Что нового в 0.23.0 (15 мая 2018)#
Это основной выпуск с версии 0.22.0 и включает ряд изменений API, устареваний, новых функций, улучшений и оптимизаций производительности, а также большое количество исправлений ошибок. Мы рекомендуем всем пользователям обновиться до этой версии.
Основные моменты включают:
Создание экземпляра из словарей сохраняет порядок для Python 3.6+.
Слияние / сортировка по комбинации столбцов и уровней индекса.
Проверьте Изменения API и устаревшие возможности перед обновлением.
Предупреждение
Начиная с 1 января 2019 года, релизы функций pandas будут поддерживать только Python 3. См. Удаление Python 2.7 подробнее.
Новые возможности#
Чтение/запись JSON с сохранением цикла (round-trippable) с orient='table'#
A DataFrame теперь можно записывать и затем считывать через JSON с сохранением метаданных с использованием orient='table' аргумент (см. GH 18912 и GH 9146). Ранее ни один из доступных orient значения гарантировали сохранение типов данных и имен индексов, среди прочих метаданных.
In [1]: df = pd.DataFrame({'foo': [1, 2, 3, 4],
...: 'bar': ['a', 'b', 'c', 'd'],
...: 'baz': pd.date_range('2018-01-01', freq='d', periods=4),
...: 'qux': pd.Categorical(['a', 'b', 'c', 'c'])},
...: index=pd.Index(range(4), name='idx'))
...:
In [2]: df
Out[2]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [3]: df.dtypes
Out[3]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
In [4]: df.to_json('test.json', orient='table')
In [5]: new_df = pd.read_json('test.json', orient='table')
In [6]: new_df
Out[6]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [7]: new_df.dtypes
Out[7]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
Обратите внимание, что строка index не поддерживается с форматом кругового обхода, так как он используется по умолчанию в write_json для указания отсутствующего имени индекса.
In [8]: df.index.name = 'index'
In [9]: df.to_json('test.json', orient='table')
In [10]: new_df = pd.read_json('test.json', orient='table')
In [11]: new_df
Out[11]:
foo bar baz qux
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [12]: new_df.dtypes
Out[12]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
Метод .assign() принимает зависимые аргументы#
The DataFrame.assign() теперь принимает зависимые ключевые аргументы для версии Python позже 3.6 (см. также PEP 468). Поздние ключевые аргументы теперь могут ссылаться на более ранние, если аргумент является вызываемым. См.
документация здесь (GH 14207)
In [13]: df = pd.DataFrame({'A': [1, 2, 3]})
In [14]: df
Out[14]:
A
0 1
1 2
2 3
[3 rows x 1 columns]
In [15]: df.assign(B=df.A, C=lambda x: x['A'] + x['B'])
Out[15]:
A B C
0 1 1 2
1 2 2 4
2 3 3 6
[3 rows x 3 columns]
Предупреждение
Это может незаметно изменить поведение вашего кода при использовании .assign() для обновления существующего столбца. Ранее вызываемые объекты,
ссылающиеся на другие обновляемые переменные, получали «старые» значения
Предыдущее поведение:
In [2]: df = pd.DataFrame({"A": [1, 2, 3]})
In [3]: df.assign(A=lambda df: df.A + 1, C=lambda df: df.A * -1)
Out[3]:
A C
0 2 -1
1 3 -2
2 4 -3
Новое поведение:
In [16]: df.assign(A=df.A + 1, C=lambda df: df.A * -1)
Out[16]:
A C
0 2 -2
1 3 -3
2 4 -4
[3 rows x 2 columns]
Слияние по комбинации столбцов и уровней индекса#
Строки, переданные в DataFrame.merge() как on, left_on, и right_on
параметры теперь могут ссылаться либо на имена столбцов, либо на имена уровней индекса.
Это позволяет объединять DataFrame экземпляры на комбинации уровней индекса
и столбцов без сброса индексов. См. Объединение по столбцам и
уровням раздел документации.
(GH 14355)
In [17]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [18]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']},
....: index=left_index)
....:
In [19]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [20]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3'],
....: 'key2': ['K0', 'K0', 'K0', 'K1']},
....: index=right_index)
....:
In [21]: left.merge(right, on=['key1', 'key2'])
Out[21]:
A B key2 C D
key1
K0 A0 B0 K0 C0 D0
K1 A2 B2 K0 C1 D1
K2 A3 B3 K1 C3 D3
[3 rows x 5 columns]
Сортировка по комбинации столбцов и уровней индекса#
Строки, переданные в DataFrame.sort_values() как by Параметр теперь может ссылаться как на имена столбцов, так и на имена уровней индекса. Это позволяет сортировку
DataFrame экземпляров по комбинации уровней индекса и столбцов без
сброса индексов. См. Сортировка по индексам и значениям раздел документации.
(GH 14353)
# Build MultiIndex
In [22]: idx = pd.MultiIndex.from_tuples([('a', 1), ('a', 2), ('a', 2),
....: ('b', 2), ('b', 1), ('b', 1)])
....:
In [23]: idx.names = ['first', 'second']
# Build DataFrame
In [24]: df_multi = pd.DataFrame({'A': np.arange(6, 0, -1)},
....: index=idx)
....:
In [25]: df_multi
Out[25]:
A
first second
a 1 6
2 5
2 4
b 2 3
1 2
1 1
[6 rows x 1 columns]
# Sort by 'second' (index) and 'A' (column)
In [26]: df_multi.sort_values(by=['second', 'A'])
Out[26]:
A
first second
b 1 1
1 2
a 1 6
b 2 3
a 2 4
2 5
[6 rows x 1 columns]
Расширение pandas пользовательскими типами (экспериментальная функция)#
pandas теперь поддерживает хранение объектов, похожих на массивы, которые не обязательно являются 1-D массивами NumPy, в качестве столбцов DataFrame или значений в Series. Это позволяет сторонним библиотекам реализовывать расширения типов NumPy, аналогично тому, как pandas реализовал категории, даты и время с часовыми поясами, периоды и интервалы.
В качестве демонстрации мы будем использовать cyberpandas, который предоставляет IPArray тип
для хранения IP-адресов.
In [1]: from cyberpandas import IPArray
In [2]: values = IPArray([
...: 0,
...: 3232235777,
...: 42540766452641154071740215577757643572
...: ])
...:
...:
IPArray не является обычным одномерным массивом NumPy, а потому что это pandas
ExtensionArray, он может быть правильно сохранен внутри контейнеров pandas.
In [3]: ser = pd.Series(values)
In [4]: ser
Out[4]:
0 0.0.0.0
1 192.168.1.1
2 2001:db8:85a3::8a2e:370:7334
dtype: ip
Обратите внимание, что тип данных - ip. Семантика пропущенных значений базового
массива учитывается:
In [5]: ser.isna()
Out[5]:
0 True
1 False
2 False
dtype: bool
Для получения дополнительной информации см. расширенные типы документации. Если вы создаете массив расширений, опубликуйте его в страница экосистемы.
Новый observed ключевое слово для исключения ненаблюдаемых категорий в GroupBy#
Группировка по категориальной переменной включает ненаблюдаемые категории в вывод. При группировке по нескольким категориальным столбцам это означает, что вы получаете декартово произведение всех категорий, включая комбинации, где нет наблюдений, что может привести к большому количеству групп. Мы добавили ключевое слово observed для управления этим поведением по умолчанию установлено
observed=False для обратной совместимости. (GH 14942, GH 8138, GH 15217, GH 17594, GH 8669, GH 20583, GH 20902)
In [27]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [28]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [29]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [30]: df['C'] = ['foo', 'bar'] * 2
In [31]: df
Out[31]:
A B values C
0 a c 1 foo
1 a d 2 bar
2 b c 3 foo
3 b d 4 bar
[4 rows x 4 columns]
Чтобы показать все значения, предыдущее поведение:
In [32]: df.groupby(['A', 'B', 'C'], observed=False).count()
Out[32]:
values
A B C
a c bar 0
foo 1
d bar 1
foo 0
y bar 0
... ...
z c foo 0
d bar 0
foo 0
y bar 0
foo 0
[18 rows x 1 columns]
Чтобы показать только наблюдаемые значения:
In [33]: df.groupby(['A', 'B', 'C'], observed=True).count()
Out[33]:
values
A B C
a c foo 1
d bar 1
b c foo 1
d bar 1
[4 rows x 1 columns]
Для операций сводных таблиц это поведение уже управляется параметром dropna ключевое слово:
In [34]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [35]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [36]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [37]: df
Out[37]:
A B values
0 a c 1
1 a d 2
2 b c 3
3 b d 4
[4 rows x 3 columns]
In [1]: pd.pivot_table(df, values='values', index=['A', 'B'], dropna=True)
Out[1]:
values
A B
a c 1.0
d 2.0
b c 3.0
d 4.0
In [2]: pd.pivot_table(df, values='values', index=['A', 'B'], dropna=False)
Out[2]:
values
A B
a c 1.0
d 2.0
y NaN
b c 3.0
d 4.0
y NaN
z c NaN
d NaN
y NaN
Rolling/Expanding.apply() принимает raw=False передать Series в функцию#
Series.rolling().apply(), DataFrame.rolling().apply(),
Series.expanding().apply(), и DataFrame.expanding().apply() получили raw=None параметр.
Это похоже на DataFame.apply()Этот параметр, если True позволяет отправить np.ndarray в применяемую функцию. Если False a Series будет передан. Значение по умолчанию: None, что сохраняет обратную совместимость, поэтому по умолчанию будет True, отправляя np.ndarray.
В будущей версии значение по умолчанию будет изменено на False, отправляя Series. (GH 5071, GH 20584)
In [38]: s = pd.Series(np.arange(5), np.arange(5) + 1)
In [39]: s
Out[39]:
1 0
2 1
3 2
4 3
5 4
Length: 5, dtype: int64
Передать Series:
In [40]: s.rolling(2, min_periods=1).apply(lambda x: x.iloc[-1], raw=False)
Out[40]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
Имитировать исходное поведение передачи ndarray:
In [41]: s.rolling(2, min_periods=1).apply(lambda x: x[-1], raw=True)
Out[41]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
DataFrame.interpolate получил limit_area kwarg#
DataFrame.interpolate() получил limit_area параметр для дополнительного контроля над тем, какие NaN заменяются.
Используйте limit_area='inside' для заполнения только NaN, окружённых допустимыми значениями, или использовать limit_area='outside' для заполнения только NaN s вне существующих допустимых значений, сохраняя те, что внутри. (GH 16284) См. полная документация здесь.
In [42]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan,
....: np.nan, 13, np.nan, np.nan])
....:
In [43]: ser
Out[43]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
Заполнить одно последовательное внутреннее значение в обоих направлениях
In [44]: ser.interpolate(limit_direction='both', limit_area='inside', limit=1)
Out[44]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
Заполнить все последовательные внешние значения назад
In [45]: ser.interpolate(limit_direction='backward', limit_area='outside')
Out[45]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
Заполнить все последовательные внешние значения в обоих направлениях
In [46]: ser.interpolate(limit_direction='both', limit_area='outside')
Out[46]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
Length: 9, dtype: float64
Функция get_dummies теперь поддерживает dtype аргумент#
The get_dummies() теперь принимает dtype аргумент, который указывает dtype для новых столбцов. По умолчанию остается uint8. (GH 18330)
In [47]: df = pd.DataFrame({'a': [1, 2], 'b': [3, 4], 'c': [5, 6]})
In [48]: pd.get_dummies(df, columns=['c']).dtypes
Out[48]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
In [49]: pd.get_dummies(df, columns=['c'], dtype=bool).dtypes
Out[49]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
Метод mod для Timedelta#
mod (%) и divmod операции теперь определены на Timedelta объектов при работе либо с дельта-времени, либо с числовыми аргументами. См. документация здесь. (GH 19365)
In [50]: td = pd.Timedelta(hours=37)
In [51]: td % pd.Timedelta(minutes=45)
Out[51]: Timedelta('0 days 00:15:00')
Метод .rank() обрабатывает inf значения, когда NaN присутствуют#
В предыдущих версиях, .rank() присвоит inf элементы NaN в качестве их рангов. Теперь ранги рассчитываются правильно. (GH 6945)
In [52]: s = pd.Series([-np.inf, 0, 1, np.nan, np.inf])
In [53]: s
Out[53]:
0 -inf
1 0.0
2 1.0
3 NaN
4 inf
Length: 5, dtype: float64
Предыдущее поведение:
In [11]: s.rank()
Out[11]:
0 1.0
1 2.0
2 3.0
3 NaN
4 NaN
dtype: float64
Текущее поведение:
In [54]: s.rank()
Out[54]:
0 1.0
1 2.0
2 3.0
3 NaN
4 4.0
Length: 5, dtype: float64
Кроме того, ранее если вы ранжировали inf или -inf значения вместе с NaN значения, вычисление не будет различать NaN от бесконечности при использовании аргументов 'top' или 'bottom'.
In [55]: s = pd.Series([np.nan, np.nan, -np.inf, -np.inf])
In [56]: s
Out[56]:
0 NaN
1 NaN
2 -inf
3 -inf
Length: 4, dtype: float64
Предыдущее поведение:
In [15]: s.rank(na_option='top')
Out[15]:
0 2.5
1 2.5
2 2.5
3 2.5
dtype: float64
Текущее поведение:
In [57]: s.rank(na_option='top')
Out[57]:
0 1.5
1 1.5
2 3.5
3 3.5
Length: 4, dtype: float64
Эти ошибки были исправлены:
Ошибка в
DataFrame.rank()иSeries.rank()когдаmethod='dense'иpct=Trueв котором процентильные ранги не использовались с количеством уникальных наблюдений (GH 15630)Ошибка в
Series.rank()иDataFrame.rank()когдаascending='False'не возвращал правильные ранги для бесконечности, еслиNaNприсутствовали (GH 19538)Ошибка в
DataFrameGroupBy.rank()где ранги были некорректными при наличии как бесконечности, так иNaNприсутствовали (GH 20561)
Series.str.cat получил join kwarg#
Ранее, Series.str.cat() не – в отличие от большинства pandas – выравнивание Series по их индексу перед конкатенацией (см. GH 18657).
Метод теперь получил ключевое слово join для управления способом выравнивания, см. примеры ниже и здесь.
В версии 0.23 join по умолчанию будет None (означает отсутствие выравнивания), но это значение по умолчанию изменится на 'left' в будущей версии pandas.
In [58]: s = pd.Series(['a', 'b', 'c', 'd'])
In [59]: t = pd.Series(['b', 'd', 'e', 'c'], index=[1, 3, 4, 2])
In [60]: s.str.cat(t)
Out[60]:
0 NaN
1 bb
2 cc
3 dd
Length: 4, dtype: object
In [61]: s.str.cat(t, join='left', na_rep='-')
Out[61]:
0 a-
1 bb
2 cc
3 dd
Length: 4, dtype: object
Кроме того, Series.str.cat() теперь работает для CategoricalIndex также (ранее вызывал ValueError; см. GH 20842).
DataFrame.astype выполняет построчное преобразование в Categorical#
DataFrame.astype() теперь может выполнять преобразование по столбцам в Categorical путем предоставления строки 'category' или CategoricalDtype. Ранее попытка этого вызывала NotImplementedError. См.
Создание объектов раздел документации для получения дополнительных подробностей и примеров. (GH 12860, GH 18099)
Предоставление строки 'category' выполняет преобразование по столбцам, с установкой в качестве категорий только меток, появляющихся в данном столбце:
In [62]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [63]: df = df.astype('category')
In [64]: df['A'].dtype
Out[64]: CategoricalDtype(categories=['a', 'b', 'c'], ordered=False, categories_dtype=object)
In [65]: df['B'].dtype
Out[65]: CategoricalDtype(categories=['b', 'c', 'd'], ordered=False, categories_dtype=object)
Предоставление CategoricalDtype сделает категории в каждом столбце согласованными с указанным dtype:
In [66]: from pandas.api.types import CategoricalDtype
In [67]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [68]: cdt = CategoricalDtype(categories=list('abcd'), ordered=True)
In [69]: df = df.astype(cdt)
In [70]: df['A'].dtype
Out[70]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True, categories_dtype=object)
In [71]: df['B'].dtype
Out[71]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True, categories_dtype=object)
Другие улучшения#
Унарный
+теперь разрешено дляSeriesиDataFrameкак числовой оператор (GH 16073)Улучшенная поддержка для
to_excel()вывод сxlsxwriterдвижок. (GH 16149)pandas.tseries.frequencies.to_offset()теперь принимает ведущие знаки '+' например '+1h'. (GH 18171)MultiIndex.unique()теперь поддерживаетlevel=аргумент, чтобы получить уникальные значения с определенного уровня индекса (GH 17896)pandas.io.formats.style.Stylerтеперь имеет методhide_index()чтобы определить, будет ли индекс отображаться в выводе (GH 14194)pandas.io.formats.style.Stylerтеперь имеет методhide_columns()для определения, будут ли столбцы скрыты в выводе (GH 14194)Улучшенная формулировка
ValueErrorвызвано вto_datetime()когдаunit=передается с неконвертируемым значением (GH 14350)Series.fillna()теперь принимает Series или dict в качествеvalueдля категориального типа данных (GH 17033)pandas.read_clipboard()обновлено для использования qtpy с откатом на PyQt5 и затем PyQt4, добавлена совместимость с Python3 и несколькими python-qt биндингами (GH 17722)Улучшенная формулировка
ValueErrorвызвано вread_csv()когдаusecolsаргумент не может соответствовать всем столбцам. (GH 17301)DataFrame.corrwith()теперь молча удаляет нечисловые столбцы при передаче Series. Ранее возникало исключение (GH 18570).IntervalIndexтеперь поддерживает учитывающие часовой поясIntervalобъекты (GH 18537, GH 18538)Series()/DataFrame()автодополнение также возвращает идентификаторы на первом уровнеMultiIndex(). (GH 16326)read_excel()получилnrowsпараметр (GH 16645)DataFrame.append()теперь может в большем числе случаев сохранять тип столбцов вызывающего dataframe (например, если оба являютсяCategoricalIndex) (GH 18359)DataFrame.to_json()иSeries.to_json()теперь принимаетindexаргумент, который позволяет пользователю исключить индекс из вывода JSON (GH 17394)IntervalIndex.to_tuples()получилna_tupleпараметр для управления, возвращается ли NA как кортеж NA или сам NA (GH 18756)Categorical.rename_categories,CategoricalIndex.rename_categoriesиSeries.cat.rename_categoriesтеперь могут принимать вызываемый объект в качестве аргумента (GH 18862)IntervalиIntervalIndexполучилиlengthатрибут (GH 18789)Resamplerобъекты теперь имеют работающийResampler.pipeметод. Ранее вызовы кpipeбыли перенаправлены вmeanметод (GH 17905).is_scalar()теперь возвращаетTrueдляDateOffsetобъекты (GH 18943).DataFrame.pivot()теперь принимает список дляvalues=kwarg (GH 17160).Добавлен
pandas.api.extensions.register_dataframe_accessor(),pandas.api.extensions.register_series_accessor(), иpandas.api.extensions.register_index_accessor(), аксессор для библиотек, зависимых от pandas, чтобы регистрировать пользовательские аксессоры, такие как.catдля объектов pandas. См. Регистрация пользовательских аксессоров для получения дополнительной информации (GH 14781).IntervalIndex.astypeтеперь поддерживает преобразования между подтипами при передачеIntervalDtype(GH 19197)IntervalIndexи связанные с ним методы конструктора (from_arrays,from_breaks,from_tuples) получилиdtypeпараметр (GH 19262)Добавлен
SeriesGroupBy.is_monotonic_increasing()иSeriesGroupBy.is_monotonic_decreasing()(GH 17015)Для унаследованных
DataFrames,DataFrame.apply()теперь сохранитSeriesподкласс (если определен) при передаче данных применяемой функции (GH 19822)DataFrame.from_dict()теперь принимаетcolumnsаргумент, который можно использовать для указания имён столбцов, когдаorient='index'используется (GH 18529)Добавлена опция
display.html.use_mathjaxтак MathJax может быть отключен при отображении таблиц вJupyterблокноты (GH 19856, GH 19824)DataFrame.replace()теперь поддерживаетmethodпараметр, который можно использовать для указания метода замены, когдаto_replaceявляется скаляром, списком или кортежем иvalueявляетсяNone(GH 19632)Timestamp.month_name(),DatetimeIndex.month_name(), иSeries.dt.month_name()теперь доступны (GH 12805)Timestamp.day_name()иDatetimeIndex.day_name()теперь доступны для возврата названий дней с указанной локалью (GH 12806)DataFrame.to_sql()теперь выполняет множественную вставку, если базовое соединение поддерживает её, вместо вставки построчно.SQLAlchemyдиалекты, поддерживающие вставку нескольких значений, включают:mysql,postgresql,sqliteи любой диалект сsupports_multivalues_insert. (GH 14315, GH 8953)read_html()теперь принимаетdisplayed_onlyключевой аргумент для управления тем, анализируются ли скрытые элементы (Trueпо умолчанию) (GH 20027)read_html()теперь читает всеэлементы в, а не только первый. (GH 20690)
Rolling.quantile()иExpanding.quantile()теперь принимаютinterpolationключевое слово,linearпо умолчанию (GH 20497)поддерживается сжатие zip через
compression=zipвDataFrame.to_pickle(),Series.to_pickle(),DataFrame.to_csv(),Series.to_csv(),DataFrame.to_json(),Series.to_json(). (GH 17778)WeekOfMonthконструктор теперь поддерживаетn=0(GH 20517).DataFrameиSeriesтеперь поддерживают матричное умножение (@) оператор (GH 10259) для Python>=3.5Обновлено
DataFrame.to_gbq()иpandas.read_gbq()сигнатуру и документацию, чтобы отразить изменения из версии 0.4.0 библиотеки pandas-gbq. Добавляет intersphinx-сопоставление с библиотекой pandas-gbq. (GH 20564)Добавлен новый модуль записи для экспорта файлов Stata dta в версии 117,
StataWriter117. Этот формат поддерживает экспорт строк длиной до 2 000 000 символов (GH 16450)to_hdf()иread_hdf()теперь принимаетerrorsключевой аргумент для управления обработкой ошибок кодировки (GH 20835)cut()получилduplicates='raise'|'drop'опцию для управления вызовом ошибки при дублировании границ (GH 20947)date_range(),timedelta_range(), иinterval_range()теперь возвращает линейно распределенный индекс, еслиstart,stop, иperiodsуказаны, ноfreqне является. (GH 20808, GH 20983, GH 20976)Обратно несовместимые изменения API#
Минимальные версии зависимостей увеличены#
Мы обновили минимальные поддерживаемые версии зависимостей (GH 15184). Если установлено, теперь требуется:
Пакет
Минимальная версия
Обязательно
Проблема
python-dateutil
2.5.0
X
openpyxl
2.4.0
beautifulsoup4
4.2.1
setuptools
24.2.0
Создание из словарей сохраняет порядок вставки словаря для Python 3.6+#
До Python 3.6 словари в Python не имели формально определённого порядка. Для версий Python 3.6 и выше словари упорядочены по порядку вставки, см. PEP 468. pandas будет использовать порядок вставки словаря при создании
SeriesилиDataFrameиз словаря, и вы используете версию Python 3.6 или выше. (GH 19884)Предыдущее поведение (и текущее поведение, если на Python < 3.6):
In [16]: pd.Series({'Income': 2000, ....: 'Expenses': -1500, ....: 'Taxes': -200, ....: 'Net result': 300}) Out[16]: Expenses -1500 Income 2000 Net result 300 Taxes -200 dtype: int64
Обратите внимание, что Series выше упорядочен по алфавиту по значениям индекса.
Новое поведение (для Python >= 3.6):
In [72]: pd.Series({'Income': 2000, ....: 'Expenses': -1500, ....: 'Taxes': -200, ....: 'Net result': 300}) ....: Out[72]: Income 2000 Expenses -1500 Taxes -200 Net result 300 Length: 4, dtype: int64
Обратите внимание, что Series теперь упорядочены по порядку вставки. Это новое поведение используется для всех соответствующих типов pandas (
Series,DataFrame,SparseSeriesиSparseDataFrame).Если вы хотите сохранить старое поведение при использовании Python >= 3.6, вы можете использовать
.sort_index():In [73]: pd.Series({'Income': 2000, ....: 'Expenses': -1500, ....: 'Taxes': -200, ....: 'Net result': 300}).sort_index() ....: Out[73]: Expenses -1500 Income 2000 Net result 300 Taxes -200 Length: 4, dtype: int64
Устаревание Panel#
Panelбыл устаревшим в релизе 0.20.x, отображаясь какDeprecationWarning. ИспользованиеPanelтеперь будет показыватьFutureWarning. Рекомендуемый способ представления 3-D данных — с помощьюMultiIndexнаDataFrameчерезto_frame()или с пакет xarray. pandas предоставляетto_xarray()метод для автоматизации этого преобразования (GH 13563, GH 18324).In [75]: import pandas._testing as tm In [76]: p = tm.makePanel() In [77]: p Out[77]:
Dimensions: 3 (items) x 3 (major_axis) x 4 (minor_axis) Items axis: ItemA to ItemC Major_axis axis: 2000-01-03 00:00:00 to 2000-01-05 00:00:00 Minor_axis axis: A to D Преобразовать в DataFrame с MultiIndex
In [78]: p.to_frame() Out[78]: ItemA ItemB ItemC major minor 2000-01-03 A 0.469112 0.721555 0.404705 B -1.135632 0.271860 -1.039268 C 0.119209 0.276232 -1.344312 D -2.104569 0.113648 -0.109050 2000-01-04 A -0.282863 -0.706771 0.577046 B 1.212112 -0.424972 -0.370647 C -1.044236 -1.087401 0.844885 D -0.494929 -1.478427 1.643563 2000-01-05 A -1.509059 -1.039575 -1.715002 B -0.173215 0.567020 -1.157892 C -0.861849 -0.673690 1.075770 D 1.071804 0.524988 -1.469388 [12 rows x 3 columns]
Преобразовать в DataArray xarray
In [79]: p.to_xarray() Out[79]:
array([[[ 0.469112, -1.135632, 0.119209, -2.104569], [-0.282863, 1.212112, -1.044236, -0.494929], [-1.509059, -0.173215, -0.861849, 1.071804]], [[ 0.721555, 0.27186 , 0.276232, 0.113648], [-0.706771, -0.424972, -1.087401, -1.478427], [-1.039575, 0.56702 , -0.67369 , 0.524988]], [[ 0.404705, -1.039268, -1.344312, -0.10905 ], [ 0.577046, -0.370647, 0.844885, 1.643563], [-1.715002, -1.157892, 1.07577 , -1.469388]]]) Coordinates: * items (items) object 'ItemA' 'ItemB' 'ItemC' * major_axis (major_axis) datetime64[ns] 2000-01-03 2000-01-04 2000-01-05 * minor_axis (minor_axis) object 'A' 'B' 'C' 'D' удаления из pandas.core.common#
Следующие сообщения об ошибках и предупреждениях удалены из
pandas.core.common(GH 13634, GH 19769):PerformanceWarningUnsupportedFunctionCallUnsortedIndexErrorAbstractMethodError
Они доступны при импорте из
pandas.errors(с версии 0.19.0).Изменения для вывода
DataFrame.applyпоследовательный#DataFrame.apply()был непоследовательным при применении произвольной пользовательской функции, возвращающей списокоподобный объект сaxis=1. Устранены несколько ошибок и несоответствий. Если примененная функция возвращает Series, то pandas вернет DataFrame; в противном случае будет возвращена Series, включая случай, когда список (например,tupleилиlistвозвращается) (GH 16353, GH 17437, GH 17970, GH 17348, GH 17892, GH 18573, GH 17602, GH 18775, GH 18901, GH 18919).In [74]: df = pd.DataFrame(np.tile(np.arange(3), 6).reshape(6, -1) + 1, ....: columns=['A', 'B', 'C']) ....: In [75]: df Out[75]: A B C 0 1 2 3 1 1 2 3 2 1 2 3 3 1 2 3 4 1 2 3 5 1 2 3 [6 rows x 3 columns]
Предыдущее поведение: если возвращаемая форма случайно совпадала с длиной исходных столбцов, это возвращало
DataFrame. Если возвращаемая форма не совпала, тоSeriesвозвращался со списками.In [3]: df.apply(lambda x: [1, 2, 3], axis=1) Out[3]: A B C 0 1 2 3 1 1 2 3 2 1 2 3 3 1 2 3 4 1 2 3 5 1 2 3 In [4]: df.apply(lambda x: [1, 2], axis=1) Out[4]: 0 [1, 2] 1 [1, 2] 2 [1, 2] 3 [1, 2] 4 [1, 2] 5 [1, 2] dtype: object
Новое поведение: Когда применяемая функция возвращает список, это теперь всегда возвращает
Series.In [76]: df.apply(lambda x: [1, 2, 3], axis=1) Out[76]: 0 [1, 2, 3] 1 [1, 2, 3] 2 [1, 2, 3] 3 [1, 2, 3] 4 [1, 2, 3] 5 [1, 2, 3] Length: 6, dtype: object In [77]: df.apply(lambda x: [1, 2], axis=1) Out[77]: 0 [1, 2] 1 [1, 2] 2 [1, 2] 3 [1, 2] 4 [1, 2] 5 [1, 2] Length: 6, dtype: object
Чтобы иметь расширенные столбцы, вы можете использовать
result_type='expand'In [78]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='expand') Out[78]: 0 1 2 0 1 2 3 1 1 2 3 2 1 2 3 3 1 2 3 4 1 2 3 5 1 2 3 [6 rows x 3 columns]
Чтобы транслировать результат по исходным столбцам (старое поведение для списков правильной длины), можно использовать
result_type='broadcast'. Форма должна соответствовать исходным столбцам.In [79]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='broadcast') Out[79]: A B C 0 1 2 3 1 1 2 3 2 1 2 3 3 1 2 3 4 1 2 3 5 1 2 3 [6 rows x 3 columns]
Возврат
Seriesпозволяет контролировать точную структуру возврата и имена столбцов:In [80]: df.apply(lambda x: pd.Series([1, 2, 3], index=['D', 'E', 'F']), axis=1) Out[80]: D E F 0 1 2 3 1 1 2 3 2 1 2 3 3 1 2 3 4 1 2 3 5 1 2 3 [6 rows x 3 columns]
Конкатенация больше не будет сортировать#
В будущей версии pandas
pandas.concat()BooleanArray реализует логику Клин (иногда называемую трёхзначной логикой) для логических операций. См.sortне указан и ось неконкатенации не выровнена (GH 4588).In [81]: df1 = pd.DataFrame({"a": [1, 2], "b": [1, 2]}, columns=['b', 'a']) In [82]: df2 = pd.DataFrame({"a": [4, 5]}) In [83]: pd.concat([df1, df2]) Out[83]: b a 0 1.0 1 1 2.0 2 0 NaN 4 1 NaN 5 [4 rows x 2 columns]
Чтобы сохранить предыдущее поведение (сортировку) и отключить предупреждение, передайте
sort=TrueIn [84]: pd.concat([df1, df2], sort=True) Out[84]: a b 0 1 1.0 1 2 2.0 0 4 NaN 1 5 NaN [4 rows x 2 columns]
Чтобы принять будущее поведение (без сортировки), передайте
sort=FalseОбратите внимание, что это изменение также применяется к
DataFrame.append(), который также получилsortключевое слово для управления этим поведением.Изменения сборки#
Деление индекса на ноль заполняется корректно#
Операции деления на
Indexи подклассы теперь будут заполнять деление положительных чисел на нольnp.inf, деление отрицательных чисел на ноль с-np.infи0 / 0сnp.nan. Это соответствует существующемуSeriesповедение. (GH 19322, GH 19347)Предыдущее поведение:
In [6]: index = pd.Int64Index([-1, 0, 1]) In [7]: index / 0 Out[7]: Int64Index([0, 0, 0], dtype='int64') # Previous behavior yielded different results depending on the type of zero in the divisor In [8]: index / 0.0 Out[8]: Float64Index([-inf, nan, inf], dtype='float64') In [9]: index = pd.UInt64Index([0, 1]) In [10]: index / np.array([0, 0], dtype=np.uint64) Out[10]: UInt64Index([0, 0], dtype='uint64') In [11]: pd.RangeIndex(1, 5) / 0 ZeroDivisionError: integer division or modulo by zero
Текущее поведение:
In [12]: index = pd.Int64Index([-1, 0, 1]) # division by zero gives -infinity where negative, # +infinity where positive, and NaN for 0 / 0 In [13]: index / 0 # The result of division by zero should not depend on # whether the zero is int or float In [14]: index / 0.0 In [15]: index = pd.UInt64Index([0, 1]) In [16]: index / np.array([0, 0], dtype=np.uint64) In [17]: pd.RangeIndex(1, 5) / 0
Извлечение совпадающих шаблонов из строк#
По умолчанию, извлечение совпадающих шаблонов из строк с
str.extract()раньше возвращалSeriesесли извлекалась одна группа (DataFrameесли было извлечено более одной группы). Начиная с pandas 0.23.0str.extract()всегда возвращаетDataFrame, если толькоexpandустановлено вFalse. Наконец,Noneбыло допустимым значением дляexpandпараметр (который был эквивалентенFalse), но теперь вызываетValueError. (GH 11386)Предыдущее поведение:
In [1]: s = pd.Series(['number 10', '12 eggs']) In [2]: extracted = s.str.extract(r'.*(\d\d).*') In [3]: extracted Out [3]: 0 10 1 12 dtype: object In [4]: type(extracted) Out [4]: pandas.core.series.Series
Новое поведение:
In [85]: s = pd.Series(['number 10', '12 eggs']) In [86]: extracted = s.str.extract(r'.*(\d\d).*') In [87]: extracted Out[87]: 0 0 10 1 12 [2 rows x 1 columns] In [88]: type(extracted) Out[88]: pandas.core.frame.DataFrame
Чтобы восстановить предыдущее поведение, просто установите
expandtoFalse:In [89]: s = pd.Series(['number 10', '12 eggs']) In [90]: extracted = s.str.extract(r'.*(\d\d).*', expand=False) In [91]: extracted Out[91]: 0 10 1 12 Length: 2, dtype: object In [92]: type(extracted) Out[92]: pandas.core.series.Series
Значение по умолчанию для
orderedпараметрCategoricalDtype#Значение по умолчанию для
orderedпараметр дляCategoricalDtypeизменился сFalsetoNoneдля разрешения обновленияcategoriesбез влияния наordered. Поведение должно оставаться согласованным для нижестоящих объектов, таких какCategorical(GH 18790)В предыдущих версиях значение по умолчанию для
orderedпараметр былFalse. Это потенциально может привести кorderedпараметр непреднамеренно изменяется сTruetoFalseкогда пользователи пытаются обновитьcategoriesiforderedне указана явно, так как она молча будет использовать значение по умолчаниюFalse. Новое поведение дляordered=Noneсостоит в сохранении существующего значенияordered.Новое поведение:
In [2]: from pandas.api.types import CategoricalDtype In [3]: cat = pd.Categorical(list('abcaba'), ordered=True, categories=list('cba')) In [4]: cat Out[4]: [a, b, c, a, b, a] Categories (3, object): [c < b < a] In [5]: cdt = CategoricalDtype(categories=list('cbad')) In [6]: cat.astype(cdt) Out[6]: [a, b, c, a, b, a] Categories (4, object): [c < b < a < d]
Обратите внимание в примере выше, что преобразованный
Categoricalсохранилordered=True. Значение по умолчанию дляorderedостался какFalse, преобразованныйCategoricalстал бы неупорядоченным, несмотря наordered=Falseникогда не указывается явно. Чтобы изменить значениеordered, явно передайте его в новый тип данных, например.CategoricalDtype(categories=list('cbad'), ordered=False).Обратите внимание, что непреднамеренное преобразование
orderedобсуждаемые выше не возникали в предыдущих версиях из-за отдельных ошибок, которые предотвращалиastypeот выполнения любого типа преобразования категории в категорию (GH 10696, GH 18593). Эти ошибки были исправлены в этом выпуске, что мотивировало изменение значения по умолчанию дляordered.Улучшенное форматирование DataFrame в терминале#
Ранее значение по умолчанию для максимального количества столбцов было
pd.options.display.max_columns=20. Это означало, что относительно широкие датафреймы не помещались в ширину терминала, и pandas добавлял переносы строк для отображения этих 20 столбцов. Это приводило к выводу, который был относительно трудно читаемым: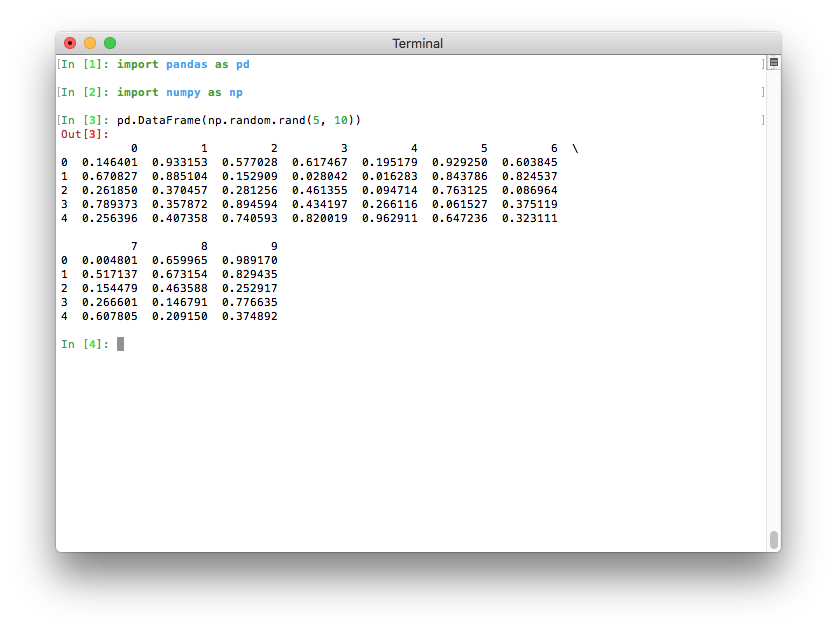
Если Python запущен в терминале, максимальное количество столбцов теперь определяется автоматически, чтобы напечатанный фрейм данных помещался в текущую ширину терминала (
pd.options.display.max_columns=0) (GH 17023). Если Python запущен как ядро Jupyter (например, Jupyter QtConsole или блокнот Jupyter, а также во многих IDE), это значение не может быть определено автоматически и поэтому устанавливается в20как в предыдущих версиях. В терминале это дает гораздо более приятный вывод: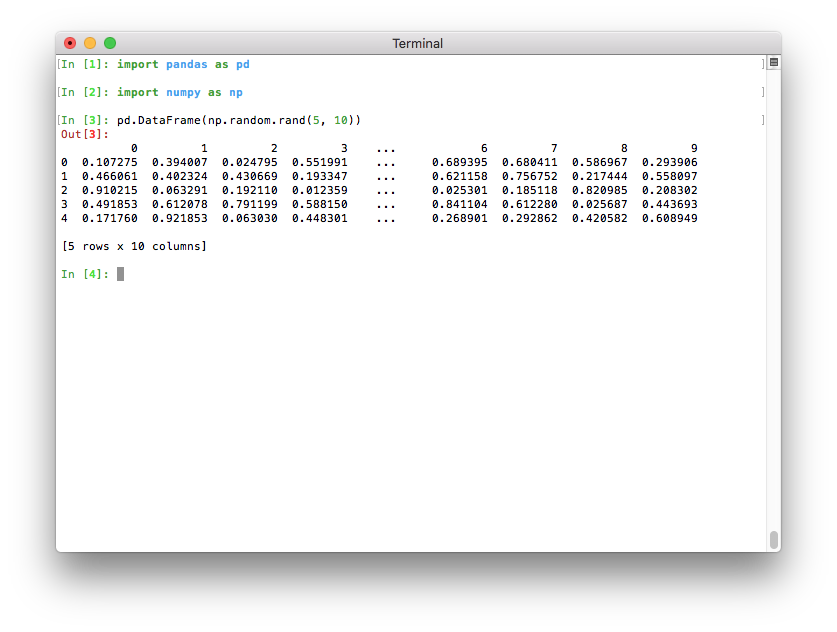
Обратите внимание, что если вам не нравится новое значение по умолчанию, вы всегда можете установить эту опцию самостоятельно. Чтобы вернуться к старой настройке, вы можете выполнить эту строку:
pd.options.display.max_columns = 20
Изменения в API Datetimelike#
По умолчанию
Timedeltaконструктор теперь принимаетISO 8601 Durationстрока в качестве аргумента (GH 19040)Вычитание
NaTизSeriesсdtype='datetime64[ns]'возвращаетSeriesсdtype='timedelta64[ns]'вместоdtype='datetime64[ns]'(GH 18808)Сложение или вычитание
NaTизTimedeltaIndexвернетTimedeltaIndexвместоDatetimeIndex(GH 19124)DatetimeIndex.shift()иTimedeltaIndex.shift()теперь будет вызыватьNullFrequencyError(который наследует отValueError, которая возникала в старых версиях) когда частота объекта индексаNone(GH 19147)Сложение и вычитание
NaNизSeriesсdtype='timedelta64[ns]'вызоветTypeErrorвместо обработкиNaNкакNaT(GH 19274)NaTделение сdatetime.timedeltaтеперь вернетNaNвместо вызова исключения (GH 17876)Операции между
Seriesс типом данныхdtype='datetime64[ns]'иPeriodIndexбудет корректно вызыватьTypeError(GH 18850)Вычитание
Seriesс учетом часового поясаdtype='datetime64[ns]'с несовпадающими часовыми поясами вызоветTypeErrorвместоValueError(GH 18817)Timestampбольше не будет молча игнорировать неиспользуемые или недопустимыеtzилиtzinfoименованные аргументы (GH 17690)Timestampбольше не будет молча игнорировать недопустимыеfreqаргументы (GH 5168)CacheableOffsetиWeekDayбольше не доступны вpandas.tseries.offsetsмодуль (GH 17830)pandas.tseries.frequencies.get_freq_group()иpandas.tseries.frequencies.DAYSудалены из публичного API (GH 18034)Series.truncate()иDataFrame.truncate()вызоветValueErrorесли индекс не отсортирован, вместо бесполезногоKeyError(GH 17935)Series.firstиDataFrame.firstтеперь вызоветTypeErrorвместоNotImplementedErrorкогда индекс не являетсяDatetimeIndex(GH 20725).Series.lastиDataFrame.lastтеперь вызоветTypeErrorвместоNotImplementedErrorкогда индекс не являетсяDatetimeIndex(GH 20725).Ограниченный
DateOffsetименованные аргументы. Ранее,DateOffsetподклассы разрешали произвольные ключевые аргументы, что могло привести к неожиданному поведению. Теперь будут приниматься только допустимые аргументы. (GH 17176, GH 18226).pandas.merge()предоставляет более информативное сообщение об ошибке при попытке слияния по колонкам с учётом часового пояса и без него (GH 15800)Для
DatetimeIndexиTimedeltaIndexсfreq=None, сложение или вычитание массива с целочисленным типом данных илиIndexвызовет исключениеNullFrequencyErrorвместоTypeError(GH 19895)Timestampконструктор теперь принимаетnanosecondключевой или позиционный аргумент (GH 18898)DatetimeIndexтеперь вызоветAttributeErrorкогдаtzатрибут устанавливается после создания экземпляра (GH 3746)DatetimeIndexсpytztimezone теперь будет возвращать согласованныйpytztimezone (GH 18595)
Другие изменения API#
Series.astype()иIndex.astype()с несовместимым dtype теперь вызоветTypeErrorа неValueError(GH 18231)Seriesконструкция сobjectdtyped tz-aware datetime иdtype=objectесли указано, теперь будет возвращатьobjectтипизированныйSeries, ранее это определяло тип datetime (GH 18231)A
Seriesofdtype=categoryсозданный из пустогоdictтеперь будет иметь категорииdtype=objectвместоdtype=float64, согласованно со случаем передачи пустого списка (GH 18515)Все-NaN уровни в
MultiIndexтеперь назначаютсяfloatвместоobjectdtype, обеспечивая согласованность сIndex(GH 17929).Названия уровней
MultiIndex(когда не None) теперь должны быть уникальными: попытка создатьMultiIndexс повторяющимися именами вызоветValueError(GH 18872)Как создание, так и переименование
Index/MultiIndexс нехешируемымname/namesтеперь будет вызыватьTypeError(GH 20527)Index.map()теперь может приниматьSeriesи объекты ввода словаря (GH 12756, GH 18482, GH 18509).DataFrame.unstack()теперь по умолчанию будет заполнятьсяnp.nanдляobjectстолбцов. (GH 12815)IntervalIndexконструктор вызовет исключение, еслиclosedпараметр конфликтует с тем, как входные данные интерпретируются как закрытые (GH 18421)Вставка пропущенных значений в индексы будет работать для всех типов индексов и автоматически вставит правильный тип пропущенного значения (
NaN,NaT, и т.д.) независимо от переданного типа (GH 18295)При создании с повторяющимися метками,
MultiIndexтеперь вызываетValueError. (GH 17464)Series.fillna()теперь вызываетTypeErrorвместоValueErrorкогда передается список, кортеж или DataFrame в качествеvalue(GH 18293)pandas.DataFrame.merge()больше не приводит кfloatстолбец вobjectпри слиянии поintиfloatстолбцы (GH 16572)pandas.merge()теперь вызываетValueErrorпри попытке слияния с несовместимыми типами данных (GH 9780)Значение NA по умолчанию для
UInt64Indexизменилось с 0 наNaN, что влияет на методы, которые маскируют с NA, такие какUInt64Index.where()(GH 18398)Рефакторинг
setup.pyиспользоватьfind_packagesвместо явного перечисления всех подпакетов (GH 18535)Изменён порядок ключевых аргументов в
read_excel()для соответствияread_csv()(GH 16672)wide_to_long()ранее сохранял числовые суффиксы какobjectdtype. Теперь они преобразуются в числовые, если возможно (GH 17627)В
read_excel(),commentаргумент теперь доступен как именованный параметр (GH 18735)Изменён порядок ключевых аргументов в
read_excel()для соответствияread_csv()(GH 16672)Опции
html.borderиmode.use_inf_as_nullбыли объявлены устаревшими в предыдущих версиях, теперь они будут отображатьсяFutureWarningа неDeprecationWarning(GH 19003)IntervalIndexиIntervalDtypeбольше не поддерживает категориальные, объектные и строковые подтипы (GH 19016)IntervalDtypeтеперь возвращаетTrueпри сравнении с'interval'независимо от подтипа, иIntervalDtype.nameтеперь возвращает'interval'независимо от подтипа (GH 18980)KeyErrorтеперь вызывает исключение вместоValueErrorвdrop(),drop(),drop(),drop()при удалении несуществующего элемента в оси с дубликатами (GH 19186)Series.to_csv()теперь принимаетcompressionаргумент, который работает так же, какcompressionаргумент вDataFrame.to_csv()(GH 18958)Операции над множествами (объединение, разность…) на
IntervalIndexс несовместимыми типами индексов теперь вызываетTypeErrorа неValueError(GH 19329)DateOffsetобъекты отображаются проще, например,Categorical.fillnaтеперь проверяет своиvalueиmethodименованные аргументы. Теперь возникает ошибка, когда указаны оба или ни один из них, что соответствует поведениюSeries.fillna()(GH 19682)pd.to_datetime('today')теперь возвращает дату и время, согласованно сpd.Timestamp('today'); ранееpd.to_datetime('today')возвращал.normalized()datetime (GH 19935)Series.str.replace()теперь принимает необязательныйregexключевое слово, которое при установке вFalse, использует замену строковых литералов вместо замены по регулярному выражению (GH 16808)DatetimeIndex.strftime()иPeriodIndex.strftime()теперь возвращаетIndexвместо массива numpy для согласованности с аналогичными аксессорами (GH 20127)Создание Series из списка длины 1 больше не транслирует этот список при указании более длинного индекса (GH 19714, GH 20391).
DataFrame.to_dict()сorient='index'больше не преобразует целочисленные столбцы в float для DataFrame только с целочисленными и float столбцами (GH 18580)Пользовательская функция, которая передается в
Series.rolling().aggregate(),DataFrame.rolling().aggregate(), или его расширяющиеся аналоги, теперь всегда передаватьсяSeries, а неnp.array;.apply()имеет толькоrawключевое слово, см. здесь. Это согласуется с сигнатурами.aggregate()по всему pandas (GH 20584)Типы Rolling и Expanding вызывают
NotImplementedErrorпри итерации (GH 11704).
Устаревшие функции#
Series.from_arrayиSparseSeries.from_arrayустарели. Используйте обычный конструкторSeries(..)иSparseSeries(..)вместо (GH 18213).DataFrame.as_matrixустарел. ИспользуйтеDataFrame.valuesвместо (GH 18458).Series.asobject,DatetimeIndex.asobject,PeriodIndex.asobjectиTimeDeltaIndex.asobjectбыли устаревшими. Используйте.astype(object)вместо (GH 18572)Группировка по кортежу ключей теперь выдает
FutureWarningи является устаревшим. В будущем кортеж, переданный в'by'всегда будет ссылаться на один ключ, который является фактическим кортежем, вместо того чтобы рассматривать кортеж как несколько ключей. Чтобы сохранить предыдущее поведение, используйте список вместо кортежа (GH 18314)Series.validустарел. ИспользуйтеSeries.dropna()вместо (GH 18800).read_excel()устарелskip_footerпараметр. Используйтеskipfooterвместо (GH 18836)ExcelFile.parse()устарелsheetnameв пользуsheet_nameдля согласованности сread_excel()(GH 20920).The
is_copyатрибут устарел и будет удалён в будущей версии (GH 18801).IntervalIndex.from_intervalsустарел в пользуIntervalIndexконструктор (GH 19263)DataFrame.from_itemsустарел. ИспользуйтеDataFrame.from_dict()вместо, илиDataFrame.from_dict(OrderedDict())если вы хотите сохранить порядок ключей (GH 17320, GH 17312)Индексирование
MultiIndexилиFloatIndexсо списком, содержащим некоторые отсутствующие ключи, теперь покажетFutureWarning, что согласуется с другими типами индексов (GH 17758).The
broadcastпараметр.apply()устарел в пользуresult_type='broadcast'(GH 18577)The
reduceпараметр.apply()устарел в пользуresult_type='reduce'(GH 18577)The
orderпараметрfactorize()устарел и будет удален в будущем релизе (GH 19727)Timestamp.weekday_name,DatetimeIndex.weekday_name, иSeries.dt.weekday_nameустарели в пользуTimestamp.day_name(),DatetimeIndex.day_name(), иSeries.dt.day_name()(GH 12806)pandas.tseries.plotting.tsplotустарел. ИспользуйтеSeries.plot()вместо (GH 18627)Index.summary()устарел и будет удален в будущей версии (GH 18217)NDFrame.get_ftype_counts()устарел и будет удален в будущей версии (GH 18243)The
convert_datetime64параметр вDataFrame.to_records()был устаревшим и будет удален в будущей версии. Ошибка NumPy, мотивировавшая этот параметр, была исправлена. Значение по умолчанию для этого параметра также изменилось сTruetoNone(GH 18160).Series.rolling().apply(),DataFrame.rolling().apply(),Series.expanding().apply(), иDataFrame.expanding().apply()устарела передачаnp.arrayпо умолчанию. Потребуется передать новыйrawпараметр, чтобы явно указать, что передается (GH 20584)The
data,base,strides,flagsиitemsizeсвойстваSeriesиIndexклассы устарели и будут удалены в будущей версии (GH 20419).DatetimeIndex.offsetустарел. ИспользуйтеDatetimeIndex.freqвместо (GH 20716)Целочисленное деление между целочисленным ndarray и
Timedeltaустарел. Разделите наTimedelta.valueвместо (GH 19761)Установка
PeriodIndex.freq(что не гарантировало корректной работы) устарело. ИспользуйтеPeriodIndex.asfreq()вместо (GH 20678)Index.get_duplicates()устарел и будет удален в будущей версии (GH 20239)Предыдущее поведение по умолчанию для отрицательных индексов в
Categorical.takeустарел. В будущей версии его значение изменится с пропущенных значений на позиционные индексы справа. Будущее поведение согласуется сSeries.take()(GH 20664).Передача нескольких осей в
axisпараметр вDataFrame.dropna()устарел и будет удален в будущей версии (GH 20987)
Удаление устаревших функций/изменений предыдущих версий#
Предупреждения об устаревшем использовании
Categorical(codes, categories), которые возникали, например, когда первые два аргумента вCategorical()имели разные типы данных, и рекомендовали использованиеCategorical.from_codes, теперь удалены (GH 8074)The
levelsиlabelsатрибутыMultiIndexбольше не может быть установлен напрямую (GH 4039).pd.tseries.util.pivot_annualбыл удален (устарел с версии v0.19). Используйтеpivot_tableвместо (GH 18370)pd.tseries.util.isleapyearбыл удален (устарел с версии v0.19). Используйте.is_leap_yearсвойство в Datetime-подобных объектах вместо (GH 18370)pd.ordered_mergeбыл удален (устарел с версии v0.19). Используйтеpd.merge_orderedвместо (GH 18459)The
SparseListкласс был удален (GH 14007)The
pandas.io.wbиpandas.io.dataзаглушки модулей были удалены (GH 13735)Categorical.from_arrayбыл удален (GH 13854)The
freqиhowпараметры были удалены изrolling/expanding/ewmметоды DataFrame и Series (устарели с v0.18). Вместо этого выполните ресемплинг перед вызовом методов. (GH 18601 & GH 18668)DatetimeIndex.to_datetime,Timestamp.to_datetime,PeriodIndex.to_datetime, иIndex.to_datetimeбыли удалены (GH 8254, GH 14096, GH 14113)read_csv()удалилskip_footerпараметр (GH 13386)read_csv()удалилas_recarrayпараметр (GH 13373)read_csv()удалилbuffer_linesпараметр (GH 13360)read_csv()удалилcompact_intsиuse_unsignedпараметры (GH 13323)The
Timestampкласс удалилoffsetатрибут в пользуfreq(GH 13593)The
Series,Categorical, иIndexклассы удалилиreshapeметод (GH 13012)pandas.tseries.frequencies.get_standard_freqбыл удалён в пользуpandas.tseries.frequencies.to_offset(freq).rule_code(GH 13874)The
freqstrключевое слово было удалено изpandas.tseries.frequencies.to_offsetв пользуfreq(GH 13874)The
Panel4DиPanelNDклассы были удалены (GH 13776)The
Panelкласс удалилto_longиtoLongметоды (GH 19077)Опции
display.line_withиdisplay.heightудалены в пользуdisplay.widthиdisplay.max_rowsсоответственно (GH 4391, GH 19107)The
labelsатрибутCategoricalкласс был удалён в пользуCategorical.codes(GH 7768)The
flavorпараметр был удален изto_sql()метод (GH 13611)Модули
pandas.tools.hashingиpandas.util.hashingбыли удалены (GH 16223)Функции верхнего уровня
pd.rolling_*,pd.expanding_*иpd.ewm*были удалены (устарели с версии v0.18). Вместо этого используйте методы DataFrame/Seriesrolling,expandingиewm(GH 18723)Импорты из
pandas.core.commonдля функций, таких какis_datetime64_dtypeтеперь удалены. Они находятся вpandas.api.types. (GH 13634, GH 19769)The
infer_dstключевое слово вSeries.tz_localize(),DatetimeIndex.tz_localize()иDatetimeIndexбыли удалены.infer_dst=Trueэквивалентноambiguous='infer', иinfer_dst=Falsetoambiguous='raise'(GH 7963).Когда
.resample()было изменено с немедленной на отложенную операцию, как.groupby()в v0.18.0 мы внедрили совместимость (сFutureWarning), поэтому операции продолжали бы работать. Это теперь полностью удалено, поэтомуResamplerбольше не будет выполнять операции совместимости вперед (GH 20554)Удалить давно устаревшие
axis=Noneпараметр из.replace()(GH 20271)
Улучшения производительности#
Индексаторы на
SeriesилиDataFrameбольше не создает цикл ссылок (GH 17956)Добавлен ключевой аргумент,
cache, вto_datetime()что улучшило производительность преобразования повторяющихся аргументов даты и времени (GH 11665)DateOffsetпроизводительность арифметических операций улучшена (GH 18218)Преобразование
SeriesofTimedeltaобъекты в дни, секунды и т.д. ускорены за счёт векторизации базовых методов (GH 18092)Улучшена производительность
.map()сSeries/dictвходные данные (GH 15081)Переопределенный
Timedeltaсвойства days, seconds и microseconds были удалены, вместо них используются их встроенные версии в Python (GH 18242)Seriesконструкция уменьшит количество копий входных данных в некоторых случаях (GH 17449)Улучшена производительность
Series.dt.date()иDatetimeIndex.date()(GH 18058)Улучшена производительность
Series.dt.time()иDatetimeIndex.time()(GH 18461)Улучшена производительность
IntervalIndex.symmetric_difference()(GH 18475)Улучшена производительность
DatetimeIndexиSeriesарифметические операции с частотами Business-Month и Business-Quarter (GH 18489)Series()/DataFrame()ограничение автодополнения вкладками до 100 значений для повышения производительности. (GH 18587)Улучшена производительность
DataFrame.median()сaxis=1когда bottleneck не установлен (GH 16468)Улучшена производительность
MultiIndex.get_loc()для больших индексов, за счет снижения производительности для маленьких (GH 18519)Улучшена производительность
MultiIndex.remove_unused_levels()когда нет неиспользуемых уровней, за счет снижения производительности, когда они есть (GH 19289)Улучшена производительность
Index.get_loc()для неуникальных индексов (GH 19478)Улучшена производительность попарного
.rolling()и.expanding()с.cov()и.corr()операции (GH 17917)Улучшена производительность
GroupBy.rank()(GH 15779)Улучшена производительность переменной
.rolling()на.min()и.max()(GH 19521)Улучшена производительность
GroupBy.ffill()иGroupBy.bfill()(GH 11296)Улучшена производительность
GroupBy.any()иGroupBy.all()(GH 15435)Улучшена производительность
GroupBy.pct_change()(GH 19165)Улучшена производительность
Series.isin()в случае категориальных типов данных (GH 20003)Улучшена производительность
getattr(Series, attr)когда Series имеет определенные типы индексов. Это проявлялось в медленном выводе больших Series сDatetimeIndex(GH 19764)Исправлена регрессия производительности для
GroupBy.nth()иGroupBy.last()с некоторыми столбцами типа object (GH 19283)Улучшена производительность
Categorical.from_codes()(GH 18501)
Изменения в документации#
Спасибо всем участникам, которые приняли участие в спринте документации pandas, состоявшемся 10 марта. У нас было около 500 участников из более чем 30 мест по всему миру. Вы заметите, что многие из строки документации API значительно улучшены.
Было слишком много одновременных вкладов, чтобы включить заметку о выпуске для каждого улучшения, но это Поиск на GitHub должно дать вам представление о том, сколько строк документации было улучшено.
Особая благодарность Марк Гарсия для организации спринта. Для получения дополнительной информации прочитайте Пост в блоге NumFOCUS подведение итогов спринта.
Исправлено написание «numpy» на «NumPy» и «python» на «Python». (GH 19017)
Согласованность при введении примеров кода, используя либо двоеточие, либо точку. Переписаны некоторые предложения для большей ясности, добавлены более динамичные ссылки на функции, методы и классы.GH 18941, GH 18948, GH 18973, GH 19017)
Добавлена ссылка на
DataFrame.assign()в разделе конкатенации документации по слиянию (GH 18665)
Исправления ошибок#
Категориальный#
Предупреждение
Класс ошибок был внесен в pandas 0.21 с
CategoricalDtypeчто влияет на корректность операций, таких какmerge,concat, и индексация при сравнении нескольких неупорядоченныхCategoricalмассивы, которые имеют одинаковые категории, но в другом порядке. Мы настоятельно рекомендуем обновить или вручную выровнять ваши категории перед выполнением этих операций.Ошибка в
Categorical.equalsвозвращает неверный результат при сравнении двух неупорядоченныхCategoricalмассивы с одинаковыми категориями, но в другом порядке (GH 16603)Ошибка в
pandas.api.types.union_categoricals()возвращает неправильный результат при работе с неупорядоченными категориальными данными, где категории в другом порядке. Это затрагиваетpandas.concat()с категориальными данными (GH 19096).Ошибка в
pandas.merge()возвращает неправильный результат при соединении по несортированномуCategoricalкоторые имели те же категории, но в другом порядке (GH 19551)Ошибка в
CategoricalIndex.get_indexer()возвращая неверный результат, когдаtargetбыл неупорядоченнымCategoricalкоторый имел те же категории, что иselfно в другом порядке (GH 19551)Ошибка в
Index.astype()с категориальным типом данных, где результирующий индекс не преобразуется вCategoricalIndexдля всех типов индекса (GH 18630)Ошибка в
Series.astype()иCategorical.astype()где существующие категориальные данные не обновляются (GH 10696, GH 18593)Ошибка в
Series.str.split()сexpand=Trueнекорректно вызывает IndexError на пустых строках (GH 20002).Ошибка в
Indexконструктор сdtype=CategoricalDtype(...)гдеcategoriesиorderedне поддерживаются (GH 19032)Ошибка в
Seriesконструктор со скаляром иdtype=CategoricalDtype(...)гдеcategoriesиorderedне поддерживаются (GH 19565)Ошибка в
Categorical.__iter__не преобразуя в типы Python (GH 19909)Ошибка в
pandas.factorize()возвращая уникальные коды дляuniques. Теперь возвращаетCategoricalс тем же типом данных, что и входные данные (GH 19721)Ошибка в
pandas.factorize()включая элемент для пропущенных значений вuniquesвозвращаемое значение (GH 19721)Ошибка в
Series.take()с категориальными данными, интерпретируя-1вindicesв качестве маркеров пропущенных значений, а не последнего элемента Series (GH 20664)
Datetimelike#
Ошибка в
Series.__sub__()вычитание не-наносекундногоnp.datetime64объект изSeriesдавал некорректные результаты (GH 7996)Ошибка в
DatetimeIndex,TimedeltaIndexсложение и вычитание нульмерных целочисленных массивов давало некорректные результаты (GH 19012)Ошибка в
DatetimeIndexиTimedeltaIndexгде добавление или вычитание массива изDateOffsetобъекты либо вызывали исключение (np.array,pd.Index) или передавались некорректно (pd.Series) (GH 18849)Ошибка в
Series.__add__()добавление Series с типом данныхtimedelta64[ns]в учитывающий часовой поясDatetimeIndexнеправильно удаленная информация о часовом поясе (GH 13905)Добавление
Periodобъект вdatetimeилиTimestampобъект теперь правильно вызываетTypeError(GH 17983)Ошибка в
Timestampгде сравнение с массивомTimestampобъекты приведут кRecursionError(GH 15183)Ошибка в
Seriesцелочисленное деление при работе со скаляромtimedeltaвызывает исключение (GH 18846)Ошибка в
DatetimeIndexгде repr не показывал значения времени с высокой точностью в конце дня (например, 23:59:59.999999999) (GH 19030)Ошибка в
.astype()в нс-единицы timedelta будет содержать неправильный dtype (GH 19176, GH 19223, GH 12425)Ошибка при вычитании
SeriesизNaTнекорректно возвращаетNaT(GH 19158)Ошибка в
Series.truncate()который вызываетTypeErrorс монотоннымPeriodIndex(GH 17717)Ошибка в
pct_change()используяperiodsиfreqвозвращали выходные данные разной длины (GH 7292)Ошибка в сравнении
DatetimeIndexпротивNoneилиdatetime.dateобъекты, вызывающиеTypeErrorдля==и!=сравнения вместо всех-Falseи все-True, соответственно (GH 19301)Ошибка в
Timestampиto_datetime()где строка, представляющая метку времени, слегка выходящую за границы, будет некорректно округлена вниз вместо вызова исключенияOutOfBoundsDatetime(GH 19382)Ошибка в
Timestamp.floor()DatetimeIndex.floor()где временные метки далеко в будущем и прошлом округлялись некорректно (GH 19206)Ошибка в
to_datetime()где передача даты и времени вне допустимого диапазона сerrors='coerce'иutc=TrueвызоветOutOfBoundsDatetimeвместо разбора вNaT(GH 19612)Ошибка в
DatetimeIndexиTimedeltaIndexсложение и вычитание, где имя возвращаемого объекта не всегда устанавливалось последовательно. (GH 19744)Ошибка в
DatetimeIndexиTimedeltaIndexсложение и вычитание, где операции с массивами numpy вызывалиTypeError(GH 19847)Ошибка в
DatetimeIndexиTimedeltaIndexгде установкаfreqатрибут не был полностью поддерживаем (GH 20678)
Timedelta#
Ошибка в
Timedelta.__mul__()где умножение наNaTвозвращёнNaTвместо вызоваTypeError(GH 19819)Ошибка в
Seriesсdtype='timedelta64[ns]'где сложение или вычитаниеTimedeltaIndexимел результаты, приведенные кdtype='int64'(GH 17250)Ошибка в
Seriesсdtype='timedelta64[ns]'где сложение или вычитаниеTimedeltaIndexможет возвращатьSeriesс некорректным именем (GH 19043)Ошибка в
Timedelta.__floordiv__()иTimedelta.__rfloordiv__()деление на многие несовместимые объекты numpy было некорректно разрешено (GH 18846)Ошибка при делении скалярного объекта типа timedelta на
TimedeltaIndexвыполнил обратную операцию (GH 19125)Ошибка в
TimedeltaIndexгде деление наSeriesвернетTimedeltaIndexвместоSeries(GH 19042)Ошибка в
Timedelta.__add__(),Timedelta.__sub__()где добавление или вычитаниеnp.timedelta64объект возвращал другойnp.timedelta64вместоTimedelta(GH 19738)Ошибка в
Timedelta.__floordiv__(),Timedelta.__rfloordiv__()где работа сTickобъект вызывалTypeErrorвместо возврата числового значения (GH 19738)Ошибка в
Period.asfreq()где периоды околоdatetime(1, 1, 1)мог быть преобразован неправильно (GH 19643, GH 19834)Ошибка в
Timedelta.total_seconds()вызывая ошибки точности, напримерTimedelta('30S').total_seconds()==30.000000000000004(GH 19458)Ошибка в
Timedelta.__rmod__()где работа сnumpy.timedelta64возвращалtimedelta64объект вместоTimedelta(GH 19820)Умножение
TimedeltaIndexbyTimedeltaIndexтеперь будет вызыватьTypeErrorвместо вызова исключенияValueErrorв случаях несоответствия длины (GH 19333)Ошибка при индексации
TimedeltaIndexсnp.timedelta64объект, который вызывалTypeError(GH 20393)
Часовые пояса#
Ошибка при создании
Seriesиз массива, содержащего как значения без часового пояса, так и с часовым поясом, приведет кSeries, чей тип данных учитывает часовой пояс вместо object (GH 16406)Ошибка при сравнении объектов с учетом часового пояса
DatetimeIndexпротивNaTнекорректное возбуждениеTypeError(GH 19276)Ошибка в
DatetimeIndex.astype()при преобразовании между типами данных с учетом часового пояса и преобразовании из данных с учетом часового пояса в наивные (GH 18951)Ошибка при сравнении
DatetimeIndex, который не смог вызватьTypeErrorпри попытке сравнить объекты datetime с часовым поясом и без часового пояса (GH 18162)Ошибка в локализации наивной строки даты-времени в
Seriesконструктор сdatetime64[ns, tz]тип данных (GH 174151)Timestamp.replace()matplotlibGH 18319)Ошибка в tz-aware
DatetimeIndexгде сложение/вычитание сTimedeltaIndexили массив сdtype='timedelta64[ns]'было некорректным (GH 17558)Ошибка в
DatetimeIndex.insert()где вставкаNaTв индекс, учитывающий часовой пояс, неправильно вызывало (GH 16357)Ошибка в
DataFrameконструктор, где Datetimeindex с учетом часового пояса и заданное имя столбца приведут к пустомуDataFrame(GH 19157)Ошибка в
Timestamp.tz_localize()где локализация временной метки около минимальных или максимальных допустимых значений могла вызвать переполнение и вернуть временную метку с некорректным наносекундным значением (GH 12677)Ошибка при итерации по
DatetimeIndexкоторый был локализован с фиксированным смещением часового пояса, округлявшим наносекундную точность до микросекунд (GH 19603)Ошибка в
DataFrame.diff()который вызвалIndexErrorс значениями, учитывающими часовой пояс (GH 18578)Ошибка в
melt()который преобразовывал типы данных с учётом часового пояса в типы без учёта часового пояса (GH 15785)Ошибка в
Dataframe.count()который вызвалValueError, еслиDataframe.dropna()был вызван для одного столбца со значениями с учетом часового пояса. (GH 13407)
Смещения#
Ошибка в
WeekOfMonthиWeekгде сложение и вычитание выполнялись некорректно (GH 18510, GH 18672, GH 18864)Ошибка в
WeekOfMonthиLastWeekOfMonthгде аргументы по умолчанию для конструктора вызвалиValueError(GH 19142)Ошибка в
FY5253Quarter,LastWeekOfMonthгде поведение отката и продвижения было несогласованным с поведением сложения и вычитания (GH 18854)Ошибка в
FY5253гдеdatetimeсложение и вычитание увеличивались некорректно для дат в конце года, но не нормализованных до полуночи (GH 18854)Ошибка в
FY5253где date offsets могли некорректно вызыватьAssertionErrorв арифметических операциях (GH 14774)
Числовой#
Ошибка в
Seriesконструктор с int или float списком, где указаниеdtype=str,dtype='str'илиdtype='U'не удалось преобразовать элементы данных в строки (GH 16605)Ошибка в
Indexметоды умножения и деления, которые работали сSeriesвернетIndexобъект вместоSeriesобъект (GH 19042)Ошибка в
DataFrameконструктор, в котором данные, содержащие очень большие положительные или очень большие отрицательные числа, вызывалиOverflowError(GH 18584)Ошибка в
Indexконструктор сdtype='uint64'где целочисленные float не приводились кUInt64Index(GH 18400)Ошибка в
DataFrameгибкая арифметика (например,df.add(other, fill_value=foo)) сfill_valueкромеNoneне удалось вызватьNotImplementedErrorв крайних случаях, когда либо фрейм, либоotherимеет нулевую длину (GH 19522)Умножение и деление числовых типов данных
Indexобъекты с timedelta-подобными скалярами возвращаютTimedeltaIndexвместо вызова исключенияTypeError(GH 19333)Ошибка, где
NaNвозвращалось вместо 0 вSeries.pct_change()иDataFrame.pct_change()когдаfill_methodне являетсяNone(GH 19873)
Строки#
Ошибка в
Series.str.get()со словарем в значениях и индексом не в ключах, вызываяKeyError(GH 20671)
Индексирование#
Ошибка в
Indexсоздание из списка кортежей смешанного типа (GH 18505)Ошибка в
Index.drop()при передаче списка, содержащего как кортежи, так и не-кортежи (GH 18304)Ошибка в
DataFrame.drop(),Panel.drop(),Series.drop(),Index.drop()где нетKeyErrorвозникает при удалении несуществующего элемента из оси, содержащей дубликаты (GH 19186)Ошибка при индексировании дата-времени
Indexкоторый поднялValueErrorвместоIndexError(GH 18386).Index.to_series()теперь принимаетindexиnamekwargs (GH 18699)DatetimeIndex.to_series()теперь принимаетindexиnamekwargs (GH 18699)Ошибка при индексации нескалярного значения из
Seriesимеющие неуникальныеIndexвернет значение в плоском виде (GH 17610)Ошибка при индексировании с итератором, содержащим только отсутствующие ключи, которая не вызывала ошибку (GH 20748)
Исправлена несогласованность в
.ixмежду списком и скалярными ключами, когда индекс имеет целочисленный тип и не включает нужные ключи (GH 20753)Ошибка в
__setitem__при индексацииDataFrameс двумерным логическим массивом NumPy (GH 18582)Ошибка в
str.extractallкогда совпадений не найдено, возвращается пустойIndexвозвращалось вместо соответствующегоMultiIndex(GH 19034)Ошибка в
IntervalIndexгде пустые и чисто NA данные строились непоследовательно в зависимости от метода построения (GH 18421)Ошибка в
IntervalIndex.symmetric_difference()где симметричная разность с не-IntervalIndexне вызывал (GH 18475)Ошибка в
IntervalIndexгде операции над множествами, возвращающие пустоеIntervalIndexимел неправильный dtype (GH 19101)Ошибка в
DataFrame.drop_duplicates()где нетKeyErrorвозникает при передаче столбцов, которых нет вDataFrame(GH 19726)Ошибка в
Indexконструкторы подклассов, которые игнорируют неожиданные аргументы ключевых слов (GH 19348)Ошибка в
Index.difference()при вычислении разницыIndexс самим собой (GH 20040)Ошибка в
DataFrame.first_valid_index()иDataFrame.last_valid_index()при наличии целых строк NaN среди значений (GH 20499).Ошибка в
IntervalIndexгде некоторые операции индексирования не поддерживались для перекрывающихся или немонотонныхuint64данные (GH 20636)Ошибка в
Series.is_uniqueгде показывается лишний вывод в stderr, если Series содержит объекты с__ne__определено (GH 20661)Ошибка в
.locприсваивание с однозначным списком неправильно присваивает как список (GH 19474)Ошибка в частичном строковом индексировании на
Series/DataFrameс монотонно убывающимDatetimeIndex(GH 19362)Ошибка при выполнении операций на месте на
DataFrameс дублирующимсяIndex(GH 17105)Ошибка в
IntervalIndex.get_loc()иIntervalIndex.get_indexer()при использовании сIntervalIndexсодержащий один интервал (GH 17284, GH 20921)Ошибка в
.locсuint64индексатор (GH 20722)
MultiIndex#
Ошибка в
MultiIndex.__contains__()где нетуплевые ключи возвращали быTrueдаже если они были удалены (GH 19027)Ошибка в
MultiIndex.set_labels()что может привести к приведению типов (и потенциальному обрезанию) новых меток, еслиlevelаргумент не равен 0 или списку вида [0, 1, …] (GH 19057)Ошибка в
MultiIndex.get_level_values()что вернуло бы недопустимый индекс на уровне целых чисел с пропущенными значениями (GH 17924)Ошибка в
MultiIndex.unique()при вызове на пустомMultiIndex(GH 20568)Ошибка в
MultiIndex.unique()что не сохранит имена уровней (GH 20570)Ошибка в
MultiIndex.remove_unused_levels()который заполнит значения nan (GH 18417)Ошибка в
MultiIndex.from_tuples()что не удавалось обработать заархивированные кортежи в python3 (GH 18434)Ошибка в
MultiIndex.get_loc()что не позволило бы автоматически преобразовывать значения между float и int (GH 18818, GH 15994)Ошибка в
MultiIndex.get_loc()что привело бы к приведению булевых меток к целочисленным (GH 19086)Ошибка в
MultiIndex.get_loc()что не позволит найти ключи, содержащиеNaN(GH 18485)Ошибка в
MultiIndex.get_loc()в большихMultiIndex, завершалось ошибкой, когда уровни имели разные типы данных (GH 18520)Ошибка в индексации, когда вложенные индексаторы, содержащие только массивы numpy, обрабатываются некорректно (GH 19686)
Ввод-вывод#
read_html()теперь перематывает доступные для поиска объекты ввода-вывода после неудачного разбора, прежде чем попытаться разобрать с новым парсером. Если парсер выдает ошибку и объект недоступен для поиска, выводится информативное сообщение об ошибке, предлагающее использовать другой парсер (GH 17975)DataFrame.to_html()теперь имеет опцию добавления идентификатора к ведущемутег (GH 8496)
Ошибка в
read_msgpack()с несуществующим файлом передается в Python 2 (GH 15296)Ошибка в
read_csv()гдеMultiIndexс дублирующимися столбцами не было соответствующим образом изменено (GH 18062)Ошибка в
read_csv()где пропущенные значения не обрабатывались должным образом, когдаkeep_default_na=Falseсо словарёмna_values(GH 19227)Ошибка в
read_csv()вызывая повреждение кучи на 32-битных архитектурах с обратным порядком байтов (GH 20785)Ошибка в
read_sas()где файл с 0 переменными выдавалAttributeErrorнеправильно. Теперь выдаётEmptyDataError(GH 18184)Ошибка в
DataFrame.to_latex()где пары фигурных скобок, предназначенные служить невидимыми заполнителями, были экранированы (GH 18667)Ошибка в
DataFrame.to_latex()гдеNaNвMultiIndexвызоветIndexErrorили некорректный вывод (GH 14249)Ошибка в
DataFrame.to_latex()где нестроковое имя уровня индекса привело бы кAttributeError(GH 19981)Ошибка в
DataFrame.to_latex()где комбинация имени индекса иindex_names=Falseопция приведет к некорректному выводу (GH 18326)Ошибка в
DataFrame.to_latex()гдеMultiIndexс пустой строкой в качестве имени привело бы к некорректному выводу (GH 18669)Ошибка в
DataFrame.to_latex()где отсутствующие пробелы вызывали неправильное экранирование и создавали невалидный latex в некоторых случаях (GH 20859)Ошибка в
read_json()где большие числовые значения вызывалиOverflowError(GH 18842)Ошибка в
DataFrame.to_parquet()где исключение вызывалось, если место записи - S3 (GH 19134)Intervalтеперь поддерживается вDataFrame.to_excel()для всех типов файлов Excel (GH 19242)Timedeltaтеперь поддерживается вDataFrame.to_excel()для всех типов файлов Excel (GH 19242, GH 9155, GH 19900)Ошибка в
pandas.io.stata.StataReader.value_labels()вызовAttributeErrorпри вызове на очень старых файлах. Теперь возвращает пустой словарь (GH 19417)Ошибка в
read_pickle()при распаковке объектов сTimedeltaIndexилиFloat64Indexсозданные с pandas до версии 0.20 (GH 19939)Ошибка в
pandas.io.json.json_normalize()где подзаписи не нормализуются должным образом, если значения любых подзаписей имеют тип NoneType (GH 20030)Ошибка в
usecolsпараметр вread_csv()где ошибка не возникает корректно при передаче строки. (GH 20529)Ошибка в
HDFStore.keys()при чтении файла с символической ссылкой вызывает исключение (GH 20523)Ошибка в
HDFStore.select_column()где ключ, который не является допустимым хранилищем, вызывалAttributeErrorвместоKeyError(GH 17912)Построение графиков#
Улучшенное сообщение об ошибке при попытке построить график, но matplotlib не установлен (GH 19810).
DataFrame.plot()теперь вызываетValueErrorкогдаxилиyаргумент неправильно сформирован (GH 18671)Ошибка в
DataFrame.plot()когдаxиyаргументы, заданные как позиции, вызывали некорректные ссылки на столбцы для линейных, столбчатых и площадных графиков (GH 20056)Ошибка в форматировании меток делений с
datetime.time()и доли секунды (GH 18478).Series.plot.kde()предоставил доступ к аргументамindиbw_methodв строке документации (GH 18461). Аргументindтеперь также может быть целым числом (количество точек выборки).DataFrame.plot()теперь поддерживает несколько столбцов дляyаргумент (GH 19699)
GroupBy/resample/rolling#
Ошибка при группировке по одному столбцу и агрегировании с классом, таким как
listилиtuple(GH 18079)Исправлена регрессия в
DataFrame.groupby()который не выдавал ошибку при вызове с ключом-кортежем, отсутствующим в индексе (GH 18798)Ошибка в
DataFrame.resample()который молча игнорировал неподдерживаемые (или опечатанные) опции дляlabel,closedиconvention(GH 19303)Ошибка в
DataFrame.groupby()где кортежи интерпретировались как списки ключей, а не как ключи (GH 17979, GH 18249)Ошибка в
DataFrame.groupby()где агрегация поfirst/last/min/maxвызывал потерю точности временных меток (GH 19526)Ошибка в
DataFrame.transform()где определенные агрегирующие функции некорректно приводились к соответствию с dtype(s) сгруппированных данных (GH 19200)Ошибка в
DataFrame.groupby()передачаon=kwarg, и последующее использование.apply()(GH 17813)Ошибка в
DataFrame.resample().aggregateне вызывалKeyErrorпри агрегации несуществующего столбца (GH 16766, GH 19566)Ошибка в
DataFrameGroupBy.cumsum()иDataFrameGroupBy.cumprod()когдаskipnaбыл передан (GH 19806)Ошибка в
DataFrame.resample()которая удалила информацию о часовом поясе (GH 13238)Ошибка в
DataFrame.groupby()где преобразования с использованиемnp.allиnp.anyвызывалиValueError(GH 20653)Ошибка в
DataFrame.resample()гдеffill,bfill,pad,backfill,fillna,interpolate, иasfreqигнорировалиloffset. (GH 20744)Ошибка в
DataFrame.groupby()при применении функции со смешанными типами данных, когда пользовательская функция может завершиться ошибкой на колонке группировки (GH 20949)Ошибка в
DataFrameGroupBy.rolling().apply()где операции выполняются против связанногоDataFrameGroupByобъект может повлиять на включение сгруппированных элементов в результат (GH 14013)
Разреженный#
Ошибка, при которой создание
SparseDataFrameиз плотногоSeriesили неподдерживаемый тип вызывал неконтролируемое исключение (GH 19374)Ошибка в
SparseDataFrame.to_csvвызывая исключение (GH 19384)Ошибка в
SparseSeries.memory_usageчто вызывало ошибку сегментации при доступе к неразреженным элементам (GH 19368)Ошибка при построении
SparseArray: еслиdataявляется скаляром иindexесли определен, он будет преобразован вfloat64независимо от dtype скаляра. (GH 19163)
Изменение формы#
Ошибка в
DataFrame.merge()где ссылка наCategoricalIndexпо имени, гдеbyаргумент будетKeyError(GH 20777)Ошибка в
DataFrame.stack()который не может отсортировать смешанные типы уровней в Python 3 (GH 18310)Ошибка в
DataFrame.unstack()который преобразует int в float, еслиcolumnsявляетсяMultiIndexс неиспользуемыми уровнями (GH 17845)Ошибка в
DataFrame.unstack()который вызывает ошибку, еслиindexявляетсяMultiIndexс неиспользуемыми метками на неуложенном уровне (GH 18562)Исправлено создание
SeriesизdictсодержащийNaNв качестве ключа (GH 18480)Исправлено создание
DataFrameизdictсодержащийNaNв качестве ключа (GH 18455)Отключено создание
Seriesгде len(index) > len(data) = 1, что ранее транслировало элемент данных, а теперь вызываетValueError(GH 18819)Подавлена ошибка при построении
DataFrameизdictсодержащие скалярные значения, когда соответствующие ключи не включены в переданный индекс (GH 18600)Исправлено (изменено с
objecttofloat64) тип данныхDataFrameинициализирован с осями, без данных иdtype=int(GH 19646)Ошибка в
Series.rank()гдеSeriesсодержащийNaTизменяетSeriesinplace (GH 18521)Ошибка в
cut()который не работает при использовании массивов только для чтения (GH 18773)Ошибка в
DataFrame.pivot_table()который не работает, когдаaggfuncаргумент имеет тип string. Поведение теперь согласовано с другими методами, такими какaggиapply(GH 18713)Ошибка в
DataFrame.merge()в котором слияние с использованиемIndexобъектов как векторов вызывало исключение (GH 19038)Ошибка в
DataFrame.stack(),DataFrame.unstack(),Series.unstack()которые не возвращали подклассы (GH 15563)Ошибка в сравнениях часовых поясов, проявляющаяся как преобразование индекса в UTC в
.concat()(GH 18523)Ошибка в
concat()при объединении разреженных и плотных серий возвращается толькоSparseDataFrame. Должен бытьDataFrame. (GH 18914, GH 18686, и GH 16874)Улучшено сообщение об ошибке для
DataFrame.merge()когда нет общего ключа слияния (GH 19427)Ошибка в
DataFrame.join()который выполняетouterвместоleftобъединять при вызове с несколькими DataFrame и некоторые имеют неуникальные индексы (GH 19624)Series.rename()теперь принимаетaxisв качестве аргумента ключевого слова (GH 18589)Ошибка в
rename()где Index кортежей одинаковой длины был преобразован в MultiIndex (GH 19497)Сравнения между
SeriesиIndexвернетSeriesс неправильным именем, игнорируяIndexатрибут name (GH 19582)Ошибка в
qcut()где данные datetime и timedelta сNaTприсутствие вызывалоValueError(GH 19768)Ошибка в
DataFrame.iterrows(), который определяет строки, не соответствующие ISO8601 в даты и время (GH 19671)Ошибка в
Seriesконструктор сCategoricalгдеValueErrorне вызывается, когда задан индекс другой длины (1.#IND)Ошибка в
DataFrame.astype()где метаданные столбцов теряются при преобразовании в категориальный или словарь типов данных (GH 19920)Ошибка в
cut()иqcut()где информация о часовом поясе была удалена (GH 19872)Ошибка в
Seriesконструктор сdtype=str, ранее возникавшая в некоторых случаях (GH 19853)Ошибка в
get_dummies(), иselect_dtypes(), где дублирующиеся имена столбцов вызывали некорректное поведение (GH 20848)Ошибка в
isna(), который не может обрабатывать неоднозначные типизированные списки (GH 20675)Ошибка в
concat()что вызывает ошибку при объединении DataFrame с учетом часового пояса и DataFrame с полностью значениями NaT (GH 12396)Ошибка в
concat()который вызывает ошибку при конкатенации пустых серий с учетом часового пояса (GH 18447)
Другие#
Улучшенное сообщение об ошибке при попытке использовать ключевое слово Python в качестве идентификатора в
numexprподдерживаемый запрос (GH 18221)Ошибка при доступе к
pandas.get_option(), что вызывалоKeyErrorвместоOptionErrorпри поиске несуществующего ключа опции в некоторых случаях (GH 19789)Ошибка в
testing.assert_series_equal()иtesting.assert_frame_equal()для Series или DataFrames с различными данными в формате unicode (GH 20503)
Участники#
Всего 328 человек внесли патчи в этот релиз. Люди с «+» рядом с их именами внесли патч впервые.
Aaron Critchley
AbdealiJK +
Adam Hooper +
Albert Villanova del Moral
Devjeet Roy +
Alejandro Hohmann +
Alex Rychyk
Alexander Buchkovsky
Alexander Lenail +
Александр Майкл Шаде
Aly Sivji +
Андреас Кёльтрингер +
Andrew
Andrew Bui +
András Novoszáth +
Andy Craze +
Andy R. Terrel
Anh Le +
Anil Kumar Pallekonda +
Antoine Pitrou +
Antonio Linde +
Antonio Molina +
Antonio Quinonez +
Armin Varshokar +
Artem Bogachev +
Avi Sen +
Azeez Oluwafemi +
Ben Auffarth +
Бернхард Тиль +
Bhavesh Poddar +
BielStela +
Blair +
Bob Haffner
Brett Naul +
Brock Mendel
Bryce Guinta +
Carlos Eduardo Moreira dos Santos +
Carlos García Márquez +
Carol Willing
Cheuk Ting Ho +
Chitrank Dixit +
Chris
Chris Burr +
Chris Catalfo +
Крис Маццулло
Christian Chwala +
Cihan Ceyhan +
Clemens Brunner
Colin +
Cornelius Riemenschneider
Crystal Gong +
DaanVanHauwermeiren
Dan Dixey +
Daniel Frank +
Daniel Garrido +
Daniel Sakuma +
DataOmbudsman +
Дэйв Хиршфельд
Dave Lewis +
David Adrián Cañones Castellano +
David Arcos +
David C Hall +
David Fischer
David Hoese +
David Lutz +
David Polo +
David Stansby
Dennis Kamau +
Dillon Niederhut
Dimitri +
Dr. Irv
Dror Atariah
Eric Chea +
Eric Kisslinger
Эрик О. ЛЕБИГО (EOL) +
FAN-GOD +
Fabian Retkowski +
Fer Sar +
Gabriel de Maeztu +
Джанпаоло Макарио +
Giftlin Rajaiah
Gilberto Olimpio +
Gina +
Gjelt +
Graham Inggs +
Grant Roch
Grant Smith +
Grzegorz Konefał +
Guilherme Beltramini
HagaiHargil +
Hamish Pitkeathly +
Hammad Mashkoor +
Hannah Ferchland +
Hans
Haochen Wu +
Хиссаши Роча +
Иэн Барр +
Ибрагим Шараф ЭльДен +
Ignasi Fosch +
Igor Conrado Alves de Lima +
Igor Shelvinskyi +
Imanflow +
Ingolf Becker
Israel Saeta Pérez
Ива Коевска +
Якуб Новацки +
Jan F-F +
Jan Koch +
Ян Веркманн
Janelle Zoutkamp +
Jason Bandlow +
Jaume Bonet +
Jay Alammar +
Jeff Reback
JennaVergeynst
Jimmy Woo +
Jing Qiang Goh +
Иоахим Вагнер +
Joan Martin Miralles +
Joel Nothman
Джоун Парк +
John Cant +
Johnny Metz +
Jon Mease
Йонас Шульце +
Jongwony +
Jordi Contestí +
Joris Van den Bossche
Жозе Ф. Р. Фонсека +
Джовикс +
Julio Martinez +
Jörg Döpfert
KOBAYASHI Ittoku +
Kate Surta +
Kenneth +
Кевин Куль
Кевин Шеппард
Krzysztof Chomski
Ksenia +
Ksenia Bobrova +
Kunal Gosar +
Kurtis Kerstein +
Kyle Barron +
Laksh Arora +
Laurens Geffert +
Leif Walsh
Liam Marshall +
Liam3851 +
Licht Takeuchi
Лиудмила +
Ludovico Russo +
Mabel Villalba +
Manan Pal Singh +
Manraj Singh
Marc +
Марк Гарсия
Marco Hemken +
Мария дель Мар Бибилони +
Mario Corchero +
Mark Woodbridge +
Martin Journois +
Mason Gallo +
Matias Heikkilä +
Мэтт Бреймер-Хейс
Matt Kirk +
Matt Maybeno +
Matthew Kirk +
Мэтью Роклин +
Мэтью Рёшке
Matthias Bussonnier +
Max Mikhaylov +
Maxim Veksler +
Maximilian Roos
Максимилиано Греко +
Michael Penkov
Michael Röttger +
Michael Selik +
Майкл Васком
Запрос столбцов DataFrame с помощью логического выражения.
Mike Kutzma +
Мин Ли +
Митар +
Mitch Negus +
Montana Low +
Мориц Мюнст +
Mortada Mehyar
Myles Braithwaite +
Nate Yoder
Nicholas Ursa +
Nick Chmura
Nikos Karagiannakis +
Nipun Sadvilkar +
Nis Martensen +
Noah +
Noémi Éltető +
Olivier Bilodeau +
Ondrej Kokes +
Onno Eberhard +
Paul Ganssle +
Пол Маннино +
Пол Риди
Paulo Roberto de Oliveira Castro +
Pepe Flores +
Peter Hoffmann
Фил Нго +
Пьетро Баттистон
Pranav Suri +
Priyanka Ojha +
Pulkit Maloo +
README Bot +
Ray Bell +
Риккардо Мальоккетти +
Ridhwan Luthra +
Роберт Мейер
Robin
Robin Kiplang’at +
Rohan Pandit +
Rok Mihevc +
Rouz Azari
Ryszard T. Kaleta +
Sam Cohan
Сэм Фу
Samir Musali +
Samuel Sinayoko +
Sangwoong Yoon
SarahJessica +
Sharad Vijalapuram +
Shubham Chaudhary +
SiYoungOh +
Sietse Brouwer
Simone Basso +
Стефания Дельпрете +
Stefano Cianciulli +
Stephen Childs +
StephenVoland +
Stijn Van Hoey +
Sven
Talitha Pumar +
Tarbo Fukazawa +
Ted Petrou +
Thomas A Caswell
Тим Хоффманн +
Tim Swast
Tom Augspurger
Tommy +
Tulio Casagrande +
Tushar Gupta +
Tushar Mittal +
Upkar Lidder +
Victor Villas +
Vince W +
Vinícius Figueiredo +
Vipin Kumar +
WBare
Wenhuan +
Wes Turner
William Ayd
Уилсон Линь +
Xbar
Yaroslav Halchenko
Yee Mey
Yeongseon Choe +
Yian +
Yimeng Zhang
Чжу Баохэ +
Цзихао Чжао +
adatasetaday +
akielbowicz +
akosel +
alinde1 +
amuta +
bolkedebruin
cbertinato
cgohlke
charlie0389 +
chris-b1
csfarkas +
dajcs +
deflatSOCO +
derestle-htwg
дискорд
dmanikowski-reef +
donK23 +
elrubio +
fivemok +
fjdiod
fjetter +
froessler +
gabrielclow
gfyoung
ghasemnaddaf
h-vetinari +
himanshu awasthi +
ignamv +
jayfoad +
jazzmuesli +
jbrockmendel
jen w +
jjames34 +
joaoavf +
joders +
jschendel
juan huguet +
l736x +
luzpaz +
mdeboc +
miguelmorin +
miker985
miquelcamprodon +
orereta +
ottiP +
peterpanmj +
rafarui +
raph-m +
readyready15728 +
rmihael +
samghelms +
scriptomation +
sfoo +
stefansimik +
stonebig
tmnhat2001 +
tomneep +
topper-123
tv3141 +
verakai +
xpvpc +
zhanghui +