Примеры#
Это галерея примеров, демонстрирующих, как можно использовать scikit-learn. Некоторые примеры показывают использование API в целом и некоторые демонстрируют конкретные приложения в форме учебника. Также ознакомьтесь с нашими руководство пользователя для более подробных иллюстраций.
Основные изменения в выпуске#
Эти примеры иллюстрируют основные особенности выпусков scikit-learn.



Бикластеризация#
Примеры, касающиеся методов бикластеризации.
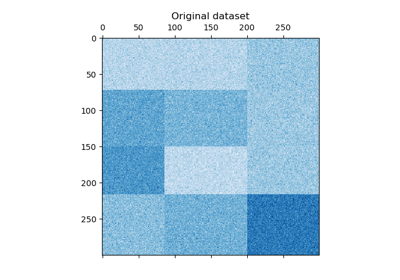
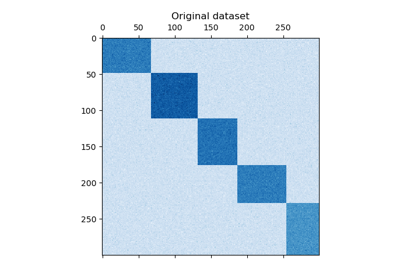
Демонстрация алгоритма спектральной совместной кластеризации

Бикластеризация документов с помощью алгоритма спектральной совместной кластеризации
Калибровка#
Примеры, иллюстрирующие калибровку предсказанных вероятностей классификаторов.
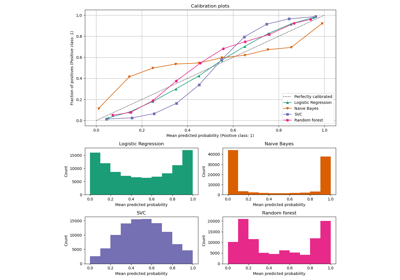
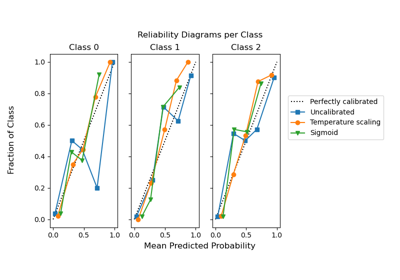
Калибровка вероятностей для классификации на 3 класса
Классификация#
Общие примеры о классификационных алгоритмах.

Линейный и квадратичный дискриминантный анализ с эллипсоидом ковариации
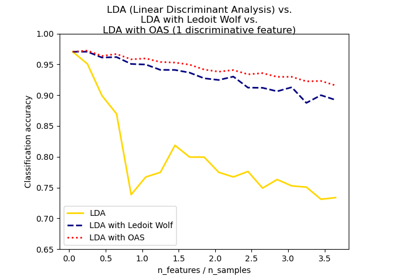
Нормальный, Ledoit-Wolf и OAS линейный дискриминантный анализ для классификации
Кластеризация#
Примеры, касающиеся sklearn.cluster модуль.
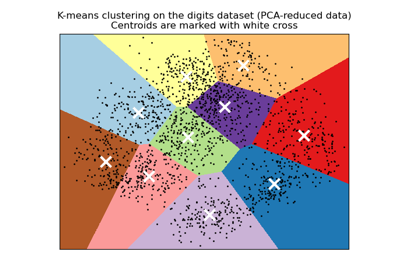
Демонстрация кластеризации K-Means на данных рукописных цифр

Демонстрация структурированной иерархической кластеризации Уорда на изображении монет
Коррекция на случайность в оценке производительности кластеризации
Сравнение производительности биссекционного K-средних и обычного K-средних
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
Сравнение различных методов иерархической связи на игрушечных наборах данных
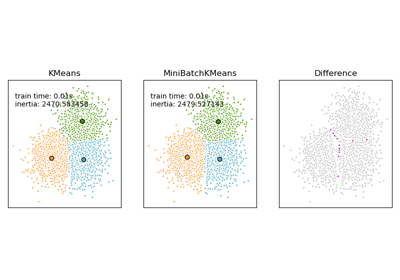
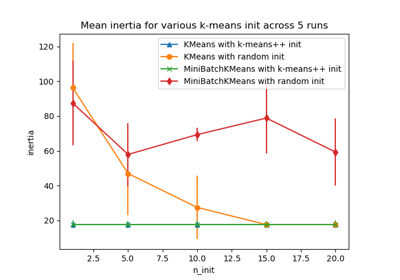
Сравнение алгоритмов кластеризации K-Means и MiniBatchKMeans
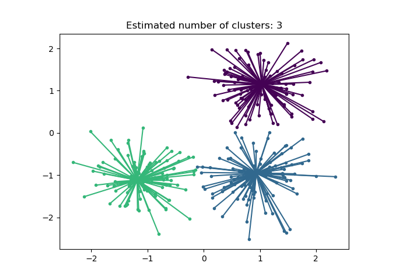
Демонстрация алгоритма кластеризации с распространением аффинности



Построить дендрограмму иерархической кластеризации

Сегментация изображения греческих монет на регионы
Выбор количества кластеров с помощью анализа силуэта для кластеризации KMeans
Спектральная кластеризация для сегментации изображений
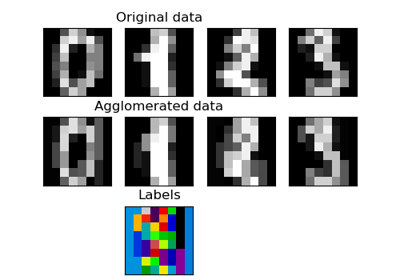
Различные агломеративные кластеризации на 2D-вложении цифр
Оценка ковариации#
Примеры, касающиеся sklearn.covariance модуль.
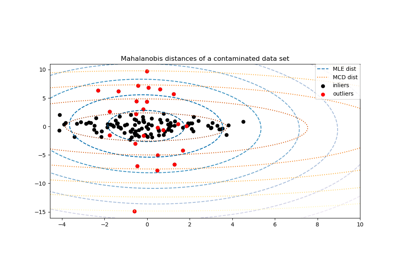
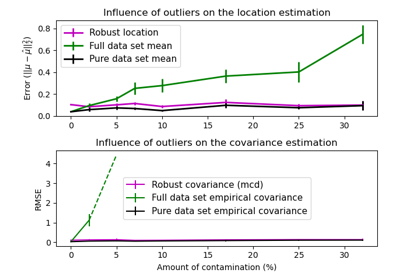
Робастная оценка ковариации и релевантность расстояний Махаланобиса
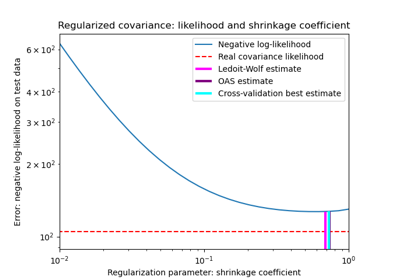
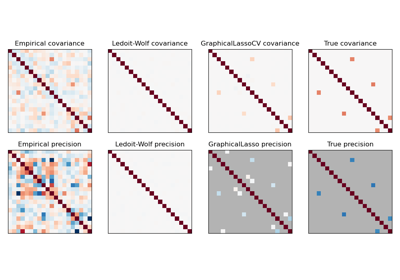
Оценка ковариации сжатием: LedoitWolf vs OAS и максимальное правдоподобие
Перекрестное разложение#
Примеры, касающиеся sklearn.cross_decomposition модуль.
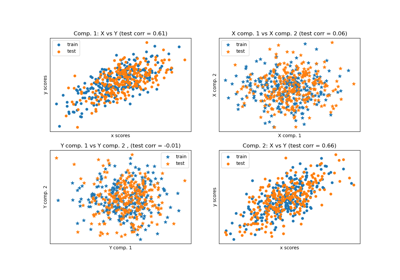
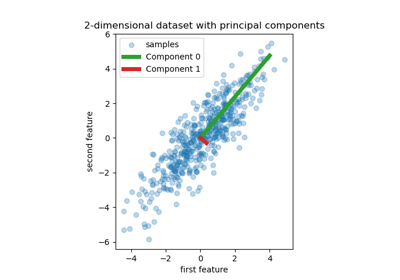
Регрессия на главных компонентах против регрессии методом частичных наименьших квадратов
Примеры наборов данных#
Примеры, касающиеся sklearn.datasets модуль.

Построение случайно сгенерированного многометочного набора данных
Деревья решений#
Примеры, касающиеся sklearn.tree модуль.
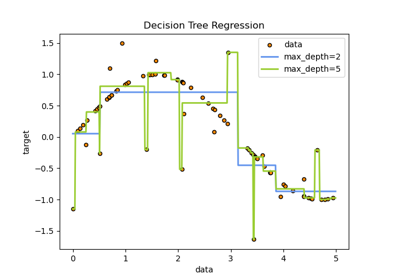
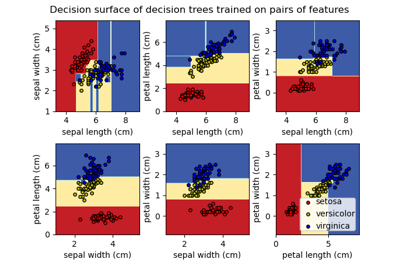
Построить поверхность решений деревьев решений, обученных на наборе данных ирисов

Пост-обрезка деревьев решений с обрезкой по стоимости сложности
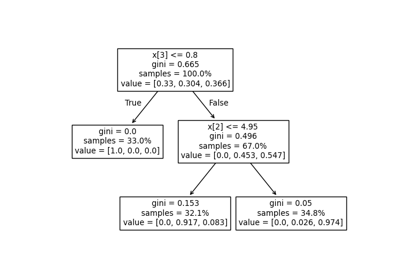
Разложение#
Примеры, касающиеся sklearn.decomposition модуль.
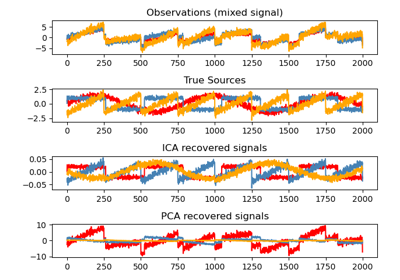
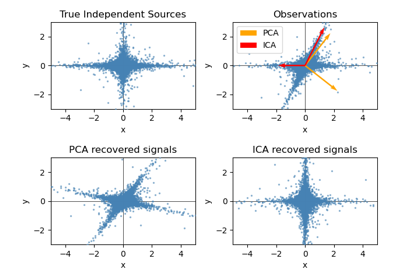
Разделение слепых источников с использованием FastICA
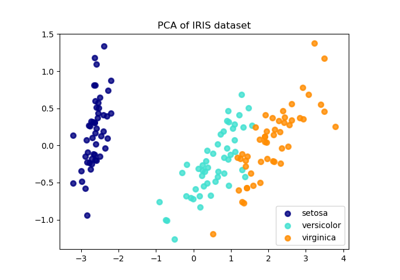
Сравнение LDA и PCA 2D проекции набора данных Iris

Факторный анализ (с вращением) для визуализации паттернов

Удаление шума изображений с использованием обучения словаря

Выбор модели с вероятностным PCA и факторным анализом (FA)
Анализ главных компонент (PCA) на наборе данных Iris
Разреженное кодирование с предвычисленным словарём
Разработка оценщиков#
Примеры, касающиеся разработки пользовательского оценщика.

Ансамблевые методы#
Примеры, касающиеся sklearn.ensemble модуль.
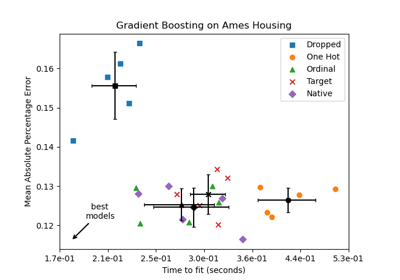
Поддержка категориальных признаков в градиентном бустинге


Сравнение моделей случайных лесов и градиентного бустинга на гистограммах

Сравнение случайных лесов и мета-оценщика с множественным выходом
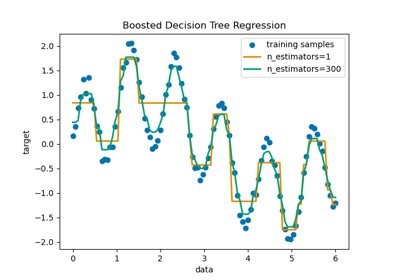
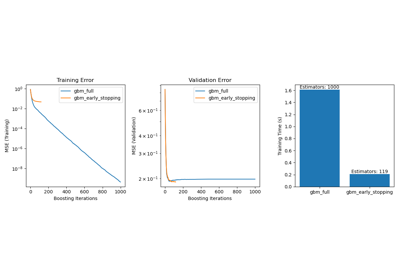
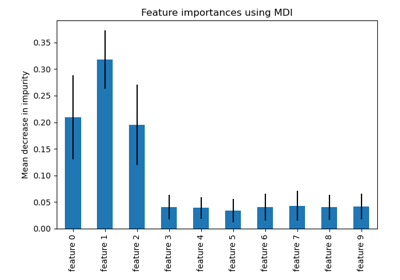
Признаки в деревьях с градиентным бустингом на гистограммах



Преобразование признаков с хешированием с использованием полностью случайных деревьев
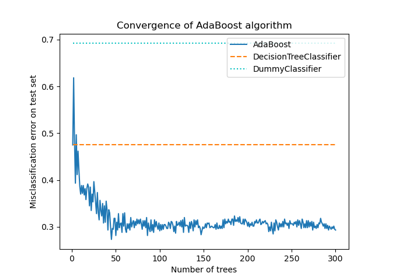
Многоклассовые деревья решений с бустингом AdaBoost
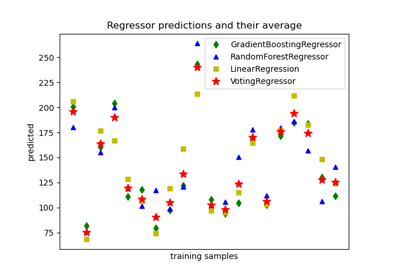
Построить индивидуальные и голосующие регрессионные предсказания

Построить поверхности решений ансамблей деревьев на наборе данных ирисов

Интервалы прогнозирования для регрессии градиентного бустинга
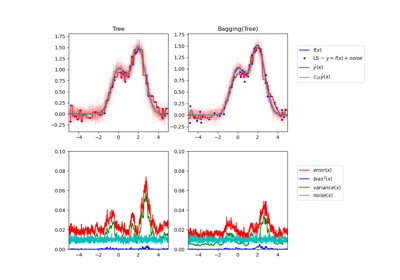
Один оценщик против бэггинга: декомпозиция смещения-дисперсии
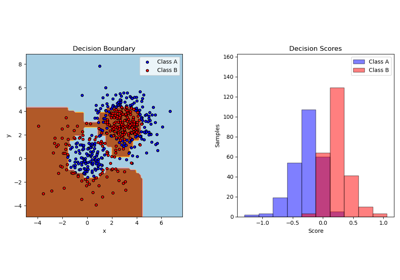
Визуализация вероятностных предсказаний VotingClassifier
Примеры на основе реальных наборов данных#
Применение к реальным задачам с некоторыми наборами данных среднего размера или интерактивным пользовательским интерфейсом.

Компрессионное зондирование: реконструкция томографии с априорным распределением L1 (Lasso)
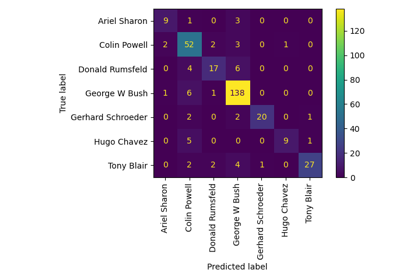
Пример распознавания лиц с использованием собственных лиц и SVM

Удаление шума с изображения с использованием ядерного PCA
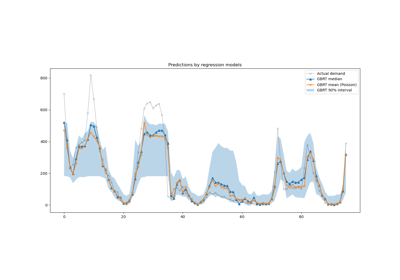
Лаггированные признаки для прогнозирования временных рядов

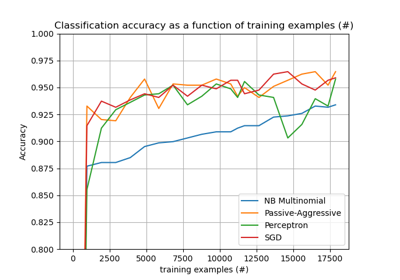
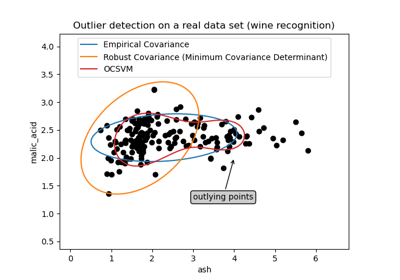
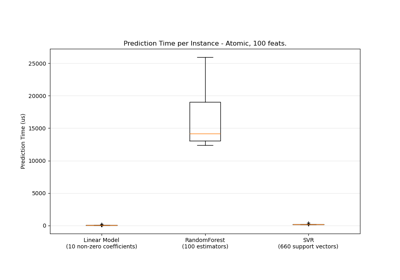
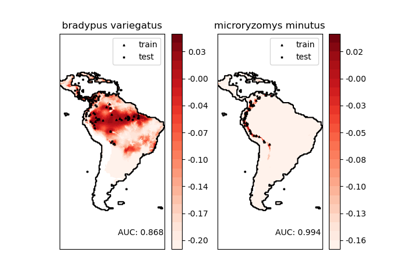

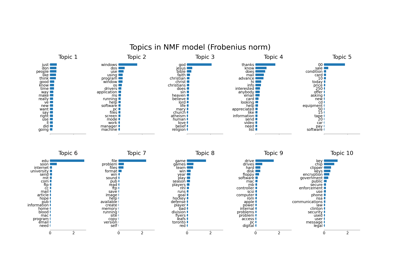
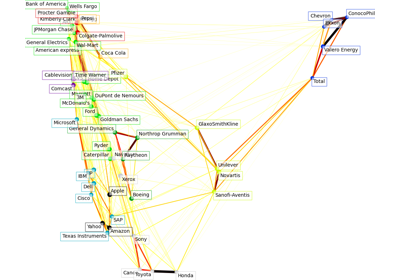

Выбор признаков#
Примеры, касающиеся sklearn.feature_selection модуль.
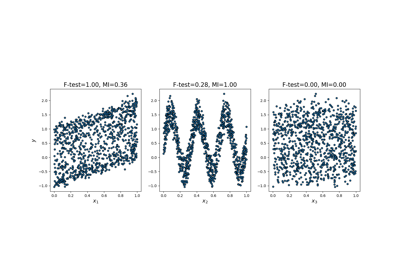
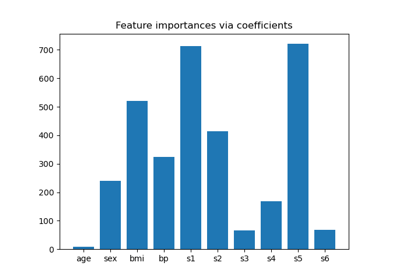
Основанный на модели и последовательный отбор признаков

Рекурсивное исключение признаков с перекрестной проверкой
Замороженные оценщики#
Примеры, касающиеся sklearn.frozen модуль.

Гауссовские смеси моделей#
Примеры, касающиеся sklearn.mixture модуль.
Анализ вариации байесовской гауссовой смеси с априорным типом концентрации
Гауссовский процесс для машинного обучения#
Примеры, касающиеся sklearn.gaussian_process модуль.
Способность гауссовского процесса регрессии (GPR) оценивать уровень шума данных
Сравнение ядерной гребневой регрессии и регрессии по методу Гауссовских процессов
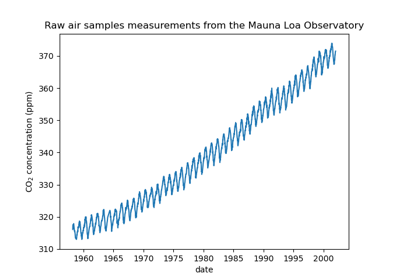
Прогнозирование уровня CO2 на наборе данных Mona Loa с использованием гауссовской регрессии (GPR)
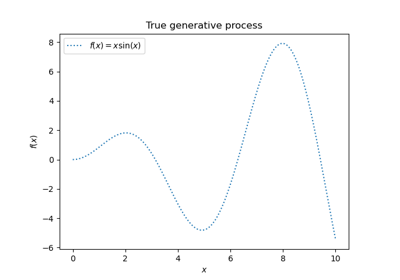
Регрессия гауссовских процессов: базовый вводный пример
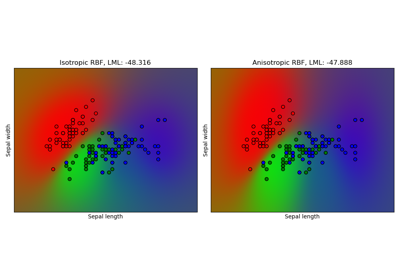
Гауссовский процесс классификации (GPC) на наборе данных iris
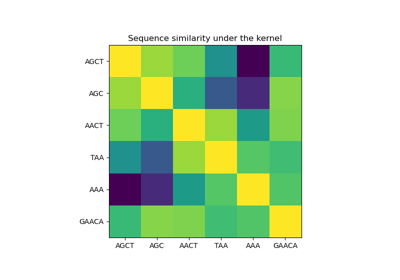
Гауссовские процессы на дискретных структурах данных
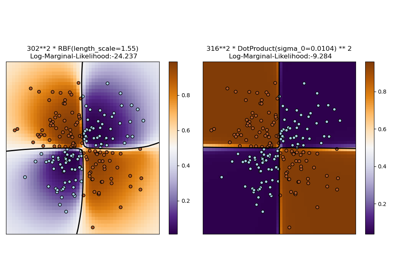
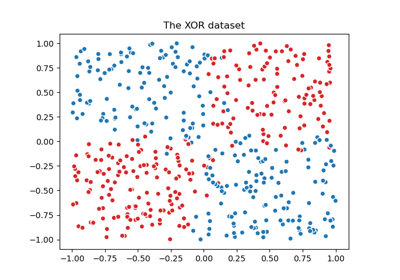
Иллюстрация классификации гауссовским процессом (GPC) на наборе данных XOR
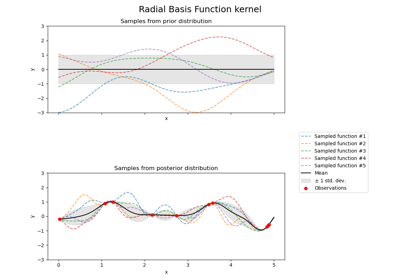
Иллюстрация априорного и апостериорного гауссовских процессов для различных ядер
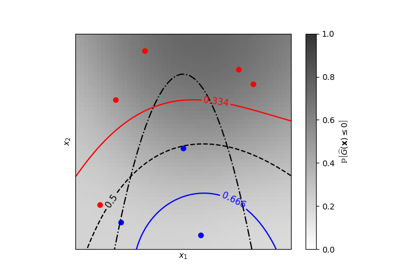
Изолинии равной вероятности для классификации гауссовских процессов (GPC)
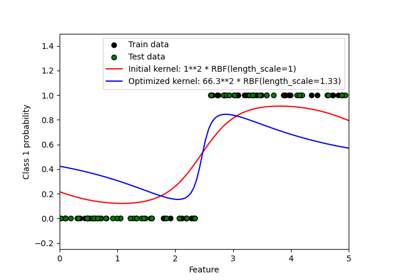
Вероятностные предсказания с гауссовским процессом классификации (GPC)
Обобщенные линейные модели#
Примеры, касающиеся sklearn.linear_model модуль.
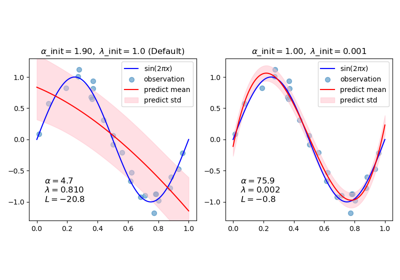
Аппроксимация кривой с использованием байесовской гребневой регрессии
Границы решений мультиномиальной и логистической регрессии One-vs-Rest
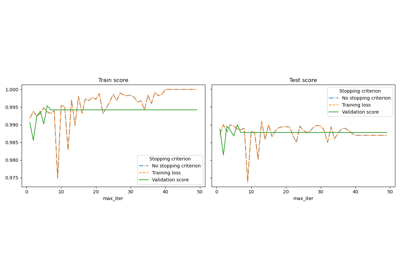
Ранняя остановка стохастического градиентного спуска

Обучение Elastic Net с предвычисленной матрицей Грама и взвешенными выборками
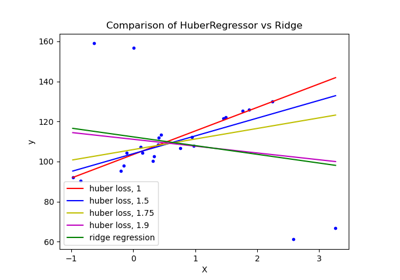
HuberRegressor против Ridge на наборе данных с сильными выбросами

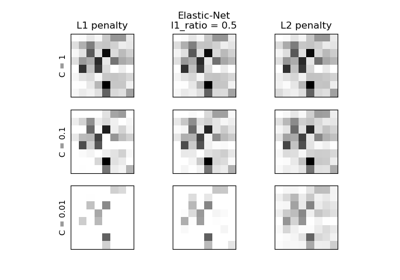
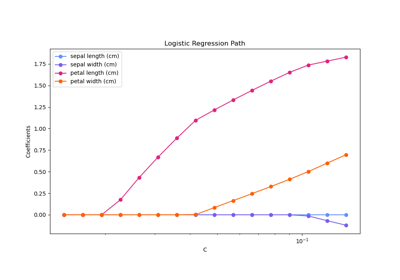
L1-штраф и разреженность в логистической регрессии
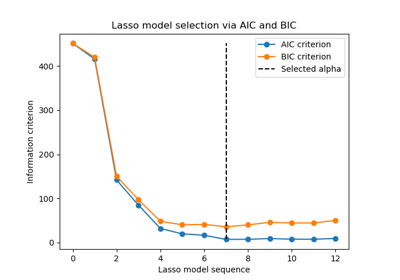
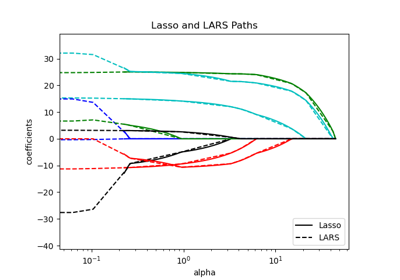
Выбор модели Lasso с помощью информационных критериев
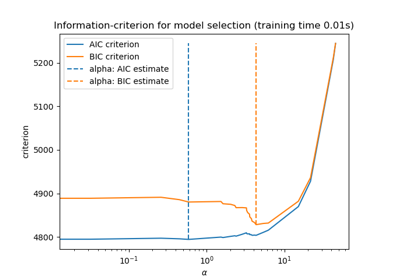
Выбор модели Lasso: AIC-BIC / перекрёстная проверка

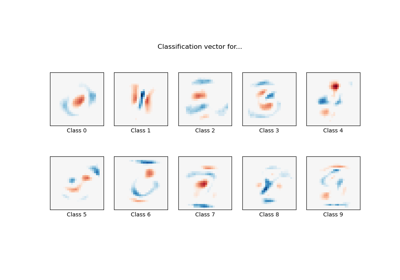
Классификация MNIST с использованием мультиномиальной логистической регрессии + L1
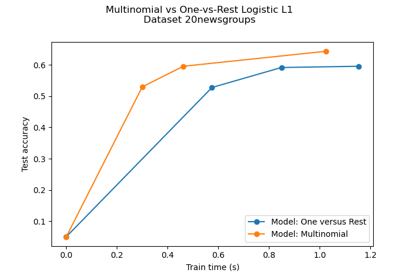
Многоклассовая разреженная логистическая регрессия на 20newsgroups
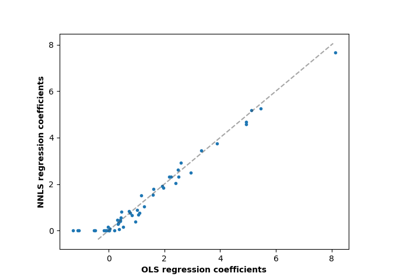
Метод наименьших квадратов с неотрицательными ограничениями
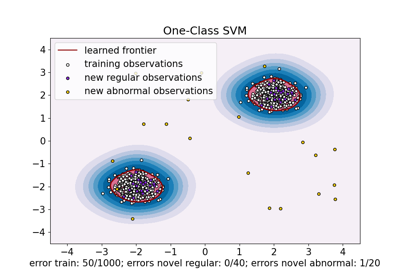
One-Class SVM против One-Class SVM с использованием стохастического градиентного спуска
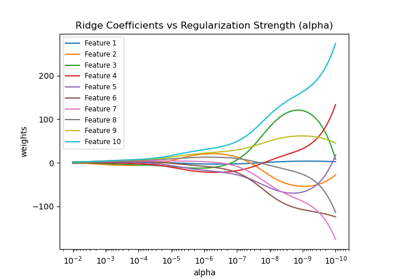
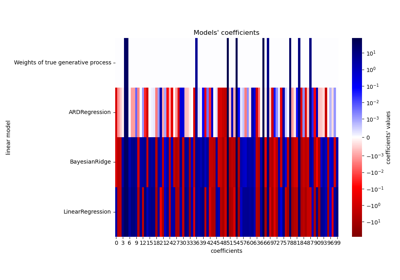
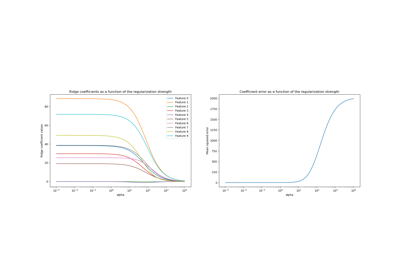
Построение коэффициентов Ridge как функции регуляризации
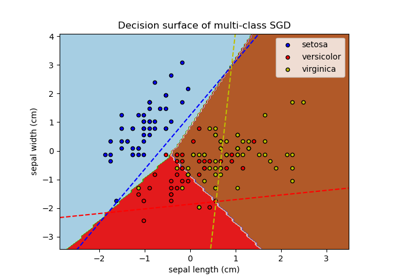
Построение многоклассового SGD на наборе данных iris
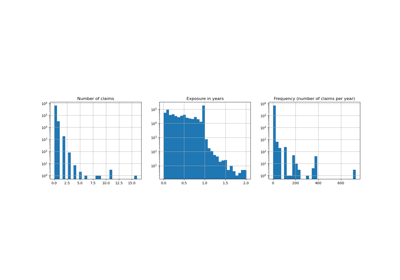
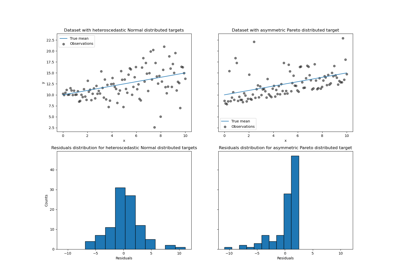
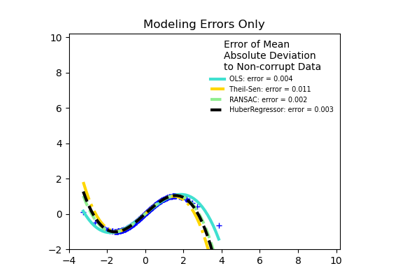
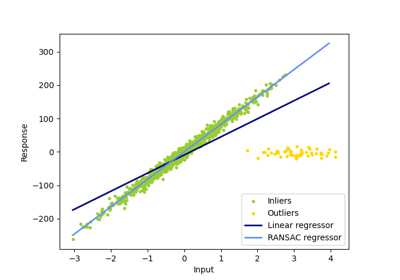
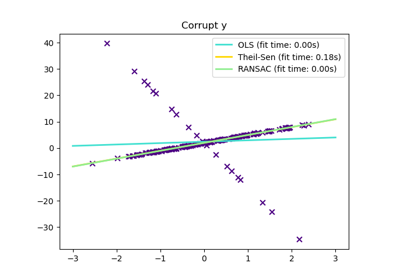
Робастная оценка линейной модели с использованием RANSAC

SGD: Гиперплоскость максимального разделяющего запаса
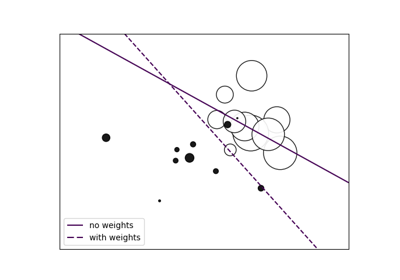
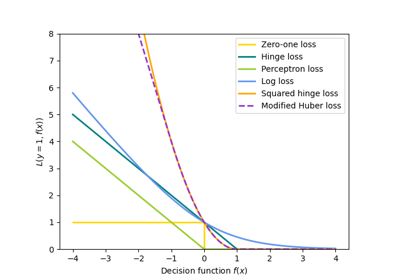
Инспекция#
Примеры, связанные с sklearn.inspection модуль.

Распространённые ошибки в интерпретации коэффициентов линейных моделей
Неспособность машинного обучения выводить причинно-следственные связи
Графики частичной зависимости и индивидуального условного ожидания
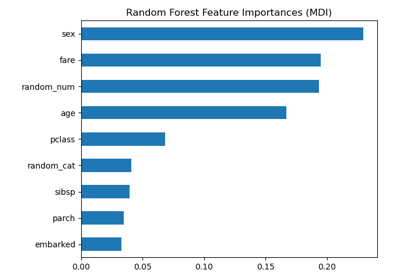
Важность перестановок против важности признаков случайного леса (MDI)
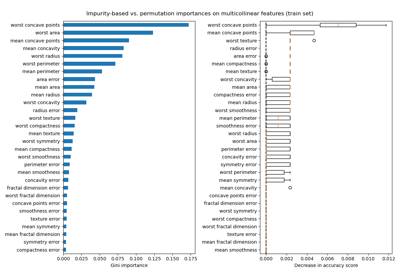
Важность перестановок с мультиколлинеарными или коррелированными признаками
Аппроксимация ядра#
Примеры, касающиеся sklearn.kernel_approximation модуль.

Масштабируемое обучение с полиномиальной аппроксимацией ядра
Обучение многообразию#
Примеры, касающиеся sklearn.manifold модуль.
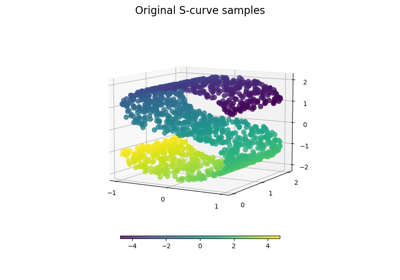
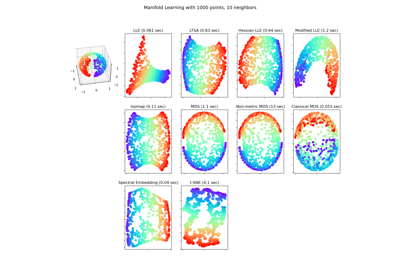

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…
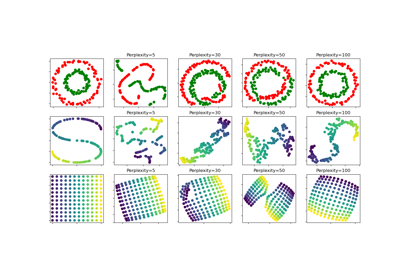
t-SNE: Влияние различных значений perplexity на форму
Разное#
Различные и вводные примеры для scikit-learn.

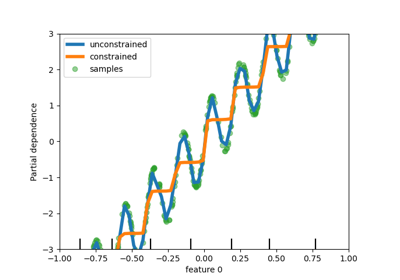
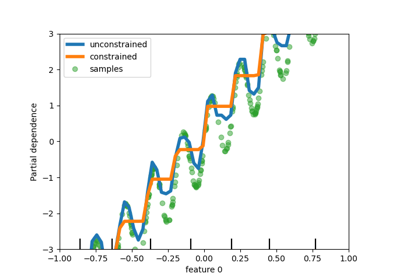
Расширенное построение графиков с частичной зависимостью
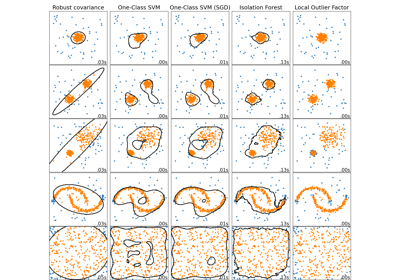
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных



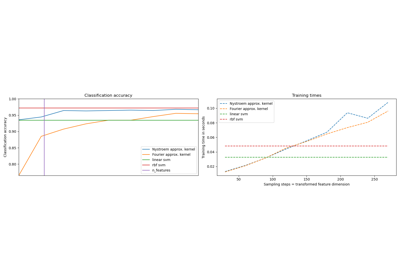
Аппроксимация явного отображения признаков для RBF-ядер

Завершение лица с помощью многоканальных оценщиков


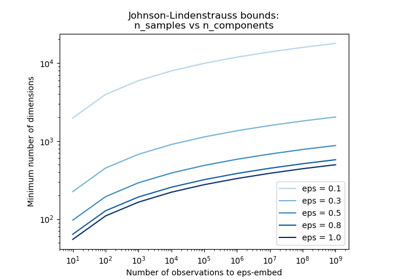
Граница Джонсона-Линденштрауса для вложения с помощью случайных проекций

Импутация пропущенных значений#
Примеры, касающиеся sklearn.impute модуль.
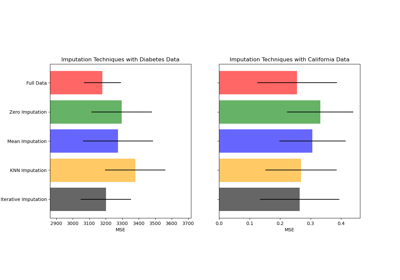
Заполнение пропущенных значений перед построением оценщика
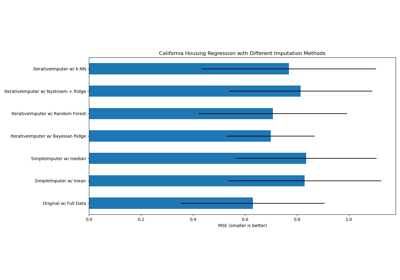
Заполнение пропущенных значений с вариантами IterativeImputer
Выбор модели#
Примеры, связанные с sklearn.model_selection модуль.
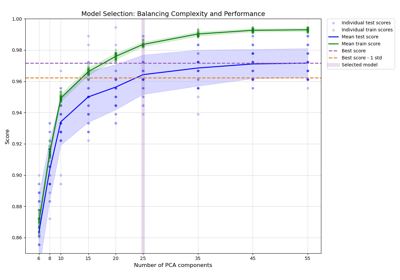
Баланс сложности модели и кросс-валидационной оценки

Сравнение рандомизированного поиска и поиска по сетке для оценки гиперпараметров
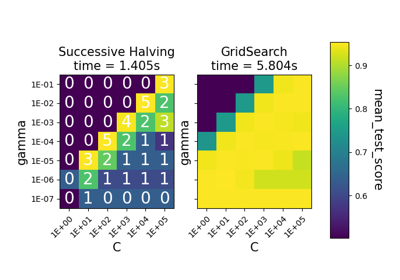
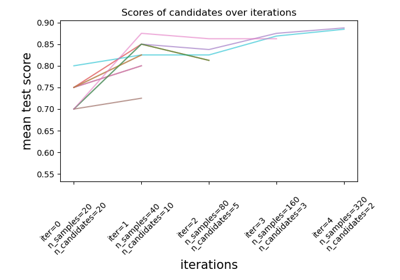
Сравнение между поиском по сетке и последовательным сокращением вдвое

Пользовательская стратегия повторного обучения для поиска по сетке с кросс-валидацией
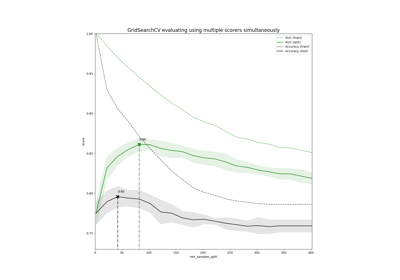
Демонстрация многометрической оценки на cross_val_score и GridSearchCV

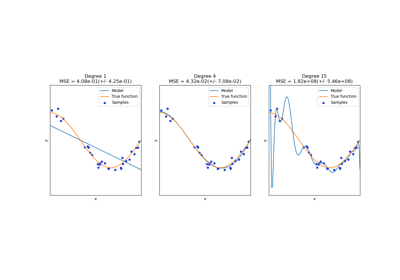
Влияние регуляризации модели на ошибку обучения и тестирования
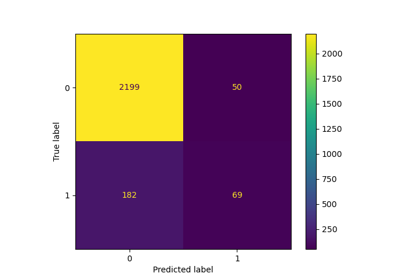
Оценить производительность классификатора с помощью матрицы ошибок
Многоклассовая рабочая характеристика приемника (ROC)

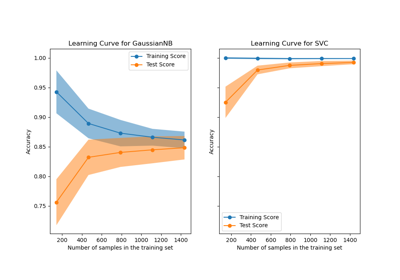
Построение кривых обучения и проверка масштабируемости моделей
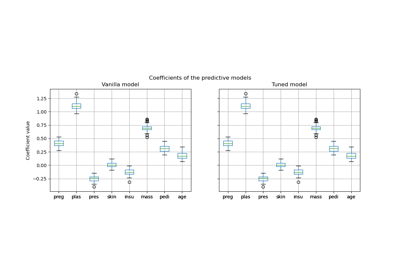
Пост-фактумная настройка точки отсечения функции принятия решений
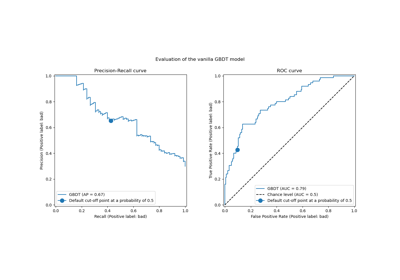
Последующая настройка порога принятия решений для обучения с учетом стоимости
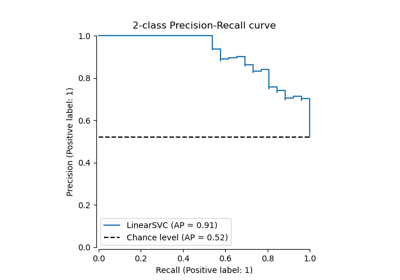
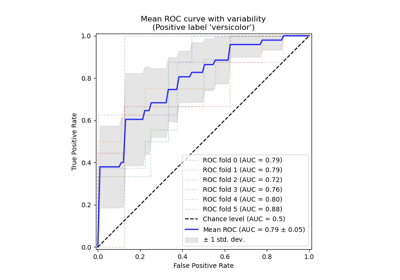
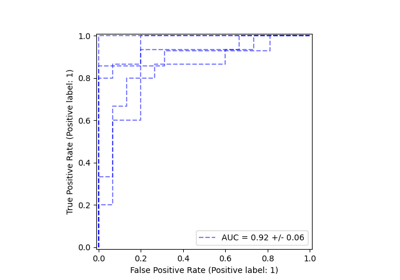
Рабочая характеристика приёмника (ROC) с перекрёстной проверкой

Примерный пайплайн для извлечения и оценки текстовых признаков
Статистическое сравнение моделей с использованием поиска по сетке

Тест с перестановками для значимости оценки классификации
Визуализация поведения кросс-валидации в scikit-learn
Многоклассовые методы#
Примеры, касающиеся sklearn.multiclass модуль.
Многовариантные методы#
Примеры, касающиеся sklearn.multioutput модуль.
Многометочная классификация с использованием цепочки классификаторов
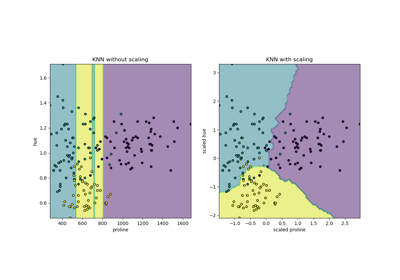
Ближайшие соседи#
Примеры, касающиеся sklearn.neighbors модуль.

Сравнение ближайших соседей с анализом компонент соседства и без него
Снижение размерности с помощью анализа компонентов соседства


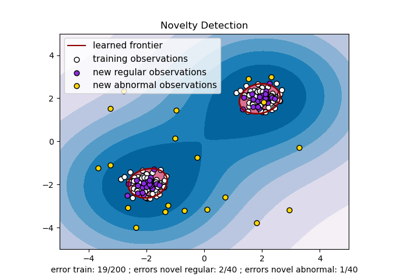
Обнаружение новизны с помощью локального фактора выбросов (LOF)
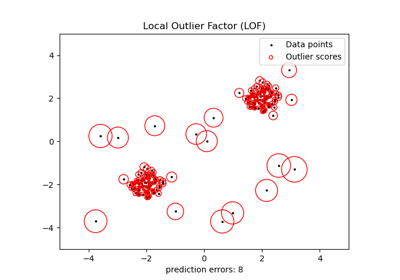
Обнаружение выбросов с помощью фактора локальных выбросов (LOF)
Нейронные сети#
Примеры, касающиеся sklearn.neural_network модуль.
Сравнение стохастических стратегий обучения для MLPClassifier

Признаки ограниченной машины Больцмана для классификации цифр
Изменение регуляризации в многослойном перцептроне

Конвейеры и составные оценщики#
Примеры того, как составлять трансформеры и пайплайны из других оценщиков. Смотрите Руководство пользователя.
Трансформер столбцов с разнородными источниками данных

Объединение нескольких методов извлечения признаков
Эффект преобразования целей в регрессионной модели
Конвейеризация: объединение PCA и логистической регрессии
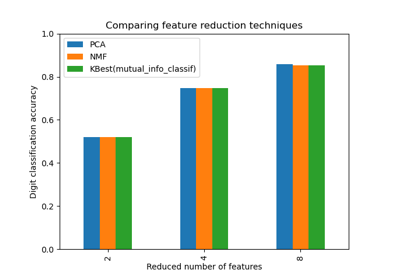
Выбор уменьшения размерности с помощью Pipeline и GridSearchCV
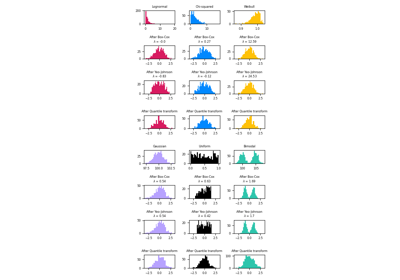
Предобработка#
Примеры, касающиеся sklearn.preprocessing модуль.
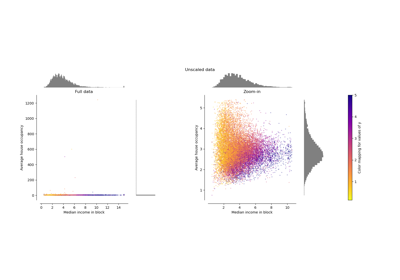
Сравнение влияния различных масштабировщиков на данные с выбросами
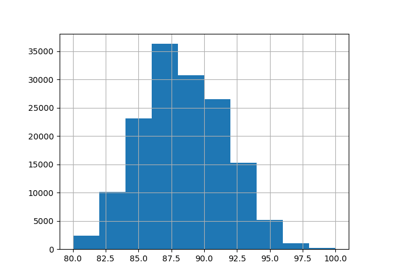
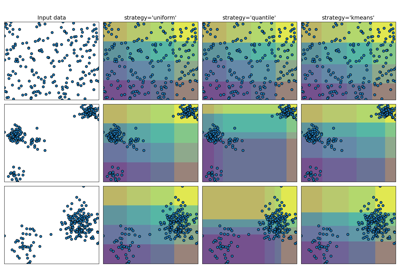
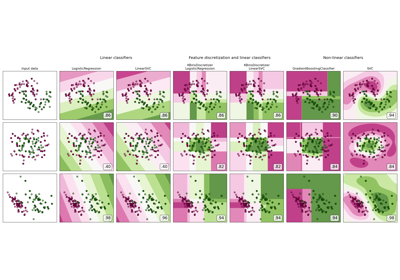
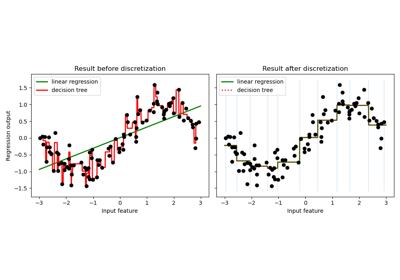
Использование KBinsDiscretizer для дискретизации непрерывных признаков
Полуавтоматическая классификация#
Примеры, касающиеся sklearn.semi_supervised модуль.
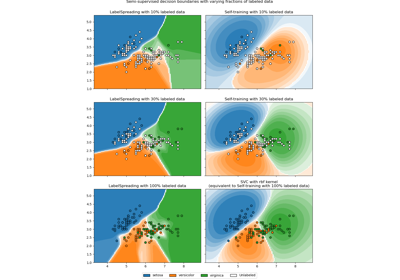
Граница решения полуконтролируемых классификаторов против SVM на наборе данных Iris
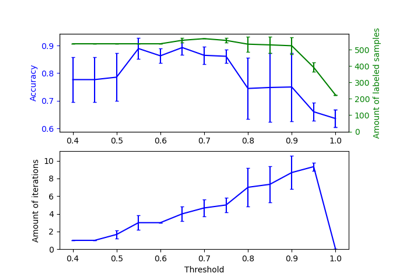
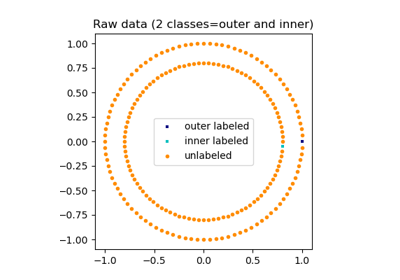
Распространение меток по кругам: Обучение сложной структуре

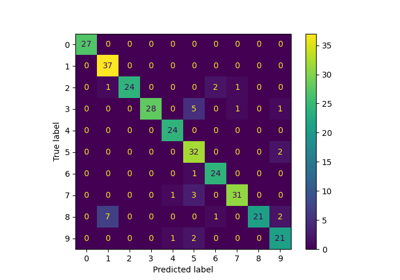
Распространение меток на цифрах: Демонстрация производительности
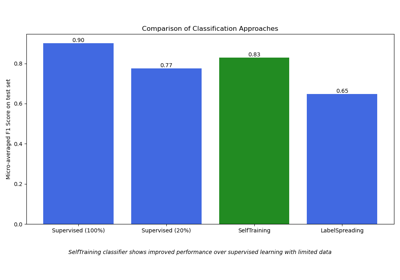
Полу-контролируемая классификация на текстовом наборе данных
Метод опорных векторов#
Примеры, касающиеся sklearn.svm модуль.
Построение границ классификации с различными ядрами SVM
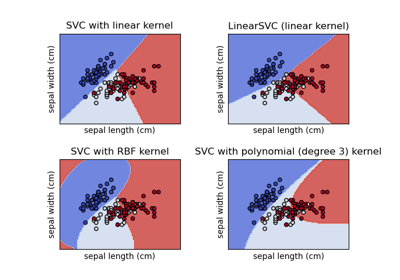
Построение различных классификаторов SVM на наборе данных iris
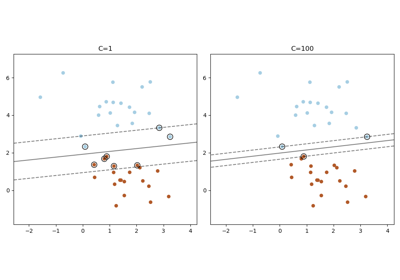
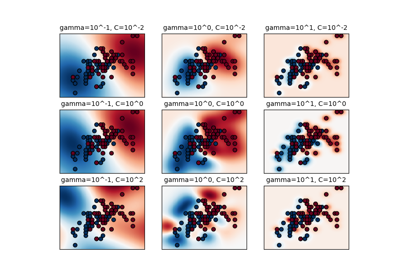
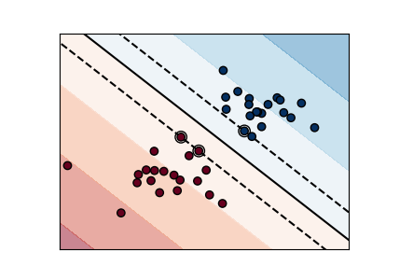
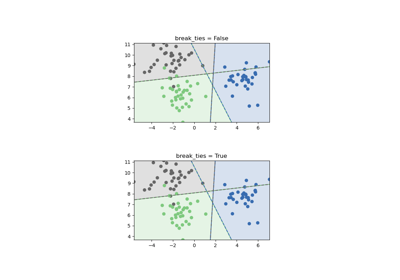
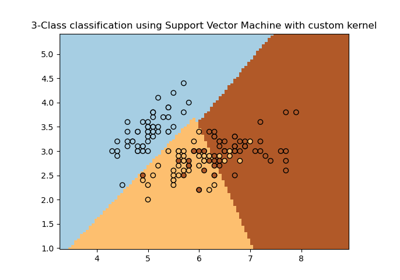
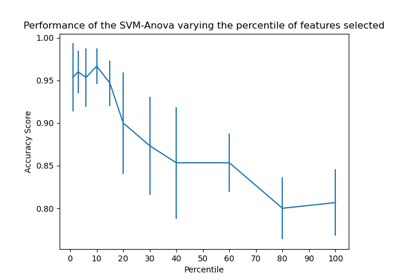
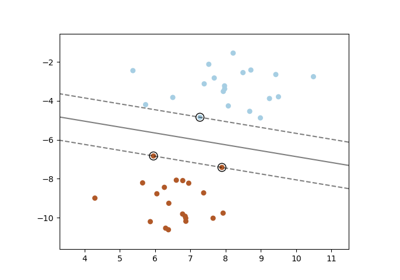
SVM: Разделяющая гиперплоскость с максимальным зазором

SVM: Разделяющая гиперплоскость для несбалансированных классов
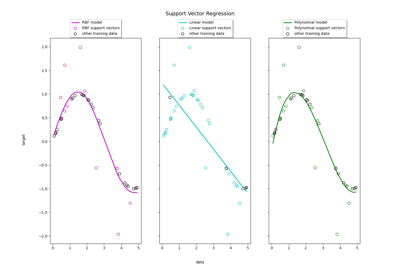
Регрессия на основе метода опорных векторов (SVR) с использованием линейных и нелинейных ядер
Работа с текстовыми документами#
Примеры, касающиеся sklearn.feature_extraction.text модуль.

Классификация текстовых документов с использованием разреженных признаков
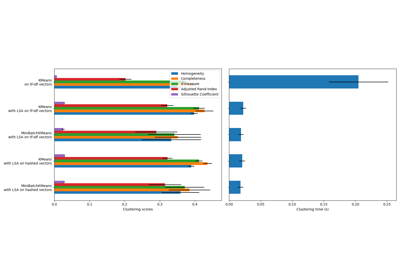
Кластеризация текстовых документов с использованием k-means
