Визуализация таблиц#
Этот раздел демонстрирует визуализацию табличных данных с использованием Styler класс. Для получения информации о визуализации с помощью построения графиков см. Визуализация диаграмм. Этот документ написан в виде Jupyter Notebook и может быть просмотрен или загружен здесь.
Объект Styler и настройка отображения#
Стилизация и настройка отображения вывода должны выполняться после данные в DataFrame были обработаны. Styler - это не динамически обновляется, если в DataFrame вносятся дальнейшие изменения. DataFrame.style атрибут является свойством, возвращающим Styler объект. Он имеет _repr_html_ метод, определенный на нем, поэтому он автоматически отображается в Jupyter Notebook.
Styler, который можно использовать для больших данных, но в основном предназначен для малых данных, в настоящее время имеет возможность вывода в эти форматы:
HTML
LaTeX
Строка (и CSV по расширению)
Excel
(JSON в настоящее время недоступен)
Первые три из них имеют методы настройки отображения, предназначенные для форматирования и кастомизации вывода. К ним относятся:
Форматирование значений, индекса и заголовков столбцов с использованием .format() и .format_index(),
Переименование меток индекса или заголовков столбцов с использованием .relabel_index()
Скрытие определенных столбцов, индекса и/или заголовков столбцов, или имен индекса с использованием .hide()
Объединение похожих DataFrame с использованием .concat()
Форматирование отображения#
Форматирование значений#
The Styler различает отображение значение из фактический значение, как в данных, так и в заголовках индекса или столбцов. Чтобы управлять отображаемым значением, текст печатается в каждой ячейке как строка, и мы можем использовать .format() и .format_index() методы для манипулирования этим в соответствии с спецификатор формата строка или вызываемый объект, который принимает одно значение и возвращает строку. Это можно определить для всей таблицы, индекса, отдельных столбцов или уровней MultiIndex. Также можно перезаписать имена индексов.
Кроме того, функция format имеет точность аргумент для специального форматирования чисел с плавающей точкой, а также десятичный и тысячи разделители для поддержки других локалей, na_rep аргумент для отображения отсутствующих данных, и escape и гиперссылки аргументы для помощи в отображении безопасного HTML или безопасного LaTeX. Форматер по умолчанию настроен на использование глобальных настроек pandas, таких как styler.format.precision опция, управляемая с помощью with pd.option_context('format.precision', 2):
[2]:
import pandas as pd
import numpy as np
import matplotlib as mpl
df = pd.DataFrame({
"strings": ["Adam", "Mike"],
"ints": [1, 3],
"floats": [1.123, 1000.23]
})
df.style \
.format(precision=3, thousands=".", decimal=",") \
.format_index(str.upper, axis=1) \
.relabel_index(["row 1", "row 2"], axis=0)
[2]:
| СТРОКИ | INTS | FLOATS | |
|---|---|---|---|
| строка 1 | Адам | 1 | 1,123 |
| строка 2 | Mike | 3 | 1.000,230 |
Использование Styler для управления отображением — полезная функция, поскольку сохранение индексации и значений данных для других целей дает больший контроль. Вам не нужно перезаписывать ваш DataFrame, чтобы отобразить его так, как вам нравится. Вот более полный пример использования функций форматирования, при этом все еще полагаясь на базовые данные для индексации и вычислений.
[3]:
weather_df = pd.DataFrame(np.random.rand(10,2)*5,
index=pd.date_range(start="2021-01-01", periods=10),
columns=["Tokyo", "Beijing"])
def rain_condition(v):
if v < 1.75:
return "Dry"
elif v < 2.75:
return "Rain"
return "Heavy Rain"
def make_pretty(styler):
styler.set_caption("Weather Conditions")
styler.format(rain_condition)
styler.format_index(lambda v: v.strftime("%A"))
styler.background_gradient(axis=None, vmin=1, vmax=5, cmap="YlGnBu")
return styler
weather_df
[3]:
| Токио | Пекин | |
|---|---|---|
| 2021-01-01 | 2.539319 | 2.400233 |
| 2021-01-02 | 4.242790 | 2.364118 |
| 2021-01-03 | 2.970093 | 3.007211 |
| 2021-01-04 | 3.355701 | 0.735296 |
| 2021-01-05 | 3.265934 | 1.929888 |
| 2021-01-06 | 2.212551 | 3.449755 |
| 2021-01-07 | 2.223986 | 0.409007 |
| 2021-01-08 | 4.457208 | 1.331950 |
| 2021-01-09 | 4.577346 | 1.380128 |
| 2021-01-10 | 3.641450 | 4.648679 |
[4]:
weather_df.loc["2021-01-04":"2021-01-08"].style.pipe(make_pretty)
[4]:
| Токио | Пекин | |
|---|---|---|
| Понедельник | Сильный дождь | Сухой |
| Вторник | Сильный дождь | Дождь |
| Среда | Дождь | Сильный дождь |
| Четверг | Дождь | Сухой |
| Пятница | Сильный дождь | Сухой |
Скрытие данных#
Индекс и заголовки столбцов могут быть полностью скрыты, а также можно выбрать строки или столбцы, которые нужно исключить. Обе эти опции выполняются с использованием одних и тех же методов.
Индекс может быть скрыт от отображения вызовом .hide() без аргументов, что может быть полезно, если ваш индекс основан на целых числах. Аналогично заголовки столбцов можно скрыть, вызвав .hide(axis="columns") без дополнительных аргументов.
Определенные строки или столбцы могут быть скрыты от отображения путем вызова того же .hide() метод и передача метки строки/столбца, списка или среза меток строк/столбцов для subset аргумент.
Скрытие не меняет целочисленное расположение CSS классов, например, скрытие первых двух столбцов DataFrame означает, что индексация классов столбцов все равно начнется с col2, поскольку col0 и col1 просто игнорируются.
[5]:
df = pd.DataFrame(np.random.randn(5, 5))
df.style \
.hide(subset=[0, 2, 4], axis=0) \
.hide(subset=[0, 2, 4], axis=1)
[5]:
| 1 | 3 | |
|---|---|---|
| 1 | 1.625023 | -1.169797 |
| 3 | -0.004225 | 0.371344 |
Чтобы инвертировать функцию в показать Для функциональности рекомендуется составлять список скрытых элементов.
[6]:
show = [0, 2, 4]
df.style \
.hide([row for row in df.index if row not in show], axis=0) \
.hide([col for col in df.columns if col not in show], axis=1)
[6]:
| 0 | 2 | 4 | |
|---|---|---|---|
| 0 | -0.087432 | -0.334898 | -0.783397 |
| 2 | -0.195797 | 0.872204 | -1.548522 |
| 4 | -0.197600 | -0.201867 | -1.044594 |
Объединение выходных данных DataFrame#
Два или более Styler могут быть объединены вместе при условии, что они используют одни и те же столбцы. Это очень полезно для отображения сводной статистики DataFrame и часто используется в сочетании с DataFrame.agg.
Поскольку объединяемые объекты являются Stylers, они могут независимо стилизоваться, как будет показано ниже, и их объединение сохраняет эти стили.
[7]:
summary_styler = df.agg(["sum", "mean"]).style \
.format(precision=3) \
.relabel_index(["Sum", "Average"])
df.style.format(precision=1).concat(summary_styler)
[7]:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | -0.1 | -0.8 | -0.3 | -2.1 | -0.8 |
| 1 | -1.5 | 1.6 | -0.5 | -1.2 | 0.6 |
| 2 | -0.2 | -1.2 | 0.9 | 0.6 | -1.5 |
| 3 | 1.3 | -0.0 | -1.2 | 0.4 | 0.5 |
| 4 | -0.2 | -0.1 | -0.2 | 1.3 | -1.0 |
| Сумма | -0.712 | -0.498 | -1.399 | -1.086 | -2.258 |
| Среднее | -0.142 | -0.100 | -0.280 | -0.217 | -0.452 |
Объект Styler и HTML#
The Styler изначально был создан для поддержки широкого спектра опций форматирования HTML. Его HTML-вывод создает HTML Ниже мы демонстрируем вывод по умолчанию, который выглядит очень похоже на стандартное HTML-представление DataFrame. Но HTML здесь уже присоединил некоторые CSS-классы к каждой ячейке, даже если мы ещё не создали никаких стилей. Мы можем просмотреть их, вызвав .to_html() метод, который возвращает необработанный HTML в виде строки, что полезно для дальнейшей обработки или добавления в файл - подробнее в Подробнее о CSS и
HTML. В этом разделе также будет представлено пошаговое руководство по преобразованию этого вывода по умолчанию для представления вывода DataFrame, который является более информативным. Например, как мы можем построить Первый шаг, который мы предприняли, — создание объекта Styler из DataFrame и затем выбор интересующего диапазона путем скрытия нежелательных столбцов с помощью .hide(). Существуют 3 основных метода добавления пользовательских стилей CSS to Styler: Используя .set_table_styles() для управления более широкими областями таблицы с указанным внутренним CSS. Хотя стили таблиц позволяют гибко добавлять селекторы и свойства CSS, управляющие всеми отдельными частями таблицы, они громоздки для спецификаций отдельных ячеек. Также обратите внимание, что стили таблиц нельзя экспортировать в Excel. Используя .set_td_classes() для прямой привязки либо внешних CSS-классов к вашим ячейкам данных, либо внутренних CSS-классов, созданных .set_table_styles(). См. здесь. Их нельзя использовать в строках заголовков столбцов или индексах, и они также не экспортируются в Excel. Используя .apply() и .map() функции для добавления прямого внутреннего CSS к конкретным ячейкам данных. См. здесь. Начиная с v1.4.0 также есть методы, работающие непосредственно со строками заголовков столбцов или индексами; .apply_index() и
.map_index(). Обратите внимание, что только эти методы добавляют стили, которые будут экспортироваться в Excel. Эти методы работают аналогично DataFrame.apply() и DataFrame.map(). Стили таблиц достаточно гибки, чтобы управлять всеми отдельными частями таблицы, включая заголовки столбцов и индексы. Однако они могут быть громоздкими для ввода для отдельных ячеек данных или любого условного форматирования, поэтому мы рекомендуем использовать стили таблиц для широкого стилирования, например, для целых строк или столбцов за раз. Стили таблиц также используются для управления функциями, которые могут применяться ко всей таблице сразу, например, для создания общей функции наведения. Чтобы воспроизвести обычный формат CSS-селекторов и свойств (пар атрибут-значение), например, необходимый формат для передачи стилей в .set_table_styles() представлен в виде списка словарей, каждый с CSS-селектором тега и CSS-свойствами. Свойства могут быть либо списком из 2-кортежей, либо обычной CSS-строкой, например: Далее мы просто добавляем еще несколько стилевых артефактов, нацеленных на определенные части таблицы. Будьте осторожны здесь, поскольку мы цепочка методов нам нужно явно указать методу не В качестве удобного метода (начиная с версии 1.2.0) мы также можем передать dict to .set_table_styles() который содержит ключи строк или столбцов. За кулисами Styler просто индексирует ключи и добавляет соответствующие Если вы разработали веб-сайт, то, вероятно, у вас уже есть внешний CSS-файл, который управляет стилизацией таблиц и ячеек. Возможно, вы захотите использовать эти нативные файлы вместо дублирования всего CSS в python (и дублирования любой работы по обслуживанию). Очень легко добавить Новое в версии 1.2.0 The .set_td_classes() метод принимает DataFrame с соответствующими индексами и столбцами к базовому Styler’s DataFrame. Этот DataFrame будет содержать строки как css-классы для добавления к отдельным ячейкам данных: Мы используем следующие методы для передачи ваших функций стиля. Оба этих метода принимают функцию (и некоторые другие ключевые аргументы) и применяют её к DataFrame определённым образом, отображая CSS-стили. .map() (поэлементно): принимает функцию, которая принимает одно значение и возвращает строку с парой атрибут-значение CSS. .apply() (по столбцам/строкам/таблице): принимает функцию, которая получает Series или DataFrame и возвращает Series, DataFrame или массив numpy с идентичной формой, где каждый элемент является строкой с парой атрибут-значение CSS. Этот метод передает каждый столбец или строку вашего DataFrame по одному или всю таблицу сразу, в зависимости от Этот метод эффективен для применения множественной сложной логики к ячейкам данных. Мы создаем новый DataFrame для демонстрации этого. Например, мы можем создать функцию, которая окрашивает текст, если он отрицательный, и связать ее с функцией, которая частично затемняет ячейки с незначительными значениями. Поскольку это рассматривает каждый элемент по очереди, мы используем Мы также можем создать функцию, которая выделяет максимальное значение по строкам, столбцам и DataFrame одновременно. В этом случае мы используем Мы можем использовать одну и ту же функцию для разных осей, выделяя здесь максимум DataFrame фиолетовым, а максимумы строк — розовым. Этот последний пример показывает, как некоторые стили были перезаписаны другими. В целом активен самый последний примененный стиль, но вы можете прочитать больше в раздел об иерархиях CSS. Вы также можете применять эти стили к более детальным частям DataFrame - подробнее в разделе срез подмножества. Можно воспроизвести часть этого функционала, используя только классы, но это может быть более громоздко. См. пункт 3) Оптимизации Совет по отладке: Если у вас возникают трудности с написанием функции стиля, попробуйте просто передать её в Похожее применение достигается для заголовков с использованием: .map_index() (поэлементно): принимает функцию, которая принимает одно значение и возвращает строку с парой атрибут-значение CSS. .apply_index() (по уровням): принимает функцию, которая принимает Series и возвращает Series или массив numpy с идентичной формой, где каждый элемент является строкой с парой атрибут-значение CSS. Этот метод передает каждый уровень вашего индекса по одному. Чтобы стилизовать индекс, используйте Вы можете выбрать Заголовки таблиц можно добавлять с помощью .set_caption() метод. Вы можете использовать стили таблиц для управления CSS, относящимся к заголовку. Добавление всплывающих подсказок (начиная с версии 1.3.0) можно выполнить с помощью .set_tooltips() метод так же, как вы можете добавить CSS-классы к ячейкам данных, предоставив строковый DataFrame с пересекающимися индексами и столбцами. Вам не нужно указывать Единственное, что осталось сделать для нашей таблицы, — это добавить выделяющие границы, чтобы привлечь внимание аудитории к всплывающим подсказкам. Мы создадим внутренние CSS-классы, как и раньше, используя стили таблиц. Установка классов всегда перезаписывает поэтому нам нужно убедиться, что мы добавляем предыдущие классы. Примеры, которые мы показали до сих пор для Значение, переданное в Скалярное значение обрабатывается как метка столбца Список (или Series, или массив NumPy) рассматривается как несколько меток столбцов Кортеж обрабатывается как Рассмотрите использование Мы будем использовать subset для выделения максимума в третьем и четвертом столбцах красным текстом. Мы выделим область среза subset желтым цветом. Если объединить с Это также обеспечивает гибкость выбора строк при использовании с Также есть возможность предоставить условная фильтрация. Предположим, мы хотим выделить максимум по столбцам 2 и 4 только в случае, если сумма столбцов 1 и 3 меньше -2.0 (по сути исключая строки В настоящее время поддерживается только срез по меткам, не по позициям и не вызываемые объекты. Если ваша функция стиля использует Обычно для небольших таблиц и большинства случаев отображаемый HTML не нуждается в оптимизации, и мы не рекомендуем это делать. Есть два случая, когда стоит рассмотреть: Если вы отображаете и стилизуете очень большую HTML-таблицу, некоторые браузеры имеют проблемы с производительностью. Если вы используете Здесь мы рекомендуем следующие шаги для реализации: Игнорировать Это не оптимально: Это лучше: Используйте стили таблиц, где это возможно (например, для всех ячеек, строк или столбцов одновременно), так как CSS почти всегда эффективнее других форматов. Это не оптимально: Это лучше: Для больших DataFrame, где один и тот же стиль применяется ко многим ячейкам, может быть более эффективно объявить стили как классы, а затем применять эти классы к ячейкам данных, а не напрямую применять стили к ячейкам. Однако, вероятно, всё ещё проще использовать API функции Styler, когда оптимизация не является приоритетом. Это не оптимально: Это лучше: Всплывающие подсказки требуют Вы можете удалить ненужный HTML или сократить стандартные имена классов, заменив стандартный словарь css. Вы можете прочитать немного больше о CSS ниже. Некоторые функции стилизации настолько распространены, что мы "встроили" их в .highlight_null: для использования при идентификации пропущенных данных. .highlight_min и .highlight_max: для использования при определении крайних значений в данных. .highlight_between и .highlight_quantile: для использования при идентификации классов в данных. .background_gradient: гибкий метод для выделения ячеек на основе их или других значений по числовой шкале. .text_gradient: аналогичный метод для выделения текста на основе их или других значений в числовой шкале. .bar: для отображения мини-графиков на фоне ячеек. Индивидуальная документация по каждой функции часто содержит больше примеров использования их аргументов. Этот метод принимает диапазоны как float, или массивы NumPy, или Series при условии совпадения индексов. Полезно для обнаружения самых высоких или самых низких процентильных значений Вы можете создавать 'тепловые карты' с помощью .background_gradient и .text_gradient имеют несколько ключевых аргументов для настройки градиентов и цветов. См. документацию. Используйте Вы можете включить «столбчатые диаграммы» в свой DataFrame. Дополнительные ключевые аргументы дают больше контроля над центрированием и позиционированием, и вы можете передать список В качестве примера, вот как можно изменить вышеуказанное с новым Следующий пример призван продемонстрировать поведение новых опций выравнивания: Предположим, у вас есть прекрасный стиль, созданный для DataFrame, и теперь вы хотите применить тот же стиль ко второму DataFrame. Экспортируйте стиль с помощью Обратите внимание, что вы можете использовать стили, даже если они учитывают данные. Стили пересчитываются на новом DataFrame, на котором они были применены, Только DataFrame (используйте Индекс и столбцы не обязательно должны быть уникальными, но некоторые функции стилизации могут работать только с уникальными индексами. Нет большого repr, и производительность создания невелика; хотя у нас есть некоторые Оптимизации HTML Вы можете применять только стили, вы не можете вставлять новые HTML-сущности, кроме как через наследование. Вот несколько интересных примеров. Если вы отображаете большую матрицу или DataFrame в блокноте, но хотите всегда видеть заголовки столбцов и строк, вы можете использовать .set_sticky метод, который манипулирует CSS стилями таблицы. Также возможно закреплять MultiIndex и даже только определенные уровни. Предположим, вам нужно отобразить HTML внутри HTML, что может быть немного проблематично, когда рендерер не может различить. Вы можете использовать Некоторая поддержка (начиная с версии 0.20.0) доступен для экспорта стилизованных Поддерживаются сокращенные и специфичные для стороны свойства границ (например, Только именованные цвета CSS2 и шестнадцатеричные цвета вида Следующие псевдо-свойства CSS также доступны для установки специфичных для Excel свойств стиля: Стили уровня таблицы и CSS-классы ячеек данных не включаются в экспорт в Excel: свойства отдельных ячеек должны быть сопоставлены с помощью Скриншот вывода: Имеется поддержка (начиная с версии 1.3.0) для экспорта Язык каскадных таблиц стилей (CSS), предназначенный для влияния на то, как браузер отображает HTML-элементы, имеет свои особенности. Он никогда не сообщает об ошибках: он просто молча игнорирует их и не отображает ваши объекты так, как вы задумали, что иногда может быть неприятно. Вот очень краткое введение в то, как Точная структура CSS Ячейки с именами индекса и столбца включают Ячейки с метками индекса включают Ячейки меток столбцов включают Ячейки данных включают Пустые ячейки включают Обрезанные ячейки включают Структура Мы можем увидеть пример HTML, вызвав .to_html() метод. Примеры показали, что при перекрытии CSS-стилей приоритет имеет тот, который идет последним в HTML-рендере. Поэтому следующие варианты дают разные результаты: Это верно только для правил CSS, которые эквивалентны по иерархии или важности. Вы можете узнать больше о Специфичность CSS здесь но для наших целей достаточно обобщить ключевые моменты: Оценка важности CSS для каждого HTML-элемента выводится, начиная с нуля и добавляя: 1000 для встроенного стиля атрибута 100 для каждого ID 10 для каждого атрибута, класса или псевдокласса 1 для каждого имени элемента или псевдоэлемента Давайте используем это для описания действия следующих конфигураций Этот текст красный, потому что сгенерированный селектор В приведенном выше случае текст синий, потому что селектор Теперь мы создали другой стиль таблицы, на этот раз селектор Если ваш стиль не применяется, и это очень раздражает, попробуйте Наконец-то получил этот зеленый текст после всего! Основой pandas является и останется его «высокопроизводительные, простые в использовании структуры данных». Исходя из этого, мы надеемся, что Предоставить API, удобный для интерактивного использования и «достаточно хороший» для многих задач Предоставить основу для специализированных библиотек Если вы создадите отличную библиотеку на основе этого, дайте нам знать, и мы ссылка к нему. Если стандартный шаблон не совсем подходит для ваших нужд, вы можете создать подкласс Styler и расширить или переопределить шаблон. Мы покажем пример расширения стандартного шаблона для вставки пользовательского заголовка перед каждой таблицей. Мы будем использовать следующий шаблон: Теперь, когда мы создали шаблон, нам нужно настроить подкласс Обратите внимание, что мы включаем исходный загрузчик в загрузчик нашего окружения. Это связано с тем, что мы расширяем исходный шаблон, поэтому окружение Jinja должно иметь возможность его найти. Теперь мы можем использовать этот пользовательский стилизатор. Он Наш пользовательский шаблон принимает Для удобства мы предоставляем Вот шаблонная структура для шаблона генерации стиля и шаблона генерации таблицы: Шаблон стиля: Шаблон таблицы: Смотрите шаблон в GitHub repo для получения дополнительной информации. и использует язык стилей CSS для управления многими параметрами, включая цвета, шрифты, границы, фон и т.д. См. здесь для получения дополнительной информации о стилизации HTML-таблиц. Это обеспечивает большую гибкость из коробки и даже позволяет веб-разработчикам
интегрировать DataFrames в свои существующие пользовательские интерфейсы.
s:[8]:
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df.style
[8]:
Модель:
Дерево решений
Регрессия
Случайный
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38.000000
2.000000
18.000000
22.000000
21
nan
Нет опухоли (Отрицательный)
19.000000
439.000000
6.000000
452.000000
226
232.000000
[10]:
s
[10]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
[11]:
s = df.style.format('{:.0f}').hide([('Random', 'Tumour'), ('Random', 'Non-Tumour')], axis="columns")
s
[11]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
Методы добавления стилей#
Стили таблиц#
:hover псевдоселектор, как и другие псевдоселекторы, можно использовать только таким образом.tr:hover {
background-color: #ffff99;
}
[13]:
cell_hover = { # for row hover use
instead of
'selector': 'td:hover',
'props': [('background-color', '#ffffb3')]
}
index_names = {
'selector': '.index_name',
'props': 'font-style: italic; color: darkgrey; font-weight:normal;'
}
headers = {
'selector': 'th:not(.index_name)',
'props': 'background-color: #000066; color: white;'
}
s.set_table_styles([cell_hover, index_names, headers])
[13]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
overwrite существующие стили.[15]:
s.set_table_styles([
{'selector': 'th.col_heading', 'props': 'text-align: center;'},
{'selector': 'th.col_heading.level0', 'props': 'font-size: 1.5em;'},
{'selector': 'td', 'props': 'text-align: center; font-weight: bold;'},
], overwrite=False)
[15]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
.col или .row классы по необходимости к заданным CSS-селекторам.[17]:
s.set_table_styles({
('Regression', 'Tumour'): [{'selector': 'th', 'props': 'border-left: 1px solid white'},
{'selector': 'td', 'props': 'border-left: 1px solid #000066'}]
}, overwrite=False, axis=0)
[17]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
Установка классов и ссылки на внешний CSS#
Атрибуты таблицы#
class в основной используя .set_table_attributes(). Этот метод также может добавлять встроенные стили - подробнее в CSS Иерархии.
[19]:
out = s.set_table_attributes('class="my-table-cls"').to_html()
print(out[out.find('
Model:
CSS-классы ячеек данных#
элементы . Вместо использования внешнего CSS мы создадим наши классы внутри и добавим их в стиль таблицы. Мы отложим добавление
границ до раздел о всплывающих подсказках.
[20]:
s.set_table_styles([ # create internal CSS classes
{'selector': '.true', 'props': 'background-color: #e6ffe6;'},
{'selector': '.false', 'props': 'background-color: #ffe6e6;'},
], overwrite=False)
cell_color = pd.DataFrame([['true ', 'false ', 'true ', 'false '],
['false ', 'true ', 'false ', 'true ']],
index=df.index,
columns=df.columns[:4])
s.set_td_classes(cell_color)
[20]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
Функции Styler#
Действия с данными#
axis аргумент ключевого слова. Для использования по столбцам axis=0, построчное использование axis=1, а для всей таблицы сразу используйте axis=None.[22]:
np.random.seed(0)
df2 = pd.DataFrame(np.random.randn(10,4), columns=['A','B','C','D'])
df2.style
[22]:
A
B
C
D
0
1.764052
0.400157
0.978738
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
-0.854096
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
map.[23]:
def style_negative(v, props=''):
return props if v < 0 else None
s2 = df2.style.map(style_negative, props='color:red;')\
.map(lambda v: 'opacity: 20%;' if (v < 0.3) and (v > -0.3) else None)
s2
[23]:
A
B
C
D
0
1.764052
0.400157
0.978738
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
-0.854096
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
apply. Ниже мы выделяем максимум в столбце.[25]:
def highlight_max(s, props=''):
return np.where(s == np.nanmax(s.values), props, '')
s2.apply(highlight_max, props='color:white;background-color:darkblue', axis=0)
[25]:
A
B
C
D
0
1.764052
0.400157
0.978738
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
-0.854096
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
[27]:
s2.apply(highlight_max, props='color:white;background-color:pink;', axis=1)\
.apply(highlight_max, props='color:white;background-color:purple', axis=None)
[27]:
A
B
C
D
0
1.764052
0.400157
0.978738
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
-0.854096
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
DataFrame.apply. Внутренне, Styler.apply использует DataFrame.apply поэтому результат должен быть одинаковым, и с DataFrame.apply вы сможете проверить строковый вывод CSS вашей целевой функции в каждой ячейке.Действия с индексом и заголовками столбцов#
axis=0 а для стилизации заголовков столбцов используйте axis=1.level из MultiIndex но в настоящее время нет аналогичного subset приложение доступно для этих методов.[29]:
s2.map_index(lambda v: "color:pink;" if v>4 else "color:darkblue;", axis=0)
s2.apply_index(lambda s: np.where(s.isin(["A", "B"]), "color:pink;", "color:darkblue;"), axis=1)
[29]:
A
B
C
D
0
1.764052
0.400157
0.978738
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
-0.854096
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
Всплывающие подсказки и заголовки#
[30]:
s.set_caption("Confusion matrix for multiple cancer prediction models.")\
.set_table_styles([{
'selector': 'caption',
'props': 'caption-side: bottom; font-size:1.25em;'
}], overwrite=False)
[30]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
css_class имя или любой css props для всплывающих подсказок, поскольку есть стандартные значения по умолчанию, но опция доступна, если вам нужен больший визуальный контроль.[32]:
tt = pd.DataFrame([['This model has a very strong true positive rate',
"This model's total number of false negatives is too high"]],
index=['Tumour (Positive)'], columns=df.columns[[0,3]])
s.set_tooltips(tt, props='visibility: hidden; position: absolute; z-index: 1; border: 1px solid #000066;'
'background-color: white; color: #000066; font-size: 0.8em;'
'transform: translate(0px, -24px); padding: 0.6em; border-radius: 0.5em;')
[32]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
[34]:
s.set_table_styles([ # create internal CSS classes
{'selector': '.border-red', 'props': 'border: 2px dashed red;'},
{'selector': '.border-green', 'props': 'border: 2px dashed green;'},
], overwrite=False)
cell_border = pd.DataFrame([['border-green ', ' ', ' ', 'border-red '],
[' ', ' ', ' ', ' ']],
index=df.index,
columns=df.columns[:4])
s.set_td_classes(cell_color + cell_border)
[34]:
Модель:
Дерево решений
Регрессия
Предсказано:
Опухоль
Неопухолевый
Опухоль
Неопухолевый
Фактическая метка:
Опухоль (Положительная)
38
2
18
22
Нет опухоли (Отрицательный)
19
439
6
452
Более точный контроль с помощью срезания#
Styler.apply и Styler.map функции не продемонстрировали использование subset аргумент. Это полезный аргумент, который обеспечивает большую гибкость: он позволяет применять стили к определенным строкам или столбцам, не кодируя эту логику в ваш style функция.subset ведет себя аналогично срезу DataFrame;
(row_indexer, column_indexer)pd.IndexSlice для построения кортежа для последнего. Мы создадим DataFrame с MultiIndex, чтобы продемонстрировать функциональность.[36]:
df3 = pd.DataFrame(np.random.randn(4,4),
pd.MultiIndex.from_product([['A', 'B'], ['r1', 'r2']]),
columns=['c1','c2','c3','c4'])
df3
[36]:
c1
c2
c3
c4
A
r1
-1.048553
-1.420018
-1.706270
1.950775
r2
-0.509652
-0.438074
-1.252795
0.777490
B
r1
-1.613898
-0.212740
-0.895467
0.386902
r2
-0.510805
-1.180632
-0.028182
0.428332
[37]:
slice_ = ['c3', 'c4']
df3.style.apply(highlight_max, props='color:red;', axis=0, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
[37]:
c1
c2
c3
c4
A
r1
-1.048553
-1.420018
-1.706270
1.950775
r2
-0.509652
-0.438074
-1.252795
0.777490
B
r1
-1.613898
-0.212740
-0.895467
0.386902
r2
-0.510805
-1.180632
-0.028182
0.428332
IndexSlice как предложено, тогда он может индексировать по обоим измерениям с большей гибкостью.[38]:
idx = pd.IndexSlice
slice_ = idx[idx[:,'r1'], idx['c2':'c4']]
df3.style.apply(highlight_max, props='color:red;', axis=0, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
[38]:
c1
c2
c3
c4
A
r1
-1.048553
-1.420018
-1.706270
1.950775
r2
-0.509652
-0.438074
-1.252795
0.777490
B
r1
-1.613898
-0.212740
-0.895467
0.386902
r2
-0.510805
-1.180632
-0.028182
0.428332
axis=1.[39]:
slice_ = idx[idx[:,'r2'], :]
df3.style.apply(highlight_max, props='color:red;', axis=1, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
[39]:
c1
c2
c3
c4
A
r1
-1.048553
-1.420018
-1.706270
1.950775
r2
-0.509652
-0.438074
-1.252795
0.777490
B
r1
-1.613898
-0.212740
-0.895467
0.386902
r2
-0.510805
-1.180632
-0.028182
0.428332
(:,'r2')).[40]:
slice_ = idx[idx[(df3['c1'] + df3['c3']) < -2.0], ['c2', 'c4']]
df3.style.apply(highlight_max, props='color:red;', axis=1, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
[40]:
c1
c2
c3
c4
A
r1
-1.048553
-1.420018
-1.706270
1.950775
r2
-0.509652
-0.438074
-1.252795
0.777490
B
r1
-1.613898
-0.212740
-0.895467
0.386902
r2
-0.510805
-1.180632
-0.028182
0.428332
subset или axis аргумент ключевого слова, рассмотрите обёртывание вашей функции в functools.partial, частичное исключение этого ключевого слова.my_func2 = functools.partial(my_func, subset=42)
Оптимизация#
Styler для динамического создания части онлайн-интерфейсов пользователя и улучшения производительности сети.1. Удалить UUID и cell_ids#
uuid и установить cell_ids to False. Это предотвратит ненужный HTML.[41]:
df4 = pd.DataFrame([[1,2],[3,4]])
s4 = df4.style
[42]:
from pandas.io.formats.style import Styler
s4 = Styler(df4, uuid_len=0, cell_ids=False)
2. Используйте стили таблиц#
[43]:
props = 'font-family: "Times New Roman", Times, serif; color: #e83e8c; font-size:1.3em;'
df4.style.map(lambda x: props, subset=[1])
[43]:
0
1
0
1
2
1
3
4
[44]:
df4.style.set_table_styles([{'selector': 'td.col1', 'props': props}])
[44]:
0
1
0
1
2
1
3
4
3. Установка классов вместо использования функций Styler#
[45]:
df2.style.apply(highlight_max, props='color:white;background-color:darkblue;', axis=0)\
.apply(highlight_max, props='color:white;background-color:pink;', axis=1)\
.apply(highlight_max, props='color:white;background-color:purple', axis=None)
[45]:
A
B
C
D
0
1.764052
0.400157
0.978738
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
-0.854096
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
[46]:
build = lambda x: pd.DataFrame(x, index=df2.index, columns=df2.columns)
cls1 = build(df2.apply(highlight_max, props='cls-1 ', axis=0))
cls2 = build(df2.apply(highlight_max, props='cls-2 ', axis=1, result_type='expand').values)
cls3 = build(highlight_max(df2, props='cls-3 '))
df2.style.set_table_styles([
{'selector': '.cls-1', 'props': 'color:white;background-color:darkblue;'},
{'selector': '.cls-2', 'props': 'color:white;background-color:pink;'},
{'selector': '.cls-3', 'props': 'color:white;background-color:purple;'}
]).set_td_classes(cls1 + cls2 + cls3)
[46]:
A
B
C
D
0
1.764052
0.400157
0.978738
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
-0.854096
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
4. Не используйте всплывающие подсказки#
cell_ids для работы и они создают дополнительные HTML-элементы для каждый ячейка данных.5. Если важен каждый байт, используйте замену строк#
[47]:
my_css = {
"row_heading": "",
"col_heading": "",
"index_name": "",
"col": "c",
"row": "r",
"col_trim": "",
"row_trim": "",
"level": "l",
"data": "",
"blank": "",
}
html = Styler(df4, uuid_len=0, cell_ids=False)
html.set_table_styles([{'selector': 'td', 'props': props},
{'selector': '.c1', 'props': 'color:green;'},
{'selector': '.l0', 'props': 'color:blue;'}],
css_class_names=my_css)
print(html.to_html())
0
1
0
1
2
1
3
4
[48]:
html
[48]:
0
1
0
1
2
1
3
4
Встроенные стили#
Styler, поэтому вам не нужно писать их и применять самостоятельно. Текущий список таких функций:
Выделить нулевые значения#
[49]:
df2.iloc[0,2] = np.nan
df2.iloc[4,3] = np.nan
df2.loc[:4].style.highlight_null(color='yellow')
[49]:
A
B
C
D
0
1.764052
0.400157
nan
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
nan
Выделить минимум или максимум#
[50]:
df2.loc[:4].style.highlight_max(axis=1, props='color:white; font-weight:bold; background-color:darkblue;')
[50]:
A
B
C
D
0
1.764052
0.400157
nan
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
nan
Выделить между#
[51]:
left = pd.Series([1.0, 0.0, 1.0], index=["A", "B", "D"])
df2.loc[:4].style.highlight_between(left=left, right=1.5, axis=1, props='color:white; background-color:purple;')
[51]:
A
B
C
D
0
1.764052
0.400157
nan
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
nan
Выделить квантиль#
[52]:
df2.loc[:4].style.highlight_quantile(q_left=0.85, axis=None, color='yellow')
[52]:
A
B
C
D
0
1.764052
0.400157
nan
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
nan
Градиент фона и градиент текста#
background_gradient и text_gradient методы. Для этого требуется matplotlib, и мы будем использовать Seaborn чтобы получить хорошую цветовую карту.[53]:
import seaborn as sns
cm = sns.light_palette("green", as_cmap=True)
df2.style.background_gradient(cmap=cm)
[53]:
A
B
C
D
0
1.764052
0.400157
nan
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
nan
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
[54]:
df2.style.text_gradient(cmap=cm)
[54]:
A
B
C
D
0
1.764052
0.400157
nan
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
nan
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
Установка свойств#
Styler.set_properties когда стиль фактически не зависит от значений. Это просто простая обёртка для .map где функция возвращает одинаковые свойства для всех ячеек.[55]:
df2.loc[:4].style.set_properties(**{'background-color': 'black',
'color': 'lawngreen',
'border-color': 'white'})
[55]:
A
B
C
D
0
1.764052
0.400157
nan
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
nan
Столбчатые диаграммы#
[56]:
df2.style.bar(subset=['A', 'B'], color='#d65f5f')
[56]:
A
B
C
D
0
1.764052
0.400157
nan
2.240893
1
1.867558
-0.977278
0.950088
-0.151357
2
-0.103219
0.410599
0.144044
1.454274
3
0.761038
0.121675
0.443863
0.333674
4
1.494079
-0.205158
0.313068
nan
5
-2.552990
0.653619
0.864436
-0.742165
6
2.269755
-1.454366
0.045759
-0.187184
7
1.532779
1.469359
0.154947
0.378163
8
-0.887786
-1.980796
-0.347912
0.156349
9
1.230291
1.202380
-0.387327
-0.302303
[color_negative, color_positive] для выделения низких и высоких значений или matplotlib colormap.align опция, в сочетании с установкой vmin и vmax ограничения, width фигуры и базового css props ячеек, оставляя место для отображения текста и полос. Мы также используем text_gradient раскрасить текст так же, как столбцы, используя цветовую карту matplotlib (хотя в данном случае визуализация, вероятно, лучше без этого дополнительного эффекта).[57]:
df2.style.format('{:.3f}', na_rep="")\
.bar(align=0, vmin=-2.5, vmax=2.5, cmap="bwr", height=50,
width=60, props="width: 120px; border-right: 1px solid black;")\
.text_gradient(cmap="bwr", vmin=-2.5, vmax=2.5)
[57]:
A
B
C
D
0
1.764
0.400
2.241
1
1.868
-0.977
0.950
-0.151
2
-0.103
NA
0.144
1.454
3
0.761
0.122
0.444
0.334
4
1.494
-0.205
0.313
5
-2.553
0.654
0.864
-0.742
6
2.270
-1.454
0.046
-0.187
7
1.533
1.469
0.155
0.378
8
-0.888
-1.981
Возвращает DataFrame отдельных компонентов разрешения Timedeltas.
0.156
9
1.230
1.202
-0.387
-0.302
[59]:
HTML(head)
[59]:
Выравнивание
Все отрицательные
И Neg, и Pos
Все положительные
Большое положительное
left
-100
-60
-30
-20
-10
-5
0
90
10
20
50
100
100
103
101
102
правый
-100
-60
-30
-20
-10
-5
0
90
10
20
50
100
100
103
101
102
ноль
-100
-60
-30
-20
-10
-5
0
90
10
20
50
100
100
103
101
102
mid
-100
-60
-30
-20
-10
-5
0
90
10
20
50
100
100
103
101
102
mean
-100
-60
-30
-20
-10
-5
0
90
10
20
50
100
100
103
101
102
99
-100
-60
-30
-20
-10
-5
0
90
10
20
50
100
100
103
101
102
Совместное использование стилей#
df1.style.export, и импортировать его на втором DataFrame с df1.style.set[60]:
style1 = df2.style\
.map(style_negative, props='color:red;')\
.map(lambda v: 'opacity: 20%;' if (v < 0.3) and (v > -0.3) else None)\
.set_table_styles([{"selector": "th", "props": "color: blue;"}])\
.hide(axis="index")
style1
[60]:
A
B
C
D
1.764052
0.400157
nan
2.240893
1.867558
-0.977278
0.950088
-0.151357
-0.103219
0.410599
0.144044
1.454274
0.761038
0.121675
0.443863
0.333674
1.494079
-0.205158
0.313068
nan
-2.552990
0.653619
0.864436
-0.742165
2.269755
-1.454366
0.045759
-0.187184
1.532779
1.469359
0.154947
0.378163
-0.887786
-1.980796
-0.347912
0.156349
1.230291
1.202380
-0.387327
-0.302303
[61]:
style2 = df3.style
style2.use(style1.export())
style2
[61]:
c1
c2
c3
c4
-1.048553
-1.420018
-1.706270
1.950775
-0.509652
-0.438074
-1.252795
0.777490
-1.613898
-0.212740
-0.895467
0.386902
-0.510805
-1.180632
-0.028182
0.428332
useосновано на.Ограничения#
Series.to_frame().style)Другие интересные и полезные вещи#
Виджеты#
Styler хорошо взаимодействует с виджетами. Если вы просматриваете это онлайн, а не запускаете блокнот самостоятельно, вы упускаете возможность интерактивной настройки цветовой палитры.[62]:
from ipywidgets import widgets
@widgets.interact
def f(h_neg=(0, 359, 1), h_pos=(0, 359), s=(0., 99.9), l=(0., 99.9)):
return df2.style.background_gradient(
cmap=sns.palettes.diverging_palette(h_neg=h_neg, h_pos=h_pos, s=s, l=l,
as_cmap=True)
)
Увеличить#
[63]:
def magnify():
return [dict(selector="th",
props=[("font-size", "4pt")]),
dict(selector="td",
props=[('padding', "0em 0em")]),
dict(selector="th:hover",
props=[("font-size", "12pt")]),
dict(selector="tr:hover td:hover",
props=[('max-width', '200px'),
('font-size', '12pt')])
]
[64]:
np.random.seed(25)
cmap = cmap=sns.diverging_palette(5, 250, as_cmap=True)
bigdf = pd.DataFrame(np.random.randn(20, 25)).cumsum()
bigdf.style.background_gradient(cmap, axis=1)\
.set_properties(**{'max-width': '80px', 'font-size': '1pt'})\
.set_caption("Hover to magnify")\
.format(precision=2)\
.set_table_styles(magnify())
[64]:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
0
0.23
1.03
-0.84
-0.59
-0.96
-0.22
-0.62
1.84
-2.05
0.87
-0.92
-0.23
2.15
-1.33
0.08
-1.25
1.20
-1.05
1.06
-0.42
2.29
-2.59
2.82
0.68
-1.58
1
-1.75
1.56
-1.13
-1.10
1.03
0.00
-2.46
3.45
-1.66
1.27
-0.52
-0.02
1.52
-1.09
-1.86
-1.13
-0.68
-0.81
0.35
-0.06
1.79
-2.82
2.26
0.78
0.44
2
-0.65
3.22
-1.76
0.52
2.20
-0.37
-3.00
3.73
-1.87
2.46
0.21
-0.24
-0.10
-0.78
-3.02
-0.82
-0.21
-0.23
0.86
-0.68
1.45
-4.89
3.03
1.91
0.61
3
-1.62
3.71
-2.31
0.43
4.17
-0.43
-3.86
4.16
-2.15
1.08
0.12
0.60
-0.89
0.27
-3.67
-2.71
-0.31
-1.59
1.35
-1.83
0.91
-5.80
2.81
2.11
0.28
4
Исправлена ошибка, при которой вызов
4.48
-1.86
-1.70
5.19
-1.02
-3.81
4.72
-0.72
1.08
-0.18
0.83
-0.22
-1.08
-4.27
-2.88
-0.97
-1.78
1.53
-1.80
2.21
-6.34
3.34
2.49
2.09
5
-0.84
4.23
-1.65
-2.00
5.34
-0.99
-4.13
3.94
-1.06
-0.94
1.24
0.09
-1.78
-0.11
-4.45
-0.85
-2.06
-1.35
0.80
-1.63
1.54
-6.51
2.80
2.14
3.77
6
-0.74
5.35
-2.11
-1.13
4.20
-1.85
-3.20
3.76
-3.22
-1.23
0.34
0.57
-1.82
0.54
-4.43
-1.83
-4.03
-2.62
-0.20
-4.68
1.93
-8.46
3.34
2.52
5.81
7
-0.44
4.69
-2.30
-0.21
5.93
-2.63
-1.83
5.46
-4.50
-3.16
-1.73
0.18
0.11
0.04
-5.99
-0.45
-6.20
-3.89
0.71
-3.95
0.67
-7.26
2.97
3.39
6.66
8
0.92
5.80
-3.33
-0.65
5.99
-3.19
-1.83
5.63
-3.53
-1.30
-1.61
0.82
-2.45
-0.40
-6.06
-0.52
-6.60
-3.48
-0.04
-4.60
0.51
-5.85
3.23
2.40
5.08
9
0.38
5.54
-4.49
-0.80
7.05
-2.64
-0.44
5.35
-1.96
-0.33
-0.80
0.26
-3.37
-0.82
-6.05
-2.61
-8.45
-4.45
0.41
-4.71
1.89
-6.93
2.14
3.00
5.16
10
2.06
5.84
-3.90
-0.98
7.78
-2.49
-0.59
5.59
-2.22
-0.71
-0.46
1.80
-2.79
0.48
-5.97
-3.44
-7.77
-5.49
-0.70
-4.61
-0.52
-7.72
1.54
5.02
5.81
11
1.86
4.47
-2.17
-1.38
5.90
-0.49
0.02
параметр,
-1.04
-0.60
0.49
1.96
-1.47
1.88
-5.92
-4.55
-8.15
-3.42
-2.24
-4.33
-1.17
-7.90
1.36
5.31
5.83
12
3.19
4.22
-3.06
-2.27
5.93
-2.64
0.33
6.72
-2.84
-0.20
1.89
2.63
-1.53
0.75
-5.27
-4.53
-7.57
-2.85
-2.17
-4.78
-1.13
-8.99
2.11
6.42
5.60
13
2.31
4.45
-3.87
-2.05
6.76
-3.25
-2.17
7.99
-2.56
-0.80
0.71
2.33
-0.16
-0.46
-5.10
-3.79
-7.58
-4.00
0.33
-3.67
-1.05
-8.71
2.47
5.87
6.71
14
3.78
4.33
-3.88
-1.58
6.22
-3.23
-1.46
5.57
-2.93
-0.33
-0.97
1.72
3.61
0.29
-4.21
-4.10
-6.68
-4.50
-2.19
-2.43
-1.64
-9.36
3.36
6.11
7.53
15
5.64
5.31
-3.98
-2.26
5.91
-3.30
-1.03
5.68
-3.06
-0.33
-1.16
2.19
4.20
1.01
-3.22
-4.31
-5.74
-4.44
-2.30
-1.36
-1.20
-11.27
2.59
6.69
5.91
16
4.08
4.34
-2.44
-3.30
6.04
-2.52
-0.47
5.28
-4.84
1.58
0.23
0.10
5.79
1.80
-3.13
-3.85
-5.53
-2.97
-2.13
-1.15
-0.56
-13.13
2.07
6.16
4.94
17
5.64
4.57
-3.53
-3.76
6.58
-2.58
-0.75
6.58
-4.78
3.63
-0.29
0.56
5.76
2.05
-2.27
-2.31
-4.95
-3.16
-3.06
-2.43
0.84
-12.57
3.56
7.36
4.70
18
5.99
5.82
-2.85
-4.15
7.12
-3.32
-1.21
7.93
-4.85
1.44
-0.63
0.35
7.47
0.87
-1.52
-2.09
-4.23
-2.55
-2.46
-2.89
1.90
-9.74
3.43
7.07
4.39
19
4.03
6.23
-4.10
-4.11
7.19
-4.10
-1.52
6.53
-5.21
-0.24
0.01
1.16
6.43
-1.97
-2.64
-1.66
-5.20
-3.25
-2.87
-1.65
1.64
-10.66
2.83
7.48
3.94
Фиксированные заголовки#
[65]:
bigdf = pd.DataFrame(np.random.randn(16, 100))
bigdf.style.set_sticky(axis="index")
[65]:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
0
-0.773866
-0.240521
-0.217165
1.173609
0.686390
0.008358
0.696232
0.173166
0.620498
0.504067
0.428066
-0.051824
0.719915
0.057165
0.562808
-0.369536
0.483399
0.620765
-0.354342
-1.469471
-1.937266
0.038031
-1.518162
-0.417599
0.386717
0.716193
0.489961
0.733957
0.914415
0.679894
0.255448
-0.508338
0.332030
-0.111107
-0.251983
-1.456620
0.409630
1.062320
-0.577115
0.718796
-0.399260
-1.311389
0.649122
0.091566
0.628872
0.297894
-0.142290
-0.542291
-0.914290
1.144514
0.313584
1.182635
1.214235
-0.416446
-1.653940
-2.550787
0.442473
0.052127
-0.464469
-0.523852
0.989726
-1.325539
-0.199687
-1.226727
0.290018
1.164574
0.817841
-0.309509
0.496599
0.943536
-0.091850
-2.802658
2.126219
-0.521161
0.288098
-0.454663
-1.676143
-0.357661
-0.788960
0.185911
-0.017106
2.454020
1.832706
-0.911743
-0.655873
-0.000514
-2.226997
0.677285
-0.140249
-0.408407
-0.838665
0.482228
1.243458
-0.477394
-0.220343
-2.463966
0.237325
-0.307380
1.172478
0.819492
1
0.405906
-0.978919
1.267526
0.145250
-1.066786
-2.114192
-1.128346
-1.082523
0.372216
0.004127
-0.211984
0.937326
-0.935890
-1.704118
0.611789
-1.030015
0.636123
-1.506193
1.736609
1.392958
1.009424
0.353266
0.697339
-0.297424
0.428702
-0.145346
-0.333553
-0.974699
0.665314
0.971944
0.121950
-1.439668
1.018808
1.442399
-0.199585
-1.165916
0.645656
1.436466
-0.921215
1.293906
-2.706443
1.460928
-0.823197
0.292952
-1.448992
0.026692
-0.975883
0.392823
0.442166
0.745741
1.187982
-0.218570
0.305288
0.054932
-1.476953
-0.114434
0.014103
0.825394
-0.060654
-0.413688
0.974836
1.339210
1.034838
0.040775
0.705001
0.017796
1.867681
-0.390173
2.285277
2.311464
-0.085070
-0.648115
0.576300
-0.790087
-1.183798
-1.334558
-0.454118
0.319302
1.706488
0.830429
0.502476
-0.079631
0.414635
0.332511
0.042935
-0.160910
0.918553
-0.292697
-1.303834
-0.199604
0.871023
-1.370681
-0.205701
-0.492973
1.123083
-0.081842
-0.118527
0.245838
-0.315742
-0.511806
2
0.011470
-0.036104
1.399603
-0.418176
-0.412229
-1.234783
-1.121500
1.196478
-0.569522
0.422022
-0.220484
0.804338
2.892667
-0.511055
-0.168722
-1.477996
-1.969917
0.471354
1.698548
0.137105
-0.762052
0.199379
-0.964346
-0.256692
1.265275
0.848762
-0.784161
1.863776
-0.355569
0.854552
0.768061
-2.075718
-2.501069
1.109868
0.957545
-0.683276
0.307764
0.733073
1.706250
-1.118091
0.374961
-1.414503
-0.524183
-1.662696
0.687921
0.521732
1.451396
-0.833491
-0.362796
-1.174444
-0.813893
-0.893220
0.770743
1.156647
-0.647444
0.125929
0.513600
-0.537874
1.992052
-1.946584
-0.104759
0.484779
-0.290936
-0.441075
0.542993
-1.050038
1.630482
0.239771
-1.177310
0.464804
-0.966995
0.646086
0.486899
1.022196
-2.267827
-1.229616
1.313805
1.073292
2.324940
-0.542720
-1.504292
0.777643
-0.618553
0.011342
1.385062
1.363552
-0.549834
0.688896
1.361288
-0.381137
0.797812
-1.128198
0.369208
0.540132
0.413853
-0.200308
-0.969126
0.981293
-0.009783
-0.320020
3
-0.574816
1.419977
0.434813
-1.101217
-1.586275
1.979573
0.378298
0.782326
2.178987
0.657564
0.683774
-0.091000
-0.059552
-0.738908
-0.907653
-0.701936
0.580039
-0.618757
0.453684
1.665382
-0.152321
0.880077
0.571073
-0.604736
0.532359
0.515031
-0.959844
-0.887184
0.435781
0.862093
-0.956321
-0.625909
0.194472
0.442490
0.526503
-0.215274
0.090711
0.932592
0.811999
-2.497026
0.631545
0.321418
-0.425549
-1.078832
0.753444
0.199790
-0.360526
-0.013448
-0.819476
0.814869
0.442118
-0.972048
-0.060603
-2.349825
1.265445
-0.573257
0.429124
1.049783
1.954773
0.071883
-0.094209
0.265616
0.948318
0.331645
1.343401
-0.167934
-1.105252
-0.167077
-0.096576
-0.838161
-0.208564
0.394534
0.762533
1.235357
-0.207282
-0.202946
-0.468025
0.256944
2.587584
1.186697
-1.031903
1.428316
0.658899
-0.046582
-0.075422
1.329359
-0.684267
-1.524182
2.014061
3.770933
0.647353
-1.021377
-0.345493
0.582811
0.797812
1.326020
1.422857
-3.077007
0.184083
1.478935
4
-0.600142
1.929561
-2.346771
-0.669700
-1.165258
0.814788
0.444449
-0.576758
0.353091
0.408893
0.091391
-2.294389
0.485506
-0.081304
-0.716272
-1.648010
1.005361
-1.489603
0.363098
0.758602
-1.373847
-0.972057
1.988537
0.319829
1.169060
0.146585
1.030388
1.165984
1.369563
0.730984
-1.383696
-0.515189
-0.808927
-1.174651
-1.631502
-1.123414
-0.478155
-1.583067
1.419074
1.668777
1.567517
0.222103
-0.336040
-1.352064
0.251032
-0.401695
0.268413
-0.012299
-0.918953
2.921208
-0.581588
0.672848
1.251136
1.382263
1.429897
1.290990
-1.272673
-0.308611
-0.422988
-0.675642
0.874441
1.305736
-0.262585
-1.099395
-0.667101
-0.646737
-0.556338
-0.196591
0.119306
-0.266455
-0.524267
2.650951
0.097318
-0.974697
0.189964
1.141155
-0.064434
1.104971
-1.508908
-0.031833
0.803919
-0.659221
0.939145
0.214041
-0.531805
0.956060
0.249328
0.637903
-0.510158
1.850287
-0.348407
2.001376
-0.389643
-0.024786
-0.470973
0.869339
0.170667
0.598062
1.217262
1.274013
5
-0.389981
-0.752441
-0.734871
3.517318
-1.173559
-0.004956
0.145419
2.151368
-3.086037
-1.569139
1.449784
-0.868951
-1.687716
-0.994401
1.153266
1.803045
-0.819059
0.847970
0.227102
-0.500762
0.868210
1.823540
1.161007
-0.307606
-0.713416
0.363560
-0.822162
2.427681
-0.129537
-0.078716
1.345644
-1.286094
0.237242
-0.136056
0.596664
-1.412381
1.206341
0.299860
0.705238
0.142412
-1.059382
0.833468
1.060015
-0.527045
-1.135732
-1.140983
-0.779540
-0.640875
-1.217196
-1.675663
0.241263
-0.273322
-1.697936
-0.594943
0.101154
1.391735
-0.426953
1.008344
-0.818577
1.924570
-0.578900
-0.457395
-1.096705
0.418522
-0.155623
0.169706
-2.533706
0.018904
1.434160
0.744095
0.647626
-0.770309
2.329141
-0.141547
-1.761594
0.702091
-1.531450
-0.788427
-0.184622
-1.942321
1.530113
0.503406
1.105845
-0.935120
-1.115483
-2.249762
1.307135
0.788412
-0.441091
0.073561
0.812101
-0.916146
1.573714
-0.309508
0.499987
0.187594
0.558913
0.903246
0.317901
-0.809797
6
1.128248
1.516826
-0.186735
-0.668157
1.132259
-0.246648
-0.855167
0.732283
0.931802
1.318684
-1.198418
-1.149318
0.586321
-1.171937
-0.607731
2.753747
1.479287
-1.136365
-0.020485
0.320444
-1.955755
0.660402
-1.545371
0.200519
-0.017263
1.634686
0.599246
0.462989
0.023721
0.225546
вызывается при наличии
-0.027496
-0.061233
-0.566411
-0.669567
0.601618
0.503656
-0.678253
-2.907108
-1.717123
0.397631
1.300108
0.215821
-0.593075
-0.225944
-0.946057
1.000308
0.393160
1.342074
-0.370687
-0.166413
-0.419814
-0.255931
1.789478
0.282378
0.742260
-0.050498
1.415309
0.838166
-1.400292
-0.937976
-1.499148
0.801859
0.224824
0.283572
0.643703
-1.198465
0.527206
0.215202
0.437048
1.312868
0.741243
0.077988
0.006123
0.190370
0.018007
-1.026036
-2.378430
-1.069949
0.843822
1.289216
-1.423369
-0.462887
0.197330
-0.935076
0.441271
0.414643
-0.377887
-0.530515
0.621592
1.009572
0.569718
0.175291
-0.656279
-0.112273
-0.392137
-1.043558
-0.467318
-0.384329
-2.009207
7
0.658598
0.101830
-0.682781
0.229349
-0.305657
0.404877
0.252244
-0.837784
-0.039624
0.329457
0.751694
1.469070
-0.157199
1.032628
-0.584639
-0.925544
0.342474
-0.969363
0.133480
-0.385974
-0.600278
0.281939
0.868579
1.129803
-0.041898
0.961193
0.131521
-0.792889
-1.285737
0.073934
-1.333315
-1.044125
1.277338
1.492257
0.411379
1.771805
-1.111128
1.123233
-1.019449
1.738357
-0.690764
-0.120710
-0.421359
-0.727294
-0.857759
-0.069436
-0.328334
-0.558180
1.063474
-0.519133
-0.496902
1.089589
-1.615801
0.080174
-0.229938
-0.498420
-0.624615
0.059481
-0.093158
-1.784549
-0.503789
-0.140528
0.002653
-0.484930
0.055914
-0.680948
-0.994271
1.277052
0.037651
2.155421
-0.437589
0.696404
0.417752
-0.544785
1.190690
0.978262
0.752102
0.504472
0.139853
-0.505089
GH 43223
-1.603194
0.731847
0.010903
-1.165346
-0.125195
-1.032685
-0.465520
1.514808
0.304762
0.793414
0.314635
-1.638279
0.111737
-0.777037
0.251783
1.126303
-0.808798
0.422064
-0.349264
8
-0.356362
-0.089227
0.609373
0.542382
-0.768681
-0.048074
2.015458
-1.552351
0.251552
1.459635
0.949707
0.339465
-0.001372
1.798589
1.559163
0.231783
0.423141
-0.310530
0.353795
2.173336
-0.196247
-0.375636
-0.858221
0.258410
0.656430
0.960819
1.137893
1.553405
0.038981
-0.632038
-0.132009
-1.834997
-0.242576
-0.297879
-0.441559
-0.769691
0.224077
-0.153009
0.519526
-0.680188
0.535851
0.671496
-0.183064
0.301234
1.288256
-2.478240
-0.360403
0.424067
-0.834659
-0.128464
-0.489013
-0.014888
-1.461230
-1.435223
-1.319802
1.083675
0.979140
-0.375291
1.110189
-1.011351
0.587886
-0.822775
-1.183865
1.455173
1.134328
0.239403
-0.837991
-1.130932
0.783168
1.845520
1.437072
-1.198443
1.379098
2.129113
0.260096
-0.011975
0.043302
0.722941
1.028152
-0.235806
1.145245
-1.359598
0.232189
0.503712
-0.614264
-0.530606
-2.435803
-0.255238
-0.064423
0.784643
0.256346
0.128023
1.414103
-1.118659
0.877353
0.500561
0.463651
-2.034512
-0.981683
-0.691944
9
-1.113376
-1.169402
0.680539
-1.534212
1.653817
-1.295181
-0.566826
0.477014
1.413371
0.517105
1.401153
-0.872685
0.830957
0.181507
-0.145616
0.694592
-0.751208
0.324444
0.681973
-0.054972
0.917776
-1.024810
-0.206446
-0.600113
0.852805
1.455109
-0.079769
0.076076
0.207699
-1.850458
-0.124124
-0.610871
-0.883362
0.219049
-0.685094
-0.645330
-0.242805
-0.775602
0.233070
2.422642
-1.423040
-0.582421
0.968304
-0.701025
-0.167850
0.277264
1.301231
0.301205
-3.081249
-0.562868
0.192944
-0.664592
0.565686
0.190913
-0.841858
-1.856545
-1.022777
1.295968
0.451921
0.659955
0.065818
-0.319586
0.253495
-1.144646
-0.483404
0.555902
0.807069
0.714196
0.661196
0.053667
0.346833
-1.288977
-0.386734
-1.262127
0.477495
-0.494034
-0.911414
1.152963
-0.342365
-0.160187
0.470054
-0.853063
-1.387949
-0.257257
-1.030690
-0.110210
0.328911
-0.555923
0.987713
-0.501957
2.069887
-0.067503
0.316029
-1.506232
2.201621
0.492097
-0.085193
-0.977822
1.039147
-0.653932
10
-0.405638
-1.402027
-1.166242
1.306184
0.856283
-1.236170
-0.646721
-1.474064
0.082960
0.090310
-0.169977
0.406345
0.915427
-0.974503
0.271637
1.539184
-0.098866
-0.525149
1.063933
0.085827
-0.129622
0.947959
-0.072496
-0.237592
0.012549
1.065761
0.996596
-0.172481
2.583139
-0.028578
-0.254856
1.328794
-1.592951
2.434350
-0.341500
-0.307719
-1.333273
-1.100845
0.209097
1.734777
0.639632
0.424779
-0.129327
0.905029
-0.482909
1.731628
-2.783425
-0.333677
-0.110895
1.212636
-0.208412
0.427117
1.348563
0.043859
1.772519
-1.416106
0.401155
0.807157
0.303427
-1.246288
0.178774
-0.066126
-1.862288
1.241295
0.377021
-0.822320
-0.749014
1.463652
1.602268
-1.043877
1.185290
-0.565783
-1.076879
1.360241
-0.121991
0.991043
1.007952
0.450185
-0.744376
1.388876
-0.316847
-0.841655
-1.056842
-0.500226
0.096959
1.176896
-2.939652
1.792213
0.316340
0.303218
1.024967
-0.590871
-0.453326
-0.795981
-0.393301
-0.374372
-1.270199
1.618372
1.197727
-0.914863
11
-0.625210
0.288911
0.288374
-1.372667
-0.591395
-0.478942
1.335664
-0.459855
-1.615975
-1.189676
0.374767
-2.488733
0.586656
-1.422008
0.496030
1.911128
-0.560660
-0.499614
-0.372171
-1.833069
0.237124
-0.944446
0.912140
0.359790
-1.359235
0.166966
-0.047107
-0.279789
-0.594454
-0.739013
-1.527645
0.401668
1.791252
GH 51076
0.523873
2.207585
0.488999
-0.339283
0.131711
0.018409
1.186551
-0.424318
1.554994
-0.205917
-0.934975
0.654102
-1.227761
-0.461025
-0.421201
-0.058615
-0.584563
0.336913
-0.477102
-1.381463
0.757745
-0.268968
0.034870
1.231686
0.236600
1.234720
-0.040247
0.029582
1.034905
0.380204
-0.012108
-0.859511
-0.990340
-1.205172
-1.030178
0.426676
0.497796
-0.876808
0.957963
0.173016
0.131612
-1.003556
-1.069908
-1.799207
1.429598
-0.116015
-1.454980
0.261917
0.444412
0.273290
0.844115
0.218745
-1.033350
-1.188295
0.058373
0.800523
-1.627068
0.861651
0.871018
-0.003733
-0.243354
0.947296
0.509406
0.044546
0.266896
1.337165
12
0.699142
-1.928033
0.105363
1.042322
0.715206
-0.763783
0.098798
-1.157898
0.134105
0.042041
0.674826
0.165649
-1.622970
-3.131274
0.597649
-1.880331
0.663980
-0.256033
-1.524058
0.492799
0.221163
0.429622
-0.659584
1.264506
-0.032131
-2.114907
-0.264043
0.457835
-0.676837
-0.629003
0.489145
-0.551686
0.942622
-0.512043
-0.455893
0.021244
-0.178035
-2.498073
-0.171292
0.323510
-0.545163
-0.668909
-0.150031
0.521620
-0.428980
0.676463
0.369081
-0.724832
0.793542
1.237422
0.401275
2.141523
0.249012
0.486755
-0.163274
0.592222
-0.292600
-0.547168
0.619104
-0.013605
0.776734
0.131424
1.189480
-0.666317
-0.939036
1.105515
0.621452
1.586605
-0.760970
1.649646
0.283199
1.275812
-0.452012
0.301361
-0.976951
-0.268106
-0.079255
-1.258332
2.216658
-1.175988
-0.863497
-1.653022
-0.561514
0.450753
0.417200
0.094676
-2.231054
1.316862
-0.477441
0.646654
-0.200252
1.074354
-0.058176
0.120990
0.222522
-0.179507
0.421655
-0.914341
-0.234178
0.741524
13
0.932714
1.423761
-1.280835
0.347882
-0.863171
-0.852580
1.044933
2.094536
0.806206
0.416201
-1.109503
0.145302
-0.996871
0.325456
-0.605081
1.175326
1.645054
0.293432
-2.766822
1.032849
0.079115
-1.414132
1.463376
2.335486
0.411951
-0.048543
0.159284
-0.651554
-1.093128
1.568390
-0.077807
-2.390779
-0.842346
-0.229675
-0.999072
-1.367219
-0.792042
-1.878575
1.451452
1.266250
-0.734315
0.266152
0.735523
-0.430860
0.229864
0.850083
-2.241241
1.063850
0.289409
-0.354360
0.113063
-0.173006
1.386998
1.886236
0.587119
-0.961133
0.399295
1.461560
0.310823
0.280220
-0.879103
-1.326348
0.003337
-1.085908
-0.436723
2.111926
0.106068
0.615597
2.152996
-0.196155
0.025747
-0.039061
0.656823
-0.347105
2.513979
1.758070
1.288473
-0.739185
-0.691592
-0.098728
-0.276386
0.489981
0.516278
-0.838258
0.596673
-0.331053
0.521174
-0.145023
0.836693
-1.092166
0.361733
-1.169981
0.046731
0.655377
-0.756852
1.285805
-0.095019
0.360253
1.370621
0.083010
14
0.888893
2.288725
-1.032332
0.212273
-1.091826
1.692498
1.025367
0.550854
0.679430
-1.335712
-0.798341
2.265351
-1.006938
2.059761
0.420266
-1.189657
0.506674
0.260847
-0.533145
0.727267
1.412276
1.482106
-0.996258
0.588641
-0.412642
-0.920733
-0.874691
0.839002
0.501668
-0.342493
-0.533806
-2.146352
-0.597339
0.115726
0.850683
-0.752239
0.377263
-0.561982
0.262783
-0.356676
-0.367462
0.753611
-1.267414
-1.330698
-0.536453
0.840938
-0.763108
-0.268100
-0.677424
1.606831
0.151732
-2.085701
1.219296
0.400863
0.591165
-1.485213
1.501979
1.196569
-0.214154
0.339554
-0.034446
1.176452
0.546340
-1.255630
-1.309210
-0.445437
0.189437
-0.737463
0.843767
-0.605632
-0.060777
0.409310
1.285569
-0.622638
1.018193
0.880680
0.046805
-1.818058
-0.809829
0.875224
0.409569
-0.116621
-1.238919
3.305724
-0.024121
-1.756500
1.328958
0.507593
-0.866554
-2.240848
-0.661376
-0.671824
0.215720
-0.296326
0.481402
0.829645
-0.721025
1.263914
0.549047
-1.234945
15
-1.978838
0.721823
-0.559067
-1.235243
0.420716
-0.598845
0.359576
-0.619366
-1.757772
-1.156251
0.705212
0.875071
-1.020376
0.394760
-0.147970
0.230249
1.355203
1.794488
2.678058
-0.153565
-0.460959
-0.098108
-1.407930
-2.487702
1.823014
0.099873
-0.517603
-0.509311
-1.833175
-0.900906
0.459493
-0.655440
1.466122
-1.531389
-0.422106
0.421422
0.578615
0.259795
0.018941
-0.168726
1.611107
-1.586550
-1.384941
0.858377
1.033242
1.701343
1.748344
-0.371182
-0.843575
2.089641
-0.345430
-1.740556
0.141915
-2.197138
0.689569
-0.150025
0.287456
0.654016
-1.521919
-0.918008
-0.587528
0.230636
0.262637
0.615674
0.600044
-0.494699
-0.743089
0.220026
-0.242207
0.528216
-0.328174
-1.536517
-1.476640
-1.162114
-1.260222
1.106252
-1.467408
-0.349341
-1.841217
0.031296
-0.076475
-0.353383
0.807545
0.779064
-2.398417
-0.267828
1.549734
0.814397
0.284770
-0.659369
0.761040
-0.722067
0.810332
1.501295
1.440865
-1.367459
-0.700301
-1.540662
0.159837
-0.625415
[66]:
bigdf.index = pd.MultiIndex.from_product([["A","B"],[0,1],[0,1,2,3]])
bigdf.style.set_sticky(axis="index", pixel_size=18, levels=[1,2])
[66]:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
A
0
0
-0.773866
-0.240521
-0.217165
1.173609
0.686390
0.008358
0.696232
0.173166
0.620498
0.504067
0.428066
-0.051824
0.719915
0.057165
0.562808
-0.369536
0.483399
0.620765
-0.354342
-1.469471
-1.937266
0.038031
-1.518162
-0.417599
0.386717
0.716193
0.489961
0.733957
0.914415
0.679894
0.255448
-0.508338
0.332030
-0.111107
-0.251983
-1.456620
0.409630
1.062320
-0.577115
0.718796
-0.399260
-1.311389
0.649122
0.091566
0.628872
0.297894
-0.142290
-0.542291
-0.914290
1.144514
0.313584
1.182635
1.214235
-0.416446
-1.653940
-2.550787
0.442473
0.052127
-0.464469
-0.523852
0.989726
-1.325539
-0.199687
-1.226727
0.290018
1.164574
0.817841
-0.309509
0.496599
0.943536
-0.091850
-2.802658
2.126219
-0.521161
0.288098
-0.454663
-1.676143
-0.357661
-0.788960
0.185911
-0.017106
2.454020
1.832706
-0.911743
-0.655873
-0.000514
-2.226997
0.677285
-0.140249
-0.408407
-0.838665
0.482228
1.243458
-0.477394
-0.220343
-2.463966
0.237325
-0.307380
1.172478
0.819492
1
0.405906
-0.978919
1.267526
0.145250
-1.066786
-2.114192
-1.128346
-1.082523
0.372216
0.004127
-0.211984
0.937326
-0.935890
-1.704118
0.611789
-1.030015
0.636123
-1.506193
1.736609
1.392958
1.009424
0.353266
0.697339
-0.297424
0.428702
-0.145346
-0.333553
-0.974699
0.665314
0.971944
0.121950
-1.439668
1.018808
1.442399
-0.199585
-1.165916
0.645656
1.436466
-0.921215
1.293906
-2.706443
1.460928
-0.823197
0.292952
-1.448992
0.026692
-0.975883
0.392823
0.442166
0.745741
1.187982
-0.218570
0.305288
0.054932
-1.476953
-0.114434
0.014103
0.825394
-0.060654
-0.413688
0.974836
1.339210
1.034838
0.040775
0.705001
0.017796
1.867681
-0.390173
2.285277
2.311464
-0.085070
-0.648115
0.576300
-0.790087
-1.183798
-1.334558
-0.454118
0.319302
1.706488
0.830429
0.502476
-0.079631
0.414635
0.332511
0.042935
-0.160910
0.918553
-0.292697
-1.303834
-0.199604
0.871023
-1.370681
-0.205701
-0.492973
1.123083
-0.081842
-0.118527
0.245838
-0.315742
-0.511806
2
0.011470
-0.036104
1.399603
-0.418176
-0.412229
-1.234783
-1.121500
1.196478
-0.569522
0.422022
-0.220484
0.804338
2.892667
-0.511055
-0.168722
-1.477996
-1.969917
0.471354
1.698548
0.137105
-0.762052
0.199379
-0.964346
-0.256692
1.265275
0.848762
-0.784161
1.863776
-0.355569
0.854552
0.768061
-2.075718
-2.501069
1.109868
0.957545
-0.683276
0.307764
0.733073
1.706250
-1.118091
0.374961
-1.414503
-0.524183
-1.662696
0.687921
0.521732
1.451396
-0.833491
-0.362796
-1.174444
-0.813893
-0.893220
0.770743
1.156647
-0.647444
0.125929
0.513600
-0.537874
1.992052
-1.946584
-0.104759
0.484779
-0.290936
-0.441075
0.542993
-1.050038
1.630482
0.239771
-1.177310
0.464804
-0.966995
0.646086
0.486899
1.022196
-2.267827
-1.229616
1.313805
1.073292
2.324940
-0.542720
-1.504292
0.777643
-0.618553
0.011342
1.385062
1.363552
-0.549834
0.688896
1.361288
-0.381137
0.797812
-1.128198
0.369208
0.540132
0.413853
-0.200308
-0.969126
0.981293
-0.009783
-0.320020
3
-0.574816
1.419977
0.434813
-1.101217
-1.586275
1.979573
0.378298
0.782326
2.178987
0.657564
0.683774
-0.091000
-0.059552
-0.738908
-0.907653
-0.701936
0.580039
-0.618757
0.453684
1.665382
-0.152321
0.880077
0.571073
-0.604736
0.532359
0.515031
-0.959844
-0.887184
0.435781
0.862093
-0.956321
-0.625909
0.194472
0.442490
0.526503
-0.215274
0.090711
0.932592
0.811999
-2.497026
0.631545
0.321418
-0.425549
-1.078832
0.753444
0.199790
-0.360526
-0.013448
-0.819476
0.814869
0.442118
-0.972048
-0.060603
-2.349825
1.265445
-0.573257
0.429124
1.049783
1.954773
0.071883
-0.094209
0.265616
0.948318
0.331645
1.343401
-0.167934
-1.105252
-0.167077
-0.096576
-0.838161
-0.208564
0.394534
0.762533
1.235357
-0.207282
-0.202946
-0.468025
0.256944
2.587584
1.186697
-1.031903
1.428316
0.658899
-0.046582
-0.075422
1.329359
-0.684267
-1.524182
2.014061
3.770933
0.647353
-1.021377
-0.345493
0.582811
0.797812
1.326020
1.422857
-3.077007
0.184083
1.478935
1
0
-0.600142
1.929561
-2.346771
-0.669700
-1.165258
0.814788
0.444449
-0.576758
0.353091
0.408893
0.091391
-2.294389
0.485506
-0.081304
-0.716272
-1.648010
1.005361
-1.489603
0.363098
0.758602
-1.373847
-0.972057
1.988537
0.319829
1.169060
0.146585
1.030388
1.165984
1.369563
0.730984
-1.383696
-0.515189
-0.808927
-1.174651
-1.631502
-1.123414
-0.478155
-1.583067
1.419074
1.668777
1.567517
0.222103
-0.336040
-1.352064
0.251032
-0.401695
0.268413
-0.012299
-0.918953
2.921208
-0.581588
0.672848
1.251136
1.382263
1.429897
1.290990
-1.272673
-0.308611
-0.422988
-0.675642
0.874441
1.305736
-0.262585
-1.099395
-0.667101
-0.646737
-0.556338
-0.196591
0.119306
-0.266455
-0.524267
2.650951
0.097318
-0.974697
0.189964
1.141155
-0.064434
1.104971
-1.508908
-0.031833
0.803919
-0.659221
0.939145
0.214041
-0.531805
0.956060
0.249328
0.637903
-0.510158
1.850287
-0.348407
2.001376
-0.389643
-0.024786
-0.470973
0.869339
0.170667
0.598062
1.217262
1.274013
1
-0.389981
-0.752441
-0.734871
3.517318
-1.173559
-0.004956
0.145419
2.151368
-3.086037
-1.569139
1.449784
-0.868951
-1.687716
-0.994401
1.153266
1.803045
-0.819059
0.847970
0.227102
-0.500762
0.868210
1.823540
1.161007
-0.307606
-0.713416
0.363560
-0.822162
2.427681
-0.129537
-0.078716
1.345644
-1.286094
0.237242
-0.136056
0.596664
-1.412381
1.206341
0.299860
0.705238
0.142412
-1.059382
0.833468
1.060015
-0.527045
-1.135732
-1.140983
-0.779540
-0.640875
-1.217196
-1.675663
0.241263
-0.273322
-1.697936
-0.594943
0.101154
1.391735
-0.426953
1.008344
-0.818577
1.924570
-0.578900
-0.457395
-1.096705
0.418522
-0.155623
0.169706
-2.533706
0.018904
1.434160
0.744095
0.647626
-0.770309
2.329141
-0.141547
-1.761594
0.702091
-1.531450
-0.788427
-0.184622
-1.942321
1.530113
0.503406
1.105845
-0.935120
-1.115483
-2.249762
1.307135
0.788412
-0.441091
0.073561
0.812101
-0.916146
1.573714
-0.309508
0.499987
0.187594
0.558913
0.903246
0.317901
-0.809797
2
1.128248
1.516826
-0.186735
-0.668157
1.132259
-0.246648
-0.855167
0.732283
0.931802
1.318684
-1.198418
-1.149318
0.586321
-1.171937
-0.607731
2.753747
1.479287
-1.136365
-0.020485
0.320444
-1.955755
0.660402
-1.545371
0.200519
-0.017263
1.634686
0.599246
0.462989
0.023721
0.225546
вызывается при наличии
-0.027496
-0.061233
-0.566411
-0.669567
0.601618
0.503656
-0.678253
-2.907108
-1.717123
0.397631
1.300108
0.215821
-0.593075
-0.225944
-0.946057
1.000308
0.393160
1.342074
-0.370687
-0.166413
-0.419814
-0.255931
1.789478
0.282378
0.742260
-0.050498
1.415309
0.838166
-1.400292
-0.937976
-1.499148
0.801859
0.224824
0.283572
0.643703
-1.198465
0.527206
0.215202
0.437048
1.312868
0.741243
0.077988
0.006123
0.190370
0.018007
-1.026036
-2.378430
-1.069949
0.843822
1.289216
-1.423369
-0.462887
0.197330
-0.935076
0.441271
0.414643
-0.377887
-0.530515
0.621592
1.009572
0.569718
0.175291
-0.656279
-0.112273
-0.392137
-1.043558
-0.467318
-0.384329
-2.009207
3
0.658598
0.101830
-0.682781
0.229349
-0.305657
0.404877
0.252244
-0.837784
-0.039624
0.329457
0.751694
1.469070
-0.157199
1.032628
-0.584639
-0.925544
0.342474
-0.969363
0.133480
-0.385974
-0.600278
0.281939
0.868579
1.129803
-0.041898
0.961193
0.131521
-0.792889
-1.285737
0.073934
-1.333315
-1.044125
1.277338
1.492257
0.411379
1.771805
-1.111128
1.123233
-1.019449
1.738357
-0.690764
-0.120710
-0.421359
-0.727294
-0.857759
-0.069436
-0.328334
-0.558180
1.063474
-0.519133
-0.496902
1.089589
-1.615801
0.080174
-0.229938
-0.498420
-0.624615
0.059481
-0.093158
-1.784549
-0.503789
-0.140528
0.002653
-0.484930
0.055914
-0.680948
-0.994271
1.277052
0.037651
2.155421
-0.437589
0.696404
0.417752
-0.544785
1.190690
0.978262
0.752102
0.504472
0.139853
-0.505089
GH 43223
-1.603194
0.731847
0.010903
-1.165346
-0.125195
-1.032685
-0.465520
1.514808
0.304762
0.793414
0.314635
-1.638279
0.111737
-0.777037
0.251783
1.126303
-0.808798
0.422064
-0.349264
B
0
0
-0.356362
-0.089227
0.609373
0.542382
-0.768681
-0.048074
2.015458
-1.552351
0.251552
1.459635
0.949707
0.339465
-0.001372
1.798589
1.559163
0.231783
0.423141
-0.310530
0.353795
2.173336
-0.196247
-0.375636
-0.858221
0.258410
0.656430
0.960819
1.137893
1.553405
0.038981
-0.632038
-0.132009
-1.834997
-0.242576
-0.297879
-0.441559
-0.769691
0.224077
-0.153009
0.519526
-0.680188
0.535851
0.671496
-0.183064
0.301234
1.288256
-2.478240
-0.360403
0.424067
-0.834659
-0.128464
-0.489013
-0.014888
-1.461230
-1.435223
-1.319802
1.083675
0.979140
-0.375291
1.110189
-1.011351
0.587886
-0.822775
-1.183865
1.455173
1.134328
0.239403
-0.837991
-1.130932
0.783168
1.845520
1.437072
-1.198443
1.379098
2.129113
0.260096
-0.011975
0.043302
0.722941
1.028152
-0.235806
1.145245
-1.359598
0.232189
0.503712
-0.614264
-0.530606
-2.435803
-0.255238
-0.064423
0.784643
0.256346
0.128023
1.414103
-1.118659
0.877353
0.500561
0.463651
-2.034512
-0.981683
-0.691944
1
-1.113376
-1.169402
0.680539
-1.534212
1.653817
-1.295181
-0.566826
0.477014
1.413371
0.517105
1.401153
-0.872685
0.830957
0.181507
-0.145616
0.694592
-0.751208
0.324444
0.681973
-0.054972
0.917776
-1.024810
-0.206446
-0.600113
0.852805
1.455109
-0.079769
0.076076
0.207699
-1.850458
-0.124124
-0.610871
-0.883362
0.219049
-0.685094
-0.645330
-0.242805
-0.775602
0.233070
2.422642
-1.423040
-0.582421
0.968304
-0.701025
-0.167850
0.277264
1.301231
0.301205
-3.081249
-0.562868
0.192944
-0.664592
0.565686
0.190913
-0.841858
-1.856545
-1.022777
1.295968
0.451921
0.659955
0.065818
-0.319586
0.253495
-1.144646
-0.483404
0.555902
0.807069
0.714196
0.661196
0.053667
0.346833
-1.288977
-0.386734
-1.262127
0.477495
-0.494034
-0.911414
1.152963
-0.342365
-0.160187
0.470054
-0.853063
-1.387949
-0.257257
-1.030690
-0.110210
0.328911
-0.555923
0.987713
-0.501957
2.069887
-0.067503
0.316029
-1.506232
2.201621
0.492097
-0.085193
-0.977822
1.039147
-0.653932
2
-0.405638
-1.402027
-1.166242
1.306184
0.856283
-1.236170
-0.646721
-1.474064
0.082960
0.090310
-0.169977
0.406345
0.915427
-0.974503
0.271637
1.539184
-0.098866
-0.525149
1.063933
0.085827
-0.129622
0.947959
-0.072496
-0.237592
0.012549
1.065761
0.996596
-0.172481
2.583139
-0.028578
-0.254856
1.328794
-1.592951
2.434350
-0.341500
-0.307719
-1.333273
-1.100845
0.209097
1.734777
0.639632
0.424779
-0.129327
0.905029
-0.482909
1.731628
-2.783425
-0.333677
-0.110895
1.212636
-0.208412
0.427117
1.348563
0.043859
1.772519
-1.416106
0.401155
0.807157
0.303427
-1.246288
0.178774
-0.066126
-1.862288
1.241295
0.377021
-0.822320
-0.749014
1.463652
1.602268
-1.043877
1.185290
-0.565783
-1.076879
1.360241
-0.121991
0.991043
1.007952
0.450185
-0.744376
1.388876
-0.316847
-0.841655
-1.056842
-0.500226
0.096959
1.176896
-2.939652
1.792213
0.316340
0.303218
1.024967
-0.590871
-0.453326
-0.795981
-0.393301
-0.374372
-1.270199
1.618372
1.197727
-0.914863
3
-0.625210
0.288911
0.288374
-1.372667
-0.591395
-0.478942
1.335664
-0.459855
-1.615975
-1.189676
0.374767
-2.488733
0.586656
-1.422008
0.496030
1.911128
-0.560660
-0.499614
-0.372171
-1.833069
0.237124
-0.944446
0.912140
0.359790
-1.359235
0.166966
-0.047107
-0.279789
-0.594454
-0.739013
-1.527645
0.401668
1.791252
GH 51076
0.523873
2.207585
0.488999
-0.339283
0.131711
0.018409
1.186551
-0.424318
1.554994
-0.205917
-0.934975
0.654102
-1.227761
-0.461025
-0.421201
-0.058615
-0.584563
0.336913
-0.477102
-1.381463
0.757745
-0.268968
0.034870
1.231686
0.236600
1.234720
-0.040247
0.029582
1.034905
0.380204
-0.012108
-0.859511
-0.990340
-1.205172
-1.030178
0.426676
0.497796
-0.876808
0.957963
0.173016
0.131612
-1.003556
-1.069908
-1.799207
1.429598
-0.116015
-1.454980
0.261917
0.444412
0.273290
0.844115
0.218745
-1.033350
-1.188295
0.058373
0.800523
-1.627068
0.861651
0.871018
-0.003733
-0.243354
0.947296
0.509406
0.044546
0.266896
1.337165
1
0
0.699142
-1.928033
0.105363
1.042322
0.715206
-0.763783
0.098798
-1.157898
0.134105
0.042041
0.674826
0.165649
-1.622970
-3.131274
0.597649
-1.880331
0.663980
-0.256033
-1.524058
0.492799
0.221163
0.429622
-0.659584
1.264506
-0.032131
-2.114907
-0.264043
0.457835
-0.676837
-0.629003
0.489145
-0.551686
0.942622
-0.512043
-0.455893
0.021244
-0.178035
-2.498073
-0.171292
0.323510
-0.545163
-0.668909
-0.150031
0.521620
-0.428980
0.676463
0.369081
-0.724832
0.793542
1.237422
0.401275
2.141523
0.249012
0.486755
-0.163274
0.592222
-0.292600
-0.547168
0.619104
-0.013605
0.776734
0.131424
1.189480
-0.666317
-0.939036
1.105515
0.621452
1.586605
-0.760970
1.649646
0.283199
1.275812
-0.452012
0.301361
-0.976951
-0.268106
-0.079255
-1.258332
2.216658
-1.175988
-0.863497
-1.653022
-0.561514
0.450753
0.417200
0.094676
-2.231054
1.316862
-0.477441
0.646654
-0.200252
1.074354
-0.058176
0.120990
0.222522
-0.179507
0.421655
-0.914341
-0.234178
0.741524
1
0.932714
1.423761
-1.280835
0.347882
-0.863171
-0.852580
1.044933
2.094536
0.806206
0.416201
-1.109503
0.145302
-0.996871
0.325456
-0.605081
1.175326
1.645054
0.293432
-2.766822
1.032849
0.079115
-1.414132
1.463376
2.335486
0.411951
-0.048543
0.159284
-0.651554
-1.093128
1.568390
-0.077807
-2.390779
-0.842346
-0.229675
-0.999072
-1.367219
-0.792042
-1.878575
1.451452
1.266250
-0.734315
0.266152
0.735523
-0.430860
0.229864
0.850083
-2.241241
1.063850
0.289409
-0.354360
0.113063
-0.173006
1.386998
1.886236
0.587119
-0.961133
0.399295
1.461560
0.310823
0.280220
-0.879103
-1.326348
0.003337
-1.085908
-0.436723
2.111926
0.106068
0.615597
2.152996
-0.196155
0.025747
-0.039061
0.656823
-0.347105
2.513979
1.758070
1.288473
-0.739185
-0.691592
-0.098728
-0.276386
0.489981
0.516278
-0.838258
0.596673
-0.331053
0.521174
-0.145023
0.836693
-1.092166
0.361733
-1.169981
0.046731
0.655377
-0.756852
1.285805
-0.095019
0.360253
1.370621
0.083010
2
0.888893
2.288725
-1.032332
0.212273
-1.091826
1.692498
1.025367
0.550854
0.679430
-1.335712
-0.798341
2.265351
-1.006938
2.059761
0.420266
-1.189657
0.506674
0.260847
-0.533145
0.727267
1.412276
1.482106
-0.996258
0.588641
-0.412642
-0.920733
-0.874691
0.839002
0.501668
-0.342493
-0.533806
-2.146352
-0.597339
0.115726
0.850683
-0.752239
0.377263
-0.561982
0.262783
-0.356676
-0.367462
0.753611
-1.267414
-1.330698
-0.536453
0.840938
-0.763108
-0.268100
-0.677424
1.606831
0.151732
-2.085701
1.219296
0.400863
0.591165
-1.485213
1.501979
1.196569
-0.214154
0.339554
-0.034446
1.176452
0.546340
-1.255630
-1.309210
-0.445437
0.189437
-0.737463
0.843767
-0.605632
-0.060777
0.409310
1.285569
-0.622638
1.018193
0.880680
0.046805
-1.818058
-0.809829
0.875224
0.409569
-0.116621
-1.238919
3.305724
-0.024121
-1.756500
1.328958
0.507593
-0.866554
-2.240848
-0.661376
-0.671824
0.215720
-0.296326
0.481402
0.829645
-0.721025
1.263914
0.549047
-1.234945
3
-1.978838
0.721823
-0.559067
-1.235243
0.420716
-0.598845
0.359576
-0.619366
-1.757772
-1.156251
0.705212
0.875071
-1.020376
0.394760
-0.147970
0.230249
1.355203
1.794488
2.678058
-0.153565
-0.460959
-0.098108
-1.407930
-2.487702
1.823014
0.099873
-0.517603
-0.509311
-1.833175
-0.900906
0.459493
-0.655440
1.466122
-1.531389
-0.422106
0.421422
0.578615
0.259795
0.018941
-0.168726
1.611107
-1.586550
-1.384941
0.858377
1.033242
1.701343
1.748344
-0.371182
-0.843575
2.089641
-0.345430
-1.740556
0.141915
-2.197138
0.689569
-0.150025
0.287456
0.654016
-1.521919
-0.918008
-0.587528
0.230636
0.262637
0.615674
0.600044
-0.494699
-0.743089
0.220026
-0.242207
0.528216
-0.328174
-1.536517
-1.476640
-1.162114
-1.260222
1.106252
-1.467408
-0.349341
-1.841217
0.031296
-0.076475
-0.353383
0.807545
0.779064
-2.398417
-0.267828
1.549734
0.814397
0.284770
-0.659369
0.761040
-0.722067
0.810332
1.501295
1.440865
-1.367459
-0.700301
-1.540662
0.159837
-0.625415
Экранирование HTML#
escape параметр форматирования для обработки этого, и даже использование его в форматтере, который сам содержит HTML.[67]:
df4 = pd.DataFrame([['', '"&other"', '']])
df4.style
[67]:
0
1
2
0
"&other"
[68]:
df4.style.format(escape="html")
[68]:
0
1
2
0
"&other"
[69]:
0
1
2
0
"&other"
Экспорт в Excel#
DataFrames в листы Excel с помощью OpenPyXL или XlsxWriter движками. Обрабатываемые свойства CSS2.2 включают:
background-colorborder-style свойствborder-width свойствborder-color свойствcolorfont-familyfont-stylefont-weighttext-aligntext-decorationvertical-alignwhite-space: nowrapborder-style и border-left-style) а также border сокращения для всех сторон (border: 1px solid green) или указанные стороны (border-left: 1px solid green). Используя border сокращение переопределит любые свойства границ, установленные ранее (см. CSS Working Group для получения дополнительных сведений)#rgb или #rrggbb в настоящее время поддерживаются.
number-formatborder-style (для Excel-специфичных стилей: "hair", "mediumDashDot", "dashDotDot", "mediumDashDotDot", "dashDot", "slantDashDot" или "mediumDashed")Styler.apply и/или Styler.map методы.[70]:
df2.style.\
map(style_negative, props='color:red;').\
highlight_max(axis=0).\
to_excel('styled.xlsx', engine='openpyxl')
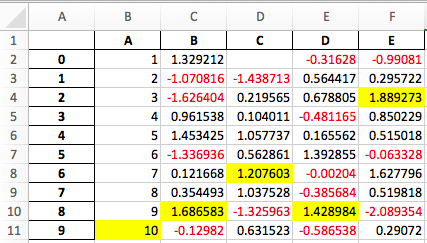
Экспорт в LaTeX#
Styler в LaTeX. Документация для .to_latex метод предоставляет дополнительные детали и многочисленные примеры.Подробнее о CSS и HTML#
Styler создает HTML и взаимодействует с CSS, с советами по избежанию распространенных ошибок.CSS-классы и идентификаторы#
class прикреплённый к каждой ячейке, выглядит следующим образом.
index_name и level где k является его уровнем в MultiIndex
row_headinglevel где k это уровень в MultiIndexrow где m является числовой позицией строки
col_headinglevel где k это уровень в MultiIndexcol где n это числовая позиция столбца
datarow, где m это числовая позиция ячейки.col, где n это числовая позиция ячейки.blankcol_trim или row_trimid является T_uuid_level где level используется только для заголовков, и заголовки будут иметь только либо row или col в зависимости от необходимости. По умолчанию мы также добавили к каждому идентификатору строки/столбца UUID, уникальный для каждого DataFrame, чтобы стили одного не конфликтовали со стилями другого в пределах одной записной книжки или страницы. Вы можете узнать больше об использовании UUID в Оптимизация.[71]:
print(pd.DataFrame([[1,2],[3,4]], index=['i1', 'i2'], columns=['c1', 'c2']).style.to_html())
c1
c2
i1
1
2
i2
3
4
CSS Иерархии#
[72]:
df4 = pd.DataFrame([['text']])
df4.style.map(lambda x: 'color:green;')\
.map(lambda x: 'color:red;')
[72]:
0
0
текст
[73]:
df4.style.map(lambda x: 'color:red;')\
.map(lambda x: 'color:green;')
[73]:
0
0
текст
[74]:
df4.style.set_uuid('a_')\
.set_table_styles([{'selector': 'td', 'props': 'color:red;'}])\
.map(lambda x: 'color:green;')
[74]:
0
0
текст
#T_a_ td составляет 101 (ID плюс элемент), тогда как #T_a_row0_col0 стоит всего 100 (ID), поэтому считается менее значимым, даже несмотря на то, что в HTML он идет после предыдущего.[75]:
df4.style.set_uuid('b_')\
.set_table_styles([{'selector': 'td', 'props': 'color:red;'},
{'selector': '.cls-1', 'props': 'color:blue;'}])\
.map(lambda x: 'color:green;')\
.set_td_classes(pd.DataFrame([['cls-1']]))
[75]:
0
0
текст
#T_b_ .cls-1 стоит 110 (ID плюс класс), что имеет приоритет.[76]:
df4.style.set_uuid('c_')\
.set_table_styles([{'selector': 'td', 'props': 'color:red;'},
{'selector': '.cls-1', 'props': 'color:blue;'},
{'selector': 'td.data', 'props': 'color:yellow;'}])\
.map(lambda x: 'color:green;')\
.set_td_classes(pd.DataFrame([['cls-1']]))
[76]:
0
0
текст
T_c_ td.data (ID плюс элемент плюс класс) увеличивается до 111.!important козырная карта.[77]:
df4.style.set_uuid('d_')\
.set_table_styles([{'selector': 'td', 'props': 'color:red;'},
{'selector': '.cls-1', 'props': 'color:blue;'},
{'selector': 'td.data', 'props': 'color:yellow;'}])\
.map(lambda x: 'color:green !important;')\
.set_td_classes(pd.DataFrame([['cls-1']]))
[77]:
0
0
текст
Расширяемость#
DataFrame.style достигает двух целей
Создание подклассов#
[78]:
from jinja2 import Environment, ChoiceLoader, FileSystemLoader
from IPython.display import HTML
from pandas.io.formats.style import Styler
[79]:
with open("templates/myhtml.tpl") as f:
print(f.read())
{% extends "html_table.tpl" %}
{% block table %}
{{ table_title|default("My Table") }}
{{ super() }}
{% endblock table %}
Styler который знает об этом.[80]:
class MyStyler(Styler):
env = Environment(
loader=ChoiceLoader([
FileSystemLoader("templates"), # contains ours
Styler.loader, # the default
])
)
template_html_table = env.get_template("myhtml.tpl")
__init__ принимает DataFrame.[81]:
MyStyler(df3)
[81]:
Моя таблица
c1
c2
c3
c4
A
r1
-1.048553
-1.420018
-1.706270
1.950775
r2
-0.509652
-0.438074
-1.252795
0.777490
B
r1
-1.613898
-0.212740
-0.895467
0.386902
r2
-0.510805
-1.180632
-0.028182
0.428332
table_title ключевое слово. Мы можем предоставить значение в .to_html метод.[82]:
HTML(MyStyler(df3).to_html(table_title="Extending Example"))
[82]:
Пример расширения
c1
c2
c3
c4
A
r1
-1.048553
-1.420018
-1.706270
1.950775
r2
-0.509652
-0.438074
-1.252795
0.777490
B
r1
-1.613898
-0.212740
-0.895467
0.386902
r2
-0.510805
-1.180632
-0.028182
0.428332
Styler.from_custom_template метод, который делает то же самое, что и пользовательский подкласс.[83]:
EasyStyler = Styler.from_custom_template("templates", "myhtml.tpl")
HTML(EasyStyler(df3).to_html(table_title="Another Title"))
[83]:
Другой заголовок
c1
c2
c3
c4
A
r1
-1.048553
-1.420018
-1.706270
1.950775
r2
-0.509652
-0.438074
-1.252795
0.777490
B
r1
-1.613898
-0.212740
-0.895467
0.386902
r2
-0.510805
-1.180632
-0.028182
0.428332
Структура шаблона#
[85]:
HTML(style_structure)
[85]:
[87]:
HTML(table_structure)
[87]: