Индексирование и выбор данных#
Информация о метках осей в объектах pandas служит многим целям:
Идентифицирует данные (т.е. предоставляет метаданные) с использованием известных индикаторов, важно для анализа, визуализации и интерактивного отображения в консоли.
Включает автоматическое и явное выравнивание данных.
Позволяет интуитивно получать и устанавливать подмножества набора данных.
В этом разделе мы сосредоточимся на последнем пункте: а именно, как выполнять срезы, нарезку и в целом получать и устанавливать подмножества объектов pandas. Основное внимание будет уделено Series и DataFrame, так как в этой области они получили больше внимания разработчиков.
Примечание
Операторы индексирования Python и NumPy [] и оператор атрибута .
обеспечивает быстрый и простой доступ к структурам данных pandas в широком диапазоне
случаев использования. Это делает интерактивную работу интуитивно понятной, так как нужно изучать мало нового,
если вы уже знаете, как работать со словарями Python и массивами NumPy.
Однако, поскольку тип данных, к которым осуществляется доступ, заранее неизвестен,
прямое использование стандартных операторов имеет некоторые ограничения по оптимизации. Для
продакшн-кода мы рекомендуем использовать оптимизированные
методы доступа к данным pandas, представленные в этой главе.
Предупреждение
Будет ли возвращена копия или ссылка при операции установки, может зависеть от контекста. Это иногда называется цепное присваивание и следует избегать. См. Возврат представления (view) против копии (copy).
См. MultiIndex / Расширенное индексирование для MultiIndex и более продвинутую документацию по индексированию.
См. cookbook для некоторых продвинутых стратегий.
Различные варианты индексирования#
Выбор объектов получил ряд дополнений по запросу пользователей для поддержки более явного индексирования на основе местоположения. pandas теперь поддерживает три типа многоосевого индексирования.
.locв основном основан на метках, но также может использоваться с булевым массивом..locвызовет исключениеKeyErrorкогда элементы не найдены. Допустимые входные данные:Одна метка, например
5или'a'(Заметим, что5интерпретируется как метка индекса. Это использование не целочисленную позицию вдоль индекса.).Список или массив меток
['a', 'b', 'c'].Объект среза с метками
'a':'f'(Обратите внимание, что в отличие от обычных Python срезов, оба начало и конец включены, если присутствуют в индексе! См. Срезы с метками и Конечные точки включительно.)Логический массив (любой
NAзначения будут рассматриваться какFalse).A
callableфункция с одним аргументом (вызываемая серия или DataFrame) и которая возвращает допустимый вывод для индексирования (один из вышеперечисленных).Кортеж индексов строк (и столбцов), элементы которого являются одним из вышеуказанных входных данных.
Подробнее см. Выбор по метке.
.ilocв основном основан на целочисленной позиции (от0tolength-1оси), но также может использоваться с булевым массивом..ilocвызовет исключениеIndexErrorесли запрошенный индексатор выходит за границы, за исключением срез индексаторы, которые позволяют индексирование за пределами границ. (это соответствует Python/NumPy срез семантика). Допустимые входные данные:Целое число, например
5.Список или массив целых чисел
[4, 3, 0].Объект среза с целыми числами
1:7.Логический массив (любой
NAзначения будут рассматриваться какFalse).A
callableфункция с одним аргументом (вызываемая серия или DataFrame) и которая возвращает допустимый вывод для индексирования (один из вышеперечисленных).Кортеж индексов строк (и столбцов), элементы которого являются одним из вышеуказанных входных данных.
Подробнее см. Выбор по позиции, Расширенная индексация и Расширенная Иерархическая.
.loc,.iloc, а также[]индексирование может приниматьcallableв качестве индексатора. Подробнее см. в Выбор по вызываемому объекту.Примечание
Разбор ключей-кортежей в индексы строк (и столбцов) происходит до вызываемые объекты применяются, поэтому нельзя вернуть кортеж из вызываемого объекта для индексации строк и столбцов.
Получение значений из объекта с выбором по нескольким осям использует следующую нотацию (используя .loc в качестве примера, но следующее применимо к .iloc также). Любой из аксессоров осей может быть нулевым срезом :. Оси, не указанные в спецификации, считаются :, например, p.loc['a'] эквивалентно
p.loc['a', :].
In [1]: ser = pd.Series(range(5), index=list("abcde"))
In [2]: ser.loc[["a", "c", "e"]]
Out[2]:
a 0
c 2
e 4
dtype: int64
In [3]: df = pd.DataFrame(np.arange(25).reshape(5, 5), index=list("abcde"), columns=list("abcde"))
In [4]: df.loc[["a", "c", "e"], ["b", "d"]]
Out[4]:
b d
a 1 3
c 11 13
e 21 23
Основы#
Как упоминалось при представлении структур данных в последний раздел, основная функция индексации с [] (также известный как __getitem__
для тех, кто знаком с реализацией поведения класса в Python) — это выбор срезов меньшей размерности. Следующая таблица показывает типы возвращаемых значений при индексации объектов pandas с []:
Тип объекта |
Выбор |
Тип возвращаемого значения |
|---|---|---|
Series |
|
скалярное значение |
DataFrame |
|
|
Здесь мы создаем простой набор данных временных рядов для иллюстрации функциональности индексирования:
In [5]: dates = pd.date_range('1/1/2000', periods=8)
In [6]: df = pd.DataFrame(np.random.randn(8, 4),
...: index=dates, columns=['A', 'B', 'C', 'D'])
...:
In [7]: df
Out[7]:
A B C D
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
2000-01-04 0.721555 -0.706771 -1.039575 0.271860
2000-01-05 -0.424972 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427 0.524988
2000-01-07 0.404705 0.577046 -1.715002 -1.039268
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
Примечание
Ни одна из функций индексирования не специфична для временных рядов, если не указано иное.
Таким образом, как указано выше, у нас есть самый базовый способ индексирования с использованием []:
In [8]: s = df['A']
In [9]: s[dates[5]]
Out[9]: -0.6736897080883706
Вы можете передать список столбцов в [] для выбора столбцов в этом порядке.
Если столбец не содержится в DataFrame, будет вызвано исключение.
Несколько столбцов также можно установить таким образом:
In [10]: df
Out[10]:
A B C D
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
2000-01-04 0.721555 -0.706771 -1.039575 0.271860
2000-01-05 -0.424972 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427 0.524988
2000-01-07 0.404705 0.577046 -1.715002 -1.039268
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
In [11]: df[['B', 'A']] = df[['A', 'B']]
In [12]: df
Out[12]:
A B C D
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
2000-01-02 -0.173215 1.212112 0.119209 -1.044236
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
2000-01-04 -0.706771 0.721555 -1.039575 0.271860
2000-01-05 0.567020 -0.424972 0.276232 -1.087401
2000-01-06 0.113648 -0.673690 -1.478427 0.524988
2000-01-07 0.577046 0.404705 -1.715002 -1.039268
2000-01-08 -1.157892 -0.370647 -1.344312 0.844885
Это может быть полезно для применения преобразования (на месте) к подмножеству столбцов.
Предупреждение
pandas выравнивает все ОСИ при установке Series и DataFrame из .loc.
Это будет не изменить df поскольку выравнивание столбцов происходит перед присвоением значений.
In [13]: df[['A', 'B']]
Out[13]:
A B
2000-01-01 -0.282863 0.469112
2000-01-02 -0.173215 1.212112
2000-01-03 -2.104569 -0.861849
2000-01-04 -0.706771 0.721555
2000-01-05 0.567020 -0.424972
2000-01-06 0.113648 -0.673690
2000-01-07 0.577046 0.404705
2000-01-08 -1.157892 -0.370647
In [14]: df.loc[:, ['B', 'A']] = df[['A', 'B']]
In [15]: df[['A', 'B']]
Out[15]:
A B
2000-01-01 -0.282863 0.469112
2000-01-02 -0.173215 1.212112
2000-01-03 -2.104569 -0.861849
2000-01-04 -0.706771 0.721555
2000-01-05 0.567020 -0.424972
2000-01-06 0.113648 -0.673690
2000-01-07 0.577046 0.404705
2000-01-08 -1.157892 -0.370647
Правильный способ поменять значения столбцов — использовать исходные значения:
In [16]: df.loc[:, ['B', 'A']] = df[['A', 'B']].to_numpy()
In [17]: df[['A', 'B']]
Out[17]:
A B
2000-01-01 0.469112 -0.282863
2000-01-02 1.212112 -0.173215
2000-01-03 -0.861849 -2.104569
2000-01-04 0.721555 -0.706771
2000-01-05 -0.424972 0.567020
2000-01-06 -0.673690 0.113648
2000-01-07 0.404705 0.577046
2000-01-08 -0.370647 -1.157892
Однако pandas не выравнивает оси при установке Series и DataFrame из .iloc
потому что .iloc работает по позиции.
Это изменит df поскольку выравнивание столбцов не выполняется перед присвоением значений.
In [18]: df[['A', 'B']]
Out[18]:
A B
2000-01-01 0.469112 -0.282863
2000-01-02 1.212112 -0.173215
2000-01-03 -0.861849 -2.104569
2000-01-04 0.721555 -0.706771
2000-01-05 -0.424972 0.567020
2000-01-06 -0.673690 0.113648
2000-01-07 0.404705 0.577046
2000-01-08 -0.370647 -1.157892
In [19]: df.iloc[:, [1, 0]] = df[['A', 'B']]
In [20]: df[['A','B']]
Out[20]:
A B
2000-01-01 -0.282863 0.469112
2000-01-02 -0.173215 1.212112
2000-01-03 -2.104569 -0.861849
2000-01-04 -0.706771 0.721555
2000-01-05 0.567020 -0.424972
2000-01-06 0.113648 -0.673690
2000-01-07 0.577046 0.404705
2000-01-08 -1.157892 -0.370647
Доступ к атрибутам#
Вы можете получить доступ к индексу на Series или столбец на DataFrame непосредственно
как атрибут:
In [21]: sa = pd.Series([1, 2, 3], index=list('abc'))
In [22]: dfa = df.copy()
In [23]: sa.b
Out[23]: 2
In [24]: dfa.A
Out[24]:
2000-01-01 -0.282863
2000-01-02 -0.173215
2000-01-03 -2.104569
2000-01-04 -0.706771
2000-01-05 0.567020
2000-01-06 0.113648
2000-01-07 0.577046
2000-01-08 -1.157892
Freq: D, Name: A, dtype: float64
In [25]: sa.a = 5
In [26]: sa
Out[26]:
a 5
b 2
c 3
dtype: int64
In [27]: dfa.A = list(range(len(dfa.index))) # ok if A already exists
In [28]: dfa
Out[28]:
A B C D
2000-01-01 0 0.469112 -1.509059 -1.135632
2000-01-02 1 1.212112 0.119209 -1.044236
2000-01-03 2 -0.861849 -0.494929 1.071804
2000-01-04 3 0.721555 -1.039575 0.271860
2000-01-05 4 -0.424972 0.276232 -1.087401
2000-01-06 5 -0.673690 -1.478427 0.524988
2000-01-07 6 0.404705 -1.715002 -1.039268
2000-01-08 7 -0.370647 -1.344312 0.844885
In [29]: dfa['A'] = list(range(len(dfa.index))) # use this form to create a new column
In [30]: dfa
Out[30]:
A B C D
2000-01-01 0 0.469112 -1.509059 -1.135632
2000-01-02 1 1.212112 0.119209 -1.044236
2000-01-03 2 -0.861849 -0.494929 1.071804
2000-01-04 3 0.721555 -1.039575 0.271860
2000-01-05 4 -0.424972 0.276232 -1.087401
2000-01-06 5 -0.673690 -1.478427 0.524988
2000-01-07 6 0.404705 -1.715002 -1.039268
2000-01-08 7 -0.370647 -1.344312 0.844885
Предупреждение
Вы можете использовать этот доступ только если элемент индекса является допустимым идентификатором Python, например.
s.1не разрешено. См. здесь для объяснения допустимых идентификаторов.Атрибут не будет доступен, если он конфликтует с существующим именем метода, например,
s.minне разрешено, ноs['min']возможно.Аналогично, атрибут не будет доступен, если он конфликтует с любым из следующего списка:
index,major_axis,minor_axis,items.В любом из этих случаев стандартная индексация будет работать, например.
s['1'],s['min'], иs['index']будет обращаться к соответствующему элементу или столбцу.
Если вы используете среду IPython, вы также можете использовать автодополнение с помощью клавиши Tab, чтобы увидеть эти доступные атрибуты.
Вы также можете назначить dict в строку DataFrame:
In [31]: x = pd.DataFrame({'x': [1, 2, 3], 'y': [3, 4, 5]})
In [32]: x.iloc[1] = {'x': 9, 'y': 99}
In [33]: x
Out[33]:
x y
0 1 3
1 9 99
2 3 5
Вы можете использовать доступ к атрибутам для изменения существующего элемента Series или столбца DataFrame, но будьте осторожны; если вы попытаетесь использовать доступ к атрибутам для создания нового столбца, это создаст новый атрибут, а не новый столбец, и это вызовет UserWarning:
In [34]: df_new = pd.DataFrame({'one': [1., 2., 3.]})
In [35]: df_new.two = [4, 5, 6]
In [36]: df_new
Out[36]:
one
0 1.0
1 2.0
2 3.0
Диапазоны срезов#
Наиболее надежный и последовательный способ среза диапазонов вдоль произвольных осей
описан в Выбор по позиции раздел,
подробно описывающий .iloc метод. Пока мы объясняем семантику нарезки с использованием [] оператор.
С Series синтаксис работает точно так же, как с ndarray, возвращая срез значений и соответствующие метки:
In [37]: s[:5]
Out[37]:
2000-01-01 0.469112
2000-01-02 1.212112
2000-01-03 -0.861849
2000-01-04 0.721555
2000-01-05 -0.424972
Freq: D, Name: A, dtype: float64
In [38]: s[::2]
Out[38]:
2000-01-01 0.469112
2000-01-03 -0.861849
2000-01-05 -0.424972
2000-01-07 0.404705
Freq: 2D, Name: A, dtype: float64
In [39]: s[::-1]
Out[39]:
2000-01-08 -0.370647
2000-01-07 0.404705
2000-01-06 -0.673690
2000-01-05 -0.424972
2000-01-04 0.721555
2000-01-03 -0.861849
2000-01-02 1.212112
2000-01-01 0.469112
Freq: -1D, Name: A, dtype: float64
Обратите внимание, что настройка также работает:
In [40]: s2 = s.copy()
In [41]: s2[:5] = 0
In [42]: s2
Out[42]:
2000-01-01 0.000000
2000-01-02 0.000000
2000-01-03 0.000000
2000-01-04 0.000000
2000-01-05 0.000000
2000-01-06 -0.673690
2000-01-07 0.404705
2000-01-08 -0.370647
Freq: D, Name: A, dtype: float64
С DataFrame, срез внутри [] срезы строк. Это предоставлено
в основном для удобства, так как это очень распространенная операция.
In [43]: df[:3]
Out[43]:
A B C D
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
2000-01-02 -0.173215 1.212112 0.119209 -1.044236
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
In [44]: df[::-1]
Out[44]:
A B C D
2000-01-08 -1.157892 -0.370647 -1.344312 0.844885
2000-01-07 0.577046 0.404705 -1.715002 -1.039268
2000-01-06 0.113648 -0.673690 -1.478427 0.524988
2000-01-05 0.567020 -0.424972 0.276232 -1.087401
2000-01-04 -0.706771 0.721555 -1.039575 0.271860
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
2000-01-02 -0.173215 1.212112 0.119209 -1.044236
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
Выбор по метке#
Предупреждение
Возвращается ли копия или ссылка при операции установки, может зависеть от контекста. Это иногда называется chained assignment и этого следует избегать.
См. Возврат представления (view) против копии (copy).
Предупреждение
.locявляется строгим при использовании срезов, несовместимых (или неконвертируемых) с типом индекса. Например, использование целых чисел вDatetimeIndex. Они вызовутTypeError.In [45]: dfl = pd.DataFrame(np.random.randn(5, 4), ....: columns=list('ABCD'), ....: index=pd.date_range('20130101', periods=5)) ....: In [46]: dfl Out[46]: A B C D 2013-01-01 1.075770 -0.109050 1.643563 -1.469388 2013-01-02 0.357021 -0.674600 -1.776904 -0.968914 2013-01-03 -1.294524 0.413738 0.276662 -0.472035 2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061 2013-01-05 0.895717 0.805244 -1.206412 2.565646 In [47]: dfl.loc[2:3] --------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[47], line 1 ----> 1 dfl.loc[2:3] File ~/work/pandas/pandas/pandas/core/indexing.py:1192, in _LocationIndexer.__getitem__(self, key) 1190 maybe_callable = com.apply_if_callable(key, self.obj) 1191 maybe_callable = self._check_deprecated_callable_usage(key, maybe_callable) -> 1192 return self._getitem_axis(maybe_callable, axis=axis) File ~/work/pandas/pandas/pandas/core/indexing.py:1412, in _LocIndexer._getitem_axis(self, key, axis) 1410 if isinstance(key, slice): 1411 self._validate_key(key, axis) -> 1412 return self._get_slice_axis(key, axis=axis) 1413 elif com.is_bool_indexer(key): 1414 return self._getbool_axis(key, axis=axis) File ~/work/pandas/pandas/pandas/core/indexing.py:1444, in _LocIndexer._get_slice_axis(self, slice_obj, axis) 1441 return obj.copy(deep=False) 1443 labels = obj._get_axis(axis) -> 1444 indexer = labels.slice_indexer(slice_obj.start, slice_obj.stop, slice_obj.step) 1446 if isinstance(indexer, slice): 1447 return self.obj._slice(indexer, axis=axis) File ~/work/pandas/pandas/pandas/core/indexes/datetimes.py:682, in DatetimeIndex.slice_indexer(self, start, end, step) 674 # GH#33146 if start and end are combinations of str and None and Index is not 675 # monotonic, we can not use Index.slice_indexer because it does not honor the 676 # actual elements, is only searching for start and end 677 if ( 678 check_str_or_none(start) 679 or check_str_or_none(end) 680 or self.is_monotonic_increasing 681 ): --> 682 return Index.slice_indexer(self, start, end, step) 684 mask = np.array(True) 685 in_index = True File ~/work/pandas/pandas/pandas/core/indexes/base.py:6708, in Index.slice_indexer(self, start, end, step) 6664 def slice_indexer( 6665 self, 6666 start: Hashable | None = None, 6667 end: Hashable | None = None, 6668 step: int | None = None, 6669 ) -> slice: 6670 """ 6671 Compute the slice indexer for input labels and step. 6672 (...) 6706 slice(1, 3, None) 6707 """ -> 6708 start_slice, end_slice = self.slice_locs(start, end, step=step) 6710 # return a slice 6711 if not is_scalar(start_slice): File ~/work/pandas/pandas/pandas/core/indexes/base.py:6934, in Index.slice_locs(self, start, end, step) 6932 start_slice = None 6933 if start is not None: -> 6934 start_slice = self.get_slice_bound(start, "left") 6935 if start_slice is None: 6936 start_slice = 0 File ~/work/pandas/pandas/pandas/core/indexes/base.py:6849, in Index.get_slice_bound(self, label, side) 6845 original_label = label 6847 # For datetime indices label may be a string that has to be converted 6848 # to datetime boundary according to its resolution. -> 6849 label = self._maybe_cast_slice_bound(label, side) 6851 # we need to look up the label 6852 try: File ~/work/pandas/pandas/pandas/core/indexes/datetimes.py:642, in DatetimeIndex._maybe_cast_slice_bound(self, label, side) 637 if isinstance(label, dt.date) and not isinstance(label, dt.datetime): 638 # Pandas supports slicing with dates, treated as datetimes at midnight. 639 # https://github.com/pandas-dev/pandas/issues/31501 640 label = Timestamp(label).to_pydatetime() --> 642 label = super()._maybe_cast_slice_bound(label, side) 643 self._data._assert_tzawareness_compat(label) 644 return Timestamp(label) File ~/work/pandas/pandas/pandas/core/indexes/datetimelike.py:378, in DatetimeIndexOpsMixin._maybe_cast_slice_bound(self, label, side) 376 return lower if side == "left" else upper 377 elif not isinstance(label, self._data._recognized_scalars): --> 378 self._raise_invalid_indexer("slice", label) 380 return label File ~/work/pandas/pandas/pandas/core/indexes/base.py:4308, in Index._raise_invalid_indexer(self, form, key, reraise) 4306 if reraise is not lib.no_default: 4307 raise TypeError(msg) from reraise -> 4308 raise TypeError(msg) TypeError: cannot do slice indexing on DatetimeIndex with these indexers [2] of type int
Строковые значения при срезе может должны быть преобразуемы к типу индекса и приводить к естественному срезу.
In [48]: dfl.loc['20130102':'20130104']
Out[48]:
A B C D
2013-01-02 0.357021 -0.674600 -1.776904 -0.968914
2013-01-03 -1.294524 0.413738 0.276662 -0.472035
2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061
pandas предоставляет набор методов для того, чтобы чисто меточное индексирование. Это строгий протокол включения.
Каждая запрошенная метка должна быть в индексе, или KeyError будет вызвано.
При срезе, как начальная граница AND верхняя граница включен, если присутствует в индексе.
Целые числа являются допустимыми метками, но они относятся к метке а не позиция.
The .loc атрибут является основным методом доступа. Допустимые входные данные:
Одна метка, например
5или'a'(Заметим, что5интерпретируется как метка индекса. Это использование не целочисленная позиция вдоль индекса.).Список или массив меток
['a', 'b', 'c'].Объект среза с метками
'a':'f'(Обратите внимание, что в отличие от обычных Python срезов, оба начало и конец включены, если присутствуют в индексе! См. Срезы с метками.Булев массив.
A
callable, см. Выбор по вызываемому объекту.
In [49]: s1 = pd.Series(np.random.randn(6), index=list('abcdef'))
In [50]: s1
Out[50]:
a 1.431256
b 1.340309
c -1.170299
d -0.226169
e 0.410835
f 0.813850
dtype: float64
In [51]: s1.loc['c':]
Out[51]:
c -1.170299
d -0.226169
e 0.410835
f 0.813850
dtype: float64
In [52]: s1.loc['b']
Out[52]: 1.3403088497993827
Обратите внимание, что настройка также работает:
In [53]: s1.loc['c':] = 0
In [54]: s1
Out[54]:
a 1.431256
b 1.340309
c 0.000000
d 0.000000
e 0.000000
f 0.000000
dtype: float64
С DataFrame:
In [55]: df1 = pd.DataFrame(np.random.randn(6, 4),
....: index=list('abcdef'),
....: columns=list('ABCD'))
....:
In [56]: df1
Out[56]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
b 1.130127 -1.436737 -1.413681 1.607920
c 1.024180 0.569605 0.875906 -2.211372
d 0.974466 -2.006747 -0.410001 -0.078638
e 0.545952 -1.219217 -1.226825 0.769804
f -1.281247 -0.727707 -0.121306 -0.097883
In [57]: df1.loc[['a', 'b', 'd'], :]
Out[57]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
b 1.130127 -1.436737 -1.413681 1.607920
d 0.974466 -2.006747 -0.410001 -0.078638
Доступ через срезы по меткам:
In [58]: df1.loc['d':, 'A':'C']
Out[58]:
A B C
d 0.974466 -2.006747 -0.410001
e 0.545952 -1.219217 -1.226825
f -1.281247 -0.727707 -0.121306
Для получения поперечного сечения с использованием метки (эквивалентно df.xs('a')):
In [59]: df1.loc['a']
Out[59]:
A 0.132003
B -0.827317
C -0.076467
D -1.187678
Name: a, dtype: float64
Для получения значений с помощью булевого массива:
In [60]: df1.loc['a'] > 0
Out[60]:
A True
B False
C False
D False
Name: a, dtype: bool
In [61]: df1.loc[:, df1.loc['a'] > 0]
Out[61]:
A
a 0.132003
b 1.130127
c 1.024180
d 0.974466
e 0.545952
f -1.281247
Значения NA в булевом массиве распространяются как False:
In [62]: mask = pd.array([True, False, True, False, pd.NA, False], dtype="boolean")
In [63]: mask
Out[63]:
, False]
Length: 6, dtype: boolean
In [64]: df1[mask]
Out[64]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
c 1.024180 0.569605 0.875906 -2.211372
Для явного получения значения:
# this is also equivalent to ``df1.at['a','A']``
In [65]: df1.loc['a', 'A']
Out[65]: 0.13200317033032932
Срезы с метками#
При использовании .loc со срезами, если обе метки начала и конца
присутствуют в индексе, то элементы расположен между двумя (включая их)
возвращаются:
In [66]: s = pd.Series(list('abcde'), index=[0, 3, 2, 5, 4])
In [67]: s.loc[3:5]
Out[67]:
3 b
2 c
5 d
dtype: object
Если хотя бы один из двух отсутствует, но индекс отсортирован и может быть сравнен с метками start и stop, то срез всё равно будет работать как ожидается, выбирая метки, которые rank между двумя:
In [68]: s.sort_index()
Out[68]:
0 a
2 c
3 b
4 e
5 d
dtype: object
In [69]: s.sort_index().loc[1:6]
Out[69]:
2 c
3 b
4 e
5 d
dtype: object
Однако, если хотя бы один из двух отсутствует и если индекс не отсортирован, будет
вызвана ошибка (поскольку иначе это было бы вычислительно затратно,
а также потенциально неоднозначно для индексов смешанного типа). Например, в
приведённом выше примере s.loc[1:6] вызовет KeyError.
Для обоснования этого поведения см. Конечные точки включительно.
In [70]: s = pd.Series(list('abcdef'), index=[0, 3, 2, 5, 4, 2])
In [71]: s.loc[3:5]
Out[71]:
3 b
2 c
5 d
dtype: object
Кроме того, если индекс имеет повторяющиеся метки и если либо начальная, либо конечная метка дублируется,
будет вызвана ошибка. Например, в приведенном выше примере, s.loc[2:5] вызовет KeyError.
Для получения дополнительной информации о дублирующихся метках см. Дублирующиеся метки.
Выбор по позиции#
Предупреждение
Возвращается ли копия или ссылка при операции установки, может зависеть от контекста. Это иногда называется chained assignment и этого следует избегать.
См. Возврат представления (view) против копии (copy).
pandas предоставляет набор методов для получения индексирование, основанное исключительно на целых числах. Семантика тесно следует срезам Python и NumPy. Это 0-based индексирование. При срезе начальная граница включен, в то время как верхняя граница равна исключен. Попытка использовать нецелое число, даже валидный метка вызовет IndexError.
The .iloc атрибут является основным методом доступа. Допустимые входные данные:
Целое число, например
5.Список или массив целых чисел
[4, 3, 0].Объект среза с целыми числами
1:7.Булев массив.
A
callable, см. Выбор по вызываемому объекту.Кортеж индексов строк (и столбцов), элементы которого являются одним из указанных выше типов.
In [72]: s1 = pd.Series(np.random.randn(5), index=list(range(0, 10, 2)))
In [73]: s1
Out[73]:
0 0.695775
2 0.341734
4 0.959726
6 -1.110336
8 -0.619976
dtype: float64
In [74]: s1.iloc[:3]
Out[74]:
0 0.695775
2 0.341734
4 0.959726
dtype: float64
In [75]: s1.iloc[3]
Out[75]: -1.110336102891167
Обратите внимание, что настройка также работает:
In [76]: s1.iloc[:3] = 0
In [77]: s1
Out[77]:
0 0.000000
2 0.000000
4 0.000000
6 -1.110336
8 -0.619976
dtype: float64
С DataFrame:
In [78]: df1 = pd.DataFrame(np.random.randn(6, 4),
....: index=list(range(0, 12, 2)),
....: columns=list(range(0, 8, 2)))
....:
In [79]: df1
Out[79]:
0 2 4 6
0 0.149748 -0.732339 0.687738 0.176444
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
6 -0.826591 -0.345352 1.314232 0.690579
8 0.995761 2.396780 0.014871 3.357427
10 -0.317441 -1.236269 0.896171 -0.487602
Выбор через целочисленный срез:
In [80]: df1.iloc[:3]
Out[80]:
0 2 4 6
0 0.149748 -0.732339 0.687738 0.176444
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
In [81]: df1.iloc[1:5, 2:4]
Out[81]:
4 6
2 0.301624 -2.179861
4 1.462696 -1.743161
6 1.314232 0.690579
8 0.014871 3.357427
Выбор через список целых чисел:
In [82]: df1.iloc[[1, 3, 5], [1, 3]]
Out[82]:
2 6
2 -0.154951 -2.179861
6 -0.345352 0.690579
10 -1.236269 -0.487602
In [83]: df1.iloc[1:3, :]
Out[83]:
0 2 4 6
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
In [84]: df1.iloc[:, 1:3]
Out[84]:
2 4
0 -0.732339 0.687738
2 -0.154951 0.301624
4 -0.954208 1.462696
6 -0.345352 1.314232
8 2.396780 0.014871
10 -1.236269 0.896171
# this is also equivalent to ``df1.iat[1,1]``
In [85]: df1.iloc[1, 1]
Out[85]: -0.1549507744249032
Для получения поперечного сечения с использованием целочисленной позиции (эквивалентно df.xs(1)):
In [86]: df1.iloc[1]
Out[86]:
0 0.403310
2 -0.154951
4 0.301624
6 -2.179861
Name: 2, dtype: float64
Индексы срезов вне диапазона обрабатываются корректно, как в Python/NumPy.
# these are allowed in Python/NumPy.
In [87]: x = list('abcdef')
In [88]: x
Out[88]: ['a', 'b', 'c', 'd', 'e', 'f']
In [89]: x[4:10]
Out[89]: ['e', 'f']
In [90]: x[8:10]
Out[90]: []
In [91]: s = pd.Series(x)
In [92]: s
Out[92]:
0 a
1 b
2 c
3 d
4 e
5 f
dtype: object
In [93]: s.iloc[4:10]
Out[93]:
4 e
5 f
dtype: object
In [94]: s.iloc[8:10]
Out[94]: Series([], dtype: object)
Обратите внимание, что использование срезов, выходящих за границы, может привести к пустой оси (например, возврату пустого DataFrame).
In [95]: dfl = pd.DataFrame(np.random.randn(5, 2), columns=list('AB'))
In [96]: dfl
Out[96]:
A B
0 -0.082240 -2.182937
1 0.380396 0.084844
2 0.432390 1.519970
3 -0.493662 0.600178
4 0.274230 0.132885
In [97]: dfl.iloc[:, 2:3]
Out[97]:
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3, 4]
In [98]: dfl.iloc[:, 1:3]
Out[98]:
B
0 -2.182937
1 0.084844
2 1.519970
3 0.600178
4 0.132885
In [99]: dfl.iloc[4:6]
Out[99]:
A B
4 0.27423 0.132885
Один индексатор, выходящий за границы, вызовет IndexError.
Список индексаторов, где любой элемент выходит за пределы, вызовет
IndexError.
In [100]: dfl.iloc[[4, 5, 6]]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
File ~/work/pandas/pandas/pandas/core/indexing.py:1715, in _iLocIndexer._get_list_axis(self, key, axis)
1714 try:
-> 1715 return self.obj._take_with_is_copy(key, axis=axis)
1716 except IndexError as err:
1717 # re-raise with different error message, e.g. test_getitem_ndarray_3d
File ~/work/pandas/pandas/pandas/core/generic.py:4175, in NDFrame._take_with_is_copy(self, indices, axis)
4166 """
4167 Internal version of the `take` method that sets the `_is_copy`
4168 attribute to keep track of the parent dataframe (using in indexing
(...)
4173 See the docstring of `take` for full explanation of the parameters.
4174 """
-> 4175 result = self.take(indices=indices, axis=axis)
4176 # Maybe set copy if we didn't actually change the index.
File ~/work/pandas/pandas/pandas/core/generic.py:4155, in NDFrame.take(self, indices, axis, **kwargs)
4151 indices = np.arange(
4152 indices.start, indices.stop, indices.step, dtype=np.intp
4153 )
-> 4155 new_data = self._mgr.take(
4156 indices,
4157 axis=self._get_block_manager_axis(axis),
4158 verify=True,
4159 )
4160 return self._constructor_from_mgr(new_data, axes=new_data.axes).__finalize__(
4161 self, method="take"
4162 )
File ~/work/pandas/pandas/pandas/core/internals/managers.py:910, in BaseBlockManager.take(self, indexer, axis, verify)
909 n = self.shape[axis]
--> 910 indexer = maybe_convert_indices(indexer, n, verify=verify)
912 new_labels = self.axes[axis].take(indexer)
File ~/work/pandas/pandas/pandas/core/indexers/utils.py:282, in maybe_convert_indices(indices, n, verify)
281 if mask.any():
--> 282 raise IndexError("indices are out-of-bounds")
283 return indices
IndexError: indices are out-of-bounds
The above exception was the direct cause of the following exception:
IndexError Traceback (most recent call last)
Cell In[100], line 1
----> 1 dfl.iloc[[4, 5, 6]]
File ~/work/pandas/pandas/pandas/core/indexing.py:1192, in _LocationIndexer.__getitem__(self, key)
1190 maybe_callable = com.apply_if_callable(key, self.obj)
1191 maybe_callable = self._check_deprecated_callable_usage(key, maybe_callable)
-> 1192 return self._getitem_axis(maybe_callable, axis=axis)
File ~/work/pandas/pandas/pandas/core/indexing.py:1744, in _iLocIndexer._getitem_axis(self, key, axis)
1742 # a list of integers
1743 elif is_list_like_indexer(key):
-> 1744 return self._get_list_axis(key, axis=axis)
1746 # a single integer
1747 else:
1748 key = item_from_zerodim(key)
File ~/work/pandas/pandas/pandas/core/indexing.py:1718, in _iLocIndexer._get_list_axis(self, key, axis)
1715 return self.obj._take_with_is_copy(key, axis=axis)
1716 except IndexError as err:
1717 # re-raise with different error message, e.g. test_getitem_ndarray_3d
-> 1718 raise IndexError("positional indexers are out-of-bounds") from err
IndexError: positional indexers are out-of-bounds
In [101]: dfl.iloc[:, 4]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[101], line 1
----> 1 dfl.iloc[:, 4]
File ~/work/pandas/pandas/pandas/core/indexing.py:1185, in _LocationIndexer.__getitem__(self, key)
1183 if self._is_scalar_access(key):
1184 return self.obj._get_value(*key, takeable=self._takeable)
-> 1185 return self._getitem_tuple(key)
1186 else:
1187 # we by definition only have the 0th axis
1188 axis = self.axis or 0
File ~/work/pandas/pandas/pandas/core/indexing.py:1691, in _iLocIndexer._getitem_tuple(self, tup)
1690 def _getitem_tuple(self, tup: tuple):
-> 1691 tup = self._validate_tuple_indexer(tup)
1692 with suppress(IndexingError):
1693 return self._getitem_lowerdim(tup)
File ~/work/pandas/pandas/pandas/core/indexing.py:967, in _LocationIndexer._validate_tuple_indexer(self, key)
965 for i, k in enumerate(key):
966 try:
--> 967 self._validate_key(k, i)
968 except ValueError as err:
969 raise ValueError(
970 "Location based indexing can only have "
971 f"[{self._valid_types}] types"
972 ) from err
File ~/work/pandas/pandas/pandas/core/indexing.py:1593, in _iLocIndexer._validate_key(self, key, axis)
1591 return
1592 elif is_integer(key):
-> 1593 self._validate_integer(key, axis)
1594 elif isinstance(key, tuple):
1595 # a tuple should already have been caught by this point
1596 # so don't treat a tuple as a valid indexer
1597 raise IndexingError("Too many indexers")
File ~/work/pandas/pandas/pandas/core/indexing.py:1686, in _iLocIndexer._validate_integer(self, key, axis)
1684 len_axis = len(self.obj._get_axis(axis))
1685 if key >= len_axis or key < -len_axis:
-> 1686 raise IndexError("single positional indexer is out-of-bounds")
IndexError: single positional indexer is out-of-bounds
Выбор по вызываемому объекту#
.loc, .iloc, а также [] индексирование может принимать callable в качестве индексатора.
callable должна быть функцией с одним аргументом (вызываемый Series или DataFrame), которая возвращает допустимый вывод для индексирования.
Примечание
Для .iloc индексирование, возврат кортежа из вызываемого объекта
не поддерживается, поскольку распаковка кортежа для индексов строк и столбцов
происходит до применение вызываемых объектов.
In [102]: df1 = pd.DataFrame(np.random.randn(6, 4),
.....: index=list('abcdef'),
.....: columns=list('ABCD'))
.....:
In [103]: df1
Out[103]:
A B C D
a -0.023688 2.410179 1.450520 0.206053
b -0.251905 -2.213588 1.063327 1.266143
c 0.299368 -0.863838 0.408204 -1.048089
d -0.025747 -0.988387 0.094055 1.262731
e 1.289997 0.082423 -0.055758 0.536580
f -0.489682 0.369374 -0.034571 -2.484478
In [104]: df1.loc[lambda df: df['A'] > 0, :]
Out[104]:
A B C D
c 0.299368 -0.863838 0.408204 -1.048089
e 1.289997 0.082423 -0.055758 0.536580
In [105]: df1.loc[:, lambda df: ['A', 'B']]
Out[105]:
A B
a -0.023688 2.410179
b -0.251905 -2.213588
c 0.299368 -0.863838
d -0.025747 -0.988387
e 1.289997 0.082423
f -0.489682 0.369374
In [106]: df1.iloc[:, lambda df: [0, 1]]
Out[106]:
A B
a -0.023688 2.410179
b -0.251905 -2.213588
c 0.299368 -0.863838
d -0.025747 -0.988387
e 1.289997 0.082423
f -0.489682 0.369374
In [107]: df1[lambda df: df.columns[0]]
Out[107]:
a -0.023688
b -0.251905
c 0.299368
d -0.025747
e 1.289997
f -0.489682
Name: A, dtype: float64
Вы можете использовать вызываемое индексирование в Series.
In [108]: df1['A'].loc[lambda s: s > 0]
Out[108]:
c 0.299368
e 1.289997
Name: A, dtype: float64
Используя эти методы / индексаторы, вы можете связывать операции выбора данных без использования временной переменной.
In [109]: bb = pd.read_csv('data/baseball.csv', index_col='id')
In [110]: (bb.groupby(['year', 'team']).sum(numeric_only=True)
.....: .loc[lambda df: df['r'] > 100])
.....:
Out[110]:
stint g ab r h X2b ... so ibb hbp sh sf gidp
year team ...
2007 CIN 6 379 745 101 203 35 ... 127.0 14.0 1.0 1.0 15.0 18.0
DET 5 301 1062 162 283 54 ... 176.0 3.0 10.0 4.0 8.0 28.0
HOU 4 311 926 109 218 47 ... 212.0 3.0 9.0 16.0 6.0 17.0
LAN 11 413 1021 153 293 61 ... 141.0 8.0 9.0 3.0 8.0 29.0
NYN 13 622 1854 240 509 101 ... 310.0 24.0 23.0 18.0 15.0 48.0
SFN 5 482 1305 198 337 67 ... 188.0 51.0 8.0 16.0 6.0 41.0
TEX 2 198 729 115 200 40 ... 140.0 4.0 5.0 2.0 8.0 16.0
TOR 4 459 1408 187 378 96 ... 265.0 16.0 12.0 4.0 16.0 38.0
[8 rows x 18 columns]
Комбинирование позиционного и основанного на метках индексирования#
Если вы хотите получить 0-й и 2-й элементы из индекса в столбце 'A', вы можете сделать:
In [111]: dfd = pd.DataFrame({'A': [1, 2, 3],
.....: 'B': [4, 5, 6]},
.....: index=list('abc'))
.....:
In [112]: dfd
Out[112]:
A B
a 1 4
b 2 5
c 3 6
In [113]: dfd.loc[dfd.index[[0, 2]], 'A']
Out[113]:
a 1
c 3
Name: A, dtype: int64
Это также можно выразить с помощью .iloc, путем явного получения позиций на индексаторах и использования
позиционный индексация для выбора элементов.
In [114]: dfd.iloc[[0, 2], dfd.columns.get_loc('A')]
Out[114]:
a 1
c 3
Name: A, dtype: int64
Для получения несколько индексаторы, используя .get_indexer:
In [115]: dfd.iloc[[0, 2], dfd.columns.get_indexer(['A', 'B'])]
Out[115]:
A B
a 1 4
c 3 6
Переиндексация#
Идиоматический способ выбора потенциально не найденных элементов — через .reindex(). См. также раздел о переиндексация.
In [116]: s = pd.Series([1, 2, 3])
In [117]: s.reindex([1, 2, 3])
Out[117]:
1 2.0
2 3.0
3 NaN
dtype: float64
В качестве альтернативы, если вы хотите выбрать только валидный ключи, следующее является идиоматичным и эффективным; гарантируется сохранение типа данных выбора.
In [118]: labels = [1, 2, 3]
In [119]: s.loc[s.index.intersection(labels)]
Out[119]:
1 2
2 3
dtype: int64
Наличие дублирующегося индекса вызовет ошибку для .reindex():
In [120]: s = pd.Series(np.arange(4), index=['a', 'a', 'b', 'c'])
In [121]: labels = ['c', 'd']
In [122]: s.reindex(labels)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[122], line 1
----> 1 s.reindex(labels)
File ~/work/pandas/pandas/pandas/core/series.py:5172, in Series.reindex(self, index, axis, method, copy, level, fill_value, limit, tolerance)
5155 @doc(
5156 NDFrame.reindex, # type: ignore[has-type]
5157 klass=_shared_doc_kwargs["klass"],
(...)
5170 tolerance=None,
5171 ) -> Series:
-> 5172 return super().reindex(
5173 index=index,
5174 method=method,
5175 copy=copy,
5176 level=level,
5177 fill_value=fill_value,
5178 limit=limit,
5179 tolerance=tolerance,
5180 )
File ~/work/pandas/pandas/pandas/core/generic.py:5632, in NDFrame.reindex(self, labels, index, columns, axis, method, copy, level, fill_value, limit, tolerance)
5629 return self._reindex_multi(axes, copy, fill_value)
5631 # perform the reindex on the axes
-> 5632 return self._reindex_axes(
5633 axes, level, limit, tolerance, method, fill_value, copy
5634 ).__finalize__(self, method="reindex")
File ~/work/pandas/pandas/pandas/core/generic.py:5655, in NDFrame._reindex_axes(self, axes, level, limit, tolerance, method, fill_value, copy)
5652 continue
5654 ax = self._get_axis(a)
-> 5655 new_index, indexer = ax.reindex(
5656 labels, level=level, limit=limit, tolerance=tolerance, method=method
5657 )
5659 axis = self._get_axis_number(a)
5660 obj = obj._reindex_with_indexers(
5661 {axis: [new_index, indexer]},
5662 fill_value=fill_value,
5663 copy=copy,
5664 allow_dups=False,
5665 )
File ~/work/pandas/pandas/pandas/core/indexes/base.py:4436, in Index.reindex(self, target, method, level, limit, tolerance)
4433 raise ValueError("cannot handle a non-unique multi-index!")
4434 elif not self.is_unique:
4435 # GH#42568
-> 4436 raise ValueError("cannot reindex on an axis with duplicate labels")
4437 else:
4438 indexer, _ = self.get_indexer_non_unique(target)
ValueError: cannot reindex on an axis with duplicate labels
Обычно можно пересечь желаемые метки с текущей осью, а затем переиндексировать.
In [123]: s.loc[s.index.intersection(labels)].reindex(labels)
Out[123]:
c 3.0
d NaN
dtype: float64
Однако это бы still вызвать исключение, если результирующий индекс дублируется.
In [124]: labels = ['a', 'd']
In [125]: s.loc[s.index.intersection(labels)].reindex(labels)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[125], line 1
----> 1 s.loc[s.index.intersection(labels)].reindex(labels)
File ~/work/pandas/pandas/pandas/core/series.py:5172, in Series.reindex(self, index, axis, method, copy, level, fill_value, limit, tolerance)
5155 @doc(
5156 NDFrame.reindex, # type: ignore[has-type]
5157 klass=_shared_doc_kwargs["klass"],
(...)
5170 tolerance=None,
5171 ) -> Series:
-> 5172 return super().reindex(
5173 index=index,
5174 method=method,
5175 copy=copy,
5176 level=level,
5177 fill_value=fill_value,
5178 limit=limit,
5179 tolerance=tolerance,
5180 )
File ~/work/pandas/pandas/pandas/core/generic.py:5632, in NDFrame.reindex(self, labels, index, columns, axis, method, copy, level, fill_value, limit, tolerance)
5629 return self._reindex_multi(axes, copy, fill_value)
5631 # perform the reindex on the axes
-> 5632 return self._reindex_axes(
5633 axes, level, limit, tolerance, method, fill_value, copy
5634 ).__finalize__(self, method="reindex")
File ~/work/pandas/pandas/pandas/core/generic.py:5655, in NDFrame._reindex_axes(self, axes, level, limit, tolerance, method, fill_value, copy)
5652 continue
5654 ax = self._get_axis(a)
-> 5655 new_index, indexer = ax.reindex(
5656 labels, level=level, limit=limit, tolerance=tolerance, method=method
5657 )
5659 axis = self._get_axis_number(a)
5660 obj = obj._reindex_with_indexers(
5661 {axis: [new_index, indexer]},
5662 fill_value=fill_value,
5663 copy=copy,
5664 allow_dups=False,
5665 )
File ~/work/pandas/pandas/pandas/core/indexes/base.py:4436, in Index.reindex(self, target, method, level, limit, tolerance)
4433 raise ValueError("cannot handle a non-unique multi-index!")
4434 elif not self.is_unique:
4435 # GH#42568
-> 4436 raise ValueError("cannot reindex on an axis with duplicate labels")
4437 else:
4438 indexer, _ = self.get_indexer_non_unique(target)
ValueError: cannot reindex on an axis with duplicate labels
Выбор случайных образцов#
Случайный выбор строк или столбцов из Series или DataFrame с sample() метод. Метод по умолчанию будет выбирать строки и принимает определенное количество строк/столбцов для возврата или долю строк.
In [126]: s = pd.Series([0, 1, 2, 3, 4, 5])
# When no arguments are passed, returns 1 row.
In [127]: s.sample()
Out[127]:
4 4
dtype: int64
# One may specify either a number of rows:
In [128]: s.sample(n=3)
Out[128]:
0 0
4 4
1 1
dtype: int64
# Or a fraction of the rows:
In [129]: s.sample(frac=0.5)
Out[129]:
5 5
3 3
1 1
dtype: int64
По умолчанию, sample будет возвращать каждую строку не более одного раза, но также можно выполнять выборку с возвращением
используя replace опция:
In [130]: s = pd.Series([0, 1, 2, 3, 4, 5])
# Without replacement (default):
In [131]: s.sample(n=6, replace=False)
Out[131]:
0 0
1 1
5 5
3 3
2 2
4 4
dtype: int64
# With replacement:
In [132]: s.sample(n=6, replace=True)
Out[132]:
0 0
4 4
3 3
2 2
4 4
4 4
dtype: int64
По умолчанию каждая строка имеет равную вероятность быть выбранной, но если вы хотите, чтобы строки имели разные вероятности, вы можете передать sample функция весов выборки как
weights. Эти веса могут быть списком, массивом NumPy или Series, но они должны быть той же длины, что и объект, который вы сэмплируете. Пропущенные значения будут обрабатываться как вес ноль, а значения inf не допускаются. Если веса не суммируются до 1, они будут перенормированы путем деления всех весов на сумму весов. Например:
In [133]: s = pd.Series([0, 1, 2, 3, 4, 5])
In [134]: example_weights = [0, 0, 0.2, 0.2, 0.2, 0.4]
In [135]: s.sample(n=3, weights=example_weights)
Out[135]:
5 5
4 4
3 3
dtype: int64
# Weights will be re-normalized automatically
In [136]: example_weights2 = [0.5, 0, 0, 0, 0, 0]
In [137]: s.sample(n=1, weights=example_weights2)
Out[137]:
0 0
dtype: int64
При применении к DataFrame вы можете использовать столбец DataFrame в качестве весов выборки (при условии, что вы выбираете строки, а не столбцы), просто передав имя столбца в виде строки.
In [138]: df2 = pd.DataFrame({'col1': [9, 8, 7, 6],
.....: 'weight_column': [0.5, 0.4, 0.1, 0]})
.....:
In [139]: df2.sample(n=3, weights='weight_column')
Out[139]:
col1 weight_column
1 8 0.4
0 9 0.5
2 7 0.1
sample также позволяет пользователям выбирать столбцы вместо строк с помощью axis аргумент.
In [140]: df3 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
In [141]: df3.sample(n=1, axis=1)
Out[141]:
col1
0 1
1 2
2 3
Наконец, можно также установить начальное значение (seed) для sampleгенератор случайных чисел с использованием random_state аргумент, который принимает либо целое число (в качестве сида), либо объект NumPy RandomState.
In [142]: df4 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
# With a given seed, the sample will always draw the same rows.
In [143]: df4.sample(n=2, random_state=2)
Out[143]:
col1 col2
2 3 4
1 2 3
In [144]: df4.sample(n=2, random_state=2)
Out[144]:
col1 col2
2 3 4
1 2 3
Установка с расширением#
The .loc/[] операции могут выполнять расширение при установке несуществующего ключа для этой оси.
В Series в этом случае это фактически операция добавления.
In [145]: se = pd.Series([1, 2, 3])
In [146]: se
Out[146]:
0 1
1 2
2 3
dtype: int64
In [147]: se[5] = 5.
In [148]: se
Out[148]:
0 1.0
1 2.0
2 3.0
5 5.0
dtype: float64
A DataFrame может быть расширен по любой оси через .loc.
In [149]: dfi = pd.DataFrame(np.arange(6).reshape(3, 2),
.....: columns=['A', 'B'])
.....:
In [150]: dfi
Out[150]:
A B
0 0 1
1 2 3
2 4 5
In [151]: dfi.loc[:, 'C'] = dfi.loc[:, 'A']
In [152]: dfi
Out[152]:
A B C
0 0 1 0
1 2 3 2
2 4 5 4
Это похоже на append операция над DataFrame.
In [153]: dfi.loc[3] = 5
In [154]: dfi
Out[154]:
A B C
0 0 1 0
1 2 3 2
2 4 5 4
3 5 5 5
Быстрое получение и установка скалярных значений#
Поскольку индексирование с [] должен обрабатывать множество случаев (доступ по одной метке,
срезы, булево индексирование и т.д.), у него есть небольшие накладные расходы, чтобы выяснить,
что вы запрашиваете. Если вы хотите получить доступ только к скалярному значению, самый
быстрый способ — использовать at и iat методы, которые реализованы на
всех структурах данных.
Аналогично loc, at предоставляет метка скалярные поиски на основе, в то время как, iat предоставляет целое число аналогично поиску на основе iloc
In [155]: s.iat[5]
Out[155]: 5
In [156]: df.at[dates[5], 'A']
Out[156]: 0.1136484096888855
In [157]: df.iat[3, 0]
Out[157]: -0.7067711336300845
Вы также можете установить, используя те же индексаторы.
In [158]: df.at[dates[5], 'E'] = 7
In [159]: df.iat[3, 0] = 7
at может увеличить объект на месте, как указано выше, если индексатор отсутствует.
In [160]: df.at[dates[-1] + pd.Timedelta('1 day'), 0] = 7
In [161]: df
Out[161]:
A B C D E 0
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632 NaN NaN
2000-01-02 -0.173215 1.212112 0.119209 -1.044236 NaN NaN
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804 NaN NaN
2000-01-04 7.000000 0.721555 -1.039575 0.271860 NaN NaN
2000-01-05 0.567020 -0.424972 0.276232 -1.087401 NaN NaN
2000-01-06 0.113648 -0.673690 -1.478427 0.524988 7.0 NaN
2000-01-07 0.577046 0.404705 -1.715002 -1.039268 NaN NaN
2000-01-08 -1.157892 -0.370647 -1.344312 0.844885 NaN NaN
2000-01-09 NaN NaN NaN NaN NaN 7.0
Булева индексация#
Ещё одна распространённая операция — использование булевых векторов для фильтрации данных.
Операторы: | для or, & для and, и ~ для not.
Эти должен можно группировать с помощью круглых скобок, так как по умолчанию Python будет вычислять выражение, такое как df['A'] > 2 & df['B'] < 3 как
df['A'] > (2 & df['B']) < 3, в то время как желаемый порядок вычислений
(df['A'] > 2) & (df['B'] < 3).
Использование логического вектора для индексации Series работает точно так же, как в ndarray NumPy:
In [162]: s = pd.Series(range(-3, 4))
In [163]: s
Out[163]:
0 -3
1 -2
2 -1
3 0
4 1
5 2
6 3
dtype: int64
In [164]: s[s > 0]
Out[164]:
4 1
5 2
6 3
dtype: int64
In [165]: s[(s < -1) | (s > 0.5)]
Out[165]:
0 -3
1 -2
4 1
5 2
6 3
dtype: int64
In [166]: s[~(s < 0)]
Out[166]:
3 0
4 1
5 2
6 3
dtype: int64
Вы можете выбрать строки из DataFrame, используя булев вектор той же длины, что и индекс DataFrame (например, полученный из одного из столбцов DataFrame):
In [167]: df[df['A'] > 0]
Out[167]:
A B C D E 0
2000-01-04 7.000000 0.721555 -1.039575 0.271860 NaN NaN
2000-01-05 0.567020 -0.424972 0.276232 -1.087401 NaN NaN
2000-01-06 0.113648 -0.673690 -1.478427 0.524988 7.0 NaN
2000-01-07 0.577046 0.404705 -1.715002 -1.039268 NaN NaN
Списковые включения и map метод Series также может использоваться для создания
более сложных критериев:
In [168]: df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'three', 'two', 'one', 'six'],
.....: 'b': ['x', 'y', 'y', 'x', 'y', 'x', 'x'],
.....: 'c': np.random.randn(7)})
.....:
# only want 'two' or 'three'
In [169]: criterion = df2['a'].map(lambda x: x.startswith('t'))
In [170]: df2[criterion]
Out[170]:
a b c
2 two y 0.041290
3 three x 0.361719
4 two y -0.238075
# equivalent but slower
In [171]: df2[[x.startswith('t') for x in df2['a']]]
Out[171]:
a b c
2 two y 0.041290
3 three x 0.361719
4 two y -0.238075
# Multiple criteria
In [172]: df2[criterion & (df2['b'] == 'x')]
Out[172]:
a b c
3 three x 0.361719
С помощью методов выбора Выбор по метке, Выбор по позиции, и Расширенная индексация вы можете выбрать более чем по одной оси, используя булевы векторы в сочетании с другими выражениями индексации.
In [173]: df2.loc[criterion & (df2['b'] == 'x'), 'b':'c']
Out[173]:
b c
3 x 0.361719
Предупреждение
iloc поддерживает два вида булевой индексации. Если индексатор является булевым Series,
будет вызвана ошибка. Например, в следующем примере, df.iloc[s.values, 1] в порядке.
Булевый индексатор является массивом. Но df.iloc[s, 1] вызовет ValueError.
In [174]: df = pd.DataFrame([[1, 2], [3, 4], [5, 6]],
.....: index=list('abc'),
.....: columns=['A', 'B'])
.....:
In [175]: s = (df['A'] > 2)
In [176]: s
Out[176]:
a False
b True
c True
Name: A, dtype: bool
In [177]: df.loc[s, 'B']
Out[177]:
b 4
c 6
Name: B, dtype: int64
In [178]: df.iloc[s.values, 1]
Out[178]:
b 4
c 6
Name: B, dtype: int64
Индексирование с помощью isin#
Рассмотрим isin() метод Series, который возвращает булев вектор, истинный везде, где Series элементы существуют в переданном списке.
Это позволяет выбрать строки, где один или несколько столбцов имеют нужные значения:
In [179]: s = pd.Series(np.arange(5), index=np.arange(5)[::-1], dtype='int64')
In [180]: s
Out[180]:
4 0
3 1
2 2
1 3
0 4
dtype: int64
In [181]: s.isin([2, 4, 6])
Out[181]:
4 False
3 False
2 True
1 False
0 True
dtype: bool
In [182]: s[s.isin([2, 4, 6])]
Out[182]:
2 2
0 4
dtype: int64
Тот же метод доступен для Index объекты и полезны в случаях, когда вы не знаете, какие из искомых меток фактически присутствуют:
In [183]: s[s.index.isin([2, 4, 6])]
Out[183]:
4 0
2 2
dtype: int64
# compare it to the following
In [184]: s.reindex([2, 4, 6])
Out[184]:
2 2.0
4 0.0
6 NaN
dtype: float64
В дополнение к этому, MultiIndex позволяет выбрать отдельный уровень для использования
в проверке принадлежности:
In [185]: s_mi = pd.Series(np.arange(6),
.....: index=pd.MultiIndex.from_product([[0, 1], ['a', 'b', 'c']]))
.....:
In [186]: s_mi
Out[186]:
0 a 0
b 1
c 2
1 a 3
b 4
c 5
dtype: int64
In [187]: s_mi.iloc[s_mi.index.isin([(1, 'a'), (2, 'b'), (0, 'c')])]
Out[187]:
0 c 2
1 a 3
dtype: int64
In [188]: s_mi.iloc[s_mi.index.isin(['a', 'c', 'e'], level=1)]
Out[188]:
0 a 0
c 2
1 a 3
c 5
dtype: int64
DataFrame также имеет isin() метод. При вызове isin, передайте набор значений в виде массива или словаря. Если values является массивом, isin возвращает
DataFrame логических значений той же формы, что и исходный DataFrame, с True
везде, где элемент находится в последовательности значений.
In [189]: df = pd.DataFrame({'vals': [1, 2, 3, 4], 'ids': ['a', 'b', 'f', 'n'],
.....: 'ids2': ['a', 'n', 'c', 'n']})
.....:
In [190]: values = ['a', 'b', 1, 3]
In [191]: df.isin(values)
Out[191]:
vals ids ids2
0 True True True
1 False True False
2 True False False
3 False False False
Часто требуется сопоставить определенные значения с определенными столбцами. Просто сделайте values dict где ключом является столбец, а значением
список элементов, которые нужно проверить.
In [192]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
In [193]: df.isin(values)
Out[193]:
vals ids ids2
0 True True False
1 False True False
2 True False False
3 False False False
Чтобы вернуть DataFrame булевых значений, где значения не в исходном DataFrame, используйте ~ оператор:
In [194]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
In [195]: ~df.isin(values)
Out[195]:
vals ids ids2
0 False False True
1 True False True
2 False True True
3 True True True
Объединение DataFrame isin с any() и all() методов для быстрого выбора подмножеств данных, соответствующих заданному критерию.
Чтобы выбрать строку, где каждый столбец соответствует своему критерию:
In [196]: values = {'ids': ['a', 'b'], 'ids2': ['a', 'c'], 'vals': [1, 3]}
In [197]: row_mask = df.isin(values).all(1)
In [198]: df[row_mask]
Out[198]:
vals ids ids2
0 1 a a
The where() Метод и маскирование#
Выбор значений из Series с помощью булева вектора обычно возвращает подмножество данных. Чтобы гарантировать, что результат выбора имеет ту же форму, что и исходные данные, можно использовать where метод в Series и DataFrame.
Чтобы вернуть только выбранные строки:
In [199]: s[s > 0]
Out[199]:
3 1
2 2
1 3
0 4
dtype: int64
Чтобы вернуть Series той же формы, что и исходный:
In [200]: s.where(s > 0)
Out[200]:
4 NaN
3 1.0
2 2.0
1 3.0
0 4.0
dtype: float64
Выбор значений из DataFrame с булевым критерием теперь также сохраняет форму входных данных. where используется внутри как реализация.
Код ниже эквивалентен df.where(df < 0).
In [201]: dates = pd.date_range('1/1/2000', periods=8)
In [202]: df = pd.DataFrame(np.random.randn(8, 4),
.....: index=dates, columns=['A', 'B', 'C', 'D'])
.....:
In [203]: df[df < 0]
Out[203]:
A B C D
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0.352480 NaN -1.192319 NaN
2000-01-03 -0.864883 NaN -0.227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1.169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2.670153 -0.114722 NaN -0.048048
2000-01-08 NaN NaN -0.048788 -0.808838
Кроме того, where принимает необязательный other аргумент для замены значений, где условие ложно, в возвращаемой копии.
In [204]: df.where(df < 0, -df)
Out[204]:
A B C D
2000-01-01 -2.104139 -1.309525 -0.485855 -0.245166
2000-01-02 -0.352480 -0.390389 -1.192319 -1.655824
2000-01-03 -0.864883 -0.299674 -0.227870 -0.281059
2000-01-04 -0.846958 -1.222082 -0.600705 -1.233203
2000-01-05 -0.669692 -0.605656 -1.169184 -0.342416
2000-01-06 -0.868584 -0.948458 -2.297780 -0.684718
2000-01-07 -2.670153 -0.114722 -0.168904 -0.048048
2000-01-08 -0.801196 -1.392071 -0.048788 -0.808838
Возможно, вы захотите установить значения на основе некоторых булевых критериев. Это можно сделать интуитивно следующим образом:
In [205]: s2 = s.copy()
In [206]: s2[s2 < 0] = 0
In [207]: s2
Out[207]:
4 0
3 1
2 2
1 3
0 4
dtype: int64
In [208]: df2 = df.copy()
In [209]: df2[df2 < 0] = 0
In [210]: df2
Out[210]:
A B C D
2000-01-01 0.000000 0.000000 0.485855 0.245166
2000-01-02 0.000000 0.390389 0.000000 1.655824
2000-01-03 0.000000 0.299674 0.000000 0.281059
2000-01-04 0.846958 0.000000 0.600705 0.000000
2000-01-05 0.669692 0.000000 0.000000 0.342416
2000-01-06 0.868584 0.000000 2.297780 0.000000
2000-01-07 0.000000 0.000000 0.168904 0.000000
2000-01-08 0.801196 1.392071 0.000000 0.000000
where возвращает изменённую копию данных.
Примечание
Сигнатура для DataFrame.where() отличается от numpy.where(). Приблизительно df1.where(m, df2) эквивалентно np.where(m, df1, df2).
In [211]: df.where(df < 0, -df) == np.where(df < 0, df, -df)
Out[211]:
A B C D
2000-01-01 True True True True
2000-01-02 True True True True
2000-01-03 True True True True
2000-01-04 True True True True
2000-01-05 True True True True
2000-01-06 True True True True
2000-01-07 True True True True
2000-01-08 True True True True
Выравнивание
Кроме того, where выравнивает входное булево условие (ndarray или DataFrame),
таким образом, что частичное выделение с установкой возможно. Это аналогично
частичной установке через .loc (но на содержимом, а не на метках осей).
In [212]: df2 = df.copy()
In [213]: df2[df2[1:4] > 0] = 3
In [214]: df2
Out[214]:
A B C D
2000-01-01 -2.104139 -1.309525 0.485855 0.245166
2000-01-02 -0.352480 3.000000 -1.192319 3.000000
2000-01-03 -0.864883 3.000000 -0.227870 3.000000
2000-01-04 3.000000 -1.222082 3.000000 -1.233203
2000-01-05 0.669692 -0.605656 -1.169184 0.342416
2000-01-06 0.868584 -0.948458 2.297780 -0.684718
2000-01-07 -2.670153 -0.114722 0.168904 -0.048048
2000-01-08 0.801196 1.392071 -0.048788 -0.808838
Where также может принимать axis и level параметры для выравнивания ввода при
выполнении where.
In [215]: df2 = df.copy()
In [216]: df2.where(df2 > 0, df2['A'], axis='index')
Out[216]:
A B C D
2000-01-01 -2.104139 -2.104139 0.485855 0.245166
2000-01-02 -0.352480 0.390389 -0.352480 1.655824
2000-01-03 -0.864883 0.299674 -0.864883 0.281059
2000-01-04 0.846958 0.846958 0.600705 0.846958
2000-01-05 0.669692 0.669692 0.669692 0.342416
2000-01-06 0.868584 0.868584 2.297780 0.868584
2000-01-07 -2.670153 -2.670153 0.168904 -2.670153
2000-01-08 0.801196 1.392071 0.801196 0.801196
Это эквивалентно (но быстрее) следующему.
In [217]: df2 = df.copy()
In [218]: df.apply(lambda x, y: x.where(x > 0, y), y=df['A'])
Out[218]:
A B C D
2000-01-01 -2.104139 -2.104139 0.485855 0.245166
2000-01-02 -0.352480 0.390389 -0.352480 1.655824
2000-01-03 -0.864883 0.299674 -0.864883 0.281059
2000-01-04 0.846958 0.846958 0.600705 0.846958
2000-01-05 0.669692 0.669692 0.669692 0.342416
2000-01-06 0.868584 0.868584 2.297780 0.868584
2000-01-07 -2.670153 -2.670153 0.168904 -2.670153
2000-01-08 0.801196 1.392071 0.801196 0.801196
where может принимать вызываемый объект в качестве условия и other аргументы. Функция должна
иметь один аргумент (вызываемый Series или DataFrame) и возвращать корректный вывод
как условие и other аргумент.
In [219]: df3 = pd.DataFrame({'A': [1, 2, 3],
.....: 'B': [4, 5, 6],
.....: 'C': [7, 8, 9]})
.....:
In [220]: df3.where(lambda x: x > 4, lambda x: x + 10)
Out[220]:
A B C
0 11 14 7
1 12 5 8
2 13 6 9
Маска#
mask() является обратной булевой операцией для where.
In [221]: s.mask(s >= 0)
Out[221]:
4 NaN
3 NaN
2 NaN
1 NaN
0 NaN
dtype: float64
In [222]: df.mask(df >= 0)
Out[222]:
A B C D
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0.352480 NaN -1.192319 NaN
2000-01-03 -0.864883 NaN -0.227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1.169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2.670153 -0.114722 NaN -0.048048
2000-01-08 NaN NaN -0.048788 -0.808838
Установка с расширением условно с использованием numpy()#
Альтернатива where() используйте numpy.where().
В сочетании с установкой нового столбца вы можете использовать это для расширения DataFrame, где
значения определяются условно.
Предположим, у вас есть два варианта для выбора в следующем DataFrame. И вы хотите установить новый столбец color в 'green', когда второй столбец имеет 'Z'. Вы можете сделать следующее:
In [223]: df = pd.DataFrame({'col1': list('ABBC'), 'col2': list('ZZXY')})
In [224]: df['color'] = np.where(df['col2'] == 'Z', 'green', 'red')
In [225]: df
Out[225]:
col1 col2 color
0 A Z green
1 B Z green
2 B X red
3 C Y red
Если у вас несколько условий, вы можете использовать numpy.select() чтобы достичь этого. Скажем
соответствующие трём условиям есть три варианта цветов, с четвёртым цветом
как запасным, вы можете сделать следующее.
In [226]: conditions = [
.....: (df['col2'] == 'Z') & (df['col1'] == 'A'),
.....: (df['col2'] == 'Z') & (df['col1'] == 'B'),
.....: (df['col1'] == 'B')
.....: ]
.....:
In [227]: choices = ['yellow', 'blue', 'purple']
In [228]: df['color'] = np.select(conditions, choices, default='black')
In [229]: df
Out[229]:
col1 col2 color
0 A Z yellow
1 B Z blue
2 B X purple
3 C Y black
The query() Метод#
DataFrame объекты имеют query()
метод, позволяющий выбор с использованием выражения.
Вы можете получить значение фрейма, где столбец b имеет значения
между значениями столбцов a и c. Например:
In [230]: n = 10
In [231]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [232]: df
Out[232]:
a b c
0 0.438921 0.118680 0.863670
1 0.138138 0.577363 0.686602
2 0.595307 0.564592 0.520630
3 0.913052 0.926075 0.616184
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
6 0.792342 0.216974 0.564056
7 0.397890 0.454131 0.915716
8 0.074315 0.437913 0.019794
9 0.559209 0.502065 0.026437
# pure python
In [233]: df[(df['a'] < df['b']) & (df['b'] < df['c'])]
Out[233]:
a b c
1 0.138138 0.577363 0.686602
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
7 0.397890 0.454131 0.915716
# query
In [234]: df.query('(a < b) & (b < c)')
Out[234]:
a b c
1 0.138138 0.577363 0.686602
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
7 0.397890 0.454131 0.915716
Сделать то же самое, но использовать именованный индекс, если нет столбца
с именем a.
In [235]: df = pd.DataFrame(np.random.randint(n / 2, size=(n, 2)), columns=list('bc'))
In [236]: df.index.name = 'a'
In [237]: df
Out[237]:
b c
a
0 0 4
1 0 1
2 3 4
3 4 3
4 1 4
5 0 3
6 0 1
7 3 4
8 2 3
9 1 1
In [238]: df.query('a < b and b < c')
Out[238]:
b c
a
2 3 4
Если вместо этого вы не хотите или не можете назвать свой индекс, вы можете использовать имя
index в вашем выражении запроса:
In [239]: df = pd.DataFrame(np.random.randint(n, size=(n, 2)), columns=list('bc'))
In [240]: df
Out[240]:
b c
0 3 1
1 3 0
2 5 6
3 5 2
4 7 4
5 0 1
6 2 5
7 0 1
8 6 0
9 7 9
In [241]: df.query('index < b < c')
Out[241]:
b c
2 5 6
Примечание
Если имя вашего индекса совпадает с именем столбца, приоритет отдается имени столбца. Например,
In [242]: df = pd.DataFrame({'a': np.random.randint(5, size=5)})
In [243]: df.index.name = 'a'
In [244]: df.query('a > 2') # uses the column 'a', not the index
Out[244]:
a
a
1 3
3 3
Вы всё ещё можете использовать индекс в выражении запроса, используя специальный идентификатор 'index':
In [245]: df.query('index > 2')
Out[245]:
a
a
3 3
4 2
Если по какой-то причине у вас есть столбец с именем index, тогда вы можете ссылаться
на индекс как ilevel_0 также, но на этом этапе вам следует рассмотреть переименование ваших столбцов во что-то менее двусмысленное.
MultiIndex query() Синтаксис#
Вы также можете использовать уровни DataFrame с
MultiIndex как если бы они были столбцами во фрейме:
In [246]: n = 10
In [247]: colors = np.random.choice(['red', 'green'], size=n)
In [248]: foods = np.random.choice(['eggs', 'ham'], size=n)
In [249]: colors
Out[249]:
array(['red', 'red', 'red', 'green', 'green', 'green', 'green', 'green',
'green', 'green'], dtype='
In [250]: foods
Out[250]:
array(['ham', 'ham', 'eggs', 'eggs', 'eggs', 'ham', 'ham', 'eggs', 'eggs',
'eggs'], dtype='
In [251]: index = pd.MultiIndex.from_arrays([colors, foods], names=['color', 'food'])
In [252]: df = pd.DataFrame(np.random.randn(n, 2), index=index)
In [253]: df
Out[253]:
0 1
color food
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
green eggs -0.748199 1.318931
eggs -2.029766 0.792652
ham 0.461007 -0.542749
ham -0.305384 -0.479195
eggs 0.095031 -0.270099
eggs -0.707140 -0.773882
eggs 0.229453 0.304418
In [254]: df.query('color == "red"')
Out[254]:
0 1
color food
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
Если уровни MultiIndex не имеют имен, вы можете ссылаться на них, используя
специальные имена:
In [255]: df.index.names = [None, None]
In [256]: df
Out[256]:
0 1
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
green eggs -0.748199 1.318931
eggs -2.029766 0.792652
ham 0.461007 -0.542749
ham -0.305384 -0.479195
eggs 0.095031 -0.270099
eggs -0.707140 -0.773882
eggs 0.229453 0.304418
In [257]: df.query('ilevel_0 == "red"')
Out[257]:
0 1
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
Соглашение заключается в ilevel_0, что означает "уровень индекса 0" для 0-го уровня index.
query() Варианты использования#
Пример использования для query() pandas.tseries.offsets.QuarterEnd.is_quarter_end
DataFrame объекты, имеющие подмножество имен столбцов (или уровней/имен индекса) общими. Вы можете передать тот же запрос в оба фрейма без
необходимость указывать, какой фрейм вас интересует для запроса
In [258]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [259]: df
Out[259]:
a b c
0 0.224283 0.736107 0.139168
1 0.302827 0.657803 0.713897
2 0.611185 0.136624 0.984960
3 0.195246 0.123436 0.627712
4 0.618673 0.371660 0.047902
5 0.480088 0.062993 0.185760
6 0.568018 0.483467 0.445289
7 0.309040 0.274580 0.587101
8 0.258993 0.477769 0.370255
9 0.550459 0.840870 0.304611
In [260]: df2 = pd.DataFrame(np.random.rand(n + 2, 3), columns=df.columns)
In [261]: df2
Out[261]:
a b c
0 0.357579 0.229800 0.596001
1 0.309059 0.957923 0.965663
2 0.123102 0.336914 0.318616
3 0.526506 0.323321 0.860813
4 0.518736 0.486514 0.384724
5 0.190804 0.505723 0.614533
6 0.891939 0.623977 0.676639
7 0.480559 0.378528 0.460858
8 0.420223 0.136404 0.141295
9 0.732206 0.419540 0.604675
10 0.604466 0.848974 0.896165
11 0.589168 0.920046 0.732716
In [262]: expr = '0.0 <= a <= c <= 0.5'
In [263]: map(lambda frame: frame.query(expr), [df, df2])
Out[263]:
query() Сравнение синтаксиса Python и pandas#
Полный синтаксис, подобный numpy:
In [264]: df = pd.DataFrame(np.random.randint(n, size=(n, 3)), columns=list('abc'))
In [265]: df
Out[265]:
a b c
0 7 8 9
1 1 0 7
2 2 7 2
3 6 2 2
4 2 6 3
5 3 8 2
6 1 7 2
7 5 1 5
8 9 8 0
9 1 5 0
In [266]: df.query('(a < b) & (b < c)')
Out[266]:
a b c
0 7 8 9
In [267]: df[(df['a'] < df['b']) & (df['b'] < df['c'])]
Out[267]:
a b c
0 7 8 9
Немного лучше за счёт удаления скобок (операторы сравнения связываются сильнее,
чем & и |):
In [268]: df.query('a < b & b < c')
Out[268]:
a b c
0 7 8 9
Используйте английский вместо символов:
In [269]: df.query('a < b and b < c')
Out[269]:
a b c
0 7 8 9
Довольно близко к тому, как вы могли бы записать это на бумаге:
In [270]: df.query('a < b < c')
Out[270]:
a b c
0 7 8 9
The in и not in операторы#
query() также поддерживает специальное использование Python in и
not in операторы сравнения, предоставляя краткий синтаксис для вызова
isin метод Series или DataFrame.
# get all rows where columns "a" and "b" have overlapping values
In [271]: df = pd.DataFrame({'a': list('aabbccddeeff'), 'b': list('aaaabbbbcccc'),
.....: 'c': np.random.randint(5, size=12),
.....: 'd': np.random.randint(9, size=12)})
.....:
In [272]: df
Out[272]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
In [273]: df.query('a in b')
Out[273]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
# How you'd do it in pure Python
In [274]: df[df['a'].isin(df['b'])]
Out[274]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
In [275]: df.query('a not in b')
Out[275]:
a b c d
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
# pure Python
In [276]: df[~df['a'].isin(df['b'])]
Out[276]:
a b c d
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
Вы можете комбинировать это с другими выражениями для очень лаконичных запросов:
# rows where cols a and b have overlapping values
# and col c's values are less than col d's
In [277]: df.query('a in b and c < d')
Out[277]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
4 c b 3 6
5 c b 0 2
# pure Python
In [278]: df[df['b'].isin(df['a']) & (df['c'] < df['d'])]
Out[278]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
4 c b 3 6
5 c b 0 2
10 f c 0 6
11 f c 1 2
Примечание
Обратите внимание, что in и not in вычисляются в Python, поскольку numexpr
не имеет эквивалента этой операции. Однако, только in/not in
само выражение вычисляется в чистом Python. Например, в выражении
df.query('a in b + c + d')
(b + c + d) оценивается с помощью numexpr и затем the in
операция вычисляется в обычном Python. В целом, любые операции, которые могут быть вычислены с использованием numexpr будет.
Особое использование == оператор с list объекты#
Сравнение list значений в столбец с помощью ==/!= работает аналогично in/not in.
In [279]: df.query('b == ["a", "b", "c"]')
Out[279]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
# pure Python
In [280]: df[df['b'].isin(["a", "b", "c"])]
Out[280]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
In [281]: df.query('c == [1, 2]')
Out[281]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
In [282]: df.query('c != [1, 2]')
Out[282]:
a b c d
1 a a 4 7
4 c b 3 6
5 c b 0 2
6 d b 3 3
8 e c 4 3
10 f c 0 6
# using in/not in
In [283]: df.query('[1, 2] in c')
Out[283]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
In [284]: df.query('[1, 2] not in c')
Out[284]:
a b c d
1 a a 4 7
4 c b 3 6
5 c b 0 2
6 d b 3 3
8 e c 4 3
10 f c 0 6
# pure Python
In [285]: df[df['c'].isin([1, 2])]
Out[285]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
Булевы операторы#
Вы можете инвертировать логические выражения с помощью слова not или ~ оператор.
In [286]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [287]: df['bools'] = np.random.rand(len(df)) > 0.5
In [288]: df.query('~bools')
Out[288]:
a b c bools
2 0.697753 0.212799 0.329209 False
7 0.275396 0.691034 0.826619 False
8 0.190649 0.558748 0.262467 False
In [289]: df.query('not bools')
Out[289]:
a b c bools
2 0.697753 0.212799 0.329209 False
7 0.275396 0.691034 0.826619 False
8 0.190649 0.558748 0.262467 False
In [290]: df.query('not bools') == df[~df['bools']]
Out[290]:
a b c bools
2 True True True True
7 True True True True
8 True True True True
Конечно, выражения также могут быть произвольно сложными:
# short query syntax
In [291]: shorter = df.query('a < b < c and (not bools) or bools > 2')
# equivalent in pure Python
In [292]: longer = df[(df['a'] < df['b'])
.....: & (df['b'] < df['c'])
.....: & (~df['bools'])
.....: | (df['bools'] > 2)]
.....:
In [293]: shorter
Out[293]:
a b c bools
7 0.275396 0.691034 0.826619 False
In [294]: longer
Out[294]:
a b c bools
7 0.275396 0.691034 0.826619 False
In [295]: shorter == longer
Out[295]:
a b c bools
7 True True True True
Производительность query()#
DataFrame.query() используя numexpr немного быстрее, чем Python для больших фреймов.
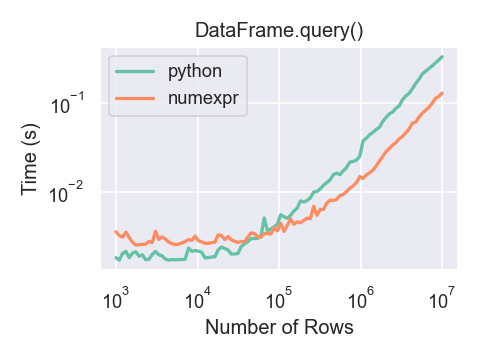
Вы увидите преимущества в производительности только при использовании numexpr движок
с DataFrame.query() если ваш фрейм имеет более примерно 100 000
строк.
Этот график был создан с использованием DataFrame с 3 столбцами, каждый из которых содержит значения с плавающей точкой, сгенерированные с помощью numpy.random.randn().
In [296]: df = pd.DataFrame(np.random.randn(8, 4),
.....: index=dates, columns=['A', 'B', 'C', 'D'])
.....:
In [297]: df2 = df.copy()
Дублирование данных#
Если вы хотите идентифицировать и удалить дублирующиеся строки в DataFrame, есть два метода, которые помогут: duplicated и drop_duplicates. Каждый
принимает в качестве аргумента столбцы для идентификации дублирующихся строк.
duplicatedвозвращает булев вектор, длина которого равна количеству строк, и который указывает, является ли строка дублированной.drop_duplicatesудаляет дублирующиеся строки.
По умолчанию первая наблюдаемая строка дублирующегося набора считается уникальной, но
каждый метод имеет keep параметр для указания целей, которые нужно сохранить.
keep='first'(по умолчанию): отмечать/удалять дубликаты, кроме первого вхождения.keep='last': отметить/удалить дубликаты, кроме последнего вхождения.keep=False: отметить / удалить все дубликаты.
In [298]: df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'two', 'two', 'three', 'four'],
.....: 'b': ['x', 'y', 'x', 'y', 'x', 'x', 'x'],
.....: 'c': np.random.randn(7)})
.....:
In [299]: df2
Out[299]:
a b c
0 one x -1.067137
1 one y 0.309500
2 two x -0.211056
3 two y -1.842023
4 two x -0.390820
5 three x -1.964475
6 four x 1.298329
In [300]: df2.duplicated('a')
Out[300]:
0 False
1 True
2 False
3 True
4 True
5 False
6 False
dtype: bool
In [301]: df2.duplicated('a', keep='last')
Out[301]:
0 True
1 False
2 True
3 True
4 False
5 False
6 False
dtype: bool
In [302]: df2.duplicated('a', keep=False)
Out[302]:
0 True
1 True
2 True
3 True
4 True
5 False
6 False
dtype: bool
In [303]: df2.drop_duplicates('a')
Out[303]:
a b c
0 one x -1.067137
2 two x -0.211056
5 three x -1.964475
6 four x 1.298329
In [304]: df2.drop_duplicates('a', keep='last')
Out[304]:
a b c
1 one y 0.309500
4 two x -0.390820
5 three x -1.964475
6 four x 1.298329
In [305]: df2.drop_duplicates('a', keep=False)
Out[305]:
a b c
5 three x -1.964475
6 four x 1.298329
Также можно передать список столбцов для идентификации дубликатов.
In [306]: df2.duplicated(['a', 'b'])
Out[306]:
0 False
1 False
2 False
3 False
4 True
5 False
6 False
dtype: bool
In [307]: df2.drop_duplicates(['a', 'b'])
Out[307]:
a b c
0 one x -1.067137
1 one y 0.309500
2 two x -0.211056
3 two y -1.842023
5 three x -1.964475
6 four x 1.298329
Чтобы удалить дубликаты по значению индекса, используйте Index.duplicated затем выполнить срез.
Тот же набор опций доступен для keep параметр.
In [308]: df3 = pd.DataFrame({'a': np.arange(6),
.....: 'b': np.random.randn(6)},
.....: index=['a', 'a', 'b', 'c', 'b', 'a'])
.....:
In [309]: df3
Out[309]:
a b
a 0 1.440455
a 1 2.456086
b 2 1.038402
c 3 -0.894409
b 4 0.683536
a 5 3.082764
In [310]: df3.index.duplicated()
Out[310]: array([False, True, False, False, True, True])
In [311]: df3[~df3.index.duplicated()]
Out[311]:
a b
a 0 1.440455
b 2 1.038402
c 3 -0.894409
In [312]: df3[~df3.index.duplicated(keep='last')]
Out[312]:
a b
c 3 -0.894409
b 4 0.683536
a 5 3.082764
In [313]: df3[~df3.index.duplicated(keep=False)]
Out[313]:
a b
c 3 -0.894409
Словареподобный get() метод#
Каждый из Series или DataFrame имеет get метод, который может возвращать
значение по умолчанию.
In [314]: s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
In [315]: s.get('a') # equivalent to s['a']
Out[315]: 1
In [316]: s.get('x', default=-1)
Out[316]: -1
Поиск значений по меткам индекса/столбцов#
Иногда требуется извлечь набор значений по заданной последовательности меток строк и меток столбцов, это можно сделать с помощью pandas.factorize и индексация NumPy.
Например:
In [317]: df = pd.DataFrame({'col': ["A", "A", "B", "B"],
.....: 'A': [80, 23, np.nan, 22],
.....: 'B': [80, 55, 76, 67]})
.....:
In [318]: df
Out[318]:
col A B
0 A 80.0 80
1 A 23.0 55
2 B NaN 76
3 B 22.0 67
In [319]: idx, cols = pd.factorize(df['col'])
In [320]: df.reindex(cols, axis=1).to_numpy()[np.arange(len(df)), idx]
Out[320]: array([80., 23., 76., 67.])
Ранее этого можно было достичь с помощью специального DataFrame.lookup метод, который был устаревшим в версии 1.2.0 и удалён в версии 2.0.0.
Объекты Index#
Pandas Index класс и его подклассы можно рассматривать как
реализующие упорядоченный мультимножество. Дубликаты разрешены.
Index также предоставляет инфраструктуру, необходимую для
поиска, выравнивания данных и переиндексации. Самый простой способ создать
Index непосредственно — это передать list или другую последовательность для
Index:
In [321]: index = pd.Index(['e', 'd', 'a', 'b'])
In [322]: index
Out[322]: Index(['e', 'd', 'a', 'b'], dtype='object')
In [323]: 'd' in index
Out[323]: True
или с использованием чисел:
In [324]: index = pd.Index([1, 5, 12])
In [325]: index
Out[325]: Index([1, 5, 12], dtype='int64')
In [326]: 5 in index
Out[326]: True
Если dtype не указан, Index пытается определить тип данных из данных. Также возможно указать явный тип данных при создании Index:
In [327]: index = pd.Index(['e', 'd', 'a', 'b'], dtype="string")
In [328]: index
Out[328]: Index(['e', 'd', 'a', 'b'], dtype='string')
In [329]: index = pd.Index([1, 5, 12], dtype="int8")
In [330]: index
Out[330]: Index([1, 5, 12], dtype='int8')
In [331]: index = pd.Index([1, 5, 12], dtype="float32")
In [332]: index
Out[332]: Index([1.0, 5.0, 12.0], dtype='float32')
Вы также можете передать name для хранения в индексе:
In [333]: index = pd.Index(['e', 'd', 'a', 'b'], name='something')
In [334]: index.name
Out[334]: 'something'
Имя, если установлено, будет отображаться в консоли:
In [335]: index = pd.Index(list(range(5)), name='rows')
In [336]: columns = pd.Index(['A', 'B', 'C'], name='cols')
In [337]: df = pd.DataFrame(np.random.randn(5, 3), index=index, columns=columns)
In [338]: df
Out[338]:
cols A B C
rows
0 1.295989 -1.051694 1.340429
1 -2.366110 0.428241 0.387275
2 0.433306 0.929548 0.278094
3 2.154730 -0.315628 0.264223
4 1.126818 1.132290 -0.353310
In [339]: df['A']
Out[339]:
rows
0 1.295989
1 -2.366110
2 0.433306
3 2.154730
4 1.126818
Name: A, dtype: float64
Настройка метаданных#
Индексы являются "в основном неизменяемыми", но возможно их установка и изменение
name атрибут. Вы можете использовать rename, set_names для установки этих атрибутов
напрямую, и по умолчанию они возвращают копию.
См. Расширенная индексация для использования MultiIndexes.
In [340]: ind = pd.Index([1, 2, 3])
In [341]: ind.rename("apple")
Out[341]: Index([1, 2, 3], dtype='int64', name='apple')
In [342]: ind
Out[342]: Index([1, 2, 3], dtype='int64')
In [343]: ind = ind.set_names(["apple"])
In [344]: ind.name = "bob"
In [345]: ind
Out[345]: Index([1, 2, 3], dtype='int64', name='bob')
set_names, set_levels, и set_codes также принимает необязательный
level аргумент
In [346]: index = pd.MultiIndex.from_product([range(3), ['one', 'two']], names=['first', 'second'])
In [347]: index
Out[347]:
MultiIndex([(0, 'one'),
(0, 'two'),
(1, 'one'),
(1, 'two'),
(2, 'one'),
(2, 'two')],
names=['first', 'second'])
In [348]: index.levels[1]
Out[348]: Index(['one', 'two'], dtype='object', name='second')
In [349]: index.set_levels(["a", "b"], level=1)
Out[349]:
MultiIndex([(0, 'a'),
(0, 'b'),
(1, 'a'),
(1, 'b'),
(2, 'a'),
(2, 'b')],
names=['first', 'second'])
Операции над множествами для объектов Index#
Две основные операции — union и intersection.
Разница предоставляется через .difference() метод.
In [350]: a = pd.Index(['c', 'b', 'a'])
In [351]: b = pd.Index(['c', 'e', 'd'])
In [352]: a.difference(b)
Out[352]: Index(['a', 'b'], dtype='object')
Также доступен symmetric_difference операция, которая возвращает элементы, присутствующие в любом из idx1 или idx2, но не в обоих. Это эквивалентно Index, созданному idx1.difference(idx2).union(idx2.difference(idx1))с удалёнными дубликатами.
In [353]: idx1 = pd.Index([1, 2, 3, 4])
In [354]: idx2 = pd.Index([2, 3, 4, 5])
In [355]: idx1.symmetric_difference(idx2)
Out[355]: Index([1, 5], dtype='int64')
Примечание
Результирующий индекс из операции над множествами будет отсортирован по возрастанию.
При выполнении Index.union() между индексами с разными типами данных, индексы
должны быть приведены к общему типу. Обычно, хотя и не всегда, это тип object. Исключение —
объединение целочисленных и вещественных данных. В этом случае
целочисленные значения преобразуются в вещественные
In [356]: idx1 = pd.Index([0, 1, 2])
In [357]: idx2 = pd.Index([0.5, 1.5])
In [358]: idx1.union(idx2)
Out[358]: Index([0.0, 0.5, 1.0, 1.5, 2.0], dtype='float64')
Пропущенные значения#
Важно
Хотя Index может содержать пропущенные значения (NaN), его следует избегать, если вы не хотите неожиданных результатов. Например, некоторые операции неявно исключают пропущенные значения.
Index.fillna заполняет пропущенные значения указанным скалярным значением.
In [359]: idx1 = pd.Index([1, np.nan, 3, 4])
In [360]: idx1
Out[360]: Index([1.0, nan, 3.0, 4.0], dtype='float64')
In [361]: idx1.fillna(2)
Out[361]: Index([1.0, 2.0, 3.0, 4.0], dtype='float64')
In [362]: idx2 = pd.DatetimeIndex([pd.Timestamp('2011-01-01'),
.....: pd.NaT,
.....: pd.Timestamp('2011-01-03')])
.....:
In [363]: idx2
Out[363]: DatetimeIndex(['2011-01-01', 'NaT', '2011-01-03'], dtype='datetime64[ns]', freq=None)
In [364]: idx2.fillna(pd.Timestamp('2011-01-02'))
Out[364]: DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03'], dtype='datetime64[ns]', freq=None)
Установить / сбросить индекс#
Иногда вы загрузите или создадите набор данных в DataFrame и захотите добавить индекс после того, как уже это сделали. Есть несколько разных способов.
Установить индекс#
DataFrame имеет set_index() метод, который принимает имя столбца
(для обычного Index) или список имен столбцов (для MultiIndex).
Чтобы создать новый DataFrame с переиндексацией:
In [365]: data = pd.DataFrame({'a': ['bar', 'bar', 'foo', 'foo'],
.....: 'b': ['one', 'two', 'one', 'two'],
.....: 'c': ['z', 'y', 'x', 'w'],
.....: 'd': [1., 2., 3, 4]})
.....:
In [366]: data
Out[366]:
a b c d
0 bar one z 1.0
1 bar two y 2.0
2 foo one x 3.0
3 foo two w 4.0
In [367]: indexed1 = data.set_index('c')
In [368]: indexed1
Out[368]:
a b d
c
z bar one 1.0
y bar two 2.0
x foo one 3.0
w foo two 4.0
In [369]: indexed2 = data.set_index(['a', 'b'])
In [370]: indexed2
Out[370]:
c d
a b
bar one z 1.0
two y 2.0
foo one x 3.0
two w 4.0
The append ключевая опция позволяет сохранить существующий индекс и добавить
заданные столбцы к MultiIndex:
In [371]: frame = data.set_index('c', drop=False)
In [372]: frame = frame.set_index(['a', 'b'], append=True)
In [373]: frame
Out[373]:
c d
c a b
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
Другие опции в set_index позволяет не удалять столбцы индекса.
In [374]: data.set_index('c', drop=False)
Out[374]:
a b c d
c
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
Сбросить индекс#
Для удобства в DataFrame добавлена новая функция
reset_index() который переносит значения индекса в столбцы DataFrame и устанавливает простой целочисленный индекс.
Это обратная операция set_index().
In [375]: data
Out[375]:
a b c d
0 bar one z 1.0
1 bar two y 2.0
2 foo one x 3.0
3 foo two w 4.0
In [376]: data.reset_index()
Out[376]:
index a b c d
0 0 bar one z 1.0
1 1 bar two y 2.0
2 2 foo one x 3.0
3 3 foo two w 4.0
Вывод больше похож на таблицу SQL или массив записей. Имена для
столбцов, полученных из индекса, хранятся в names атрибут.
Вы можете использовать level ключевое слово для удаления только части индекса:
In [377]: frame
Out[377]:
c d
c a b
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
In [378]: frame.reset_index(level=1)
Out[378]:
a c d
c b
z one bar z 1.0
y two bar y 2.0
x one foo x 3.0
w two foo w 4.0
reset_index принимает необязательный параметр drop что если true просто
отбрасывает индекс, вместо помещения значений индекса в столбцы DataFrame.
Добавление специального индекса#
Вы можете назначить пользовательский индекс для index attribute:
In [379]: df_idx = pd.DataFrame(range(4))
In [380]: df_idx.index = pd.Index([10, 20, 30, 40], name="a")
In [381]: df_idx
Out[381]:
0
a
10 0
20 1
30 2
40 3
Возврат представления против копии#
Предупреждение
Копирование при записи
станет новым значением по умолчанию в pandas 3.0. Это означает, что цепочечная индексация никогда не будет работать. Как следствие, SettingWithCopyWarning больше не потребуется.
См. этот раздел
для получения дополнительного контекста.
Мы рекомендуем включить Copy-on-Write, чтобы воспользоваться улучшениями с
`
pd.options.mode.copy_on_write = True
`
даже до того, как pandas 3.0 станет доступной.
При установке значений в объект pandas необходимо соблюдать осторожность, чтобы избежать так называемого
chained indexing. Вот пример.
In [382]: dfmi = pd.DataFrame([list('abcd'),
.....: list('efgh'),
.....: list('ijkl'),
.....: list('mnop')],
.....: columns=pd.MultiIndex.from_product([['one', 'two'],
.....: ['first', 'second']]))
.....:
In [383]: dfmi
Out[383]:
one two
first second first second
0 a b c d
1 e f g h
2 i j k l
3 m n o p
Сравните эти два метода доступа:
In [384]: dfmi['one']['second']
Out[384]:
0 b
1 f
2 j
3 n
Name: second, dtype: object
In [385]: dfmi.loc[:, ('one', 'second')]
Out[385]:
0 b
1 f
2 j
3 n
Name: (one, second), dtype: object
Оба варианта дают одинаковые результаты, так какой из них следует использовать? Полезно понять порядок
операций в них и почему метод 2 (.loc) гораздо предпочтительнее, чем метод 1 (цепочка []).
dfmi['one'] выбирает первый уровень столбцов и возвращает DataFrame с одним индексом.
Затем другая операция Python dfmi_with_one['second'] выбирает серию, индексированную по 'second'.
Это обозначается переменной dfmi_with_one поскольку pandas рассматривает эти операции как отдельные события.
Например, отдельные вызовы __getitem__, поэтому он должен рассматривать их как линейные операции, они выполняются одна за другой.
В отличие от df.loc[:,('one','second')] который передает вложенный кортеж (slice(None),('one','second')) в один вызов
__getitem__. Это позволяет pandas обрабатывать это как единую сущность. Кроме того, этот порядок операций может значительно
быстрее и позволяет индексировать оба оси, если это необходимо.
Почему присваивание не срабатывает при использовании цепочечной индексации?#
Предупреждение
Копирование при записи
станет новым значением по умолчанию в pandas 3.0. Это означает, что цепочечное индексирование никогда не будет работать. Как следствие, SettingWithCopyWarning больше не потребуется.
См. этот раздел
для получения дополнительного контекста.
Мы рекомендуем включить Copy-on-Write, чтобы воспользоваться улучшениями с
`
pd.options.mode.copy_on_write = True
`
даже до того, как pandas 3.0 станет доступной.
Проблема в предыдущем разделе — это лишь вопрос производительности. А что насчёт SettingWithCopy предупреждение? Мы не обычно выдавать предупреждения, когда
вы делаете что-то, что может стоить несколько лишних миллисекунд!
Но оказывается, что присваивание результату цепочечной индексации имеет по своей природе непредсказуемые результаты. Чтобы понять это, подумайте, как интерпретатор Python выполняет этот код:
dfmi.loc[:, ('one', 'second')] = value
# becomes
dfmi.loc.__setitem__((slice(None), ('one', 'second')), value)
Но этот код обрабатывается иначе:
dfmi['one']['second'] = value
# becomes
dfmi.__getitem__('one').__setitem__('second', value)
Обратите внимание, что __getitem__ там? За пределами простых случаев очень сложно
предсказать, вернет ли он представление или копию (это зависит от расположения
памяти массива, о котором pandas не дает гарантий), и, следовательно, будет ли __setitem__ будет изменять dfmi или временный объект, который немедленно
отбрасывается. Это что SettingWithCopy предупреждает вас об этом!
Примечание
Возможно, вы задаётесь вопросом, стоит ли нам беспокоиться о loc
свойство в первом примере. Но dfmi.loc гарантированно будет dfmi
сам объект с измененным поведением индексирования, поэтому dfmi.loc.__getitem__ /
dfmi.loc.__setitem__ работать с dfmi напрямую. Конечно,
dfmi.loc.__getitem__(idx) может быть представлением или копией dfmi.
Иногда SettingWithCopy предупреждение будет возникать в случаях, когда нет
очевидного цепочечного индексирования. Эти это ошибки, которые
SettingWithCopy предназначен для обнаружения! pandas, вероятно, пытается предупредить вас, что вы сделали это:
def do_something(df):
foo = df[['bar', 'baz']] # Is foo a view? A copy? Nobody knows!
# ... many lines here ...
# We don't know whether this will modify df or not!
foo['quux'] = value
return foo
Ой!
Порядок вычислений имеет значение#
Предупреждение
Копирование при записи
станет новым значением по умолчанию в pandas 3.0. Это означает, что цепочечное индексирование никогда не будет работать. Как следствие, SettingWithCopyWarning больше не потребуется.
См. этот раздел
для получения дополнительного контекста.
Мы рекомендуем включить Copy-on-Write, чтобы воспользоваться улучшениями с
`
pd.options.mode.copy_on_write = True
`
даже до того, как pandas 3.0 станет доступной.
При использовании цепочечной индексации порядок и тип операции индексации частично определяют, является ли результат срезом исходного объекта или копией среза.
pandas имеет SettingWithCopyWarning поскольку присваивание копии среза часто не является преднамеренным, а ошибкой, вызванной цепочечной индексацией, возвращающей копию, где ожидался срез.
Если вы хотите, чтобы pandas был более или менее доверчивым при присваивании
цепочке индексации, вы можете установить опция
mode.chained_assignment к одному из этих значений:
'warn', по умолчанию, означаетSettingWithCopyWarningвыводится.'raise'означает, что pandas вызоветSettingWithCopyErrorс которыми вам придётся иметь дело.Noneполностью подавит предупреждения.
In [386]: dfb = pd.DataFrame({'a': ['one', 'one', 'two',
.....: 'three', 'two', 'one', 'six'],
.....: 'c': np.arange(7)})
.....:
# This will show the SettingWithCopyWarning
# but the frame values will be set
In [387]: dfb['c'][dfb['a'].str.startswith('o')] = 42
Однако это работает с копией и не будет функционировать.
In [388]: with pd.option_context('mode.chained_assignment','warn'):
.....: dfb[dfb['a'].str.startswith('o')]['c'] = 42
.....:
Цепное присваивание также может возникнуть при установке значения во фрейме смешанного типа данных.
Примечание
Эти правила настройки применяются ко всем .loc/.iloc.
Следующий метод доступа рекомендуется использовать .loc для нескольких элементов (используя mask) и один элемент с использованием фиксированного индекса:
In [389]: dfc = pd.DataFrame({'a': ['one', 'one', 'two',
.....: 'three', 'two', 'one', 'six'],
.....: 'c': np.arange(7)})
.....:
In [390]: dfd = dfc.copy()
# Setting multiple items using a mask
In [391]: mask = dfd['a'].str.startswith('o')
In [392]: dfd.loc[mask, 'c'] = 42
In [393]: dfd
Out[393]:
a c
0 one 42
1 one 42
2 two 2
3 three 3
4 two 4
5 one 42
6 six 6
# Setting a single item
In [394]: dfd = dfc.copy()
In [395]: dfd.loc[2, 'a'] = 11
In [396]: dfd
Out[396]:
a c
0 one 0
1 one 1
2 11 2
3 three 3
4 two 4
5 one 5
6 six 6
Следующие может может работать временами, но это не гарантируется, и поэтому следует избегать:
In [397]: dfd = dfc.copy()
In [398]: dfd['a'][2] = 111
In [399]: dfd
Out[399]:
a c
0 one 0
1 one 1
2 111 2
3 three 3
4 two 4
5 one 5
6 six 6
Наконец, следующий пример будет не вообще не работают, и их следует избегать:
In [400]: with pd.option_context('mode.chained_assignment','raise'):
.....: dfd.loc[0]['a'] = 1111
.....:
---------------------------------------------------------------------------
SettingWithCopyError Traceback (most recent call last)
Предупреждение
Предупреждения/исключения цепочечного присваивания направлены на информирование пользователя о возможном недопустимом присваивании. Могут быть ложные срабатывания; ситуации, когда цепочечное присваивание ошибочно сообщается.