silhouette_score#
- sklearn.metrics.silhouette_score(X, метки, *, метрика='euclidean', sample_size=None, random_state=None, **kwds)[источник]#
Вычислить средний коэффициент силуэта всех образцов.
Коэффициент силуэта рассчитывается с использованием среднего внутрикластерного расстояния (
a) и среднее расстояние до ближайшего кластера (b) для каждого образца. Коэффициент силуэта для образца(b - a) / max(a, b). Для уточнения,bэто расстояние между образцом и ближайшим кластером, частью которого образец не является. Обратите внимание, что коэффициент силуэта определен только если количество меток равно2 <= n_labels <= n_samples - 1.Эта функция возвращает средний коэффициент силуэта по всем образцам. Чтобы получить значения для каждого образца, используйте
silhouette_samples.Лучшее значение — 1, а худшее — -1. Значения, близкие к 0, указывают на перекрывающиеся кластеры. Отрицательные значения обычно указывают на то, что образец был назначен неправильному кластеру, так как другой кластер более похож.
Подробнее в Руководство пользователя.
- Параметры:
- Xlength_scale_bounds
Массив попарных расстояний между образцами или массив признаков.
- меткиarray-like формы (n_samples,)
Предсказанные метки для каждого образца.
- метрикаstr или callable, по умолчанию='euclidean'
Метрика для использования при вычислении расстояния между экземплярами в массиве признаков. Если метрика является строкой, она должна быть одной из опций, разрешенных
pairwise_distances. ЕслиXявляется самим массивом расстояний, используйтеmetric="precomputed".- sample_sizeint, default=None
Размер выборки для вычисления коэффициента силуэта на случайном подмножестве данных. Если
sample_size is None, выборка не используется.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для выбора подмножества образцов. Используется, когда
sample_size is not None. Передайте int для воспроизводимых результатов при множественных вызовах функции. См. Глоссарий.- **kwdsопциональные параметры ключевых слов
Любые дополнительные параметры передаются непосредственно в функцию расстояния. При использовании метрики scipy.spatial.distance параметры все еще зависят от метрики. См. документацию scipy для примеров использования.
- Возвращает:
- силуэтfloat
Средний коэффициент силуэта для всех образцов.
Ссылки
Примеры
>>> from sklearn.datasets import make_blobs >>> from sklearn.cluster import KMeans >>> from sklearn.metrics import silhouette_score >>> X, y = make_blobs(random_state=42) >>> kmeans = KMeans(n_clusters=2, random_state=42) >>> silhouette_score(X, kmeans.fit_predict(X)) 0.49...
Примеры галереи#
Демонстрация алгоритма кластеризации с распространением аффинности
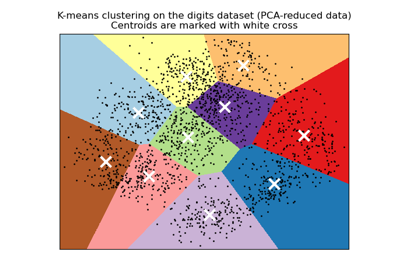
Демонстрация кластеризации K-Means на данных рукописных цифр
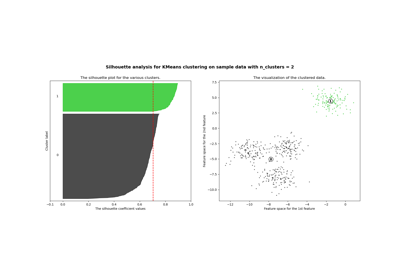
Выбор количества кластеров с помощью анализа силуэта для кластеризации KMeans
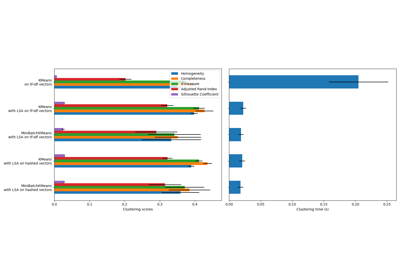
Кластеризация текстовых документов с использованием k-means