Визуализация диаграмм#
Примечание
Примеры ниже предполагают, что вы используете Jupyter.
В этом разделе демонстрируется визуализация с помощью построения графиков. Для получения информации о визуализации табличных данных см. раздел Визуализация таблиц.
Мы используем стандартное соглашение для ссылки на API matplotlib:
In [1]: import matplotlib.pyplot as plt
In [2]: plt.close("all")
Мы предоставляем основы в pandas для легкого создания приличных графиков. См. страница экосистемы для библиотек визуализации, выходящих за рамки основ, описанных здесь.
Примечание
Все вызовы np.random инициализируются с 123456.
Базовое построение графиков: plot#
Мы продемонстрируем основы, см. cookbook для некоторых продвинутых стратегий.
The plot метод на Series и DataFrame — это просто простая обёртка вокруг
plt.plot():
In [3]: np.random.seed(123456)
In [4]: ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
In [5]: ts = ts.cumsum()
In [6]: ts.plot();
Если индекс состоит из дат, он вызывает gcf().autofmt_xdate()
попытаться красиво отформатировать ось x, как указано выше.
На DataFrame, plot() удобно для построения графиков всех столбцов с метками:
In [7]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
In [8]: df = df.cumsum()
In [9]: plt.figure();
In [10]: df.plot();
Вы можете построить график одного столбца против другого, используя x и y ключевые слова в
plot():
In [11]: df3 = pd.DataFrame(np.random.randn(1000, 2), columns=["B", "C"]).cumsum()
In [12]: df3["A"] = pd.Series(list(range(len(df))))
In [13]: df3.plot(x="A", y="B");
Примечание
Дополнительные параметры форматирования и стилизации см. в форматирование ниже.
Другие графики#
Методы построения графиков позволяют использовать несколько стилей графиков, отличных от
графика по умолчанию. Эти методы могут быть предоставлены как kind
ключевой аргумент для plot(), и включает:
‘hist’ для гистограммы
‘box’ для boxplot
‘area’ для площадных графиков
'scatter' для точечных графиков
‘hexbin’ для шестиугольных бинарных графиков
'pie' для круговых диаграмм
Например, столбчатая диаграмма может быть создана следующим образом:
In [14]: plt.figure();
In [15]: df.iloc[5].plot(kind="bar");
Вы также можете создавать эти другие графики, используя методы DataFrame.plot. вместо предоставления kind ключевой аргумент. Это упрощает обнаружение методов построения графиков и конкретных аргументов, которые они используют:
In [16]: df = pd.DataFrame()
In [17]: df.plot.<TAB> # noqa: E225, E999
df.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter
df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
В дополнение к этим kind s, существуют DataFrame.hist(),
и DataFrame.boxplot() методы, которые используют отдельный интерфейс.
Наконец, есть несколько функции построения графиков в pandas.plotting
который принимает Series или DataFrame в качестве аргумента. К ним
относятся:
Графики также могут быть украшены полосы ошибок или tables.
Столбчатые диаграммы#
Для помеченных данных, не являющихся временными рядами, вы можете создать столбчатую диаграмму:
In [18]: plt.figure();
In [19]: df.iloc[5].plot.bar();
In [20]: plt.axhline(0, color="k");
Вызов метода DataFrame plot.bar() метод создаёт многоуровневую столбчатую диаграмму:
In [21]: df2 = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"])
In [22]: df2.plot.bar();
Чтобы создать сложенную столбчатую диаграмму, передайте stacked=True:
In [23]: df2.plot.bar(stacked=True);
Для получения горизонтальных столбчатых диаграмм используйте barh method:
In [24]: df2.plot.barh(stacked=True);
Гистограммы#
Гистограммы можно построить с помощью DataFrame.plot.hist() и Series.plot.hist() методы.
In [25]: df4 = pd.DataFrame(
....: {
....: "a": np.random.randn(1000) + 1,
....: "b": np.random.randn(1000),
....: "c": np.random.randn(1000) - 1,
....: },
....: columns=["a", "b", "c"],
....: )
....:
In [26]: plt.figure();
In [27]: df4.plot.hist(alpha=0.5);
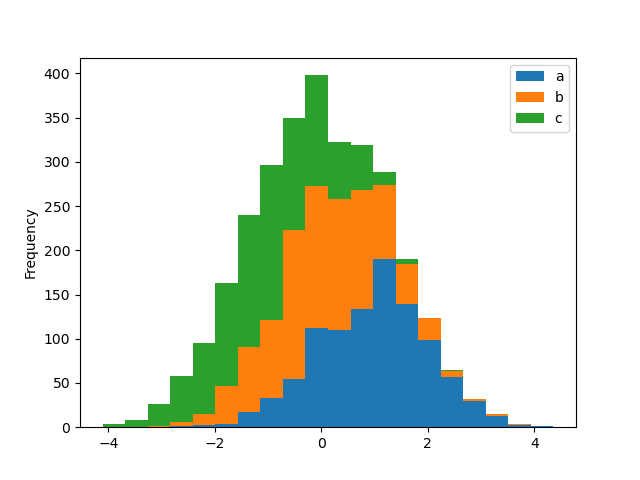
Гистограмма может быть сложена с использованием stacked=True. Размер бина может быть изменён
с помощью bins ключевое слово.
In [28]: plt.figure();
In [29]: df4.plot.hist(stacked=True, bins=20);
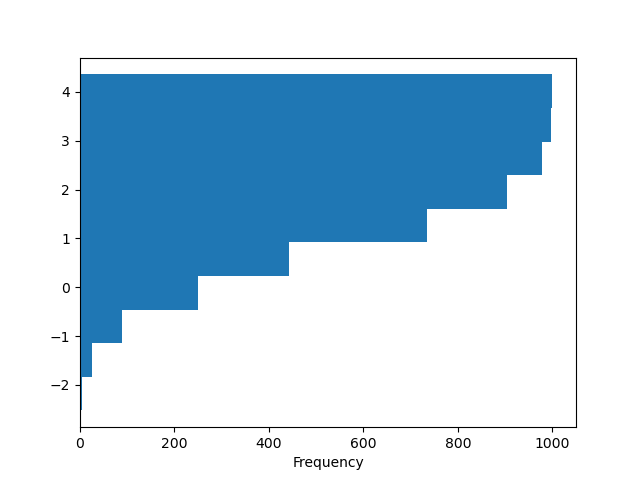
Вы можете передать другие ключевые слова, поддерживаемые matplotlib hist. Например,
горизонтальные и кумулятивные гистограммы можно нарисовать с помощью
orientation='horizontal' и cumulative=True.
In [30]: plt.figure();
In [31]: df4["a"].plot.hist(orientation="horizontal", cumulative=True);
См. hist метод и
документация matplotlib hist подробнее.
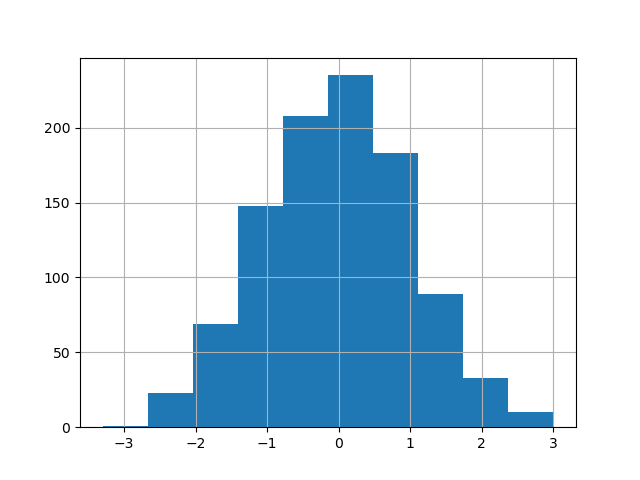
Существующий интерфейс DataFrame.hist для построения гистограммы всё ещё можно использовать.
In [32]: plt.figure();
In [33]: df["A"].diff().hist();
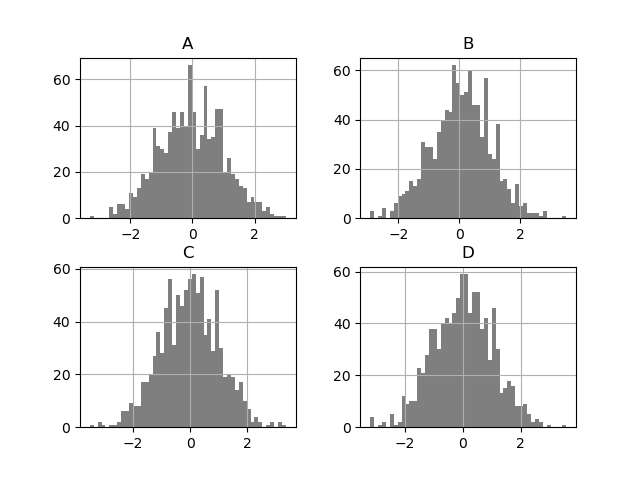
DataFrame.hist() строит гистограммы столбцов на нескольких подграфиках:
In [34]: plt.figure();
In [35]: df.diff().hist(color="k", alpha=0.5, bins=50);
The by ключевое слово может быть указано для построения сгруппированных гистограмм:
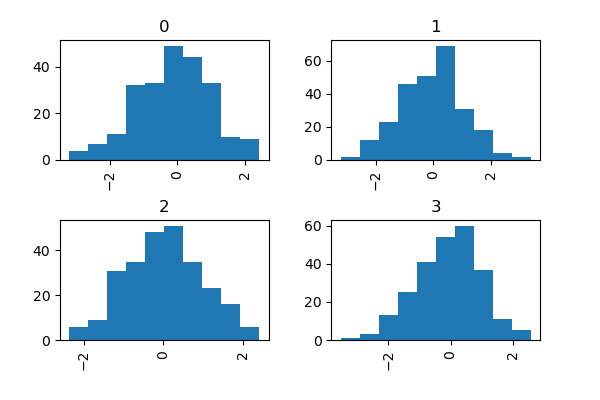
In [36]: data = pd.Series(np.random.randn(1000))
In [37]: data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4));
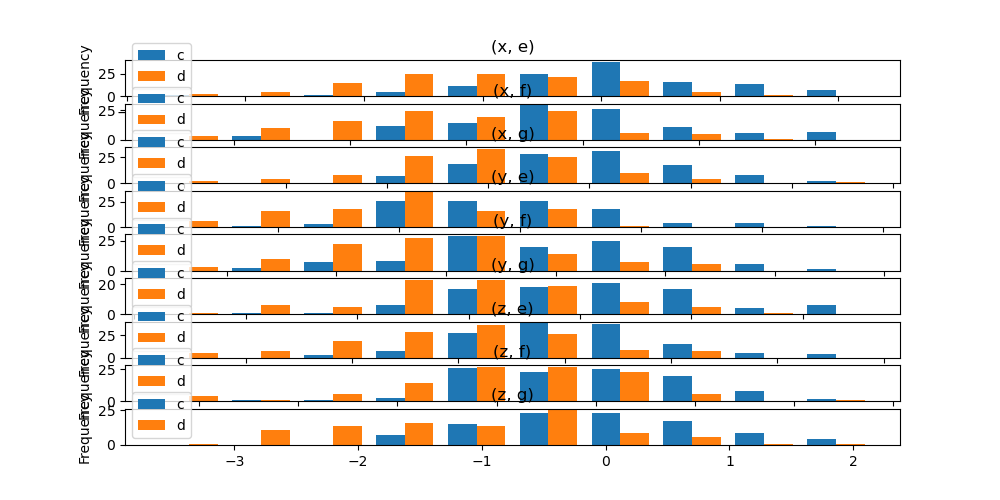
Кроме того, by ключевое слово также может быть указано в DataFrame.plot.hist().
Изменено в версии 1.4.0.
In [38]: data = pd.DataFrame(
....: {
....: "a": np.random.choice(["x", "y", "z"], 1000),
....: "b": np.random.choice(["e", "f", "g"], 1000),
....: "c": np.random.randn(1000),
....: "d": np.random.randn(1000) - 1,
....: },
....: )
....:
In [39]: data.plot.hist(by=["a", "b"], figsize=(10, 5));
Диаграммы размаха (Box plots)#
Boxplot можно построить, вызвав Series.plot.box() и DataFrame.plot.box(),
или DataFrame.boxplot() для визуализации распределения значений в каждом столбце.
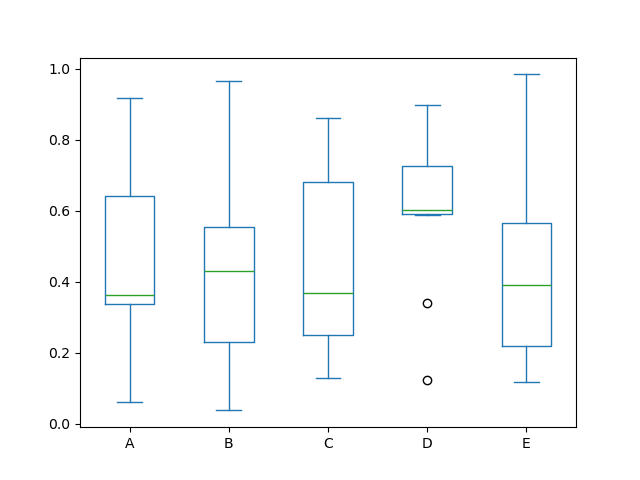
Например, вот boxplot, представляющий пять испытаний по 10 наблюдений равномерной случайной величины на [0,1).
In [40]: df = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"])
In [41]: df.plot.box();
Boxplot может быть раскрашен путем передачи color ключевое слово. Вы можете передать dict
чьи ключи являются boxes, whiskers, medians и caps.
Если некоторые ключи отсутствуют в dict, по умолчанию используются цвета
для соответствующих художников. Также, boxplot имеет sym ключевой параметр для указания стиля выбросов.
Когда вы передаете аргументы других типов через color ключевое слово, оно будет напрямую
передано в matplotlib для всех boxes, whiskers, medians и caps
раскрашивание.
Цвета применяются к каждому рисуемому блоку. Если вам нужно более сложное окрашивание, вы можете получить каждого нарисованного художника, передав return_type.
In [42]: color = {
....: "boxes": "DarkGreen",
....: "whiskers": "DarkOrange",
....: "medians": "DarkBlue",
....: "caps": "Gray",
....: }
....:
In [43]: df.plot.box(color=color, sym="r+");

Также можно передать другие ключевые слова, поддерживаемые matplotlib boxplot.
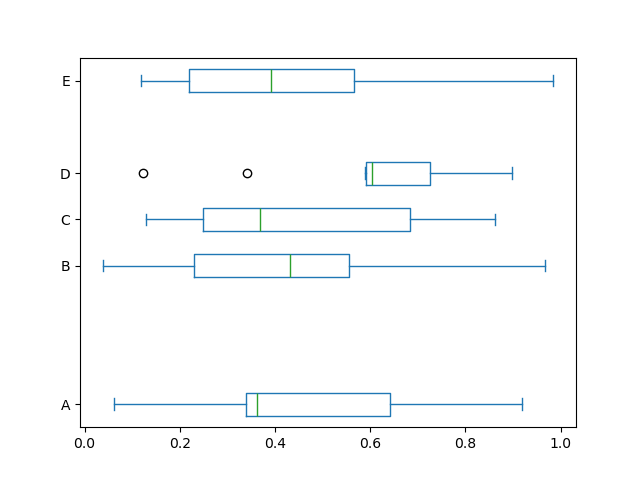
Например, горизонтальная и кастомно-позиционированная диаграмма размаха может быть нарисована с помощью
vert=False и positions ключевые слова.
In [44]: df.plot.box(vert=False, positions=[1, 4, 5, 6, 8]);
См. boxplot метод и
документация matplotlib boxplot подробнее.
Существующий интерфейс DataFrame.boxplot для построения boxplot всё ещё можно использовать.
In [45]: df = pd.DataFrame(np.random.rand(10, 5))
In [46]: plt.figure();
In [47]: bp = df.boxplot()
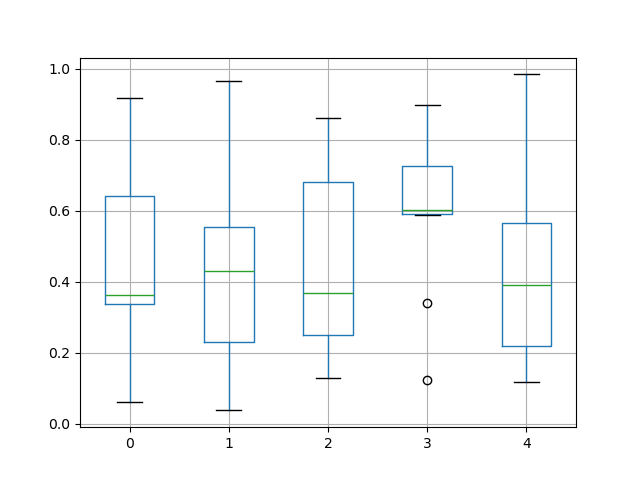
Вы можете создать стратифицированный boxplot с помощью by ключевой аргумент для создания группировок. Например,
In [48]: df = pd.DataFrame(np.random.rand(10, 2), columns=["Col1", "Col2"])
In [49]: df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"])
In [50]: plt.figure();
In [51]: bp = df.boxplot(by="X")
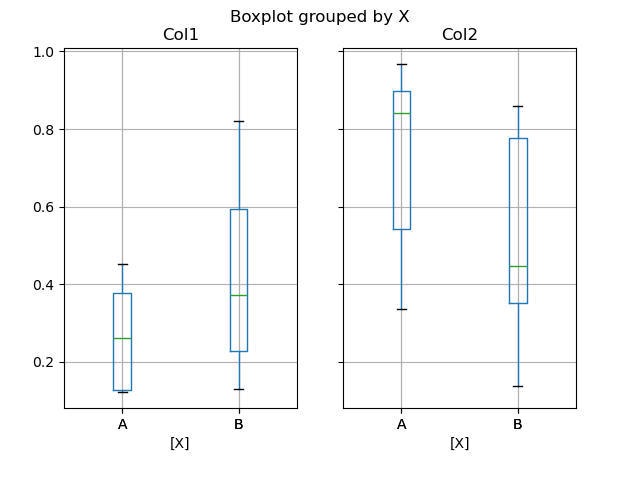
Вы также можете передать подмножество столбцов для построения графика, а также группировать по нескольким столбцам:
In [52]: df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"])
In [53]: df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"])
In [54]: df["Y"] = pd.Series(["A", "B", "A", "B", "A", "B", "A", "B", "A", "B"])
In [55]: plt.figure();
In [56]: bp = df.boxplot(column=["Col1", "Col2"], by=["X", "Y"])
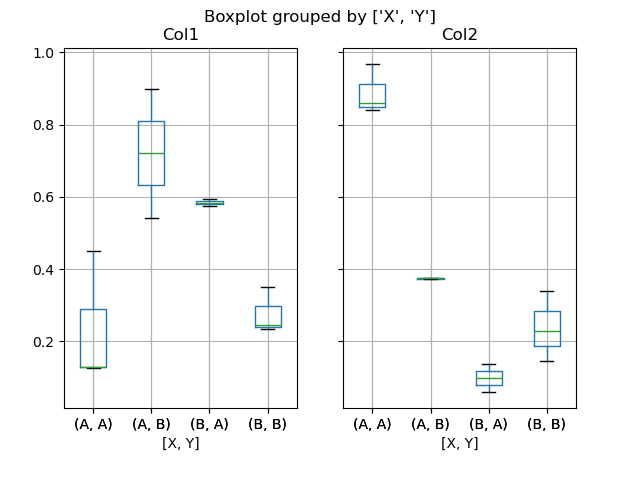
Вы также можете создавать группировки с помощью DataFrame.plot.box(), например:
Изменено в версии 1.4.0.
In [57]: df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"])
In [58]: df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"])
In [59]: plt.figure();
In [60]: bp = df.plot.box(column=["Col1", "Col2"], by="X")
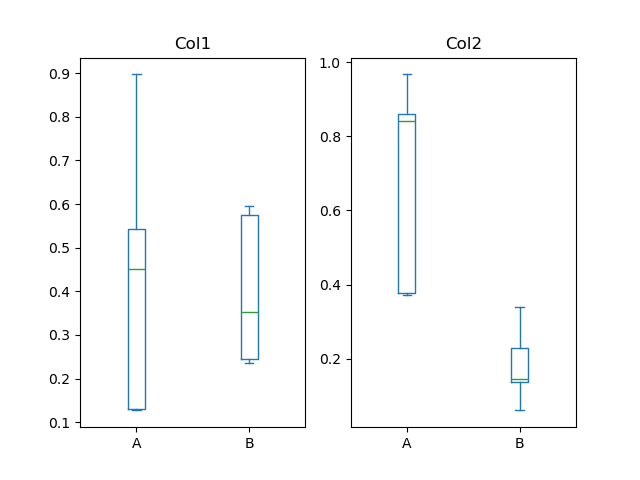
В boxplot, тип возвращаемого значения может контролироваться с помощью return_type, ключевое слово. Допустимые варианты: {"axes", "dict", "both", None}.
Фасетирование, созданное DataFrame.boxplot с by
ключевое слово также повлияет на тип вывода:
|
Фасетный |
Тип вывода |
|---|---|---|
|
Нет |
оси |
|
Да |
2-D ndarray осей |
|
Нет |
оси |
|
Да |
Серия осей |
|
Нет |
словарь художников |
|
Да |
Серия словарей художников |
|
Нет |
namedtuple |
|
Да |
Series из namedtuples |
Groupby.boxplot всегда возвращает Series of return_type.
In [61]: np.random.seed(1234)
In [62]: df_box = pd.DataFrame(np.random.randn(50, 2))
In [63]: df_box["g"] = np.random.choice(["A", "B"], size=50)
In [64]: df_box.loc[df_box["g"] == "B", 1] += 3
In [65]: bp = df_box.boxplot(by="g")
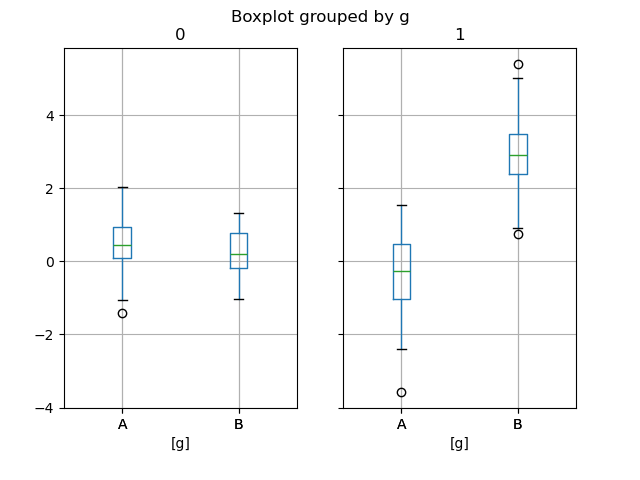
Подграфики выше разделены сначала по числовым столбцам, затем по значению g столбец. Ниже подграфики сначала разделяются по значению gзатем по числовым столбцам.
In [66]: bp = df_box.groupby("g").boxplot()
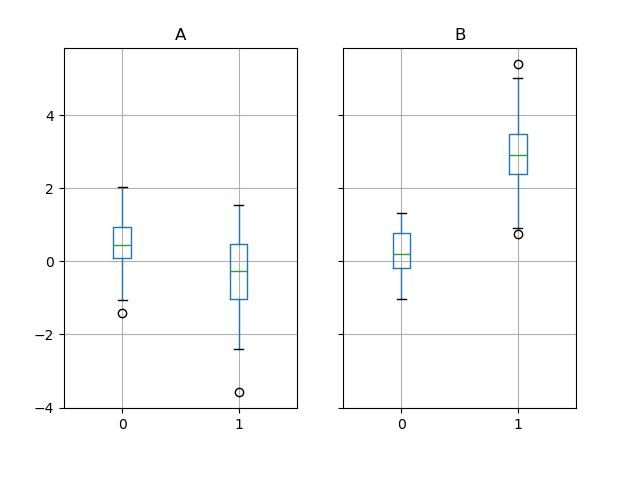
Диаграмма с областями#
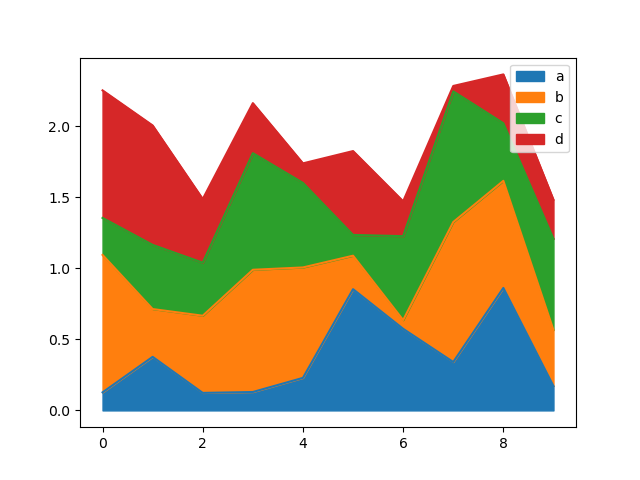
Вы можете создавать площадные графики с помощью Series.plot.area() и DataFrame.plot.area().
Диаграммы площадей по умолчанию накладываются. Чтобы создать наложенную диаграмму площадей, каждый столбец должен содержать либо все положительные, либо все отрицательные значения.
Когда входные данные содержат NaN, он будет автоматически заполнен 0. Если вы хотите удалить или заполнить другими значениями, используйте dataframe.dropna() или dataframe.fillna() перед вызовом plot.
In [67]: df = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"])
In [68]: df.plot.area();
Чтобы создать неуложенный график, передайте stacked=False. Значение альфа установлено на 0.5, если не указано иное:
In [69]: df.plot.area(stacked=False);
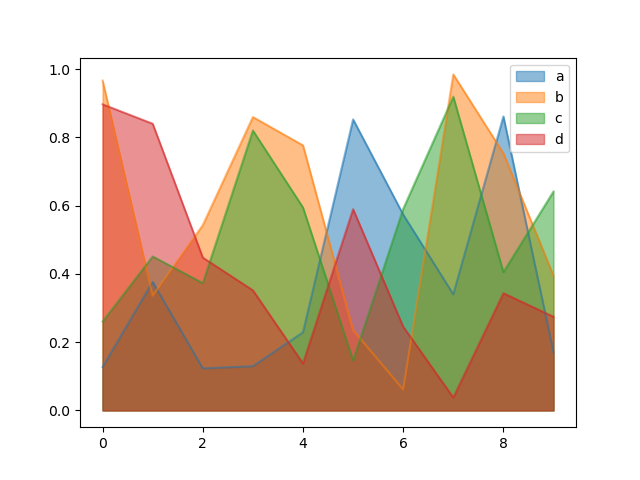
Диаграмма рассеяния#
Диаграмму рассеяния можно нарисовать с помощью DataFrame.plot.scatter() метод.
Диаграмма рассеяния требует числовых столбцов для осей x и y.
Они могут быть указаны с помощью x и y ключевые слова.
In [70]: df = pd.DataFrame(np.random.rand(50, 4), columns=["a", "b", "c", "d"])
In [71]: df["species"] = pd.Categorical(
....: ["setosa"] * 20 + ["versicolor"] * 20 + ["virginica"] * 10
....: )
....:
In [72]: df.plot.scatter(x="a", y="b");
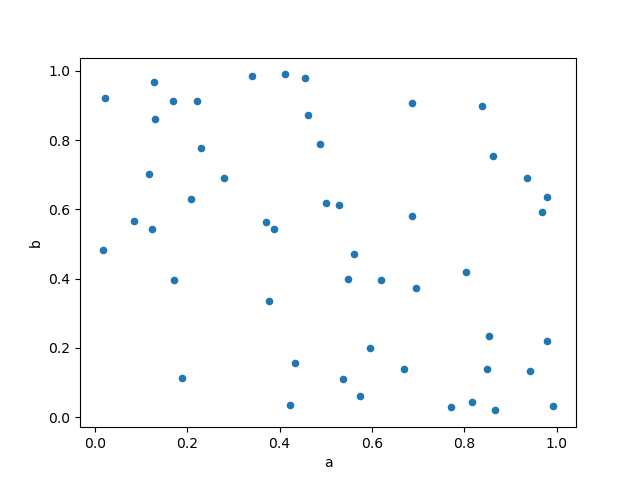
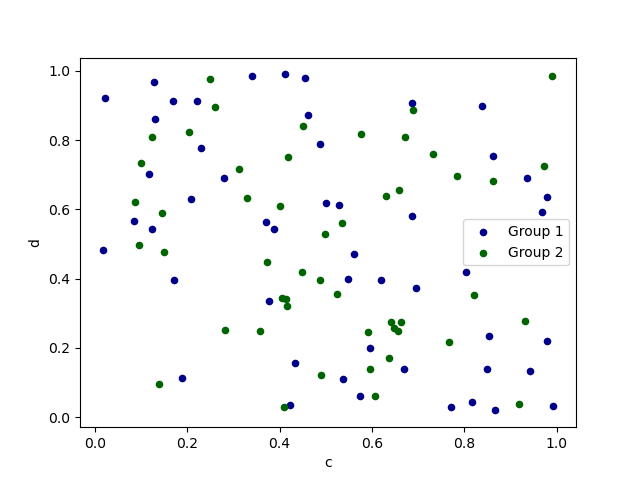
Чтобы построить несколько групп столбцов на одной оси, повторите plot метод, указывающий цель ax.
Рекомендуется указать color и label ключевые слова для различения каждой группы.
In [73]: ax = df.plot.scatter(x="a", y="b", color="DarkBlue", label="Group 1")
In [74]: df.plot.scatter(x="c", y="d", color="DarkGreen", label="Group 2", ax=ax);
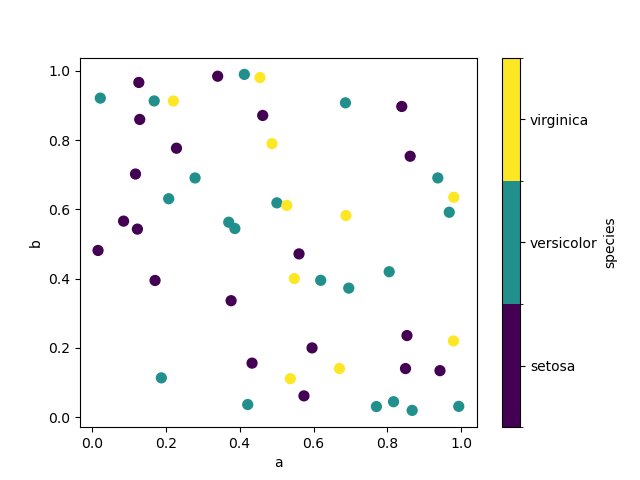
Ключевое слово c может быть указано как имя столбца для предоставления цветов для
каждой точки:
In [75]: df.plot.scatter(x="a", y="b", c="c", s=50);

Если категориальный столбец передается в c, тогда будет создана дискретная цветовая шкала:
Добавлено в версии 1.3.0.
In [76]: df.plot.scatter(x="a", y="b", c="species", cmap="viridis", s=50);
Вы можете передать другие ключевые слова, поддерживаемые matplotlib
scatter. Пример ниже показывает пузырьковую диаграмму, использующую столбец DataFrame в качестве размера пузырька.
In [77]: df.plot.scatter(x="a", y="b", s=df["c"] * 200);
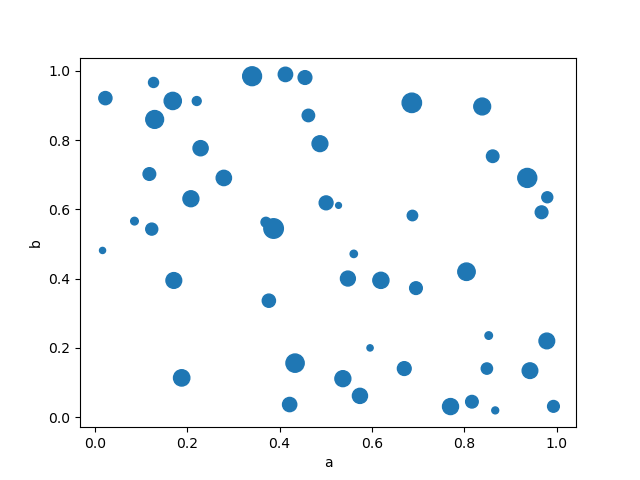
См. scatter метод и
документация matplotlib scatter подробнее.
Шестиугольная бинарная диаграмма#
Вы можете создавать шестиугольные биновые графики с DataFrame.plot.hexbin().
Гексагональные диаграммы могут быть полезной альтернативой точечным диаграммам, если ваши данные слишком плотные для отображения каждой точки отдельно.
In [78]: df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
In [79]: df["b"] = df["b"] + np.arange(1000)
In [80]: df.plot.hexbin(x="a", y="b", gridsize=25);
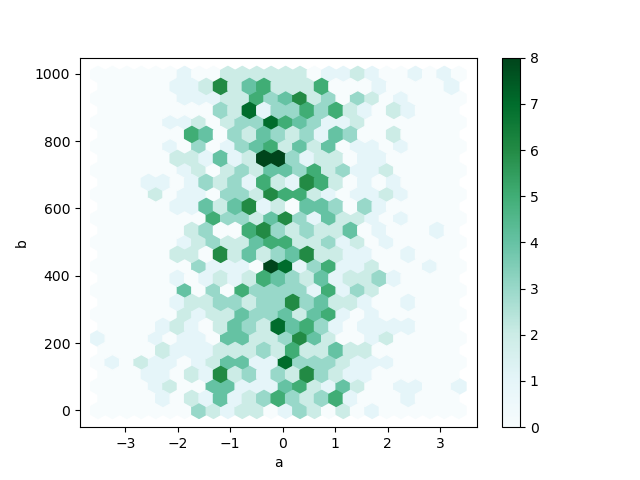
Полезным ключевым аргументом является gridsize; он управляет количеством шестиугольников
в направлении x и по умолчанию равен 100. Большее gridsize означает больше, меньшие
корзины.
По умолчанию гистограмма подсчётов вокруг каждого (x, y) точка вычисляется.
Вы можете указать альтернативные агрегации, передавая значения в C и
reduce_C_function аргументы. C определяет значение на каждом (x, y) точка
и reduce_C_function является функцией одного аргумента, которая сводит все
значения в бине к одному числу (например, mean, max, sum, std). В этом примере позиции задаются столбцами a и b, в то время как значение задаётся столбцом z. Блоки агрегируются с помощью max функция.
In [81]: df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
In [82]: df["b"] = df["b"] + np.arange(1000)
In [83]: df["z"] = np.random.uniform(0, 3, 1000)
In [84]: df.plot.hexbin(x="a", y="b", C="z", reduce_C_function=np.max, gridsize=25);
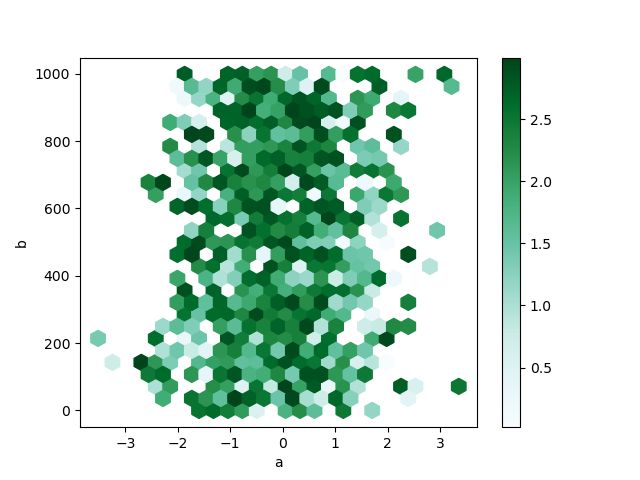
См. hexbin метод и
документация matplotlib hexbin подробнее.
Круговая диаграмма#
Вы можете создать круговую диаграмму с помощью DataFrame.plot.pie() или Series.plot.pie().
Если ваши данные включают любые NaN, они будут автоматически заполнены 0.
A ValueError будет вызвано, если в ваших данных есть какие-либо отрицательные значения.
In [85]: series = pd.Series(3 * np.random.rand(4), index=["a", "b", "c", "d"], name="series")
In [86]: series.plot.pie(figsize=(6, 6));
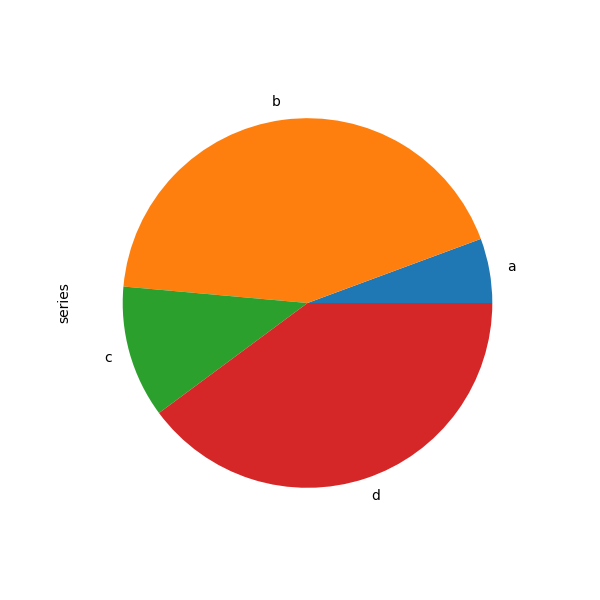
Для круговых диаграмм лучше использовать квадратные фигуры, т.е. соотношение сторон фигуры 1. Вы можете создать фигуру с равной шириной и высотой или принудительно установить соотношение сторон равным после построения, вызвав ax.set_aspect('equal') на возвращенном
axes объект.
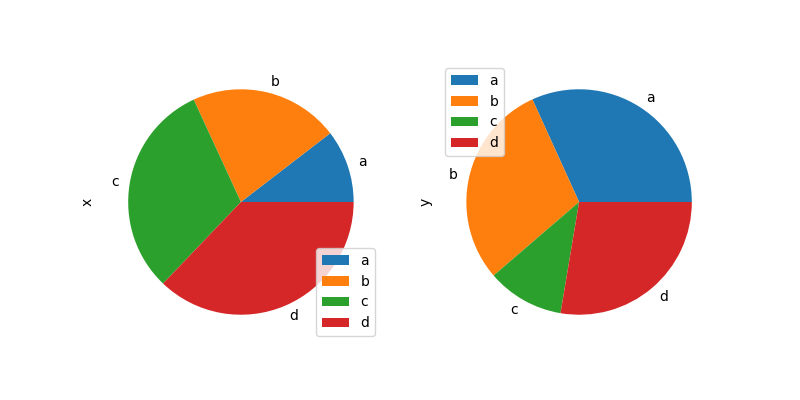
Обратите внимание, что круговая диаграмма с DataFrame требует, чтобы вы указали целевой столбец с помощью y аргумент или subplots=True. Когда y указан, будет построена круговая диаграмма выбранного столбца. Если subplots=True указан, круговые диаграммы для каждого столбца рисуются как подграфики. Легенда будет
нарисована в каждой круговой диаграмме по умолчанию; укажите legend=False чтобы скрыть его.
In [87]: df = pd.DataFrame(
....: 3 * np.random.rand(4, 2), index=["a", "b", "c", "d"], columns=["x", "y"]
....: )
....:
In [88]: df.plot.pie(subplots=True, figsize=(8, 4));
Вы можете использовать labels и colors ключевые слова для указания меток и цветов каждого сегмента.
Предупреждение
Большинство графиков pandas используют label и color аргументы (обратите внимание на отсутствие "s" у них).
Для согласованности с matplotlib.pyplot.pie() вы должны использовать labels и colors.
Если вы хотите скрыть метки сегментов, укажите labels=None.
Если fontsize указано, значение будет применено к меткам сегментов. Также другие ключевые слова, поддерживаемые matplotlib.pyplot.pie() может быть использован.
In [89]: series.plot.pie(
....: labels=["AA", "BB", "CC", "DD"],
....: colors=["r", "g", "b", "c"],
....: autopct="%.2f",
....: fontsize=20,
....: figsize=(6, 6),
....: );
....:
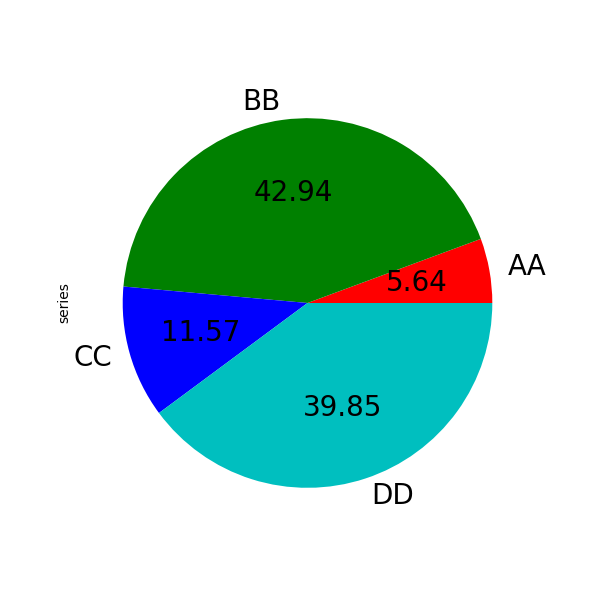
Если передать значения, сумма которых меньше 1.0, они будут перемасштабированы так, чтобы их сумма равнялась 1.
In [90]: series = pd.Series([0.1] * 4, index=["a", "b", "c", "d"], name="series2")
In [91]: series.plot.pie(figsize=(6, 6));
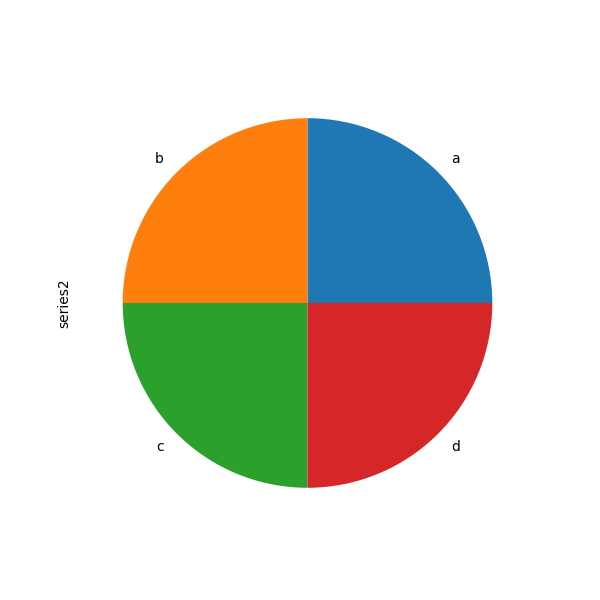
См. документация matplotlib pie подробнее.
Построение графиков с отсутствующими данными#
pandas старается быть прагматичным в отношении построения графиков DataFrames или Series
которые содержат пропущенные данные. Пропущенные значения удаляются, исключаются или заполняются в зависимости от типа графика.
Тип графика |
Обработка NaN |
|---|---|
Строка |
Оставлять пропуски на NaN |
Линейная (с накоплением) |
Заполнить 0 |
Bar |
Заполнить 0 |
Scatter |
Удалить NaN |
Гистограмма |
Удалить NaN (по столбцам) |
Box |
Удалить NaN (по столбцам) |
Площадь |
Заполнить 0 |
KDE |
Удалить NaN (по столбцам) |
Шестиугольная диаграмма рассеяния |
Удалить NaN |
Круговая диаграмма |
Заполнить 0 |
Если какие-либо из этих значений по умолчанию не соответствуют вашим требованиям, или если вы хотите явно указать, как обрабатываются пропущенные значения, рассмотрите использование
fillna() или dropna()
перед построением графика.
Инструменты построения графиков#
Эти функции можно импортировать из pandas.plotting
и возьмите Series или DataFrame в качестве аргумента.
Диаграмма рассеяния#
Вы можете создать матрицу диаграмм рассеяния с помощью
scatter_matrix метод в pandas.plotting:
In [92]: from pandas.plotting import scatter_matrix
In [93]: df = pd.DataFrame(np.random.randn(1000, 4), columns=["a", "b", "c", "d"])
In [94]: scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal="kde");
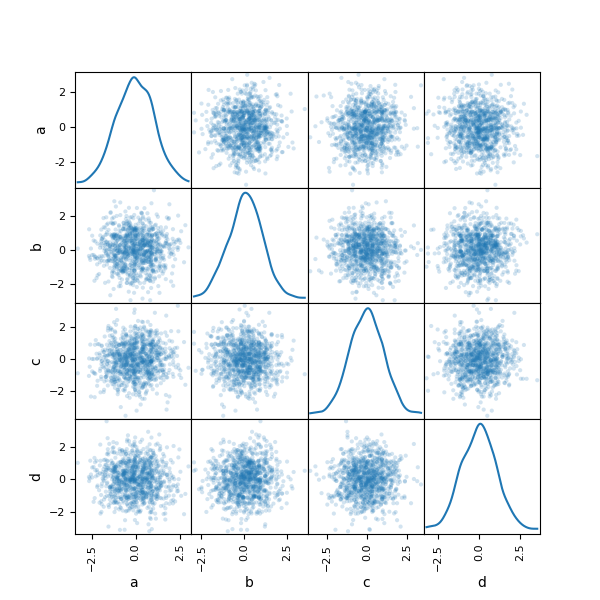
График плотности#
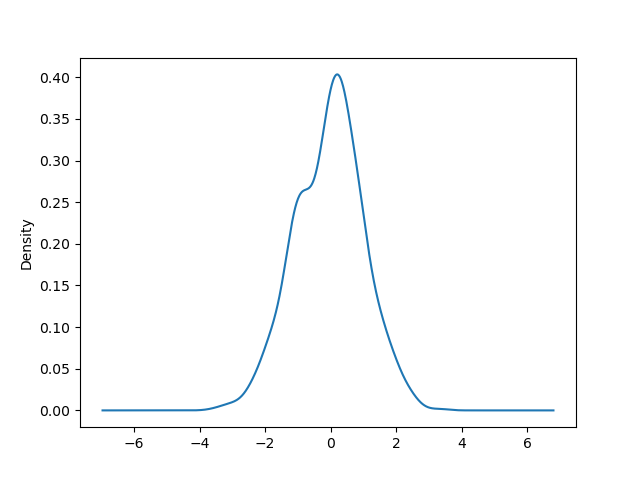
Вы можете создавать графики плотности с помощью Series.plot.kde() и DataFrame.plot.kde() методы.
In [95]: ser = pd.Series(np.random.randn(1000))
In [96]: ser.plot.kde();
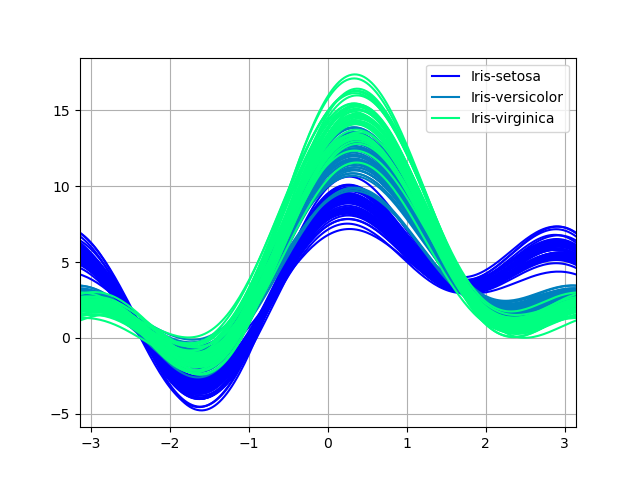
Кривые Эндрюса#
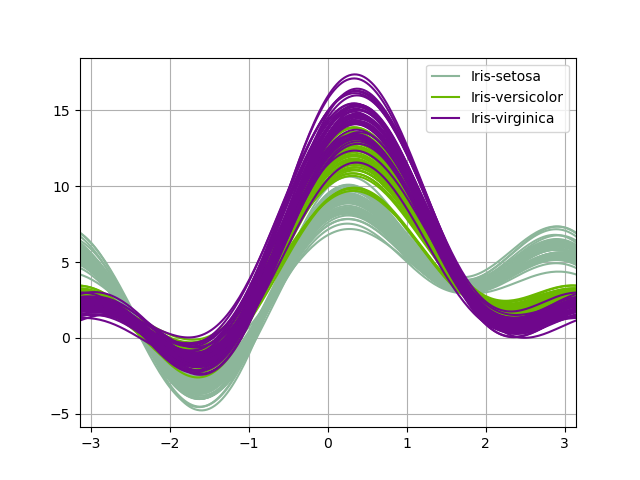
Кривые Эндрюса позволяют отображать многомерные данные в виде большого количества кривых, которые создаются с использованием атрибутов выборок в качестве коэффициентов для рядов Фурье, см. Запись в Википедии для получения дополнительной информации. Раскрашивая эти кривые по-разному для каждого класса, можно визуализировать кластеризацию данных. Кривые, принадлежащие образцам одного класса, обычно будут ближе друг к другу и формировать более крупные структуры.
Примечание: Набор данных "Ирис" доступен здесь.
In [97]: from pandas.plotting import andrews_curves
In [98]: data = pd.read_csv("data/iris.data")
In [99]: plt.figure();
In [100]: andrews_curves(data, "Name");
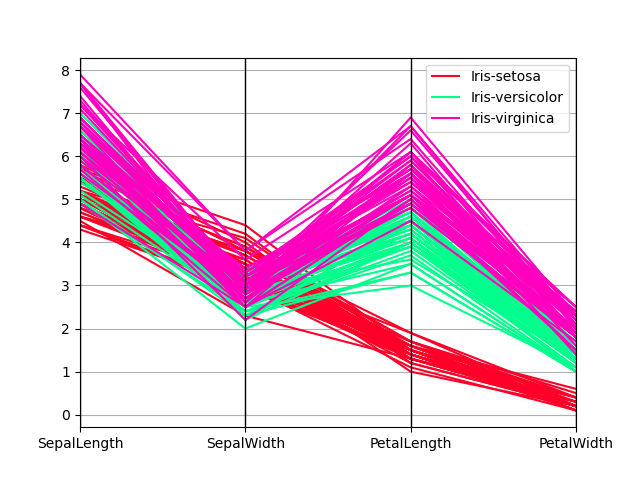
Параллельные координаты#
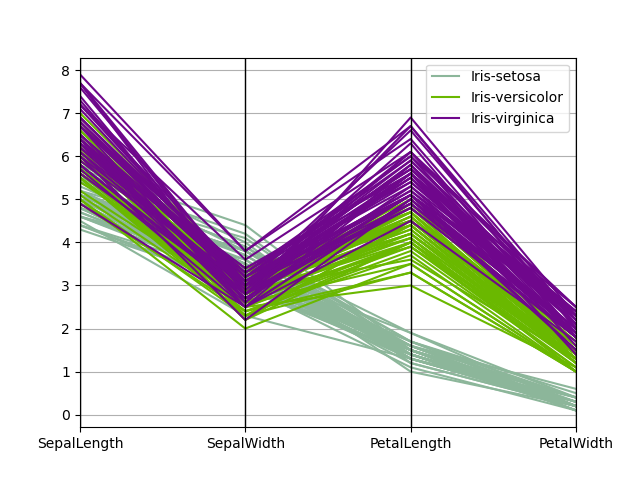
Параллельные координаты - это техника построения графиков для многомерных данных, см. Запись в Википедии для введения. Параллельные координаты позволяют увидеть кластеры в данных и визуально оценить другие статистики. Используя параллельные координаты, точки представляются в виде соединенных отрезков линий. Каждая вертикальная линия представляет один атрибут. Один набор соединенных отрезков линий представляет одну точку данных. Точки, которые имеют тенденцию к кластеризации, будут появляться ближе друг к другу.
In [101]: from pandas.plotting import parallel_coordinates
In [102]: data = pd.read_csv("data/iris.data")
In [103]: plt.figure();
In [104]: parallel_coordinates(data, "Name");
Лаг-график#
Графики лагов используются для проверки случайности набора данных или временного ряда. Случайные
данные не должны демонстрировать какой-либо структуры на графике лагов. Неслучайная структура
подразумевает, что исходные данные не являются случайными. lag аргумент может быть передан, и когда lag=1 график по сути data[:-1] vs.
data[1:].
In [105]: from pandas.plotting import lag_plot
In [106]: plt.figure();
In [107]: spacing = np.linspace(-99 * np.pi, 99 * np.pi, num=1000)
In [108]: data = pd.Series(0.1 * np.random.rand(1000) + 0.9 * np.sin(spacing))
In [109]: lag_plot(data);
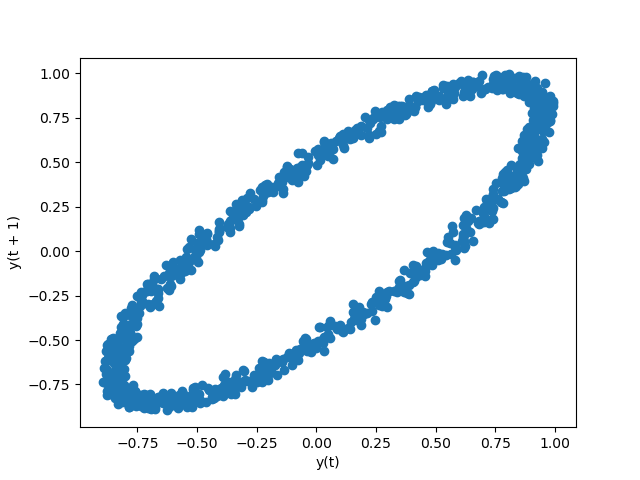
График автокорреляции#
Графики автокорреляции часто используются для проверки случайности временных рядов. Это делается путем вычисления автокорреляций для значений данных при различных временных лагах. Если временной ряд случайный, такие автокорреляции должны быть близки к нулю для любых и всех разделений по временному лагу. Если временной ряд неслучайный, то одна или несколько автокорреляций будут значительно отличаться от нуля. Горизонтальные линии, отображаемые на графике, соответствуют 95% и 99% доверительным интервалам. Пунктирная линия - это 99% доверительный интервал. См. Запись в Википедии подробнее о графиках автокорреляции.
In [110]: from pandas.plotting import autocorrelation_plot
In [111]: plt.figure();
In [112]: spacing = np.linspace(-9 * np.pi, 9 * np.pi, num=1000)
In [113]: data = pd.Series(0.7 * np.random.rand(1000) + 0.3 * np.sin(spacing))
In [114]: autocorrelation_plot(data);
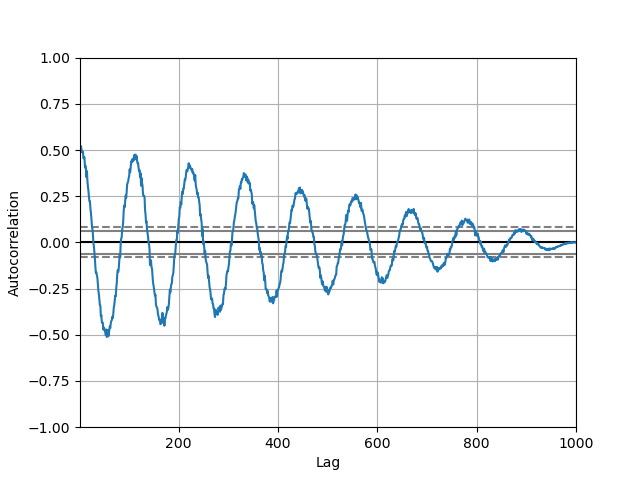
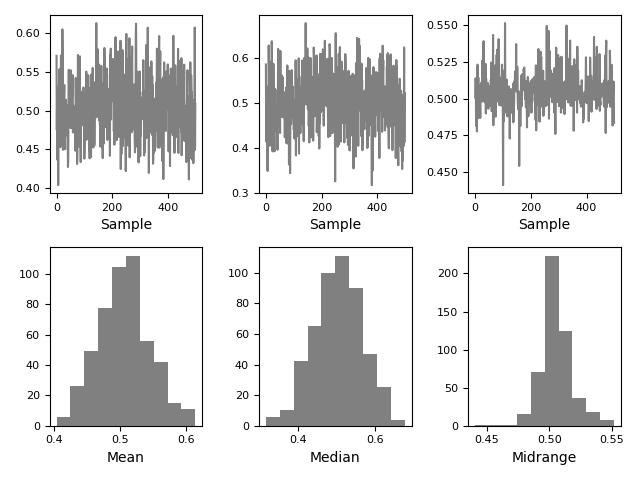
Диаграмма бутстрапа#
Бутстрап-графики используются для визуальной оценки неопределенности статистики, такой как среднее, медиана, средний размах и т.д. Из набора данных выбирается случайное подмножество указанного размера, вычисляется интересующая статистика для этого подмножества, и процесс повторяется указанное количество раз. Полученные графики и гистограммы составляют бутстрап-график.
In [115]: from pandas.plotting import bootstrap_plot
In [116]: data = pd.Series(np.random.rand(1000))
In [117]: bootstrap_plot(data, size=50, samples=500, color="grey");
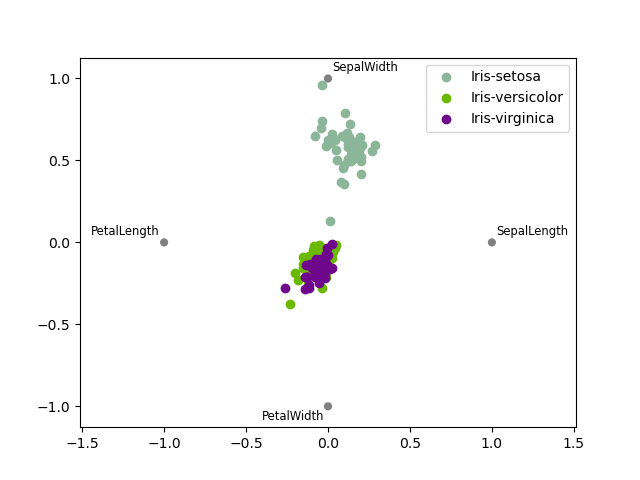
RadViz#
RadViz — это способ визуализации многомерных данных. Он основан на простом алгоритме минимизации натяжения пружины. По сути, вы размещаете набор точек на плоскости. В нашем случае они равномерно распределены по единичной окружности. Каждая точка представляет отдельный атрибут. Затем вы представляете, что каждый образец в наборе данных прикреплен к каждой из этих точек пружиной, жесткость которой пропорциональна числовому значению этого атрибута (они нормализованы к единичному интервалу). Точка на плоскости, где наш образец устанавливается (где силы, действующие на наш образец, находятся в равновесии), — это место, где будет нарисована точка, представляющая наш образец. В зависимости от того, к какому классу принадлежит образец, он будет окрашен по-разному. См. пакет R Radviz для получения дополнительной информации.
Примечание: Набор данных "Ирис" доступен здесь.
In [118]: from pandas.plotting import radviz
In [119]: data = pd.read_csv("data/iris.data")
In [120]: plt.figure();
In [121]: radviz(data, "Name");
Форматирование графиков#
Установка стиля графика#
Начиная с версии 1.5 и выше, matplotlib предлагает набор предварительно настроенных стилей построения графиков. Установка стиля может использоваться для легкого придания графикам общего вида, который вам нужен. Установка стиля так же проста, как вызов matplotlib.style.use(my_plot_style) перед созданием графика. Например, вы можете написать matplotlib.style.use('ggplot') для графиков в стиле ggplot.
Вы можете увидеть различные доступные названия стилей на matplotlib.style.available и их очень
легко попробовать.
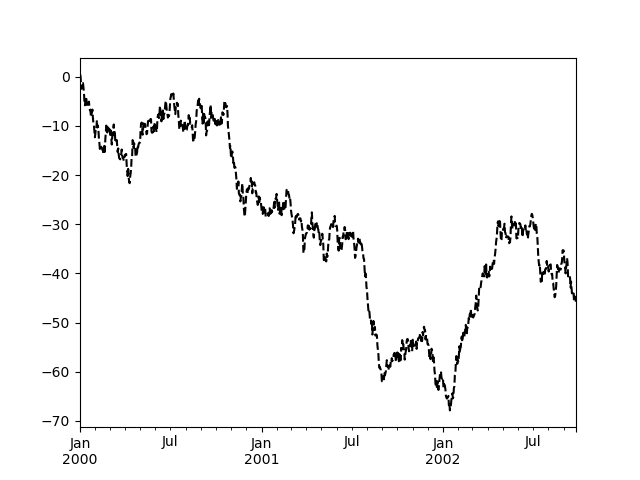
Общие аргументы стиля графика#
Большинство методов построения графиков имеют набор ключевых аргументов, которые управляют макетом и форматированием возвращаемого графика:
In [122]: plt.figure();
In [123]: ts.plot(style="k--", label="Series");
Для каждого типа графика (например, line, bar, scatter) любые дополнительные аргументы и ключевые слова передаются соответствующей функции matplotlib (ax.plot(),
ax.bar(),
ax.scatter()). Их можно использовать для управления дополнительным стилем, помимо того, что предоставляет pandas.
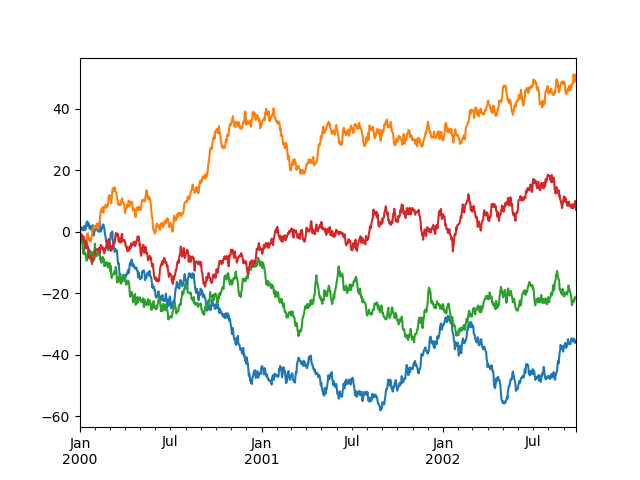
Управление легендой#
Вы можете установить legend аргумент для False чтобы скрыть легенду, которая
показывается по умолчанию.
In [124]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
In [125]: df = df.cumsum()
In [126]: df.plot(legend=False);
Управление метками#
Вы можете установить xlabel и ylabel аргументы для задания пользовательских меток
для осей x и y. По умолчанию pandas использует имя индекса как метку x, оставляя
метку y пустой.
In [127]: df.plot();
In [128]: df.plot(xlabel="new x", ylabel="new y");
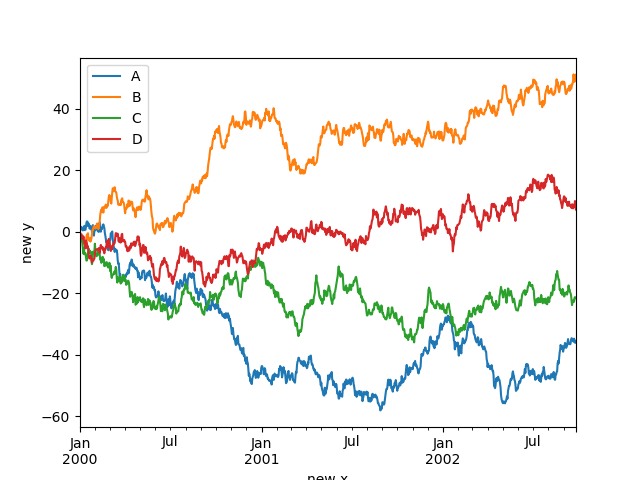
Масштабы#
Вы можете передать logy чтобы получить логарифмическую ось Y.
In [129]: ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
In [130]: ts = np.exp(ts.cumsum())
In [131]: ts.plot(logy=True);
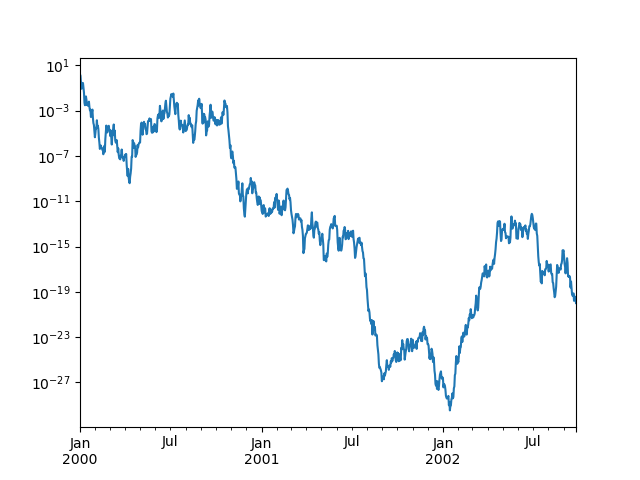
См. также logx и loglog ключевые аргументы.
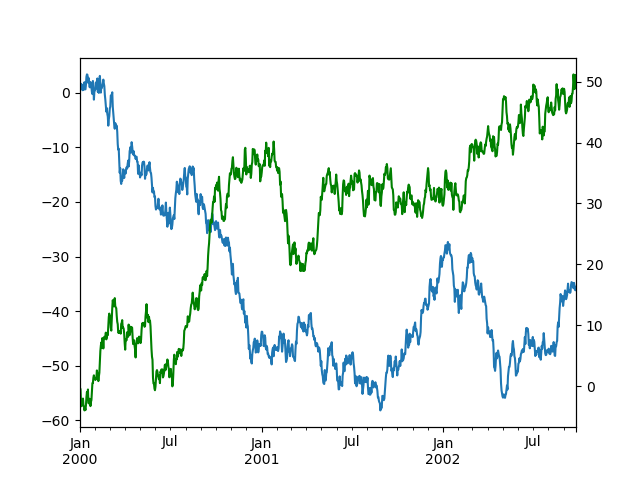
Построение графика на дополнительной оси Y#
Для построения данных на вторичной оси Y используйте secondary_y ключевое слово:
In [132]: df["A"].plot();
In [133]: df["B"].plot(secondary_y=True, style="g");
Чтобы построить график для некоторых столбцов в DataFrame, укажите имена столбцов для secondary_y
ключевое слово:
In [134]: plt.figure();
In [135]: ax = df.plot(secondary_y=["A", "B"])
In [136]: ax.set_ylabel("CD scale");
In [137]: ax.right_ax.set_ylabel("AB scale");
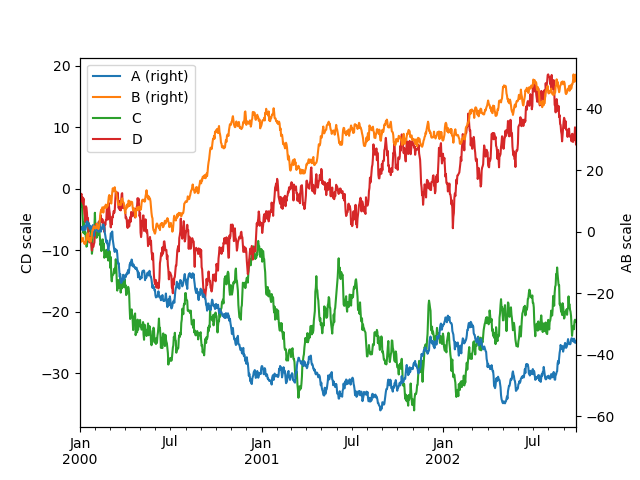
Обратите внимание, что столбцы, отображаемые на вторичной оси Y, автоматически помечаются
«(справа)» в легенде. Чтобы отключить автоматическую маркировку, используйте
mark_right=False ключевое слово:
In [138]: plt.figure();
In [139]: df.plot(secondary_y=["A", "B"], mark_right=False);
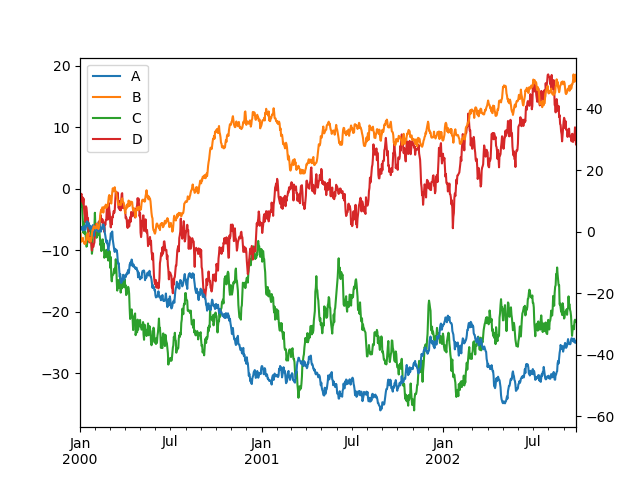
Пользовательские форматтеры для графиков временных рядов#
pandas предоставляет пользовательские форматтеры для временных рядов на графиках. Они изменяют форматирование меток осей для дат и времени. По умолчанию пользовательские форматтеры применяются только к графикам, созданным pandas с помощью
DataFrame.plot() или Series.plot(). Чтобы они применялись ко всем графикам, включая созданные с помощью matplotlib, установите опцию
pd.options.plotting.matplotlib.register_converters = True или используйте
pandas.plotting.register_matplotlib_converters().
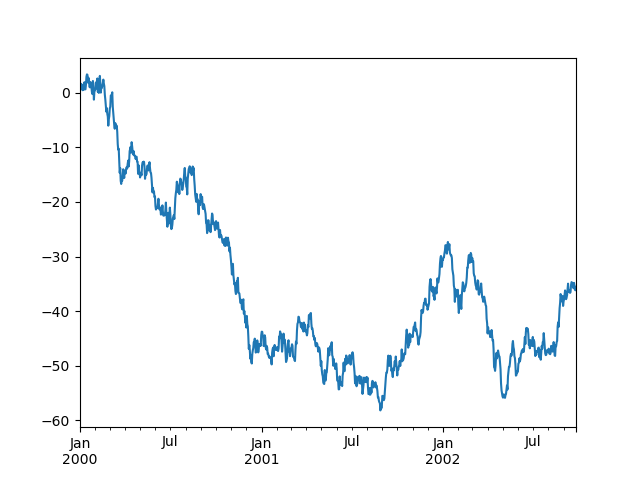
Подавление корректировки разрешения делений#
pandas включает автоматическую настройку разрешения делений для регулярных временных рядов. В ограниченных случаях, когда pandas не может определить информацию о частоте (например, во внешне созданном twinx), вы можете выбрать
подавление этого поведения для целей выравнивания.
Вот поведение по умолчанию, обратите внимание, как выполняется маркировка делений оси x:
In [140]: plt.figure();
In [141]: df["A"].plot();
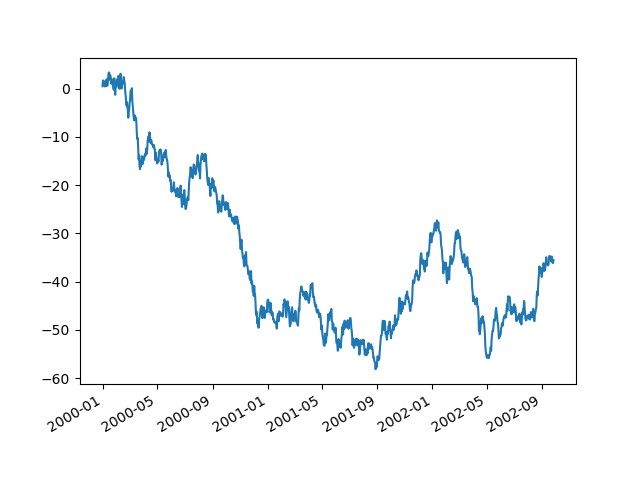
Используя x_compat параметр, вы можете отключить это поведение:
In [142]: plt.figure();
In [143]: df["A"].plot(x_compat=True);
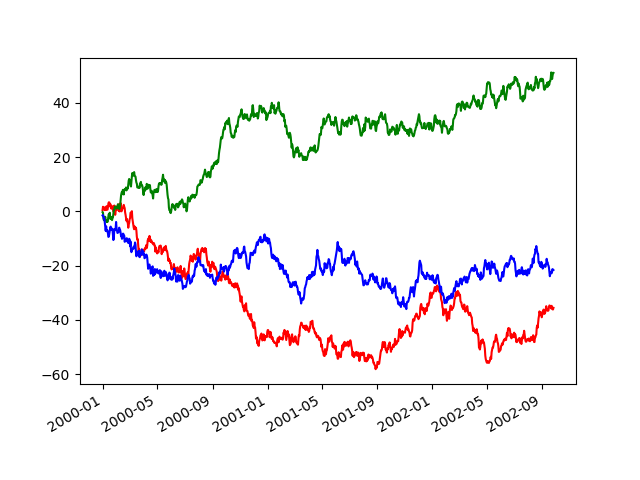
Если у вас более одного графика, который нужно подавить, use метод
в pandas.plotting.plot_params может использоваться в with оператор:
In [144]: plt.figure();
In [145]: with pd.plotting.plot_params.use("x_compat", True):
.....: df["A"].plot(color="r")
.....: df["B"].plot(color="g")
.....: df["C"].plot(color="b")
.....:
Автоматическая настройка делений дат#
TimedeltaIndex теперь использует нативные методы расположения делений matplotlib, полезно вызывать автоматическую
настройку делений дат из matplotlib для графиков, чьи подписи делений перекрываются.
См. autofmt_xdate метод и
документация matplotlib подробнее.
Подграфики#
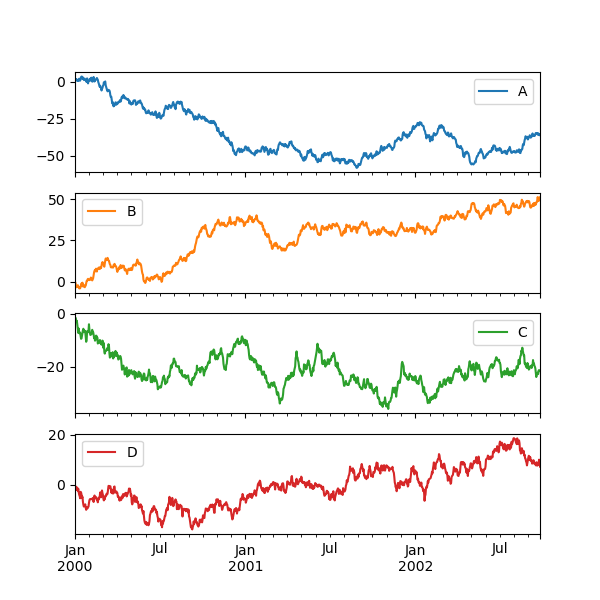
Каждый Series в DataFrame может быть построен на другой оси с помощью subplots ключевое слово:
In [146]: df.plot(subplots=True, figsize=(6, 6));
Использование layout и нацеливание на несколько осей#
Макет подграфиков может быть задан с помощью layout ключевое слово. Может принимать
(rows, columns). layout ключевое слово может использоваться в
hist и boxplot также. Если ввод недействителен, ValueError будет вызвано исключение.
Количество осей, которые могут содержаться в строках x столбцах, указанных layout должен быть
больше количества требуемых подграфиков. Если макет может содержать больше осей, чем требуется,
пустые оси не рисуются. Аналогично reshape метод, вы
можете использовать -1 для одного измерения для автоматического расчета количества строк или столбцов, необходимых при заданном другом.
In [147]: df.plot(subplots=True, layout=(2, 3), figsize=(6, 6), sharex=False);
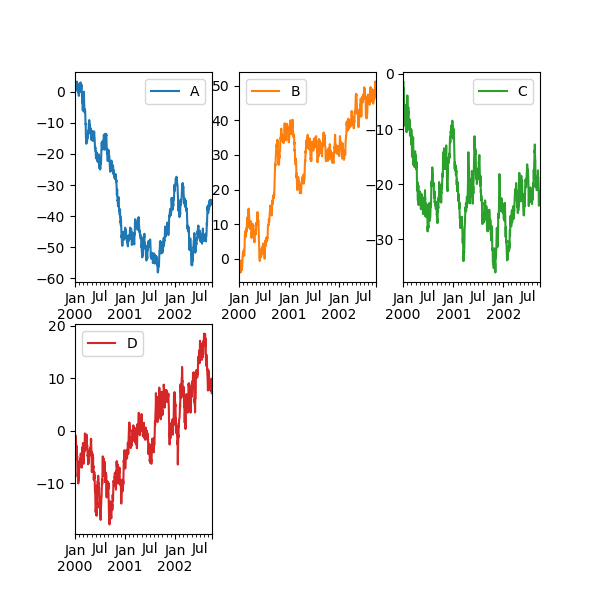
Приведенный выше пример идентичен использованию:
In [148]: df.plot(subplots=True, layout=(2, -1), figsize=(6, 6), sharex=False);
Необходимое количество столбцов (3) выводится из количества серий для построения графика и заданного количества строк (2).
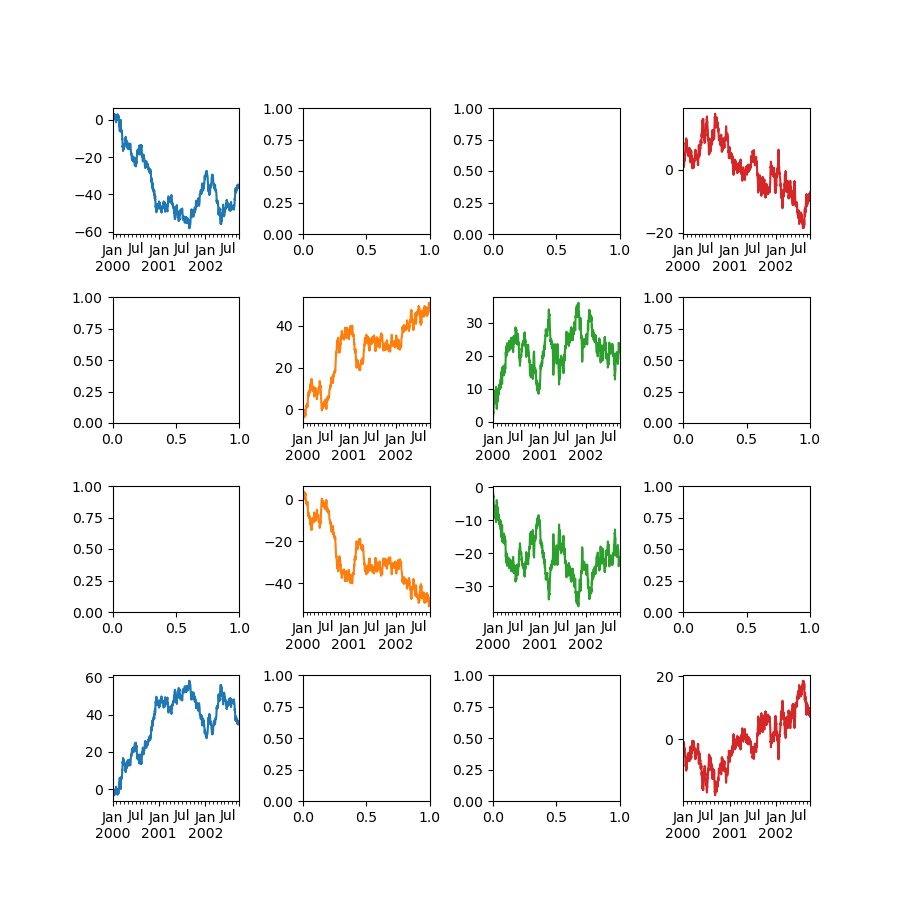
Вы можете передать несколько осей, созданных заранее, как список через ax ключевое слово. Это позволяет создавать более сложные макеты. Переданные оси должны совпадать по количеству с рисуемыми подграфиками.
Когда несколько осей передаются через ax ключевое слово, layout, sharex и sharey ключевые слова
не влияют на вывод. Следует явно передать sharex=False и sharey=False,
иначе вы увидите предупреждение.
In [149]: fig, axes = plt.subplots(4, 4, figsize=(9, 9))
In [150]: plt.subplots_adjust(wspace=0.5, hspace=0.5)
In [151]: target1 = [axes[0][0], axes[1][1], axes[2][2], axes[3][3]]
In [152]: target2 = [axes[3][0], axes[2][1], axes[1][2], axes[0][3]]
In [153]: df.plot(subplots=True, ax=target1, legend=False, sharex=False, sharey=False);
In [154]: (-df).plot(subplots=True, ax=target2, legend=False, sharex=False, sharey=False);
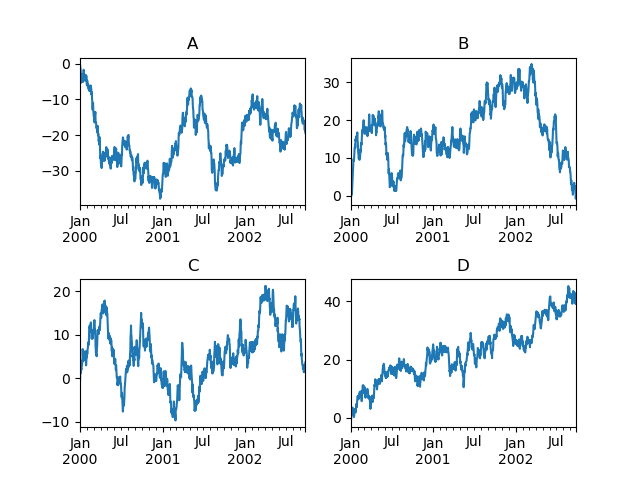
Другой вариант - передача ax аргумент для Series.plot() для построения на конкретной оси:
In [155]: np.random.seed(123456)
In [156]: ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
In [157]: ts = ts.cumsum()
In [158]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
In [159]: df = df.cumsum()
In [160]: fig, axes = plt.subplots(nrows=2, ncols=2)
In [161]: plt.subplots_adjust(wspace=0.2, hspace=0.5)
In [162]: df["A"].plot(ax=axes[0, 0]);
In [163]: axes[0, 0].set_title("A");
In [164]: df["B"].plot(ax=axes[0, 1]);
In [165]: axes[0, 1].set_title("B");
In [166]: df["C"].plot(ax=axes[1, 0]);
In [167]: axes[1, 0].set_title("C");
In [168]: df["D"].plot(ax=axes[1, 1]);
In [169]: axes[1, 1].set_title("D");
Построение графиков с полосами погрешностей#
Построение графиков с полосами ошибок поддерживается в DataFrame.plot() и Series.plot().
Горизонтальные и вертикальные полосы ошибок могут быть предоставлены для xerr и yerr ключевые аргументы для plot(). Значения ошибок могут быть указаны с использованием различных форматов:
Как
DataFrameилиdictошибок с именами столбцов, соответствующимиcolumnsатрибут построения графиковDataFrameили соответствиеnameатрибутSeries.Как
strуказывая, какой из столбцов построенияDataFrameсодержат значения ошибок.В виде исходных значений (
list,tuple, илиnp.ndarray). Должен быть той же длины, что и графикDataFrame/Series.
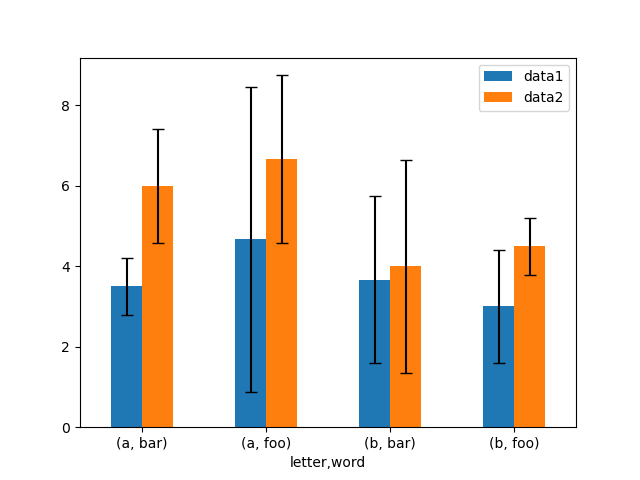
Вот пример одного из способов легко построить график средних значений групп со стандартными отклонениями из исходных данных.
# Generate the data
In [170]: ix3 = pd.MultiIndex.from_arrays(
.....: [
.....: ["a", "a", "a", "a", "a", "b", "b", "b", "b", "b"],
.....: ["foo", "foo", "foo", "bar", "bar", "foo", "foo", "bar", "bar", "bar"],
.....: ],
.....: names=["letter", "word"],
.....: )
.....:
In [171]: df3 = pd.DataFrame(
.....: {
.....: "data1": [9, 3, 2, 4, 3, 2, 4, 6, 3, 2],
.....: "data2": [9, 6, 5, 7, 5, 4, 5, 6, 5, 1],
.....: },
.....: index=ix3,
.....: )
.....:
# Group by index labels and take the means and standard deviations
# for each group
In [172]: gp3 = df3.groupby(level=("letter", "word"))
In [173]: means = gp3.mean()
In [174]: errors = gp3.std()
In [175]: means
Out[175]:
data1 data2
letter word
a bar 3.500000 6.000000
foo 4.666667 6.666667
b bar 3.666667 4.000000
foo 3.000000 4.500000
In [176]: errors
Out[176]:
data1 data2
letter word
a bar 0.707107 1.414214
foo 3.785939 2.081666
b bar 2.081666 2.645751
foo 1.414214 0.707107
# Plot
In [177]: fig, ax = plt.subplots()
In [178]: means.plot.bar(yerr=errors, ax=ax, capsize=4, rot=0);
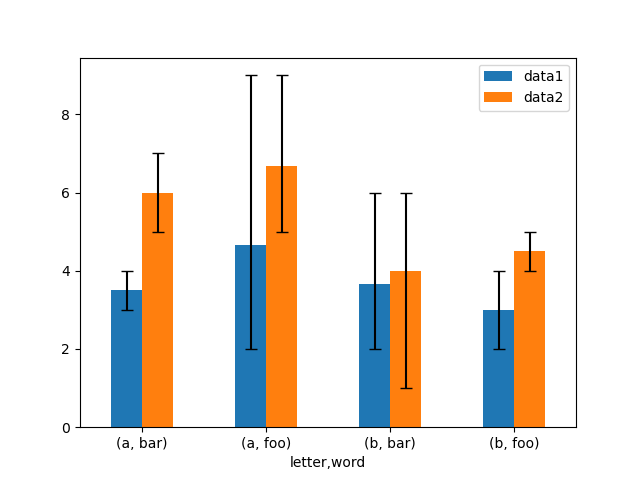
Асимметричные планки погрешностей также поддерживаются, однако в этом случае должны быть предоставлены исходные значения погрешностей. Для N длина Series, a 2xN должен быть предоставлен массив, указывающий нижнюю и верхнюю (или левую и правую) ошибки. Для MxN DataFrame, асимметричные ошибки должны быть в Mx2xN массив.
Вот пример одного из способов построения диапазона min/max с использованием асимметричных полос ошибок.
In [179]: mins = gp3.min()
In [180]: maxs = gp3.max()
# errors should be positive, and defined in the order of lower, upper
In [181]: errors = [[means[c] - mins[c], maxs[c] - means[c]] for c in df3.columns]
# Plot
In [182]: fig, ax = plt.subplots()
In [183]: means.plot.bar(yerr=errors, ax=ax, capsize=4, rot=0);
Построение таблиц#
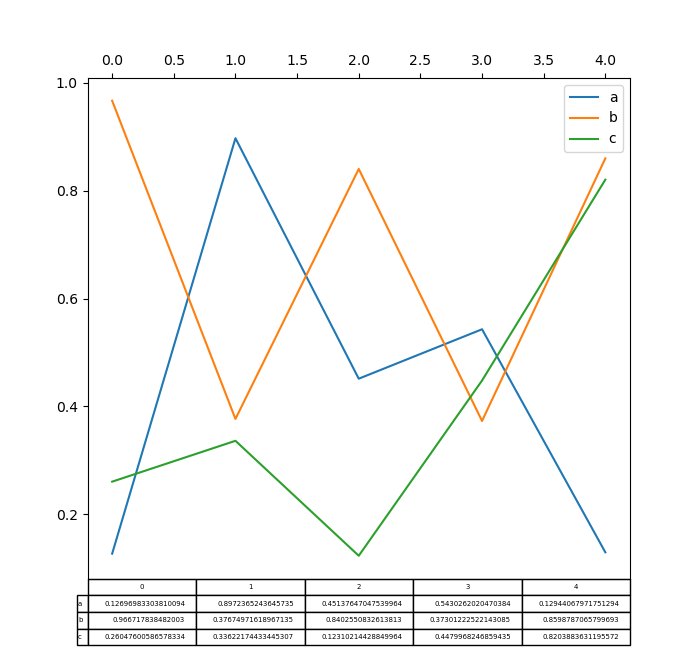
Построение графиков с таблицей matplotlib теперь поддерживается в DataFrame.plot() и Series.plot() с table ключевое слово. The table ключевое слово может принимать bool, DataFrame или Series. Простой способ нарисовать таблицу — указать table=True. Данные будут транспонированы для соответствия стандартному макету matplotlib.
In [184]: np.random.seed(123456)
In [185]: fig, ax = plt.subplots(1, 1, figsize=(7, 6.5))
In [186]: df = pd.DataFrame(np.random.rand(5, 3), columns=["a", "b", "c"])
In [187]: ax.xaxis.tick_top() # Display x-axis ticks on top.
In [188]: df.plot(table=True, ax=ax);
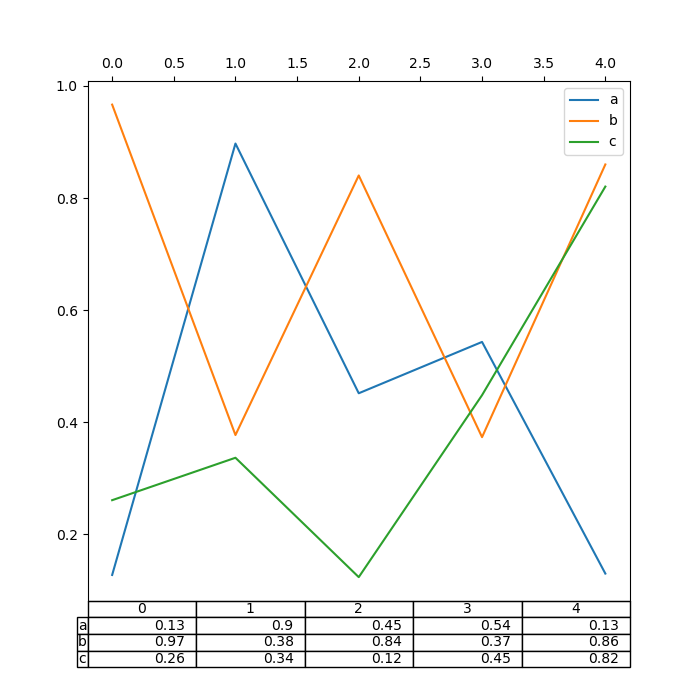
Также вы можете передать другой DataFrame или Series в
table ключевое слово. Данные будут отображаться как показано в методе печати
(не транспонируются автоматически). При необходимости их следует транспонировать вручную,
как показано в примере ниже.
In [189]: fig, ax = plt.subplots(1, 1, figsize=(7, 6.75))
In [190]: ax.xaxis.tick_top() # Display x-axis ticks on top.
In [191]: df.plot(table=np.round(df.T, 2), ax=ax);
Также существует вспомогательная функция pandas.plotting.table, который создает
таблицу из DataFrame или Series, и добавляет его в
matplotlib.Axes экземпляр. Эта функция может принимать ключевые слова, которые таблица имеет.
In [192]: from pandas.plotting import table
In [193]: fig, ax = plt.subplots(1, 1)
In [194]: table(ax, np.round(df.describe(), 2), loc="upper right", colWidths=[0.2, 0.2, 0.2]);
In [195]: df.plot(ax=ax, ylim=(0, 2), legend=None);
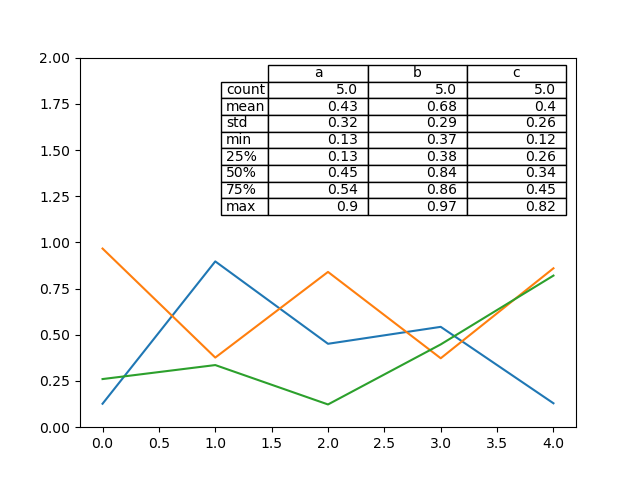
Примечание: Вы можете получить экземпляры таблиц на осях, используя axes.tables свойство для дальнейшего оформления. См. документация по таблицам matplotlib подробнее.
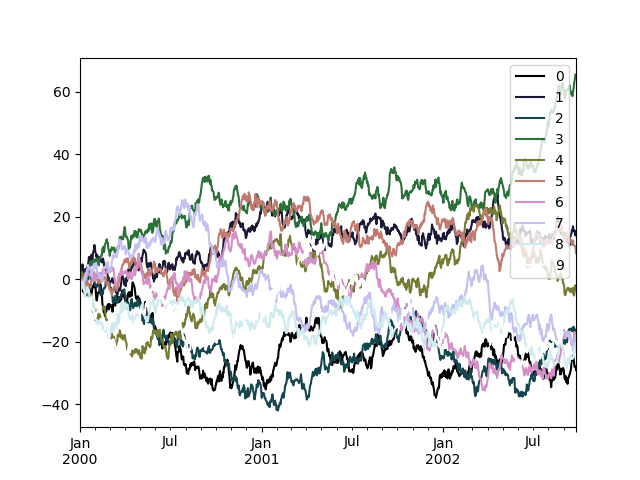
Цветовые карты#
Потенциальная проблема при построении большого количества столбцов заключается в том, что может быть
трудно различить некоторые серии из-за повторения цветов по умолчанию. Чтобы
исправить это, DataFrame plotting поддерживает использование colormap аргумент,
который принимает либо Matplotlib цветовая карта
или строку, которая является именем цветовой карты, зарегистрированной в Matplotlib. Визуализация цветовых карт matplotlib по умолчанию доступна здесь.
Поскольку matplotlib напрямую не поддерживает цветовые карты для линейных графиков,
цвета выбираются на основе равномерного интервала, определяемого количеством столбцов
в DataFrame. Фон не учитывается, поэтому некоторые
цветовые карты будут создавать линии, которые плохо видны.
Чтобы использовать цветовую карту cubehelix, мы можем передать colormap='cubehelix'.
In [196]: np.random.seed(123456)
In [197]: df = pd.DataFrame(np.random.randn(1000, 10), index=ts.index)
In [198]: df = df.cumsum()
In [199]: plt.figure();
In [200]: df.plot(colormap="cubehelix");
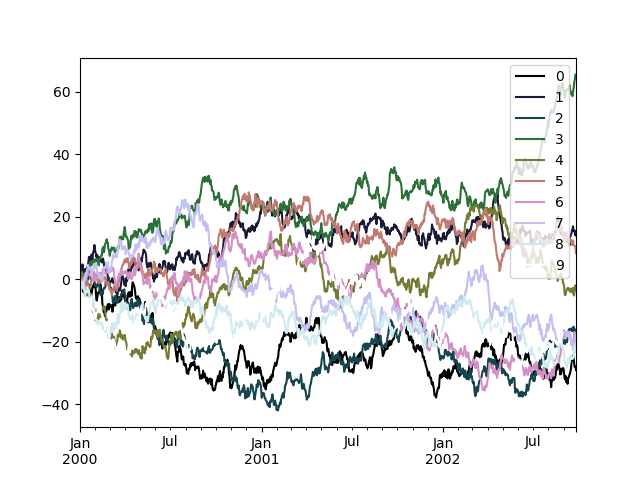
В качестве альтернативы мы можем передать саму цветовую карту:
In [201]: from matplotlib import cm
In [202]: plt.figure();
In [203]: df.plot(colormap=cm.cubehelix);
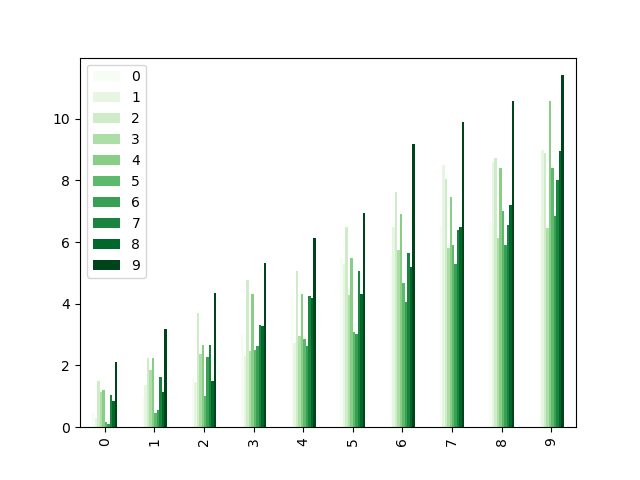
Цветовые карты также могут использоваться в других типах графиков, например, в столбчатых диаграммах:
In [204]: np.random.seed(123456)
In [205]: dd = pd.DataFrame(np.random.randn(10, 10)).map(abs)
In [206]: dd = dd.cumsum()
In [207]: plt.figure();
In [208]: dd.plot.bar(colormap="Greens");
Диаграммы параллельных координат:
In [209]: plt.figure();
In [210]: parallel_coordinates(data, "Name", colormap="gist_rainbow");
Диаграммы кривых Эндрюса:
In [211]: plt.figure();
In [212]: andrews_curves(data, "Name", colormap="winter");
Построение графиков напрямую с помощью Matplotlib#
В некоторых ситуациях может быть предпочтительнее или необходимо готовить графики напрямую с помощью matplotlib, например, когда определенный тип графика или настройка не поддерживается (пока) pandas. Series и DataFrame
объекты ведут себя как массивы и поэтому могут быть переданы непосредственно в
функции matplotlib без явного приведения типов.
pandas также автоматически регистрирует форматировщики и локаторы, которые распознают даты в индексах, тем самым расширяя поддержку дат и времени практически для всех типов графиков, доступных в matplotlib. Хотя это форматирование не обеспечивает тот же уровень детализации, который вы получили бы при построении графиков через pandas, оно может быть быстрее при построении большого количества точек.
In [213]: np.random.seed(123456)
In [214]: price = pd.Series(
.....: np.random.randn(150).cumsum(),
.....: index=pd.date_range("2000-1-1", periods=150, freq="B"),
.....: )
.....:
In [215]: ma = price.rolling(20).mean()
In [216]: mstd = price.rolling(20).std()
In [217]: plt.figure();
In [218]: plt.plot(price.index, price, "k");
In [219]: plt.plot(ma.index, ma, "b");
In [220]: plt.fill_between(mstd.index, ma - 2 * mstd, ma + 2 * mstd, color="b", alpha=0.2);
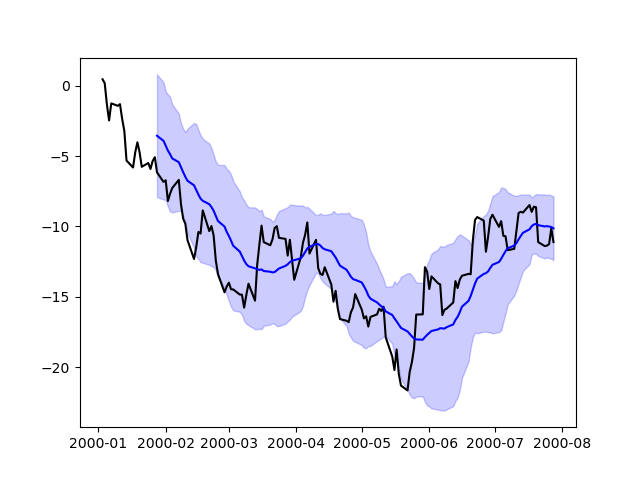
Бэкенды построения графиков#
pandas может быть расширен сторонними бэкендами для построения графиков. Основная идея заключается в том, чтобы позволить пользователям выбирать бэкенд для построения графиков, отличный от предоставленного на основе Matplotlib.
Это можно сделать, передав 'backend.module' в качестве аргумента backend в plot
функция. Например:
>>> Series([1, 2, 3]).plot(backend="backend.module")
Кроме того, вы также можете установить эту опцию глобально, чтобы не указывать
ключевое слово в каждом plot вызов. Например:
>>> pd.set_option("plotting.backend", "backend.module")
>>> pd.Series([1, 2, 3]).plot()
Или:
>>> pd.options.plotting.backend = "backend.module"
>>> pd.Series([1, 2, 3]).plot()
Это было бы более или менее эквивалентно:
>>> import backend.module
>>> backend.module.plot(pd.Series([1, 2, 3]))
Модуль бэкенда может затем использовать другие инструменты визуализации (Bokeh, Altair, hvplot,…) для генерации графиков. Некоторые библиотеки, реализующие бэкенд для pandas, перечислены на страница экосистемы.
Руководство для разработчиков можно найти на https://pandas.pydata.org/docs/dev/development/extending.html#plotting-backends