pandas.plotting.radviz#
- pandas.plotting.radviz(фрейм, class_column, ax=None, цвет=None, цветовая карта=None, **kwds)[источник]#
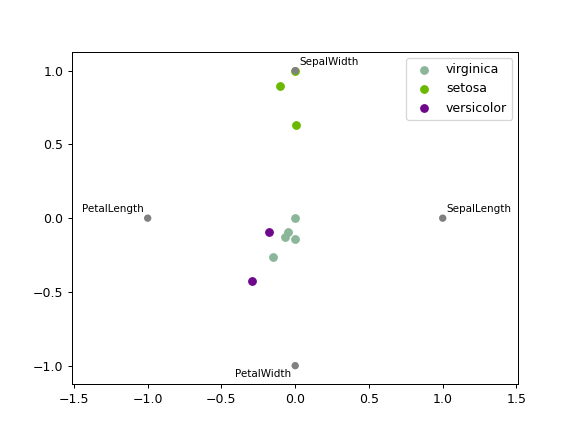
Построение многомерного набора данных в 2D.
Каждый Series в DataFrame представлен как равномерно распределенный сегмент на окружности. Каждая точка данных отображается в окружности в соответствии с значением в каждом Series. Высококоррелированные Series в DataFrame расположены ближе на единичной окружности.
RadViz позволяет проецировать N-мерный набор данных в 2D-пространство, где влияние каждого измерения можно интерпретировать как баланс между влиянием всех измерений.
Дополнительная информация доступна на оригинальная статья описание RadViz.
- Параметры:
- фреймDataFrame
Объект, содержащий данные.
- class_columnstr
Имя столбца, содержащее название категории точки данных.
- ax
matplotlib.axes.Axes, опционально Экземпляр графика, к которому добавляется информация.
- цветlist[str] или tuple[str], опционально
Назначьте цвет каждой категории. Пример: [‘синий’, ‘зеленый’].
- цветовая картаstr или
matplotlib.colors.Colormap, по умолчанию None Цветовая карта для выбора цветов. Если строка, загрузить цветовую карту с этим именем из matplotlib.
- **kwds
Параметры для передачи методу построения диаграммы рассеяния matplotlib.
- Возвращает:
Смотрите также
pandas.plotting.andrews_curvesВизуализация кластеризации.
Примеры
>>> df = pd.DataFrame( ... { ... 'SepalLength': [6.5, 7.7, 5.1, 5.8, 7.6, 5.0, 5.4, 4.6, 6.7, 4.6], ... 'SepalWidth': [3.0, 3.8, 3.8, 2.7, 3.0, 2.3, 3.0, 3.2, 3.3, 3.6], ... 'PetalLength': [5.5, 6.7, 1.9, 5.1, 6.6, 3.3, 4.5, 1.4, 5.7, 1.0], ... 'PetalWidth': [1.8, 2.2, 0.4, 1.9, 2.1, 1.0, 1.5, 0.2, 2.1, 0.2], ... 'Category': [ ... 'virginica', ... 'virginica', ... 'setosa', ... 'virginica', ... 'virginica', ... 'versicolor', ... 'versicolor', ... 'setosa', ... 'virginica', ... 'setosa' ... ] ... } ... ) >>> pd.plotting.radviz(df, 'Category')