Версия 0.14.0 (31 мая 2014)#
Это основной релиз с версии 0.13.1, включающий небольшое количество изменений API, несколько новых функций, улучшений и оптимизаций производительности, а также большое количество исправлений ошибок. Рекомендуем всем пользователям обновиться до этой версии.
Основные моменты включают:
Официальная поддержка Python 3.4
SQL интерфейсы обновлены для использования
sqlalchemy, См. Здесь.Изменения интерфейса отображения, см. Здесь
MultiIndexing с использованием слайсеров, см. Здесь.
Возможность объединения DataFrame с одним индексом с DataFrame с MultiIndex, см. Здесь
Большая согласованность в результатах groupby и более гибкие спецификации groupby, см. Здесь
Календари праздников теперь поддерживаются в
CustomBusinessDay, см. ЗдесьНесколько улучшений в функциях построения графиков, включая: гексагональные, площадные и круговые диаграммы, см. Здесь.
Раздел документации по производительности операций ввода-вывода, см. Здесь
Предупреждение
В версии 0.14.0 все NDFrame контейнеры на основе индекса подверглись значительной внутренней рефакторизации. До этого каждый блок однородных данных имел свои собственные метки, и требовалась особая осторожность, чтобы поддерживать их синхронизацию с метками родительского контейнера. Это не должно иметь видимых изменений в поведении пользователя/API (GH 6745)
Изменения API#
read_excelиспользует 0 как лист по умолчанию (GH 6573)ilocтеперь будет принимать индексаторы срезов, выходящие за границы, например, значение, превышающее длину индексируемого объекта. Они будут исключены. Это сделает pandas более соответствующим индексации python/numpy значений, выходящих за границы. Отдельный индексатор, выходящий за границы и уменьшающий размерность объекта, по-прежнему вызоветIndexError(GH 6296, GH 6299). Это может привести к пустой оси (например, возврату пустого DataFrame)In [1]: dfl = pd.DataFrame(np.random.randn(5, 2), columns=list('AB')) In [2]: dfl Out[2]: A B 0 0.469112 -0.282863 1 -1.509059 -1.135632 2 1.212112 -0.173215 3 0.119209 -1.044236 4 -0.861849 -2.104569 [5 rows x 2 columns] In [3]: dfl.iloc[:, 2:3] Out[3]: Empty DataFrame Columns: [] Index: [0, 1, 2, 3, 4] [5 rows x 0 columns] In [4]: dfl.iloc[:, 1:3] Out[4]: B 0 -0.282863 1 -1.135632 2 -0.173215 3 -1.044236 4 -2.104569 [5 rows x 1 columns] In [5]: dfl.iloc[4:6] Out[5]: A B 4 -0.861849 -2.104569 [1 rows x 2 columns]
Это выборки за пределами допустимого диапазона
>>> dfl.iloc[[4, 5, 6]] IndexError: positional indexers are out-of-bounds >>> dfl.iloc[:, 4] IndexError: single positional indexer is out-of-bounds
Срезы с отрицательными значениями start, stop и step лучше обрабатывают крайние случаи (GH 6531):
df.iloc[:-len(df)]теперь пустdf.iloc[len(df)::-1]теперь перечисляет все элементы в обратном порядке
The
DataFrame.interpolate()ключевое словоdowncastзначение по умолчанию изменено сinfertoNone. Это сделано для сохранения исходного dtype, если явно не запрошено иное (GH 6290).При преобразовании датафрейма в HTML раньше возвращалось
Empty DataFrame. Этот особый случай был удален, вместо этого возвращается заголовок с именами столбцов (GH 6062).SeriesиIndexтеперь внутренне используют больше общих операций, напримерfactorize(),nunique(),value_counts()теперь поддерживаются наIndexтипов также. TheSeries.weekdayсвойство is удалено из Series для согласованности API. ИспользованиеDatetimeIndex/PeriodIndexметод на Series теперь будет вызыватьTypeError. (GH 4551, GH 4056, GH 5519, GH 6380, GH 7206).Добавить
is_month_start,is_month_end,is_quarter_start,is_quarter_end,is_year_start,is_year_endаксессоры дляDateTimeIndex/Timestampкоторые возвращают булев массив, указывающий, находятся ли метки времени в начале/конце месяца/квартала/года, определённого частотойDateTimeIndex/Timestamp(GH 4565, GH 6998)Использование локальных переменных изменилось в
pandas.eval()/DataFrame.eval()/DataFrame.query()(GH 5987). ДляDataFrameметоды, две вещи изменилисьИмена столбцов теперь имеют приоритет над локальными переменными
Локальные переменные должны быть указаны явно. Это означает, что даже если у вас есть локальная переменная, которая не столбец, вы все равно должны ссылаться на него с помощью
'@'префикс.Вы можете использовать выражение вида
df.query('@a < a')без жалоб отpandasо неоднозначности названияa.Верхнеуровневый
pandas.eval()функция не позволяет использовать'@'префикс и предоставляет вам сообщение об ошибке, сообщающее об этом.NameResolutionErrorбыл удалён, так как больше не нужен.
Определить и задокументировать порядок имён столбцов и индексов в query/eval (GH 6676)
concatтеперь будет объединять смешанные Series и DataFrames, используя имя Series или нумерацию столбцов по мере необходимости (GH 2385). См. документацияОперации срезов и расширенного/булевого индексирования на
Indexклассы, а такжеIndex.delete()иIndex.drop()методы больше не будут изменять тип результирующего индекса (GH 6440, GH 7040)In [6]: i = pd.Index([1, 2, 3, 'a', 'b', 'c']) In [7]: i[[0, 1, 2]] Out[7]: Index([1, 2, 3], dtype='object') In [8]: i.drop(['a', 'b', 'c']) Out[8]: Index([1, 2, 3], dtype='object')
Ранее указанная операция возвращала
Int64Index. Если вы хотите сделать это вручную, используйтеIndex.astype()In [9]: i[[0, 1, 2]].astype(np.int_) Out[9]: Index([1, 2, 3], dtype='int64')
set_indexбольше не преобразует MultiIndex в Index кортежей. Например, старое поведение возвращало Index в этом случае (GH 6459):# Old behavior, casted MultiIndex to an Index In [10]: tuple_ind Out[10]: Index([('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd')], dtype='object') In [11]: df_multi.set_index(tuple_ind) Out[11]: 0 1 (a, c) 0.471435 -1.190976 (a, d) 1.432707 -0.312652 (b, c) -0.720589 0.887163 (b, d) 0.859588 -0.636524 [4 rows x 2 columns] # New behavior In [12]: mi Out[12]: MultiIndex([('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd')], ) In [13]: df_multi.set_index(mi) Out[13]: 0 1 a c 0.471435 -1.190976 d 1.432707 -0.312652 b c -0.720589 0.887163 d 0.859588 -0.636524 [4 rows x 2 columns]
Это также применяется при передаче нескольких индексов в
set_index:# Old output, 2-level MultiIndex of tuples In [14]: df_multi.set_index([df_multi.index, df_multi.index]) Out[14]: 0 1 (a, c) (a, c) 0.471435 -1.190976 (a, d) (a, d) 1.432707 -0.312652 (b, c) (b, c) -0.720589 0.887163 (b, d) (b, d) 0.859588 -0.636524 [4 rows x 2 columns] # New output, 4-level MultiIndex In [15]: df_multi.set_index([df_multi.index, df_multi.index]) Out[15]: 0 1 a c a c 0.471435 -1.190976 d a d 1.432707 -0.312652 b c b c -0.720589 0.887163 d b d 0.859588 -0.636524 [4 rows x 2 columns]
pairwiseключевое слово было добавлено к функциям статистических моментовrolling_cov,rolling_corr,ewmcov,ewmcorr,expanding_cov,expanding_corrдля расчёта скользящих ковариационных и корреляционных матриц (GH 4950). См. Вычисление скользящих попарных ковариаций и корреляций в документации.In [1]: df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD')) In [4]: covs = pd.rolling_cov(df[['A', 'B', 'C']], ....: df[['B', 'C', 'D']], ....: 5, ....: pairwise=True) In [5]: covs[df.index[-1]] Out[5]: B C D A 0.035310 0.326593 -0.505430 B 0.137748 -0.006888 -0.005383 C -0.006888 0.861040 0.020762
Series.iteritems()теперь ленивый (возвращает итератор вместо списка). Это было задокументированное поведение до версии 0.14. (GH 6760)Добавлен
nuniqueиvalue_countsфункции дляIndexдля подсчёта уникальных элементов. (GH 6734)stackиunstackтеперь вызываетValueErrorкогдаlevelключевое слово относится к неуникальному элементу вIndex(ранее вызывалKeyError). (GH 6738)удалить неиспользуемый аргумент order из
Series.sort; args теперь в том же порядке, что иSeries.order; добавитьna_positionаргумент для соответствияSeries.order(GH 6847)алгоритм сортировки по умолчанию для
Series.orderтеперьquicksort, чтобы соответствоватьSeries.sort(и значения по умолчанию numpy)добавить
inplaceключевое слово дляSeries.order/sortчтобы сделать их обратными (GH 6859)DataFrame.sortтеперь помещает NaN в начало или конец сортировки в соответствии сna_positionпараметр. (GH 3917)принимать
TextFileReaderвconcat, что влияло на распространенную пользовательскую идиому (GH 6583), это была регрессия с 0.13.1Добавлен
factorizeфункции дляIndexиSeriesдля получения индексатора и уникальных значений (GH 7090)describeв DataFrame со смесью объектов Timestamp и строковых объектов возвращает другой Index (GH 7088). Ранее индекс непреднамеренно сортировался.Арифметические операции с only
boolтипы данных теперь выдают предупреждение, указывающее, что они вычисляются в пространстве Python для+,-, и*операций и вызывает исключение для всех остальных (GH 7011, GH 6762, GH 7015, GH 7210)>>> x = pd.Series(np.random.rand(10) > 0.5) >>> y = True >>> x + y # warning generated: should do x | y instead UserWarning: evaluating in Python space because the '+' operator is not supported by numexpr for the bool dtype, use '|' instead >>> x / y # this raises because it doesn't make sense NotImplementedError: operator '/' not implemented for bool dtypes
В
HDFStore,select_as_multipleвсегда будет вызыватьKeyError, когда ключ или селектор не найден (GH 6177)df['col'] = valueиdf.loc[:,'col'] = valueтеперь полностью эквивалентны; ранее.locне обязательно привел бы к приведению типа результирующего ряда (GH 6149)dtypesиftypesтеперь возвращает серию сdtype=objectна пустых контейнерах (GH 5740)df.to_csvтеперь будет возвращать строку с данными CSV, если не указан целевой путь или буфер (GH 6061)pd.infer_freq()теперь вызоветTypeErrorесли задан недопустимыйSeries/Indexтип (GH 6407, GH 6463)Кортеж, переданный в
DataFame.sort_indexбудет интерпретироваться как уровни индекса, вместо требования списка кортежей (GH 4370)все операции смещения теперь возвращают
Timestampтипы (вместо datetime), бизнес/недельные частоты были некорректными (GH 4069)to_excelтеперь преобразуетnp.infв строковое представление, настраиваемое с помощьюinf_repаргумент ключевого слова (Excel не имеет собственного представления inf ) (GH 6782)Заменить
pandas.compat.scipy.scoreatpercentileсnumpy.percentile(GH 6810).quantileнаdatetime[ns]series теперь возвращаетTimestampвместоnp.datetime64объекты (GH 6810)изменение
AssertionErrortoTypeErrorдля недопустимых типов, переданных вconcat(GH 6583)Вызвать
TypeErrorкогдаDataFrameпередается итератор в качествеdataаргумент (GH 5357)
Отображение изменений#
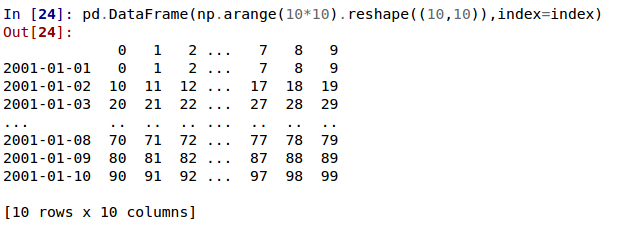
Стандартный способ печати больших DataFrame изменился. DataFrame, превышающие
max_rowsи/илиmax_columnsтеперь отображаются в центрально усеченном представлении, согласованном с выводомpandas.Series(GH 5603).В предыдущих версиях DataFrame обрезался, как только достигались ограничения размерности, и многоточие (…) сигнализировало, что часть данных была обрезана.
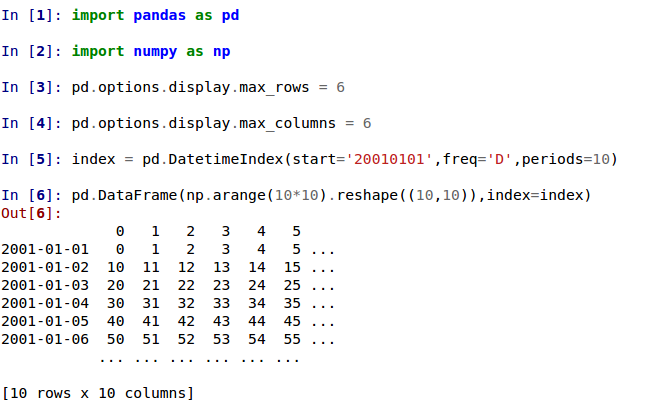
В текущей версии большие DataFrame центрально усекаются, показывая предварительный просмотр начала и конца в обоих измерениях.
разрешить опцию
'truncate'дляdisplay.show_dimensionsпоказывать размеры только если фрейм обрезан (GH 6547).Значение по умолчанию для
display.show_dimensionsтеперь будетtruncate. Это согласуется с тем, как Series отображает длину.In [16]: dfd = pd.DataFrame(np.arange(25).reshape(-1, 5), ....: index=[0, 1, 2, 3, 4], ....: columns=[0, 1, 2, 3, 4]) ....: # show dimensions since this is truncated In [17]: with pd.option_context('display.max_rows', 2, 'display.max_columns', 2, ....: 'display.show_dimensions', 'truncate'): ....: print(dfd) ....: 0 ... 4 0 0 ... 4 .. .. ... .. 4 20 ... 24 [5 rows x 5 columns] # will not show dimensions since it is not truncated In [18]: with pd.option_context('display.max_rows', 10, 'display.max_columns', 40, ....: 'display.show_dimensions', 'truncate'): ....: print(dfd) ....: 0 1 2 3 4 0 0 1 2 3 4 1 5 6 7 8 9 2 10 11 12 13 14 3 15 16 17 18 19 4 20 21 22 23 24
Регрессия в отображении Series с MultiIndex при
display.max_rowsменьше, чем длина серии (GH 7101)Исправлена ошибка в HTML-представлении усечённой Series или DataFrame, не показывающая имя класса с
large_reprустановлено в 'info' (GH 7105)The
verboseключевое слово вDataFrame.info(), который управляет сокращениемinfoпредставление, теперьNoneпо умолчанию. Это будет следовать глобальной настройке вdisplay.max_info_columns. Глобальная настройка может быть переопределена с помощьюverbose=Trueилиverbose=False.Исправлена ошибка с
inforepr не учитываетdisplay.max_info_columnsнастройка (GH 6939)Информация о смещении/частоте теперь в Timestamp __repr__ (GH 4553)
Изменения в API парсинга текста#
read_csv()/read_table() теперь будет более шумным в отношении недопустимых опций, а не возвращаться к PythonParser.
Вызвать
ValueErrorкогдаsepуказан сdelim_whitespace=Trueвread_csv()/read_table()(GH 6607)Вызвать
ValueErrorкогдаengine='c'указан с неподдерживаемыми опциями вread_csv()/read_table()(GH 6607)Вызвать
ValueErrorкогда откат к парсеру python приводит к игнорированию опций (GH 6607)Создать
ParserWarningпри откате на python парсер, когда никакие опции не игнорируются (GH 6607)Перевести
sep='\s+'todelim_whitespace=Trueвread_csv()/read_table()если не указаны другие параметры, не поддерживаемые C (GH 6607)
Изменения в API GroupBy#
Более последовательное поведение для некоторых методов groupby:
groupby
headиtailтеперь ведут себя больше какfilterвместо агрегации:In [1]: df = pd.DataFrame([[1, 2], [1, 4], [5, 6]], columns=['A', 'B']) In [2]: g = df.groupby('A') In [3]: g.head(1) # filters DataFrame Out[3]: A B 0 1 2 2 5 6 In [4]: g.apply(lambda x: x.head(1)) # used to simply fall-through Out[4]: A B A 1 0 1 2 5 2 5 6
groupby head и tail учитывают выбор столбцов:
In [19]: g[['B']].head(1) Out[19]: B 0 2 2 6 [2 rows x 1 columns]
groupby
nthтеперь по умолчанию сокращает; фильтрация может быть достигнута путем передачиas_index=False. С необязательнымdropnaаргумент для игнорирования NaN. См. документация.Сокращение
In [19]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], columns=['A', 'B']) In [20]: g = df.groupby('A') In [21]: g.nth(0) Out[21]: A B 0 1 NaN 2 5 6.0 [2 rows x 2 columns] # this is equivalent to g.first() In [22]: g.nth(0, dropna='any') Out[22]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns] # this is equivalent to g.last() In [23]: g.nth(-1, dropna='any') Out[23]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns]
Фильтрация
In [24]: gf = df.groupby('A', as_index=False) In [25]: gf.nth(0) Out[25]: A B 0 1 NaN 2 5 6.0 [2 rows x 2 columns] In [26]: gf.nth(0, dropna='any') Out[26]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns]
groupby теперь не будет возвращать сгруппированный столбец для не-cython функций (GH 5610, GH 5614, GH 6732), так как это уже индекс
In [27]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6], [5, 8]], columns=['A', 'B']) In [28]: g = df.groupby('A') In [29]: g.count() Out[29]: B A 1 1 5 2 [2 rows x 1 columns] In [30]: g.describe() Out[30]: B count mean std min 25% 50% 75% max A 1 1.0 4.0 NaN 4.0 4.0 4.0 4.0 4.0 5 2.0 7.0 1.414214 6.0 6.5 7.0 7.5 8.0 [2 rows x 8 columns]
передача
as_indexоставит сгруппированный столбец на месте (это не изменено в 0.14.0)In [31]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6], [5, 8]], columns=['A', 'B']) In [32]: g = df.groupby('A', as_index=False) In [33]: g.count() Out[33]: A B 0 1 1 1 5 2 [2 rows x 2 columns] In [34]: g.describe() Out[34]: A B count mean std min 25% 50% 75% max 0 1 1.0 4.0 NaN 4.0 4.0 4.0 4.0 4.0 1 5 2.0 7.0 1.414214 6.0 6.5 7.0 7.5 8.0 [2 rows x 9 columns]
Разрешить указание более сложного группирования через
pd.Grouper, например, группировка по времени и строковому полю одновременно. См. документация. (GH 3794)Улучшенное распространение/сохранение имен Series при выполнении операций groupby:
SeriesGroupBy.aggобеспечит передачу атрибута name исходного ряда в результат (GH 6265).Если функция, переданная в
GroupBy.applyвозвращает именованный Series, имя Series будет сохранено как имя индексного столбца DataFrame, возвращаемогоGroupBy.apply(GH 6124). Это облегчаетDataFrame.stackопераций, где имя индекса столбца используется как имя вставленного столбца, содержащего сводные данные.
SQL#
Функции чтения и записи SQL теперь поддерживают больше типов баз данных через SQLAlchemy (GH 2717, GH 4163, GH 5950, GH 6292). Все базы данных, поддерживаемые SQLAlchemy, могут быть использованы, такие как PostgreSQL, MySQL, Oracle, Microsoft SQL server (см. документацию SQLAlchemy на включённые диалекты).
Функциональность предоставления объектов соединения DBAPI будет поддерживаться только для sqlite3 в будущем. 'mysql' параметр flavor устарел.
Новые функции read_sql_query() и read_sql_table()
вводятся. Функция read_sql() сохраняется как удобная оболочка вокруг двух других и будет делегировать вызов конкретной функции в зависимости от предоставленного ввода (имя таблицы базы данных или SQL-запрос).
На практике вам необходимо предоставить SQLAlchemy engine к функциям sql.
Для подключения с SQLAlchemy используйте create_engine() функция для создания объекта engine из URI базы данных. Вам нужно создать engine только один раз для каждой базы данных, к которой вы подключаетесь. Для базы данных sqlite в памяти:
In [35]: from sqlalchemy import create_engine
# Create your connection.
In [36]: engine = create_engine('sqlite:///:memory:')
Это engine затем может использоваться для записи или чтения данных в/из этой базы данных:
In [37]: df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
In [38]: df.to_sql(name='db_table', con=engine, index=False)
Out[38]: 3
Вы можете читать данные из базы данных, указав имя таблицы:
In [39]: pd.read_sql_table('db_table', engine)
Out[39]:
A B
0 1 a
1 2 b
2 3 c
[3 rows x 2 columns]
или указав SQL-запрос:
In [40]: pd.read_sql_query('SELECT * FROM db_table', engine)
Out[40]:
A B
0 1 a
1 2 b
2 3 c
[3 rows x 2 columns]
Некоторые другие улучшения функций sql включают:
поддержка записи индекса. Это можно контролировать с помощью
indexключевое слово (по умолчанию True).указать метку столбца для использования при записи индекса с
index_label.указать строковые столбцы для разбора как даты и времени с помощью
parse_datesключевое слово вread_sql_query()иread_sql_table().
Предупреждение
Некоторые существующие функции или псевдонимы функций устарели
и будут удалены в будущих версиях. К ним относятся: tquery, uquery,
read_frame, frame_query, write_frame.
Предупреждение
Поддержка 'mysql' при использовании объектов соединения DBAPI устарела. MySQL будет поддерживаться далее с движками SQLAlchemy (GH 6900).
Мультииндексирование с использованием слайсеров#
В версии 0.14.0 мы добавили новый способ среза объектов с MultiIndex. Вы можете срезать MultiIndex, предоставив несколько индексаторов.
Вы можете предоставить любой из селекторов, как если бы вы индексировали по метке, см. Выбор по метке, включая срезы, списки меток, метки и булевы индексаторы.
Вы можете использовать slice(None) чтобы выбрать всё содержимое что уровень. Вам не нужно указывать все
глубже уровни, они будут подразумеваться как slice(None).
Как обычно, обе стороны слайсеров включены, так как это индексирование по меткам.
См. документация См. также проблемы (GH 6134, GH 4036, GH 3057, GH 2598, GH 5641, GH 7106)
Предупреждение
Вы должны указать все оси в
.locспецификатор, означающий индексатор для index и для столбцы. Есть некоторые неоднозначные случаи, когда переданный индексатор может быть неверно истолкован как индексация оба оси, а не, скажем, в MultiIndex для строк.Вам следует сделать следующее:
>>> df.loc[(slice('A1', 'A3'), ...), :] # noqa: E901
rather than this:
>>> df.loc[(slice('A1', 'A3'), ...)] # noqa: E901
Предупреждение
Вам нужно убедиться, что оси выбора полностью лексикографически отсортированы!
In [41]: def mklbl(prefix, n):
....: return ["%s%s" % (prefix, i) for i in range(n)]
....:
In [42]: index = pd.MultiIndex.from_product([mklbl('A', 4),
....: mklbl('B', 2),
....: mklbl('C', 4),
....: mklbl('D', 2)])
....:
In [43]: columns = pd.MultiIndex.from_tuples([('a', 'foo'), ('a', 'bar'),
....: ('b', 'foo'), ('b', 'bah')],
....: names=['lvl0', 'lvl1'])
....:
In [44]: df = pd.DataFrame(np.arange(len(index) * len(columns)).reshape((len(index),
....: len(columns))),
....: index=index,
....: columns=columns).sort_index().sort_index(axis=1)
....:
In [45]: df
Out[45]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9 8 11 10
D1 13 12 15 14
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 237 236 239 238
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 249 248 251 250
D1 253 252 255 254
[64 rows x 4 columns]
Базовое срезы MultiIndex с использованием срезов, списков и меток.
In [46]: df.loc[(slice('A1', 'A3'), slice(None), ['C1', 'C3']), :]
Out[46]:
lvl0 a b
lvl1 bar foo bah foo
A1 B0 C1 D0 73 72 75 74
D1 77 76 79 78
C3 D0 89 88 91 90
D1 93 92 95 94
B1 C1 D0 105 104 107 106
... ... ... ... ...
A3 B0 C3 D1 221 220 223 222
B1 C1 D0 233 232 235 234
D1 237 236 239 238
C3 D0 249 248 251 250
D1 253 252 255 254
[24 rows x 4 columns]
Вы можете использовать pd.IndexSlice для сокращения создания этих срезов
In [47]: idx = pd.IndexSlice
In [48]: df.loc[idx[:, :, ['C1', 'C3']], idx[:, 'foo']]
Out[48]:
lvl0 a b
lvl1 foo foo
A0 B0 C1 D0 8 10
D1 12 14
C3 D0 24 26
D1 28 30
B1 C1 D0 40 42
... ... ...
A3 B0 C3 D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[32 rows x 2 columns]
С помощью этого метода можно выполнять довольно сложные выборки по нескольким осям одновременно.
In [49]: df.loc['A1', (slice(None), 'foo')]
Out[49]:
lvl0 a b
lvl1 foo foo
B0 C0 D0 64 66
D1 68 70
C1 D0 72 74
D1 76 78
C2 D0 80 82
... ... ...
B1 C1 D1 108 110
C2 D0 112 114
D1 116 118
C3 D0 120 122
D1 124 126
[16 rows x 2 columns]
In [50]: df.loc[idx[:, :, ['C1', 'C3']], idx[:, 'foo']]
Out[50]:
lvl0 a b
lvl1 foo foo
A0 B0 C1 D0 8 10
D1 12 14
C3 D0 24 26
D1 28 30
B1 C1 D0 40 42
... ... ...
A3 B0 C3 D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[32 rows x 2 columns]
Используя булевый индексатор, вы можете предоставить выбор, связанный с values.
In [51]: mask = df[('a', 'foo')] > 200
In [52]: df.loc[idx[mask, :, ['C1', 'C3']], idx[:, 'foo']]
Out[52]:
lvl0 a b
lvl1 foo foo
A3 B0 C1 D1 204 206
C3 D0 216 218
D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[7 rows x 2 columns]
Вы также можете указать axis аргумент для .loc для интерпретации переданных
срезов на одной оси.
In [53]: df.loc(axis=0)[:, :, ['C1', 'C3']]
Out[53]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C1 D0 9 8 11 10
D1 13 12 15 14
C3 D0 25 24 27 26
D1 29 28 31 30
B1 C1 D0 41 40 43 42
... ... ... ... ...
A3 B0 C3 D1 221 220 223 222
B1 C1 D0 233 232 235 234
D1 237 236 239 238
C3 D0 249 248 251 250
D1 253 252 255 254
[32 rows x 4 columns]
Кроме того, вы можете set значения с использованием этих методов
In [54]: df2 = df.copy()
In [55]: df2.loc(axis=0)[:, :, ['C1', 'C3']] = -10
In [56]: df2
Out[56]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 -10 -10 -10 -10
D1 -10 -10 -10 -10
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 -10 -10 -10 -10
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 -10 -10 -10 -10
D1 -10 -10 -10 -10
[64 rows x 4 columns]
Вы также можете использовать правую часть выравниваемого объекта.
In [57]: df2 = df.copy()
In [58]: df2.loc[idx[:, :, ['C1', 'C3']], :] = df2 * 1000
In [59]: df2
Out[59]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9000 8000 11000 10000
D1 13000 12000 15000 14000
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 237000 236000 239000 238000
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 249000 248000 251000 250000
D1 253000 252000 255000 254000
[64 rows x 4 columns]
Построение графиков#
Шестиугольные бинарные графики из
DataFrame.plotсkind='hexbin'(GH 5478), См. документация.DataFrame.plotиSeries.plotтеперь поддерживает построение area plot с указаниемkind='area'(GH 6656), См. документацияКруговые диаграммы из
Series.plotиDataFrame.plotсkind='pie'(GH 6976), См. документация.Построение графиков с полосами погрешностей теперь поддерживается в
.plotметодDataFrameиSeriesобъекты (GH 3796, GH 6834), См. документация.DataFrame.plotиSeries.plotтеперь поддерживаетtableключевое слово для построения графиковmatplotlib.Table, См. документация.tableключевое слово может принимать следующие значения.False: Ничего не делать (по умолчанию).True: Нарисовать таблицу с использованиемDataFrameилиSeriesвызываетсяplotметод. Данные будут транспонированы для соответствия стандартному макету matplotlib.DataFrameилиSeries: Нарисовать matplotlib.table, используя переданные данные. Данные будут нарисованы так, как отображаются в методе печати (не транспонируются автоматически). Также вспомогательная функцияpandas.tools.plotting.tableдобавлен для создания таблицы изDataFrameиSeries, и добавить его вmatplotlib.Axes.
plot(legend='reverse')теперь будет обращать порядок меток легенды для большинства видов графиков. (GH 6014)Линейный график и график с областями могут быть наложены путем
stacked=True(GH 6656)Следующие ключевые слова теперь допустимы для
DataFrame.plot()сkind='bar'иkind='barh':width: Укажите ширину столбца. В предыдущих версиях в matplotlib передавалось статическое значение 0.5, и его нельзя было переопределить. (GH 6604)align: Укажите выравнивание столбцов. По умолчаниюcenter(отличается от matplotlib). В предыдущих версиях pandas передаетalign='edge'в matplotlib и настроить расположение наcenterсамо по себе, и это приводит кalignключевое слово не применяется, как ожидалось. (GH 4525)position: Указать относительные выравнивания для макета столбчатой диаграммы. От 0 (левый/нижний край) до 1 (правый/верхний край). По умолчанию 0.5 (центр). (GH 6604)
Из-за значения по умолчанию
alignизменения значений, координаты столбчатых диаграмм теперь расположены на целых значениях (0.0, 1.0, 2.0 …). Это предназначено для того, чтобы столбчатые диаграммы располагались на тех же координатах, что и линейные. Однако столбчатая диаграмма может отличаться неожиданно, когда вы вручную настраиваете расположение столбцов или область рисования, например, используяset_xlim,set_ylim, и т.д. В таких случаях, пожалуйста, измените свой скрипт для соответствия новым координатам.The
parallel_coordinates()функция теперь принимает аргументcolorвместоcolors. AFutureWarningвызывается, чтобы предупредить, что старыйcolorsаргумент не будет поддерживаться в будущем выпуске. (GH 6956)The
parallel_coordinates()иandrews_curves()функции теперь принимают позиционный аргументframeвместоdata. AFutureWarningвызывается, если старыйdataаргумент используется по имени. (GH 6956)DataFrame.boxplot()теперь поддерживаетlayoutключевое слово (GH 6769)DataFrame.boxplot()имеет новый аргумент ключевого слова,return_type. Он принимает'dict','axes', или'both', в этом случае возвращается namedtuple с осями matplotlib и словарём линий matplotlib.
Устаревшие функции/изменения в предыдущих версиях#
Существуют устаревшие функции предыдущих версий, которые вступают в силу с версии 0.14.0.
Удалить
DateRangeв пользуDatetimeIndex(GH 6816)Удалить
columnключевое слово изDataFrame.sort(GH 4370)Удалить
precisionключевое слово изset_eng_float_format()(GH 395)Удалить
force_unicodeключевое слово изDataFrame.to_string(),DataFrame.to_latex(), иDataFrame.to_html(); эти функции по умолчанию кодируют в unicode (GH 2224, GH 2225)Удалить
nanRepключевое слово изDataFrame.to_csv()иDataFrame.to_string()(GH 275)Удалить
uniqueключевое слово изHDFStore.select_column()(GH 3256)Удалить
inferTimeRuleключевое слово изTimestamp.offset()(GH 391)Удалить
nameключевое слово изget_data_yahoo()иget_data_google()( коммит b921d1a )Удалить
offsetключевое слово изDatetimeIndexконструктор ( коммит 3136390 )Удалить
time_ruleиз нескольких статистических функций скользящего момента, таких какrolling_sum()(GH 1042)Удалено отрицательное
-логические операции над массивами numpy в пользу использования inv~, так как это будет устаревшим в numpy 1.9 (GH 6960)
Устаревшие функции#
The
pivot_table()/DataFrame.pivot_table()иcrosstab()функции теперь принимают аргументыindexиcolumnsвместоrowsиcols. AFutureWarningвызывается для предупреждения, что старыйrowsиcolsаргументы не будут поддерживаться в будущем выпуске (GH 5505)The
DataFrame.drop_duplicates()иDataFrame.duplicated()методы теперь принимают аргументsubsetвместоcolsдля лучшего соответствия сDataFrame.dropna(). AFutureWarningвызывается для предупреждения, что старыйcolsаргументы не будут поддерживаться в будущем релизе (GH 6680)The
DataFrame.to_csv()иDataFrame.to_excel()функции теперь принимают аргументcolumnsвместоcols. AFutureWarningвызывается для предупреждения, что старыйcolsаргументы не будут поддерживаться в будущем выпуске (GH 6645)Индексаторы будут предупреждать
FutureWarningпри использовании со скалярным индексатором и нечисловым индексом с плавающей точкой (GH 4892, GH 6960)# non-floating point indexes can only be indexed by integers / labels In [1]: pd.Series(1, np.arange(5))[3.0] pandas/core/index.py:469: FutureWarning: scalar indexers for index type Int64Index should be integers and not floating point Out[1]: 1 In [2]: pd.Series(1, np.arange(5)).iloc[3.0] pandas/core/index.py:469: FutureWarning: scalar indexers for index type Int64Index should be integers and not floating point Out[2]: 1 In [3]: pd.Series(1, np.arange(5)).iloc[3.0:4] pandas/core/index.py:527: FutureWarning: slice indexers when using iloc should be integers and not floating point Out[3]: 3 1 dtype: int64 # these are Float64Indexes, so integer or floating point is acceptable In [4]: pd.Series(1, np.arange(5.))[3] Out[4]: 1 In [5]: pd.Series(1, np.arange(5.))[3.0] Out[6]: 1
Совместимость с Numpy 1.9 в отношении предупреждений об устаревании (GH 6960)
Panel.shift()теперь имеет сигнатуру функции, соответствующуюDataFrame.shift(). Старый позиционный аргументlagsбыл изменён на аргумент ключевого словаperiodsсо значением по умолчанию 1. AFutureWarningвозникает, если старый аргументlagsиспользуется по имени. (GH 6910)The
orderименованный аргументfactorize()будет удален. (GH 6926).Удалить
copyключевое слово изDataFrame.xs(),Panel.major_xs(),Panel.minor_xs(). Представление будет возвращено, если возможно, в противном случае будет создана копия. Ранее пользователь мог подумать, чтоcopy=Falseбудет ВСЕГДА возвращать представление. (GH 6894)The
parallel_coordinates()функция теперь принимает аргументcolorвместоcolors. AFutureWarningвызывается, чтобы предупредить, что старыйcolorsаргумент не будет поддерживаться в будущем выпуске. (GH 6956)The
parallel_coordinates()иandrews_curves()функции теперь принимают позиционный аргументframeвместоdata. AFutureWarningвызывается, если старыйdataаргумент используется по имени. (GH 6956)Поддержка 'mysql' при использовании объектов соединения DBAPI устарела. MySQL будет поддерживаться далее с движками SQLAlchemy (GH 6900).
Следующие
io.sqlфункции были объявлены устаревшими:tquery,uquery,read_frame,frame_query,write_frame.The
percentile_widthименованный аргумент вdescribe()был устаревшим. Используйтеpercentilesключевое слово вместо этого, которое принимает список процентилей для отображения. Выходные данные по умолчанию не изменены.Тип возвращаемого значения по умолчанию для
boxplot()изменится с dict на matplotlib Axes в будущем релизе. Вы можете использовать будущее поведение сейчас, передавreturn_type='axes'для построения диаграммы размаха.
Известные проблемы#
OpenPyXL 2.0.0 нарушает обратную совместимость (GH 7169)
Улучшения#
DataFrame и Series создадут объект MultiIndex, если передан словарь кортежей, см. документация (GH 3323)
In [60]: pd.Series({('a', 'b'): 1, ('a', 'a'): 0, ....: ('a', 'c'): 2, ('b', 'a'): 3, ('b', 'b'): 4}) ....: Out[60]: a b 1 a 0 c 2 b a 3 b 4 Length: 5, dtype: int64 In [61]: pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2}, ....: ('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4}, ....: ('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6}, ....: ('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8}, ....: ('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}}) ....: Out[61]: a b b a c a b A B 1.0 4.0 5.0 8.0 10.0 C 2.0 3.0 6.0 7.0 NaN D NaN NaN NaN NaN 9.0 [3 rows x 5 columns]
Добавлен
sym_diffметод дляIndex(GH 5543)DataFrame.to_latexтеперь принимает ключевое слово longtable, которое при значении True возвращает таблицу в среде longtable.GH 6617)Добавлена опция отключения экранирования в
DataFrame.to_latex(GH 6472)pd.read_clipboardбудет, если ключевое словоsepне указано, попытайтесь обнаружить данные, скопированные из электронной таблицы, и проанализировать соответствующим образом. (GH 6223)Объединение DataFrame с одним индексом и DataFrame с MultiIndex (GH 3662)
См. документация. Объединение MultiIndex DataFrame как слева, так и справа пока не поддерживается.
In [62]: household = pd.DataFrame({'household_id': [1, 2, 3], ....: 'male': [0, 1, 0], ....: 'wealth': [196087.3, 316478.7, 294750] ....: }, ....: columns=['household_id', 'male', 'wealth'] ....: ).set_index('household_id') ....: In [63]: household Out[63]: male wealth household_id 1 0 196087.3 2 1 316478.7 3 0 294750.0 [3 rows x 2 columns] In [64]: portfolio = pd.DataFrame({'household_id': [1, 2, 2, 3, 3, 3, 4], ....: 'asset_id': ["nl0000301109", ....: "nl0000289783", ....: "gb00b03mlx29", ....: "gb00b03mlx29", ....: "lu0197800237", ....: "nl0000289965", ....: np.nan], ....: 'name': ["ABN Amro", ....: "Robeco", ....: "Royal Dutch Shell", ....: "Royal Dutch Shell", ....: "AAB Eastern Europe Equity Fund", ....: "Postbank BioTech Fonds", ....: np.nan], ....: 'share': [1.0, 0.4, 0.6, 0.15, 0.6, 0.25, 1.0] ....: }, ....: columns=['household_id', 'asset_id', 'name', 'share'] ....: ).set_index(['household_id', 'asset_id']) ....: In [65]: portfolio Out[65]: name share household_id asset_id 1 nl0000301109 ABN Amro 1.00 2 nl0000289783 Robeco 0.40 gb00b03mlx29 Royal Dutch Shell 0.60 3 gb00b03mlx29 Royal Dutch Shell 0.15 lu0197800237 AAB Eastern Europe Equity Fund 0.60 nl0000289965 Postbank BioTech Fonds 0.25 4 NaN NaN 1.00 [7 rows x 2 columns] In [66]: household.join(portfolio, how='inner') Out[66]: male ... share household_id asset_id ... 1 nl0000301109 0 ... 1.00 2 nl0000289783 1 ... 0.40 gb00b03mlx29 1 ... 0.60 3 gb00b03mlx29 0 ... 0.15 lu0197800237 0 ... 0.60 nl0000289965 0 ... 0.25 [6 rows x 4 columns]
quotechar,doublequote, иescapecharтеперь может быть указан при использованииDataFrame.to_csv(GH 5414, GH 4528)Частичная сортировка только по указанным уровням MultiIndex с помощью
sort_remainingбулевый аргумент. (GH 3984)Добавлен
to_julian_datetoTimeStampиDatetimeIndex. Юлианская дата используется в основном в астрономии и представляет количество дней от полудня 1 января 4713 года до н.э. Поскольку в pandas для определения времени используются наносекунды, фактический диапазон дат, который можно использовать, — с 1678 года н.э. по 2262 год н.э. (GH 4041)DataFrame.to_stataтеперь будет проверять данные на совместимость с типами данных Stata и повышать тип при необходимости. Когда невозможно безопасно повысить тип, выдаётся предупреждение (GH 6327)DataFrame.to_stataиStataWriterбудет принимать ключевые аргументы time_stamp и data_label, которые позволяют установить метку времени и метку набора данных при создании файла. (GH 6545)pandas.io.gbqтеперь корректно обрабатывает чтение строк в Unicode. (GH 5940)Календари праздников теперь доступны и могут использоваться с
CustomBusinessDayсмещение (GH 6719)Float64Indexтеперь поддерживаетсяfloat64dtype ndarray вместоobjectмассив типа данных (GH 6471).Реализовано
Panel.pct_change(GH 6904)Добавлен
howопция для функций скользящего момента, определяющая, как обрабатывать передискретизацию;rolling_max()по умолчанию max,rolling_min()по умолчанию min, а все остальные по умолчанию mean (GH 6297)CustomBusinessMonthBeginиCustomBusinessMonthEndтеперь доступны (GH 6866)Series.quantile()иDataFrame.quantile()теперь принимает массив квантилей.describe()теперь принимает массив процентилей для включения в сводную статистику (GH 4196)pivot_tableтеперь может приниматьGrouperbyindexиcolumnsключевые слова (GH 6913)In [67]: import datetime In [68]: df = pd.DataFrame({ ....: 'Branch': 'A A A A A B'.split(), ....: 'Buyer': 'Carl Mark Carl Carl Joe Joe'.split(), ....: 'Quantity': [1, 3, 5, 1, 8, 1], ....: 'Date': [datetime.datetime(2013, 11, 1, 13, 0), ....: datetime.datetime(2013, 9, 1, 13, 5), ....: datetime.datetime(2013, 10, 1, 20, 0), ....: datetime.datetime(2013, 10, 2, 10, 0), ....: datetime.datetime(2013, 11, 1, 20, 0), ....: datetime.datetime(2013, 10, 2, 10, 0)], ....: 'PayDay': [datetime.datetime(2013, 10, 4, 0, 0), ....: datetime.datetime(2013, 10, 15, 13, 5), ....: datetime.datetime(2013, 9, 5, 20, 0), ....: datetime.datetime(2013, 11, 2, 10, 0), ....: datetime.datetime(2013, 10, 7, 20, 0), ....: datetime.datetime(2013, 9, 5, 10, 0)]}) ....: In [69]: df Out[69]: Branch Buyer Quantity Date PayDay 0 A Carl 1 2013-11-01 13:00:00 2013-10-04 00:00:00 1 A Mark 3 2013-09-01 13:05:00 2013-10-15 13:05:00 2 A Carl 5 2013-10-01 20:00:00 2013-09-05 20:00:00 3 A Carl 1 2013-10-02 10:00:00 2013-11-02 10:00:00 4 A Joe 8 2013-11-01 20:00:00 2013-10-07 20:00:00 5 B Joe 1 2013-10-02 10:00:00 2013-09-05 10:00:00 [6 rows x 5 columns]
In [75]: df.pivot_table(values='Quantity', ....: index=pd.Grouper(freq='M', key='Date'), ....: columns=pd.Grouper(freq='M', key='PayDay'), ....: aggfunc="sum") Out[75]: PayDay 2013-09-30 2013-10-31 2013-11-30 Date 2013-09-30 NaN 3.0 NaN 2013-10-31 6.0 NaN 1.0 2013-11-30 NaN 9.0 NaN [3 rows x 3 columns]
Массивы строк могут быть обернуты до указанной ширины (
str.wrap) (GH 6999)Добавить
nsmallest()иSeries.nlargest()методы для Series, см. документация (GH 3960)PeriodIndexполностью поддерживает частичную строковую индексацию, какDatetimeIndex(GH 7043)In [76]: prng = pd.period_range('2013-01-01 09:00', periods=100, freq='H') In [77]: ps = pd.Series(np.random.randn(len(prng)), index=prng) In [78]: ps Out[78]: 2013-01-01 09:00 0.015696 2013-01-01 10:00 -2.242685 2013-01-01 11:00 1.150036 2013-01-01 12:00 0.991946 2013-01-01 13:00 0.953324 ... 2013-01-05 08:00 0.285296 2013-01-05 09:00 0.484288 2013-01-05 10:00 1.363482 2013-01-05 11:00 -0.781105 2013-01-05 12:00 -0.468018 Freq: H, Length: 100, dtype: float64 In [79]: ps['2013-01-02'] Out[79]: 2013-01-02 00:00 0.553439 2013-01-02 01:00 1.318152 2013-01-02 02:00 -0.469305 2013-01-02 03:00 0.675554 2013-01-02 04:00 -1.817027 ... 2013-01-02 19:00 0.036142 2013-01-02 20:00 -2.074978 2013-01-02 21:00 0.247792 2013-01-02 22:00 -0.897157 2013-01-02 23:00 -0.136795 Freq: H, Length: 24, dtype: float64
read_excelтеперь может читать миллисекунды в датах и времени Excel с xlrd >= 0.9.3. (GH 5945)pd.stats.moments.rolling_varтеперь использует метод Велфорда для повышения численной стабильности (GH 6817)pd.expanding_apply и pd.rolling_apply теперь принимают args и kwargs, которые передаются в func (GH 6289)
DataFrame.rank()теперь имеет опцию процентного ранга (GH 5971)Series.rank()теперь имеет опцию процентного ранга (GH 5971)Series.rank()иDataFrame.rank()теперь принимаютmethod='dense'для рангов без пропусков (GH 6514)Поддержка передачи
encodingс xlwt (GH 3710)Рефакторинг классов Block с удалением
Block.itemsатрибуты, чтобы избежать дублирования при обработке элементов (GH 6745, GH 6988).Тестовые утверждения обновлены для использования специализированных проверок (GH 6175)
Производительность#
Улучшение производительности при преобразовании
DatetimeIndexв плавающие порядковые номера используяDatetimeConverter(GH 6636)Улучшение производительности для
DataFrame.shift(GH 5609)Улучшение производительности при индексации в Series с MultiIndex (GH 5567)
Улучшения производительности при индексировании с одним типом данных (GH 6484)
Улучшение производительности создания DataFrame с определёнными смещениями путём удаления ошибочного кэширования (например, MonthEnd, BusinessMonthEnd), (GH 6479)
Улучшена производительность
CustomBusinessDay(GH 6584)улучшить производительность срезной индексации на Series со строковыми ключами (GH 6341, GH 6372)
Улучшение производительности для
DataFrame.from_recordsпри чтении указанного количества строк из итерируемого объекта (GH 6700)Улучшения производительности при преобразовании timedelta для целочисленных типов данных (GH 6754)
Улучшена производительность совместимых pickle-объектов (GH 6899)
Улучшение производительности в определенных операциях переиндексации путем оптимизации
take_2d(GH 6749)GroupBy.count()теперь реализован на Cython и значительно быстрее для большого количества групп (GH 7016).
Экспериментальный#
В версии 0.14.0 нет экспериментальных изменений.
Исправления ошибок#
Ошибка в Series ValueError, когда индекс не соответствует данным (GH 6532)
Предотвращение сегфолта из-за неподдержки MultiIndex в формате таблицы HDFStore (GH 1848)
Ошибка в
pd.DataFrame.sort_indexгде mergesort не был стабильным, когдаascending=False(GH 6399)Ошибка в
pd.tseries.frequencies.to_offsetкогда аргумент имеет ведущие нули (GH 6391)Ошибка в генерации строки версии для dev-версий с неглубокими клонами / установкой из tarball (GH 6127)
Нестабильный разбор часовых поясов
Timestamp/to_datetimeдля текущего года (GH 5958)Ошибки индексирования с переупорядоченными индексами (GH 6252, GH 6254)
Ошибка при преобразовании строковых типов в DatetimeIndex с указанной частотой (GH 6273, GH 6274)
Ошибка в
evalгде приведение типов не удалось для больших выражений (GH 6205)Ошибка в interpolate с
inplace=True(GH 6281)HDFStore.removeтеперь обрабатывает start и stop (GH 6177)HDFStore.select_as_multipleобрабатывает start и stop так же, какselect(GH 6177)HDFStore.select_as_coordinatesиselect_columnработает сwhereусловие, которое приводит к фильтрам (GH 6177)Регрессия при соединении non_unique_indexes (GH 6329)
Проблема с groupby
aggс одной функцией и фреймом смешанного типа (GH 6337)Ошибка в
DataFrame.replace()при передаче не-boolto_replaceаргумент (GH 6332)Вызов при попытке выравнивания на разных уровнях назначения MultiIndex (GH 3738)
Ошибка при установке сложных типов данных через булево индексирование (GH 6345)
Ошибка в TimeGrouper/resample при представлении не монотонного DatetimeIndex, которая возвращала неверные результаты. (GH 4161)
Ошибка в распространении имени индекса в TimeGrouper/resample (GH 4161)
TimeGrouper имеет более совместимый API с остальными группировщиками (например,
groupsотсутствовал) (GH 3881)Ошибка при множественной группировке с TimeGrouper в зависимости от порядка целевых столбцов (GH 6764)
Ошибка в
pd.evalпри разборе строк с возможными токенами, такими как'&'(GH 6351)Исправлена ошибка правильной обработки размещений
-infв Panels при делении на целое число 0 (GH 6178)DataFrame.shiftсaxis=1вызывал исключение (GH 6371)Отключены тесты буфера обмена до времени релиза (запускайте локально с
nosetests -A disabled) (GH 6048).Ошибка в
DataFrame.replace()при передаче вложенногоdictкоторый содержал ключи, отсутствующие в значениях для замены (GH 6342)str.matchигнорировал флаг na (GH 6609).Ошибка в take с дублирующимися столбцами, которые не были консолидированы (GH 6240)
Ошибка в interpolate, изменяющая типы данных (GH 6290)
Ошибка в
Series.get, использовал ошибочный метод доступа (GH 6383)Ошибка в запросах hdfstore вида
where=[('date', '>=', datetime(2013,1,1)), ('date', '<=', datetime(2014,1,1))](GH 6313)Ошибка в
DataFrame.dropnaс повторяющимися индексами (GH 6355)Регрессия в цепочке индексирования getitem со встроенным спискообразным из 0.12 (GH 6394)
Float64Indexс nan, которые некорректно сравниваются (GH 6401)eval/queryвыражения со строками, содержащими@символ теперь будет работать (GH 6366).Ошибка в
Series.reindexпри указанииmethodс некоторыми значениями nan был непоследовательным (отмечено при ресемплинге) (GH 6418)Ошибка в
DataFrame.replace()где вложенные словари ошибочно зависели от порядка ключей и значений словаря (GH 5338).Проблема производительности при конкатенации с пустыми объектами (GH 3259)
Уточнение сортировки
sym_diffнаIndexобъекты сNaNзначения (GH 6444)Регрессия в
MultiIndex.from_productсDatetimeIndexв качестве входных данных (GH 6439)Ошибка в
str.extractпри передаче нестандартного индекса (GH 6348)Ошибка в
str.splitпри передачеpat=Noneиn=1(GH 6466)Ошибка в
io.data.DataReaderпри передаче"F-F_Momentum_Factor"иdata_source="famafrench"(GH 6460)Ошибка в
sumизtimedelta64[ns]серия (GH 6462)Ошибка в
resampleс часовым поясом и определенными смещениями (GH 6397)Ошибка в
iat/ilocс дублирующимися индексами в Series (GH 6493)Ошибка в
read_htmlгде nan'ы некорректно использовались для обозначения пропущенных значений в тексте. Следует использовать пустую строку для согласованности с остальной частью pandas (GH 5129).Ошибка в
read_htmlтесты, где перенаправленные недействительные URL-адреса приводили к провалу одного теста (GH 6445).Ошибка в индексации по нескольким осям с использованием
.locна неуникальных индексах (GH 6504)Ошибка, вызывавшая повреждение _ref_locs при срезовой индексации по оси столбцов DataFrame (GH 6525)
Регрессия с версии 0.13 в обработке numpy
datetime64не-ns типы данных при создании Series (GH 6529).namesатрибут MultiIndex, переданный вset_indexтеперь сохраняются (GH 6459).Ошибка в setitem с дублирующимся индексом и выравниваемым правым операндом (GH 6541)
Ошибка в setitem с
.locна смешанных целочисленных индексах (GH 6546)Ошибка в
pd.read_stataчто использовало бы неправильные типы данных и пропущенные значения (GH 6327)Ошибка в
DataFrame.to_stataчто приводило к потере данных в некоторых случаях и могло экспортироваться с использованием неправильных типов данных и пропущенных значений (GH 6335)StataWriterзаменяет пропущенные значения в строковых столбцах пустой строкой (GH 6802)Несогласованные типы в
Timestampсложение/вычитание (GH 6543)Ошибка в сохранении частоты при сложении/вычитании Timestamp (GH 4547)
Ошибка при поиске в пустом списке вызвала
IndexErrorисключения (GH 6536, GH 6551)Series.quantileвызов исключения наobjectтип данных (GH 6555)Ошибка в
.xsсnanв уровне при удалении (GH 6574)Ошибка в fillna с
method='bfill/ffill'иdatetime64[ns]тип данных (GH 6587)Ошибка при записи в SQL со смешанными типами данных, возможно приводящая к потере данных (GH 6509)
Ошибка в
Series.pop(GH 6600)Ошибка в
ilocиндексирование при совпадении позиционного индексатораInt64Indexсоответствующей оси, и переупорядочивания не произошло (GH 6612)Ошибка в
fillnaсlimitиvalueуказанныйОшибка в
DataFrame.to_stataкогда столбцы имеют нестроковые имена (GH 4558)Ошибка в совместимости с
np.compress, обнаружено в (GH 6658)Ошибка в бинарных операциях с правой частью в виде Series, не выравнивающейся (GH 6681)
Ошибка в
DataFrame.to_stataкоторый некорректно обрабатывает значения nan и игнорируетwith_indexименованный аргумент (GH 6685)Ошибка в resample с дополнительными бинами при использовании равномерно делимой частоты (GH 4076)
Ошибка в согласованности агрегации groupby при передаче пользовательской функции (GH 6715)
Ошибка в resample, когда
how=Noneчастота ресемплинга совпадает с частотой оси (GH 5955)Ошибка в определении понижающего преобразования с пустыми массивами (GH 6733)
Ошибка в
obj.blocksна разреженных контейнерах, удаляющих все, кроме последних элементов того же dtype (GH 6748)Ошибка при распаковке
NaT (NaTType)(GH 4606)Ошибка в
DataFrame.replace()где метасимволы регулярных выражений обрабатывались как регулярные выражения, даже когдаregex=False(GH 6777).Ошибка в операциях с timedelta на 32-битных платформах (GH 6808)
Исправлена ошибка при установке индекса с учетом часового пояса напрямую через
.index(GH 6785)Ошибка в expressions.py, где numexpr пытался вычислить арифметические операции (GH 6762).
Ошибка в Makefile, где не удалялись сгенерированные Cython C-файлы с
make clean(GH 6768)Ошибка с numpy < 1.7.2 при чтении длинных строк из
HDFStore(GH 6166)Ошибка в
DataFrame._reduceгде не булеподобные (0/1) целые числа преобразовывались в булевы значения. (GH 6806)Регрессия с версии 0.13 с
fillnaи Series с датой-временем (GH 6344)Ошибка при добавлении
np.timedelta64toDatetimeIndexс часовым поясом выдает некорректные результаты (GH 6818)Ошибка в
DataFrame.replace()где изменение типа данных через замену заменяло бы только первое вхождение значения (GH 6689)Улучшенное сообщение об ошибке при передаче частоты 'MS' в
Periodконструкция (GH5332)Ошибка в
Series.__unicode__когдаmax_rows=Noneи Series имеет более 1000 строк. (GH 6863)Ошибка в
groupby.get_groupгде датаподобные значения не всегда принимались (GH 5267)Ошибка в
groupBy.get_groupсозданныйTimeGrouperвызываетAttributeError(GH 6914)Ошибка в
DatetimeIndex.tz_localizeиDatetimeIndex.tz_convertпреобразованиеNaTнекорректно (GH 5546)Ошибка в арифметических операциях, затрагивающая
NaT(GH 6873)Ошибка в
Series.str.extractгде результирующийSeriesиз одного совпадения группы не было переименовано в имя группыОшибка в
DataFrame.to_csvгде установкаindex=Falseигнорировалheaderkwarg (GH 6186)Ошибка в
DataFrame.plotиSeries.plot, где легенда ведет себя непоследовательно при многократном построении графиков на одних и тех же осях (GH 6678)Внутренние тесты для исправления
__finalize__/ ошибка в merge не завершающая (GH 6923, GH 6927)принимать
TextFileReaderвconcat, что влияло на распространенную пользовательскую идиому (GH 6583)Ошибка в C-парсере с ведущими пробелами (GH 3374)
Ошибка в C-парсере с
delim_whitespace=Trueи\r-разделенные строкиОшибка в парсере Python с явным MultiIndex в строке, следующей за заголовком столбца (GH 6893)
Ошибка в
Series.rankиDataFrame.rankчто приводило к присвоению одинакового ранга всем малым числам с плавающей точкой (<1e-13) (GH 6886)Ошибка в
DataFrame.applyс функциями, которые использовали*argsили**kwargsи возвращал пустой результат (GH 6952)Ошибка в sum/mean на 32-битных платформах при переполнении (GH 6915)
Перемещено
Panel.shifttoNDFrame.slice_shiftи исправлено для учета нескольких типов данных. (GH 6959)Ошибка при включении
subplots=TrueвDataFrame.plotтолько один столбец вызываетTypeError, иSeries.plotвызываетAttributeError(GH 6951)Ошибка в
DataFrame.plotрисует ненужные оси при включенииsubplotsиkind=scatter(GH 6951)Ошибка в
read_csvиз файловой системы с кодировкой, отличной от utf-8 (GH 6807)Ошибка в
ilocпри установке / выравнивании (GH 6766)Ошибка, вызывающая UnicodeEncodeError при вызове get_dummies с юникодными значениями и префиксом (GH 6885)
Ошибка в отображении курсора графика временных рядов с частотой (GH 5453)
Ошибка обнаружена в
groupby.plotпри использованииFloat64Index(GH 7025)Остановлены сбои тестов, если данные опционов не могут быть загружены с Yahoo (GH 7034)
Ошибка в
parallel_coordinatesиradvizгде переупорядочивание столбца класса вызывало возможное несоответствие цвета/класса (GH 6956)Ошибка в
radvizиandrews_curvesгде несколько значений 'color' передавались в метод построения графиков (GH 6956)Ошибка в
Float64Index.isin()где содержитсяnans заставили бы индексы утверждать, что они содержат все элементы (GH 7066).Ошибка в
DataFrame.boxplotгде не удалось использовать переданную осьaxаргумент (GH 3578)Ошибка в
XlsxWriterиXlwtWriterреализации, которые приводили к форматированию столбцов с датой и временем без времени (GH 7075) передавались в метод построения графиковread_fwf()обрабатываетNoneвcolspecкак обычные срезы Python. Теперь он читает с начала или до конца строки, когдаcolspecсодержитNone(ранее вызывалTypeError)Ошибка в когерентности кэша при цепочечной индексации и срезе; добавлено
_is_viewсвойство дляNDFrameдля правильного предсказания просмотров; отметитьis_copyнаxsтолько если это фактическая копия (а не представление) (GH 7084)Ошибка при создании DatetimeIndex из строкового ndarray с
dayfirst=True(GH 5917)Ошибка в
MultiIndex.from_arraysсозданный изDatetimeIndexне сохраняетfreqиtz(GH 7090)Ошибка в
unstackвызываетValueErrorкогдаMultiIndexсодержитPeriodIndex(GH 4342)Ошибка в
boxplotиhistрисует ненужные оси (GH 6769)Регрессия в
groupby.nth()для индексаторов вне границ (GH 6621)Ошибка в
quantileсо значениями даты и времени (GH 6965)Ошибка в
Dataframe.set_index,reindexиpivotне сохраняютDatetimeIndexиPeriodIndexатрибуты (GH 3950, GH 5878, GH 6631)Ошибка в
MultiIndex.get_level_valuesне сохраняетDatetimeIndexиPeriodIndexатрибуты (GH 7092)Ошибка в
Groupbyне сохраняетtz(GH 3950)Ошибка в
PeriodIndexЧастичная строковая нарезка (GH 6716)Ошибка в HTML-представлении усеченной Series или DataFrame, не отображающая имя класса с
large_reprустановлено в ‘info’ (GH 7105)Ошибка в
DatetimeIndexуказаниеfreqвызываетValueErrorкогда переданное значение слишком короткое (GH 7098)Исправлена ошибка с
inforepr не учитываетdisplay.max_info_columnsнастройка (GH 6939)Ошибка
PeriodIndexсрез строки с выходящими за границы значениями (GH 5407)Исправлена ошибка памяти в реализации хэш-таблицы/факторизаторе при изменении размера больших таблиц (GH 7157)
Ошибка в
isnullпри применении к 0-мерным массивам объектов (GH 7176)Ошибка в
query/evalгде глобальные константы не были найдены правильно (GH 7178)Ошибка в распознавании позиционных индексаторов списка вне диапазона с
ilocи многомерный кортеж индексатора (GH 7189)Ошибка в setitem с одним значением, MultiIndex и целочисленными индексами (GH 7190, -0.348)
Ошибка в вычислении выражений с обратными операциями, проявляющаяся в операциях серия-датафрейм (GH 7198, GH 7192)
Ошибка в многоосевом индексировании с > 2 измерениями и MultiIndex (GH 7199)
Исправлена ошибка, при которой недопустимые операции eval/query могли переполнить стек (GH 5198)
Участники#
Всего 94 человека внесли патчи в этот релиз. Люди со знаком «+» рядом с именами внесли патч впервые.
Acanthostega +
Adam Marcus +
Алекс Гаудио
Алекс Ротберг
AllenDowney +
Andrew Rosenfeld +
Andy Hayden
Antoine Mazières +
Benedikt Sauer
Брэд Буран
Кристофер Уилан
Clark Fitzgerald
DSM
Dale Jung
Dan Allan
Dan Birken
Daniel Waeber
Дэвид Юнг +
David Stephens +
Дуглас МакНил
Garrett Drapala
Gouthaman Balaraman +
Guillaume Poulin +
Jacob Howard +
Джейкоб Шаер
Jason Sexauer +
Jeff Reback
Jeff Tratner
Jeffrey Starr +
John David Reaver +
John McNamara
John W. O’Brien
Jonathan Chambers
Joris Van den Bossche
Джулия Эванс
Júlio +
K.-Michael Aye
Katie Atkinson +
Келси Джордал
Kevin Sheppard +
Matt Wittmann +
Маттиас Кун +
Max Grender-Jones +
Michael E. Gruen +
Mike Kelly
Нипун Батра +
Noah Spies +
PKEuS
Patrick O’Keeffe
Филлип Клауд
Pietro Battiston +
Randy Carnevale +
Robert Gibboni +
Skipper Seabold
SplashDance +
Stephan Hoyer +
Tim Cera +
Тобиас Брандт
Todd Jennings +
Tom Augspurger
TomAugspurger
Yaroslav Halchenko
agijsberts +
akittredge
анкостис +
anomrake
anton-d +
bashtage +
benjamin +
bwignall
cgohlke +
chebee7i +
clham +
danielballan
hshimizu77 +
hugo +
immerrr
ischwabacher +
jaimefrio +
jreback
jsexauer +
kdiether +
michaelws +
mikebailey +
ojdo +
onesandzeroes +
phaebz +
ribonoous +
rockg
sinhrks +
unutbu
westurner
y-p
zach powers