LinearRegression#
- класс sklearn.linear_model.LinearRegression(*, fit_intercept=True, copy_X=True, tol=1e-06, n_jobs=None, положительный=False)[источник]#
Линейная регрессия методом наименьших квадратов.
LinearRegression подгоняет линейную модель с коэффициентами w = (w1, …, wp) для минимизации остаточной суммы квадратов между наблюдаемыми целями в наборе данных и целями, предсказанными линейной аппроксимацией.
- Параметры:
- fit_interceptbool, по умолчанию=True
Вычислять ли свободный член для этой модели. Если установлено в False, свободный член не будет использоваться в вычислениях (т.е. данные ожидаются центрированными).
- copy_Xbool, по умолчанию=True
Если True, X будет скопирован; иначе, он может быть перезаписан.
- tolfloat, по умолчанию=1e-6
Точность решения (
coef_) определяетсяtolкоторый задаёт другой критерий сходимости дляlsqrрешатель.tolустановлен какatolиbtolofscipy.sparse.linalg.lsqrпри подгонке на разреженных обучающих данных. Этот параметр не оказывает эффекта при подгонке на плотных данных.Добавлено в версии 1.7.
- n_jobsint, default=None
Количество задач для вычислений. Это ускорит работу только в случае достаточно больших задач, то есть если во-первых
n_targets > 1и во-вторыхXявляется разреженным или еслиpositiveустановлено вTrue.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- положительныйbool, по умолчанию=False
При установке значения
True, заставляет коэффициенты быть положительными. Этот параметр поддерживается только для плотных массивов.Для сравнения линейной регрессионной модели с положительными ограничениями на коэффициенты регрессии и линейной регрессии без таких ограничений, см. Метод наименьших квадратов с неотрицательными ограничениями.
Добавлено в версии 0.24.
- Атрибуты:
- coef_массив формы (n_features,) или (n_targets, n_features)
Оцененные коэффициенты для задачи линейной регрессии. Если во время обучения передано несколько целей (y 2D), это двумерный массив формы (n_targets, n_features), а если передана только одна цель, это одномерный массив длины n_features.
- rank_int
Ранг матрицы
X. Доступно только, когдаXявляется плотной.- singular_массив формы (min(X, y),)
Сингулярные значения
X. Доступно только, когдаXявляется плотной.- intercept_float или массив формы (n_targets,)
Независимый член в линейной модели. Устанавливается в 0.0, если
fit_intercept = False.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
RidgeРидж-регрессия решает некоторые проблемы метода наименьших квадратов, накладывая штраф на размер коэффициентов с помощью l2-регуляризации.
LassoLasso — это линейная модель, которая оценивает разреженные коэффициенты с L1-регуляризацией.
ElasticNetElastic-Net — это линейная регрессионная модель, обученная с регуляризацией коэффициентов как по норме l1, так и по норме l2.
Примечания
С точки зрения реализации, это просто обычный метод наименьших квадратов (
scipy.linalg.lstsq) или неотрицательные наименьшие квадраты (scipy.optimize.nnls) обёрнутый как объект-предсказатель.Примеры
>>> import numpy as np >>> from sklearn.linear_model import LinearRegression >>> X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]]) >>> # y = 1 * x_0 + 2 * x_1 + 3 >>> y = np.dot(X, np.array([1, 2])) + 3 >>> reg = LinearRegression().fit(X, y) >>> reg.score(X, y) 1.0 >>> reg.coef_ array([1., 2.]) >>> reg.intercept_ np.float64(3.0) >>> reg.predict(np.array([[3, 5]])) array([16.])
- fit(X, y, sample_weight=None)[источник]#
Обучить линейную модель.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные.
- yмассивоподобный формы (n_samples,) или (n_samples, n_targets)
Целевые значения. Будут приведены к типу данных X при необходимости.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Индивидуальные веса для каждого образца.
Добавлено в версии 0.17: параметр sample_weight поддержка для LinearRegression.
- Возвращает:
- selfobject
Обученный оценщик.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Прогнозирование с использованием линейной модели.
- Параметры:
- Xмассивоподобный или разреженная матрица, форма (n_samples, n_features)
Образцы.
- Возвращает:
- Cмассив, формы (n_samples,)
Возвращает предсказанные значения.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearRegression[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearRegression[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
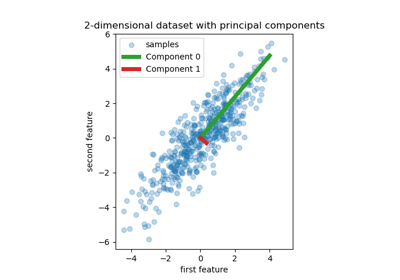
Регрессия на главных компонентах против регрессии методом частичных наименьших квадратов
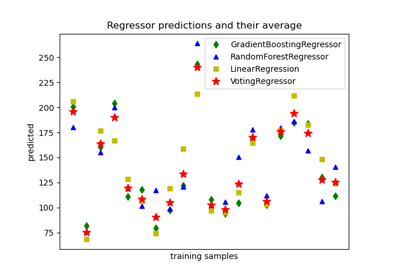
Построить индивидуальные и голосующие регрессионные предсказания
Неспособность машинного обучения выводить причинно-следственные связи
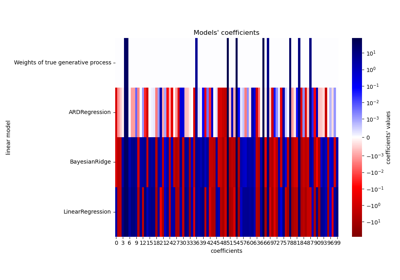
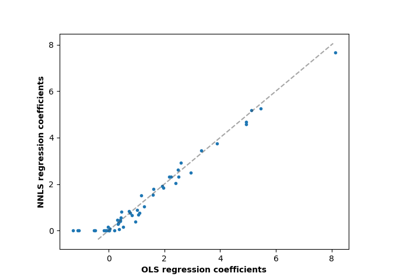
Метод наименьших квадратов с неотрицательными ограничениями
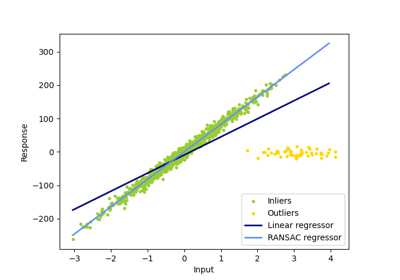
Робастная оценка линейной модели с использованием RANSAC


Завершение лица с помощью многоканальных оценщиков
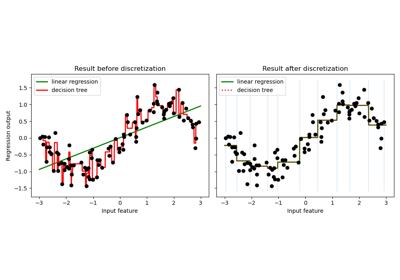
Использование KBinsDiscretizer для дискретизации непрерывных признаков