Группировка: разделение-применение-объединение#
Под «группировкой» мы подразумеваем процесс, включающий один или несколько из следующих шагов:
Разделение данные в группы на основе некоторых критериев.
Применение функцию к каждой группе независимо.
Объединение результаты в структуру данных.
Из них шаг разделения является наиболее простым. На шаге применения мы можем захотеть сделать одно из следующих действий:
Агрегация: вычисление сводной статистики (или статистик) для каждой группы. Некоторые примеры:
Вычислить групповые суммы или средние.
Вычисление размеров/количеств групп.
Преобразование: выполнить некоторые вычисления для группы и вернуть объект с похожей индексацией. Некоторые примеры:
Стандартизация данных (z-оценка) внутри группы.
Заполнение NA в группах значением, полученным из каждой группы.
Фильтрация: отбросить некоторые группы в соответствии с групповым вычислением, которое оценивается как True или False. Некоторые примеры:
Отбросить данные, принадлежащие группам с небольшим количеством членов.
Фильтровать данные на основе суммы или среднего значения группы.
Многие из этих операций определены для объектов GroupBy. Эти операции похожи на операции API агрегации, window API, и API resample.
Возможно, что данная операция не попадает ни в одну из этих категорий или
является их комбинацией. В таком случае может быть возможно вычислить
операцию с использованием apply метод. Этот метод проверит результаты шага apply и попытается разумно объединить их в один результат, если он не подходит ни в одну из вышеуказанных трех категорий.
Примечание
Операция, разделённая на несколько шагов с использованием встроенных операций GroupBy, будет более эффективной, чем использование apply метод с пользовательской функцией Python.
Название GroupBy должно быть довольно знакомо тем, кто использовал
инструменты на основе SQL (или itertools), в которой вы можете писать код, например:
SELECT Column1, Column2, mean(Column3), sum(Column4)
FROM SomeTable
GROUP BY Column1, Column2
Мы стремимся сделать такие операции естественными и легко выражаемыми с помощью pandas. Мы рассмотрим каждую область функциональности GroupBy, затем предоставим некоторые нетривиальные примеры/случаи использования.
См. cookbook для некоторых продвинутых стратегий.
Разделение объекта на группы#
Абстрактное определение группировки — это предоставление сопоставления меток с именами групп. Чтобы создать объект GroupBy (подробнее о том, что такое объект GroupBy позже), вы можете сделать следующее:
In [1]: speeds = pd.DataFrame(
...: [
...: ("bird", "Falconiformes", 389.0),
...: ("bird", "Psittaciformes", 24.0),
...: ("mammal", "Carnivora", 80.2),
...: ("mammal", "Primates", np.nan),
...: ("mammal", "Carnivora", 58),
...: ],
...: index=["falcon", "parrot", "lion", "monkey", "leopard"],
...: columns=("class", "order", "max_speed"),
...: )
...:
In [2]: speeds
Out[2]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [3]: grouped = speeds.groupby("class")
In [4]: grouped = speeds.groupby(["class", "order"])
Отображение может быть задано разными способами:
Функция Python, которая будет вызываться для каждой метки индекса.
Список или массив NumPy той же длины, что и индекс.
Словарь или
Series, предоставляяlabel -> group nameотображение.Для
DataFrameобъектов, строка, указывающая либо имя столбца, либо имя уровня индекса для группировки.Список любых из вышеперечисленных элементов.
В совокупности мы называем объекты группировки ключи. Например,
рассмотрим следующий DataFrame:
Примечание
Строка, переданная в groupby может ссылаться либо на столбец, либо на уровень индекса. Если строка соответствует и имени столбца, и имени уровня индекса,
ValueError будет вызвано исключение.
In [5]: df = pd.DataFrame(
...: {
...: "A": ["foo", "bar", "foo", "bar", "foo", "bar", "foo", "foo"],
...: "B": ["one", "one", "two", "three", "two", "two", "one", "three"],
...: "C": np.random.randn(8),
...: "D": np.random.randn(8),
...: }
...: )
...:
In [6]: df
Out[6]:
A B C D
0 foo one 0.469112 -0.861849
1 bar one -0.282863 -2.104569
2 foo two -1.509059 -0.494929
3 bar three -1.135632 1.071804
4 foo two 1.212112 0.721555
5 bar two -0.173215 -0.706771
6 foo one 0.119209 -1.039575
7 foo three -1.044236 0.271860
На DataFrame мы получаем объект GroupBy, вызывая groupby(). Этот метод возвращает pandas.api.typing.DataFrameGroupBy экземпляр.
Мы могли бы естественным образом группировать либо по A или B столбцы, или оба:
In [7]: grouped = df.groupby("A")
In [8]: grouped = df.groupby("B")
In [9]: grouped = df.groupby(["A", "B"])
Примечание
df.groupby('A') это просто синтаксический сахар для df.groupby(df['A']).
Если у нас также есть MultiIndex для столбцов A и B, мы можем сгруппировать по всем
столбцам, кроме указанного:
In [10]: df2 = df.set_index(["A", "B"])
In [11]: grouped = df2.groupby(level=df2.index.names.difference(["B"]))
In [12]: grouped.sum()
Out[12]:
C D
A
bar -1.591710 -1.739537
foo -0.752861 -1.402938
Приведённый выше GroupBy разделит DataFrame по его индексу (строки). Чтобы разделить по столбцам, сначала выполните транспонирование:
In [13]: def get_letter_type(letter):
....: if letter.lower() in 'aeiou':
....: return 'vowel'
....: else:
....: return 'consonant'
....:
In [14]: grouped = df.T.groupby(get_letter_type)
pandas Index объекты поддерживают повторяющиеся значения. Если
неуникальный индекс используется как ключ группировки в операции groupby, все значения
для одного и того же значения индекса будут считаться в одной группе, и, следовательно,
результат агрегирующих функций будет содержать только уникальные значения индекса:
In [15]: index = [1, 2, 3, 1, 2, 3]
In [16]: s = pd.Series([1, 2, 3, 10, 20, 30], index=index)
In [17]: s
Out[17]:
1 1
2 2
3 3
1 10
2 20
3 30
dtype: int64
In [18]: grouped = s.groupby(level=0)
In [19]: grouped.first()
Out[19]:
1 1
2 2
3 3
dtype: int64
In [20]: grouped.last()
Out[20]:
1 10
2 20
3 30
dtype: int64
In [21]: grouped.sum()
Out[21]:
1 11
2 22
3 33
dtype: int64
Обратите внимание, что разделение не происходит пока это не потребуется. Создание объекта GroupBy только проверяет, что вы передали допустимое отображение.
Примечание
Многие виды сложных манипуляций с данными могут быть выражены через операции GroupBy (хотя это не гарантирует наиболее эффективную реализацию). Вы можете проявить большую креативность с функциями сопоставления меток.
Сортировка GroupBy#
По умолчанию ключи групп сортируются во время groupby операцией. Однако вы можете передать sort=False для потенциального ускорения. С sort=False порядок среди ключей групп следует порядку появления ключей в исходном датафрейме:
In [22]: df2 = pd.DataFrame({"X": ["B", "B", "A", "A"], "Y": [1, 2, 3, 4]})
In [23]: df2.groupby(["X"]).sum()
Out[23]:
Y
X
A 7
B 3
In [24]: df2.groupby(["X"], sort=False).sum()
Out[24]:
Y
X
B 3
A 7
Обратите внимание, что groupby сохранит порядок, в котором наблюдения отсортированы внутри каждой группы.
Например, группы, созданные groupby() ниже приведены в порядке их появления в оригинале DataFrame:
In [25]: df3 = pd.DataFrame({"X": ["A", "B", "A", "B"], "Y": [1, 4, 3, 2]})
In [26]: df3.groupby("X").get_group("A")
Out[26]:
X Y
0 A 1
2 A 3
In [27]: df3.groupby(["X"]).get_group(("B",))
Out[27]:
X Y
1 B 4
3 B 2
GroupBy dropna#
По умолчанию NA значения исключаются из ключей групп во время groupby операция. Однако,
в случае, если вы хотите включить NA значения в ключах группировки, вы могли передать dropna=False для достижения этого.
In [28]: df_list = [[1, 2, 3], [1, None, 4], [2, 1, 3], [1, 2, 2]]
In [29]: df_dropna = pd.DataFrame(df_list, columns=["a", "b", "c"])
In [30]: df_dropna
Out[30]:
a b c
0 1 2.0 3
1 1 NaN 4
2 2 1.0 3
3 1 2.0 2
# Default ``dropna`` is set to True, which will exclude NaNs in keys
In [31]: df_dropna.groupby(by=["b"], dropna=True).sum()
Out[31]:
a c
b
1.0 2 3
2.0 2 5
# In order to allow NaN in keys, set ``dropna`` to False
In [32]: df_dropna.groupby(by=["b"], dropna=False).sum()
Out[32]:
a c
b
1.0 2 3
2.0 2 5
NaN 1 4
Настройка по умолчанию для dropna аргумент является True что означает NA не включены в ключи групп.
Атрибуты объекта GroupBy#
The groups атрибут - это словарь, ключами которого являются вычисленные уникальные группы, а соответствующие значения - метки осей, принадлежащие каждой группе. В приведённом выше примере у нас есть:
In [33]: df.groupby("A").groups
Out[33]: {'bar': [1, 3, 5], 'foo': [0, 2, 4, 6, 7]}
In [34]: df.T.groupby(get_letter_type).groups
Out[34]: {'consonant': ['B', 'C', 'D'], 'vowel': ['A']}
Вызов стандартной функции Python len функция на объекте GroupBy возвращает количество групп, что совпадает с длиной groups словарь:
In [35]: grouped = df.groupby(["A", "B"])
In [36]: grouped.groups
Out[36]: {('bar', 'one'): [1], ('bar', 'three'): [3], ('bar', 'two'): [5], ('foo', 'one'): [0, 6], ('foo', 'three'): [7], ('foo', 'two'): [2, 4]}
In [37]: len(grouped)
Out[37]: 6
GroupBy будет автодополнять имена столбцов, операции GroupBy и другие атрибуты:
In [38]: n = 10
In [39]: weight = np.random.normal(166, 20, size=n)
In [40]: height = np.random.normal(60, 10, size=n)
In [41]: time = pd.date_range("1/1/2000", periods=n)
In [42]: gender = np.random.choice(["male", "female"], size=n)
In [43]: df = pd.DataFrame(
....: {"height": height, "weight": weight, "gender": gender}, index=time
....: )
....:
In [44]: df
Out[44]:
height weight gender
2000-01-01 42.849980 157.500553 male
2000-01-02 49.607315 177.340407 male
2000-01-03 56.293531 171.524640 male
2000-01-04 48.421077 144.251986 female
2000-01-05 46.556882 152.526206 male
2000-01-06 68.448851 168.272968 female
2000-01-07 70.757698 136.431469 male
2000-01-08 58.909500 176.499753 female
2000-01-09 76.435631 174.094104 female
2000-01-10 45.306120 177.540920 male
In [45]: gb = df.groupby("gender")
In [46]: gb.<TAB> # noqa: E225, E999
gb.agg gb.boxplot gb.cummin gb.describe gb.filter gb.get_group gb.height gb.last gb.median gb.ngroups gb.plot gb.rank gb.std gb.transform
gb.aggregate gb.count gb.cumprod gb.dtype gb.first gb.groups gb.hist gb.max gb.min gb.nth gb.prod gb.resample gb.sum gb.var
gb.apply gb.cummax gb.cumsum gb.fillna gb.gender gb.head gb.indices gb.mean gb.name gb.ohlc gb.quantile gb.size gb.tail gb.weight
GroupBy с MultiIndex#
С иерархически индексированные данные, вполне естественно группировать по одному из уровней иерархии.
Создадим Series с двухуровневым MultiIndex.
In [47]: arrays = [
....: ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
....: ["one", "two", "one", "two", "one", "two", "one", "two"],
....: ]
....:
In [48]: index = pd.MultiIndex.from_arrays(arrays, names=["first", "second"])
In [49]: s = pd.Series(np.random.randn(8), index=index)
In [50]: s
Out[50]:
first second
bar one -0.919854
two -0.042379
baz one 1.247642
two -0.009920
foo one 0.290213
two 0.495767
qux one 0.362949
two 1.548106
dtype: float64
Затем мы можем сгруппировать по одному из уровней в s.
In [51]: grouped = s.groupby(level=0)
In [52]: grouped.sum()
Out[52]:
first
bar -0.962232
baz 1.237723
foo 0.785980
qux 1.911055
dtype: float64
Если у MultiIndex указаны имена, их можно передать вместо номера уровня:
In [53]: s.groupby(level="second").sum()
Out[53]:
second
one 0.980950
two 1.991575
dtype: float64
Группировка с несколькими уровнями поддерживается.
In [54]: arrays = [
....: ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
....: ["doo", "doo", "bee", "bee", "bop", "bop", "bop", "bop"],
....: ["one", "two", "one", "two", "one", "two", "one", "two"],
....: ]
....:
In [55]: index = pd.MultiIndex.from_arrays(arrays, names=["first", "second", "third"])
In [56]: s = pd.Series(np.random.randn(8), index=index)
In [57]: s
Out[57]:
first second third
bar doo one -1.131345
two -0.089329
baz bee one 0.337863
two -0.945867
foo bop one -0.932132
two 1.956030
qux bop one 0.017587
two -0.016692
dtype: float64
In [58]: s.groupby(level=["first", "second"]).sum()
Out[58]:
first second
bar doo -1.220674
baz bee -0.608004
foo bop 1.023898
qux bop 0.000895
dtype: float64
Имена уровней индекса могут быть указаны в качестве ключей.
In [59]: s.groupby(["first", "second"]).sum()
Out[59]:
first second
bar doo -1.220674
baz bee -0.608004
foo bop 1.023898
qux bop 0.000895
dtype: float64
Подробнее о sum функция и агрегация позже.
Группировка DataFrame с уровнями индекса и столбцами#
DataFrame может быть сгруппирован по комбинации столбцов и уровней индекса. Вы
можете указать имена столбцов и индексов, или использовать Grouper.
Давайте сначала создадим DataFrame с MultiIndex:
In [60]: arrays = [
....: ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
....: ["one", "two", "one", "two", "one", "two", "one", "two"],
....: ]
....:
In [61]: index = pd.MultiIndex.from_arrays(arrays, names=["first", "second"])
In [62]: df = pd.DataFrame({"A": [1, 1, 1, 1, 2, 2, 3, 3], "B": np.arange(8)}, index=index)
In [63]: df
Out[63]:
A B
first second
bar one 1 0
two 1 1
baz one 1 2
two 1 3
foo one 2 4
two 2 5
qux one 3 6
two 3 7
Затем мы группируем df с помощью second уровень индекса и A столбец.
In [64]: df.groupby([pd.Grouper(level=1), "A"]).sum()
Out[64]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
Уровни индекса также могут быть указаны по имени.
In [65]: df.groupby([pd.Grouper(level="second"), "A"]).sum()
Out[65]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
Имена уровней индекса могут быть указаны как ключи непосредственно в groupby.
In [66]: df.groupby(["second", "A"]).sum()
Out[66]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
Выбор столбцов DataFrame в GroupBy#
После создания объекта GroupBy из DataFrame, вы можете захотеть сделать
что-то разное для каждого из столбцов. Таким образом, используя [] на объекте GroupBy аналогично тому, как получают столбец из DataFrame, можно сделать:
In [67]: df = pd.DataFrame(
....: {
....: "A": ["foo", "bar", "foo", "bar", "foo", "bar", "foo", "foo"],
....: "B": ["one", "one", "two", "three", "two", "two", "one", "three"],
....: "C": np.random.randn(8),
....: "D": np.random.randn(8),
....: }
....: )
....:
In [68]: df
Out[68]:
A B C D
0 foo one -0.575247 1.346061
1 bar one 0.254161 1.511763
2 foo two -1.143704 1.627081
3 bar three 0.215897 -0.990582
4 foo two 1.193555 -0.441652
5 bar two -0.077118 1.211526
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
In [69]: grouped = df.groupby(["A"])
In [70]: grouped_C = grouped["C"]
In [71]: grouped_D = grouped["D"]
Это в основном синтаксический сахар для альтернативного варианта, который гораздо более многословен:
In [72]: df["C"].groupby(df["A"])
Out[72]: Кроме того, этот метод избегает пересчета внутренней группирующей информации, полученной из переданного ключа.
Вы также можете включить группирующие столбцы, если хотите работать с ними.
In [73]: grouped[["A", "B"]].sum()
Out[73]:
A B
A
bar barbarbar onethreetwo
foo foofoofoofoofoo onetwotwoonethree
Итерация по группам#
Имея объект GroupBy, итерация по сгруппированным данным очень естественна и работает аналогично itertools.groupby():
In [74]: grouped = df.groupby('A')
In [75]: for name, group in grouped:
....: print(name)
....: print(group)
....:
bar
A B C D
1 bar one 0.254161 1.511763
3 bar three 0.215897 -0.990582
5 bar two -0.077118 1.211526
foo
A B C D
0 foo one -0.575247 1.346061
2 foo two -1.143704 1.627081
4 foo two 1.193555 -0.441652
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
В случае группировки по нескольким ключам имя группы будет кортежем:
In [76]: for name, group in df.groupby(['A', 'B']):
....: print(name)
....: print(group)
....:
('bar', 'one')
A B C D
1 bar one 0.254161 1.511763
('bar', 'three')
A B C D
3 bar three 0.215897 -0.990582
('bar', 'two')
A B C D
5 bar two -0.077118 1.211526
('foo', 'one')
A B C D
0 foo one -0.575247 1.346061
6 foo one -0.408530 0.268520
('foo', 'three')
A B C D
7 foo three -0.862495 0.02458
('foo', 'two')
A B C D
2 foo two -1.143704 1.627081
4 foo two 1.193555 -0.441652
См. Итерация по группам.
Выбор группы#
Одна группа может быть выбрана с помощью
DataFrameGroupBy.get_group():
In [77]: grouped.get_group("bar")
Out[77]:
A B C D
1 bar one 0.254161 1.511763
3 bar three 0.215897 -0.990582
5 bar two -0.077118 1.211526
Или для объекта, сгруппированного по нескольким столбцам:
In [78]: df.groupby(["A", "B"]).get_group(("bar", "one"))
Out[78]:
A B C D
1 bar one 0.254161 1.511763
Агрегация#
Агрегация — это операция GroupBy, которая уменьшает размерность группирующего объекта. Результат агрегации — это, или, по крайней мере, рассматривается как, скалярное значение для каждого столбца в группе. Например, получение суммы каждого столбца в группе значений.
In [79]: animals = pd.DataFrame(
....: {
....: "kind": ["cat", "dog", "cat", "dog"],
....: "height": [9.1, 6.0, 9.5, 34.0],
....: "weight": [7.9, 7.5, 9.9, 198.0],
....: }
....: )
....:
In [80]: animals
Out[80]:
kind height weight
0 cat 9.1 7.9
1 dog 6.0 7.5
2 cat 9.5 9.9
3 dog 34.0 198.0
In [81]: animals.groupby("kind").sum()
Out[81]:
height weight
kind
cat 18.6 17.8
dog 40.0 205.5
В результате ключи групп по умолчанию появляются в индексе. Они могут быть включены в столбцы, передав as_index=False.
In [82]: animals.groupby("kind", as_index=False).sum()
Out[82]:
kind height weight
0 cat 18.6 17.8
1 dog 40.0 205.5
Встроенные методы агрегации#
Многие общие агрегации встроены в объекты GroupBy как методы. Из перечисленных ниже методов те, у которых есть * делать не имеют эффективную, специфичную для GroupBy, реализацию.
Метод |
Описание |
|---|---|
Определяет, являются ли какие-либо значения в группах истинными |
|
Вычисляет, являются ли все значения в группах истинными |
|
Вычисление количества не-NA значений в группах |
|
|
Вычислить ковариацию групп |
Вычисление первого встречающегося значения в каждой группе |
|
Вычислить индекс максимального значения в каждой группе |
|
Вычислить индекс минимального значения в каждой группе |
|
Вычислить последнее встречающееся значение в каждой группе |
|
Вычислить максимальное значение в каждой группе |
|
Вычислить среднее значение каждой группы |
|
Вычислить медиану каждой группы |
|
Вычислить минимальное значение в каждой группе |
|
Вычислить количество уникальных значений в каждой группе |
|
Вычислить произведение значений в каждой группе |
|
Вычисляет заданный квантиль значений в каждой группе |
|
Вычислить стандартную ошибку среднего значений в каждой группе |
|
Вычислить количество значений в каждой группе |
|
|
Вычислить асимметрию значений в каждой группе |
Вычислить стандартное отклонение значений в каждой группе |
|
Вычисляет сумму значений в каждой группе |
|
Вычислить дисперсию значений в каждой группе |
Некоторые примеры:
In [83]: df.groupby("A")[["C", "D"]].max()
Out[83]:
C D
A
bar 0.254161 1.511763
foo 1.193555 1.627081
In [84]: df.groupby(["A", "B"]).mean()
Out[84]:
C D
A B
bar one 0.254161 1.511763
three 0.215897 -0.990582
two -0.077118 1.211526
foo one -0.491888 0.807291
three -0.862495 0.024580
two 0.024925 0.592714
Другой пример агрегации — вычисление размера каждой группы.
Это включено в GroupBy как size метод. Он возвращает Series, чей
индекс состоит из имен групп, а значения — это размеры каждой группы.
In [85]: grouped = df.groupby(["A", "B"])
In [86]: grouped.size()
Out[86]:
A B
bar one 1
three 1
two 1
foo one 2
three 1
two 2
dtype: int64
Хотя DataFrameGroupBy.describe() метод сам по себе не является редуктором, он
может использоваться для удобного создания набора сводной статистики о каждой из
групп.
In [87]: grouped.describe()
Out[87]:
C ... D
count mean std ... 50% 75% max
A B ...
bar one 1.0 0.254161 NaN ... 1.511763 1.511763 1.511763
three 1.0 0.215897 NaN ... -0.990582 -0.990582 -0.990582
two 1.0 -0.077118 NaN ... 1.211526 1.211526 1.211526
foo one 2.0 -0.491888 0.117887 ... 0.807291 1.076676 1.346061
three 1.0 -0.862495 NaN ... 0.024580 0.024580 0.024580
two 2.0 0.024925 1.652692 ... 0.592714 1.109898 1.627081
[6 rows x 16 columns]
Другой пример агрегации — вычисление количества уникальных значений в каждой группе.
Это похоже на DataFrameGroupBy.value_counts() функция, за исключением того, что она подсчитывает только
количество уникальных значений.
In [88]: ll = [['foo', 1], ['foo', 2], ['foo', 2], ['bar', 1], ['bar', 1]]
In [89]: df4 = pd.DataFrame(ll, columns=["A", "B"])
In [90]: df4
Out[90]:
A B
0 foo 1
1 foo 2
2 foo 2
3 bar 1
4 bar 1
In [91]: df4.groupby("A")["B"].nunique()
Out[91]:
A
bar 1
foo 2
Name: B, dtype: int64
Примечание
Функции агрегации не будет возвращает группы, по которым вы агрегируете, как именованные столбцы когда as_index=True, по умолчанию. Сгруппированные столбцы будут
индексы возвращаемого объекта.
Передача as_index=False будет возвращает группы, по которым вы агрегируете, как именованные столбцы, независимо от того, названы ли они индексы или столбцы во входных данных.
The aggregate() метод#
Примечание
The aggregate() метод может принимать множество различных типов входных данных. В этом разделе подробно описано использование строковых псевдонимов для различных методов GroupBy; другие входные данные подробно описаны в следующих разделах.
Любой метод редукции, который реализует pandas, может быть передан как строка в
aggregate(). Пользователям рекомендуется использовать сокращённую запись,
agg. Он будет работать так, как если бы был вызван соответствующий метод.
In [92]: grouped = df.groupby("A")
In [93]: grouped[["C", "D"]].aggregate("sum")
Out[93]:
C D
A
bar 0.392940 1.732707
foo -1.796421 2.824590
In [94]: grouped = df.groupby(["A", "B"])
In [95]: grouped.agg("sum")
Out[95]:
C D
A B
bar one 0.254161 1.511763
three 0.215897 -0.990582
two -0.077118 1.211526
foo one -0.983776 1.614581
three -0.862495 0.024580
two 0.049851 1.185429
Результат агрегации будет иметь имена групп в качестве
нового индекса. В случае нескольких ключей результат представляет собой
MultiIndex по умолчанию. Как упоминалось выше, это можно изменить, используя as_index опция:
In [96]: grouped = df.groupby(["A", "B"], as_index=False)
In [97]: grouped.agg("sum")
Out[97]:
A B C D
0 bar one 0.254161 1.511763
1 bar three 0.215897 -0.990582
2 bar two -0.077118 1.211526
3 foo one -0.983776 1.614581
4 foo three -0.862495 0.024580
5 foo two 0.049851 1.185429
In [98]: df.groupby("A", as_index=False)[["C", "D"]].agg("sum")
Out[98]:
A C D
0 bar 0.392940 1.732707
1 foo -1.796421 2.824590
Обратите внимание, что вы можете использовать DataFrame.reset_index() Функция DataFrame для достижения
того же результата, так как имена столбцов хранятся в результирующем MultiIndex, хотя
это создаст дополнительную копию.
In [99]: df.groupby(["A", "B"]).agg("sum").reset_index()
Out[99]:
A B C D
0 bar one 0.254161 1.511763
1 bar three 0.215897 -0.990582
2 bar two -0.077118 1.211526
3 foo one -0.983776 1.614581
4 foo three -0.862495 0.024580
5 foo two 0.049851 1.185429
Агрегация с пользовательскими функциями#
Пользователи также могут предоставлять свои собственные пользовательские функции (UDF) для пользовательских агрегаций.
Предупреждение
При агрегировании с помощью пользовательской функции (UDF), UDF не должна изменять
предоставленные Series. См. Изменение с помощью методов пользовательских функций (UDF) для получения дополнительной информации.
Примечание
Агрегация с использованием пользовательской функции часто менее производительна, чем использование встроенных методов pandas в GroupBy. Рассмотрите возможность разбиения сложной операции на цепочку операций, использующих встроенные методы.
In [100]: animals
Out[100]:
kind height weight
0 cat 9.1 7.9
1 dog 6.0 7.5
2 cat 9.5 9.9
3 dog 34.0 198.0
In [101]: animals.groupby("kind")[["height"]].agg(lambda x: set(x))
Out[101]:
height
kind
cat {9.1, 9.5}
dog {34.0, 6.0}
Результирующий тип данных будет отражать тип агрегирующей функции. Если результаты из разных групп имеют разные типы данных, то общий тип данных будет определен таким же образом, как DataFrame конструкция.
In [102]: animals.groupby("kind")[["height"]].agg(lambda x: x.astype(int).sum())
Out[102]:
height
kind
cat 18
dog 40
Применение нескольких функций одновременно#
На сгруппированном Series, вы можете передать список или словарь функций в
SeriesGroupBy.agg(), выводя DataFrame:
In [103]: grouped = df.groupby("A")
In [104]: grouped["C"].agg(["sum", "mean", "std"])
Out[104]:
sum mean std
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
На сгруппированном DataFrame, вы можете передать список функций в
DataFrameGroupBy.agg() для агрегации каждого столбца, что создаёт агрегированный результат с иерархическим индексом столбцов:
In [105]: grouped[["C", "D"]].agg(["sum", "mean", "std"])
Out[105]:
C D
sum mean std sum mean std
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
Полученные агрегации называются по именам самих функций. Если вам
нужно переименовать их, вы можете добавить цепочку операций для Series например:
In [106]: (
.....: grouped["C"]
.....: .agg(["sum", "mean", "std"])
.....: .rename(columns={"sum": "foo", "mean": "bar", "std": "baz"})
.....: )
.....:
Out[106]:
foo bar baz
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
Для сгруппированного DataFrame, вы можете переименовать аналогичным образом:
In [107]: (
.....: grouped[["C", "D"]].agg(["sum", "mean", "std"]).rename(
.....: columns={"sum": "foo", "mean": "bar", "std": "baz"}
.....: )
.....: )
.....:
Out[107]:
C D
foo bar baz foo bar baz
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
Примечание
В общем случае, имена выходных столбцов должны быть уникальными, но pandas позволит вам применить одну и ту же функцию (или две функции с одинаковым именем) к одному и тому же столбцу.
In [108]: grouped["C"].agg(["sum", "sum"])
Out[108]:
sum sum
A
bar 0.392940 0.392940
foo -1.796421 -1.796421
pandas также позволяет использовать несколько лямбда-функций. В этом случае pandas изменит имя (безымянных) лямбда-функций, добавляя _
к каждому последующему лямбда-выражению.
In [109]: grouped["C"].agg([lambda x: x.max() - x.min(), lambda x: x.median() - x.mean()])
Out[109]:
A
bar 0.331279 0.084917
foo 2.337259 -0.215962
Именованная агрегация#
Для поддержки агрегации по столбцам с контролем над именами выходных столбцов, pandas
принимает специальный синтаксис в DataFrameGroupBy.agg() и SeriesGroupBy.agg(), известный как "именованная агрегация", где
Ключевые слова - это вывод имена столбцов
Значения представляют собой кортежи, первый элемент которых — столбец для выбора, а второй элемент — агрегация, применяемая к этому столбцу. pandas предоставляет
NamedAggnamedtuple с полями['column', 'aggfunc']чтобы сделать аргументы более понятными. Как обычно, агрегация может быть вызываемым объектом или строковым псевдонимом.
In [110]: animals
Out[110]:
kind height weight
0 cat 9.1 7.9
1 dog 6.0 7.5
2 cat 9.5 9.9
3 dog 34.0 198.0
In [111]: animals.groupby("kind").agg(
.....: min_height=pd.NamedAgg(column="height", aggfunc="min"),
.....: max_height=pd.NamedAgg(column="height", aggfunc="max"),
.....: average_weight=pd.NamedAgg(column="weight", aggfunc="mean"),
.....: )
.....:
Out[111]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
NamedAgg это просто namedtuple. Простые кортежи также разрешены.
In [112]: animals.groupby("kind").agg(
.....: min_height=("height", "min"),
.....: max_height=("height", "max"),
.....: average_weight=("weight", "mean"),
.....: )
.....:
Out[112]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
Если имена столбцов, которые вы хотите, не являются допустимыми ключевыми словами Python, создайте словарь и распакуйте аргументы ключевых слов
In [113]: animals.groupby("kind").agg(
.....: **{
.....: "total weight": pd.NamedAgg(column="weight", aggfunc="sum")
.....: }
.....: )
.....:
Out[113]:
total weight
kind
cat 17.8
dog 205.5
При использовании именованной агрегации дополнительные ключевые аргументы не передаются
функциям агрегации; передаются только пары
вида (column, aggfunc) должен быть передан как **kwargs. Если ваши агрегирующие функции
требуют дополнительных аргументов, примените их частично с помощью functools.partial().
Именованная агрегация также действительна для агрегаций группировки Series. В этом случае нет выбора столбца, поэтому значения — это просто функции.
In [114]: animals.groupby("kind").height.agg(
.....: min_height="min",
.....: max_height="max",
.....: )
.....:
Out[114]:
min_height max_height
kind
cat 9.1 9.5
dog 6.0 34.0
Применение различных функций к столбцам DataFrame#
Передавая словарь в aggregate вы можете применить другую агрегацию к столбцам DataFrame:
In [115]: grouped.agg({"C": "sum", "D": lambda x: np.std(x, ddof=1)})
Out[115]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
Имена функций также могут быть строками. Чтобы строка была допустимой, она должна быть реализована в GroupBy:
In [116]: grouped.agg({"C": "sum", "D": "std"})
Out[116]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
Преобразование#
Преобразование — это операция GroupBy, результат которой индексируется так же, как и группируемый объект. Распространённые примеры включают cumsum() и
diff().
In [117]: speeds
Out[117]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [118]: grouped = speeds.groupby("class")["max_speed"]
In [119]: grouped.cumsum()
Out[119]:
falcon 389.0
parrot 413.0
lion 80.2
monkey NaN
leopard 138.2
Name: max_speed, dtype: float64
In [120]: grouped.diff()
Out[120]:
falcon NaN
parrot -365.0
lion NaN
monkey NaN
leopard NaN
Name: max_speed, dtype: float64
В отличие от агрегаций, группировки, которые используются для разделения исходного объекта, не включаются в результат.
Примечание
Поскольку преобразования не включают группировки, используемые для разделения результата, аргументы as_index и sort в DataFrame.groupby() и
Series.groupby() не оказывают эффекта.
Распространенное использование преобразования — добавление результата обратно в исходный DataFrame.
In [121]: result = speeds.copy()
In [122]: result["cumsum"] = grouped.cumsum()
In [123]: result["diff"] = grouped.diff()
In [124]: result
Out[124]:
class order max_speed cumsum diff
falcon bird Falconiformes 389.0 389.0 NaN
parrot bird Psittaciformes 24.0 413.0 -365.0
lion mammal Carnivora 80.2 80.2 NaN
monkey mammal Primates NaN NaN NaN
leopard mammal Carnivora 58.0 138.2 NaN
Встроенные методы преобразования#
Следующие методы в GroupBy действуют как преобразования.
Метод |
Описание |
|---|---|
Обратное заполнение NA значений внутри каждой группы |
|
Вычисление кумулятивного подсчета внутри каждой группы |
|
Вычислить кумулятивный максимум в каждой группе |
|
Вычислить кумулятивный минимум в каждой группе |
|
Вычислите кумулятивное произведение в каждой группе |
|
Вычислить кумулятивную сумму внутри каждой группы |
|
Вычислите разницу между соседними значениями в каждой группе |
|
Прямое заполнение NA-значений внутри каждой группы |
|
Вычисление процентного изменения между соседними значениями в каждой группе |
|
Вычислить ранг каждого значения внутри каждой группы |
|
Сдвинуть значения вверх или вниз внутри каждой группы |
Кроме того, передача любого встроенного метода агрегации в виде строки в
transform() (см. следующий раздел) будет транслировать результат по группе, создавая преобразованный результат. Если метод агрегации имеет эффективную реализацию, это также будет производительно.
The transform() метод#
Аналогично метод агрегации,
transform() метод может принимать строковые псевдонимы для встроенных методов преобразования из предыдущего раздела. Он может также принимать строковые псевдонимы для
встроенных методов агрегации. Когда предоставлен метод агрегации, результат
будет транслироваться по группе.
In [125]: speeds
Out[125]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [126]: grouped = speeds.groupby("class")[["max_speed"]]
In [127]: grouped.transform("cumsum")
Out[127]:
max_speed
falcon 389.0
parrot 413.0
lion 80.2
monkey NaN
leopard 138.2
In [128]: grouped.transform("sum")
Out[128]:
max_speed
falcon 413.0
parrot 413.0
lion 138.2
monkey 138.2
leopard 138.2
В дополнение к строковым псевдонимам, transform() метод также
может принимать пользовательские функции (UDF). UDF должна:
Возвращает результат, который либо того же размера, что и фрагмент группы, либо может быть транслирован до размера фрагмента группы (например, скаляр,
grouped.transform(lambda x: x.iloc[-1])).Обрабатывайте колонку за колонкой в групповом фрагменте. Преобразование применяется к первому групповому фрагменту с помощью chunk.apply.
Не выполняйте операции на месте с фрагментом группы. Фрагменты групп следует рассматривать как неизменяемые, и изменения фрагмента группы могут привести к непредсказуемым результатам. См. Изменение с помощью методов пользовательских функций (UDF) для получения дополнительной информации.
(Опционально) работает со всеми столбцами всей группы фрагментов одновременно. Если это поддерживается, используется быстрый путь, начиная с второй чанк.
Примечание
Преобразование путем предоставления transform с пользовательской функцией часто менее производительно, чем использование встроенных методов GroupBy.
Рассмотрите разбиение сложной операции на цепочку операций, использующих встроенные методы.
Все примеры в этом разделе могут быть сделаны более производительными путем вызова встроенных методов вместо использования UDF. См. ниже для примеров.
Изменено в версии 2.0.0: При использовании .transform на сгруппированном DataFrame, и функция преобразования
возвращает DataFrame, pandas теперь выравнивает индекс результата
с индексом входных данных. Вы можете вызвать .to_numpy() внутри функции преобразования, чтобы избежать выравнивания.
Аналогично Метод aggregate(), результирующий тип данных будет отражать тип
функции преобразования. Если результаты из разных групп имеют разные типы данных, то
общий тип данных будет определен таким же образом, как DataFrame конструкция.
Предположим, мы хотим стандартизировать данные внутри каждой группы:
In [129]: index = pd.date_range("10/1/1999", periods=1100)
In [130]: ts = pd.Series(np.random.normal(0.5, 2, 1100), index)
In [131]: ts = ts.rolling(window=100, min_periods=100).mean().dropna()
In [132]: ts.head()
Out[132]:
2000-01-08 0.779333
2000-01-09 0.778852
2000-01-10 0.786476
2000-01-11 0.782797
2000-01-12 0.798110
Freq: D, dtype: float64
In [133]: ts.tail()
Out[133]:
2002-09-30 0.660294
2002-10-01 0.631095
2002-10-02 0.673601
2002-10-03 0.709213
2002-10-04 0.719369
Freq: D, dtype: float64
In [134]: transformed = ts.groupby(lambda x: x.year).transform(
.....: lambda x: (x - x.mean()) / x.std()
.....: )
.....:
Мы ожидаем, что результат теперь будет иметь среднее 0 и стандартное отклонение 1 в каждой группе (с учетом погрешности с плавающей запятой), что мы можем легко проверить:
# Original Data
In [135]: grouped = ts.groupby(lambda x: x.year)
In [136]: grouped.mean()
Out[136]:
2000 0.442441
2001 0.526246
2002 0.459365
dtype: float64
In [137]: grouped.std()
Out[137]:
2000 0.131752
2001 0.210945
2002 0.128753
dtype: float64
# Transformed Data
In [138]: grouped_trans = transformed.groupby(lambda x: x.year)
In [139]: grouped_trans.mean()
Out[139]:
2000 -4.870756e-16
2001 -1.545187e-16
2002 4.136282e-16
dtype: float64
In [140]: grouped_trans.std()
Out[140]:
2000 1.0
2001 1.0
2002 1.0
dtype: float64
Мы также можем визуально сравнить исходные и преобразованные наборы данных.
In [141]: compare = pd.DataFrame({"Original": ts, "Transformed": transformed})
In [142]: compare.plot()
Out[142]: 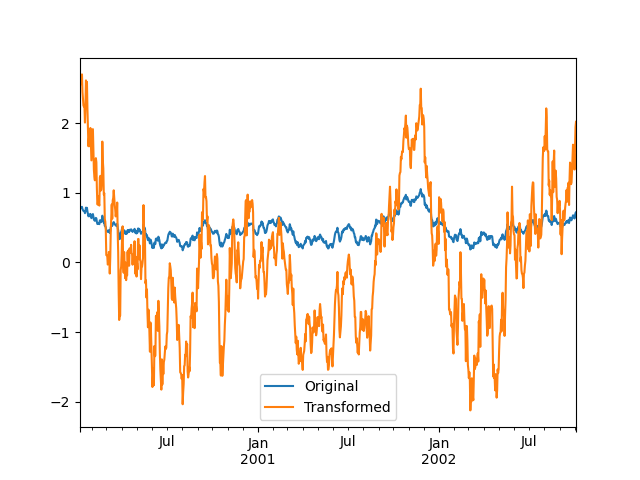
Функции преобразования, имеющие выходные данные меньшей размерности, транслируются для соответствия форме входного массива.
In [143]: ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min())
Out[143]:
2000-01-08 0.623893
2000-01-09 0.623893
2000-01-10 0.623893
2000-01-11 0.623893
2000-01-12 0.623893
...
2002-09-30 0.558275
2002-10-01 0.558275
2002-10-02 0.558275
2002-10-03 0.558275
2002-10-04 0.558275
Freq: D, Length: 1001, dtype: float64
Еще одно распространенное преобразование данных — замена пропущенных данных средним значением группы.
In [144]: cols = ["A", "B", "C"]
In [145]: values = np.random.randn(1000, 3)
In [146]: values[np.random.randint(0, 1000, 100), 0] = np.nan
In [147]: values[np.random.randint(0, 1000, 50), 1] = np.nan
In [148]: values[np.random.randint(0, 1000, 200), 2] = np.nan
In [149]: data_df = pd.DataFrame(values, columns=cols)
In [150]: data_df
Out[150]:
A B C
0 1.539708 -1.166480 0.533026
1 1.302092 -0.505754 NaN
2 -0.371983 1.104803 -0.651520
3 -1.309622 1.118697 -1.161657
4 -1.924296 0.396437 0.812436
.. ... ... ...
995 -0.093110 0.683847 -0.774753
996 -0.185043 1.438572 NaN
997 -0.394469 -0.642343 0.011374
998 -1.174126 1.857148 NaN
999 0.234564 0.517098 0.393534
[1000 rows x 3 columns]
In [151]: countries = np.array(["US", "UK", "GR", "JP"])
In [152]: key = countries[np.random.randint(0, 4, 1000)]
In [153]: grouped = data_df.groupby(key)
# Non-NA count in each group
In [154]: grouped.count()
Out[154]:
A B C
GR 209 217 189
JP 240 255 217
UK 216 231 193
US 239 250 217
In [155]: transformed = grouped.transform(lambda x: x.fillna(x.mean()))
Мы можем проверить, что групповые средние не изменились в преобразованных данных, и что преобразованные данные не содержат NA.
In [156]: grouped_trans = transformed.groupby(key)
In [157]: grouped.mean() # original group means
Out[157]:
A B C
GR -0.098371 -0.015420 0.068053
JP 0.069025 0.023100 -0.077324
UK 0.034069 -0.052580 -0.116525
US 0.058664 -0.020399 0.028603
In [158]: grouped_trans.mean() # transformation did not change group means
Out[158]:
A B C
GR -0.098371 -0.015420 0.068053
JP 0.069025 0.023100 -0.077324
UK 0.034069 -0.052580 -0.116525
US 0.058664 -0.020399 0.028603
In [159]: grouped.count() # original has some missing data points
Out[159]:
A B C
GR 209 217 189
JP 240 255 217
UK 216 231 193
US 239 250 217
In [160]: grouped_trans.count() # counts after transformation
Out[160]:
A B C
GR 228 228 228
JP 267 267 267
UK 247 247 247
US 258 258 258
In [161]: grouped_trans.size() # Verify non-NA count equals group size
Out[161]:
GR 228
JP 267
UK 247
US 258
dtype: int64
Как упоминалось в примечании выше, каждый из примеров в этом разделе может быть вычислен более эффективно с использованием встроенных методов. В коде ниже неэффективный способ с использованием пользовательской функции закомментирован, а более быстрая альтернатива приведена ниже.
# result = ts.groupby(lambda x: x.year).transform(
# lambda x: (x - x.mean()) / x.std()
# )
In [162]: grouped = ts.groupby(lambda x: x.year)
In [163]: result = (ts - grouped.transform("mean")) / grouped.transform("std")
# result = ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min())
In [164]: grouped = ts.groupby(lambda x: x.year)
In [165]: result = grouped.transform("max") - grouped.transform("min")
# grouped = data_df.groupby(key)
# result = grouped.transform(lambda x: x.fillna(x.mean()))
In [166]: grouped = data_df.groupby(key)
In [167]: result = data_df.fillna(grouped.transform("mean"))
Операции с окнами и передискретизацией#
Можно использовать resample(), expanding() и
rolling() в качестве методов на группировках.
Пример ниже применит rolling() метод на выборках столбца B, основанный на группах столбца A.
In [168]: df_re = pd.DataFrame({"A": [1] * 10 + [5] * 10, "B": np.arange(20)})
In [169]: df_re
Out[169]:
A B
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
.. .. ..
15 5 15
16 5 16
17 5 17
18 5 18
19 5 19
[20 rows x 2 columns]
In [170]: df_re.groupby("A").rolling(4).B.mean()
Out[170]:
A
1 0 NaN
1 NaN
2 NaN
3 1.5
4 2.5
...
5 15 13.5
16 14.5
17 15.5
18 16.5
19 17.5
Name: B, Length: 20, dtype: float64
The expanding() метод будет накапливать заданную операцию
(sum() в примере) для всех членов каждой конкретной
группы.
In [171]: df_re.groupby("A").expanding().sum()
Out[171]:
B
A
1 0 0.0
1 1.0
2 3.0
3 6.0
4 10.0
... ...
5 15 75.0
16 91.0
17 108.0
18 126.0
19 145.0
[20 rows x 1 columns]
Предположим, вы хотите использовать resample() метод для получения ежедневной частоты в каждой группе вашего dataframe и желания заполнить пропущенные значения с помощью ffill() метод.
In [172]: df_re = pd.DataFrame(
.....: {
.....: "date": pd.date_range(start="2016-01-01", periods=4, freq="W"),
.....: "group": [1, 1, 2, 2],
.....: "val": [5, 6, 7, 8],
.....: }
.....: ).set_index("date")
.....:
In [173]: df_re
Out[173]:
group val
date
2016-01-03 1 5
2016-01-10 1 6
2016-01-17 2 7
2016-01-24 2 8
In [174]: df_re.groupby("group").resample("1D", include_groups=False).ffill()
Out[174]:
val
group date
1 2016-01-03 5
2016-01-04 5
2016-01-05 5
2016-01-06 5
2016-01-07 5
... ...
2 2016-01-20 7
2016-01-21 7
2016-01-22 7
2016-01-23 7
2016-01-24 8
[16 rows x 1 columns]
Фильтрация#
Фильтрация — это операция GroupBy, которая выбирает подмножество исходного группируемого объекта. Она может либо отфильтровывать целые группы, части групп или и то, и другое. Фильтрации возвращают отфильтрованную версию вызывающего объекта, включая столбцы группировки, когда они предоставлены. В следующем примере, class включен в результат.
In [175]: speeds
Out[175]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [176]: speeds.groupby("class").nth(1)
Out[176]:
class order max_speed
parrot bird Psittaciformes 24.0
monkey mammal Primates NaN
Примечание
В отличие от агрегаций, фильтрации не добавляют ключи групп к индексу результата. Из-за этого передача as_index=False или sort=True не повлияет на эти методы.
Фильтрации будут учитывать выбор подмножества столбцов объекта GroupBy.
In [177]: speeds.groupby("class")[["order", "max_speed"]].nth(1)
Out[177]:
order max_speed
parrot Psittaciformes 24.0
monkey Primates NaN
Встроенные фильтрации#
Следующие методы в GroupBy действуют как фильтрации. Все эти методы имеют эффективную, специфичную для GroupBy, реализацию.
Метод |
Описание |
|---|---|
Выберите верхнюю строку(и) каждой группы |
|
Выбрать n-ю строку(и) каждой группы |
|
Выберите нижнюю строку(и) каждой группы |
Пользователи также могут использовать преобразования вместе с булевым индексированием для построения сложных фильтраций внутри групп. Например, предположим, что у нас есть группы продуктов и их объемы, и мы хотим выбрать только крупнейшие продукты, охватывающие не более 90% от общего объема в каждой группе.
In [178]: product_volumes = pd.DataFrame(
.....: {
.....: "group": list("xxxxyyy"),
.....: "product": list("abcdefg"),
.....: "volume": [10, 30, 20, 15, 40, 10, 20],
.....: }
.....: )
.....:
In [179]: product_volumes
Out[179]:
group product volume
0 x a 10
1 x b 30
2 x c 20
3 x d 15
4 y e 40
5 y f 10
6 y g 20
# Sort by volume to select the largest products first
In [180]: product_volumes = product_volumes.sort_values("volume", ascending=False)
In [181]: grouped = product_volumes.groupby("group")["volume"]
In [182]: cumpct = grouped.cumsum() / grouped.transform("sum")
In [183]: cumpct
Out[183]:
4 0.571429
1 0.400000
2 0.666667
6 0.857143
3 0.866667
0 1.000000
5 1.000000
Name: volume, dtype: float64
In [184]: significant_products = product_volumes[cumpct <= 0.9]
In [185]: significant_products.sort_values(["group", "product"])
Out[185]:
group product volume
1 x b 30
2 x c 20
3 x d 15
4 y e 40
6 y g 20
The filter метод#
Примечание
Фильтрация путем предоставления filter с пользовательской функцией (UDF) часто менее производительно, чем использование встроенных методов GroupBy. Рассмотрите разбиение сложной операции на цепочку операций, использующих встроенные методы.
The filter метод принимает пользовательскую функцию (UDF), которая при применении к
целой группе возвращает либо True или False. Результат filter
метод затем является подмножеством групп, для которых UDF вернул True.
Предположим, мы хотим взять только элементы, принадлежащие группам с суммой группы больше 2.
In [186]: sf = pd.Series([1, 1, 2, 3, 3, 3])
In [187]: sf.groupby(sf).filter(lambda x: x.sum() > 2)
Out[187]:
3 3
4 3
5 3
dtype: int64
Еще одна полезная операция — фильтрация элементов, принадлежащих группам с небольшим количеством участников.
In [188]: dff = pd.DataFrame({"A": np.arange(8), "B": list("aabbbbcc")})
In [189]: dff.groupby("B").filter(lambda x: len(x) > 2)
Out[189]:
A B
2 2 b
3 3 b
4 4 b
5 5 b
В качестве альтернативы, вместо удаления проблемных групп, мы можем вернуть объекты с аналогичным индексом, где группы, не прошедшие фильтр, заполнены значениями NaN.
In [190]: dff.groupby("B").filter(lambda x: len(x) > 2, dropna=False)
Out[190]:
A B
0 NaN NaN
1 NaN NaN
2 2.0 b
3 3.0 b
4 4.0 b
5 5.0 b
6 NaN NaN
7 NaN NaN
Для DataFrame с несколькими столбцами фильтры должны явно указывать столбец как критерий фильтрации.
In [191]: dff["C"] = np.arange(8)
In [192]: dff.groupby("B").filter(lambda x: len(x["C"]) > 2)
Out[192]:
A B C
2 2 b 2
3 3 b 3
4 4 b 4
5 5 b 5
Гибкий apply#
Некоторые операции над сгруппированными данными могут не подходить под категории агрегации,
преобразования или фильтрации. Для них можно использовать apply
функция.
Предупреждение
apply должен попытаться определить по результату, должен ли он действовать как редуктор, преобразователь, или фильтр, в зависимости от того, что именно передано. Таким образом, сгруппированный столбец(ы) может быть включен в вывод или нет. Хотя он пытается интеллектуально угадать, как вести себя, иногда он может ошибаться.
Примечание
Все примеры в этом разделе можно более надежно и эффективно вычислить с использованием других функций pandas.
In [193]: df
Out[193]:
A B C D
0 foo one -0.575247 1.346061
1 bar one 0.254161 1.511763
2 foo two -1.143704 1.627081
3 bar three 0.215897 -0.990582
4 foo two 1.193555 -0.441652
5 bar two -0.077118 1.211526
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
In [194]: grouped = df.groupby("A")
# could also just call .describe()
In [195]: grouped["C"].apply(lambda x: x.describe())
Out[195]:
A
bar count 3.000000
mean 0.130980
std 0.181231
min -0.077118
25% 0.069390
...
foo min -1.143704
25% -0.862495
50% -0.575247
75% -0.408530
max 1.193555
Name: C, Length: 16, dtype: float64
Размерность возвращаемого результата также может измениться:
In [196]: grouped = df.groupby('A')['C']
In [197]: def f(group):
.....: return pd.DataFrame({'original': group,
.....: 'demeaned': group - group.mean()})
.....:
In [198]: grouped.apply(f)
Out[198]:
original demeaned
A
bar 1 0.254161 0.123181
3 0.215897 0.084917
5 -0.077118 -0.208098
foo 0 -0.575247 -0.215962
2 -1.143704 -0.784420
4 1.193555 1.552839
6 -0.408530 -0.049245
7 -0.862495 -0.503211
apply на Series может работать с возвращаемым значением из применённой функции,
которая сама является серией, и возможно повысить тип результата до DataFrame:
In [199]: def f(x):
.....: return pd.Series([x, x ** 2], index=["x", "x^2"])
.....:
In [200]: s = pd.Series(np.random.rand(5))
In [201]: s
Out[201]:
0 0.582898
1 0.098352
2 0.001438
3 0.009420
4 0.815826
dtype: float64
In [202]: s.apply(f)
Out[202]:
x x^2
0 0.582898 0.339770
1 0.098352 0.009673
2 0.001438 0.000002
3 0.009420 0.000089
4 0.815826 0.665572
Аналогично Метод aggregate(), результирующий тип данных будет отражать тип данных функции
apply. Если результаты из разных групп имеют разные типы данных, то
общий тип данных будет определён таким же способом, как DataFrame конструкция.
Управление размещением сгруппированных колонок с помощью group_keys#
Чтобы контролировать, включаются ли сгруппированные столбцы в индексы, вы можете использовать
аргумент group_keys который по умолчанию равен True. Сравнить
In [203]: df.groupby("A", group_keys=True).apply(lambda x: x, include_groups=False)
Out[203]:
B C D
A
bar 1 one 0.254161 1.511763
3 three 0.215897 -0.990582
5 two -0.077118 1.211526
foo 0 one -0.575247 1.346061
2 two -1.143704 1.627081
4 two 1.193555 -0.441652
6 one -0.408530 0.268520
7 three -0.862495 0.024580
с
In [204]: df.groupby("A", group_keys=False).apply(lambda x: x, include_groups=False)
Out[204]:
B C D
0 one -0.575247 1.346061
1 one 0.254161 1.511763
2 two -1.143704 1.627081
3 three 0.215897 -0.990582
4 two 1.193555 -0.441652
5 two -0.077118 1.211526
6 one -0.408530 0.268520
7 three -0.862495 0.024580
Ускоренные процедуры Numba#
Добавлено в версии 1.1.
Если Numba установлен как опциональная зависимость, transform и
aggregate методы поддерживают engine='numba' и engine_kwargs аргументы.
См. улучшение производительности с помощью Numba для общего использования аргументов
и соображений производительности.
Сигнатура функции должна начинаться с values, index точно как данные, принадлежащие каждой группе,
будут переданы в values, и групповой индекс будет передан в index.
Предупреждение
При использовании engine='numba', не будет внутреннего поведения "отката". Групповые
данные и групповой индекс будут передаваться как массивы NumPy в JIT-компилированную пользовательскую функцию, и никаких
альтернативных попыток выполнения предпринято не будет.
Другие полезные функции#
Исключение нечисловых столбцов#
Снова рассмотрим пример DataFrame, который мы изучали:
In [205]: df
Out[205]:
A B C D
0 foo one -0.575247 1.346061
1 bar one 0.254161 1.511763
2 foo two -1.143704 1.627081
3 bar three 0.215897 -0.990582
4 foo two 1.193555 -0.441652
5 bar two -0.077118 1.211526
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
Предположим, мы хотим вычислить стандартное отклонение, сгруппированное по A
столбец. Есть небольшая проблема, а именно, что нас не интересуют данные в столбце B потому что он не числовой. Вы можете избежать нечисловых столбцов,
указав numeric_only=True:
In [206]: df.groupby("A").std(numeric_only=True)
Out[206]:
C D
A
bar 0.181231 1.366330
foo 0.912265 0.884785
Обратите внимание, что df.groupby('A').colname.std(). более эффективен, чем
df.groupby('A').std().colname. Поэтому если результат агрегационной функции
нужен только для одного столбца (здесь colname), он может быть отфильтрован
до применение агрегирующей функции.
In [207]: from decimal import Decimal
In [208]: df_dec = pd.DataFrame(
.....: {
.....: "id": [1, 2, 1, 2],
.....: "int_column": [1, 2, 3, 4],
.....: "dec_column": [
.....: Decimal("0.50"),
.....: Decimal("0.15"),
.....: Decimal("0.25"),
.....: Decimal("0.40"),
.....: ],
.....: }
.....: )
.....:
In [209]: df_dec.groupby(["id"])[["dec_column"]].sum()
Out[209]:
dec_column
id
1 0.75
2 0.55
Обработка (не)наблюдаемых значений Categorical#
При использовании Categorical группировщик (как одиночный группировщик или как часть нескольких группировщиков), observed ключевое слово
управляет, возвращать ли декартово произведение всех возможных значений группировщиков (observed=False) или только тех
которые являются наблюдаемыми группировщиками (observed=True).
Показать все значения:
In [210]: pd.Series([1, 1, 1]).groupby(
.....: pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=False
.....: ).count()
.....:
Out[210]:
a 3
b 0
dtype: int64
Показать только наблюдаемые значения:
In [211]: pd.Series([1, 1, 1]).groupby(
.....: pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=True
.....: ).count()
.....:
Out[211]:
a 3
dtype: int64
Возвращаемый dtype сгруппированного будет всегда включать все категорий, которые были сгруппированы.
In [212]: s = (
.....: pd.Series([1, 1, 1])
.....: .groupby(pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=True)
.....: .count()
.....: )
.....:
In [213]: s.index.dtype
Out[213]: CategoricalDtype(categories=['a', 'b'], ordered=False, categories_dtype=object)
Обработка группы NA#
По NA, мы имеем в виду любой NA значения, включая
NA, NaN, NaT, и None. Если есть какие-либо NA значения в
ключе группировки, по умолчанию они будут исключены. Другими словами, любые
"NA группа” будет удалена. Вы можете включить группы NA, указав dropna=False.
In [214]: df = pd.DataFrame({"key": [1.0, 1.0, np.nan, 2.0, np.nan], "A": [1, 2, 3, 4, 5]})
In [215]: df
Out[215]:
key A
0 1.0 1
1 1.0 2
2 NaN 3
3 2.0 4
4 NaN 5
In [216]: df.groupby("key", dropna=True).sum()
Out[216]:
A
key
1.0 3
2.0 4
In [217]: df.groupby("key", dropna=False).sum()
Out[217]:
A
key
1.0 3
2.0 4
NaN 8
Группировка с упорядоченными факторами#
Категориальные переменные, представленные как экземпляры Categorical класс
может использоваться как ключи группировки. Если да, порядок уровней будет сохранен. Когда
observed=False и sort=False, любые ненаблюдаемые категории будут в
конце результата по порядку.
In [218]: days = pd.Categorical(
.....: values=["Wed", "Mon", "Thu", "Mon", "Wed", "Sat"],
.....: categories=["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"],
.....: )
.....:
In [219]: data = pd.DataFrame(
.....: {
.....: "day": days,
.....: "workers": [3, 4, 1, 4, 2, 2],
.....: }
.....: )
.....:
In [220]: data
Out[220]:
day workers
0 Wed 3
1 Mon 4
2 Thu 1
3 Mon 4
4 Wed 2
5 Sat 2
In [221]: data.groupby("day", observed=False, sort=True).sum()
Out[221]:
workers
day
Mon 8
Tue 0
Wed 5
Thu 1
Fri 0
Sat 2
Sun 0
In [222]: data.groupby("day", observed=False, sort=False).sum()
Out[222]:
workers
day
Wed 5
Mon 8
Thu 1
Sat 2
Tue 0
Fri 0
Sun 0
Группировка со спецификацией группировщика#
Возможно, вам потребуется указать немного больше данных для правильной группировки. Вы можете использовать pd.Grouper для предоставления этого локального контроля.
In [223]: import datetime
In [224]: df = pd.DataFrame(
.....: {
.....: "Branch": "A A A A A A A B".split(),
.....: "Buyer": "Carl Mark Carl Carl Joe Joe Joe Carl".split(),
.....: "Quantity": [1, 3, 5, 1, 8, 1, 9, 3],
.....: "Date": [
.....: datetime.datetime(2013, 1, 1, 13, 0),
.....: datetime.datetime(2013, 1, 1, 13, 5),
.....: datetime.datetime(2013, 10, 1, 20, 0),
.....: datetime.datetime(2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 10, 1, 20, 0),
.....: datetime.datetime(2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 12, 2, 12, 0),
.....: datetime.datetime(2013, 12, 2, 14, 0),
.....: ],
.....: }
.....: )
.....:
In [225]: df
Out[225]:
Branch Buyer Quantity Date
0 A Carl 1 2013-01-01 13:00:00
1 A Mark 3 2013-01-01 13:05:00
2 A Carl 5 2013-10-01 20:00:00
3 A Carl 1 2013-10-02 10:00:00
4 A Joe 8 2013-10-01 20:00:00
5 A Joe 1 2013-10-02 10:00:00
6 A Joe 9 2013-12-02 12:00:00
7 B Carl 3 2013-12-02 14:00:00
Группировка по определенному столбцу с желаемой частотой. Это похоже на ресемплинг.
In [226]: df.groupby([pd.Grouper(freq="1ME", key="Date"), "Buyer"])[["Quantity"]].sum()
Out[226]:
Quantity
Date Buyer
2013-01-31 Carl 1
Mark 3
2013-10-31 Carl 6
Joe 9
2013-12-31 Carl 3
Joe 9
Когда freq указан, объект, возвращаемый pd.Grouper будет экземпляром pandas.api.typing.TimeGrouper. Когда есть столбец и индекс
с одинаковым именем, вы можете использовать key для группировки по столбцу и level
для группировки по индексу.
In [227]: df = df.set_index("Date")
In [228]: df["Date"] = df.index + pd.offsets.MonthEnd(2)
In [229]: df.groupby([pd.Grouper(freq="6ME", key="Date"), "Buyer"])[["Quantity"]].sum()
Out[229]:
Quantity
Date Buyer
2013-02-28 Carl 1
Mark 3
2014-02-28 Carl 9
Joe 18
In [230]: df.groupby([pd.Grouper(freq="6ME", level="Date"), "Buyer"])[["Quantity"]].sum()
Out[230]:
Quantity
Date Buyer
2013-01-31 Carl 1
Mark 3
2014-01-31 Carl 9
Joe 18
Взятие первых строк каждой группы#
Так же как для DataFrame или Series, вы можете вызывать head и tail на groupby:
In [231]: df = pd.DataFrame([[1, 2], [1, 4], [5, 6]], columns=["A", "B"])
In [232]: df
Out[232]:
A B
0 1 2
1 1 4
2 5 6
In [233]: g = df.groupby("A")
In [234]: g.head(1)
Out[234]:
A B
0 1 2
2 5 6
In [235]: g.tail(1)
Out[235]:
A B
1 1 4
2 5 6
Это показывает первые или последние n строк из каждой группы.
Взятие n-й строки каждой группы#
Чтобы выбрать n-й элемент из каждой группы, используйте DataFrameGroupBy.nth() или
SeriesGroupBy.nth(). Передаваемые аргументы могут быть любыми целыми числами, списками целых чисел,
срезами или списками срезов; см. примеры ниже. Когда n-й элемент группы
не существует, возникает ошибка не вызывается; вместо этого соответствующие строки не возвращаются.
В общем случае эта операция действует как фильтрация. В некоторых случаях она также возвращает одну строку на группу, что делает её также редукцией. Однако, поскольку в общем случае она может возвращать ноль или несколько строк на группу, pandas рассматривает её как фильтрацию во всех случаях.
In [236]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], columns=["A", "B"])
In [237]: g = df.groupby("A")
In [238]: g.nth(0)
Out[238]:
A B
0 1 NaN
2 5 6.0
In [239]: g.nth(-1)
Out[239]:
A B
1 1 4.0
2 5 6.0
In [240]: g.nth(1)
Out[240]:
A B
1 1 4.0
Если n-й элемент группы не существует, то соответствующая строка не включается
в результат. В частности, если указанный n больше любой группы, результат будет пустым DataFrame.
In [241]: g.nth(5)
Out[241]:
Empty DataFrame
Columns: [A, B]
Index: []
Если вы хотите выбрать n-й непустой элемент, используйте dropna kwarg. Для DataFrame это должно быть либо 'any' или 'all' точно так же, как вы бы передали в dropna:
# nth(0) is the same as g.first()
In [242]: g.nth(0, dropna="any")
Out[242]:
A B
1 1 4.0
2 5 6.0
In [243]: g.first()
Out[243]:
B
A
1 4.0
5 6.0
# nth(-1) is the same as g.last()
In [244]: g.nth(-1, dropna="any")
Out[244]:
A B
1 1 4.0
2 5 6.0
In [245]: g.last()
Out[245]:
B
A
1 4.0
5 6.0
In [246]: g.B.nth(0, dropna="all")
Out[246]:
1 4.0
2 6.0
Name: B, dtype: float64
Вы также можете выбрать несколько строк из каждой группы, указав несколько значений nth в виде списка целых чисел.
In [247]: business_dates = pd.date_range(start="4/1/2014", end="6/30/2014", freq="B")
In [248]: df = pd.DataFrame(1, index=business_dates, columns=["a", "b"])
# get the first, 4th, and last date index for each month
In [249]: df.groupby([df.index.year, df.index.month]).nth([0, 3, -1])
Out[249]:
a b
2014-04-01 1 1
2014-04-04 1 1
2014-04-30 1 1
2014-05-01 1 1
2014-05-06 1 1
2014-05-30 1 1
2014-06-02 1 1
2014-06-05 1 1
2014-06-30 1 1
Вы также можете использовать срезы или списки срезов.
In [250]: df.groupby([df.index.year, df.index.month]).nth[1:]
Out[250]:
a b
2014-04-02 1 1
2014-04-03 1 1
2014-04-04 1 1
2014-04-07 1 1
2014-04-08 1 1
... .. ..
2014-06-24 1 1
2014-06-25 1 1
2014-06-26 1 1
2014-06-27 1 1
2014-06-30 1 1
[62 rows x 2 columns]
In [251]: df.groupby([df.index.year, df.index.month]).nth[1:, :-1]
Out[251]:
a b
2014-04-01 1 1
2014-04-02 1 1
2014-04-03 1 1
2014-04-04 1 1
2014-04-07 1 1
... .. ..
2014-06-24 1 1
2014-06-25 1 1
2014-06-26 1 1
2014-06-27 1 1
2014-06-30 1 1
[65 rows x 2 columns]
Перечисление элементов группы#
Чтобы увидеть порядок, в котором каждая строка появляется в своей группе, используйте
cumcount method:
In [252]: dfg = pd.DataFrame(list("aaabba"), columns=["A"])
In [253]: dfg
Out[253]:
A
0 a
1 a
2 a
3 b
4 b
5 a
In [254]: dfg.groupby("A").cumcount()
Out[254]:
0 0
1 1
2 2
3 0
4 1
5 3
dtype: int64
In [255]: dfg.groupby("A").cumcount(ascending=False)
Out[255]:
0 3
1 2
2 1
3 1
4 0
5 0
dtype: int64
Перечисление групп#
Чтобы увидеть порядок групп (в отличие от порядка строк
внутри группы, заданного cumcount) вы можете использовать
DataFrameGroupBy.ngroup().
Обратите внимание, что номера, присвоенные группам, соответствуют порядку, в котором группы будут видны при итерации по объекту groupby, а не порядку, в котором они впервые наблюдаются.
In [256]: dfg = pd.DataFrame(list("aaabba"), columns=["A"])
In [257]: dfg
Out[257]:
A
0 a
1 a
2 a
3 b
4 b
5 a
In [258]: dfg.groupby("A").ngroup()
Out[258]:
0 0
1 0
2 0
3 1
4 1
5 0
dtype: int64
In [259]: dfg.groupby("A").ngroup(ascending=False)
Out[259]:
0 1
1 1
2 1
3 0
4 0
5 1
dtype: int64
Построение графиков#
Groupby также работает с некоторыми методами построения графиков. В этом случае предположим, что значения в столбце 1 в среднем в 3 раза выше в группе "B".
In [260]: np.random.seed(1234)
In [261]: df = pd.DataFrame(np.random.randn(50, 2))
In [262]: df["g"] = np.random.choice(["A", "B"], size=50)
In [263]: df.loc[df["g"] == "B", 1] += 3
Мы можем легко визуализировать это с помощью boxplot:
In [264]: df.groupby("g").boxplot()
Out[264]:
A Axes(0.1,0.15;0.363636x0.75)
B Axes(0.536364,0.15;0.363636x0.75)
dtype: object
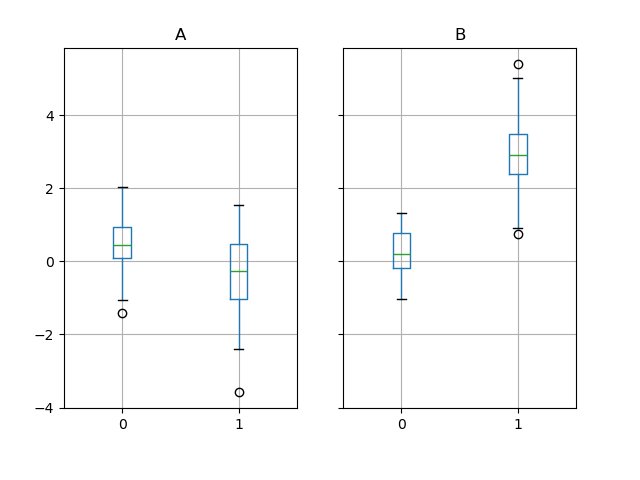
Результат вызова boxplot является словарём, ключи которого представляют значения
нашего столбца группировки g (“A” и “B”). Значения результирующего словаря
могут контролироваться с помощью return_type ключевое слово boxplot.
См. документация по визуализации подробнее.
Предупреждение
По историческим причинам, df.groupby("g").boxplot() не эквивалентно
df.boxplot(by="g"). См. здесь для объяснения.
Конвейерный вызов функций#
Аналогично функциональности, предоставляемой DataFrame и Series, функции, которые принимают GroupBy объекты могут быть объединены в цепочку с использованием pipe метод для
обеспечения более чистого и читаемого синтаксиса. Чтобы узнать о .pipe в общих терминах,
см. здесь.
Объединение .groupby и .pipe часто полезно, когда нужно повторно использовать
объекты GroupBy.
В качестве примера представьте DataFrame со столбцами для магазинов, продуктов, выручки и проданного количества. Мы хотели бы выполнить групповой расчет цены (т.е. выручка/количество) на магазин и на продукт. Мы могли бы сделать это в несколько шагов, но выражение через конвейер может сделать код более читаемым. Сначала мы устанавливаем данные:
In [265]: n = 1000
In [266]: df = pd.DataFrame(
.....: {
.....: "Store": np.random.choice(["Store_1", "Store_2"], n),
.....: "Product": np.random.choice(["Product_1", "Product_2"], n),
.....: "Revenue": (np.random.random(n) * 50 + 10).round(2),
.....: "Quantity": np.random.randint(1, 10, size=n),
.....: }
.....: )
.....:
In [267]: df.head(2)
Out[267]:
Store Product Revenue Quantity
0 Store_2 Product_1 26.12 1
1 Store_2 Product_1 28.86 1
Теперь мы находим цены на каждый магазин/продукт.
In [268]: (
.....: df.groupby(["Store", "Product"])
.....: .pipe(lambda grp: grp.Revenue.sum() / grp.Quantity.sum())
.....: .unstack()
.....: .round(2)
.....: )
.....:
Out[268]:
Product Product_1 Product_2
Store
Store_1 6.82 7.05
Store_2 6.30 6.64
Конвейерная обработка также может быть выразительной, когда вы хотите передать сгруппированный объект в какую-либо произвольную функцию, например:
In [269]: def mean(groupby):
.....: return groupby.mean()
.....:
In [270]: df.groupby(["Store", "Product"]).pipe(mean)
Out[270]:
Revenue Quantity
Store Product
Store_1 Product_1 34.622727 5.075758
Product_2 35.482815 5.029630
Store_2 Product_1 32.972837 5.237589
Product_2 34.684360 5.224000
Здесь mean берет объект GroupBy и находит среднее столбцов Revenue и Quantity
соответственно для каждой комбинации Store-Product. mean функция может быть любой функцией, принимающей объект GroupBy; .pipe передаст объект GroupBy как параметр в указанную вами функцию.
Примеры#
Факторизация по нескольким столбцам#
Используя DataFrameGroupBy.ngroup(), мы можем извлекать
информацию о группах способом, похожим на factorize() (как описано
далее в API изменения формы), но который естественным образом применяется
к нескольким столбцам смешанного типа и различных
источников. Это может быть полезно как промежуточный категориальный шаг
в обработке, когда отношения между строками групп более
важны, чем их содержимое, или как вход для алгоритма, который принимает
только целочисленное кодирование. (Для получения дополнительной информации о поддержке в
pandas полноценных категориальных данных см. Введение в категориальные данные и
документация API.)
In [271]: dfg = pd.DataFrame({"A": [1, 1, 2, 3, 2], "B": list("aaaba")})
In [272]: dfg
Out[272]:
A B
0 1 a
1 1 a
2 2 a
3 3 b
4 2 a
In [273]: dfg.groupby(["A", "B"]).ngroup()
Out[273]:
0 0
1 0
2 1
3 2
4 1
dtype: int64
In [274]: dfg.groupby(["A", [0, 0, 0, 1, 1]]).ngroup()
Out[274]:
0 0
1 0
2 1
3 3
4 2
dtype: int64
Группировка по индексатору для 'передискретизации' данных#
Ресемплинг создает новые гипотетические выборки (ресемплы) из уже существующих наблюдаемых данных или из модели, генерирующей данные. Эти новые выборки похожи на предшествующие выборки.
Для того чтобы resample работал с индексами, не являющимися датой-временем, можно использовать следующую процедуру.
В следующих примерах, df.index // 5 тип данных, содержащий
Примечание
Пример ниже показывает, как можно уменьшить частоту дискретизации путем объединения выборок в меньшее количество. Здесь с использованием df.index // 5, мы агрегируем выборки в бины. Применяя std() функция, мы агрегируем информацию, содержащуюся во многих образцах, в небольшое подмножество значений, которое является их стандартным отклонением, тем самым уменьшая количество образцов.
In [275]: df = pd.DataFrame(np.random.randn(10, 2))
In [276]: df
Out[276]:
0 1
0 -0.793893 0.321153
1 0.342250 1.618906
2 -0.975807 1.918201
3 -0.810847 -1.405919
4 -1.977759 0.461659
5 0.730057 -1.316938
6 -0.751328 0.528290
7 -0.257759 -1.081009
8 0.505895 -1.701948
9 -1.006349 0.020208
In [277]: df.index // 5
Out[277]: Index([0, 0, 0, 0, 0, 1, 1, 1, 1, 1], dtype='int64')
In [278]: df.groupby(df.index // 5).std()
Out[278]:
0 1
0 0.823647 1.312912
1 0.760109 0.942941
Возврат Series для распространения имён#
Сгруппировать столбцы DataFrame, вычислить набор метрик и вернуть именованный Series. Имя Series используется как имя для индекса столбцов. Это особенно полезно в сочетании с операциями изменения формы, такими как укладка, в которых имя индекса столбцов будет использоваться как имя вставленного столбца:
In [279]: df = pd.DataFrame(
.....: {
.....: "a": [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2],
.....: "b": [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1],
.....: "c": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0],
.....: "d": [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1],
.....: }
.....: )
.....:
In [280]: def compute_metrics(x):
.....: result = {"b_sum": x["b"].sum(), "c_mean": x["c"].mean()}
.....: return pd.Series(result, name="metrics")
.....:
In [281]: result = df.groupby("a").apply(compute_metrics, include_groups=False)
In [282]: result
Out[282]:
metrics b_sum c_mean
a
0 2.0 0.5
1 2.0 0.5
2 2.0 0.5
In [283]: result.stack(future_stack=True)
Out[283]:
a metrics
0 b_sum 2.0
c_mean 0.5
1 b_sum 2.0
c_mean 0.5
2 b_sum 2.0
c_mean 0.5
dtype: float64