Работа с пропущенными данными#
Значения, считающиеся "пропущенными"#
pandas использует разные значения-метки для представления пропущенных (также называемых NA) в зависимости от типа данных.
numpy.nan для типов данных NumPy. Недостаток использования типов данных NumPy заключается в том, что исходный тип данных будет приведён к np.float64 или object.
In [1]: pd.Series([1, 2], dtype=np.int64).reindex([0, 1, 2])
Out[1]:
0 1.0
1 2.0
2 NaN
dtype: float64
In [2]: pd.Series([True, False], dtype=np.bool_).reindex([0, 1, 2])
Out[2]:
0 True
1 False
2 NaN
dtype: object
NaT для NumPy np.datetime64, np.timedelta64, и PeriodDtype. Для типизации
используйте api.types.NaTType.
In [3]: pd.Series([1, 2], dtype=np.dtype("timedelta64[ns]")).reindex([0, 1, 2])
Out[3]:
0 0 days 00:00:00.000000001
1 0 days 00:00:00.000000002
2 NaT
dtype: timedelta64[ns]
In [4]: pd.Series([1, 2], dtype=np.dtype("datetime64[ns]")).reindex([0, 1, 2])
Out[4]:
0 1970-01-01 00:00:00.000000001
1 1970-01-01 00:00:00.000000002
2 NaT
dtype: datetime64[ns]
In [5]: pd.Series(["2020", "2020"], dtype=pd.PeriodDtype("D")).reindex([0, 1, 2])
Out[5]:
0 2020-01-01
1 2020-01-01
2 NaT
dtype: period[D]
NA для StringDtype, Int64Dtype (и другие разрядности),
Float64Dtype`(and other bit widths), :class:`BooleanDtype и ArrowDtype.
Эти типы будут сохранять исходный тип данных.
Для приложений типизации используйте api.types.NAType.
In [6]: pd.Series([1, 2], dtype="Int64").reindex([0, 1, 2])
Out[6]:
0 1
1 2
2 Для обнаружения этих пропущенных значений используйте isna() или notna() методы.
In [8]: ser = pd.Series([pd.Timestamp("2020-01-01"), pd.NaT])
In [9]: ser
Out[9]:
0 2020-01-01
1 NaT
dtype: datetime64[ns]
In [10]: pd.isna(ser)
Out[10]:
0 False
1 True
dtype: bool
Примечание
isna() или notna() также будет учитывать None пропущенное значение.
In [11]: ser = pd.Series([1, None], dtype=object)
In [12]: ser
Out[12]:
0 1
1 None
dtype: object
In [13]: pd.isna(ser)
Out[13]:
0 False
1 True
dtype: bool
Предупреждение
Сравнения на равенство между np.nan, NaT, и NA
не ведут себя как None
In [14]: None == None # noqa: E711
Out[14]: True
In [15]: np.nan == np.nan
Out[15]: False
In [16]: pd.NaT == pd.NaT
Out[16]: False
In [17]: pd.NA == pd.NA
Out[17]: Поэтому сравнение на равенство между DataFrame или Series
с одним из этих пропущенных значений не предоставляет ту же информацию, что и
isna() или notna().
In [18]: ser = pd.Series([True, None], dtype="boolean[pyarrow]")
In [19]: ser == pd.NA
Out[19]:
0 NA семантика#
Предупреждение
Экспериментально: поведение NA` всё ещё может измениться без предупреждения.
Начиная с pandas 1.0, экспериментальный NA значение (синглтон) доступно для представления скалярных пропущенных значений. Цель NA предоставляет
индикатор "пропущенных" значений, который можно использовать последовательно для всех типов данных
(вместо np.nan, None или pd.NaT в зависимости от типа данных).
Например, при наличии пропущенных значений в Series с nullable integer dtype, будет использовать NA:
In [21]: s = pd.Series([1, 2, None], dtype="Int64")
In [22]: s
Out[22]:
0 1
1 2
2 В настоящее время pandas еще не использует эти типы данных, используя NA по умолчанию DataFrame или Series, поэтому вам нужно указать
type явно. Простой способ преобразования в эти типы данных объясняется в
раздел преобразования.
Распространение в арифметических и операциях сравнения#
В общем случае, отсутствующие значения распространять в операциях с участием NA. Когда
один из операндов неизвестен, результат операции также неизвестен.
Например, NA распространяется в арифметических операциях, аналогично
np.nan:
In [25]: pd.NA + 1
Out[25]: Есть несколько особых случаев, когда результат известен, даже если один из
операндов NA.
In [27]: pd.NA ** 0
Out[27]: 1
In [28]: 1 ** pd.NA
Out[28]: 1
В операциях равенства и сравнения, NA также распространяется. Это отклоняется
от поведения np.nan, где сравнения с np.nan всегда
возвращает False.
In [29]: pd.NA == 1
Out[29]: Чтобы проверить, равно ли значение NA, используйте isna()
In [32]: pd.isna(pd.NA)
Out[32]: True
Примечание
Исключением из этого базового правила распространения являются редукции (таких как среднее значение или минимум), где pandas по умолчанию пропускает отсутствующие значения. См. раздел расчёта подробнее.
Логические операции#
Для логических операций, NA следует правилам
трехзначная логика (или
Логика Клини, аналогично R, SQL и Julia). Эта логика означает распространение пропущенных значений только тогда, когда это логически необходимо.
Например, для логической операции «или» (|), если один из операндов
является True, мы уже знаем, что результат будет True, независимо от
другого значения (так что независимо от того, что пропущенное значение будет True или False).
В этом случае, NA не распространяется:
In [33]: True | False
Out[33]: True
In [34]: True | pd.NA
Out[34]: True
In [35]: pd.NA | True
Out[35]: True
С другой стороны, если один из операндов False, результат зависит
от значения другого операнда. Поэтому в этом случае NA
распространяет:
In [36]: False | True
Out[36]: True
In [37]: False | False
Out[37]: False
In [38]: False | pd.NA
Out[38]: Поведение логической операции "и" (&) может быть получено с использованием
аналогичной логики (где теперь NA не будет распространяться, если один из операндов
уже False):
In [39]: False & True
Out[39]: False
In [40]: False & False
Out[40]: False
In [41]: False & pd.NA
Out[41]: False
In [42]: True & True
Out[42]: True
In [43]: True & False
Out[43]: False
In [44]: True & pd.NA
Out[44]: NA в булевом контексте#
Поскольку фактическое значение NA неизвестно, преобразование NA в логическое значение неоднозначно.
In [45]: bool(pd.NA)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[45], line 1
----> 1 bool(pd.NA)
File ~/work/pandas/pandas/pandas/_libs/missing.pyx:392, in pandas._libs.missing.NAType.__bool__()
TypeError: boolean value of NA is ambiguous
Это также означает, что NA нельзя использовать в контексте, где он оценивается как булево значение, например if condition: ... где condition может
потенциально быть NA. В таких случаях, isna() можно использовать для проверки
на NA или condition будучи NA можно избежать, например, заполнив пропущенные значения заранее.
Аналогичная ситуация возникает при использовании Series или DataFrame объекты в if
операторы, см. Использование операторов if/truth с pandas.
NumPy ufuncs#
pandas.NA реализует NumPy __array_ufunc__ протокол. Большинство ufuncs
работают с NA, и обычно возвращают NA:
In [46]: np.log(pd.NA)
Out[46]: Предупреждение
В настоящее время, уфункции, включающие ndarray и NA вернет объект типа object, заполненный значениями NA.
In [48]: a = np.array([1, 2, 3])
In [49]: np.greater(a, pd.NA)
Out[49]: array([, , ], dtype=object)
Тип возвращаемого значения здесь может измениться, чтобы возвращать другой тип массива в будущем.
См. Совместимость DataFrame с функциями NumPy для получения дополнительной информации о ufuncs.
Преобразование#
Если у вас есть DataFrame или Series используя np.nan,
Series.convert_dtypes() и DataFrame.convert_dtypes()
в DataFrame который может преобразовывать данные для использования типов данных, которые используют NA
такие как Int64Dtype или ArrowDtype. Это особенно полезно после чтения
наборов данных из методов ввода-вывода, где типы данных были выведены.
В этом примере, хотя типы данных всех столбцов изменены, мы показываем результаты для первых 10 столбцов.
In [50]: import io
In [51]: data = io.StringIO("a,b\n,True\n2,")
In [52]: df = pd.read_csv(data)
In [53]: df.dtypes
Out[53]:
a float64
b object
dtype: object
In [54]: df_conv = df.convert_dtypes()
In [55]: df_conv
Out[55]:
a b
0 True
1 2 Вставка пропущенных данных#
Вы можете вставить пропущенные значения, просто присвоив Series или DataFrame.
Сентинель для пропущенных значений будет выбран на основе типа данных.
In [57]: ser = pd.Series([1., 2., 3.])
In [58]: ser.loc[0] = None
In [59]: ser
Out[59]:
0 NaN
1 2.0
2 3.0
dtype: float64
In [60]: ser = pd.Series([pd.Timestamp("2021"), pd.Timestamp("2021")])
In [61]: ser.iloc[0] = np.nan
In [62]: ser
Out[62]:
0 NaT
1 2021-01-01
dtype: datetime64[ns]
In [63]: ser = pd.Series([True, False], dtype="boolean[pyarrow]")
In [64]: ser.iloc[0] = None
In [65]: ser
Out[65]:
0 Для object типы, pandas будет использовать заданное значение:
In [66]: s = pd.Series(["a", "b", "c"], dtype=object)
In [67]: s.loc[0] = None
In [68]: s.loc[1] = np.nan
In [69]: s
Out[69]:
0 None
1 NaN
2 c
dtype: object
Вычисления с пропущенными данными#
Пропущенные значения распространяются через арифметические операции между объектами pandas.
In [70]: ser1 = pd.Series([np.nan, np.nan, 2, 3])
In [71]: ser2 = pd.Series([np.nan, 1, np.nan, 4])
In [72]: ser1
Out[72]:
0 NaN
1 NaN
2 2.0
3 3.0
dtype: float64
In [73]: ser2
Out[73]:
0 NaN
1 1.0
2 NaN
3 4.0
dtype: float64
In [74]: ser1 + ser2
Out[74]:
0 NaN
1 NaN
2 NaN
3 7.0
dtype: float64
Описательная статистика и вычислительные методы, обсуждаемые в обзор структуры данных (и перечисленные здесь и здесь) все учитывают отсутствующие данные.
При суммировании данных значения NA или пустые данные будут обрабатываться как ноль.
In [75]: pd.Series([np.nan]).sum()
Out[75]: 0.0
In [76]: pd.Series([], dtype="float64").sum()
Out[76]: 0.0
При вычислении произведения значения NA или пустые данные будут рассматриваться как 1.
In [77]: pd.Series([np.nan]).prod()
Out[77]: 1.0
In [78]: pd.Series([], dtype="float64").prod()
Out[78]: 1.0
Кумулятивные методы, такие как cumsum() и cumprod()
игнорировать значения NA по умолчанию, сохраняя их в результате. Это поведение можно изменить
с помощью skipna
Кумулятивные методы, такие как
cumsum()иcumprod()игнорировать значения NA по умолчанию, но сохранять их в результирующих массивах. Чтобы переопределить это поведение и включить значения NA, используйтеskipna=False.
In [79]: ser = pd.Series([1, np.nan, 3, np.nan])
In [80]: ser
Out[80]:
0 1.0
1 NaN
2 3.0
3 NaN
dtype: float64
In [81]: ser.cumsum()
Out[81]:
0 1.0
1 NaN
2 4.0
3 NaN
dtype: float64
In [82]: ser.cumsum(skipna=False)
Out[82]:
0 1.0
1 NaN
2 NaN
3 NaN
dtype: float64
Удаление пропущенных данных#
dropna() удалить строки или столбцы с отсутствующими данными.
In [83]: df = pd.DataFrame([[np.nan, 1, 2], [1, 2, np.nan], [1, 2, 3]])
In [84]: df
Out[84]:
0 1 2
0 NaN 1 2.0
1 1.0 2 NaN
2 1.0 2 3.0
In [85]: df.dropna()
Out[85]:
0 1 2
2 1.0 2 3.0
In [86]: df.dropna(axis=1)
Out[86]:
1
0 1
1 2
2 2
In [87]: ser = pd.Series([1, pd.NA], dtype="int64[pyarrow]")
In [88]: ser.dropna()
Out[88]:
0 1
dtype: int64[pyarrow]
Заполнение пропущенных данных#
Заполнение значением#
fillna() заменяет значения NA на не-NA данные.
Заменить NA скалярным значением
In [89]: data = {"np": [1.0, np.nan, np.nan, 2], "arrow": pd.array([1.0, pd.NA, pd.NA, 2], dtype="float64[pyarrow]")}
In [90]: df = pd.DataFrame(data)
In [91]: df
Out[91]:
np arrow
0 1.0 1.0
1 NaN Заполнение пропусков вперед или назад
In [93]: df.ffill()
Out[93]:
np arrow
0 1.0 1.0
1 1.0 1.0
2 1.0 1.0
3 2.0 2.0
In [94]: df.bfill()
Out[94]:
np arrow
0 1.0 1.0
1 2.0 2.0
2 2.0 2.0
3 2.0 2.0
Ограничить количество заполняемых значений NA
In [95]: df.ffill(limit=1)
Out[95]:
np arrow
0 1.0 1.0
1 1.0 1.0
2 NaN Значения NA могут быть заменены соответствующим значением из Series или DataFrame
где индекс и столбец выравниваются между исходным объектом и заполненным объектом.
In [96]: dff = pd.DataFrame(np.arange(30, dtype=np.float64).reshape(10, 3), columns=list("ABC"))
In [97]: dff.iloc[3:5, 0] = np.nan
In [98]: dff.iloc[4:6, 1] = np.nan
In [99]: dff.iloc[5:8, 2] = np.nan
In [100]: dff
Out[100]:
A B C
0 0.0 1.0 2.0
1 3.0 4.0 5.0
2 6.0 7.0 8.0
3 NaN 10.0 11.0
4 NaN NaN 14.0
5 15.0 NaN NaN
6 18.0 19.0 NaN
7 21.0 22.0 NaN
8 24.0 25.0 26.0
9 27.0 28.0 29.0
In [101]: dff.fillna(dff.mean())
Out[101]:
A B C
0 0.00 1.0 2.000000
1 3.00 4.0 5.000000
2 6.00 7.0 8.000000
3 14.25 10.0 11.000000
4 14.25 14.5 14.000000
5 15.00 14.5 13.571429
6 18.00 19.0 13.571429
7 21.00 22.0 13.571429
8 24.00 25.0 26.000000
9 27.00 28.0 29.000000
Примечание
DataFrame.where() также может использоваться для заполнения значений NA. Тот же результат, что и выше.
In [102]: dff.where(pd.notna(dff), dff.mean(), axis="columns")
Out[102]:
A B C
0 0.00 1.0 2.000000
1 3.00 4.0 5.000000
2 6.00 7.0 8.000000
3 14.25 10.0 11.000000
4 14.25 14.5 14.000000
5 15.00 14.5 13.571429
6 18.00 19.0 13.571429
7 21.00 22.0 13.571429
8 24.00 25.0 26.000000
9 27.00 28.0 29.000000
Интерполяция#
DataFrame.interpolate() и Series.interpolate() заполняет NA значения с использованием различных методов интерполяции.
In [103]: df = pd.DataFrame(
.....: {
.....: "A": [1, 2.1, np.nan, 4.7, 5.6, 6.8],
.....: "B": [0.25, np.nan, np.nan, 4, 12.2, 14.4],
.....: }
.....: )
.....:
In [104]: df
Out[104]:
A B
0 1.0 0.25
1 2.1 NaN
2 NaN NaN
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [105]: df.interpolate()
Out[105]:
A B
0 1.0 0.25
1 2.1 1.50
2 3.4 2.75
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [106]: idx = pd.date_range("2020-01-01", periods=10, freq="D")
In [107]: data = np.random.default_rng(2).integers(0, 10, 10).astype(np.float64)
In [108]: ts = pd.Series(data, index=idx)
In [109]: ts.iloc[[1, 2, 5, 6, 9]] = np.nan
In [110]: ts
Out[110]:
2020-01-01 8.0
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 2.0
2020-01-05 4.0
2020-01-06 NaN
2020-01-07 NaN
2020-01-08 0.0
2020-01-09 3.0
2020-01-10 NaN
Freq: D, dtype: float64
In [111]: ts.plot()
Out[111]: 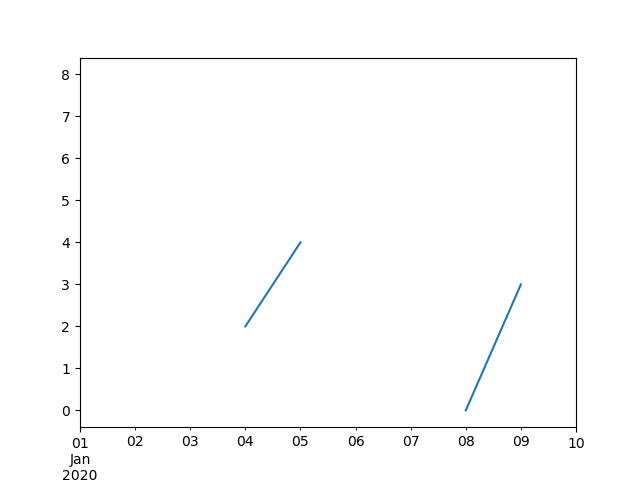
In [112]: ts.interpolate()
Out[112]:
2020-01-01 8.000000
2020-01-02 6.000000
2020-01-03 4.000000
2020-01-04 2.000000
2020-01-05 4.000000
2020-01-06 2.666667
2020-01-07 1.333333
2020-01-08 0.000000
2020-01-09 3.000000
2020-01-10 3.000000
Freq: D, dtype: float64
In [113]: ts.interpolate().plot()
Out[113]: 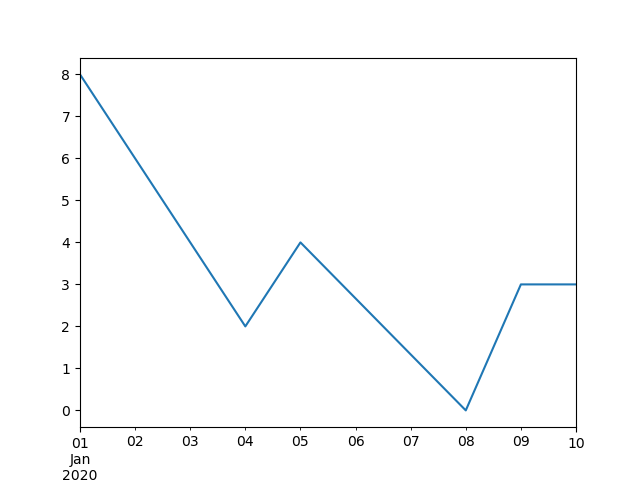
Интерполяция относительно Timestamp в DatetimeIndex
доступно путём установки method="time"
In [114]: ts2 = ts.iloc[[0, 1, 3, 7, 9]]
In [115]: ts2
Out[115]:
2020-01-01 8.0
2020-01-02 NaN
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 NaN
dtype: float64
In [116]: ts2.interpolate()
Out[116]:
2020-01-01 8.0
2020-01-02 5.0
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 0.0
dtype: float64
In [117]: ts2.interpolate(method="time")
Out[117]:
2020-01-01 8.0
2020-01-02 6.0
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 0.0
dtype: float64
Для индекса с плавающей точкой используйте method='values':
In [118]: idx = [0.0, 1.0, 10.0]
In [119]: ser = pd.Series([0.0, np.nan, 10.0], idx)
In [120]: ser
Out[120]:
0.0 0.0
1.0 NaN
10.0 10.0
dtype: float64
In [121]: ser.interpolate()
Out[121]:
0.0 0.0
1.0 5.0
10.0 10.0
dtype: float64
In [122]: ser.interpolate(method="values")
Out[122]:
0.0 0.0
1.0 1.0
10.0 10.0
dtype: float64
Если у вас есть scipy установлен, вы можете передать имя одномерной интерполяционной процедуры в method.
как указано в интерполяции scipy документация и ссылка руководство.
Подходящий метод интерполяции будет зависеть от типа данных.
Совет
Если вы работаете с временным рядом, который растет с увеличивающейся скоростью,
используйте method='barycentric'.
Если у вас есть значения, приближающиеся к функции кумулятивного распределения, используйте method='pchip'.
Для заполнения пропущенных значений с целью плавного построения графиков используйте method='akima'.
In [123]: df = pd.DataFrame(
.....: {
.....: "A": [1, 2.1, np.nan, 4.7, 5.6, 6.8],
.....: "B": [0.25, np.nan, np.nan, 4, 12.2, 14.4],
.....: }
.....: )
.....:
In [124]: df
Out[124]:
A B
0 1.0 0.25
1 2.1 NaN
2 NaN NaN
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [125]: df.interpolate(method="barycentric")
Out[125]:
A B
0 1.00 0.250
1 2.10 -7.660
2 3.53 -4.515
3 4.70 4.000
4 5.60 12.200
5 6.80 14.400
In [126]: df.interpolate(method="pchip")
Out[126]:
A B
0 1.00000 0.250000
1 2.10000 0.672808
2 3.43454 1.928950
3 4.70000 4.000000
4 5.60000 12.200000
5 6.80000 14.400000
In [127]: df.interpolate(method="akima")
Out[127]:
A B
0 1.000000 0.250000
1 2.100000 -0.873316
2 3.406667 0.320034
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
При интерполяции с помощью полиномиальной или сплайновой аппроксимации вы также должны указать степень или порядок аппроксимации:
In [128]: df.interpolate(method="spline", order=2)
Out[128]:
A B
0 1.000000 0.250000
1 2.100000 -0.428598
2 3.404545 1.206900
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
In [129]: df.interpolate(method="polynomial", order=2)
Out[129]:
A B
0 1.000000 0.250000
1 2.100000 -2.703846
2 3.451351 -1.453846
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
Сравнение нескольких методов.
In [130]: np.random.seed(2)
In [131]: ser = pd.Series(np.arange(1, 10.1, 0.25) ** 2 + np.random.randn(37))
In [132]: missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])
In [133]: ser.iloc[missing] = np.nan
In [134]: methods = ["linear", "quadratic", "cubic"]
In [135]: df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods})
In [136]: df.plot()
Out[136]: 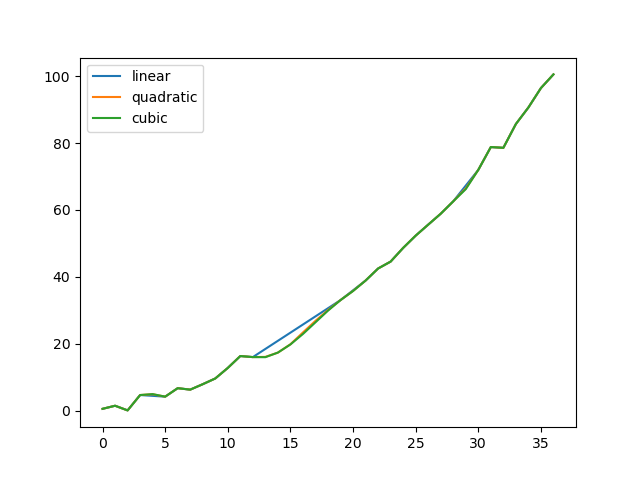
Интерполяция новых наблюдений из расширяющихся данных с Series.reindex().
In [137]: ser = pd.Series(np.sort(np.random.uniform(size=100)))
# interpolate at new_index
In [138]: new_index = ser.index.union(pd.Index([49.25, 49.5, 49.75, 50.25, 50.5, 50.75]))
In [139]: interp_s = ser.reindex(new_index).interpolate(method="pchip")
In [140]: interp_s.loc[49:51]
Out[140]:
49.00 0.471410
49.25 0.476841
49.50 0.481780
49.75 0.485998
50.00 0.489266
50.25 0.491814
50.50 0.493995
50.75 0.495763
51.00 0.497074
dtype: float64
Пределы интерполяции#
interpolate() принимает limit ключевой
аргумент для ограничения количества последовательных NaN значения
заполнены с момента последнего допустимого наблюдения
In [141]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, np.nan, 13, np.nan, np.nan])
In [142]: ser
Out[142]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
In [143]: ser.interpolate()
Out[143]:
0 NaN
1 NaN
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
In [144]: ser.interpolate(limit=1)
Out[144]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 NaN
6 13.0
7 13.0
8 NaN
dtype: float64
По умолчанию, NaN значения заполняются в forward направление. Используйте
limit_direction параметр для заполнения backward или из both направления.
In [145]: ser.interpolate(limit=1, limit_direction="backward")
Out[145]:
0 NaN
1 5.0
2 5.0
3 NaN
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
In [146]: ser.interpolate(limit=1, limit_direction="both")
Out[146]:
0 NaN
1 5.0
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 13.0
8 NaN
dtype: float64
In [147]: ser.interpolate(limit_direction="both")
Out[147]:
0 5.0
1 5.0
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
По умолчанию, NaN значения заполняются независимо от того, окружены ли они существующими допустимыми значениями или находятся за пределами существующих допустимых значений. limit_area
параметр ограничивает заполнение только внутренними или внешними значениями.
# fill one consecutive inside value in both directions
In [148]: ser.interpolate(limit_direction="both", limit_area="inside", limit=1)
Out[148]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
# fill all consecutive outside values backward
In [149]: ser.interpolate(limit_direction="backward", limit_area="outside")
Out[149]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
# fill all consecutive outside values in both directions
In [150]: ser.interpolate(limit_direction="both", limit_area="outside")
Out[150]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
dtype: float64
Замена значений#
Series.replace() и DataFrame.replace() может использоваться аналогично
Series.fillna() и DataFrame.fillna() для замены или вставки пропущенных значений.
In [151]: df = pd.DataFrame(np.eye(3))
In [152]: df
Out[152]:
0 1 2
0 1.0 0.0 0.0
1 0.0 1.0 0.0
2 0.0 0.0 1.0
In [153]: df_missing = df.replace(0, np.nan)
In [154]: df_missing
Out[154]:
0 1 2
0 1.0 NaN NaN
1 NaN 1.0 NaN
2 NaN NaN 1.0
In [155]: df_filled = df_missing.replace(np.nan, 2)
In [156]: df_filled
Out[156]:
0 1 2
0 1.0 2.0 2.0
1 2.0 1.0 2.0
2 2.0 2.0 1.0
Замена более одного значения возможна путем передачи списка.
In [157]: df_filled.replace([1, 44], [2, 28])
Out[157]:
0 1 2
0 2.0 2.0 2.0
1 2.0 2.0 2.0
2 2.0 2.0 2.0
Замена с использованием словаря сопоставления.
In [158]: df_filled.replace({1: 44, 2: 28})
Out[158]:
0 1 2
0 44.0 28.0 28.0
1 28.0 44.0 28.0
2 28.0 28.0 44.0
Замена регулярным выражением#
Примечание
Строки Python с префиксом r символ, такой как r'hello world'
являются «сырые» строки.
У них другая семантика относительно обратных слешей, чем у строк без этого префикса.
Обратные слеши в сырых строках будут интерпретироваться как экранированный обратный слеш, например, r'\' == '\\'.
Замените '.' на NaN
In [159]: d = {"a": list(range(4)), "b": list("ab.."), "c": ["a", "b", np.nan, "d"]}
In [160]: df = pd.DataFrame(d)
In [161]: df.replace(".", np.nan)
Out[161]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Замените '.' на NaN с регулярным выражением, которое удаляет окружающие пробелы
In [162]: df.replace(r"\s*\.\s*", np.nan, regex=True)
Out[162]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Заменить списком регулярных выражений.
In [163]: df.replace([r"\.", r"(a)"], ["dot", r"\1stuff"], regex=True)
Out[163]:
a b c
0 0 astuff astuff
1 1 b b
2 2 dot NaN
3 3 dot d
Заменить с помощью регулярного выражения в словаре сопоставления.
In [164]: df.replace({"b": r"\s*\.\s*"}, {"b": np.nan}, regex=True)
Out[164]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Передавайте вложенные словари регулярных выражений, которые используют regex ключевое слово.
In [165]: df.replace({"b": {"b": r""}}, regex=True)
Out[165]:
a b c
0 0 a a
1 1 b
2 2 . NaN
3 3 . d
In [166]: df.replace(regex={"b": {r"\s*\.\s*": np.nan}})
Out[166]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
In [167]: df.replace({"b": r"\s*(\.)\s*"}, {"b": r"\1ty"}, regex=True)
Out[167]:
a b c
0 0 a a
1 1 b b
2 2 .ty NaN
3 3 .ty d
Передайте список регулярных выражений, которые заменят совпадения скаляром.
In [168]: df.replace([r"\s*\.\s*", r"a|b"], "placeholder", regex=True)
Out[168]:
a b c
0 0 placeholder placeholder
1 1 placeholder placeholder
2 2 placeholder NaN
3 3 placeholder d
Все примеры регулярных выражений также могут быть переданы с
to_replace аргумент как regex аргумент. В этом случае value
аргумент должен быть передан явно по имени или regex должен быть вложенным
словарем.
In [169]: df.replace(regex=[r"\s*\.\s*", r"a|b"], value="placeholder")
Out[169]:
a b c
0 0 placeholder placeholder
1 1 placeholder placeholder
2 2 placeholder NaN
3 3 placeholder d
Примечание
Объект регулярного выражения из re.compile также является допустимым входным значением.