Версия 0.17.0 (9 октября 2015)#
Это основной релиз с версии 0.16.2, включающий небольшое количество изменений API, несколько новых функций, улучшений и оптимизаций производительности, а также большое количество исправлений ошибок. Рекомендуем всем пользователям обновиться до этой версии.
Предупреждение
pandas >= 0.17.0 больше не будет поддерживать совместимость с версией Python 3.2 (GH 9118)
Предупреждение
The pandas.io.data пакет устарел и будет заменен на
пакет pandas-datareader. Это позволит независимо обновлять модули данных в вашей установке pandas. API для pandas-datareader v0.1.1 точно такой же
как в pandas v0.17.0 (GH 8961, GH 10861).
После установки pandas-datareader вы можете легко изменить импорты:
from pandas.io import data, wb
становится
from pandas_datareader import data, wb
Основные моменты включают:
Освободить глобальную блокировку интерпретатора (GIL) для некоторых операций cython, см. здесь
Методы построения графиков теперь доступны как атрибуты
.plotаксессор, см. здесьAPI сортировки был переработан, чтобы устранить некоторые давние несоответствия, см. здесь
Поддержка
datetime64[ns]с часовыми поясами как dtype первого класса, см. здесьЗначение по умолчанию для
to_datetimeтеперь будетraiseпри представлении неразбираемых форматов, ранее это возвращало исходный ввод. Также функции разбора дат теперь возвращают согласованные результаты. См. здесьЗначение по умолчанию для
dropnaвHDFStoreизменилось наFalse, чтобы по умолчанию сохранять все строки, даже если они всеNaN, см. здесьДоступ к дате и времени (
dt) теперь поддерживаетSeries.dt.strftimeдля генерации форматированных строк для datetime-подобных объектов, иSeries.dt.total_secondsдля генерации каждой длительности timedelta в секундах. Смотрите здесьPeriodиPeriodIndexможет обрабатывать умноженную частоту, такую как3D, что соответствует промежутку в 3 дня. См. здесьУстановленные версии pandas для разработки теперь будут иметь
PEP440совместимые версии строк (GH 9518)Поддержка разработки для бенчмаркинга с Библиотека Air Speed Velocity (GH 8361)
Поддержка чтения файлов SAS xport, см. здесь
Документация, сравнивающая SAS с pandas, см. здесь
Удаление автоматического вещания TimeSeries, устаревшего с версии 0.8.0, см. здесь
Формат отображения с простым текстом может дополнительно выравниваться по ширине символов Восточной Азии, см. здесь
Совместимость с Python 3.5 (GH 11097)
Совместимость с matplotlib 1.5.0 (GH 11111)
Проверьте Изменения API и устаревшие возможности перед обновлением.
Новые возможности#
Дата-время с часовым поясом#
Мы добавляем реализацию, которая изначально поддерживает datetime с часовыми поясами. Series или DataFrame столбец ранее
мог будет присвоена дата-время с часовыми поясами и будет работать как object dtype. Это вызывало проблемы с производительностью при большом
количестве строк. См. документация для получения дополнительных сведений. (GH 8260, GH 10763, GH 11034).
Новая реализация позволяет использовать единый часовой пояс для всех строк, выполняя операции производительным образом.
In [1]: df = pd.DataFrame(
...: {
...: "A": pd.date_range("20130101", periods=3),
...: "B": pd.date_range("20130101", periods=3, tz="US/Eastern"),
...: "C": pd.date_range("20130101", periods=3, tz="CET"),
...: }
...: )
...:
In [2]: df
Out[2]:
A B C
0 2013-01-01 2013-01-01 00:00:00-05:00 2013-01-01 00:00:00+01:00
1 2013-01-02 2013-01-02 00:00:00-05:00 2013-01-02 00:00:00+01:00
2 2013-01-03 2013-01-03 00:00:00-05:00 2013-01-03 00:00:00+01:00
[3 rows x 3 columns]
In [3]: df.dtypes
Out[3]:
A datetime64[ns]
B datetime64[ns, US/Eastern]
C datetime64[ns, CET]
Length: 3, dtype: object
In [4]: df.B
Out[4]:
0 2013-01-01 00:00:00-05:00
1 2013-01-02 00:00:00-05:00
2 2013-01-03 00:00:00-05:00
Name: B, Length: 3, dtype: datetime64[ns, US/Eastern]
In [5]: df.B.dt.tz_localize(None)
Out[5]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
Name: B, Length: 3, dtype: datetime64[ns]
Это использует новое представление типа данных, которое очень похоже по внешнему виду и ощущениям на его аналог в numpy datetime64[ns]
In [6]: df["B"].dtype
Out[6]: datetime64[ns, US/Eastern]
In [7]: type(df["B"].dtype)
Out[7]: pandas.core.dtypes.dtypes.DatetimeTZDtype
Примечание
Существует немного другое строковое представление для базового DatetimeIndex в результате изменения типа данных, но функционально они одинаковы.
Предыдущее поведение:
In [1]: pd.date_range('20130101', periods=3, tz='US/Eastern')
Out[1]: DatetimeIndex(['2013-01-01 00:00:00-05:00', '2013-01-02 00:00:00-05:00',
'2013-01-03 00:00:00-05:00'],
dtype='datetime64[ns]', freq='D', tz='US/Eastern')
In [2]: pd.date_range('20130101', periods=3, tz='US/Eastern').dtype
Out[2]: dtype('
Новое поведение:
In [8]: pd.date_range("20130101", periods=3, tz="US/Eastern")
Out[8]:
DatetimeIndex(['2013-01-01 00:00:00-05:00', '2013-01-02 00:00:00-05:00',
'2013-01-03 00:00:00-05:00'],
dtype='datetime64[ns, US/Eastern]', freq='D')
In [9]: pd.date_range("20130101", periods=3, tz="US/Eastern").dtype
Out[9]: datetime64[ns, US/Eastern]
Освобождение GIL#
Мы освобождаем глобальную блокировку интерпретатора (GIL) в некоторых операциях на Cython.
Это позволит другим потокам выполняться одновременно во время вычислений, потенциально улучшая производительность
за счёт многопоточности. В частности groupby, nsmallest, value_counts и некоторые операции индексации выигрывают от этого. (GH 8882)
Например, группировка в следующем коде освободит GIL на этапе факторизации, например. df.groupby('key')
а также .sum() операция.
N = 1000000
ngroups = 10
df = DataFrame(
{"key": np.random.randint(0, ngroups, size=N), "data": np.random.randn(N)}
)
df.groupby("key")["data"].sum()
Освобождение GIL может быть полезно для приложений, использующих потоки для взаимодействия с пользователем (например, QT), или выполнение многопоточных вычислений. Хорошим примером библиотеки, которая может обрабатывать такие типы параллельных вычислений, является dask библиотека.
Подметоды построения графиков#
Series и DataFrame .plot() метод позволяет настраивать типы графиков путем указания kind Ключевые аргументы. К сожалению, многие из таких графиков используют разные обязательные и необязательные ключевые аргументы, что затрудняет определение, какие из десятков возможных аргументов использует конкретный тип графика.
Чтобы смягчить эту проблему, мы добавили новый, опциональный интерфейс построения графиков, который предоставляет каждый тип графика как метод .plot атрибут. Вместо записи series.plot(kind=, теперь вы также можете использовать series.plot.:
In [10]: df = pd.DataFrame(np.random.rand(10, 2), columns=['a', 'b'])
In [11]: df.plot.bar()
В результате этого изменения, эти методы теперь все доступны через автодополнение по табуляции:
In [12]: df.plot.<TAB> # noqa: E225, E999
df.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter
df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
Каждая сигнатура метода включает только соответствующие аргументы. В настоящее время они ограничены обязательными аргументами, но в будущем будут включать и необязательные аргументы. Для обзора см. новый Построение графиков Документация API.
Дополнительные методы для dt аксессор#
Series.dt.strftime#
Теперь мы поддерживаем Series.dt.strftime метода для datetime-подобных объектов для генерации форматированной строки (GH 10110). Примеры:
# DatetimeIndex
In [13]: s = pd.Series(pd.date_range("20130101", periods=4))
In [14]: s
Out[14]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
3 2013-01-04
Length: 4, dtype: datetime64[ns]
In [15]: s.dt.strftime("%Y/%m/%d")
Out[15]:
0 2013/01/01
1 2013/01/02
2 2013/01/03
3 2013/01/04
Length: 4, dtype: object
# PeriodIndex
In [16]: s = pd.Series(pd.period_range("20130101", periods=4))
In [17]: s
Out[17]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
3 2013-01-04
Length: 4, dtype: period[D]
In [18]: s.dt.strftime("%Y/%m/%d")
Out[18]:
0 2013/01/01
1 2013/01/02
2 2013/01/03
3 2013/01/04
Length: 4, dtype: object
Строковый формат соответствует стандартной библиотеке Python, подробности можно найти здесь
Series.dt.total_seconds#
pd.Series типа timedelta64 имеет новый метод .dt.total_seconds() возвращая длительность timedelta в секундах (GH 10817)
# TimedeltaIndex
In [19]: s = pd.Series(pd.timedelta_range("1 minutes", periods=4))
In [20]: s
Out[20]:
0 0 days 00:01:00
1 1 days 00:01:00
2 2 days 00:01:00
3 3 days 00:01:00
Length: 4, dtype: timedelta64[ns]
In [21]: s.dt.total_seconds()
Out[21]:
0 60.0
1 86460.0
2 172860.0
3 259260.0
Length: 4, dtype: float64
Улучшение частоты периодов#
Period, PeriodIndex и period_range теперь может принимать умноженную частоту. Также, Period.freq и PeriodIndex.freq теперь хранятся как DateOffset экземпляр, как DatetimeIndex, а не как str (GH 7811)
Умноженная частота представляет промежуток соответствующей длины. Пример ниже создает период в 3 дня. Сложение и вычитание сдвинут период на его промежуток.
In [22]: p = pd.Period("2015-08-01", freq="3D")
In [23]: p
Out[23]: Period('2015-08-01', '3D')
In [24]: p + 1
Out[24]: Period('2015-08-04', '3D')
In [25]: p - 2
Out[25]: Period('2015-07-26', '3D')
In [26]: p.to_timestamp()
Out[26]: Timestamp('2015-08-01 00:00:00')
In [27]: p.to_timestamp(how="E")
Out[27]: Timestamp('2015-08-03 23:59:59.999999999')
Вы можете использовать умноженную частоту в PeriodIndex и period_range.
In [28]: idx = pd.period_range("2015-08-01", periods=4, freq="2D")
In [29]: idx
Out[29]: PeriodIndex(['2015-08-01', '2015-08-03', '2015-08-05', '2015-08-07'], dtype='period[2D]')
In [30]: idx + 1
Out[30]: PeriodIndex(['2015-08-03', '2015-08-05', '2015-08-07', '2015-08-09'], dtype='period[2D]')
Поддержка файлов SAS XPORT#
read_sas() предоставляет поддержку чтения SAS XPORT форматные файлы. (GH 4052).
df = pd.read_sas("sas_xport.xpt")
Также возможно получить итератор и читать файл XPORT постепенно.
for df in pd.read_sas("sas_xport.xpt", chunksize=10000):
do_something(df)
См. документация для получения дополнительной информации.
Поддержка математических функций в .eval()#
eval() теперь поддерживает вызов математических функций (GH 4893)
df = pd.DataFrame({"a": np.random.randn(10)})
df.eval("b = sin(a)")
Поддерживаемые математические функции: sin, cos, exp, log, expm1, log1p,
sqrt, sinh, cosh, tanh, arcsin, arccos, arctan, arccosh,
arcsinh, arctanh, abs и arctan2.
Эти функции соответствуют встроенным функциям для NumExpr движок. Для Python
движка они сопоставляются с NumPy вызовы.
Изменения в Excel с MultiIndex#
В версии 0.16.2 DataFrame с MultiIndex столбцы не могли быть записаны в Excel через to_excel.
Эта функциональность была добавлена (GH 10564), вместе с обновлением read_excel чтобы данные можно было прочитать обратно без потери информации, указав, какие столбцы/строки составляют MultiIndex
в header и index_col параметры (GH 4679)
См. документация для получения дополнительной информации.
In [31]: df = pd.DataFrame(
....: [[1, 2, 3, 4], [5, 6, 7, 8]],
....: columns=pd.MultiIndex.from_product(
....: [["foo", "bar"], ["a", "b"]], names=["col1", "col2"]
....: ),
....: index=pd.MultiIndex.from_product([["j"], ["l", "k"]], names=["i1", "i2"]),
....: )
....:
In [32]: df
Out[32]:
col1 foo bar
col2 a b a b
i1 i2
j l 1 2 3 4
k 5 6 7 8
[2 rows x 4 columns]
In [33]: df.to_excel("test.xlsx")
In [34]: df = pd.read_excel("test.xlsx", header=[0, 1], index_col=[0, 1])
In [35]: df
Out[35]:
col1 foo bar
col2 a b a b
i1 i2
j l 1 2 3 4
k 5 6 7 8
[2 rows x 4 columns]
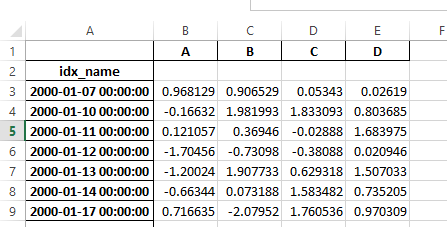
Ранее было необходимо указать has_index_names аргумент в read_excel,
если сериализованные данные имели имена индекса. Для версии 0.17.0 выходной формат to_excel
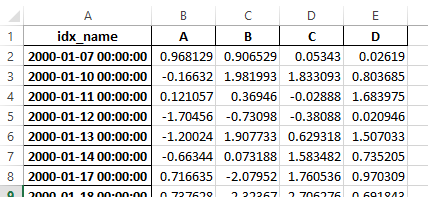
был изменен, чтобы сделать этот ключевое слово ненужным - изменение показано ниже.
Старый
Новый
Предупреждение
Файлы Excel, сохранённые в версии 0.16.2 или ранее, которые содержали имена индексов, всё ещё можно будет читать,
но has_index_names аргумент должен быть указан для True.
Улучшения Google BigQuery#
Добавлена возможность автоматического создания таблицы/набора данных с использованием
pandas.io.gbq.to_gbq()функция, если целевая таблица/набор данных не существует. (GH 8325, GH 11121).Добавлена возможность замены существующей таблицы и схемы при вызове
pandas.io.gbq.to_gbq()функцию черезif_existsаргумент. См. документация для дополнительных деталей (GH 8325).InvalidColumnOrderиInvalidPageTokenв модуле gbq вызоветValueErrorвместоIOError.The
generate_bq_schema()функция теперь устарела и будет удалена в будущей версии (GH 11121)Модуль gbq теперь будет поддерживать Python 3 (GH 11094).
Выравнивание отображения с шириной восточноазиатских символов Юникода#
Предупреждение
Включение этой опции повлияет на производительность при выводе DataFrame и Series (примерно в 2 раза медленнее).
Используйте только тогда, когда это действительно необходимо.
Некоторые восточноазиатские страны используют символы Юникода, ширина которых соответствует 2 алфавитам. Если DataFrame или Series содержит эти символы, вывод по умолчанию не может быть правильно выровнен. Добавлены следующие опции для точной обработки этих символов.
display.unicode.east_asian_width: Использовать ли ширину East Asian Width в Unicode для расчета ширины отображаемого текста. (GH 2612)display.unicode.ambiguous_as_wide: Обрабатывать ли символы Юникода, принадлежащие к неоднозначным, как широкие. (GH 11102)
In [36]: df = pd.DataFrame({u"国籍": ["UK", u"日本"], u"名前": ["Alice", u"しのぶ"]})
In [37]: df
Out[37]:
国籍 名前
0 UK Alice
1 日本 しのぶ
[2 rows x 2 columns]
In [38]: pd.set_option("display.unicode.east_asian_width", True)
In [39]: df
Out[39]:
国籍 名前
0 UK Alice
1 日本 しのぶ
[2 rows x 2 columns]
Для получения дополнительной информации см. здесь
Другие улучшения#
Поддержка
openpyxl>= 2.2. API для поддержки стилей теперь стабилен (GH 10125)mergeтеперь принимает аргументindicatorкоторый добавляет столбец типа Categorical (по умолчанию называется_merge) к выходному объекту, который принимает значения (GH 8790)Источник наблюдения
_mergeзначениеКлюч слияния только в
'left'фреймleft_onlyКлюч слияния только в
'right'фреймright_onlyКлюч слияния в обоих фреймах
bothIn [40]: df1 = pd.DataFrame({"col1": [0, 1], "col_left": ["a", "b"]}) In [41]: df2 = pd.DataFrame({"col1": [1, 2, 2], "col_right": [2, 2, 2]}) In [42]: pd.merge(df1, df2, on="col1", how="outer", indicator=True) Out[42]: col1 col_left col_right _merge 0 0 a NaN left_only 1 1 b 2.0 both 2 2 NaN 2.0 right_only 3 2 NaN 2.0 right_only [4 rows x 4 columns]
Для получения дополнительной информации см. обновлённая документация
pd.to_numericэто новая функция для приведения строк к числам (возможно с принудительным преобразованием) (GH 11133)pd.mergeтеперь разрешит повторяющиеся имена столбцов, если они не участвуют в слиянии (GH 10639).pd.pivotтеперь разрешит передачу index какNone(GH 3962).pd.concatтеперь будет использовать существующие имена Series, если они предоставлены (GH 10698).In [43]: foo = pd.Series([1, 2], name="foo") In [44]: bar = pd.Series([1, 2]) In [45]: baz = pd.Series([4, 5])
Предыдущее поведение:
In [1]: pd.concat([foo, bar, baz], axis=1) Out[1]: 0 1 2 0 1 1 4 1 2 2 5
Новое поведение:
In [46]: pd.concat([foo, bar, baz], axis=1) Out[46]: foo 0 1 0 1 1 4 1 2 2 5 [2 rows x 3 columns]
DataFrameполучилnlargestиnsmallestметоды (GH 10393)Добавить
limit_directionаргумент, позволяющий пользователям указать, использовать ли устаревший SQL BigQuery или стандартный SQL BigQuery. См.limitвключитьinterpolateдля заполненияNaNзначения вперед, назад или в обоих направлениях (GH 9218, GH 10420, GH 11115)In [47]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, np.nan, 13]) In [48]: ser.interpolate(limit=1, limit_direction="both") Out[48]: 0 NaN 1 5.0 2 5.0 3 7.0 4 NaN 5 11.0 6 13.0 Length: 7, dtype: float64
Добавлен
DataFrame.roundметод для округления значений до переменного количества десятичных знаков (GH 10568).In [49]: df = pd.DataFrame( ....: np.random.random([3, 3]), ....: columns=["A", "B", "C"], ....: index=["first", "second", "third"], ....: ) ....: In [50]: df Out[50]: A B C first 0.126970 0.966718 0.260476 second 0.897237 0.376750 0.336222 third 0.451376 0.840255 0.123102 [3 rows x 3 columns] In [51]: df.round(2) Out[51]: A B C first 0.13 0.97 0.26 second 0.90 0.38 0.34 third 0.45 0.84 0.12 [3 rows x 3 columns] In [52]: df.round({"A": 0, "C": 2}) Out[52]: A B C first 0.0 0.966718 0.26 second 1.0 0.376750 0.34 third 0.0 0.840255 0.12 [3 rows x 3 columns]
drop_duplicatesиduplicatedтеперь принимаетkeepключевое слово для нацеливания на первые, последние и все дубликаты. Ключевое словоtake_lastключевое слово устарело, см. здесь (GH 6511, GH 8505)In [53]: s = pd.Series(["A", "B", "C", "A", "B", "D"]) In [54]: s.drop_duplicates() Out[54]: 0 A 1 B 2 C 5 D Length: 4, dtype: object In [55]: s.drop_duplicates(keep="last") Out[55]: 2 C 3 A 4 B 5 D Length: 4, dtype: object In [56]: s.drop_duplicates(keep=False) Out[56]: 2 C 5 D Length: 2, dtype: object
Reindex теперь имеет
toleranceаргумент, который позволяет более точно контролировать Ограничения на заполнение при переиндексации (GH 10411):In [57]: df = pd.DataFrame({"x": range(5), "t": pd.date_range("2000-01-01", periods=5)}) In [58]: df.reindex([0.1, 1.9, 3.5], method="nearest", tolerance=0.2) Out[58]: x t 0.1 0.0 2000-01-01 1.9 2.0 2000-01-03 3.5 NaN NaT [3 rows x 2 columns]
При использовании на
DatetimeIndex,TimedeltaIndexилиPeriodIndex,toleranceбудет преобразовано вTimedeltaесли возможно. Это позволяет указать допуск строкой:In [59]: df = df.set_index("t") In [60]: df.reindex(pd.to_datetime(["1999-12-31"]), method="nearest", tolerance="1 day") Out[60]: x 1999-12-31 0 [1 rows x 1 columns]
toleranceтакже доступен на более низком уровнеIndex.get_indexerиIndex.get_locметоды.Добавлена функциональность для использования
baseаргумент при передискретизацииTimeDeltaIndex(GH 10530)DatetimeIndexможет быть создан с использованием строк, содержащихNaT(GH 7599)to_datetimeтеперь может приниматьyearfirstключевое слово (GH 7599)pandas.tseries.offsetsбольше, чемDayсмещение теперь можно использовать сSeriesдля сложения/вычитания (GH 10699). См. документация для получения дополнительной информации.pd.Timedelta.total_seconds()теперь возвращает длительность Timedelta с точностью до наносекунд (ранее микросекундная точность) (GH 10939)PeriodIndexтеперь поддерживает арифметические операции сnp.ndarray(GH 10638)Поддержка сериализации
Periodобъекты (GH 10439).as_blocksтеперь будет приниматьcopyопциональный аргумент для возврата копии данных, по умолчанию копировать (без изменения поведения по сравнению с предыдущими версиями), (GH 9607)regexаргумент дляDataFrame.filterтеперь обрабатывает числовые имена столбцов вместо вызова исключенияValueError(GH 10384).Включить чтение файлов, сжатых gzip, через URL, либо явно установив параметр сжатия, либо определив по наличию заголовка HTTP Content-Encoding в ответе (GH 8685)
Включение записи файлов Excel в память используя StringIO/BytesIO (GH 7074)
Включить сериализацию списков и словарей в строки в
ExcelWriter(GH 8188)Функции ввода-вывода SQL теперь принимают SQLAlchemy connectable. (GH 7877)
pd.read_sqlиto_sqlможет принимать URI базы данных какconпараметр (подклассы. Это повлияет на порядок сортировки при сортировке DataFrame по нескольким столбцам, сортировке с ключевой функцией, создающей дубликаты, или запросе индекса сортировки при использовании)read_sql_tableтеперь позволяет чтение из представлений (GH 10750).Разрешить запись комплексных значений в
HDFStoresпри использованииtableформат (GH 10447)Включить
pd.read_hdfдля использования без указания ключа, когда HDF-файл содержит один набор данных (GH 10443)pd.read_stataтеперь будет читать файлы типа Stata 118. (GH 9882)msgpackподмодуль обновлен до версии 0.4.6 с обратной совместимостью (GH 10581)DataFrame.to_dictтеперь принимаетorient='index'именованный аргумент (GH 10844).DataFrame.applyвернет Series словарей, если переданная функция возвращает словарь, иreduce=True(GH 8735).Разрешить передачу
kwargsк методам интерполяции (GH 10378).Улучшено сообщение об ошибке при конкатенации пустого итерируемого объекта
Dataframeобъекты (GH 9157)pd.read_csvтеперь может читать bz2-сжатые файлы инкрементально, а C-парсер может читать bz2-сжатые файлы из AWS S3 (GH 11070, GH 11072).В
pd.read_csv, распознаватьs3n://иs3a://URL-адреса как обозначающие хранилище файлов S3 (GH 11070, GH 11071).Чтение CSV-файлов из AWS S3 инкрементально, вместо предварительной загрузки всего файла. (Полная загрузка файла все еще требуется для сжатых файлов в Python 2.) (GH 11070, GH 11073)
pd.read_csvтеперь может определять тип сжатия для файлов, читаемых из хранилища AWS S3 (GH 11070, GH 11074).
Обратно несовместимые изменения API#
Изменения в API сортировки#
API сортировки имел некоторые давние несоответствия. (GH 9816, GH 8239).
Вот сводка API PRIOR до 0.17.0:
Series.sortявляется INPLACE в то время какDataFrame.sortвозвращает новый объект.Series.orderвозвращает новый объектБыло возможно использовать
Series/DataFrame.sort_indexдля сортировки по values передавbyключевое слово.Series/DataFrame.sortlevelработал только наMultiIndexдля сортировки по индексу.
Для решения этих проблем мы переработали API:
Мы представили новый метод,
DataFrame.sort_values(), что является объединениемDataFrame.sort(),Series.sort(), иSeries.order(), для обработки сортировки values.Существующие методы
Series.sort(),Series.order(), иDataFrame.sort()были устаревшими и будут удалены в будущей версии.The
byаргументDataFrame.sort_index()был объявлен устаревшим и будет удален в будущей версии.Существующий метод
.sort_index()получитlevelключевое слово для включения сортировки по уровням.
Теперь у нас есть два различных и непересекающихся метода сортировки. * помечает элементы, которые
будут отображать FutureWarning.
Для сортировки по values:
Предыдущий |
Замена |
|---|---|
* |
|
* |
|
* |
|
Для сортировки по index:
Предыдущий |
Замена |
|---|---|
|
|
|
|
|
|
|
|
* |
|
Мы также устарели и изменили аналогичные методы в двух классах, подобных Series, Index и Categorical.
Предыдущий |
Замена |
|---|---|
* |
|
* |
|
Изменения в to_datetime и to_timedelta#
Обработка ошибок#
Значение по умолчанию для pd.to_datetime обработка ошибок изменилась на errors='raise'.
В предыдущих версиях это было errors='ignore'Кроме того, coerce аргумент
был устаревшим в пользу errors='coerce'. Это означает, что некорректный разбор
вызовет ошибку, а не вернёт исходные данные, как в предыдущих версиях. (GH 10636)
Предыдущее поведение:
In [2]: pd.to_datetime(['2009-07-31', 'asd'])
Out[2]: array(['2009-07-31', 'asd'], dtype=object)
Новое поведение:
In [3]: pd.to_datetime(['2009-07-31', 'asd'])
ValueError: Unknown string format
Конечно, вы также можете принудительно преобразовать это.
In [61]: pd.to_datetime(["2009-07-31", "asd"], errors="coerce")
Out[61]: DatetimeIndex(['2009-07-31', 'NaT'], dtype='datetime64[ns]', freq=None)
Чтобы сохранить предыдущее поведение, можно использовать errors='ignore':
In [4]: pd.to_datetime(["2009-07-31", "asd"], errors="ignore")
Out[4]: Index(['2009-07-31', 'asd'], dtype='object')
Кроме того, pd.to_timedelta получил аналогичный API, errors='raise'|'ignore'|'coerce'должны быть включены в старые категории. Значения, которые были в
удаленных категориях, будут установлены в NaN coerce ключевое слово
было объявлено устаревшим в пользу errors='coerce'.
Согласованный парсинг#
Строковый разбор to_datetime, Timestamp и DatetimeIndex было
сделано согласованным. (GH 7599)
До версии 0.17.0, Timestamp и to_datetime может некорректно разобрать строку даты-времени только с годом, используя сегодняшнюю дату, в противном случае DatetimeIndex
использует начало года. Timestamp и to_datetime может вызывать ValueError в некоторых типах строк даты-времени, которые DatetimeIndex
может разбирать, например, квартальную строку.
Предыдущее поведение:
In [1]: pd.Timestamp('2012Q2')
Traceback
...
ValueError: Unable to parse 2012Q2
# Results in today's date.
In [2]: pd.Timestamp('2014')
Out [2]: 2014-08-12 00:00:00
v0.17.0 может анализировать их, как показано ниже. Работает на DatetimeIndex также.
Новое поведение:
In [62]: pd.Timestamp("2012Q2")
Out[62]: Timestamp('2012-04-01 00:00:00')
In [63]: pd.Timestamp("2014")
Out[63]: Timestamp('2014-01-01 00:00:00')
In [64]: pd.DatetimeIndex(["2012Q2", "2014"])
Out[64]: DatetimeIndex(['2012-04-01', '2014-01-01'], dtype='datetime64[ns]', freq=None)
Примечание
Если вы хотите выполнить вычисления на основе сегодняшней даты, используйте Timestamp.now() и pandas.tseries.offsets.
In [65]: import pandas.tseries.offsets as offsets
In [66]: pd.Timestamp.now()
Out[66]: Timestamp('2025-09-29 22:21:01.322703')
In [67]: pd.Timestamp.now() + offsets.DateOffset(years=1)
Out[67]: Timestamp('2026-09-29 22:21:01.323808')
Изменения в сравнениях Index#
Оператор равенства на Index должен вести себя аналогично Series (GH 9947, GH 10637)
Начиная с v0.17.0, сравнение Index объекты разной длины вызовут ValueError. Это необходимо для согласованности с поведением Series.
Предыдущее поведение:
In [2]: pd.Index([1, 2, 3]) == pd.Index([1, 4, 5])
Out[2]: array([ True, False, False], dtype=bool)
In [3]: pd.Index([1, 2, 3]) == pd.Index([2])
Out[3]: array([False, True, False], dtype=bool)
In [4]: pd.Index([1, 2, 3]) == pd.Index([1, 2])
Out[4]: False
Новое поведение:
In [8]: pd.Index([1, 2, 3]) == pd.Index([1, 4, 5])
Out[8]: array([ True, False, False], dtype=bool)
In [9]: pd.Index([1, 2, 3]) == pd.Index([2])
ValueError: Lengths must match to compare
In [10]: pd.Index([1, 2, 3]) == pd.Index([1, 2])
ValueError: Lengths must match to compare
Обратите внимание, что это отличается от numpy поведение, при котором сравнение может
распространяться:
In [68]: np.array([1, 2, 3]) == np.array([1])
Out[68]: array([ True, False, False])
или он может вернуть False, если трансляция не может быть выполнена:
In [11]: np.array([1, 2, 3]) == np.array([1, 2])
Out[11]: False
Изменения в булевых сравнениях с None#
Булевы сравнения a Series против None теперь будет эквивалентно сравнению с np.nan, а не вызывать TypeError. (GH 1079).
In [69]: s = pd.Series(range(3), dtype="float")
In [70]: s.iloc[1] = None
In [71]: s
Out[71]:
0 0.0
1 NaN
2 2.0
Length: 3, dtype: float64
Предыдущее поведение:
In [5]: s == None
TypeError: Could not compare type with Series
Новое поведение:
In [72]: s == None
Out[72]:
0 False
1 False
2 False
Length: 3, dtype: bool
Обычно вы просто хотите знать, какие значения являются null.
In [73]: s.isnull()
Out[73]:
0 False
1 True
2 False
Length: 3, dtype: bool
Предупреждение
Обычно вы захотите использовать isnull/notnull для таких типов сравнений, как isnull/notnull показывает, какие элементы являются нулевыми. Необходимо
учитывать, что nan's не равны при сравнении, но None's делает. Обратите внимание, что pandas/numpy использует тот факт, что np.nan != np.nan, и обрабатывает None как np.nan.
In [74]: None == None
Out[74]: True
In [75]: np.nan == np.nan
Out[75]: False
поведение HDFStore dropna#
Поведение по умолчанию для функций записи HDFStore с format='table' теперь сохранять строки, которые полностью отсутствуют. Ранее поведение заключалось в удалении строк, которые полностью отсутствовали, кроме индекса. Предыдущее поведение можно воспроизвести с помощью dropna=True опция. (GH 9382)
Предыдущее поведение:
In [76]: df_with_missing = pd.DataFrame(
....: {"col1": [0, np.nan, 2], "col2": [1, np.nan, np.nan]}
....: )
....:
In [77]: df_with_missing
Out[77]:
col1 col2
0 0.0 1.0
1 NaN NaN
2 2.0 NaN
[3 rows x 2 columns]
In [27]:
df_with_missing.to_hdf('file.h5',
key='df_with_missing',
format='table',
mode='w')
In [28]: pd.read_hdf('file.h5', 'df_with_missing')
Out [28]:
col1 col2
0 0 1
2 2 NaN
Новое поведение:
In [78]: df_with_missing.to_hdf("file.h5", key="df_with_missing", format="table", mode="w")
In [79]: pd.read_hdf("file.h5", "df_with_missing")
Out[79]:
col1 col2
0 0.0 1.0
1 NaN NaN
2 2.0 NaN
[3 rows x 2 columns]
См. документация для получения дополнительной информации.
Изменения в display.precision опция#
The display.precision опция была уточнена для обозначения десятичных знаков (GH 10451).
Более ранние версии pandas форматировали числа с плавающей точкой, чтобы иметь на один десятичный знак меньше, чем значение в
display.precision.
In [1]: pd.set_option('display.precision', 2)
In [2]: pd.DataFrame({'x': [123.456789]})
Out[2]:
x
0 123.5
Если интерпретировать точность как «значащие цифры», это работало для научной записи, но та же интерпретация не работала для значений со стандартным форматированием. Это также не соответствовало тому, как numpy обрабатывает форматирование.
В дальнейшем значение display.precision будет напрямую контролировать количество знаков после запятой,
как для обычного форматирования, так и для научной нотации, аналогично тому, как numpy precision опция print работает.
In [80]: pd.set_option("display.precision", 2)
In [81]: pd.DataFrame({"x": [123.456789]})
Out[81]:
x
0 123.46
[1 rows x 1 columns]
Для сохранения поведения вывода с предыдущими версиями значение по умолчанию display.precision было сокращено до 6
из 7.
Изменения в Categorical.unique#
Categorical.unique теперь возвращает новый Categoricals с categories и codes которые уникальны, а не возвращают np.array (GH 10508)
неупорядоченная категория: значения и категории сортируются по порядку появления.
упорядоченная категория: значения сортируются по порядку появления, категории сохраняют существующий порядок.
In [82]: cat = pd.Categorical(["C", "A", "B", "C"], categories=["A", "B", "C"], ordered=True)
In [83]: cat
Out[83]:
['C', 'A', 'B', 'C']
Categories (3, object): ['A' < 'B' < 'C']
In [84]: cat.unique()
Out[84]:
['C', 'A', 'B']
Categories (3, object): ['A' < 'B' < 'C']
In [85]: cat = pd.Categorical(["C", "A", "B", "C"], categories=["A", "B", "C"])
In [86]: cat
Out[86]:
['C', 'A', 'B', 'C']
Categories (3, object): ['A', 'B', 'C']
In [87]: cat.unique()
Out[87]:
['C', 'A', 'B']
Categories (3, object): ['A', 'B', 'C']
Изменения в bool передан как header в парсерах#
В более ранних версиях pandas, если передавалось булево значение header аргумент
read_csv, read_excel, или read_html он был неявно преобразован в целое число, что привело к header=0 для False и header=1 для True
(GH 6113)
A bool входные данные для header теперь вызовет TypeError
In [29]: df = pd.read_csv('data.csv', header=False)
TypeError: Passing a bool to header is invalid. Use header=None for no header or
header=int or list-like of ints to specify the row(s) making up the column names
Другие изменения API#
Линейный и kde график с
subplots=Trueтеперь использует цвета по умолчанию, а не все черные. Укажитеcolor='k'чтобы рисовать все линии черным цветом (GH 9894)Вызов
.value_counts()метод на Series сcategoricaldtype теперь возвращает Series сCategoricalIndex(GH 10704)Свойства метаданных подклассов объектов pandas теперь будут сериализованы (GH 10553).
groupbyиспользуяCategoricalследует тому же правилу, что иCategorical.uniqueописанный выше (GH 10508)При создании
DataFrameс массивомcomplex64dtype ранее означал, что соответствующий столбец автоматически повышался доcomplex128dtype. pandas теперь будет сохранять размер элементов входных данных для комплексных данных (GH 10952)некоторые операторы числовой редукции вернут
ValueError, а неTypeErrorдля объектных типов, включающих строки и числа (GH 11131)Передача в настоящее время неподдерживаемых
chunksizeаргумент дляread_excelилиExcelFile.parseтеперь будет вызыватьNotImplementedError(GH 8011)Разрешить
ExcelFileобъект для передачи вread_excel(GH 11198)DatetimeIndex.unionне выводитfreqifselfи входные данные имеютNoneкакfreq(GH 11086)NaTметоды теперь либо вызывают исключениеValueError, или возвращаетnp.nanилиNaT(GH 9513)Поведение
Методы
возвращает
np.nanweekday,isoweekdayвозвращает
NaTdate,now,replace,to_datetime,todayвозвращает
np.datetime64('NaT')to_datetime64(без изменений)raise
ValueErrorВсе остальные публичные методы (имена, не начинающиеся с подчеркивания)
Устаревшие функции#
Для
Seriesследующие функции индексирования устарели (GH 10177).Устаревшая функция
Замена
.irow(i).iloc[i]или.iat[i].iget(i).iloc[i]или.iat[i].iget_value(i).iloc[i]или.iat[i]Для
DataFrameследующие функции индексирования устарели (GH 10177).Устаревшая функция
Замена
.irow(i).iloc[i].iget_value(i, j).iloc[i, j]или.iat[i, j].icol(j).iloc[:, j]
Примечание
Эти функции индексирования устарели в документации с версии 0.11.0.
Categorical.nameбыл устаревшим, чтобы сделатьCategoricalбольшеnumpy.ndarrayнравится. ИспользуйтеSeries(cat, name="whatever")вместо (GH 10482).Установка пропущенных значений (NaN) в
Categorical’scategoriesвыдаст предупреждение (GH 10748). Вы все еще можете иметь пропущенные значения вvalues.drop_duplicatesиduplicated’stake_lastключевое слово было устаревшим в пользуkeep. (GH 6511, GH 8505)Series.nsmallestиnlargest’stake_lastключевое слово было устаревшим в пользуkeep. (GH 10792)DataFrame.combineAddиDataFrame.combineMultустарели. Их можно легко заменить, используяaddиmulметоды:DataFrame.add(other, fill_value=0)иDataFrame.mul(other, fill_value=1.)(GH 10735).TimeSeriesустарело в пользуSeries(обратите внимание, что это было псевдонимом с версии 0.13.0), (GH 10890)SparsePanelустарел и будет удалён в будущей версии (GH 11157).Series.is_time_seriesустарело в пользуSeries.index.is_all_dates(GH 11135)Устаревшие смещения (как
'A@JAN') устарели (обратите внимание, что это было псевдонимом с версии 0.8.0) (GH 10878)WidePanelустарело в пользуPanel,LongPanelв пользуDataFrame(обратите внимание, что это были псевдонимы с версии < 0.11.0), (GH 10892)DataFrame.convert_objectsбыл устаревшим в пользу функций для конкретных типовpd.to_datetime,pd.to_timestampиpd.to_numeric(новое в 0.17.0) (GH 11133).
Удаление устаревших функций/изменений предыдущих версий#
Удаление
na_lastпараметры изSeries.order()иSeries.sort(), в пользуna_position. (GH 5231)Удаление
percentile_widthиз.describe(), в пользуpercentiles. (GH 7088)Удаление
colSpaceпараметр изDataFrame.to_string(), в пользуcol_space, примерно версия 0.8.0.Удаление автоматического вещания временных рядов (GH 2304)
In [88]: np.random.seed(1234) In [89]: df = pd.DataFrame( ....: np.random.randn(5, 2), ....: columns=list("AB"), ....: index=pd.date_range("2013-01-01", periods=5), ....: ) ....: In [90]: df Out[90]: A B 2013-01-01 0.471435 -1.190976 2013-01-02 1.432707 -0.312652 2013-01-03 -0.720589 0.887163 2013-01-04 0.859588 -0.636524 2013-01-05 0.015696 -2.242685 [5 rows x 2 columns]
Ранее
In [3]: df + df.A FutureWarning: TimeSeries broadcasting along DataFrame index by default is deprecated. Please use DataFrame.
to explicitly broadcast arithmetic operations along the index Out[3]: A B 2013-01-01 0.942870 -0.719541 2013-01-02 2.865414 1.120055 2013-01-03 -1.441177 0.166574 2013-01-04 1.719177 0.223065 2013-01-05 0.031393 -2.226989Текущий
In [91]: df.add(df.A, axis="index") Out[91]: A B 2013-01-01 0.942870 -0.719541 2013-01-02 2.865414 1.120055 2013-01-03 -1.441177 0.166574 2013-01-04 1.719177 0.223065 2013-01-05 0.031393 -2.226989 [5 rows x 2 columns]
Удалить
tableключевое слово вHDFStore.put/append, в пользу использованияformat=(GH 4645)Удалить
kindвread_excel/ExcelFileтак как он не используется (GH 4712)Удалить
infer_typeключевое слово изpd.read_htmlтак как он не используется (GH 4770, GH 7032)Удалить
offsetиtimeRuleключевые слова изSeries.tshift/shift, в пользуfreq(GH 4853, GH 4864)Удалить
pd.load/pd.saveпсевдонимы в пользуpd.to_pickle/pd.read_pickle(GH 3787)
Улучшения производительности#
Поддержка разработки для бенчмаркинга с Библиотека Air Speed Velocity (GH 8361)
Добавлены vbench-тесты для альтернативных движков ExcelWriter и чтения файлов Excel (GH 7171)
Улучшения производительности в
Categorical.value_counts(GH 10804)Улучшения производительности в
SeriesGroupBy.nuniqueиSeriesGroupBy.value_countsиSeriesGroupby.transform(GH 10820, GH 11077)Улучшения производительности в
DataFrame.drop_duplicatesс целочисленными типами данных (GH 10917)Улучшения производительности в
DataFrame.duplicatedс широкими фреймами. (GH 10161, GH 11180)4-кратное улучшение в
timedeltaразбор строк (GH 6755, GH 10426)8-кратное улучшение в
timedelta64иdatetime64ops (GH 6755)Значительно улучшена производительность индексации
MultiIndexс помощью слайсеров (GH 10287)8-кратное улучшение в
ilocиспользуя ввод в виде списка (GH 10791)Улучшена производительность
Series.isinдля Series типа datetime/целых чисел (GH 10287)20-кратное улучшение в
concatCategoricals, когда категории идентичны (GH 10587)Улучшена производительность
to_datetimeкогда указанный строковый формат является ISO8601 (GH 10178)2-кратное улучшение
Series.value_countsдля float dtype (GH 10821)Включить
infer_datetime_formatвto_datetimeкогда компоненты даты не имеют заполнения нулями (GH 11142)Регрессия с 0.16.1 при построении
DataFrameиз вложенного словаря (GH 11084)Улучшения производительности операций сложения/вычитания для
DateOffsetсSeriesилиDatetimeIndex(GH 10744, GH 11205)
Исправления ошибок#
Ошибка в некорректном вычислении
.mean()наtimedelta64[ns]из-за переполнения (GH 9442)Ошибка в
.isinна старых версиях numpy (GH 11232)Ошибка в
DataFrame.to_html(index=False)делает ненужнымnameстрока (GH 10344)Ошибка в
DataFrame.to_latex()thecolumn_formatаргумент не мог быть передан (GH 9402)Ошибка в
DatetimeIndexпри локализации сNaT(GH 10477)Ошибка в
Series.dtоперации в сохранении метаданных (GH 10477)Ошибка в сохранении
NaTкогда передается в ином случае недопустимыйto_datetimeсоздание (GH 10477)Ошибка в
DataFrame.applyкогда функция возвращает категориальный ряд. (GH 9573)Ошибка в
to_datetimeс неверными датами и форматами (GH 10154)Ошибка в
Index.drop_duplicatesудаление имени(ён) (GH 10115)Ошибка в
Series.quantileудаление имени (GH 10881)Ошибка в
pd.Seriesпри установке значения на пустомSeriesчей индекс имеет частоту. (GH 10193)Ошибка в
pd.Series.interpolateс недопустимымиorderзначения ключевых слов. (GH 10633)Ошибка в
DataFrame.plotвызываетValueErrorкогда имя цвета задано несколькими символами (GH 10387)Ошибка в
Indexконструкция со смешанным списком кортежей (GH 10697)Ошибка в
DataFrame.reset_indexкогда индекс содержитNaT. (GH 10388)Ошибка в
ExcelReaderкогда лист пуст (GH 6403)Ошибка в
BinGrouper.group_infoгде возвращаемые значения не совместимы с базовым классом (GH 10914)Ошибка в очистке кэша на
DataFrame.popи последующая операция на месте (GH 10912)Ошибка при индексации со смешанным целым числом
IndexвызываяImportError(GH 10610)Ошибка в
Series.countкогда индекс содержит нулевые значения (GH 10946)Ошибка при сериализации нерегулярной частоты
DatetimeIndex(GH 11002)Ошибка, вызывающая
DataFrame.whereне учитыватьaxisпараметр, когда фрейм имеет симметричную форму. (GH 9736)Ошибка в
Table.select_columnгде имя не сохраняется (GH 10392)Ошибка в
offsets.generate_rangeгдеstartиendимеют более высокую точность, чемoffset(GH 9907)Ошибка в
pd.rolling_*гдеSeries.nameбудет потеряно в выводе (GH 10565)Ошибка в
stackкогда индекс или столбцы не уникальны. (GH 10417)Ошибка при установке
Panelкогда ось имеет MultiIndex (GH 10360)Ошибка в
USFederalHolidayCalendarгдеUSMemorialDayиUSMartinLutherKingJrбыли некорректными (GH 10278 и GH 9760 )Ошибка в
.sample()где возвращаемый объект, если задан, дает ненужныеSettingWithCopyWarning(GH 10738)Ошибка в
.sample()где веса передаются какSeriesне были выровнены по оси перед позиционной обработкой, что могло вызвать проблемы, если индексы весов не были выровнены с объектом выборки. (GH 10738)Регрессия исправлена в (GH 9311, GH 6620, GH 9345), где groupby с datetime-like преобразованием в float с определенными агрегаторами (GH 10979)
Ошибка в
DataFrame.interpolateсaxis=1иinplace=True(GH 10395)Ошибка в
io.sql.get_schemaпри указании нескольких столбцов в качестве первичного ключа (GH 10385).Ошибка в
groupby(sort=False)с датой-временемCategoricalвызываетValueError(GH 10505)Ошибка в
groupby(axis=1)сfilter()выбрасываетIndexError(GH 11041)Ошибка в
test_categoricalна big-endian сборках (GH 10425)Ошибка в
Series.shiftиDataFrame.shiftне поддерживает категориальные данные (GH 9416)Ошибка в
Series.mapиспользуя категориальныйSeriesвызываетAttributeError(GH 10324)Ошибка в
MultiIndex.get_level_valuesвключаяCategoricalвызываетAttributeError(GH 10460)Ошибка в
pd.get_dummiesсsparse=Trueне возвращаетSparseDataFrame(GH 10531)Ошибка в
Indexподтипы (такие какPeriodIndex) не возвращает свой собственный тип для.dropи.insertметоды (GH 10620)Ошибка в
algos.outer_join_indexerкогдаrightмассив пуст (GH 10618)Ошибка в
filter(регрессия с версии 0.16.0) иtransformпри группировке по нескольким ключам, один из которых является датой-временем (GH 10114)Ошибка в
to_datetimeиto_timedeltaвызываяIndexимя будет потеряно (GH 10875)Ошибка в
len(DataFrame.groupby)вызываяIndexErrorкогда есть столбец, содержащий только NaN (GH 11016)Ошибка, вызывавшая segfault при ресемплинге пустого Series (GH 10228)
Ошибка в
DatetimeIndexиPeriodIndex.value_countsсбрасывает имя из своего результата, но сохраняет в результатеIndex. (GH 10150)Ошибка в
pd.evalиспользуяnumexprдвижок преобразует 1-элементный массив numpy в скаляр (GH 10546)Ошибка в
pd.concatсaxis=0когда столбец имеет тип данныхcategory(GH 10177)Ошибка в
read_msgpackгде тип ввода не всегда проверяется (GH 10369, GH 10630)Ошибка в
pd.read_csvс kwargsindex_col=False,index_col=['a', 'b']илиdtype(GH 10413, GH 10467, GH 10577)Ошибка в
Series.from_csvсheaderkwarg не устанавливаетSeries.nameилиSeries.index.name(GH 10483)Ошибка в
groupby.varчто приводило к неточности дисперсии для малых значений с плавающей точкой (GH 10448)Ошибка в
Series.plot(kind='hist')Метка Y не информативна (GH 10485)Ошибка в
read_csvпри использовании конвертера, который генерируетuint8тип (GH 9266)Ошибка вызывает утечку памяти в линейных и площадных графиках временных рядов (GH 9003)
Ошибка при установке
Panelразрезанный вдоль основной или второстепенной оси, когда правая сторона являетсяDataFrame(GH 11014)Ошибка, которая возвращает
Noneи не вызываетNotImplementedErrorкогда операторные функции (например,.add) изPanelне реализованы (GH 7692)Ошибка в линейном и kde графике: не может принимать несколько цветов, когда
subplots=True(GH 9894)Ошибка в
DataFrame.plotвызываетValueErrorкогда имя цвета задано несколькими символами (GH 10387)Ошибка в левом и правом
alignofSeriesсMultiIndexможет быть инвертирован (GH 10665)Ошибка в левом и правом
joinof сMultiIndexможет быть инвертирован (GH 10741)Ошибка в
read_stataпри чтении файла с другим порядком, установленным вcolumns(GH 10757)Ошибка в
Categoricalможет неправильно представлять, когда категория содержитtzилиPeriod(GH 10713)Ошибка в
Categorical.__iter__может не возвращать корректныйdatetimeиPeriod(GH 10713)Ошибка при индексации с
PeriodIndexна объекте сPeriodIndex(GH 4125)Ошибка в
read_csvсengine='c': EOF, предшествующий комментарию, пустой строке и т.д., обрабатывался некорректно (GH 10728, GH 10548)Чтение данных “famafrench” через
DataReaderприводит к ошибке HTTP 404 из-за изменения URL веб-сайта (GH 10591).Ошибка в
read_msgpackгде DataFrame для декодирования имеет повторяющиеся имена столбцов (GH 9618)Ошибка в
io.common.get_filepath_or_bufferчто приводило к сбою чтения корректных файлов S3, если в бакете также содержались ключи, для которых у пользователя нет прав на чтение (GH 10604)Ошибка в векторизованной установке столбцов с метками времени с использованием python
datetime.dateи numpydatetime64(GH 10408, GH 10412)Ошибка в
Index.takeможет добавить ненужныеfreqатрибут (GH 10791)Ошибка в
mergeс пустымDataFrameможет вызыватьIndexError(GH 10824)Ошибка в
to_latexгде неожиданный ключевой аргумент для некоторых документированных аргументов (GH 10888)Ошибка при индексации больших
DataFrameгдеIndexErrorне перехватывается (GH 10645 и GH 10692)Ошибка в
read_csvпри использованииnrowsилиchunksizeпараметры, если файл содержит только строку заголовка (GH 9535)Ошибка в сериализации
categoryтипы в HDF5 при наличии альтернативных кодировок. (GH 10366)Ошибка в
pd.DataFrameпри создании пустого DataFrame со строковым типом данных (GH 9428)Ошибка в
pd.DataFrame.diffкогда DataFrame не консолидирован (GH 10907)Ошибка в
pd.uniqueдля массивов сdatetime64илиtimedelta64dtype, из-за которого возвращался массив с object dtype вместо исходного dtype (GH 9431)Ошибка в
Timedeltaвызывая ошибку при срезе с 0с (GH 10583)Ошибка в
DatetimeIndex.takeиTimedeltaIndex.takeможет не вызыватьIndexErrorпротив недопустимого индекса (GH 10295)Ошибка в
Series([np.nan]).astype('M8[ms]'), который теперь возвращаетSeries([pd.NaT])(GH 10747)Ошибка в
PeriodIndex.orderсброс частоты (GH 10295)Ошибка в
date_rangeкогдаfreqделитendв наносекундах (GH 10885)Ошибка в
ilocпозволяя обращаться к памяти за пределами Series с отрицательными целыми числами (GH 10779)Ошибка в
read_msgpackгде кодировка не соблюдается (GH 10581)Ошибка, препятствующая доступу к первому индексу при использовании
ilocсо списком, содержащим соответствующее отрицательное целое число (GH 10547, GH 10779)Ошибка в
TimedeltaIndexформаттер вызывает ошибку при попытке сохранитьDataFrameсTimedeltaIndexиспользуяto_csv(GH 10833)Ошибка в
DataFrame.whereпри обработке срезов Series (GH 10218, GH 9558)Ошибка, где
pd.read_gbqвыбрасываетValueErrorкогда Bigquery возвращает ноль строк (GH 10273)Ошибка в
to_jsonчто вызывало ошибку сегментации при сериализации ndarray ранга 0 (GH 9576)Ошибка в функциях построения графиков может вызвать
IndexErrorпри построении наGridSpec(GH 10819)Ошибка в графике может показывать ненужные подписи второстепенных делений (GH 10657)
Ошибка в
groupbyнекорректное вычисление для агрегации наDataFrameсNaT(Напримерfirst,last,min). (GH 10590, GH 11010)Ошибка при создании
DataFrameгде передача словаря только со скалярными значениями и указание столбцов не вызывало ошибку (GH 10856)Ошибка в
.var()вызывая ошибки округления для очень похожих значений (GH 10242)Ошибка в
DataFrame.plot(subplots=True)с дублированными столбцами выдает некорректный результат (GH 10962)Ошибка в
Indexарифметические операции могут привести к некорректному классу (GH 10638)Ошибка в
date_rangeприводит к пустому результату, если частота отрицательная ежегодно, ежеквартально и ежемесячно (GH 11018)Ошибка в
DatetimeIndexне может определить отрицательную частоту (GH 11018)Удалено использование некоторых устаревших операций сравнения NumPy, в основном в тестах. (GH 10569)
Ошибка в
Indexтип данных может применяться некорректно (GH 11017)Ошибка в
io.gbqпри проверке минимальной версии клиента google api (GH 10652)Ошибка в
DataFrameсоздание из вложенныхdictсtimedeltaключи (GH 11129)Ошибка в
.fillnaпротив может вызватьTypeErrorкогда данные содержат тип datetime (GH 7095, GH 11153)Ошибка в
.groupbyкогда количество ключей для группировки совпадает с длиной индекса (GH 11185)Ошибка в
convert_objectsгде преобразованные значения могут не возвращаться, если все null иcoerce(GH 9589)Ошибка в
convert_objectsгдеcopyключевое слово не учитывалось (GH 9589)
Участники#
Всего 112 человек внесли патчи в этот релиз. Люди со знаком «+» рядом с именами внесли патч впервые.
Алекс Ротберг
Andrea Bedini +
Andrew Rosenfeld
Andy Hayden
#N/A
Anthonios Partheniou +
Artemy Kolchinsky
Bernard Willers
Charlie Clark +
Chris +
Крис Уилан
Christoph Gohlke +
Кристофер Уилан
Clark Fitzgerald
Clearfield Christopher +
Dan Ringwalt +
Daniel Ni +
Эксперт по данным и коду, экспериментирующий с кодом на данных +
David Cottrell
David John Gagne +
David Kelly +
ETF +
Eduardo Schettino +
Egor +
Egor Panfilov +
Evan Wright
Frank Pinter +
Gabriel Araujo +
Garrett-R
Gianluca Rossi +
Guillaume Gay
Guillaume Poulin
Harsh Nisar +
Ian Henriksen +
Ian Hoegen +
Джайдев Дешпанде +
Jan Rudolph +
Ян Шульц
Jason Swails +
Jeff Reback
Jonas Buyl +
Joris Van den Bossche
Joris Vankerschaver +
Josh Levy-Kramer +
Жюльен Данжу
Ka Wo Chen
Karrie Kehoe +
Келси Джордал
Керби Шедден
Кевин Шеппард
Lars Buitinck
Leif Johnson +
Луис Ортис +
Mac +
Matt Gambogi +
Мэтт Савой +
Matthew Gilbert +
Maximilian Roos +
Микеланджело Д’Агостино +
Mortada Mehyar
Nick Eubank
Nipun Batra
Ondřej Čertík
Филлип Клауд
Pratap Vardhan +
Rafal Skolasinski +
Richard Lewis +
Rinoc Johnson +
Rob Levy
Robert Gieseke
Safia Abdalla +
Samuel Denny +
Saumitra Shahapure +
Sebastian Pölsterl +
Себастьян Рубберт +
Шеппард, Кевин +
Sinhrks
Siu Kwan Lam +
Skipper Seabold
Spencer Carrucciu +
Stephan Hoyer
Stephen Hoover +
Stephen Pascoe +
Терри Сантегоедс +
Томас Грейнджер
Tjerk Santegoeds +
Tom Augspurger
Vincent Davis +
Winterflower +
Yaroslav Halchenko
Yuan Tang (Terry) +
agijsberts
ajcr +
behzad nouri
cel4
chris-b1 +
cyrusmaher +
davidovitch +
ganego +
jreback
juricast +
larvian +
maximilianr +
msund +
rekcahpassyla
robertzk +
scls19fr
seth-p
sinhrks
springcoil +
terrytangyuan +
tzinckgraf +