numpy.percentile#
- numpy.процентиль(a, q, ось=None, выход=None, overwrite_input=False, метод='linear', keepdims=False, *, веса=None)[источник]#
Вычисляет q-й процентиль данных вдоль указанной оси.
Возвращает q-й процентиль(и) элементов массива.
- Параметры:
- aarray_like из действительных чисел
Входной массив или объект, который может быть преобразован в массив.
- qarray_like из float
Процент или последовательность процентов для вычисляемых перцентилей. Значения должны быть между 0 и 100 включительно.
- ось{int, tuple of int, None}, optional
Ось или оси, вдоль которых вычисляются процентили. По умолчанию вычисляется процентиль(и) вдоль сжатой версии массива.
- выходndarray, необязательно
Альтернативный выходной массив для размещения результата. Он должен иметь ту же форму и длину буфера, что и ожидаемый вывод, но тип (вывода) будет приведён при необходимости.
- overwrite_inputbool, необязательно
Если True, то разрешить входной массив a для модификации промежуточными вычислениями, чтобы сэкономить память. В этом случае содержимое входного a после завершения этой функции не определено.
- методstr, optional
Этот параметр определяет метод для оценки процентиля. Существует много различных методов, некоторые уникальны для NumPy. См. примечания для объяснения. Опции отсортированы по их типу R, как обобщено в статье H&F [1] являются:
‘inverted_cdf’
'averaged_inverted_cdf'
‘closest_observation’
'interpolated_inverted_cdf'
'hazen'
'weibull'
'linear' (по умолчанию)
‘median_unbiased’
'normal_unbiased'
Первые три метода являются разрывными. NumPy дополнительно определяет следующие разрывные вариации опции по умолчанию 'linear' (7.):
'lower'
'higher',
'midpoint'
‘nearest’
Изменено в версии 1.22.0: Этот аргумент ранее назывался "interpolation" и предлагал только "linear" по умолчанию и последние четыре опции.
- keepdimsbool, необязательно
Если установлено значение True, оси, которые были сокращены, остаются в результате как измерения с размером один. С этой опцией результат будет корректно транслироваться на исходный массив a.
- весаarray_like, необязательный
Массив весов, связанных со значениями в a. Каждое значение в a вносит вклад в процентиль в соответствии с его связанным весом. Массив весов может быть либо 1-D (в этом случае его длина должна быть равна размеру a вдоль заданной оси) или той же формы, что и a. Если weights=None, тогда все данные в a предполагаются имеющими вес, равный единице. Только method="inverted_cdf" поддерживает веса. См. примечания для получения дополнительных сведений.
Новое в версии 2.0.0.
- Возвращает:
- процентильскаляр или ndarray
Если q является одним процентилем и axis=None, тогда результат является скаляром. Если задано несколько процентилей, первая ось результата соответствует процентилям. Остальные оси — это оси, которые остаются после сокращения a. Если входные данные содержат целые числа или числа с плавающей точкой меньше
float64, выходной тип данных —float64. В противном случае тип выходных данных совпадает с типом входных данных. Если выход указан, возвращается этот массив.
Смотрите также
meanmedianэквивалентно
percentile(..., 50)nanpercentilequantileэквивалентно процентилю, за исключением q в диапазоне [0, 1].
Примечания
Поведение
numpy.percentileс процентным соотношением q являетсяnumpy.quantileс аргументомq/100. Для получения дополнительной информации см.numpy.quantile.Ссылки
[1]R. J. Hyndman и Y. Fan, «Выборочные квантили в статистических пакетах», The American Statistician, 50(4), стр. 361-365, 1996
Примеры
>>> import numpy as np >>> a = np.array([[10, 7, 4], [3, 2, 1]]) >>> a array([[10, 7, 4], [ 3, 2, 1]]) >>> np.percentile(a, 50) 3.5 >>> np.percentile(a, 50, axis=0) array([6.5, 4.5, 2.5]) >>> np.percentile(a, 50, axis=1) array([7., 2.]) >>> np.percentile(a, 50, axis=1, keepdims=True) array([[7.], [2.]])
>>> m = np.percentile(a, 50, axis=0) >>> out = np.zeros_like(m) >>> np.percentile(a, 50, axis=0, out=out) array([6.5, 4.5, 2.5]) >>> m array([6.5, 4.5, 2.5])
>>> b = a.copy() >>> np.percentile(b, 50, axis=1, overwrite_input=True) array([7., 2.]) >>> assert not np.all(a == b)
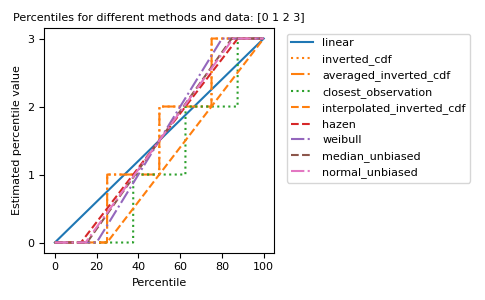
Различные методы можно визуализировать графически:
import matplotlib.pyplot as plt a = np.arange(4) p = np.linspace(0, 100, 6001) ax = plt.gca() lines = [ ('linear', '-', 'C0'), ('inverted_cdf', ':', 'C1'), # Almost the same as `inverted_cdf`: ('averaged_inverted_cdf', '-.', 'C1'), ('closest_observation', ':', 'C2'), ('interpolated_inverted_cdf', '--', 'C1'), ('hazen', '--', 'C3'), ('weibull', '-.', 'C4'), ('median_unbiased', '--', 'C5'), ('normal_unbiased', '-.', 'C6'), ] for method, style, color in lines: ax.plot( p, np.percentile(a, p, method=method), label=method, linestyle=style, color=color) ax.set( title='Percentiles for different methods and data: ' + str(a), xlabel='Percentile', ylabel='Estimated percentile value', yticks=a) ax.legend(bbox_to_anchor=(1.03, 1)) plt.tight_layout() plt.show()