Внесение вклада#
Этот проект является результатом совместных усилий сообщества, сформированным большим количеством участников со всего мира. Для получения дополнительной информации об истории и людях, стоящих за scikit-learn, см. О нас. Он размещён на scikit-learn/scikit-learn. Процесс принятия решений и структура управления scikit-learn изложены в Управление и принятие решений в Scikit-learn.
Scikit-learn — это селективный когда дело доходит до добавления новых алгоритмов и функций. Это означает, что лучший способ внести вклад и помочь проекту — начать работать над известными проблемами. См. Способы внести вклад чтобы узнать, как делать значимые вклады.
Способы внести вклад#
Существует множество способов внести вклад в scikit-learn. К ним относятся:
ссылаясь на scikit-learn в вашем блоге и статьях, ссылаясь на него с вашего сайта, или просто запуская его сказать 'Я использую это'; это помогает нам продвигать проект
сообщая о трудностях при использовании этого пакета, отправив проблемаи ставя "лайк" на проблемах, о которых сообщили другие и которые актуальны для вас (см. Отправка отчета об ошибке или запроса на новую функцию подробности)
улучшение Документация
внесение вклада в код
Существует множество способов внести вклад без написания кода, и мы ценим эти вклады так же высоко, как и вклады в код. Если вы заинтересованы во внесении вклада в код, пожалуйста, имейте в виду, что scikit-learn превратился в зрелый и сложный проект с момента его создания в 2007 году. Вклад в код проекта обычно требует продвинутых навыков и может не быть лучшим местом для начала, если вы новичок в открытом исходном коде. В этом случае мы предлагаем вам следовать рекомендациям в Новые участники.
Новые участники#
Мы рекомендуем новым участникам начать с прочтения этого руководства по вкладу, в частности Способы внести вклад, Политика автоматизированных вкладов.
Далее мы советуем новым участникам получить базовые знания о scikit-learn и открытом исходном коде, выполнив:
улучшение и исследование проблем
подтверждая, что сообщенная проблема может быть воспроизведена, и предоставляя минимальный воспроизводимый код (если отсутствует), может помочь вам узнать о различных случаях использования и потребностях пользователей
исследование корневой причины проблемы поможет вам ознакомиться с кодом scikit-learn
рецензирование pull request'ов других разработчиков поможет вам понять требования и ожидаемое качество вкладов
улучшение Документация может помочь углубить ваши знания о статистических концепциях, лежащих в основе моделей и функций, и API scikit-learn
Если вы хотите внести вклад в код после получения базовых знаний, мы рекомендуем начать с поиска интересующей вас проблемы в области, с которой вы уже знакомы как пользователь или имеете фоновые знания. Мы рекомендуем начинать с небольших pull request и следовать нашим Контрольный список pull request. Для ожидаемого этикета относительно того, над какими проблемами и застрявшими PR работать, пожалуйста, прочитайте Базовые классы для всех оценщиков и различные служебные функции., Застопорившиеся и Невостребованные Проблемы и Проблемы с тегом «Требуется сортировка».
Мы редко используем метку «good first issue», потому что сложно делать предположения о новых участниках, и эти задачи часто оказываются сложнее, чем изначально предполагалось. Тем не менее, полезно проверить, есть ли “хорошие первые задачи”, хотя обратите внимание, что их решение все еще может быть трудоемким в зависимости от вашего предыдущего опыта.
Для более опытных участников scikit-learn, задачи с меткой "Лёгкие" может быть хорошим местом для поиска.
Политика автоматизированных вкладов#
Вклад в scikit-learn требует человеческого суждения, контекстного понимания и знакомства со структурой и целями scikit-learn. Это не подходит для автоматической обработки инструментами ИИ.
Пожалуйста, воздержитесь от отправки проблем или запросов на включение, сгенерированных полностью автоматизированными инструментами. Сопровождающие оставляют за собой право, по своему усмотрению, закрывать такие отправки и блокировать любую учетную запись, ответственную за них.
Просмотрите все изменения кода или документации, сделанные с помощью инструментов ИИ, и убедитесь, что вы понимаете все изменения и можете объяснить их по запросу, прежде чем отправлять их под своим именем. Не отправляйте код, сгенерированный ИИ, который вы лично не просмотрели, не поняли и не протестировали, так как это тратит время сопровождающих.
Пожалуйста, не вставляйте текст, сгенерированный ИИ, в описания проблем, PR или комментарии, так как это затрудняет оценку вашего вклада рецензентами. Мы допускаем его использование для улучшения грамматики или если вы не являетесь носителем английского языка.
Если вы использовали инструменты ИИ, пожалуйста, укажите это в описании вашего PR.
PR, которые нарушают эту политику, будут закрыты без рецензирования.
Отправка отчета об ошибке или запроса на новую функцию#
Мы используем GitHub issues для отслеживания всех ошибок и запросов функций; не стесняйтесь открывать issue, если вы нашли ошибку или хотите увидеть реализацию функции.
Если у вас возникли проблемы при использовании этого пакета, не стесняйтесь создать тикет в Система отслеживания ошибок. Вы также можете отправлять запросы на функции или pull-запросы.
Рекомендуется проверить, соответствует ли ваша проблема следующим правилам перед отправкой:
Убедитесь, что ваша проблема в настоящее время не решается другими проблемы или запросы на включение изменений.
Если вы отправляете запрос на алгоритм или функцию, пожалуйста, убедитесь, что алгоритм соответствует нашим новые требования алгоритма.
Если вы отправляете отчет об ошибке, мы настоятельно рекомендуем следовать рекомендациям в Как создать хороший отчет об ошибке.
Когда запрос на добавление функции включает изменения в принципы API или изменения зависимостей или поддерживаемых версий, он должен быть подкреплен SLEP, который должен быть отправлен как pull-request в предложения по улучшению используя Шаблон SLEP и следует процессу принятия решений, описанному в Управление и принятие решений в Scikit-learn.
Как создать хороший отчет об ошибке#
Когда вы отправляете проблему в GitHub, пожалуйста, постарайтесь следовать этим рекомендациям! Это значительно упростит предоставление вам качественной обратной связи:
Идеальный отчет об ошибке содержит короткий воспроизводимый фрагмент кода, таким образом, любой может попытаться легко воспроизвести ошибку. Если ваш фрагмент кода длиннее примерно 50 строк, пожалуйста, приведите ссылку на Gist или репозиторий GitHub.
Если невозможно включить воспроизводимый фрагмент, укажите конкретно, что оценщики и/или функции задействованы, и форма данных.
Если возникает исключение, пожалуйста, предоставить полную трассировку стека.
Пожалуйста, укажите ваш тип операционной системы и номер версии, а также ваш Результат этого метода идентиченЭту информацию можно получить, выполнив:
python -c "import sklearn; sklearn.show_versions()"Пожалуйста, убедитесь, что все фрагменты кода и сообщения об ошибках форматируются в соответствующих блоках кода. См. Создание и выделение блоков кода для получения дополнительной информации.
Если вы хотите помочь курировать проблемы, прочитайте о Триажирование ошибок и курация проблем.
Вклад в код и документацию#
Предпочтительный способ внести вклад в scikit-learn — это форкнуть основной репозиторий на GitHub, затем отправьте «запрос на слияние» (PR).
Чтобы начать, вам нужно
Найдите задачу для работы (см. Новые участники)
Следуйте Рабочий процесс разработки
Убедитесь, что вы отметили Контрольный список pull request
Если вы хотите внести вклад Документация, убедитесь, что вы можете собрать локально, перед отправкой PR.
Примечание
Чтобы избежать дублирования работы, настоятельно рекомендуется выполнить поиск по трекер проблем и Список PR. Если есть сомнения по поводу дублирования работы или если вы хотите работать над нетривиальной функцией, рекомендуется сначала открыть issue в трекер проблем чтобы получить обратную связь от основных разработчиков.
Один простой способ найти задачу для работы — использовать метку «требуется помощь» в вашем поиске. Это перечисляет все задачи, которые еще не были заявлены. Если вы хотите работать над такой задачей, оставьте комментарий со своей идеей о том, как вы планируете подойти к ней, и начните работать над ней. Если кто-то другой уже сказал, что будет работать над задачей в последние 2-3 недели, пожалуйста, дайте им закончить свою работу, в противном случае считайте задачу заброшенной и возьмите ее на себя.
Для поддержания качества кодовой базы и упрощения процесса ревью, любой вклад должен соответствовать руководства по написанию кода, в частности:
Не изменяйте несвязанные строки, чтобы сохранить PR сфокусированным на области, указанной в его описании или задаче.
Пишите только встроенные комментарии, которые добавляют ценность, и избегайте очевидных утверждений: объясняйте "почему", а не "что".
Самое главное: Не вносите код, который вы не понимаете.
Рабочий процесс разработки#
Следующие шаги описывают процесс изменения кода и отправки PR:
Синхронизируйте ваш
mainветка сupstream/mainветка, подробнее о GitHub Docs:git checkout main git fetch upstream git merge upstream/main
Создать ветку признаков для хранения изменений разработки:
git checkout -b my_featureи начните вносить изменения. Всегда используйте ветку для разработки. Это хорошая практика — никогда не работать на
mainветка!Разработайте функцию в вашей ветке функций на вашем компьютере, используя Git для управления версиями. Когда вы закончите редактирование, добавьте измененные файлы с помощью
git addи затемgit commit:git add modified_files git commit
Примечание
pre-commit может автоматически переформатировать ваш код, когда вы делаете
git commit. Когда это происходит, вам нужно сделатьgit addс последующимgit commitснова. В некоторых редких случаях может потребоваться исправить вещи вручную, использовать сообщение об ошибке, чтобы понять, что нужно изменить, и использоватьgit addс последующимgit commitдо тех пор, пока коммит не будет успешным.Затем отправьте изменения в свой аккаунт GitHub с помощью:
git push -u origin my_featureСледуйте эти инструкции по созданию запроса на слияние из вашей ветки. Это отправит уведомление потенциальным рецензентам. Возможно, вы захотите отправить сообщение в discord в канале разработки для большей видимости, если ваш pull request не получает внимания через пару дней (хотя мгновенные ответы не гарантируются).
Часто полезно поддерживать синхронизацию вашей локальной ветки признаков с последними изменениями основного репозитория scikit-learn:
git fetch upstream
git merge upstream/main
Впоследствии вам может потребоваться разрешить конфликты. Вы можете обратиться к Документация Git, связанная с разрешением конфликтов слияния с использованием командной строки.
Контрольный список pull request#
Перед слиянием PR он должен быть одобрен двумя основными разработчиками. Незавершенный вклад – где вы ожидаете выполнить больше работы перед получением полного обзора – должен быть помечен как черновик pull request и изменяется на "готово к проверке", когда созреет. Черновики PR могут быть полезны для: указания, что вы работаете над чем-то, чтобы избежать дублирования работы, запроса широкого обзора функциональности или API или поиска соавторов. Черновики PR часто выигрывают от включения список задач в описании PR.
Чтобы облегчить процесс рецензирования, мы рекомендуем, чтобы ваш вклад соответствовал следующим правилам перед пометкой PR как «готов к рецензированию». выделено жирным особенно важны:
Дайте вашему pull request полезное название которое суммирует, что делает ваш вклад. Этот заголовок часто становится сообщением коммита после слияния, поэтому он должен суммировать ваш вклад для потомков. В некоторых случаях достаточно "Fix <НАЗВАНИЕ ПРОБЛЕМЫ>". "Fix #<НОМЕР ПРОБЛЕМЫ>" никогда не является хорошим заголовком.
Убедитесь, что ваш код проходит тесты. Весь набор тестов может быть запущен с помощью
pytest, но обычно это не рекомендуется, так как занимает много времени. Часто достаточно запустить только тест, связанный с вашими изменениями: например, если вы изменили что-то вsklearn/linear_model/_logistic.py, выполнение следующих команд обычно достаточно:pytest sklearn/linear_model/_logistic.pyчтобы убедиться, что примеры doctest правильныpytest sklearn/linear_model/tests/test_logistic.pyдля запуска тестов, специфичных для файлаpytest sklearn/linear_modelдля тестирования всегоlinear_modelмодульpytest doc/modules/linear_model.rstчтобы убедиться, что примеры в руководстве пользователя корректны.pytest sklearn/tests/test_common.py -k LogisticRegressionдля запуска всех наших проверок оценщиков (особенно дляLogisticRegression, если это оценщик, который вы изменили).
Могут быть и другие падающие тесты, но они будут отловлены CI, так что вам не нужно запускать весь набор тестов локально. Для руководства по использованию
pytestэффективно, см. Полезные псевдонимы и флаги pytest.Убедитесь, что ваш код правильно прокомментирован и задокументирован, и убедитесь, что документация отображается правильно. Чтобы собрать документацию, пожалуйста, обратитесь к нашему Документация рекомендаций. CI также будет строить документацию: пожалуйста, обратитесь к Сгенерированная документация на GitHub Actions.
Тесты необходимы для принятия улучшений. Исправления ошибок или новые функции должны предоставляться с тестами на отсутствие регрессии. Эти тесты проверяют правильность поведения исправления или функции. Таким образом, дальнейшие изменения в кодовой базе гарантированно будут соответствовать желаемому поведению. В случае исправления ошибок, на момент PR тесты на отсутствие регрессии должны падать для кодовой базы в
mainветка и передача для кода PR.Если ваш PR может повлиять на пользователей, вам нужно добавить запись в журнал изменений, описывающую изменения в вашем PR. См. README для получения дополнительной информации.
Следуйте Руководство по стилю кодирования.
При возможности используйте инструменты и скрипты проверки в
sklearn.utilsмодуля. Список служебных процедур, доступных для разработчиков, можно найти в Утилиты для разработчиков страница.Часто pull request'ы решают одну или несколько других проблем (или pull request'ов). Если слияние вашего pull request'а означает, что некоторые другие проблемы/PR должны быть закрыты, вам следует используйте ключевые слова для создания ссылок на них (например,
Fixes #1234; несколько issues/PR разрешены, если каждый из них предваряется ключевым словом). При слиянии эти issues/PR будут автоматически закрыты GitHub. Если ваш pull request просто связан с некоторыми другими issues/PR, или он лишь частично решает целевую проблему, создайте ссылку на них без использования ключевых слов (например,Towards #1234).PRs часто должны обосновывать изменение через бенчмарки производительности и эффективности (см. Мониторинг производительности) или через примеры использования. Примеры также иллюстрируют возможности и особенности библиотеки пользователям. Посмотрите другие примеры в examples/ каталог для справки. Примеры должны демонстрировать, почему новая функциональность полезна на практике и, если возможно, сравнивать её с другими методами, доступными в scikit-learn.
Новые функции требуют некоторых затрат на поддержку. Мы ожидаем, что авторы PR будут участвовать в поддержке кода, который они отправляют, по крайней мере изначально. Новые функции должны быть проиллюстрированы повествовательной документацией в руководстве пользователя, с небольшими фрагментами кода. Если это уместно, пожалуйста, также добавьте ссылки в литературе, с ссылками на PDF когда это возможно.
Руководство пользователя также должно включать ожидаемую временную и пространственную сложность алгоритма и масштабируемость, например, «этот алгоритм может масштабироваться до большого количества образцов > 100000, но не масштабируется по размерности:
n_featuresожидается ниже 100".
Вы также можете проверить наш Руководство по рецензированию кода чтобы получить представление о том, что рецензенты будут ожидать.
Вы можете проверить на наличие распространенных ошибок программирования с помощью следующих инструментов:
Код с хорошим покрытием модульными тестами (не менее 80%, лучше 100%), проверьте с помощью:
pip install pytest pytest-cov pytest --cov sklearn path/to/tests
Смотрите также Тестирование и улучшение покрытия тестами.
Запустить статический анализ с
mypy:mypy sklearnЭто не должно создавать новых ошибок в вашем запросе на включение. Используя
# type: ignoreаннотация может быть обходным решением для некоторых случаев, которые не поддерживаются mypy, в частности,при импорте модулей C или Cython,
на свойствах с декораторами.
Дополнительные баллы за вклады, включающие анализ производительности с скриптом бенчмарка и выводом профилирования (см. Мониторинг производительности). Также ознакомьтесь с Как оптимизировать для скорости руководство для получения дополнительной информации о профилировании и оптимизациях Cython.
Примечание
Мы создадим столбчатую диаграмму, показывающую тестовые оценки для разного количества компонент PCA, вместе с горизонтальными линиями, указывающими наилучшую оценку и порог в одно стандартное отклонение.
Смотрите также
Для двух очень хорошо документированных и более подробных руководств по рабочему процессу разработки пожалуйста, посетите Рабочий процесс разработки Scipy - и Рабочий процесс Astropy для разработчиков разделах.
Непрерывная интеграция (CI)#
Azure pipelines используются для тестирования scikit-learn на Linux, Mac и Windows, с различными зависимостями и настройками.
CircleCI используется для сборки документации для просмотра.
Github Actions используются для различных задач, включая сборку wheel-пакетов и дистрибутивов исходного кода.
Маркеры сообщений коммитов#
Обратите внимание, что если в последнем сообщении коммита появляется один из следующих маркеров, предпринимаются указанные действия.
Маркер сообщения коммита |
Действие, предпринятое CI |
|---|---|
[ci skip] |
CI полностью пропускается |
[cd build] |
CD запускается (собираются колеса и исходное распределение) |
[lint skip] |
Azure pipeline пропускает линтинг |
[scipy-dev] |
Сборка и тестирование с нашими зависимостями (numpy, scipy и т.д.) в версиях для разработки |
[свободнопоточный] |
Сборка и тестирование с CPython 3.14 с поддержкой свободных потоков |
[pyodide] |
Сборка и тестирование с Pyodide |
[azure parallel] |
Запуск заданий Azure CI параллельно |
[float32] |
Запуск тестов float32 путем установки |
[все случайные сиды] |
Запустите тесты с помощью |
[doc skip] |
Документация не собрана |
[doc quick] |
Документация собрана, но исключает графики из галереи примеров |
[сборка документации] |
Документация построена, включая галерею примеров графиков (очень длинная) |
Обратите внимание, что по умолчанию документация строится, но выполняются только примеры, которые непосредственно изменены запросом на включение.
Разрешение конфликтов в файлах блокировок#
Вот фрагмент bash-скрипта, который помогает разрешать конфликты в файлах окружения и блокировок:
# pull latest upstream/main
git pull upstream main --no-rebase
# resolve conflicts - keeping the upstream/main version for specific files
git checkout --theirs build_tools/*/*.lock build_tools/*/*environment.yml \
build_tools/*/*lock.txt build_tools/*/*requirements.txt
git add build_tools/*/*.lock build_tools/*/*environment.yml \
build_tools/*/*lock.txt build_tools/*/*requirements.txt
git merge --continue
Это объединит upstream/main в нашу ветку, автоматически расставляя приоритеты для
upstream/main для конфликтующих файлов окружения и блокировки (этого достаточно, потому что мы пересоздадим файлы блокировки позже).
Обратите внимание, что это исправляет только конфликты в файлах окружения и блокировки, и у вас могут быть другие конфликты для разрешения.
Наконец, необходимо повторно сгенерировать файлы окружения и блокировки для CI, выполнив команду:
python build_tools/update_environments_and_lock_files.py
Базовые классы для всех оценщиков и различные служебные функции.#
Поскольку добавление признака может быть длительным процессом, некоторые пул-реквесты кажутся неактивными, но незавершенными. В таком случае взять их на себя — отличная услуга для проекта. Хороший этикет для взятия на себя:
Определить, остановлен ли PR
Запрос на включение изменений может иметь метку «застрявший» или «требуется помощь», если мы уже определили его как кандидата для других участников.
Чтобы решить, является ли неактивный PR застрявшим, спросите участника, планирует ли он/она продолжить работу над PR в ближайшее время. Отсутствие ответа в течение 2 недель с активностью, продвигающей PR вперед, предполагает, что PR застрял и приведет к пометке этого PR как «требуется помощь».
Обратите внимание, что если PR получил более ранние комментарии по вкладу, на которые не было ответа в течение месяца, можно предположить, что PR застопорился, и сократить время ожидания до одного дня.
После спринта, последующие действия по неслитым PR, открытым во время спринта, будут сообщены участникам спринта, и эти PR будут помечены тегом "sprint". PR с тегом "sprint" могут быть перераспределены или объявлены застрявшими лидерами спринта.
Принятие на себя застопорившегося PR: Чтобы взять на себя PR, важно оставить комментарий в застопорившемся PR о том, что вы берёте его на себя, и добавить ссылку из нового PR на старый. Новый PR должен быть создан путём ответвления от старого.
Застопорившиеся и Невостребованные Проблемы#
Вообще говоря, задачи, которые доступны для взятия, будут иметь “нужна помощь”тег. Однако не все проблемы, требующие участников, будут иметь этот тег, так как тег 'help wanted' не всегда актуален с состоянием проблемы. Участники могут найти проблемы, которые всё ещё доступны, используя следующие рекомендации:
Во-первых, чтобы определить, заявлена ли проблема:
Проверить связанные pull requests
Проверьте обсуждение, чтобы увидеть, сказал ли кто-нибудь, что работает над созданием pull request
Если участник комментирует проблему, говоря, что работает над ней, ожидается pull request в течение 2 недель (для нового участника) или 4 недель (для участника или основного разработчика), если не указан более длительный срок. По истечении этого времени другой участник может взять проблему и создать pull request для нее. Мы рекомендуем участникам напрямую комментировать застопорившуюся или незанятую проблему, чтобы сообщить участникам сообщества, что они будут работать над ней.
Если проблема связана с замороженный pull request, мы рекомендуем, чтобы участники следовали процедуре, описанной в Базовые классы для всех оценщиков и различные служебные функции. раздел, а не работа непосредственно над проблемой.
Проблемы с тегом «Требуется сортировка»#
The “Требует сортировки” Метка означает, что проблема еще не подтверждена или полностью понята. Она сигнализирует участникам scikit-learn о необходимости уточнить проблему, обсудить масштаб и определить следующие шаги. Вы можете присоединиться к обсуждению, но в соответствии с нашими Кодекс поведения пожалуйста, не открывайте PR, пока метка "Needs Triage" не будет удалена, есть четкий консенсус по решению проблемы и некоторые направления по ее устранению.
Видеоресурсы#
Эти видео — пошаговые введения о том, как внести вклад в scikit-learn, и являются отличным дополнением к текстовым руководствам. Пожалуйста, убедитесь, что все равно проверяете наши руководства, так как они описывают наш последний актуальный рабочий процесс.
Краткий курс по вкладу в Scikit-Learn и проекты с открытым исходным кодом: Видео, Транскрипт
Пример отправки Pull Request в scikit-learn: Видео, Транскрипт
Инструкции и практические советы, специфичные для спринта: Видео, Транскрипт
3 компонента проверки Pull Request: Видео, Транскрипт
Примечание
В январе 2021 года название ветки по умолчанию изменилось с master to main
для репозитория scikit-learn на GitHub, чтобы использовать более инклюзивные термины. Эти видео были созданы до переименования ветки. Для участников, которые просматривают эти видео для настройки рабочей среды и отправки PR, master должно быть заменено на main.
Документация#
Мы приветствуем продуманные вклады в документацию и готовы рассмотреть дополнения в следующих областях:
Строки документации функций/методов/классов: Также известная как "документация API", эти описания объясняют, что делает объект, и детализируют любые параметры, атрибуты и методы. Строки документации находятся рядом с кодом в sklearn/, и генерируются в соответствии с doc/api_reference.py. Чтобы добавить, обновить, удалить или устареть публичный API, который указан в Справочник API, здесь стоит посмотреть.
Руководство пользователя: Они предоставляют более подробную информацию об алгоритмах, реализованных в scikit-learn, и обычно находятся в корне doc/ каталог и doc/modules/.
Примеры: Они предоставляют полные примеры кода, которые могут демонстрировать использование модулей scikit-learn, сравнивать различные алгоритмы или обсуждать их интерпретацию и т.д. Примеры находятся в examples/.
Другие документы reStructuredText: Они предоставляют различную другую полезную информацию (например, Вклад в pandas руководство) и находятся в doc/.
Рекомендации по написанию docstrings#
Вы можете использовать
pytestдля тестирования docstrings, например, предполагая, чтоRandomForestClassifierdocstring был изменён, следующая команда проверит его соответствие требованиям:pytest --doctest-modules sklearn/ensemble/_forest.py -k RandomForestClassifierПравильный порядок разделов: Parameters, Returns, See Also, Notes, Examples. См. документация numpydoc для получения информации о других возможных разделах.
При документировании параметров и атрибутов вот список некоторых хорошо отформатированных примеров
n_clusters : int, default=3 The number of clusters detected by the algorithm. some_param : {"hello", "goodbye"}, bool or int, default=True The parameter description goes here, which can be either a string literal (either `hello` or `goodbye`), a bool, or an int. The default value is True. array_parameter : {array-like, sparse matrix} of shape (n_samples, n_features) \ or (n_samples,) This parameter accepts data in either of the mentioned forms, with one of the mentioned shapes. The default value is `np.ones(shape=(n_samples,))`. list_param : list of int typed_ndarray : ndarray of shape (n_samples,), dtype=np.int32 sample_weight : array-like of shape (n_samples,), default=None multioutput_array : ndarray of shape (n_samples, n_classes) or list of such arraysВ целом имейте в виду следующее:
Используйте базовые типы Python. (
boolвместоboolean)Используйте скобки для определения форм:
array-like of shape (n_samples,)илиarray-like of shape (n_samples, n_features)Для строк с несколькими вариантами используйте скобки:
input: {'log', 'squared', 'multinomial'}1D или 2D данные могут быть подмножеством
{array-like, ndarray, sparse matrix, dataframe}. Обратите внимание, чтоarray-likeтакже может бытьlist, в то время какndarrayявно является толькоnumpy.ndarray.Укажите
dataframeкогда используются "фреймоподобные" признаки, такие как имена столбцов.При указании типа данных списка используйте
ofв качестве разделителя:list of int. Когда параметр поддерживает массивы с информацией о форме и/или типе данных и список таких массивов, вы можете использовать один изarray-like of shape (n_samples,) or list of such arrays.При указании dtype для ndarray используйте, например.
dtype=np.int32после определения формы:ndarray of shape (n_samples,), dtype=np.int32. Вы можете указать несколько dtype как набор:array-like of shape (n_samples,), dtype={np.float64, np.float32}. Если нужно указать произвольную точность, используйтеintegralиfloatingвместо Python dtypeintиfloat. Когда обаintиfloatingподдерживаются, нет необходимости указывать dtype.Когда значение по умолчанию
None,Noneнужно указать только в конце сdefault=None. Обязательно укажите в документации, что это означает для параметра или атрибута бытьNone.
Добавить «Смотрите также» в документации для связанных классов/функций.
“См. также” в строках документации должно быть по одной строке на ссылку, с двоеточием и объяснением, например:
See Also -------- SelectKBest : Select features based on the k highest scores. SelectFpr : Select features based on a false positive rate test.
Раздел «Примечания» является необязательным. Он предназначен для предоставления информации о специфическом поведении функции/класса/метода класса/метода.
A
Noteтакже может быть добавлен к атрибуту, но в этом случае требуется использование.. rubric:: Noteдиректива.Добавьте один или два сниппеты кода в разделе «Пример», чтобы показать, как его можно использовать. Код должен быть запускаемым как есть, т.е. он должен включать все необходимые импорты. Сделайте этот раздел как можно более кратким.
Руководство по написанию руководства пользователя и других документов в reStructuredText#
Важно соблюдать баланс между математическими и алгоритмическими деталями и давать читателю интуитивное понимание того, что делает алгоритм.
Начните с краткого, упрощённого объяснения того, что алгоритм/код делает с данными.
Подчеркните полезность функции и её рекомендуемое применение. Учтите сложность алгоритма (\(O\left(g\left(n\right)\right)\)) если доступны, так как 'правила большого пальца' могут сильно зависеть от машины. Только если эти сложности недоступны, тогда могут быть предоставлены правила большого пальца.
Включите соответствующую иллюстрацию (сгенерированную из примера) для наглядного представления.
Включите один или два коротких примера кода, демонстрирующих использование функции.
Введите необходимые математические уравнения, за которыми следуют ссылки. Откладывая математические аспекты, документация становится более доступной для пользователей, в первую очередь заинтересованных в понимании практических последствий функции, а не её внутренней механики.
При редактировании reStructuredText (
.rst) файлы, старайтесь сохранять длину строки менее 88 символов, когда это возможно (исключения включают ссылки и таблицы).В файлах reStructuredText scikit-learn как одинарные, так и двойные обратные кавычки вокруг текста будут отображаться как встроенный литерал (часто используется для кода, например,
list). Это связано с определенными настройками, которые мы установили. Одиночные обратные кавычки следует использовать в настоящее время.Too much information makes it difficult for users to access the content they are interested in. Use dropdowns to factorize it by using the following syntax
.. dropdown:: Dropdown title Dropdown content.
Приведённый выше фрагмент кода приведёт к следующему выпадающему списку:
Заголовок выпадающего списка#
Выпадающее содержимое.
Информация, которую можно скрыть по умолчанию с помощью выпадающих списков:
низкие иерархические разделы, такие как
References,Properties, и т.д. (см., например, подразделы в Компромисс ошибок обнаружения (DET));подробные математические детали;
повествование, специфичное для случая использования;
В общем, повествование, которое может заинтересовать только пользователей, желающих выйти за рамки прагматики конкретного инструмента.
Не использовать выпадающие списки для раздела низкого уровня
Examples, так как он должен оставаться видимым для всех пользователей. Убедитесь, чтоExamplesраздел идет сразу после основного обсуждения с минимально возможным свернутым разделом между ними.Имейте в виду, что выпадающие списки нарушают перекрестные ссылки. Если это имеет смысл, скройте ссылку вместе с текстом, упоминающим её. В противном случае не используйте выпадающий список.
Рекомендации по написанию ссылок#
Когда библиографические ссылки доступны с arxiv или Цифровой идентификатор объекта идентификационные номера, используйте директивы sphinx
:arxiv:или:doi:. Например, смотрите ссылки в Spectral Clustering Graphs.Для раздела "References" в строках документации см.
sklearn.metrics.silhouette_scoreв качестве примера.Для перекрестных ссылок на другие страницы документации scikit-learn используйте синтаксис перекрестных ссылок reStructuredText:
Раздел: для ссылки на произвольный раздел документации используйте метки ссылок (см. Документация Sphinx). Например:
.. _my-section: My section ---------- This is the text of the section. To refer to itself use :ref:`my-section`.
Не следует изменять существующие метки ссылок sphinx, так как это нарушит существующие перекрестные ссылки и внешние ссылки, указывающие на конкретные разделы документации scikit-learn.
Глоссарий: ссылка на термин в Глоссарий общих терминов и элементов API:
:term:`cross_validation`
Функция: чтобы сослаться на документацию функции, используйте полный путь импорта к функции:
:func:`~sklearn.model_selection.cross_val_score`
Однако, если существует
.. currentmodule::директива выше вас в документе, вам нужно будет использовать только путь к функции, следующей за текущим указанным модулем. Например:.. currentmodule:: sklearn.model_selection :func:`cross_val_score`
Класс: для ссылки на документацию класса используйте полный путь импорта к классу, если только нет
.. currentmodule::директива в документе выше (см. выше)::class:`~sklearn.preprocessing.StandardScaler`
Вы можете редактировать документацию с помощью любого текстового редактора, а затем генерировать
HTML-вывод, следуя Сборка документации. Полученные HTML-файлы
будут размещены в _build/html/ и могут быть просмотрены в веб-браузере, например,
открыв локальный _build/html/index.html файл или запуском локального сервера
python -m http.server -d _build/html
Сборка документации#
Перед отправкой запроса на слияние проверьте, не ввели ли ваши изменения новые предупреждения sphinx, собрав документацию локально, и попытайтесь их исправить.
Сначала убедитесь, что у вас есть правильно установлен разрабатываемая версия. Кроме того, для сборки документации требуется установка некоторых дополнительных пакетов:
pip install sphinx sphinx-gallery numpydoc matplotlib Pillow pandas \
polars scikit-image packaging seaborn sphinx-prompt \
sphinxext-opengraph sphinx-copybutton plotly pooch \
pydata-sphinx-theme sphinxcontrib-sass sphinx-design \
sphinx-remove-toctrees
Чтобы собрать документацию, вы должны находиться в doc папка:
cd doc
В подавляющем большинстве случаев вам нужно только сгенерировать веб-сайт без галереи примеров:
make
Документация будет сгенерирована в _build/html/stable каталог и доступны для просмотра в веб-браузере, например, открыв локальный
_build/html/stable/index.html файла.
Чтобы также сгенерировать галерею примеров, можно использовать:
make html
Это запустит все примеры, что займёт некоторое время. Вы также можете запустить только несколько примеров на основе их имён файлов.
Вот способ запустить все примеры с именами файлов, содержащими plot_calibration:
EXAMPLES_PATTERN="plot_calibration" make html
Вы можете использовать регулярные выражения для более сложных случаев использования.
Установить переменную окружения NO_MATHJAX=1 если вы планируете просматривать документацию в
автономном режиме. Чтобы собрать PDF-руководство, выполните:
make latexpdf
Версия Sphinx
Хотя мы прилагаем все усилия, чтобы документация собиралась в как можно большем количестве версий Sphinx, разные версии имеют небольшие различия в поведении. Для получения наилучших результатов следует использовать ту же версию, что и на CircleCI. Смотрите Поиск на GitHub чтобы знать точную версию.
Сгенерированная документация на GitHub Actions#
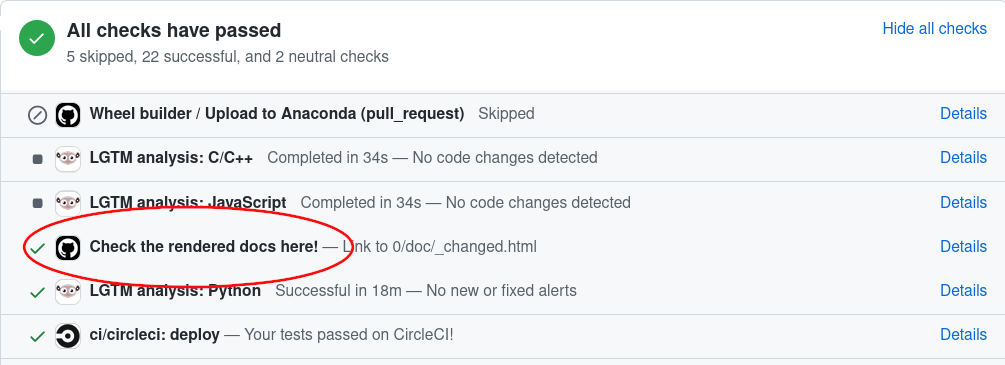
Когда вы изменяете документацию в pull request, GitHub Actions автоматически собирает её. Чтобы просмотреть сгенерированную документацию GitHub Actions, просто перейдите в нижнюю часть страницы вашего PR, найдите пункт «Check the rendered docs here!» и нажмите на 'details' рядом с ним:
Тестирование и улучшение покрытия тестами#
Высококачественный модульное тестирование
является краеугольным камнем процесса разработки scikit-learn. Для этой
цели мы используем pytest
пакет. Тесты — это функции с соответствующими именами, расположенные в tests
подкаталоги, которые проверяют корректность алгоритмов и
различные опции кода.
Запуск pytest в папке запустит все тесты соответствующих подпакетов. Для более подробного pytest рабочий процесс, пожалуйста, обратитесь к
Контрольный список pull request.
Мы ожидаем, что покрытие кода новыми функциями будет не менее 90%.
Рабочий процесс для улучшения покрытия тестами#
Для проверки покрытия кода необходимо установить покрытие пакет в дополнение к pytest.
Запустить
pytest --cov sklearn /path/to/tests. Выходные данные перечисляют для каждого файла номера строк, которые не протестированы.Найдите легкую задачу, посмотрев, какие строки не протестированы, напишите или адаптируйте тест специально для этих строк.
Цикл.
Мониторинг производительности#
Этот раздел сильно вдохновлен документация pandas.
При предложении изменений в существующую кодовую базу важно убедиться, что они не вводят регрессии производительности. Scikit-learn использует
asv benchmarks для мониторинга
производительности выбранных общих оценщиков и функций. Вы можете просмотреть
эти бенчмарки на дважды для одного и того же скорера приводит к двум отдельным объектам скорера.. Соответствующий набор тестов можно найти в asv_benchmarks/ каталог.
Чтобы использовать все возможности asv, вам потребуется либо conda или virtualenv. Для получения дополнительных сведений см. страница установки asv.
Прежде всего, вам необходимо установить версию для разработки asv:
pip install git+https://github.com/airspeed-velocity/asv
и измените ваш каталог на asv_benchmarks/:
cd asv_benchmarks
Набор тестов настроен на запуск против вашей локальной копии scikit-learn. Убедитесь, что она обновлена:
git fetch upstream
В наборе тестов производительности тесты организованы в соответствии с той же структурой, что и scikit-learn. Например, можно сравнить производительность конкретного оценщика между upstream/main и веткой, с которой вы работаете:
asv continuous -b LogisticRegression upstream/main HEAD
Команда по умолчанию использует conda для создания сред бенчмаркинга. Если вы хотите использовать virtualenv вместо этого, используйте -E флаг:
asv continuous -E virtualenv -b LogisticRegression upstream/main HEAD
Вы также можете указать целый модуль для тестирования производительности:
asv continuous -b linear_model upstream/main HEAD
Вы можете заменить HEAD любой локальной веткой. По умолчанию будут отображаться только
тесты, которые изменились как минимум на 10%. Вы можете управлять этим соотношением с помощью -f флаг.
Чтобы запустить полный набор тестов, просто удалите -b flag :
asv continuous upstream/main HEAD
Однако это может занять до двух часов. -b флаг также принимает регулярное
выражение для более сложного подмножества тестов для запуска.
Чтобы запустить тесты без сравнения с другой веткой, используйте run
команда:
asv run -b linear_model HEAD^!
Вы также можете запустить набор тестов производительности, используя версию scikit-learn, уже установленную в вашей текущей среде Python:
asv run --python=same
Это особенно полезно, когда вы установили scikit-learn в редактируемом режиме, чтобы избежать создания нового окружения каждый раз при запуске тестов. По умолчанию результаты не сохраняются при использовании существующей установки. Чтобы сохранить результаты, вы должны указать хэш коммита:
asv run --python=same --set-commit-hash= hash>
Бенчмарки сохраняются и организуются по машине, окружению и коммиту. Чтобы увидеть список всех сохраненных бенчмарков:
asv show
и чтобы увидеть отчёт о конкретном запуске:
asv show hash>
При запуске тестов для пул-реквеста, над которым вы работаете, пожалуйста, сообщайте результаты на github.
Набор тестов поддерживает дополнительные настраиваемые опции, которые можно задать
в benchmarks/config.json файл конфигурации. Например, бенчмарки
могут выполняться для предоставленного списка значений для n_jobs параметр.
Дополнительная информация о том, как написать бенчмарк и использовать asv, доступна в документация asv.
Сохранение обратной совместимости#
Deprecation#
Если любой общедоступный класс, функция, метод, атрибут или параметр переименован, мы всё ещё поддерживаем старый в течение двух релизов и выдаём предупреждение об устаревании при его вызове, передаче или доступе.
Устаревание класса или функции
Предположим, функция zero_one переименован в zero_one_loss, мы добавляем декоратор
utils.deprecated to zero_one и вызвать zero_one_loss из этой
функции:
from sklearn.utils import deprecated
def zero_one_loss(y_true, y_pred, normalize=True):
# actual implementation
pass
@deprecated(
"Function `zero_one` was renamed to `zero_one_loss` in 0.13 and will be "
"removed in 0.15. Default behavior is changed from `normalize=False` to "
"`normalize=True`"
)
def zero_one(y_true, y_pred, normalize=False):
return zero_one_loss(y_true, y_pred, normalize)
Также необходимо переместить zero_one из API_REFERENCE to
DEPRECATED_API_REFERENCE и добавьте zero_one_loss to API_REFERENCE в
doc/api_reference.py файл, чтобы отразить изменения в Справочник API.
Устаревание атрибута или метода
Если атрибут или метод нужно устареть, используйте декоратор
deprecated на свойстве. Обратите внимание, что
deprecated декоратор должен быть размещён перед property декоратор
если он есть, чтобы документация могла быть правильно отображена. Например, переименование
атрибута labels_ to classes_ может быть выполнено как:
@deprecated(
"Attribute `labels_` was deprecated in 0.13 and will be removed in 0.15. Use "
"`classes_` instead"
)
@property
def labels_(self):
return self.classes_
Устаревание параметра
Если параметр необходимо устареть, FutureWarning предупреждение должно быть поднято вручную. В следующем примере, k устарел и переименован в n_clusters:
import warnings
def example_function(n_clusters=8, k="deprecated"):
if k != "deprecated":
warnings.warn(
"`k` was renamed to `n_clusters` in 0.13 and will be removed in 0.15",
FutureWarning,
)
n_clusters = k
Когда изменение происходит в классе, мы проверяем и выдаём предупреждение в fit:
import warnings
class ExampleEstimator(BaseEstimator):
def __init__(self, n_clusters=8, k='deprecated'):
self.n_clusters = n_clusters
self.k = k
def fit(self, X, y):
if self.k != "deprecated":
warnings.warn(
"`k` was renamed to `n_clusters` in 0.13 and will be removed in 0.15.",
FutureWarning,
)
self._n_clusters = self.k
else:
self._n_clusters = self.n_clusters
Как в этих примерах, предупреждающее сообщение всегда должно указывать как версию, в которой произошло устаревание, так и версию, в которой старое поведение будет удалено. Если устаревание произошло в версии 0.x-dev, сообщение должно говорить, что устаревание произошло в версии 0.x, а удаление будет в 0.(x+2), чтобы у пользователей было достаточно времени адаптировать свой код к новому поведению. Например, если устаревание произошло в версии 0.18-dev, сообщение должно говорить, что это произошло в версии 0.18, а старое поведение будет удалено в версии 0.20.
Предупреждающее сообщение также должно включать краткое объяснение изменения и указывать пользователям на альтернативу.
Кроме того, в документации должна быть добавлена заметка об устаревании, напоминающая
ту же информацию, что и предупреждение об устаревании, как объяснено выше. Используйте
.. deprecated:: директива:
.. deprecated:: 0.13
``k`` was renamed to ``n_clusters`` in version 0.13 and will be removed
in 0.15.
Более того, устаревание требует теста, который гарантирует, что предупреждение выдается в соответствующих случаях, но не в других. Предупреждение должно быть перехвачено во всех других тестах (используя, например, @pytest.mark.filterwarnings),
и в примерах не должно быть предупреждений.
Изменить значение параметра по умолчанию#
Если значение параметра по умолчанию нужно изменить, пожалуйста, замените значение по умолчанию на конкретное значение (например, "warn") и вызывает
FutureWarning когда пользователи используют значение по умолчанию. Следующий
пример предполагает, что текущая версия — 0.20 и что мы изменяем
значение по умолчанию для n_clusters с 5 (старое значение по умолчанию для 0.20) до 10 (новое значение по умолчанию для 0.22):
import warnings
def example_function(n_clusters="warn"):
if n_clusters == "warn":
warnings.warn(
"The default value of `n_clusters` will change from 5 to 10 in 0.22.",
FutureWarning,
)
n_clusters = 5
Когда изменение происходит в классе, мы проверяем и выдаём предупреждение в fit:
import warnings
class ExampleEstimator:
def __init__(self, n_clusters="warn"):
self.n_clusters = n_clusters
def fit(self, X, y):
if self.n_clusters == "warn":
warnings.warn(
"The default value of `n_clusters` will change from 5 to 10 in 0.22.",
FutureWarning,
)
self._n_clusters = 5
Аналогично устареваниям, предупреждающее сообщение всегда должно указывать как версию, в которой произошло изменение, так и версию, в которой старое поведение будет удалено.
Описание параметра в docstring должно быть обновлено соответствующим образом путем добавления versionchanged директивы со старым и новым значением по умолчанию, указывая на
версию, когда изменение вступит в силу:
.. versionchanged:: 0.22
The default value for `n_clusters` will change from 5 to 10 in version 0.22.
Наконец, нам нужен тест, который гарантирует, что предупреждение возникает в соответствующих случаях, но не в других случаях. Предупреждение должно быть перехвачено во всех других тестах (используя, например, @pytest.mark.filterwarnings), и в примерах не должно быть предупреждений.
Руководство по рецензированию кода#
Проверка кода, внесенного в проект в виде PR, является важнейшим компонентом разработки scikit-learn. Мы призываем всех начать проверять код других разработчиков. Процесс проверки кода часто очень полезен для всех участников. Это особенно уместно, если это функция, которую вы хотели бы использовать, и поэтому можете критически оценить, соответствует ли PR вашим потребностям. Хотя каждый pull request должен быть подписан двумя основными разработчиками, вы можете ускорить этот процесс, предоставив свой отзыв.
Примечание
Разница между объективным улучшением и субъективной придиркой не всегда очевидна. Рецензентам следует помнить, что рецензирование кода в первую очередь направлено на снижение рисков в проекте. При рецензировании кода следует стремиться предотвращать ситуации, которые могут потребовать исправления ошибки, устаревания или отзыва. Что касается документации: опечатки, грамматические ошибки и неоднозначности лучше исправлять сразу.
Важные аспекты, которые должны быть рассмотрены при любом ревью кода#
Вот несколько важных аспектов, которые необходимо охватить в любом обзоре кода, от высокоуровневых вопросов до более детального контрольного списка.
Хотим ли мы это в библиотеке? Будет ли это использоваться? Вам, как пользователю scikit-learn, нравится изменение и вы планируете его использовать? Это в рамках scikit-learn? Будет ли стоимость поддержки новой функции оправдана её преимуществами?
Соответствует ли код API scikit-learn? Хорошо ли названы и интуитивно спроектированы публичные функции/классы/параметры?
Все ли публичные функции/классы и их параметры, типы возвращаемых значений и хранимые атрибуты названы в соответствии с соглашениями scikit-learn и четко документированы?
Описывается ли какая-либо новая функциональность в руководстве пользователя и иллюстрируется примерами?
Проверяется ли каждая публичная функция/класс? Проверяется ли разумный набор параметров, их значений, типов значений и комбинаций? Проверяют ли тесты, что код корректен, т.е. делает то, что говорит документация? Если изменение — это исправление ошибки, включён ли нерегрессионный тест? Эти тесты проверяют правильность поведения исправления или функции. Таким образом, дальнейшие изменения в кодовой базе гарантированно соответствуют желаемому поведению. В случае исправлений ошибок, на момент PR, нерегрессионные тесты должны падать для кодовой базы в
mainветку и пройти проверку для кода PR.Проходят ли тесты в сборке непрерывной интеграции? Если уместно, помогите участнику понять, почему тесты не прошли.
Покрывают ли тесты каждую строку кода (см. отчёт о покрытии в логе сборки)? Если нет, являются ли непокрытые строки хорошими исключениями?
Легко ли читать код и низка ли избыточность? Следует ли улучшить имена переменных для ясности или согласованности? Следует ли добавить комментарии? Следует ли удалить комментарии как бесполезные или избыточные?
Может ли код быть легко переписан для более эффективной работы в релевантных настройках?
Совместим ли код с предыдущими версиями? (или необходим цикл устаревания?)
Будет ли новый код добавлять зависимости от других библиотек? (это маловероятно для принятия)
Правильно ли отображается документация (см. Документация раздел для подробностей), и являются ли графики информативными?
Стандартные ответы для рецензирования включает некоторые частые комментарии, которые могут оставлять рецензенты.
Руководство по коммуникации#
Просмотр открытых запросов на включение изменений (PR) помогает продвигать проект. Это отличный способ ознакомиться с кодом и должен мотивировать участника продолжать вовлечение в проект. [1]
Каждый PR, хороший или плохой, является актом щедрости. Начало с положительного комментария поможет автору почувствовать себя вознагражденным, и ваши последующие замечания могут быть услышаны более четко. Вы также можете почувствовать себя хорошо.
Начните, если возможно, с крупных проблем, чтобы автор знал, что его поняли. Удерживайтесь от соблазна сразу перейти к построчному разбору или начать с мелких повсеместных проблем.
Не позволяйте идеальному быть врагом хорошего. Если вы делаете много мелких предложений, которые не попадают в Руководство по рецензированию кода, рассмотрите следующие подходы:
воздержитесь от отправки этих;
помечайте их как «Nit», чтобы участник знал, что их можно не исправлять;
продолжить в последующем PR, из вежливости, вы можете сообщить оригинальному участнику.
Не торопитесь, уделите время, чтобы сделать ваши комментарии понятными и обосновать ваши предложения.
Вы — лицо проекта. Плохие дни случаются у всех, в такие моменты вы заслуживаете перерыва: постарайтесь уделить время и оставаться офлайн.
Чтение существующей кодовой базы#
Чтение и осмысление существующей кодовой базы всегда является сложным упражнением, требующим времени и опыта для освоения. Хотя мы стараемся писать простой код в целом, понимание кода может показаться непосильным на первый взгляд, учитывая огромный размер проекта. Вот список советов, которые могут помочь сделать эту задачу проще и быстрее (в произвольном порядке).
Ознакомьтесь с API объектов scikit-learn: понять, что fit, predict, преобразовать, и т.д. используются для.
Прежде чем углубляться в чтение кода функции/класса, сначала просмотрите docstrings и попытайтесь понять, что делает каждый параметр/атрибут. Также может помочь остановиться на минуту и подумать как бы я сделал это сам, если бы пришлось?
Самое сложное часто — определить, какие части кода релевантны, а какие нет. В scikit-learn много проверки ввода выполняется, особенно в начале fit методы. Иногда только очень небольшая часть кода выполняет фактическую работу. Например, рассматривая
fitметодLinearRegression, то, что вы ищете, может быть просто вызовомscipy.linalg.lstsq, но оно скрыто в нескольких строках проверки входных данных и обработки различных видов параметров.Из-за использования Наследование, некоторые методы могут быть реализованы в родительских классах. Все оценщики наследуют как минимум от
BaseEstimator, и изMixinкласс (например,ClassifierMixin), который обеспечивает поведение по умолчанию в зависимости от типа оценщика (классификатор, регрессор, трансформер и т.д.).Иногда чтение тестов для данной функции даст вам представление о её предполагаемом назначении. Вы можете использовать
git grep(см. ниже) для поиска всех тестов, написанных для функции. Большинство тестов для конкретной функции/класса размещены подtests/папка модуляВы часто будете видеть код, выглядящий так:
out = Parallel(...)(delayed(some_function)(param) for param in some_iterable). Это запускаетsome_functionпараллельно с использованием Joblib.outзатем является итерируемым объектом, содержащим значения, возвращённыеsome_functionдля каждого вызова.Мы используем Cython для написания быстрого кода. Код на Cython находится в
.pyxи.pxdфайлы. Код на Cython имеет более C-подобный стиль: мы используем указатели, выполняем ручное выделение памяти и т.д. Наличие минимального опыта в C / C++ здесь практически обязательно. Для получения дополнительной информации см. Лучшие практики, соглашения и знания Cython.Освойте свои инструменты.
В таком большом проекте эффективность работы с любимым редактором или IDE значительно помогает в освоении кодовой базы. Возможность быстро переходить (или заглянуть) к определению функции/класса/атрибута очень помогает. Также помогает возможность быстро увидеть, где данное имя используется в файле.
Git также имеет некоторые встроенные ключевые функции. Часто полезно понимать, как файл изменялся со временем, используя, например,
git blame(ручной). Это также можно сделать непосредственно на GitHub.git grep(примеры) также чрезвычайно полезно для просмотра каждого вхождения шаблона (например, вызова функции или переменной) в кодовой базе.
Настроить
git blameчтобы игнорировать коммит, который перенёс стиль кода вblackи затемruff.git config blame.ignoreRevsFile .git-blame-ignore-revsУзнайте больше информации в black's документация по избежанию порчи git blame.