Версия 0.20.1 (5 мая 2017)#
Это основной выпуск с версии 0.19.2 и включает ряд изменений API, устареваний, новых функций, улучшений и оптимизаций производительности, а также большое количество исправлений ошибок. Мы рекомендуем всем пользователям обновиться до этой версии.
Основные моменты включают:
Новый
.agg()API для Series/DataFrame, аналогичный API groupby-rolling-resample, см. здесьИнтеграция с
feather-format, включая новый верхнеуровневыйpd.read_feather()иDataFrame.to_feather()метод, см. здесь.The
.ixиндексатор устарел, см. здесьPanelбыл устаревшим, см. здесьДобавление
IntervalIndexиIntervalскалярный тип, см. здесьУлучшенный пользовательский API при группировке по уровням индекса в
.groupby(), см. здесьУлучшенная поддержка для
UInt64типы данных, см. здесьНовая ориентация для JSON-сериализации,
orient='table', который использует спецификацию Table Schema и предоставляет возможность более интерактивного repr в Jupyter Notebook, см. здесьЭкспериментальная поддержка экспорта стилизованных DataFrames (
DataFrame.style) в Excel, см. здесьОкно бинарных операций corr/cov теперь возвращает MultiIndex
DataFrameа неPanel, какPanelтеперь устарело, см. здесьПоддержка обработки S3 теперь использует
s3fs, см. здесьПоддержка Google BigQuery теперь использует
pandas-gbqбиблиотека, см. здесь
Предупреждение
pandas изменил внутреннюю структуру и организацию кодовой базы. Это может повлиять на импорты, которые не выполняются из верхнего уровня pandas.* пространство имён, пожалуйста, ознакомьтесь с изменениями здесь.
Проверьте Изменения API и устаревшие возможности перед обновлением.
Примечание
Это комбинированный выпуск для версий 0.20.0 и 0.20.1. Версия 0.20.1 содержит одно дополнительное изменение для обратной совместимости с проектами, использующими pandas' utils процедуры. (GH 16250)
Новые возможности#
Метод agg API для DataFrame/Series#
Series и DataFrame были улучшены для поддержки API агрегации. Это знакомый API
из groupby, оконных операций и передискретизации. Это позволяет выполнять операции агрегации кратко
с использованием agg() и transform(). Полная документация
находится здесь (GH 1623).
Вот пример
In [1]: df = pd.DataFrame(np.random.randn(10, 3), columns=['A', 'B', 'C'],
...: index=pd.date_range('1/1/2000', periods=10))
...:
In [2]: df.iloc[3:7] = np.nan
In [3]: df
Out[3]:
A B C
2000-01-01 0.469112 -0.282863 -1.509059
2000-01-02 -1.135632 1.212112 -0.173215
2000-01-03 0.119209 -1.044236 -0.861849
2000-01-04 NaN NaN NaN
2000-01-05 NaN NaN NaN
2000-01-06 NaN NaN NaN
2000-01-07 NaN NaN NaN
2000-01-08 0.113648 -1.478427 0.524988
2000-01-09 0.404705 0.577046 -1.715002
2000-01-10 -1.039268 -0.370647 -1.157892
[10 rows x 3 columns]
Можно работать с именами строковых функций, вызываемыми объектами, списками или словарями этих элементов.
Использование одной функции эквивалентно .apply.
In [4]: df.agg('sum')
Out[4]:
A -1.068226
B -1.387015
C -4.892029
Length: 3, dtype: float64
Множественные агрегации со списком функций.
In [5]: df.agg(['sum', 'min'])
Out[5]:
A B C
sum -1.068226 -1.387015 -4.892029
min -1.135632 -1.478427 -1.715002
[2 rows x 3 columns]
Использование словаря позволяет применять специфические агрегации для каждого столбца.
Вы получите матричный вывод всех агрегаторов. Вывод имеет один столбец
на каждую уникальную функцию. Эти функции, примененные к конкретному столбцу, будут NaN:
In [6]: df.agg({'A': ['sum', 'min'], 'B': ['min', 'max']})
Out[6]:
A B
sum -1.068226 NaN
min -1.135632 -1.478427
max NaN 1.212112
[3 rows x 2 columns]
API также поддерживает .transform() функция для широковещательной передачи результатов.
In [7]: df.transform(['abs', lambda x: x - x.min()])
Out[7]:
A B C
abs abs abs
2000-01-01 0.469112 1.604745 0.282863 1.195563 1.509059 0.205944
2000-01-02 1.135632 0.000000 1.212112 2.690539 0.173215 1.541787
2000-01-03 0.119209 1.254841 1.044236 0.434191 0.861849 0.853153
2000-01-04 NaN NaN NaN NaN NaN NaN
2000-01-05 NaN NaN NaN NaN NaN NaN
2000-01-06 NaN NaN NaN NaN NaN NaN
2000-01-07 NaN NaN NaN NaN NaN NaN
2000-01-08 0.113648 1.249281 1.478427 0.000000 0.524988 2.239990
2000-01-09 0.404705 1.540338 0.577046 2.055473 1.715002 0.000000
2000-01-10 1.039268 0.096364 0.370647 1.107780 1.157892 0.557110
[10 rows x 6 columns]
При представлении смешанных типов данных, которые не могут быть агрегированы, .agg() будет принимать только допустимые
агрегации. Это похоже на то, как groupby .agg() работает. (GH 15015)
In [8]: df = pd.DataFrame({'A': [1, 2, 3],
...: 'B': [1., 2., 3.],
...: 'C': ['foo', 'bar', 'baz'],
...: 'D': pd.date_range('20130101', periods=3)})
...:
In [9]: df.dtypes
Out[9]:
A int64
B float64
C object
D datetime64[ns]
Length: 4, dtype: object
In [10]: df.agg(['min', 'sum'])
Out[10]:
A B C D
min 1 1.0 bar 2013-01-01
sum 6 6.0 foobarbaz NaT
Ключевой аргумент dtype для ввода-вывода данных#
The 'python' движок для read_csv(), а также read_fwf() функция для анализа файлов с фиксированной шириной текста и read_excel() для парсинга файлов Excel теперь принимают dtype ключевой аргумент для указания типов конкретных столбцов (GH 14295). См. документация io для получения дополнительной информации.
In [10]: data = "a b\n1 2\n3 4"
In [11]: pd.read_fwf(StringIO(data)).dtypes
Out[11]:
a int64
b int64
Length: 2, dtype: object
In [12]: pd.read_fwf(StringIO(data), dtype={'a': 'float64', 'b': 'object'}).dtypes
Out[12]:
a float64
b object
Length: 2, dtype: object
Метод .to_datetime() приобрёл origin параметр#
to_datetime() получил новый параметр, origin, чтобы определить опорную дату
от которой вычисляются результирующие временные метки при разборе числовых значений с определенным unit указано. (GH 11276, GH 11745)
Например, с 1960-01-01 в качестве начальной даты:
In [13]: pd.to_datetime([1, 2, 3], unit='D', origin=pd.Timestamp('1960-01-01'))
Out[13]: DatetimeIndex(['1960-01-02', '1960-01-03', '1960-01-04'], dtype='datetime64[ns]', freq=None)
Значение по умолчанию установлено на origin='unix', который по умолчанию равен 1970-01-01 00:00:00, которая обычно называется 'эпохой Unix' или временем POSIX. Это было предыдущим значением по умолчанию, поэтому это изменение обратно совместимо.
In [14]: pd.to_datetime([1, 2, 3], unit='D')
Out[14]: DatetimeIndex(['1970-01-02', '1970-01-03', '1970-01-04'], dtype='datetime64[ns]', freq=None)
Улучшения GroupBy#
Строки, переданные в DataFrame.groupby() как by параметр теперь может ссылаться либо на имена столбцов, либо на имена уровней индекса. Ранее можно было ссылаться только на имена столбцов. Это позволяет легко группировать по столбцу и уровню индекса одновременно. (GH 5677)
In [15]: arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],
....: ['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
....:
In [16]: index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
In [17]: df = pd.DataFrame({'A': [1, 1, 1, 1, 2, 2, 3, 3],
....: 'B': np.arange(8)},
....: index=index)
....:
In [18]: df
Out[18]:
A B
first second
bar one 1 0
two 1 1
baz one 1 2
two 1 3
foo one 2 4
two 2 5
qux one 3 6
two 3 7
[8 rows x 2 columns]
In [19]: df.groupby(['second', 'A']).sum()
Out[19]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
[6 rows x 1 columns]
Улучшенная поддержка сжатых URL в read_csv#
Код сжатия был переработан (GH 12688). В результате чтение
фреймов данных из URL-адресов в read_csv() или read_table() теперь поддерживает
дополнительные методы сжатия: xz, bz2, и zip (GH 14570).
Ранее только gzip поддерживалось сжатие. По умолчанию сжатие
URL и путей теперь определяется по их расширениям файлов. Кроме того,
улучшена поддержка сжатия bz2 в C-движке python 2 (GH 14874).
In [20]: url = ('https://github.com/{repo}/raw/{branch}/{path}'
....: .format(repo='pandas-dev/pandas',
....: branch='main',
....: path='pandas/tests/io/parser/data/salaries.csv.bz2'))
....:
# default, infer compression
In [21]: df = pd.read_csv(url, sep='\t', compression='infer')
# explicitly specify compression
In [22]: df = pd.read_csv(url, sep='\t', compression='bz2')
In [23]: df.head(2)
Out[23]:
S X E M
0 13876 1 1 1
1 11608 1 3 0
[2 rows x 4 columns]
Ввод-вывод файлов Pickle теперь поддерживает сжатие#
read_pickle(), DataFrame.to_pickle() и Series.to_pickle()
теперь может читать и записывать сжатые файлы pickle. Методы сжатия
могут быть явным параметром или определяться по расширению файла.
См. документацию здесь.
In [24]: df = pd.DataFrame({'A': np.random.randn(1000),
....: 'B': 'foo',
....: 'C': pd.date_range('20130101', periods=1000, freq='s')})
....:
Использование явного типа сжатия
In [25]: df.to_pickle("data.pkl.compress", compression="gzip")
In [26]: rt = pd.read_pickle("data.pkl.compress", compression="gzip")
In [27]: rt.head()
Out[27]:
A B C
0 -1.344312 foo 2013-01-01 00:00:00
1 0.844885 foo 2013-01-01 00:00:01
2 1.075770 foo 2013-01-01 00:00:02
3 -0.109050 foo 2013-01-01 00:00:03
4 1.643563 foo 2013-01-01 00:00:04
[5 rows x 3 columns]
По умолчанию тип сжатия определяется по расширению (compression='infer'):
In [28]: df.to_pickle("data.pkl.gz")
In [29]: rt = pd.read_pickle("data.pkl.gz")
In [30]: rt.head()
Out[30]:
A B C
0 -1.344312 foo 2013-01-01 00:00:00
1 0.844885 foo 2013-01-01 00:00:01
2 1.075770 foo 2013-01-01 00:00:02
3 -0.109050 foo 2013-01-01 00:00:03
4 1.643563 foo 2013-01-01 00:00:04
[5 rows x 3 columns]
In [31]: df["A"].to_pickle("s1.pkl.bz2")
In [32]: rt = pd.read_pickle("s1.pkl.bz2")
In [33]: rt.head()
Out[33]:
0 -1.344312
1 0.844885
2 1.075770
3 -0.109050
4 1.643563
Name: A, Length: 5, dtype: float64
Поддержка UInt64 улучшена#
pandas значительно улучшил поддержку операций с беззнаковыми или строго неотрицательными целыми числами. Ранее работа с такими числами приводила к неправильному округлению или приведению типов данных, что давало некорректные результаты. В частности, новый числовой индекс, UInt64Index, был создан (GH 14937)
In [1]: idx = pd.UInt64Index([1, 2, 3])
In [2]: df = pd.DataFrame({'A': ['a', 'b', 'c']}, index=idx)
In [3]: df.index
Out[3]: UInt64Index([1, 2, 3], dtype='uint64')
Ошибка при преобразовании объектных элементов массивоподобных объектов в 64-битные беззнаковые целые числа (GH 4471, GH 14982)
Ошибка в
Series.unique()в котором беззнаковые 64-битные целые числа вызывали переполнение (GH 14721)Ошибка в
DataFrameконструкция, в которой элементы беззнаковых 64-битных целых чисел преобразовывались в объекты (GH 14881)Ошибка в
pd.read_csv()в котором элементы беззнаковых 64-битных целых чисел неправильно преобразовывались в неверные типы данных (GH 14983)Ошибка в
pd.unique()в котором беззнаковые 64-битные целые числа вызывали переполнение (GH 14915)Ошибка в
pd.value_counts()в котором беззнаковые 64-битные целые числа ошибочно обрезались в выводе (GH 14934)
GroupBy по категориальным данным#
В предыдущих версиях, .groupby(..., sort=False) завершится с ошибкой ValueError при группировке по категориальному ряду, где некоторые категории не встречаются в данных. (GH 13179)
In [34]: chromosomes = np.r_[np.arange(1, 23).astype(str), ['X', 'Y']]
In [35]: df = pd.DataFrame({
....: 'A': np.random.randint(100),
....: 'B': np.random.randint(100),
....: 'C': np.random.randint(100),
....: 'chromosomes': pd.Categorical(np.random.choice(chromosomes, 100),
....: categories=chromosomes,
....: ordered=True)})
....:
In [36]: df
Out[36]:
A B C chromosomes
0 87 22 81 4
1 87 22 81 13
2 87 22 81 22
3 87 22 81 2
4 87 22 81 6
.. .. .. .. ...
95 87 22 81 8
96 87 22 81 11
97 87 22 81 X
98 87 22 81 1
99 87 22 81 19
[100 rows x 4 columns]
Предыдущее поведение:
In [3]: df[df.chromosomes != '1'].groupby('chromosomes', observed=False, sort=False).sum()
---------------------------------------------------------------------------
ValueError: items in new_categories are not the same as in old categories
Новое поведение:
In [37]: df[df.chromosomes != '1'].groupby('chromosomes', observed=False, sort=False).sum()
Out[37]:
A B C
chromosomes
4 348 88 324
13 261 66 243
22 348 88 324
2 348 88 324
6 174 44 162
... ... .. ...
3 348 88 324
11 348 88 324
19 174 44 162
1 0 0 0
21 0 0 0
[24 rows x 3 columns]
Вывод схемы таблицы#
Новая ориентация 'table' для DataFrame.to_json()
сгенерирует Схема таблицы совместимое строковое представление данных.
In [38]: df = pd.DataFrame(
....: {'A': [1, 2, 3],
....: 'B': ['a', 'b', 'c'],
....: 'C': pd.date_range('2016-01-01', freq='d', periods=3)},
....: index=pd.Index(range(3), name='idx'))
....:
In [39]: df
Out[39]:
A B C
idx
0 1 a 2016-01-01
1 2 b 2016-01-02
2 3 c 2016-01-03
[3 rows x 3 columns]
In [40]: df.to_json(orient='table')
Out[40]: '{"schema":{"fields":[{"name":"idx","type":"integer"},{"name":"A","type":"integer"},{"name":"B","type":"string"},{"name":"C","type":"datetime"}],"primaryKey":["idx"],"pandas_version":"1.4.0"},"data":[{"idx":0,"A":1,"B":"a","C":"2016-01-01T00:00:00.000"},{"idx":1,"A":2,"B":"b","C":"2016-01-02T00:00:00.000"},{"idx":2,"A":3,"B":"c","C":"2016-01-03T00:00:00.000"}]}'
См. Ввод-вывод: Схема таблицы для получения дополнительной информации.
Кроме того, repr для DataFrame и Series теперь может публиковать
это представление схемы JSON Table для Series или DataFrame, если вы
используете IPython (или другой интерфейс, такой как nteract используя протокол обмена сообщениями Jupyter.
Это позволяет фронтендам, таким как Jupyter notebook и nteract
больше гибкости в отображении объектов pandas, поскольку они имеют
больше информации о данных.
Вы должны включить это, установив display.html.table_schema опция для True.
Разреженная матрица SciPy из/в SparseDataFrame#
pandas теперь поддерживает создание разреженных датафреймов непосредственно из scipy.sparse.spmatrix экземпляры.
См. документация для получения дополнительной информации. (GH 4343)
Все разреженные форматы поддерживаются, но матрицы, которые не находятся в COOrdinate формат будет преобразован, копируя данные по мере необходимости.
from scipy.sparse import csr_matrix
arr = np.random.random(size=(1000, 5))
arr[arr < .9] = 0
sp_arr = csr_matrix(arr)
sp_arr
sdf = pd.SparseDataFrame(sp_arr)
sdf
Чтобы преобразовать SparseDataFrame обратно в разреженную матрицу SciPy в формате COO можно использовать:
sdf.to_coo()
Вывод в Excel для стилизованных DataFrame#
Добавлена экспериментальная поддержка экспорта DataFrame.style форматы в Excel с использованием openpyxl движок. (GH 15530)
Например, после выполнения следующего, styled.xlsx отображается как ниже:
In [41]: np.random.seed(24)
In [42]: df = pd.DataFrame({'A': np.linspace(1, 10, 10)})
In [43]: df = pd.concat([df, pd.DataFrame(np.random.RandomState(24).randn(10, 4),
....: columns=list('BCDE'))],
....: axis=1)
....:
In [44]: df.iloc[0, 2] = np.nan
In [45]: df
Out[45]:
A B C D E
0 1.0 1.329212 NaN -0.316280 -0.990810
1 2.0 -1.070816 -1.438713 0.564417 0.295722
2 3.0 -1.626404 0.219565 0.678805 1.889273
3 4.0 0.961538 0.104011 -0.481165 0.850229
4 5.0 1.453425 1.057737 0.165562 0.515018
5 6.0 -1.336936 0.562861 1.392855 -0.063328
6 7.0 0.121668 1.207603 -0.002040 1.627796
7 8.0 0.354493 1.037528 -0.385684 0.519818
8 9.0 1.686583 -1.325963 1.428984 -2.089354
9 10.0 -0.129820 0.631523 -0.586538 0.290720
[10 rows x 5 columns]
In [46]: styled = (df.style
....: .applymap(lambda val: 'color:red;' if val < 0 else 'color:black;')
....: .highlight_max())
....:
In [47]: styled.to_excel('styled.xlsx', engine='openpyxl')
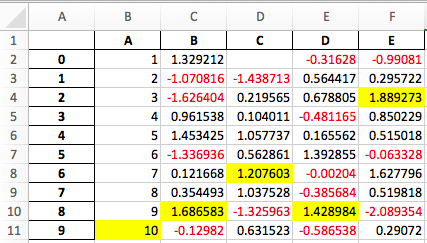
См. Документация по стилю для более подробной информации.
IntervalIndex#
pandas получил IntervalIndex со своим собственным типом данных, interval а также Interval скалярного типа. Это обеспечивает первоклассную поддержку интервальной
нотации, в частности, как тип возвращаемого значения для категорий в cut() и qcut(). IntervalIndex позволяет уникальную индексацию, см.
документация. (GH 7640, GH 8625)
Предупреждение
Эти особенности индексирования IntervalIndex являются временными и могут измениться в будущих версиях pandas. Отзывы об использовании приветствуются.
Предыдущее поведение:
Возвращенные категории были строками, представляющими интервалы
In [1]: c = pd.cut(range(4), bins=2)
In [2]: c
Out[2]:
[(-0.003, 1.5], (-0.003, 1.5], (1.5, 3], (1.5, 3]]
Categories (2, object): [(-0.003, 1.5] < (1.5, 3]]
In [3]: c.categories
Out[3]: Index(['(-0.003, 1.5]', '(1.5, 3]'], dtype='object')
Новое поведение:
In [48]: c = pd.cut(range(4), bins=2)
In [49]: c
Out[49]:
[(-0.003, 1.5], (-0.003, 1.5], (1.5, 3.0], (1.5, 3.0]]
Categories (2, interval[float64, right]): [(-0.003, 1.5] < (1.5, 3.0]]
In [50]: c.categories
Out[50]: IntervalIndex([(-0.003, 1.5], (1.5, 3.0]], dtype='interval[float64, right]')
Кроме того, это позволяет группировать other данные с этими же интервалами, с NaN представляющий отсутствующее
значение, аналогично другим типам данных.
In [51]: pd.cut([0, 3, 5, 1], bins=c.categories)
Out[51]:
[(-0.003, 1.5], (1.5, 3.0], NaN, (-0.003, 1.5]]
Categories (2, interval[float64, right]): [(-0.003, 1.5] < (1.5, 3.0]]
An IntervalIndex также может использоваться в Series и DataFrame в качестве индекса.
In [52]: df = pd.DataFrame({'A': range(4),
....: 'B': pd.cut([0, 3, 1, 1], bins=c.categories)
....: }).set_index('B')
....:
In [53]: df
Out[53]:
A
B
(-0.003, 1.5] 0
(1.5, 3.0] 1
(-0.003, 1.5] 2
(-0.003, 1.5] 3
[4 rows x 1 columns]
Выбор через определенный интервал:
In [54]: df.loc[pd.Interval(1.5, 3.0)]
Out[54]:
A 1
Name: (1.5, 3.0], Length: 1, dtype: int64
Выбор через скалярное значение, которое содержится в интервалы.
In [55]: df.loc[0]
Out[55]:
A
B
(-0.003, 1.5] 0
(-0.003, 1.5] 2
(-0.003, 1.5] 3
[3 rows x 1 columns]
Другие улучшения#
DataFrame.rolling()теперь принимает параметрclosed='right'|'left'|'both'|'neither'для выбора закрытости конечной точки скользящего окна. См. документация (GH 13965)Интеграция с
feather-format, включая новый верхнеуровневыйpd.read_feather()иDataFrame.to_feather()метод, см. здесь.Series.str.replace()теперь принимает вызываемый объект в качестве замены, который передается вre.sub(GH 15055)Series.str.replace()теперь принимает скомпилированное регулярное выражение в качестве шаблона (GH 15446)Series.sort_indexпринимает параметрыkindиna_position(GH 13589, GH 14444)DataFrameиDataFrame.groupby()получилиnunique()метод для подсчёта уникальных значений по оси (GH 14336, GH 15197).DataFrameполучилmelt()метод, эквивалентныйpd.melt(), для преобразования из широкого в длинный формат (GH 12640).pd.read_excel()теперь сохраняет порядок листов при использованииsheetname=None(GH 9930)Теперь поддерживаются множественные псевдонимы смещений с десятичными точками (например,
0.5minпарсится как30s) (GH 8419).isnull()и.notnull()были добавлены вIndexобъект, чтобы сделать их более согласованными сSeriesAPI (GH 15300)Новый
UnsortedIndexError(подклассKeyError) возникает при индексировании/срезе в несортированном MultiIndex (GH 11897). Это позволяет различать ошибки из-за отсутствия сортировки или некорректного ключа. См. здесьMultiIndexполучил.to_frame()метод для преобразования вDataFrame(GH 12397)pd.cutиpd.qcutтеперь поддерживают типы данных datetime64 и timedelta64 (GH 14714, GH 14798)pd.qcutполучилduplicates='raise'|'drop'опцию для управления вызовом ошибки при дублировании границ (GH 7751)Seriesпредоставляетto_excelметод для вывода файлов Excel (GH 8825)The
usecolsаргумент вpd.read_csv()теперь принимает вызываемую функцию в качестве значения (GH 14154)The
skiprowsаргумент вpd.read_csv()теперь принимает вызываемую функцию в качестве значения (GH 10882)The
nrowsиchunksizeаргументы вpd.read_csv()поддерживаются, если оба переданы (GH 6774, GH 15755)DataFrame.plotтеперь выводит заголовок над каждым подграфиком, еслиsuplots=Trueиtitleявляется списком строк (GH 14753)DataFrame.plotможно передать цветовой цикл по умолчанию matplotlib 2.0 в виде одной строки в качестве параметра color, см. здесь. (GH 15516)Series.interpolate()теперь поддерживает timedelta в качестве типа индекса сmethod='time'(GH 6424)Добавление
levelключевое слово дляDataFrame/Series.renameдля переименования меток в указанном уровне MultiIndex (GH 4160).DataFrame.reset_index()теперь будет интерпретировать кортежindex.nameв качестве ключа, охватывающего уровниcolumns, если этоMultiIndex(GH 16164)Timedelta.isoformatметод добавлен для форматирования Timedelta как ISO 8601 длительность. См. Документация по Timedelta (GH 15136).select_dtypes()теперь позволяет строкуdatetimetzдля универсального выбора дат с tz (GH 14910)The
.to_latex()метод теперь будет приниматьmulticolumnиmultirowаргументы для использования сопутствующих улучшений LaTeXpd.merge_asof()получил опциюdirection='backward'|'forward'|'nearest'(GH 14887)Series/DataFrame.asfreq()получилиfill_valueпараметр для заполнения пропущенных значений (GH 3715).Series/DataFrame.resample.asfreqполучилиfill_valueпараметр, для заполнения пропущенных значений при ресемплинге (GH 3715).pandas.util.hash_pandas_object()получил возможность хэшироватьMultiIndex(GH 15224)Series/DataFrame.squeeze()получилиaxisпараметр. (GH 15339)DataFrame.to_excel()имеет новыйfreeze_panesпараметр для включения закрепления областей при экспорте в Excel (GH 15160)pd.read_html()будет парсить несколько строк заголовков, создавая заголовок MultiIndex. (GH 13434).Вывод HTML таблицы пропускает
colspanилиrowspanатрибут, если равен 1. (GH 15403)pandas.io.formats.style.Stylerшаблон теперь содержит блоки для более простого расширения, см. пример ноутбука (GH 15649)Styler.render()теперь принимает**kwargsчтобы разрешить пользовательские переменные в шаблоне (GH 15649)Совместимость с Jupyter notebook 5.0; Метки столбцов MultiIndex выровнены по левому краю, а метки строк MultiIndex — по верхнему краю (GH 15379)
TimedeltaIndexтеперь имеет пользовательский форматтер даты, специально разработанный для точности на уровне наносекунд (GH 8711)pd.api.types.union_categoricalsполучилignore_orderedаргумент для игнорирования упорядоченного атрибута объединенных категориальных данных (GH 13410). См. документация по объединению категориальных данных для получения дополнительной информации.DataFrame.to_latex()иDataFrame.to_string()теперь допускают необязательные псевдонимы заголовков. (GH 15536)Повторно включить
parse_datesключевое словоpd.read_excel()для парсинга строковых столбцов как дат (GH 14326)Добавлен
.emptyсвойство для подклассовIndex. (GH 15270)Включено целочисленное деление для
TimedeltaиTimedeltaIndex(GH 15828)pandas.io.json.json_normalize()получил опциюerrors='ignore'|'raise'; по умолчаниюerrors='raise'что обратно совместимо. (GH 14583)pandas.io.json.json_normalize()с пустымlistвернет пустойDataFrame(GH 15534)pandas.io.json.json_normalize()получилsepопция, которая принимаетstrдля разделения объединённых полей; по умолчанию используется “.”, что обратно совместимо. (GH 14883)MultiIndex.remove_unused_levels()был добавлен для облегчения удаление неиспользуемых уровней. (GH 15694)pd.read_csv()теперь вызоветParserErrorошибка при возникновении любой ошибки парсинга (GH 15913, GH 15925)pd.read_csv()теперь поддерживаетerror_bad_linesиwarn_bad_linesаргументы для парсера Python (GH 15925)The
display.show_dimensionsопция теперь также может использоваться для указания длиныSeriesдолжен отображаться в его repr (GH 7117).parallel_coordinates()получилsort_labelsаргумент ключевого слова, который сортирует метки классов и назначенные им цвета (GH 15908)Добавлены опции для включения/отключения использования
bottleneckиnumexpr, см. здесь (GH 16157)DataFrame.style.bar()теперь принимает два дополнительных параметра для дальнейшей настройки гистограммы. Выравнивание столбцов устанавливается с помощьюalign='left'|'mid'|'zero', по умолчанию используется "left", что обратно совместимо; Теперь можно передать списокcolor=[color_negative, color_positive]. (GH 14757)
Обратно несовместимые изменения API#
Возможная несовместимость для форматов HDF5, созданных с pandas < 0.13.0#
pd.TimeSeries был официально устаревшим в 0.17.0, хотя уже был псевдонимом с 0.13.0. Он был
заменён на pd.Series. (GH 15098).
Это может приводит к тому, что файлы HDF5, созданные в предыдущих версиях, становятся нечитаемыми, если pd.TimeSeries
использовался. Это, скорее всего, относится к pandas < 0.13.0. Если вы оказались в такой ситуации, вы можете использовать более раннюю версию pandas для чтения файлов HDF5, а затем записать их снова после применения процедуры ниже.
In [2]: s = pd.TimeSeries([1, 2, 3], index=pd.date_range('20130101', periods=3))
In [3]: s
Out[3]:
2013-01-01 1
2013-01-02 2
2013-01-03 3
Freq: D, dtype: int64
In [4]: type(s)
Out[4]: pandas.core.series.TimeSeries
In [5]: s = pd.Series(s)
In [6]: s
Out[6]:
2013-01-01 1
2013-01-02 2
2013-01-03 3
Freq: D, dtype: int64
In [7]: type(s)
Out[7]: pandas.core.series.Series
Map на типах Index теперь возвращает другие типы Index#
map на Index теперь возвращает Index, а не массив numpy (GH 12766)
In [56]: idx = pd.Index([1, 2])
In [57]: idx
Out[57]: Index([1, 2], dtype='int64')
In [58]: mi = pd.MultiIndex.from_tuples([(1, 2), (2, 4)])
In [59]: mi
Out[59]:
MultiIndex([(1, 2),
(2, 4)],
)
Предыдущее поведение:
In [5]: idx.map(lambda x: x * 2)
Out[5]: array([2, 4])
In [6]: idx.map(lambda x: (x, x * 2))
Out[6]: array([(1, 2), (2, 4)], dtype=object)
In [7]: mi.map(lambda x: x)
Out[7]: array([(1, 2), (2, 4)], dtype=object)
In [8]: mi.map(lambda x: x[0])
Out[8]: array([1, 2])
Новое поведение:
In [60]: idx.map(lambda x: x * 2)
Out[60]: Index([2, 4], dtype='int64')
In [61]: idx.map(lambda x: (x, x * 2))
Out[61]:
MultiIndex([(1, 2),
(2, 4)],
)
In [62]: mi.map(lambda x: x)
Out[62]:
MultiIndex([(1, 2),
(2, 4)],
)
In [63]: mi.map(lambda x: x[0])
Out[63]: Index([1, 2], dtype='int64')
map на Series с datetime64 значения могут возвращать int64 dtypes, а не int32
In [64]: s = pd.Series(pd.date_range('2011-01-02T00:00', '2011-01-02T02:00', freq='H')
....: .tz_localize('Asia/Tokyo'))
....:
In [65]: s
Out[65]:
0 2011-01-02 00:00:00+09:00
1 2011-01-02 01:00:00+09:00
2 2011-01-02 02:00:00+09:00
Length: 3, dtype: datetime64[ns, Asia/Tokyo]
Предыдущее поведение:
In [9]: s.map(lambda x: x.hour)
Out[9]:
0 0
1 1
2 2
dtype: int32
Новое поведение:
In [66]: s.map(lambda x: x.hour)
Out[66]:
0 0
1 1
2 2
Length: 3, dtype: int64
Доступ к полям даты и времени Index теперь возвращает Index#
Атрибуты, связанные с датой и временем (см. здесь
для обзора) из DatetimeIndex, PeriodIndex и TimedeltaIndex ранее
возвращаемые массивы numpy. Теперь они будут возвращать новый Index объект, за исключением
случая булевого поля, где результат всё равно будет булевым ndarray. (GH 15022)
Предыдущее поведение:
In [1]: idx = pd.date_range("2015-01-01", periods=5, freq='10H')
In [2]: idx.hour
Out[2]: array([ 0, 10, 20, 6, 16], dtype=int32)
Новое поведение:
In [67]: idx = pd.date_range("2015-01-01", periods=5, freq='10H')
In [68]: idx.hour
Out[68]: Index([0, 10, 20, 6, 16], dtype='int32')
Это имеет преимущество в том, что конкретные Index методы все еще доступны для результата. С другой стороны, это может иметь обратную несовместимость: например, по сравнению с массивами numpy, Index объекты не изменяемы. Чтобы получить исходный ndarray, вы всегда можете явно преобразовать, используя np.asarray(idx.hour).
pd.unique теперь будет согласован с типами расширений#
В предыдущих версиях, использование Series.unique() и pandas.unique() на Categorical и типы данных с учетом часового пояса
давали бы разные типы возвращаемых значений. Теперь они приведены к единообразию. (GH 15903)
Datetime с учетом часового пояса
Предыдущее поведение:
# Series In [5]: pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]).unique() Out[5]: array([Timestamp('2016-01-01 00:00:00-0500', tz='US/Eastern')], dtype=object) In [6]: pd.unique(pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')])) Out[6]: array(['2016-01-01T05:00:00.000000000'], dtype='datetime64[ns]') # Index In [7]: pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]).unique() Out[7]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None) In [8]: pd.unique([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]) Out[8]: array(['2016-01-01T05:00:00.000000000'], dtype='datetime64[ns]')
Новое поведение:
# Series, returns an array of Timestamp tz-aware In [64]: pd.Series([pd.Timestamp(r'20160101', tz=r'US/Eastern'), ....: pd.Timestamp(r'20160101', tz=r'US/Eastern')]).unique() ....: Out[64]:
['2016-01-01 00:00:00-05:00'] Length: 1, dtype: datetime64[ns, US/Eastern] In [65]: pd.unique(pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')])) ....: Out[65]: ['2016-01-01 00:00:00-05:00'] Length: 1, dtype: datetime64[ns, US/Eastern] # Index, returns a DatetimeIndex In [66]: pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')]).unique() ....: Out[66]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None) In [67]: pd.unique(pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')])) ....: Out[67]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None) Категориальные данные
Предыдущее поведение:
In [1]: pd.Series(list('baabc'), dtype='category').unique() Out[1]: [b, a, c] Categories (3, object): [b, a, c] In [2]: pd.unique(pd.Series(list('baabc'), dtype='category')) Out[2]: array(['b', 'a', 'c'], dtype=object)
Новое поведение:
# returns a Categorical In [68]: pd.Series(list('baabc'), dtype='category').unique() Out[68]: ['b', 'a', 'c'] Categories (3, object): ['a', 'b', 'c'] In [69]: pd.unique(pd.Series(list('baabc'), dtype='category')) Out[69]: ['b', 'a', 'c'] Categories (3, object): ['a', 'b', 'c']
Обработка файлов S3#
pandas теперь использует s3fs для обработки соединений S3. Это не должно нарушать
никакой код. Однако, поскольку s3fs не является обязательной зависимостью, вам нужно будет установить её отдельно, например boto
в предыдущих версиях pandas. (GH 11915).
Изменения частичного строкового индексирования#
Частичная строковая индексация DatetimeIndex теперь работает как точное совпадение, при условии, что разрешение строки совпадает с разрешением индекса, включая случай, когда оба являются секундами (GH 14826). См. Срез против точного совпадения подробности.
In [70]: df = pd.DataFrame({'a': [1, 2, 3]}, pd.DatetimeIndex(['2011-12-31 23:59:59',
....: '2012-01-01 00:00:00',
....: '2012-01-01 00:00:01']))
....:
Предыдущее поведение:
In [4]: df['2011-12-31 23:59:59']
Out[4]:
a
2011-12-31 23:59:59 1
In [5]: df['a']['2011-12-31 23:59:59']
Out[5]:
2011-12-31 23:59:59 1
Name: a, dtype: int64
Новое поведение:
In [4]: df['2011-12-31 23:59:59']
KeyError: '2011-12-31 23:59:59'
In [5]: df['a']['2011-12-31 23:59:59']
Out[5]: 1
Конкатенация разных типов float не будет автоматически повышать тип#
Ранее, concat нескольких объектов с разными float dtypes автоматически повышали бы результаты до dtype float64. Теперь будет использоваться наименьший допустимый тип данных (GH 13247)
In [71]: df1 = pd.DataFrame(np.array([1.0], dtype=np.float32, ndmin=2))
In [72]: df1.dtypes
Out[72]:
0 float32
Length: 1, dtype: object
In [73]: df2 = pd.DataFrame(np.array([np.nan], dtype=np.float32, ndmin=2))
In [74]: df2.dtypes
Out[74]:
0 float32
Length: 1, dtype: object
Предыдущее поведение:
In [7]: pd.concat([df1, df2]).dtypes
Out[7]:
0 float64
dtype: object
Новое поведение:
In [75]: pd.concat([df1, df2]).dtypes
Out[75]:
0 float32
Length: 1, dtype: object
поддержка pandas Google BigQuery перемещена#
pandas выделил поддержку Google BigQuery в отдельный пакет pandas-gbq. Вы можете conda install pandas-gbq -c conda-forge или
pip install pandas-gbq чтобы получить его. Функциональность read_gbq() и DataFrame.to_gbq() остаются такими же, как в
текущей выпущенной версии pandas-gbq=0.1.4. Документация теперь размещена здесь (GH 15347)
Использование памяти для Index стало более точным#
В предыдущих версиях отображение .memory_usage() в структуре pandas с индексом включало бы только фактические значения индекса, а не структуры, обеспечивающие быстрое индексирование. Обычно это различается для Index и MultiIndex и менее для других типов индексов. (GH 15237)
Предыдущее поведение:
In [8]: index = pd.Index(['foo', 'bar', 'baz'])
In [9]: index.memory_usage(deep=True)
Out[9]: 180
In [10]: index.get_loc('foo')
Out[10]: 0
In [11]: index.memory_usage(deep=True)
Out[11]: 180
Новое поведение:
In [8]: index = pd.Index(['foo', 'bar', 'baz'])
In [9]: index.memory_usage(deep=True)
Out[9]: 180
In [10]: index.get_loc('foo')
Out[10]: 0
In [11]: index.memory_usage(deep=True)
Out[11]: 260
Изменения в DataFrame.sort_index#
В некоторых случаях вызов .sort_index() на DataFrame с MultiIndex вернет тот же DataFrame без видимой сортировки.
Это может произойти с lexsorted, но не монотонные уровни. (GH 15622, GH 15687, GH 14015, GH 13431, GH 15797)
Это неизмененным из предыдущих версий, но показаны для иллюстрации:
In [81]: df = pd.DataFrame(np.arange(6), columns=['value'],
....: index=pd.MultiIndex.from_product([list('BA'), range(3)]))
....:
In [82]: df
Out[82]:
value
B 0 0
1 1
2 2
A 0 3
1 4
2 5
[6 rows x 1 columns]
In [87]: df.index.is_lexsorted()
Out[87]: False
In [88]: df.index.is_monotonic
Out[88]: False
Сортировка работает как ожидается
In [76]: df.sort_index()
Out[76]:
a
2011-12-31 23:59:59 1
2012-01-01 00:00:00 2
2012-01-01 00:00:01 3
[3 rows x 1 columns]
In [90]: df.sort_index().index.is_lexsorted()
Out[90]: True
In [91]: df.sort_index().index.is_monotonic
Out[91]: True
Однако этот пример, имеющий немонотонный 2-й уровень, не ведёт себя как ожидалось.
In [77]: df = pd.DataFrame({'value': [1, 2, 3, 4]},
....: index=pd.MultiIndex([['a', 'b'], ['bb', 'aa']],
....: [[0, 0, 1, 1], [0, 1, 0, 1]]))
....:
In [78]: df
Out[78]:
value
a bb 1
aa 2
b bb 3
aa 4
[4 rows x 1 columns]
Предыдущее поведение:
In [11]: df.sort_index()
Out[11]:
value
a bb 1
aa 2
b bb 3
aa 4
In [14]: df.sort_index().index.is_lexsorted()
Out[14]: True
In [15]: df.sort_index().index.is_monotonic
Out[15]: False
Новое поведение:
In [94]: df.sort_index()
Out[94]:
value
a aa 2
bb 1
b aa 4
bb 3
[4 rows x 1 columns]
In [95]: df.sort_index().index.is_lexsorted()
Out[95]: True
In [96]: df.sort_index().index.is_monotonic
Out[96]: True
Форматирование GroupBy describe#
Форматирование вывода groupby.describe() теперь помечает describe() метрики в столбцах вместо индекса.
Этот формат согласуется с groupby.agg() при применении нескольких функций одновременно. (GH 4792)
Предыдущее поведение:
In [1]: df = pd.DataFrame({'A': [1, 1, 2, 2], 'B': [1, 2, 3, 4]})
In [2]: df.groupby('A').describe()
Out[2]:
B
A
1 count 2.000000
mean 1.500000
std 0.707107
min 1.000000
25% 1.250000
50% 1.500000
75% 1.750000
max 2.000000
2 count 2.000000
mean 3.500000
std 0.707107
min 3.000000
25% 3.250000
50% 3.500000
75% 3.750000
max 4.000000
In [3]: df.groupby('A').agg(["mean", "std", "min", "max"])
Out[3]:
B
mean std amin amax
A
1 1.5 0.707107 1 2
2 3.5 0.707107 3 4
Новое поведение:
In [79]: df = pd.DataFrame({'A': [1, 1, 2, 2], 'B': [1, 2, 3, 4]})
In [80]: df.groupby('A').describe()
Out[80]:
B
count mean std min 25% 50% 75% max
A
1 2.0 1.5 0.707107 1.0 1.25 1.5 1.75 2.0
2 2.0 3.5 0.707107 3.0 3.25 3.5 3.75 4.0
[2 rows x 8 columns]
In [81]: df.groupby('A').agg(["mean", "std", "min", "max"])
Out[81]:
B
mean std min max
A
1 1.5 0.707107 1 2
2 3.5 0.707107 3 4
[2 rows x 4 columns]
Бинарные операции окна corr/cov возвращают DataFrame с MultiIndex#
Бинарная операция окна, например, .corr() или .cov(), при работе с .rolling(..), .expanding(..), или .ewm(..) object,
теперь будет возвращать 2-уровневый MultiIndexed DataFrame а не Panel, как Panel теперь устарел,
см. здесь. Они эквивалентны по функции,
но MultiIndexed DataFrame имеет большую поддержку в pandas. См. раздел о Оконные бинарные операции для получения дополнительной информации. (GH 15677)
In [82]: np.random.seed(1234)
In [83]: df = pd.DataFrame(np.random.rand(100, 2),
....: columns=pd.Index(['A', 'B'], name='bar'),
....: index=pd.date_range('20160101',
....: periods=100, freq='D', name='foo'))
....:
In [84]: df.tail()
Out[84]:
bar A B
foo
2016-04-05 0.640880 0.126205
2016-04-06 0.171465 0.737086
2016-04-07 0.127029 0.369650
2016-04-08 0.604334 0.103104
2016-04-09 0.802374 0.945553
[5 rows x 2 columns]
Предыдущее поведение:
In [2]: df.rolling(12).corr()
Out[2]:
Новое поведение:
In [85]: res = df.rolling(12).corr()
In [86]: res.tail()
Out[86]:
bar A B
foo bar
2016-04-07 B -0.132090 1.000000
2016-04-08 A 1.000000 -0.145775
B -0.145775 1.000000
2016-04-09 A 1.000000 0.119645
B 0.119645 1.000000
[5 rows x 2 columns]
Получение матрицы корреляций для поперечного сечения
In [87]: df.rolling(12).corr().loc['2016-04-07']
Out[87]:
bar A B
bar
A 1.00000 -0.13209
B -0.13209 1.00000
[2 rows x 2 columns]
HDFStore, где сравнение строк#
В предыдущих версиях большинство типов можно было сравнивать со строковым столбцом в HDFStore
обычно приводящее к недопустимому сравнению, возвращающему пустой фрейм результатов. Такие сравнения теперь будут вызывать
TypeError (GH 15492)
In [88]: df = pd.DataFrame({'unparsed_date': ['2014-01-01', '2014-01-01']})
In [89]: df.to_hdf('store.h5', key='key', format='table', data_columns=True)
In [90]: df.dtypes
Out[90]:
unparsed_date object
Length: 1, dtype: object
Предыдущее поведение:
In [4]: pd.read_hdf('store.h5', 'key', where='unparsed_date > ts')
File "", line 1
(unparsed_date > 1970-01-01 00:00:01.388552400)
^
SyntaxError: invalid token
Новое поведение:
In [18]: ts = pd.Timestamp('2014-01-01')
In [19]: pd.read_hdf('store.h5', 'key', where='unparsed_date > ts')
TypeError: Cannot compare 2014-01-01 00:00:00 of
type to string column
Index.intersection и внутреннее соединение теперь сохраняют порядок левого индекса#
Index.intersection() теперь сохраняет порядок вызова Index (слева) вместо другого Index (справа) (GH 15582). Это влияет на внутренние объединения, DataFrame.join() и merge()должны быть включены в старые категории. Значения, которые были в
удаленных категориях, будут установлены в NaN .align метод.
Index.intersectionIn [91]: left = pd.Index([2, 1, 0]) In [92]: left Out[92]: Index([2, 1, 0], dtype='int64') In [93]: right = pd.Index([1, 2, 3]) In [94]: right Out[94]: Index([1, 2, 3], dtype='int64')
Предыдущее поведение:
In [4]: left.intersection(right) Out[4]: Int64Index([1, 2], dtype='int64')
Новое поведение:
In [95]: left.intersection(right) Out[95]: Index([2, 1], dtype='int64')
DataFrame.joinиpd.mergeIn [96]: left = pd.DataFrame({'a': [20, 10, 0]}, index=[2, 1, 0]) In [97]: left Out[97]: a 2 20 1 10 0 0 [3 rows x 1 columns] In [98]: right = pd.DataFrame({'b': [100, 200, 300]}, index=[1, 2, 3]) In [99]: right Out[99]: b 1 100 2 200 3 300 [3 rows x 1 columns]
Предыдущее поведение:
In [4]: left.join(right, how='inner') Out[4]: a b 1 10 100 2 20 200
Новое поведение:
In [100]: left.join(right, how='inner') Out[100]: a b 2 20 200 1 10 100 [2 rows x 2 columns]
Сводная таблица всегда возвращает DataFrame#
Документация для pivot_table() утверждает, что DataFrame является всегда возвращена. Здесь исправлена ошибка,
которая позволяла возвращать Series при определенных обстоятельствах. (GH 4386)
In [101]: df = pd.DataFrame({'col1': [3, 4, 5],
.....: 'col2': ['C', 'D', 'E'],
.....: 'col3': [1, 3, 9]})
.....:
In [102]: df
Out[102]:
col1 col2 col3
0 3 C 1
1 4 D 3
2 5 E 9
[3 rows x 3 columns]
Предыдущее поведение:
In [2]: df.pivot_table('col1', index=['col3', 'col2'], aggfunc="sum")
Out[2]:
col3 col2
1 C 3
3 D 4
9 E 5
Name: col1, dtype: int64
Новое поведение:
In [103]: df.pivot_table('col1', index=['col3', 'col2'], aggfunc="sum")
Out[103]:
col1
col3 col2
1 C 3
3 D 4
9 E 5
[3 rows x 1 columns]
Другие изменения API#
numexprтеперь требуется версия >= 2.4.6, и она не будет использоваться вообще, если это требование не выполнено (GH 15213).CParserErrorбыл переименован вParserErrorвpd.read_csv()и будет удалено в будущем (GH 12665)SparseArray.cumsum()иSparseSeries.cumsum()теперь всегда будет возвращатьSparseArrayиSparseSeriesсоответственно (GH 12855)DataFrame.applymap()с пустымDataFrameвернёт копию пустогоDataFrameвместоSeries(GH 8222)Series.map()теперь учитывает значения по умолчанию подклассов словаря с__missing__метод, такой какcollections.Counter(GH 15999).locимеет совместимость с.ixдля принятия итераторов и NamedTuples (GH 15120)interpolate()иfillna()вызоветValueErrorеслиlimitаргумент ключевого слова не больше 0. (GH 9217)pd.read_csv()теперь будет выдаватьParserWarningвсякий раз, когда есть конфликтующие значения, предоставленныеdialectпараметр и пользователь (GH 14898)pd.read_csv()теперь вызоветValueErrorдля движка C, если символ кавычки больше одного байта (GH 11592)inplaceаргументы теперь требуют булево значение, иначеValueErrorвыбрасывается (GH 14189)pandas.api.types.is_datetime64_ns_dtypeтеперь будет сообщатьTrueна tz-aware dtype, аналогичноpandas.api.types.is_datetime64_any_dtypeDataFrame.asof()вернёт заполненный nullSeriesвместо скаляраNaNесли совпадение не найдено (GH 15118)Специальная поддержка для
copy.copy()иcopy.deepcopy()функции на объектах NDFrame (GH 15444)Series.sort_values()принимает список из одного логического значения для согласованности с поведениемDataFrame.sort_values()(GH 15604).merge()и.join()наcategoryстолбцы dtype теперь будут сохранять категориальный dtype, когда это возможно (GH 10409)SparseDataFrame.default_fill_valueбудет 0, ранее былоnanв возвращаемом значении изpd.get_dummies(..., sparse=True)(GH 15594)Поведение по умолчанию
Series.str.matchизменилось с извлечения групп на сопоставление с шаблоном. Поведение извлечения было устаревшим начиная с версии pandas 0.13.0 и может быть выполнено с помощьюSeries.str.extractметод (GH 5224). Как следствие,as_indexerключевое слово игнорируется (больше не нужно указывать новое поведение) и устарело.NaTтеперь будет корректно сообщатьFalseдля логических операций с датами и временем, таких какis_month_start(GH 15781)NaTтеперь будет корректно возвращатьnp.nanдляTimedeltaиPeriodаксессоры, такие какdaysиquarter(GH 15782)NaTтеперь возвращаетNaTдляtz_localizeиtz_convertметоды (GH 15830)DataFrameиPanelконструкторы с недопустимыми входными данными теперь будут вызыватьValueErrorвместоPandasError, если вызывается со скалярными входами и без осей (GH 15541)DataFrameиPanelконструкторы с недопустимыми входными данными теперь будут вызыватьValueErrorвместоpandas.core.common.PandasError, если вызывается со скалярными входами и не осями; ИсключениеPandasErrorтакже удален. (GH 15541)Исключение
pandas.core.common.AmbiguousIndexErrorудален, так как на него нет ссылок (GH 15541)
Реорганизация библиотеки: изменения конфиденциальности#
Изменена приватность модулей#
Некоторые ранее публичные модули расширений python/c/c++/cython были перемещены и/или переименованы. Все они удалены из публичного API. Кроме того, pandas.core, pandas.compat, и pandas.util модули верхнего уровня теперь считаются ПРИВАТНЫМИ.
Если указано, будет выдано предупреждение об устаревании при обращении к этим модулям. (GH 12588)
Предыдущее местоположение |
Новое местоположение |
Устаревший |
|---|---|---|
pandas.lib |
pandas._libs.lib |
X |
pandas.tslib |
pandas._libs.tslib |
X |
pandas.computation |
pandas.core.computation |
X |
pandas.msgpack |
pandas.io.msgpack |
|
pandas.index |
pandas._libs.index |
|
pandas.algos |
pandas._libs.algos |
|
pandas.hashtable |
pandas._libs.hashtable |
|
pandas.indexes |
pandas.core.indexes |
|
pandas.json |
pandas._libs.json / pandas.io.json |
X |
pandas.parser |
pandas._libs.parsers |
X |
pandas.formats |
pandas.io.formats |
|
pandas.sparse |
pandas.core.sparse |
|
pandas.tools |
pandas.core.reshape |
X |
pandas.types |
pandas.core.dtypes |
X |
pandas.io.sas.saslib |
pandas.io.sas._sas |
|
pandas._join |
pandas._libs.join |
|
pandas._hash |
pandas._libs.hashing |
|
pandas._period |
pandas._libs.period |
|
pandas._sparse |
pandas._libs.sparse |
|
pandas._testing |
pandas._libs.testing |
|
pandas._window |
pandas._libs.window |
Некоторые новые подпакеты созданы с публичной функциональностью, которая не представлена напрямую в пространстве имен верхнего уровня: pandas.errors, pandas.plotting и
pandas.testing (подробнее ниже). Вместе с pandas.api.types и
определенные функции в pandas.io и pandas.tseries подмодули,
теперь это публичные подпакеты.
Дополнительные изменения:
Функция
union_categoricals()теперь импортируется изpandas.api.types, ранее изpandas.types.concat(GH 15998)Импорт типа
pandas.tslib.NaTTypeустарел и может быть заменен использованиемtype(pandas.NaT)(GH 16146)Публичные функции в
pandas.tools.hashingустарели в этих местах, но теперь импортируются изpandas.util(GH 16223)Модули в
pandas.util:decorators,print_versions,doctools,validators,depr_moduleтеперь являются приватными. Только функции, представленные вpandas.utilсами являются публичными (GH 16223)
pandas.errors#
Мы добавляем стандартный публичный модуль для всех исключений и предупреждений pandas pandas.errors. (GH 14800). Ранее
эти исключения и предупреждения можно было импортировать из pandas.core.common или pandas.io.common. Эти исключения и предупреждения
будут удалены из *.common местоположения в будущем выпуске. (GH 15541)
Следующие элементы теперь являются частью этого API:
['DtypeWarning',
'EmptyDataError',
'OutOfBoundsDatetime',
'ParserError',
'ParserWarning',
'PerformanceWarning',
'UnsortedIndexError',
'UnsupportedFunctionCall']
pandas.testing#
Мы добавляем стандартный модуль, который предоставляет публичные тестовые функции в pandas.testing (GH 9895). Эти функции можно использовать при написании тестов для функциональности, использующей объекты pandas.
Следующие тестовые функции теперь являются частью этого API:
pandas.plotting#
Новый публичный pandas.plotting модуль был добавлен, содержащий функциональность построения графиков, которая ранее находилась либо в pandas.tools.plotting или в пространстве имен верхнего уровня. См. разделы об устаревании для получения дополнительной информации.
Другие изменения в разработке#
Устаревшие функции#
Устарело .ix#
The .ix indexer устарел, в пользу более строгого .iloc и .loc индексаторы. .ix предлагает много магии в определении того, что пользователь хочет сделать. Более конкретно, .ix может решить индексировать позиционно ИЛИ через метки, в зависимости от типа данных индекса. Это вызывало значительную путаницу у пользователей на протяжении многих лет. Полная документация по индексированию находится здесь. (GH 14218)
Рекомендуемые методы индексации:
.locесли вы хотите метка index.ilocесли вы хотите позиционно index.
Используя .ix теперь будет показывать DeprecationWarning со ссылкой на некоторые примеры преобразования кода здесь.
In [104]: df = pd.DataFrame({'A': [1, 2, 3],
.....: 'B': [4, 5, 6]},
.....: index=list('abc'))
.....:
In [105]: df
Out[105]:
A B
a 1 4
b 2 5
c 3 6
[3 rows x 2 columns]
Предыдущее поведение, когда вы хотите получить 0-й и 2-й элементы из индекса в столбце 'A'.
In [3]: df.ix[[0, 2], 'A']
Out[3]:
a 1
c 3
Name: A, dtype: int64
Используя .loc. Здесь мы выберем соответствующие индексы из индекса, затем используем метка индексация.
In [106]: df.loc[df.index[[0, 2]], 'A']
Out[106]:
a 1
c 3
Name: A, Length: 2, dtype: int64
Используя .iloc. Здесь мы получим расположение столбца 'A', затем используем позиционный индексация для выбора элементов.
In [107]: df.iloc[[0, 2], df.columns.get_loc('A')]
Out[107]:
a 1
c 3
Name: A, Length: 2, dtype: int64
Устаревание Panel#
Panel устарело и будет удалено в будущей версии. Рекомендуемый способ представления 3-D данных — MultiIndex на DataFrame через to_frame() или с пакет xarray. pandas предоставляет to_xarray() метод для автоматизации этого преобразования (GH 13563).
In [133]: import pandas._testing as tm
In [134]: p = tm.makePanel()
In [135]: p
Out[135]:
Преобразовать в DataFrame с MultiIndex
In [136]: p.to_frame()
Out[136]:
ItemA ItemB ItemC
major minor
2000-01-03 A 0.628776 -1.409432 0.209395
B 0.988138 -1.347533 -0.896581
C -0.938153 1.272395 -0.161137
D -0.223019 -0.591863 -1.051539
2000-01-04 A 0.186494 1.422986 -0.592886
B -0.072608 0.363565 1.104352
C -1.239072 -1.449567 0.889157
D 2.123692 -0.414505 -0.319561
2000-01-05 A 0.952478 -2.147855 -1.473116
B -0.550603 -0.014752 -0.431550
C 0.139683 -1.195524 0.288377
D 0.122273 -1.425795 -0.619993
[12 rows x 3 columns]
Преобразовать в DataArray xarray
In [137]: p.to_xarray()
Out[137]:
Устаревание groupby.agg() со словарём при переименовании#
The .groupby(..).agg(..), .rolling(..).agg(..), и .resample(..).agg(..) синтаксис может принимать переменное количество входных данных, включая скаляры, списки и словарь имен столбцов к скалярам или спискам. Это предоставляет полезный синтаксис для построения нескольких (потенциально различных) агрегаций.
Однако, .agg(..) может также принимает словарь, позволяющий 'переименовать' результирующие столбцы. Это сложный и запутанный синтаксис, а также не согласованный между Series и DataFrame. Мы устареваем эту функциональность 'переименования'.
Мы устареваем передачу словаря в сгруппированный/скользящий/передискретизированный
Series. Это позволялоrenameрезультирующая агрегация, но это имело совершенно другое значение, чем передача словаря в сгруппированныйDataFrame, который принимает столбцы для агрегации.Мы устареваем передачу словаря-словарей в сгруппированный/скользящий/передискретизированный
DataFrameаналогичным образом.
Это иллюстративный пример:
In [108]: df = pd.DataFrame({'A': [1, 1, 1, 2, 2],
.....: 'B': range(5),
.....: 'C': range(5)})
.....:
In [109]: df
Out[109]:
A B C
0 1 0 0
1 1 1 1
2 1 2 2
3 2 3 3
4 2 4 4
[5 rows x 3 columns]
Вот типичный полезный синтаксис для вычисления различных агрегаций для разных столбцов. Это
естественный и полезный синтаксис. Мы агрегируем из словаря в список, беря указанные
столбцы и применяя список функций. Это возвращает MultiIndex для столбцов (это не устарело).
In [110]: df.groupby('A').agg({'B': 'sum', 'C': 'min'})
Out[110]:
B C
A
1 3 0
2 7 3
[2 rows x 2 columns]
Вот пример первого устаревания, передача словаря в сгруппированный Series. Это
комбинация агрегации и переименования:
In [6]: df.groupby('A').B.agg({'foo': 'count'})
FutureWarning: using a dict on a Series for aggregation
is deprecated and will be removed in a future version
Out[6]:
foo
A
1 3
2 2
Вы можете выполнить ту же операцию более идиоматично:
In [111]: df.groupby('A').B.agg(['count']).rename(columns={'count': 'foo'})
Out[111]:
foo
A
1 3
2 2
[2 rows x 1 columns]
Вот пример второго устаревания, передача словаря-из-словарей в сгруппированный DataFrame:
In [23]: (df.groupby('A')
...: .agg({'B': {'foo': 'sum'}, 'C': {'bar': 'min'}})
...: )
FutureWarning: using a dict with renaming is deprecated and
will be removed in a future version
Out[23]:
B C
foo bar
A
1 3 0
2 7 3
Вы можете достичь почти того же результата с помощью:
In [112]: (df.groupby('A')
.....: .agg({'B': 'sum', 'C': 'min'})
.....: .rename(columns={'B': 'foo', 'C': 'bar'})
.....: )
.....:
Out[112]:
foo bar
A
1 3 0
2 7 3
[2 rows x 2 columns]
Устаревание .plotting#
The pandas.tools.plotting модуль устарел, в пользу верхнего уровня pandas.plotting модуль. Все публичные функции построения графиков теперь доступны
из pandas.plotting (GH 12548).
Кроме того, верхнеуровневый pandas.scatter_matrix и pandas.plot_params устарели.
Пользователи могут импортировать их из pandas.plotting также.
Предыдущий скрипт:
pd.tools.plotting.scatter_matrix(df)
pd.scatter_matrix(df)
Следует изменить на:
pd.plotting.scatter_matrix(df)
Другие устаревшие функции#
SparseArray.to_dense()устарелfillпараметр, так как этот параметр не учитывался (GH 14647)SparseSeries.to_dense()устарелsparse_onlyпараметр (GH 14647)Series.repeat()устарелrepsпараметр в пользуrepeats(GH 12662)The
Seriesконструкторе и.astypeметод устарел для приёма timestamp dtypes без частоты (например,np.datetime64) дляdtypeпараметр (GH 15524)Index.repeat()иMultiIndex.repeat()устарелиnпараметр в пользуrepeats(GH 12662)Categorical.searchsorted()иSeries.searchsorted()устарелиvпараметр в пользуvalue(GH 12662)TimedeltaIndex.searchsorted(),DatetimeIndex.searchsorted(), иPeriodIndex.searchsorted()устарелиkeyпараметр в пользуvalue(GH 12662)DataFrame.astype()устарелraise_on_errorпараметр в пользуerrors(GH 14878)Series.sortlevelиDataFrame.sortlevelустарели в пользуSeries.sort_indexиDataFrame.sort_index(GH 15099)импорт
concatизpandas.tools.mergeбыл объявлен устаревшим в пользу импорта изpandasпространство имён. Это должно затрагивать только явные импорты (GH 15358)Series/DataFrame/Panel.consolidate()был устаревшим как публичный метод. (GH 15483)The
as_indexerключевое словоSeries.str.match()был устаревшим (игнорируемое ключевое слово) (GH 15257).Следующие функции верхнего уровня pandas устарели и будут удалены в будущей версии (GH 13790, GH 15940)
pd.pnow(), заменено наPeriod.now()pd.Term, удален, так как он не применим к пользовательскому коду. Вместо этого используйте встроенные строковые выражения в условии where при поиске в HDFStorepd.Expr, удален, так как не применим к пользовательскому коду.pd.match(), удаляется.pd.groupby(), заменено использованием.groupby()метод непосредственно наSeries/DataFramepd.get_store(), заменено прямым вызовомpd.HDFStore(...)
is_any_int_dtype,is_floating_dtype, иis_sequenceустарели сpandas.api.types(GH 16042)
Удаление устаревших функций/изменений предыдущих версий#
The
pandas.rpyмодуль удален. Похожий функционал можно получить через rpy2 проект. См. Документация по интерфейсу с R для получения дополнительной информации.The
pandas.io.gaмодуль сgoogle-analyticsинтерфейс удалён (GH 11308). Аналогичную функциональность можно найти в Google2Pandas пакет.pd.to_datetimeиpd.to_timedeltaудалилиcoerceпараметр в пользуerrors(GH 13602)pandas.stats.fama_macbeth,pandas.stats.ols,pandas.stats.plmиpandas.stats.var, а также на верхнем уровнеpandas.fama_macbethиpandas.olsпроцедуры удалены. Аналогичную функциональность можно найти в statsmodels пакет. (GH 11898)The
TimeSeriesиSparseTimeSeriesклассы, псевдонимыSeriesиSparseSeries, удалены (GH 10890, GH 15098).Series.is_time_seriesудалено в пользуSeries.index.is_all_dates(GH 15098)Устаревший
irow,icol,igetиiget_valueметоды удалены в пользуilocиiatкак объяснено здесь (GH 10711).Устаревший
DataFrame.iterkv()был удалён в пользуDataFrame.iteritems()(GH 10711)The
Categoricalконструктор удалилnameпараметр (GH 10632)Categoricalпрекратил поддержкуNaNкатегории (GH 10748)The
take_lastпараметр был удалён изduplicated(),drop_duplicates(),nlargest(), иnsmallest()методы (GH 10236, GH 10792, GH 10920)Series,Index, иDataFrameудалилиsortиorderметоды (GH 10726)Предложения WHERE в
pytablesпринимаются только как строки и типы выражений, а не другие типы данных (GH 12027)DataFrameудалилcombineAddиcombineMultметоды в пользуaddиmulсоответственно (GH 10735)
Улучшения производительности#
Улучшена производительность
pd.wide_to_long()(GH 14779)Улучшена производительность
pd.factorize()путем освобождения GIL с помощьюobjectтип данных, когда выводится как строки (GH 14859, GH 16057)Улучшена производительность построения временных рядов с нерегулярным DatetimeIndex (или с
compat_x=True) (GH 15073).Улучшена производительность
groupby().cummin()иgroupby().cummax()(GH 15048, GH 15109, GH 15561, GH 15635)Улучшена производительность и уменьшено использование памяти при индексации с помощью
MultiIndex(GH 15245)При чтении буферного объекта в
read_sas()метод без указанного формата, строка пути к файлу выводится, а не объект буфера. (GH 14947)Улучшена производительность
.rank()для категориальных данных (GH 15498)Улучшенная производительность при использовании
.unstack()(GH 15503)Улучшена производительность слияния/объединения
categoryстолбцы (GH 10409)Улучшена производительность
drop_duplicates()наboolстолбцы (GH 12963)Улучшена производительность
pd.core.groupby.GroupBy.applyкогда применённая функция использовала.nameатрибут группового DataFrame (GH 15062).Улучшена производительность
ilocиндексирование списком или массивом (GH 15504).Улучшена производительность
Series.sort_index()с монотонным индексом (GH 15694)Улучшена производительность в
pd.read_csv()на некоторых платформах с буферизованным чтением (GH 16039)
Исправления ошибок#
Преобразование#
Ошибка в
Timestamp.replaceтеперь вызываетTypeErrorпри указании некорректных имен аргументов; ранее это вызывалоValueError(GH 15240)Ошибка в
Timestamp.replaceс совместимостью для передачи длинных целых чисел (GH 15030)Ошибка в
Timestampвозвращая атрибуты времени/даты на основе UTC, когда был предоставлен часовой пояс (GH 13303, GH 6538)Ошибка в
Timestampнеправильная локализация часовых поясов при создании (GH 11481, GH 15777)Ошибка в
TimedeltaIndexсложение, где переполнение допускалось без ошибки (GH 14816)Ошибка в
TimedeltaIndexвызовValueErrorпри булевом индексировании сloc(GH 14946)Ошибка в перехвате переполнения в
Timestamp+Timedelta/Offsetоперации (GH 15126)Ошибка в
DatetimeIndex.round()иTimestamp.round()точность с плавающей запятой при округлении на миллисекунды или меньше (GH 14440, GH 15578)Ошибка в
astype()гдеinfзначения были некорректно преобразованы в целые числа. Теперь выдает ошибку сastype()для Series и DataFrames (GH 14265)Ошибка в
DataFrame(..).apply(to_numeric)когда значения имеют тип decimal.Decimal. (GH 14827)Ошибка в
describe()при передаче массива numpy, который не содержит медиану, вpercentilesименованный аргумент (GH 14908)Очищено
PeriodIndexконструктора, включая более последовательное возбуждение исключений для чисел с плавающей точкой (GH 13277)Ошибка при использовании
__deepcopy__на пустых объектах NDFrame (GH 15370)Ошибка в
.replace()может привести к неверным типам данных. (GH 12747, GH 15765)Ошибка в
Series.replaceиDataFrame.replaceкоторый не работал с пустыми словарями замены (GH 15289)Ошибка в
Series.replaceкоторый заменил числовое значение строковым (GH 15743)Ошибка в
Indexсоздание сNaNэлементы и указанный целочисленный тип данных (GH 15187)Ошибка в
Seriesконструкция с datetimetz (GH 14928)Ошибка в
Series.dt.round()непоследовательное поведение наNaT‘s с разными аргументами (GH 14940)Ошибка в
Seriesконструктор, когда обаcopy=Trueиdtypeпредоставлены аргументы (GH 15125)Некорректный тип данных
Seriesвозвращался методами сравнения (например,lt,gt, …) против константы для пустогоDataFrame(GH 15077)Ошибка в
Series.ffill()со смешанными типами данных, содержащими даты с учетом часового пояса. (GH 14956)Ошибка в
DataFrame.fillna()где аргументdowncastигнорировалось, когда значение fillna было типаdict(GH 15277)Ошибка в
.asfreq(), где частота не была установлена для пустогоSeries(GH 14320)Ошибка в
DataFrameконструкция с null и датами в спискообразном (GH 15869)Ошибка в
DataFrame.fillna()с датами с учетом часового пояса (GH 15855)Ошибка в
is_string_dtype,is_timedelta64_ns_dtype, иis_string_like_dtypeв котором возникала ошибка, когдаNoneбыл передан (GH 15941)Ошибка в типе возвращаемого значения
pd.uniqueнаCategorical, который возвращал ndarray, а неCategorical(GH 15903)Ошибка в
Index.to_series()где индекс не был скопирован (и последующее изменение изменило бы оригинал), (GH 15949)Ошибка при индексировании с частичным строковым индексированием с DataFrame длины 1 (GH 16071)
Ошибка в
Seriesсоздание, при котором передача недопустимого dtype не вызывала ошибку. (GH 15520)
Индексирование#
Ошибка в
Indexоперации возведения в степень с обратными операндами (GH 14973)Ошибка в
DataFrame.sort_values()при сортировке по нескольким столбцам, где один столбец имеет типint64и содержитNaT(GH 14922)Ошибка в
DataFrame.reindex()в которомmethodигнорировалось при передачеcolumns(GH 14992)Ошибка в
DataFrame.locпри индексацииMultiIndexсSeriesиндексатор (GH 14730, GH 15424)Ошибка в
DataFrame.locпри индексацииMultiIndexс массивом numpy (GH 15434)Ошибка в
Series.asofкоторая возникала, если ряд содержал всеnp.nan(GH 15713)Ошибка в
.atпри выборе из столбца с информацией о часовом поясе (GH 15822)Ошибка в
Series.where()иDataFrame.where()где условные выражения в виде массивов отклонялись (GH 15414)Ошибка в
Series.where()где данные с учетом часового пояса были преобразованы в представление с плавающей запятой (GH 15701)Ошибка в
.locчто не вернёт правильный dtype для скалярного доступа к DataFrame (GH 11617)Ошибка в форматировании вывода
MultiIndexкогда имена являются целыми числами (GH 12223, GH 15262)Ошибка в
Categorical.searchsorted()где использовался алфавитный порядок вместо предоставленного категориального (GH 14522)Ошибка в
Series.ilocгдеCategoricalобъект для ввода индексов в виде списка был возвращен, гдеSeriesожидалось. (GH 14580)Ошибка в
DataFrame.isinсравнение дат/времени с пустым фреймом (GH 15473)Ошибка в
.reset_index()когда всеNaNуровеньMultiIndexзавершится неудачей (GH 6322)Ошибка в
.reset_index()при вызове ошибки для имени индекса, уже присутствующего вMultiIndexстолбцы (GH 16120)Ошибка при создании
MultiIndexс кортежами без передачи списка имен; теперь это будет вызывать ошибкуValueError(GH 15110)Ошибка в HTML отображении с
MultiIndexи усечение (GH 14882)Ошибка в отображении
.info()где квалификатор (+) всегда отображался бы сMultiIndexкоторый содержит только нестроковые значения (GH 15245)Ошибка в
pd.concat()где именаMultiIndexрезультирующегоDataFrameне обрабатываются корректно, когдаNoneпредставлено в названияхMultiIndexвводаDataFrame(GH 15787)Ошибка в
DataFrame.sort_index()иSeries.sort_index()гдеna_positionне работает сMultiIndex(GH 14784, GH 16604)Ошибка в
pd.concat()при объединении объектов сCategoricalIndex(GH 16111)Ошибка при индексации со скаляром и
CategoricalIndex(GH 16123)
Ввод-вывод#
Ошибка в
pd.to_numeric()в котором элементы с плавающей точкой и беззнаковые целые числа неправильно приводились (GH 14941, GH 15005)Ошибка в
pd.read_fwf()где параметр skiprows не учитывался при определении ширины столбцов (GH 11256)Ошибка в
pd.read_csv()в которомdialectпараметр не проверялся перед обработкой (GH 14898)Ошибка в
pd.read_csv()в котором отсутствующие данные неправильно обрабатывались сusecols(GH 6710)Ошибка в
pd.read_csv()в котором файл, содержащий строку со многими столбцами, за которой следуют строки с меньшим количеством столбцов, вызывал сбой (GH 14125)Ошибка в
pd.read_csv()для движка C, гдеusecolsиндексировались некорректно сparse_dates(GH 14792)Ошибка в
pd.read_csv()сparse_datesкогда указаны многострочные заголовки (GH 15376)Ошибка в
pd.read_csv()сfloat_precision='round_trip'что вызывало ошибку сегментации при разборе текстовой записи (GH 15140)Ошибка в
pd.read_csv()когда был указан индекс и никакие значения не были указаны как нулевые значения (GH 15835)Ошибка в
pd.read_csv()в котором некоторые недопустимые файловые объекты вызывали сбой интерпретатора Python (GH 15337)Ошибка в
pd.read_csv()в котором недопустимые значения дляnrowsиchunksizeбыли разрешены (GH 15767)Ошибка в
pd.read_csv()для движка Python, в котором выводились бесполезные сообщения об ошибках при возникновении ошибок парсинга (GH 15910)Ошибка в
pd.read_csv()в которомskipfooterпараметр не проходил должную проверку (GH 15925)Ошибка в
pd.to_csv()в котором происходило числовое переполнение при записи временного индекса (GH 15982)Ошибка в
pd.util.hashing.hash_pandas_object()в котором хеширование категориальных данных зависело от порядка категорий, а не только от их значений. (GH 15143)Ошибка в
.to_json()гдеlines=Trueи содержимое (ключи или значения) содержит экранированные символы (GH 15096)Ошибка в
.to_json()вызывая расширение однобайтовых ASCII-символов до четырехбайтовых Unicode (GH 15344)Ошибка в
.to_json()для движка C, где переполнение не обрабатывалось корректно для случая, когда frac нечетное и diff равно точно 0.5 (GH 15716, GH 15864)Ошибка в
pd.read_json()для Python 2, гдеlines=Trueи содержимое содержит не-ASCII символы Unicode (GH 15132)Ошибка в
pd.read_msgpack()в которомSeriesкатегориальные переменные обрабатывались некорректно (GH 14901)Ошибка в
pd.read_msgpack()который не позволял загрузить датафрейм с индексом типаCategoricalIndex(GH 15487)Ошибка в
pd.read_msgpack()при десериализацииCategoricalIndex(GH 15487)Ошибка в
DataFrame.to_records()при преобразованииDatetimeIndexс часовым поясом (GH 13937)Ошибка в
DataFrame.to_records()который завершался сбоем при наличии символов Unicode в именах столбцов (GH 11879)Ошибка в
.to_sql()при записи DataFrame с числовыми именами индексов (GH 15404).Ошибка в
DataFrame.to_html()сindex=Falseиmax_rowsвызов исключения вIndexError(GH 14998)Ошибка в
pd.read_hdf()передачаTimestampвwhereпараметр с недатовым столбцом (GH 15492)Ошибка в
DataFrame.to_stata()иStataWriterчто приводит к созданию некорректно отформатированных файлов для некоторых локалей (GH 13856)Ошибка в
StataReaderиStataWriterкоторый допускает недопустимые кодировки (GH 15723)Ошибка в
Seriesrepr не показывает длину, когда вывод был усечен (GH 15962).
Построение графиков#
Ошибка в
DataFrame.histгдеplt.tight_layoutвызвалAttributeError(используйтеmatplotlib >= 2.0.1) (GH 9351)Ошибка в
DataFrame.boxplotгдеfontsizeоперации между объектами несовместимых типов данных, результат будет базовымGH 15108)Ошибка в конвертерах даты и времени, которые pandas регистрирует в matplotlib, не обрабатывающих многомерные данные (GH 16026)
Ошибка в
pd.scatter_matrix()может принимать либоcolorилиc, но не оба (GH 14855)
GroupBy/resample/rolling#
Ошибка в
.groupby(..).resample()при передачеon=kwarg. (GH 15021)Правильно установить
__name__и__qualname__дляGroupby.*функции (GH 14620)Ошибка в
GroupBy.get_group()неудача с категориальным группировщиком (GH 15155)Ошибка в
.groupby(...).rolling(...)когдаonуказан и используетсяDatetimeIndex(GH 15130, GH 13966)Ошибка в операциях groupby с
timedelta64при передачеnumeric_only=False(GH 5724)Ошибка в
groupby.apply()приведениеobjectdtypes в числовые типы, когда не все значения были числовыми (GH 14423, GH 15421, и parse_dates включён для столбца, попытаться определить формат даты и времени для ускорения обработки.)Ошибка в
resample, где нестроковыйloffsetаргумент не применялся при ресемплинге временного ряда (GH 13218)Ошибка в
DataFrame.groupby().describe()при группировке поIndexсодержащий кортежи (GH 14848)Ошибка в
groupby().nunique()с группировщиком типа datetime, где подсчеты бинов были некорректны (GH 13453)Ошибка в
groupby.transform()который бы приводил результирующие типы данных обратно к исходным (GH 10972, GH 11444)Ошибка в
groupby.agg()неправильная локализация часового пояса наdatetime(GH 15426, GH 10668, GH 13046)Ошибка в
.rolling/expanding()функции, гдеcount()не подсчитывалnp.Inf, ни обработкаobjectтипы данных (GH 12541)Ошибка в
.rolling()гдеpd.Timedeltaилиdatetime.timedeltaне принимался какwindowаргумент (GH 15440)Ошибка в
Rolling.quantileфункция, вызывавшая ошибку сегментации при вызове с квантилем вне диапазона [0, 1] (GH 15463)Ошибка в
DataFrame.resample().median()если присутствуют повторяющиеся имена столбцов (GH 14233)
Разреженный#
Ошибка в
SparseSeries.reindexна одном уровне со списком длины 1 (GH 15447)Ошибка в форматировании repr для
SparseDataFrameпосле установки значения на (копии) одного из его рядов (GH 15488)Ошибка в
SparseDataFrameконструкция со списками без приведения к dtype (GH 15682)Ошибка в индексации разреженных массивов, при которой индексы не проверялись (GH 15863)
Изменение формы#
Ошибка в
pd.merge_asof()гдеleft_indexилиright_indexвызывал сбой, когда несколькоbyбыл указан (GH 15676)Ошибка в
pd.merge_asof()гдеleft_index/right_indexвместе вызвали ошибку, когдаtoleranceбыл указан (GH 15135)Ошибка в
DataFrame.pivot_table()гдеdropna=Trueне удалял все-NaN столбцы, когда столбец былcategoryтип данных (GH 15193)Ошибка в
pd.melt()где передача кортежа значения дляvalue_varsвызвалTypeError(GH 15348)Ошибка в
pd.pivot_table()где ошибка не возникала, когда аргумент values не был в столбцах (GH 14938)Ошибка в
pd.concat()при конкатенации с пустым датафреймом сjoin='inner'неправильно обрабатывался (GH 15328)Ошибка с
sort=TrueвDataFrame.joinиpd.mergeпри объединении по индексам (GH 15582)Ошибка в
DataFrame.nsmallestиDataFrame.nlargestгде одинаковые значения приводили к дублированию строк (GH 15297)Ошибка в
pandas.pivot_table()некорректное возбуждениеUnicodeErrorпри передаче юникодного ввода дляmarginsключевое слово (GH 13292)
Числовой#
Ошибка в
.rank()который некорректно ранжирует упорядоченные категории (GH 15420)Ошибка в
.corr()и.cov()где столбец и индекс были одним и тем же объектом (GH 14617)Ошибка в
.mode()гдеmodeне возвращался, если было только одно значение (GH 15714)Ошибка в
pd.cut()с одним бином на массиве, состоящем только из нулей (GH 15428)Ошибка в
pd.qcut()с одним квантилем и массивом с идентичными значениями (GH 15431)Ошибка в
pandas.tools.utils.cartesian_product()при большом объеме входных данных может произойти переполнение в Windows (GH 15265)Ошибка в
.eval()что приводило к сбою многострочных вычислений, когда локальные переменные не находились на первой строке (GH 15342)
Другие#
Совместимость с SciPy 0.19.0 для тестирования на
.interpolate()(GH 15662)Совместимость для 32-битных платформ для
.qcut/cut; интервалы теперь будутint64тип данных (GH 14866)Ошибка во взаимодействиях с
QtкогдаQtApplicationуже существует (GH 14372)Избегайте использования
np.finfo()во времяimport pandasудалено для устранения взаимоблокировки из-за неправильного использования GIL Python (GH 14641)
Участники#
Всего 204 человека внесли патчи в этот релиз. Люди со знаком «+» рядом с именами внесли патч впервые.
Adam J. Stewart +
Adrian +
Ajay Saxena
Akash Tandon +
Albert Villanova del Moral +
Алексей Билоур +
Alexis Mignon +
Amol Kahat +
Андреас Винклер +
Andrew Kittredge +
Anthonios Partheniou
Arco Bast +
Ashish Singal +
Baurzhan Muftakhidinov +
Бен Кандел
Ben Thayer +
Ben Welsh +
Билл Чемберс +
Brandon M. Burroughs
Brian +
Brian McFee +
Carlos Souza +
Chris
Chris Ham
Chris Warth
Кристоф Голке
Christoph Paulik +
Christopher C. Aycock
Clemens Brunner +
Д.С. МакНил +
DaanVanHauwermeiren +
Daniel Himmelstein
Dave Willmer
David Cook +
David Gwynne +
David Hoffman +
David Krych
Diego Fernandez +
Dimitris Spathis +
Dmitry L +
Dody Suria Wijaya +
Dominik Stanczak +
Др-Ирв
Dr. Irv +
Эллиотт Сейлс де Андраде +
Эннемозер Кристоф +
Francesc Alted +
Fumito Hamamura +
Giacomo Ferroni
Graham R. Jeffries +
Greg Williams +
Guilherme Beltramini +
Гильерме Саморра +
Хао Ву +
Harshit Patni +
Ilya V. Schurov +
Иван Вальес Перес
Jackie Leng +
Jaehoon Hwang +
James Draper +
James Goppert +
James McBride +
Джеймс Сантуччи +
Ян Шульц
Jeff Carey
Jeff Reback
JennaVergeynst +
Джим +
Jim Crist
Joe Jevnik
Joel Nothman +
John +
Джон Такер +
John W. O’Brien
John Zwinck
Jon M. Mease
Jon Mease
Jonathan Whitmore +
Jonathan de Bruin +
Joost Kranendonk +
Joris Van den Bossche
Джошуа Брадт +
Julian Santander
Julien Marrec +
Jun Kim +
Justin Solinsky +
Kacawi +
Kamal Kamalaldin +
Керби Шедден
Kernc
Keshav Ramaswamy
Кевин Шеппард
Kyle Kelley
Ларри Рен
Leon Yin +
Line Pedersen +
Lorenzo Cestaro +
Luca Scarabello
Lukasz +
Mahmoud Lababidi
Mark Mandel +
Мэтт Рёшке
Мэтью Бретт
Matthew Roeschke +
Matti Picus
Maximilian Roos
Michael Charlton +
Michael Felt
Michael Lamparski +
Michiel Stock +
Mikolaj Chwalisz +
Min RK
Miroslav Šedivý +
Mykola Golubyev
Nate Yoder
Nathalie Rud +
Николас Вер Хейлен
Nick Chmura +
Nolan Nichols +
Pankaj Pandey +
Pawel Kordek
Pete Huang +
Питер +
Peter Csizsek +
Petio Petrov +
Phil Ruffwind +
Пьетро Баттистон
Piotr Chromiec
Prasanjit Prakash +
Rob Forgione +
Роберт Брэдшоу
Robin +
Родольфо Фернандес
Roger Thomas
Rouz Azari +
Сахил Дуа
Sam Foo +
Sami Salonen +
Sarah Bird +
Sarma Tangirala +
Скотт Сандерсон
Sebastian Bank
Sebastian Gsänger +
Шон Хайде
Shyam Saladi +
Sinhrks
Стивен Раух +
Sébastien de Menten +
Tara Adiseshan
Thiago Serafim
Thoralf Gutierrez +
Thrasibule +
Tobias Gustafsson +
Tom Augspurger
Tong SHEN +
Tong Shen +
TrigonaMinima +
Уве +
Wes Turner
Wiktor Tomczak +
WillAyd
Yaroslav Halchenko
Yimeng Zhang +
abaldenko +
adrian-stepien +
alexandercbooth +
atbd +
bastewart +
bmagnusson +
carlosdanielcsantos +
chaimdemulder +
chris-b1
dickreuter +
discort +
dr-leo +
dubourg
dwkenefick +
GH 16493
gfyoung
goldenbull +
hesham.shabana@hotmail.com
jojomdt +
linebp +
manu +
manuels +
mattip +
maxalbert +
mcocdawc +
nuffe +
paul-mannino
pbreach +
sakkemo +
scls19fr
sinhrks
stijnvanhoey +
the-nose-knows +
themrmax +
tomrod +
tzinckgraf
wandersoncferreira
watercrossing +
wcwagner
xgdgsc +
yui-knk