Улучшение производительности#
В этой части руководства мы исследуем, как ускорить определенные
функции, работающие с pandas DataFrame используя Cython, Numba и pandas.eval().
Как правило, использование Cython и Numba может обеспечить большее ускорение, чем использование pandas.eval()
но потребует гораздо больше кода.
Примечание
В дополнение к следованию шагам этого руководства, пользователям, заинтересованным в повышении производительности, настоятельно рекомендуется установить рекомендуемые зависимости для pandas. Эти зависимости часто не устанавливаются по умолчанию, но обеспечат ускорение при наличии.
-1.#QNAN#
Для многих случаев использования pandas в чистом Python и NumPy достаточно. Однако в некоторых вычислительно сложных приложениях можно достичь значительного ускорения, передавая работу cython.
Это руководство предполагает, что вы провели рефакторинг по максимуму на Python, например, пытаясь удалить циклы for и используя векторизацию NumPy. Всегда стоит сначала оптимизировать на Python.
Это руководство проходит через «типичный» процесс цитонизации медленного вычисления. Мы используем пример из документации Cython но в контексте pandas. Наше окончательное цитонизированное решение примерно в 100 раз быстрее, чем чистое Python-решение.
Чистый Python#
У нас есть DataFrame к которым мы хотим применить функцию построчно.
In [1]: df = pd.DataFrame(
...: {
...: "a": np.random.randn(1000),
...: "b": np.random.randn(1000),
...: "N": np.random.randint(100, 1000, (1000)),
...: "x": "x",
...: }
...: )
...:
In [2]: df
Out[2]:
a b N x
0 0.469112 -0.218470 585 x
1 -0.282863 -0.061645 841 x
2 -1.509059 -0.723780 251 x
3 -1.135632 0.551225 972 x
4 1.212112 -0.497767 181 x
.. ... ... ... ..
995 -1.512743 0.874737 374 x
996 0.933753 1.120790 246 x
997 -0.308013 0.198768 157 x
998 -0.079915 1.757555 977 x
999 -1.010589 -1.115680 770 x
[1000 rows x 4 columns]
Вот функция на чистом Python:
In [3]: def f(x):
...: return x * (x - 1)
...:
In [4]: def integrate_f(a, b, N):
...: s = 0
...: dx = (b - a) / N
...: for i in range(N):
...: s += f(a + i * dx)
...: return s * dx
...:
Мы достигаем нашего результата, используя DataFrame.apply() (по строкам):
In [5]: %timeit df.apply(lambda x: integrate_f(x["a"], x["b"], x["N"]), axis=1)
82.4 ms +- 2.27 ms per loop (mean +- std. dev. of 7 runs, 10 loops each)
Давайте посмотрим, где тратится время во время этой операции, используя магическая функция prun ipython:
# most time consuming 4 calls
In [6]: %prun -l 4 df.apply(lambda x: integrate_f(x["a"], x["b"], x["N"]), axis=1) # noqa E999
605956 function calls (605938 primitive calls) in 0.173 seconds
Ordered by: internal time
List reduced from 163 to 4 due to restriction <4>
ncalls tottime percall cumtime percall filename:lineno(function)
1000 0.102 0.000 0.153 0.000 :1(integrate_f)
552423 0.051 0.000 0.051 0.000 :1(f)
3000 0.003 0.000 0.013 0.000 series.py:1107(__getitem__)
3000 0.002 0.000 0.006 0.000 series.py:1232(_get_value)
Подавляющее большинство времени тратится либо внутри integrate_f или f, поэтому мы сосредоточим наши усилия на цитонизации этих двух функций.
Чистый Cython#
Сначала нам нужно импортировать магическую функцию Cython в IPython:
In [7]: %load_ext Cython
Теперь просто скопируем наши функции в Cython:
In [8]: %%cython
...: def f_plain(x):
...: return x * (x - 1)
...: def integrate_f_plain(a, b, N):
...: s = 0
...: dx = (b - a) / N
...: for i in range(N):
...: s += f_plain(a + i * dx)
...: return s * dx
...:
In [9]: %timeit df.apply(lambda x: integrate_f_plain(x["a"], x["b"], x["N"]), axis=1)
47.4 ms +- 341 us per loop (mean +- std. dev. of 7 runs, 10 loops each)
Это улучшило производительность по сравнению с чистым подходом на Python на одну треть.
Объявление типов C#
Мы можем аннотировать переменные функции и типы возвращаемых значений, а также использовать cdef
и cpdef для повышения производительности:
In [10]: %%cython
....: cdef double f_typed(double x) except? -2:
....: return x * (x - 1)
....: cpdef double integrate_f_typed(double a, double b, int N):
....: cdef int i
....: cdef double s, dx
....: s = 0
....: dx = (b - a) / N
....: for i in range(N):
....: s += f_typed(a + i * dx)
....: return s * dx
....:
In [11]: %timeit df.apply(lambda x: integrate_f_typed(x["a"], x["b"], x["N"]), axis=1)
8.08 ms +- 52.7 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
Аннотирование функций типами C дает более чем десятикратное улучшение производительности по сравнению с оригинальной реализацией на Python.
Использование ndarray#
При повторном профилировании время тратится на создание Series из каждой строки и вызов __getitem__ как из индекса, так и из серии (три раза для каждой строки). Эти вызовы функций Python дорогостоящи и могут быть улучшены путем передачи np.ndarray.
In [12]: %prun -l 4 df.apply(lambda x: integrate_f_typed(x["a"], x["b"], x["N"]), axis=1)
52533 function calls (52515 primitive calls) in 0.020 seconds
Ordered by: internal time
List reduced from 161 to 4 due to restriction <4>
ncalls tottime percall cumtime percall filename:lineno(function)
3000 0.003 0.000 0.013 0.000 series.py:1107(__getitem__)
3000 0.002 0.000 0.006 0.000 series.py:1232(_get_value)
3000 0.002 0.000 0.003 0.000 indexing.py:2801(check_dict_or_set_indexers)
3000 0.002 0.000 0.002 0.000 base.py:3784(get_loc)
In [13]: %%cython
....: cimport numpy as np
....: import numpy as np
....: cdef double f_typed(double x) except? -2:
....: return x * (x - 1)
....: cpdef double integrate_f_typed(double a, double b, int N):
....: cdef int i
....: cdef double s, dx
....: s = 0
....: dx = (b - a) / N
....: for i in range(N):
....: s += f_typed(a + i * dx)
....: return s * dx
....: cpdef np.ndarray[double] apply_integrate_f(np.ndarray col_a, np.ndarray col_b,
....: np.ndarray col_N):
....: assert (col_a.dtype == np.float64
....: and col_b.dtype == np.float64 and col_N.dtype == np.dtype(int))
....: cdef Py_ssize_t i, n = len(col_N)
....: assert (len(col_a) == len(col_b) == n)
....: cdef np.ndarray[double] res = np.empty(n)
....: for i in range(len(col_a)):
....: res[i] = integrate_f_typed(col_a[i], col_b[i], col_N[i])
....: return res
....:
Content of stderr:
In file included from /home/runner/micromamba/envs/test/lib/python3.10/site-packages/numpy/core/include/numpy/ndarraytypes.h:1929,
from /home/runner/micromamba/envs/test/lib/python3.10/site-packages/numpy/core/include/numpy/ndarrayobject.h:12,
from /home/runner/micromamba/envs/test/lib/python3.10/site-packages/numpy/core/include/numpy/arrayobject.h:5,
from /home/runner/.cache/ipython/cython/_cython_magic_6f79c211c83920a2c1a226b721dbaa1a7b937ab1b184711d287bddf3564f713d.c:1149:
/home/runner/micromamba/envs/test/lib/python3.10/site-packages/numpy/core/include/numpy/npy_1_7_deprecated_api.h:17:2: warning: #warning "Using deprecated NumPy API, disable it with " "#define NPY_NO_DEPRECATED_API NPY_1_7_API_VERSION" [-Wcpp]
17 | #warning "Using deprecated NumPy API, disable it with " \
| ^~~~~~~
Эта реализация создает массив нулей и вставляет результат integrate_f_typed применяется к каждой строке. Цикл по ndarray быстрее в Cython, чем перебор по Series объект.
Поскольку apply_integrate_f типизирован для принятия np.ndarray, Series.to_numpy()
вызовы необходимы для использования этой функции.
In [14]: %timeit apply_integrate_f(df["a"].to_numpy(), df["b"].to_numpy(), df["N"].to_numpy())
854 us +- 847 ns per loop (mean +- std. dev. of 7 runs, 1,000 loops each)
Производительность улучшилась по сравнению с предыдущей реализацией почти в десять раз.
Отключение директив компилятора#
Большая часть времени теперь тратится на apply_integrate_f. Отключение Cython boundscheck
и wraparound проверки могут дать большую производительность.
In [15]: %prun -l 4 apply_integrate_f(df["a"].to_numpy(), df["b"].to_numpy(), df["N"].to_numpy())
78 function calls in 0.001 seconds
Ordered by: internal time
List reduced from 21 to 4 due to restriction <4>
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 0.001 0.001 :1()
3 0.000 0.000 0.000 0.000 frame.py:4073(__getitem__)
1 0.000 0.000 0.001 0.001 {built-in method builtins.exec}
3 0.000 0.000 0.000 0.000 base.py:545(to_numpy)
In [16]: %%cython
....: cimport cython
....: cimport numpy as np
....: import numpy as np
....: cdef np.float64_t f_typed(np.float64_t x) except? -2:
....: return x * (x - 1)
....: cpdef np.float64_t integrate_f_typed(np.float64_t a, np.float64_t b, np.int64_t N):
....: cdef np.int64_t i
....: cdef np.float64_t s = 0.0, dx
....: dx = (b - a) / N
....: for i in range(N):
....: s += f_typed(a + i * dx)
....: return s * dx
....: @cython.boundscheck(False)
....: @cython.wraparound(False)
....: cpdef np.ndarray[np.float64_t] apply_integrate_f_wrap(
....: np.ndarray[np.float64_t] col_a,
....: np.ndarray[np.float64_t] col_b,
....: np.ndarray[np.int64_t] col_N
....: ):
....: cdef np.int64_t i, n = len(col_N)
....: assert len(col_a) == len(col_b) == n
....: cdef np.ndarray[np.float64_t] res = np.empty(n, dtype=np.float64)
....: for i in range(n):
....: res[i] = integrate_f_typed(col_a[i], col_b[i], col_N[i])
....: return res
....:
Content of stderr:
In file included from /home/runner/micromamba/envs/test/lib/python3.10/site-packages/numpy/core/include/numpy/ndarraytypes.h:1929,
from /home/runner/micromamba/envs/test/lib/python3.10/site-packages/numpy/core/include/numpy/ndarrayobject.h:12,
from /home/runner/micromamba/envs/test/lib/python3.10/site-packages/numpy/core/include/numpy/arrayobject.h:5,
from /home/runner/.cache/ipython/cython/_cython_magic_27218b06da183432f48b9a15b771ea1138d351147accb5fdbe8c5112e23dc4ae.c:1150:
/home/runner/micromamba/envs/test/lib/python3.10/site-packages/numpy/core/include/numpy/npy_1_7_deprecated_api.h:17:2: warning: #warning "Using deprecated NumPy API, disable it with " "#define NPY_NO_DEPRECATED_API NPY_1_7_API_VERSION" [-Wcpp]
17 | #warning "Using deprecated NumPy API, disable it with " \
| ^~~~~~~
In [17]: %timeit apply_integrate_f_wrap(df["a"].to_numpy(), df["b"].to_numpy(), df["N"].to_numpy())
624 us +- 506 ns per loop (mean +- std. dev. of 7 runs, 1,000 loops each)
Однако индексатор цикла i обращение к недопустимому местоположению в массиве вызывало ошибку сегментации, потому что доступ к памяти не проверялся.
Подробнее о boundscheck и wraparound, см. документацию Cython по
директивы компилятора.
Numba (JIT-компиляция)#
Альтернативой статической компиляции кода Cython является использование динамического JIT-компилятора (just-in-time) с Numba.
Numba позволяет написать чистую функцию на Python, которая может быть JIT-скомпилирована в нативные машинные инструкции, с производительностью, сравнимой с C, C++ и Fortran,
путем декорирования вашей функции с помощью @jit.
Numba работает путем генерации оптимизированного машинного кода с использованием инфраструктуры компилятора LLVM во время импорта, выполнения или статически (с помощью встроенного инструмента pycc). Numba поддерживает компиляцию Python для запуска на CPU или GPU оборудовании и предназначена для интеграции со стеком научного программного обеспечения Python.
Примечание
The @jit компиляция добавит накладные расходы на время выполнения функции, поэтому преимущества производительности могут не быть реализованы, особенно при использовании небольших наборов данных.
Рассмотрите кэширование вашу функцию, чтобы избежать накладных расходов на компиляцию каждый раз при запуске функции.
Numba можно использовать с pandas двумя способами:
Укажите
engine="numba"ключевое слово в некоторых методах pandasОпределите свою собственную функцию Python, декорированную с помощью
@jitи передать базовый массив NumPy изSeriesилиDataFrame(используяSeries.to_numpy()) в функцию
Движок pandas Numba#
Если установлен Numba, можно указать engine="numba" в некоторых методах pandas для выполнения метода с использованием Numba.
Методы, поддерживающие engine="numba" также будет иметь engine_kwargs ключевое слово, которое принимает словарь, позволяющий указать
"nogil", "nopython" и "parallel" ключи с булевыми значениями для передачи в @jit декоратор.
Если engine_kwargs не указан, по умолчанию используется {"nogil": False, "nopython": True, "parallel": False} если не указано иное.
Примечание
С точки зрения производительности, первый запуск функции с использованием движка Numba будет медленным поскольку Numba имеет некоторые накладные расходы на компиляцию функций. Однако JIT-скомпилированные функции кэшируются, и последующие вызовы будут быстрыми. В целом, движок Numba производителен при большом объеме данных (например, 1+ миллион).
In [1]: data = pd.Series(range(1_000_000)) # noqa: E225
In [2]: roll = data.rolling(10)
In [3]: def f(x):
...: return np.sum(x) + 5
# Run the first time, compilation time will affect performance
In [4]: %timeit -r 1 -n 1 roll.apply(f, engine='numba', raw=True)
1.23 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
# Function is cached and performance will improve
In [5]: %timeit roll.apply(f, engine='numba', raw=True)
188 ms ± 1.93 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
In [6]: %timeit roll.apply(f, engine='cython', raw=True)
3.92 s ± 59 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Если ваше вычислительное оборудование содержит несколько процессоров, наибольший прирост производительности может быть достигнут путем установки parallel to True
для использования более чем 1 CPU. Внутренне pandas использует numba для распараллеливания вычислений по столбцам DataFrame;
поэтому это преимущество производительности полезно только для DataFrame с большим количеством столбцов.
In [1]: import numba
In [2]: numba.set_num_threads(1)
In [3]: df = pd.DataFrame(np.random.randn(10_000, 100))
In [4]: roll = df.rolling(100)
In [5]: %timeit roll.mean(engine="numba", engine_kwargs={"parallel": True})
347 ms ± 26 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [6]: numba.set_num_threads(2)
In [7]: %timeit roll.mean(engine="numba", engine_kwargs={"parallel": True})
201 ms ± 2.97 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Примеры пользовательских функций#
Пользовательская функция Python, украшенная @jit может использоваться с объектами pandas путем передачи их представлений в виде массивов NumPy с Series.to_numpy().
import numba
@numba.jit
def f_plain(x):
return x * (x - 1)
@numba.jit
def integrate_f_numba(a, b, N):
s = 0
dx = (b - a) / N
for i in range(N):
s += f_plain(a + i * dx)
return s * dx
@numba.jit
def apply_integrate_f_numba(col_a, col_b, col_N):
n = len(col_N)
result = np.empty(n, dtype="float64")
assert len(col_a) == len(col_b) == n
for i in range(n):
result[i] = integrate_f_numba(col_a[i], col_b[i], col_N[i])
return result
def compute_numba(df):
result = apply_integrate_f_numba(
df["a"].to_numpy(), df["b"].to_numpy(), df["N"].to_numpy()
)
return pd.Series(result, index=df.index, name="result")
In [4]: %timeit compute_numba(df)
1000 loops, best of 3: 798 us per loop
В этом примере использование Numba было быстрее, чем Cython.
Numba также может использоваться для написания векторизованных функций, не требующих от пользователя явного цикла по наблюдениям вектора; векторизованная функция будет автоматически применяться к каждой строке. Рассмотрим следующий пример удвоения каждого наблюдения:
import numba
def double_every_value_nonumba(x):
return x * 2
@numba.vectorize
def double_every_value_withnumba(x): # noqa E501
return x * 2
# Custom function without numba
In [5]: %timeit df["col1_doubled"] = df["a"].apply(double_every_value_nonumba) # noqa E501
1000 loops, best of 3: 797 us per loop
# Standard implementation (faster than a custom function)
In [6]: %timeit df["col1_doubled"] = df["a"] * 2
1000 loops, best of 3: 233 us per loop
# Custom function with numba
In [7]: %timeit df["col1_doubled"] = double_every_value_withnumba(df["a"].to_numpy())
1000 loops, best of 3: 145 us per loop
Предостережения#
Numba лучше всего ускоряет функции, которые применяют числовые функции к массивам NumPy.
Если вы попытаетесь @jit функция, содержащая неподдерживаемые Python
или NumPy
код, компиляция вернется режим object что, скорее всего, не ускорит вашу функцию. Если вы предпочитаете, чтобы Numba выдавала ошибку, когда не может скомпилировать функцию таким образом, чтобы ускорить ваш код, передайте Numba аргумент
nopython=True (например, @jit(nopython=True)). Для получения дополнительной информации
по устранению неполадок режимов Numba, см. больше не будет сортировать ось не-конкатенации, когда она не выровнена.
Текущее поведение такое же, как и предыдущее (сортировка), но теперь выдаётся предупреждение, когда.
Используя parallel=True (например, @jit(parallel=True)) может привести к SIGABRT если слой потоков приводит к небезопасному
поведению. Вы можете сначала указать безопасный слой потоков
перед запуском JIT-функции с parallel=True.
Обычно, если вы столкнулись с ошибкой сегментации (SIGSEGV) при использовании Numba, пожалуйста, сообщите о проблеме
в Трекер проблем Numba.
Вычисление выражений через eval()#
Функция верхнего уровня pandas.eval() реализует производительное вычисление выражений для
Series и DataFrameВычисление выражений позволяет представлять операции в виде строк и может потенциально повысить производительность, вычисляя арифметические и логические выражения все сразу для больших DataFrame.
Примечание
Вам не следует использовать eval() для простых
выражений или выражений с небольшими DataFrames. Фактически,
eval() на несколько порядков медленнее для
меньших выражений или объектов, чем чистый Python. Хорошее правило —
использовать только eval() когда у вас есть
DataFrame с более чем 10 000 строк.
Поддерживаемый синтаксис#
Эти операции поддерживаются pandas.eval():
Арифметические операции, кроме сдвига влево (
<<) и сдвиг вправо (>>) операторы, например,df + 2 * pi / s ** 4 % 42 - the_golden_ratioОперации сравнения, включая цепочки сравнений, например,
2 < df < df2Булевы операции, например,
df < df2 and df3 < df4 or not df_boollistиtupleлитералы, например,[1, 2]или(1, 2)Доступ к атрибутам, например,
df.aВыражения с подстрочными индексами, например,
df[0]Простая оценка переменной, например,
pd.eval("df")(это не очень полезно)Математические функции:
sin,cos,exp,log,expm1,log1p,sqrt,sinh,cosh,tanh,arcsin,arccos,arctan,arccosh,arcsinh,arctanh,abs,arctan2иlog10.
Следующий синтаксис Python является не разрешено:
Выражения
Вызовы функций, кроме математических функций.
is/is notоперацииifвыраженияlambdaвыраженияlist/set/dictгенераторы списковLiteral
dictиsetвыраженияyieldвыраженияВыражения-генераторы
Логические выражения, состоящие только из скалярных значений
Операторы
Локальные переменные#
Вы должны явно ссылаться любую локальную переменную, которую вы хотите использовать в
выражении, поместив @ символ перед именем. Этот механизм
одинаков для обоих DataFrame.query() и DataFrame.eval(). Например,
In [18]: df = pd.DataFrame(np.random.randn(5, 2), columns=list("ab"))
In [19]: newcol = np.random.randn(len(df))
In [20]: df.eval("b + @newcol")
Out[20]:
0 -0.206122
1 -1.029587
2 0.519726
3 -2.052589
4 1.453210
dtype: float64
In [21]: df.query("b < @newcol")
Out[21]:
a b
1 0.160268 -0.848896
3 0.333758 -1.180355
4 0.572182 0.439895
Если вы не добавите префикс к локальной переменной @, pandas будет вызывать исключение, сообщая, что переменная не определена.
При использовании DataFrame.eval() и DataFrame.query(), это позволяет вам
иметь локальную переменную и DataFrame столбец с тем же именем в выражении.
In [22]: a = np.random.randn()
In [23]: df.query("@a < a")
Out[23]:
a b
0 0.473349 0.891236
1 0.160268 -0.848896
2 0.803311 1.662031
3 0.333758 -1.180355
4 0.572182 0.439895
In [24]: df.loc[a < df["a"]] # same as the previous expression
Out[24]:
a b
0 0.473349 0.891236
1 0.160268 -0.848896
2 0.803311 1.662031
3 0.333758 -1.180355
4 0.572182 0.439895
Предупреждение
pandas.eval() вызовет исключение, если вы не можете использовать @ префикс, потому что он не определен в этом контексте.
In [25]: a, b = 1, 2
In [26]: pd.eval("@a + b")
Traceback (most recent call last):
File ~/micromamba/envs/test/lib/python3.10/site-packages/IPython/core/interactiveshell.py:3579 in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
Cell In[26], line 1
pd.eval("@a + b")
File ~/work/pandas/pandas/pandas/core/computation/eval.py:328 in eval
_check_for_locals(expr, level, parser)
File ~/work/pandas/pandas/pandas/core/computation/eval.py:170 in _check_for_locals
raise SyntaxError(msg)
File В этом случае вы должны просто ссылаться на переменные, как в стандартном Python.
In [27]: pd.eval("a + b")
Out[27]: 3
pandas.eval() парсеры#
Существует два разных парсера синтаксиса выражений.
По умолчанию 'pandas' парсер позволяет использовать более интуитивный синтаксис для выражения
операций, подобных запросам (сравнения, конъюнкции и дизъюнкции). В частности, приоритет & и | операторов устанавливается равным
приоритету соответствующих булевых операций and и or.
Например, приведённую выше конъюнкцию можно записать без скобок.
В качестве альтернативы можно использовать 'python' парсер для обеспечения строгой семантики Python.
In [28]: nrows, ncols = 20000, 100
In [29]: df1, df2, df3, df4 = [pd.DataFrame(np.random.randn(nrows, ncols)) for _ in range(4)]
In [30]: expr = "(df1 > 0) & (df2 > 0) & (df3 > 0) & (df4 > 0)"
In [31]: x = pd.eval(expr, parser="python")
In [32]: expr_no_parens = "df1 > 0 & df2 > 0 & df3 > 0 & df4 > 0"
In [33]: y = pd.eval(expr_no_parens, parser="pandas")
In [34]: np.all(x == y)
Out[34]: True
То же выражение можно «связать» с помощью слова and также:
In [35]: expr = "(df1 > 0) & (df2 > 0) & (df3 > 0) & (df4 > 0)"
In [36]: x = pd.eval(expr, parser="python")
In [37]: expr_with_ands = "df1 > 0 and df2 > 0 and df3 > 0 and df4 > 0"
In [38]: y = pd.eval(expr_with_ands, parser="pandas")
In [39]: np.all(x == y)
Out[39]: True
The and и or операторы здесь имеют тот же приоритет, что и
в Python.
pandas.eval() движки#
Существует два разных механизма выражений.
The 'numexpr' engine — это более производительный движок, который может обеспечить улучшение производительности по сравнению со стандартным синтаксисом Python для больших DataFrame. Этот движок требует необязательную зависимость numexpr должен быть установлен.
The 'python' движок обычно не полезен только для тестирования других механизмов оценки. Вы достигнете нет преимущества производительности
используя eval() с engine='python' и может привести к снижению производительности.
In [40]: %timeit df1 + df2 + df3 + df4
8.54 ms +- 181 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
In [41]: %timeit pd.eval("df1 + df2 + df3 + df4", engine="python")
9.65 ms +- 139 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
The DataFrame.eval() метод#
В дополнение к верхнему уровню pandas.eval() функцию вы также можете оценить выражение в «контексте» DataFrame.
In [42]: df = pd.DataFrame(np.random.randn(5, 2), columns=["a", "b"])
In [43]: df.eval("a + b")
Out[43]:
0 -0.161099
1 0.805452
2 0.747447
3 1.189042
4 -2.057490
dtype: float64
Любое выражение, которое является допустимым pandas.eval() выражение также является допустимым
DataFrame.eval() выражение, с дополнительным преимуществом, что вам не нужно
префикс имени DataFrame к столбцу(ам), которые
вас интересуют для оценки.
Кроме того, вы можете выполнять присваивание столбцов внутри выражения. Это позволяет формульное вычисление. Целью присваивания может быть новое имя столбца или существующее имя столбца, и оно должно быть допустимым идентификатором Python.
In [44]: df = pd.DataFrame(dict(a=range(5), b=range(5, 10)))
In [45]: df = df.eval("c = a + b")
In [46]: df = df.eval("d = a + b + c")
In [47]: df = df.eval("a = 1")
In [48]: df
Out[48]:
a b c d
0 1 5 5 10
1 1 6 7 14
2 1 7 9 18
3 1 8 11 22
4 1 9 13 26
Копия DataFrame возвращается с новыми или изменёнными столбцами, а исходный фрейм остаётся неизменным.
In [49]: df
Out[49]:
a b c d
0 1 5 5 10
1 1 6 7 14
2 1 7 9 18
3 1 8 11 22
4 1 9 13 26
In [50]: df.eval("e = a - c")
Out[50]:
a b c d e
0 1 5 5 10 -4
1 1 6 7 14 -6
2 1 7 9 18 -8
3 1 8 11 22 -10
4 1 9 13 26 -12
In [51]: df
Out[51]:
a b c d
0 1 5 5 10
1 1 6 7 14
2 1 7 9 18
3 1 8 11 22
4 1 9 13 26
Множественное присвоение столбцов может быть выполнено с использованием многострочной строки.
In [52]: df.eval(
....: """
....: c = a + b
....: d = a + b + c
....: a = 1""",
....: )
....:
Out[52]:
a b c d
0 1 5 6 12
1 1 6 7 14
2 1 7 8 16
3 1 8 9 18
4 1 9 10 20
Эквивалент в стандартном Python будет
In [53]: df = pd.DataFrame(dict(a=range(5), b=range(5, 10)))
In [54]: df["c"] = df["a"] + df["b"]
In [55]: df["d"] = df["a"] + df["b"] + df["c"]
In [56]: df["a"] = 1
In [57]: df
Out[57]:
a b c d
0 1 5 5 10
1 1 6 7 14
2 1 7 9 18
3 1 8 11 22
4 1 9 13 26
eval() сравнение производительности#
pandas.eval() хорошо работает с выражениями, содержащими большие массивы.
In [58]: nrows, ncols = 20000, 100
In [59]: df1, df2, df3, df4 = [pd.DataFrame(np.random.randn(nrows, ncols)) for _ in range(4)]
DataFrame арифметика:
In [60]: %timeit df1 + df2 + df3 + df4
8.9 ms +- 220 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
In [61]: %timeit pd.eval("df1 + df2 + df3 + df4")
3.58 ms +- 164 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
DataFrame сравнение:
In [62]: %timeit (df1 > 0) & (df2 > 0) & (df3 > 0) & (df4 > 0)
5.69 ms +- 104 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
In [63]: %timeit pd.eval("(df1 > 0) & (df2 > 0) & (df3 > 0) & (df4 > 0)")
9.13 ms +- 80.9 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
DataFrame арифметические операции с невыровненными осями.
In [64]: s = pd.Series(np.random.randn(50))
In [65]: %timeit df1 + df2 + df3 + df4 + s
14.3 ms +- 515 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
In [66]: %timeit pd.eval("df1 + df2 + df3 + df4 + s")
4.3 ms +- 123 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
Примечание
Операции, такие как
1 and 2 # would parse to 1 & 2, but should evaluate to 2
3 or 4 # would parse to 3 | 4, but should evaluate to 3
~1 # this is okay, but slower when using eval
должно выполняться в Python. Исключение будет вызвано, если вы попытаетесь
выполнить любые булевы/битовые операции со скалярными операндами, которые не
имеют тип bool или np.bool_.
Вот график, показывающий время выполнения
pandas.eval() как функция размера фрейма, участвующего в
вычислениях. Две линии представляют два разных движка.
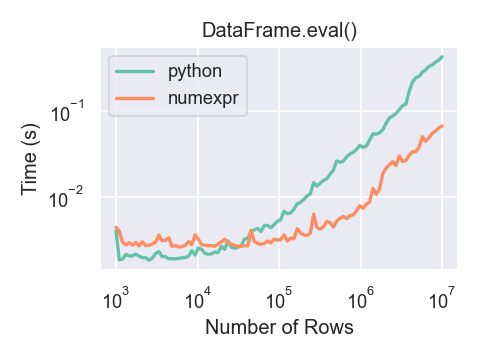
Вы увидите преимущества в производительности только при использовании numexpr движок с pandas.eval() если ваш DataFrame
имеет более примерно 100 000 строк.
Этот график был создан с использованием DataFrame с 3 столбцами, каждый из которых содержит значения с плавающей точкой, сгенерированные с помощью numpy.random.randn().
Ограничения вычисления выражений с numexpr#
Выражения, которые приведут к типу данных object или включают операции с датой и временем из-за NaT должен быть вычислен в пространстве Python, но часть выражения
все еще может быть вычислена с помощью numexpr. Например:
In [67]: df = pd.DataFrame(
....: {"strings": np.repeat(list("cba"), 3), "nums": np.repeat(range(3), 3)}
....: )
....:
In [68]: df
Out[68]:
strings nums
0 c 0
1 c 0
2 c 0
3 b 1
4 b 1
5 b 1
6 a 2
7 a 2
8 a 2
In [69]: df.query("strings == 'a' and nums == 1")
Out[69]:
Empty DataFrame
Columns: [strings, nums]
Index: []
Числовая часть сравнения (nums == 1) будет вычислен
numexpr и объектная часть сравнения ("strings == 'a') будет вычислено Python.