fit#
-
scipy.stats.fit(dist, данные, bounds=None, *, guess=None, method='mle', optimizer=
Подгонка дискретного или непрерывного распределения к данным
Для заданного распределения, данных и границ параметров распределения верните оценки максимального правдоподобия параметров.
- Параметры:
- dist
scipy.stats.rv_continuousилиscipy.stats.rv_discrete Объект, представляющий распределение, которое нужно подогнать к данным.
- данные1D array_like
Данные, к которым распределение должно быть подогнано. Если данные содержат любой из
np.nan,np.inf, или -np.inf, метод fit вызоветValueError.- границыdict или последовательность кортежей, опционально
Если словарь, каждый ключ — это имя параметра распределения, а соответствующее значение — кортеж, содержащий нижнюю и верхнюю границы для этого параметра. Если распределение определено только для конечного диапазона значений этого параметра, запись для этого параметра не требуется; например, некоторые распределения имеют параметры, которые должны находиться в интервале [0, 1]. Границы для параметров location (
loc) и масштаб (scale) являются опциональными; по умолчанию они фиксированы как 0 и 1 соответственно.Если последовательность, элемент i является кортежем, содержащим нижнюю и верхнюю границы для iпараметр th распределения. В этом случае, границы для все параметры формы распределения должны быть предоставлены. Опционально, границы для местоположения и масштаба могут следовать за параметрами формы распределения.
Если форма должна оставаться фиксированной (например, если она известна), нижняя и верхняя границы могут быть равны. Если предоставленная пользователем нижняя или верхняя граница выходит за пределы области определения распределения, граница области определения распределения заменит предоставленное пользователем значение. Аналогично, параметры, которые должны быть целочисленными, будут ограничены целочисленными значениями в пределах предоставленных пользователем границ.
- предположениеdict или array_like, опционально
Если словарь, каждый ключ — это имя параметра распределения, а соответствующее значение — предположение о значении параметра.
Если последовательность, элемент i является предположением для ith параметр распределения. В этом случае предположения для все параметры формы распределения должны быть предоставлены.
Если предположение не предоставлен, предположения для переменных решения не будут переданы оптимизатору. Если предположение если предоставлено, предположения для любых отсутствующих параметров будут установлены на среднее значение нижней и верхней границ. Предположения для параметров, которые должны быть целочисленными, будут округлены до целых значений, а предположения, лежащие вне пересечения предоставленных пользователем границ и области определения распределения, будут обрезаны.
- метод{‘mle’, ‘mse’}
С
method="mle"(по умолчанию), подгонка вычисляется путём минимизации функции отрицательного логарифма правдоподобия. Большое конечное штрафное значение (вместо бесконечного отрицательного логарифма правдоподобия) применяется для наблюдений за пределами области определения распределения. Приmethod="mse", подгонка вычисляется путем минимизации функции отрицательного логарифма произведения интервалов. Такое же штрафное значение применяется для наблюдений за пределами области определения. Мы следуем подходу [1], который обобщен для выборок с повторяющимися наблюдениями.- оптимизаторвызываемый объект, необязательный
оптимизатор является вызываемым объектом, который принимает следующий позиционный аргумент.
- funcallable
Целевая функция для оптимизации. fun принимает один аргумент
x, кандидаты параметров формы распределения, и возвращает значение целевой функции, заданноеx, dist, и предоставленный данные. Задача оптимизатор заключается в нахождении значений переменных решения, которые минимизируют fun.
оптимизатор также должен принимать следующий именованный аргумент.
- границыпоследовательность кортежей
Границы значений переменных решения; каждый элемент будет представлять собой кортеж, содержащий нижнюю и верхнюю границу для переменной решения.
Если предположение предоставлен, оптимизатор также должен принимать следующий ключевой аргумент.
- x0array_like
Начальные приближения для каждой переменной решения.
Если распределение имеет какие-либо параметры формы, которые должны быть целочисленными, или если распределение дискретное и параметр местоположения не фиксирован, оптимизатор также должен принимать следующий именованный аргумент.
- integralityarray_like булевых значений
Для каждой переменной решения: True, если переменная решения должна быть ограничена целочисленными значениями, и False, если переменная решения является непрерывной.
оптимизатор должен возвращать объект, например, экземпляр
scipy.optimize.OptimizeResult, который хранит оптимальные значения переменных решения в атрибутеx. Если атрибутыfun,status, илиmessageпредоставлены, они будут включены в объект результата, возвращаемыйfit.
- dist
- Возвращает:
- результат
FitResult Объект со следующими полями.
- paramsnamedtuple
Именованный кортеж, содержащий оценки максимального правдоподобия параметров формы, местоположения и (если применимо) масштаба распределения.
- successbool или None
Считал ли оптимизатор оптимизацию успешно завершённой или нет.
- messagestr или None
Любое сообщение о статусе, предоставленное оптимизатором.
Объект имеет следующий метод:
- nllf(params=None, data=None)
По умолчанию, функция отрицательного логарифма правдоподобия при подогнанных params для заданного данные. Принимает кортеж, содержащий альтернативные формы, местоположение и масштаб распределения и массив альтернативных данных.
- plot(ax=None)
Накладывает PDF/PMF подобранного распределения на нормализованную гистограмму данных.
- результат
Смотрите также
Примечания
Оптимизация с большей вероятностью сойдётся к оценке максимального правдоподобия, когда пользователь предоставляет узкие границы, содержащие оценку максимального правдоподобия. Например, при подгонке биномиального распределения к данным количество экспериментов, лежащих в основе каждого образца, может быть известно, и в этом случае соответствующий параметр формы
nможет быть исправлена.Ссылки
[1]Shao, Yongzhao, and Marjorie G. Hahn. “Maximum product of spacings method: a unified formulation with illustration of strong consistency.” Illinois Journal of Mathematics 43.3 (1999): 489-499.
Примеры
Предположим, мы хотим подогнать распределение к следующим данным.
>>> import numpy as np >>> from scipy import stats >>> rng = np.random.default_rng() >>> dist = stats.nbinom >>> shapes = (5, 0.5) >>> data = dist.rvs(*shapes, size=1000, random_state=rng)
Предположим, мы не знаем, как были сгенерированы данные, но подозреваем, что они следуют отрицательному биномиальному распределению с параметрами n и p. (См.
scipy.stats.nbinom.) Мы считаем, что параметр n было меньше 30, и мы знаем, что параметр p должен лежать на интервале [0, 1]. Мы записываем эту информацию в переменную границы и передать эту информацию вfit.>>> bounds = [(0, 30), (0, 1)] >>> res = stats.fit(dist, data, bounds)
fitосуществляет поиск в пределах, указанных пользователем границы для значений, которые наилучшим образом соответствуют данным (в смысле оценки максимального правдоподобия). В этом случае были найдены значения формы, похожие на те, из которых данные были фактически сгенерированы.>>> res.params FitParams(n=5.0, p=0.5028157644634368, loc=0.0) # may vary
Мы можем визуализировать результаты, наложив функцию вероятности распределения (с формами, подобранными к данным) на нормализованную гистограмму данных.
>>> import matplotlib.pyplot as plt # matplotlib must be installed to plot >>> res.plot() >>> plt.show()
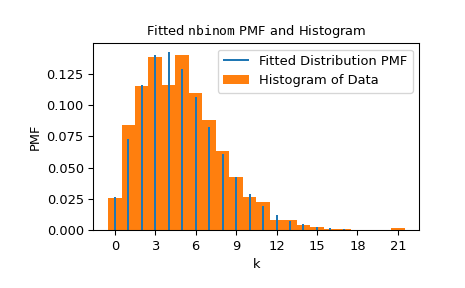
Обратите внимание, что оценка для n был точно целочисленным; это потому, что область определения
nbinomPMF включает только целочисленные nдолжны быть включены в старые категории. Значения, которые были в удаленных категориях, будут установлены в NaNnbinomобъект «знает», что.nbinomтакже знает, что форма p должно быть значением между 0 и 1. В таком случае - когда область определения распределения относительно параметра конечна - нам не требуется указывать границы для параметра.>>> bounds = {'n': (0, 30)} # omit parameter p using a `dict` >>> res2 = stats.fit(dist, data, bounds) >>> res2.params FitParams(n=5.0, p=0.5016492009232932, loc=0.0) # may vary
Если мы хотим заставить распределение быть подобранным с n зафиксировано на 6, мы можем установить как нижнюю, так и верхнюю границы для n до 6. Однако обратите внимание, что значение оптимизируемой целевой функции обычно хуже (выше) в этом случае.
>>> bounds = {'n': (6, 6)} # fix parameter `n` >>> res3 = stats.fit(dist, data, bounds) >>> res3.params FitParams(n=6.0, p=0.5486556076755706, loc=0.0) # may vary >>> res3.nllf() > res.nllf() True # may vary
Обратите внимание, что численные результаты предыдущих примеров типичны, но они могут варьироваться, поскольку используемый по умолчанию оптимизатор в
fit,scipy.optimize.differential_evolution, является стохастическим. Однако мы можем настроить параметры, используемые оптимизатором, чтобы обеспечить воспроизводимость - или даже использовать другой оптимизатор - с помощью оптимизатор параметр.>>> from scipy.optimize import differential_evolution >>> rng = np.random.default_rng() >>> def optimizer(fun, bounds, *, integrality): ... return differential_evolution(fun, bounds, strategy='best2bin', ... rng=rng, integrality=integrality) >>> bounds = [(0, 30), (0, 1)] >>> res4 = stats.fit(dist, data, bounds, optimizer=optimizer) >>> res4.params FitParams(n=5.0, p=0.5015183149259951, loc=0.0)