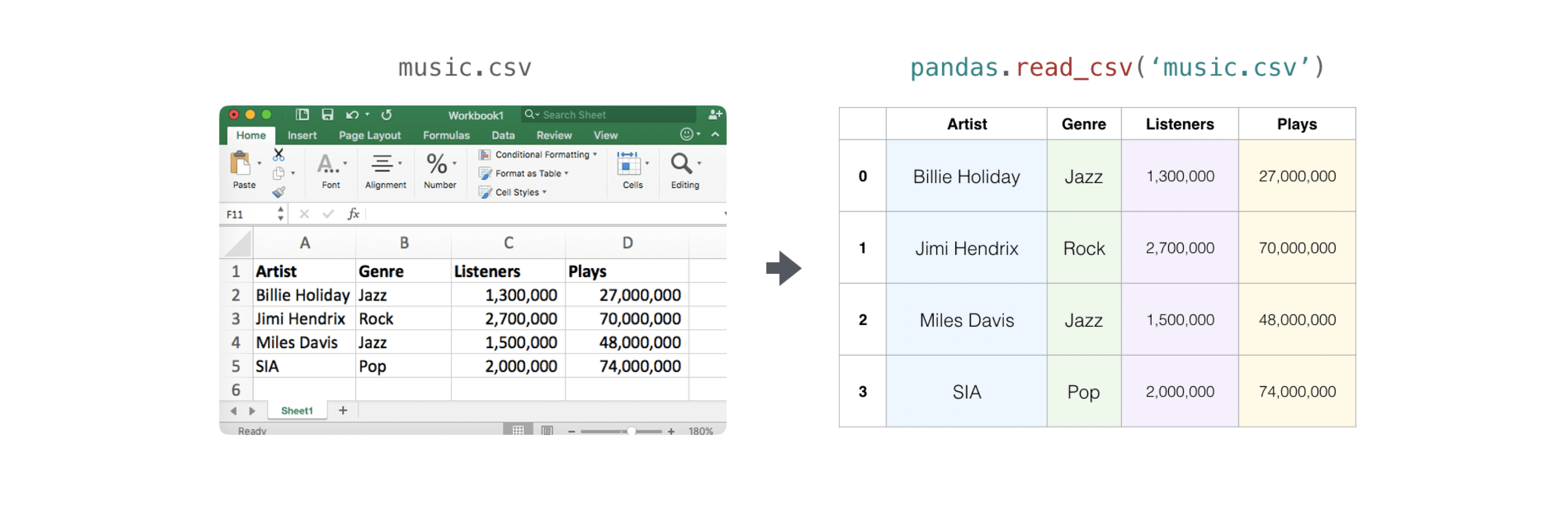
Просто считать CSV, содержащий существующую информацию. Лучший и самый простой способ сделать это — использовать Pandas.
>>> import pandas as pd
>>> # If all of your columns are the same type:
>>> x = pd.read_csv('music.csv', header=0).values
>>> print(x)
[['Billie Holiday' 'Jazz' 1300000 27000000]
['Jimmie Hendrix' 'Rock' 2700000 70000000]
['Miles Davis' 'Jazz' 1500000 48000000]
['SIA' 'Pop' 2000000 74000000]]
>>> # You can also simply select the columns you need:
>>> x = pd.read_csv('music.csv', usecols=['Artist', 'Plays']).values
>>> print(x)
[['Billie Holiday' 27000000]
['Jimmie Hendrix' 70000000]
['Miles Davis' 48000000]
['SIA' 74000000]]
Просто использовать Pandas для экспорта вашего массива. Если вы новичок в NumPy, вы можете создать фрейм данных Pandas из значений в вашем массиве, а затем записать фрейм данных в CSV-файл с помощью Pandas.
Если вы создали этот массив "a"
>>> a = np.array([[-2.58289208, 0.43014843, -1.24082018, 1.59572603],
... [ 0.99027828, 1.17150989, 0.94125714, -0.14692469],
... [ 0.76989341, 0.81299683, -0.95068423, 0.11769564],
... [ 0.20484034, 0.34784527, 1.96979195, 0.51992837]])
Вы можете создать датафрейм Pandas
>>> df = pd.DataFrame(a)
>>> print(df)
0 1 2 3
0 -2.582892 0.430148 -1.240820 1.595726
1 0.990278 1.171510 0.941257 -0.146925
2 0.769893 0.812997 -0.950684 0.117696
3 0.204840 0.347845 1.969792 0.519928
Вы можете легко сохранить ваш dataframe с помощью:
>>> df.to_csv('pd.csv')
И прочитайте ваш CSV с:
>>> data = pd.read_csv('pd.csv')

Вы также можете сохранить свой массив с помощью NumPy savetxt метод.
>>> np.savetxt('np.csv', a, fmt='%.2f', delimiter=',', header='1, 2, 3, 4')
Если вы используете командную строку, вы можете прочитать сохраненный CSV в любое время с помощью команды, такой как:
$ cat np.csv
# 1, 2, 3, 4
-2.58,0.43,-1.24,1.60
0.99,1.17,0.94,-0.15
0.77,0.81,-0.95,0.12
0.20,0.35,1.97,0.52
Или вы можете открыть файл в любое время с помощью текстового редактора!
Если вы хотите узнать больше о Pandas, ознакомьтесь с официальная документация Pandas. Узнайте, как установить Pandas с помощью официальная информация об установке Pandas.
Построение графиков массивов с помощью Matplotlib#
Если вам нужно сгенерировать график для ваших значений, это очень просто с Matplotlib.
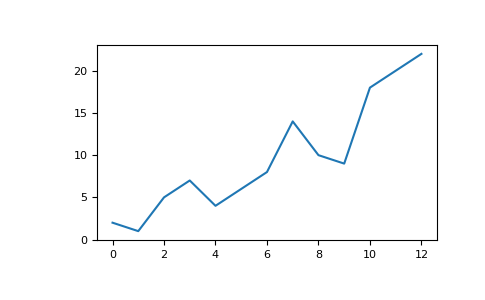
Например, у вас может быть массив, подобный этому:
>>> a = np.array([2, 1, 5, 7, 4, 6, 8, 14, 10, 9, 18, 20, 22])
Если у вас уже установлен Matplotlib, вы можете импортировать его с помощью:
>>> import matplotlib.pyplot as plt
# If you're using Jupyter Notebook, you may also want to run the following
# line of code to display your code in the notebook:
%matplotlib inline
Все, что вам нужно сделать для построения графика ваших значений, это запустить:
>>> plt.plot(a)
# If you are running from a command line, you may need to do this:
# >>> plt.show()
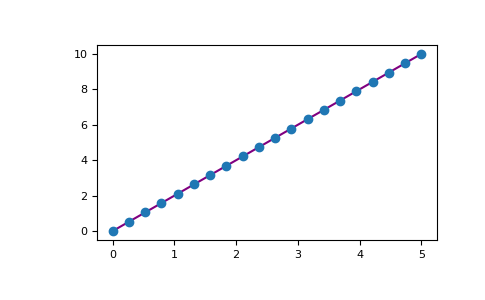
Например, вы можете построить график одномерного массива так:
>>> x = np.linspace(0, 5, 20)
>>> y = np.linspace(0, 10, 20)
>>> plt.plot(x, y, 'purple') # line
>>> plt.plot(x, y, 'o') # dots
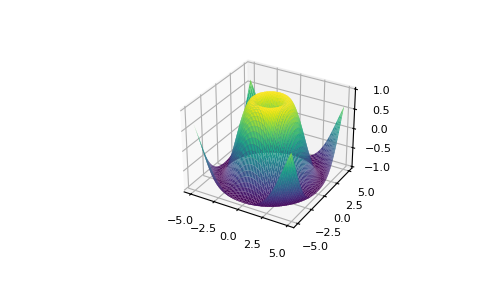
С Matplotlib у вас есть доступ к огромному количеству вариантов визуализации.
>>> fig = plt.figure()
>>> ax = fig.add_subplot(projection='3d')
>>> X = np.arange(-5, 5, 0.15)
>>> Y = np.arange(-5, 5, 0.15)
>>> X, Y = np.meshgrid(X, Y)
>>> R = np.sqrt(X**2 + Y**2)
>>> Z = np.sin(R)
>>> ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='viridis')
Чтобы узнать больше о Matplotlib и его возможностях, посмотрите официальная документация. По поводу инструкций по установке Matplotlib см. официальный раздел установки.
Автор изображения: Jay Alammar https://jalammar.github.io/