Введение в структуры данных#
Мы начнем с краткого, не исчерпывающего обзора основных структур данных в pandas, чтобы вы могли начать работу. Основное поведение, касающееся типов данных, индексирования, маркировки осей и выравнивания, применяется ко всем объектам. Чтобы начать, импортируйте NumPy и загрузите pandas в свое пространство имен:
In [1]: import numpy as np
In [2]: import pandas as pd
По сути, выравнивание данных является внутренним. Связь между метками и данными не будет разорвана, если вы не сделаете это явно.
Мы дадим краткое введение в структуры данных, затем рассмотрим все широкие категории функциональности и методов в отдельных разделах.
Series#
Series это одномерный помеченный массив, способный хранить любые типы данных (целые числа, строки, числа с плавающей точкой, объекты Python и т.д.). Метки осей в совокупности называются index. Основной метод создания Series это вызвать:
s = pd.Series(data, index=index)
Здесь, data может быть многими разными вещами:
словарь Python
ndarray
скалярное значение (например, 5)
Переданный index является списком меток осей. Таким образом, это разделяется на несколько случаев в зависимости от того, что данные:
Из ndarray
Если data является ndarray, index должен быть той же длины, что и данные. Если
индекс не передан, он будет создан со значениями [0, ..., len(data) - 1].
In [3]: s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
In [4]: s
Out[4]:
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 1.212112
dtype: float64
In [5]: s.index
Out[5]: Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
In [6]: pd.Series(np.random.randn(5))
Out[6]:
0 -0.173215
1 0.119209
2 -1.044236
3 -0.861849
4 -2.104569
dtype: float64
Примечание
pandas поддерживает неуникальные значения индекса. Если выполняется операция, которая не поддерживает повторяющиеся значения индекса, будет вызвано исключение в этот момент.
Из словаря
Series может быть создан из словарей:
In [7]: d = {"b": 1, "a": 0, "c": 2}
In [8]: pd.Series(d)
Out[8]:
b 1
a 0
c 2
dtype: int64
Если передан индекс, значения в данных, соответствующие меткам в индексе, будут извлечены.
In [9]: d = {"a": 0.0, "b": 1.0, "c": 2.0}
In [10]: pd.Series(d)
Out[10]:
a 0.0
b 1.0
c 2.0
dtype: float64
In [11]: pd.Series(d, index=["b", "c", "d", "a"])
Out[11]:
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
Примечание
NaN (не число) — стандартный маркер пропущенных данных, используемый в pandas.
Из скалярного значения
Если data является скалярным значением, должен быть предоставлен
индекс. Значение будет повторено, чтобы соответствовать длине index.
In [12]: pd.Series(5.0, index=["a", "b", "c", "d", "e"])
Out[12]:
a 5.0
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float64
Series подобен ndarray#
Series действует очень похоже на ndarray и является допустимым аргументом для большинства функций NumPy.
Однако операции, такие как срезы, также будут срезать индекс.
In [13]: s.iloc[0]
Out[13]: 0.4691122999071863
In [14]: s.iloc[:3]
Out[14]:
a 0.469112
b -0.282863
c -1.509059
dtype: float64
In [15]: s[s > s.median()]
Out[15]:
a 0.469112
e 1.212112
dtype: float64
In [16]: s.iloc[[4, 3, 1]]
Out[16]:
e 1.212112
d -1.135632
b -0.282863
dtype: float64
In [17]: np.exp(s)
Out[17]:
a 1.598575
b 0.753623
c 0.221118
d 0.321219
e 3.360575
dtype: float64
Примечание
Мы рассмотрим индексацию на основе массивов, такую как s.iloc[[4, 3, 1]]
в раздел об индексировании.
Как массив NumPy, pandas Series имеет один dtype.
In [18]: s.dtype
Out[18]: dtype('float64')
Это часто dtype NumPy. Однако pandas и сторонние библиотеки расширяют систему типов NumPy в некоторых местах, в этом случае dtype будет ExtensionDtype. Некоторые примеры в
pandas: Категориальные данные и Допускающий значения null целочисленный тип данных. См. dtypes
подробнее.
Если вам нужен фактический массив, поддерживающий Series, используйте Series.array.
In [19]: s.array
Out[19]:
Доступ к массиву может быть полезен, когда вам нужно выполнить какую-либо операцию без индекса (чтобы отключить автоматическое выравнивание, например).
Series.array всегда будет ExtensionArray.
Кратко, ExtensionArray - это тонкая оболочка вокруг одного или нескольких конкретный массивы как
numpy.ndarray. pandas умеет брать ExtensionArray и
сохранить его в Series или столбец DataFrame.
См. dtypes подробнее.
В то время как Series является ndarray-подобным, если вам нужен фактический ndarray, затем использовать
Series.to_numpy().
In [20]: s.to_numpy()
Out[20]: array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
Даже если Series поддерживается ExtensionArray,
Series.to_numpy() вернет массив NumPy ndarray.
Series ведет себя как словарь#
A Series также похож на словарь фиксированного размера, поскольку вы можете получать и устанавливать значения по метке
индекса:
In [21]: s["a"]
Out[21]: 0.4691122999071863
In [22]: s["e"] = 12.0
In [23]: s
Out[23]:
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 12.000000
dtype: float64
In [24]: "e" in s
Out[24]: True
In [25]: "f" in s
Out[25]: False
Если метка не содержится в индексе, возникает исключение:
In [26]: s["f"]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File ~/work/pandas/pandas/pandas/core/indexes/base.py:3812, in Index.get_loc(self, key)
3811 try:
-> 3812 return self._engine.get_loc(casted_key)
3813 except KeyError as err:
File ~/work/pandas/pandas/pandas/_libs/index.pyx:167, in pandas._libs.index.IndexEngine.get_loc()
File ~/work/pandas/pandas/pandas/_libs/index.pyx:196, in pandas._libs.index.IndexEngine.get_loc()
File pandas/_libs/hashtable_class_helper.pxi:7088, in pandas._libs.hashtable.PyObjectHashTable.get_item()
File pandas/_libs/hashtable_class_helper.pxi:7096, in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 'f'
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
Cell In[26], line 1
----> 1 s["f"]
File ~/work/pandas/pandas/pandas/core/series.py:1133, in Series.__getitem__(self, key)
1130 return self._values[key]
1132 elif key_is_scalar:
-> 1133 return self._get_value(key)
1135 # Convert generator to list before going through hashable part
1136 # (We will iterate through the generator there to check for slices)
1137 if is_iterator(key):
File ~/work/pandas/pandas/pandas/core/series.py:1249, in Series._get_value(self, label, takeable)
1246 return self._values[label]
1248 # Similar to Index.get_value, but we do not fall back to positional
-> 1249 loc = self.index.get_loc(label)
1251 if is_integer(loc):
1252 return self._values[loc]
File ~/work/pandas/pandas/pandas/core/indexes/base.py:3819, in Index.get_loc(self, key)
3814 if isinstance(casted_key, slice) or (
3815 isinstance(casted_key, abc.Iterable)
3816 and any(isinstance(x, slice) for x in casted_key)
3817 ):
3818 raise InvalidIndexError(key)
-> 3819 raise KeyError(key) from err
3820 except TypeError:
3821 # If we have a listlike key, _check_indexing_error will raise
3822 # InvalidIndexError. Otherwise we fall through and re-raise
3823 # the TypeError.
3824 self._check_indexing_error(key)
KeyError: 'f'
Используя Series.get() метод, отсутствующая метка вернет None или указанное значение по умолчанию:
In [27]: s.get("f")
In [28]: s.get("f", np.nan)
Out[28]: nan
Эти метки также доступны через атрибут.
Векторизованные операции и выравнивание меток с Series#
При работе с сырыми массивами NumPy обычно не требуется перебирать значения по одному. То же самое верно при работе с Series в pandas.
Series также может передаваться в большинство методов NumPy, ожидающих ndarray.
In [29]: s + s
Out[29]:
a 0.938225
b -0.565727
c -3.018117
d -2.271265
e 24.000000
dtype: float64
In [30]: s * 2
Out[30]:
a 0.938225
b -0.565727
c -3.018117
d -2.271265
e 24.000000
dtype: float64
In [31]: np.exp(s)
Out[31]:
a 1.598575
b 0.753623
c 0.221118
d 0.321219
e 162754.791419
dtype: float64
Ключевое различие между Series и ndarray заключается в том, что операции между Series
автоматически выровнять данные по метке. Таким образом, вы можете записывать вычисления
без учета того, является ли Series имеют одинаковые метки.
In [32]: s.iloc[1:] + s.iloc[:-1]
Out[32]:
a NaN
b -0.565727
c -3.018117
d -2.271265
e NaN
dtype: float64
Результат операции между невыровненными Series будет иметь union индексов, участвующих в операции. Если метка не найдена в одном Series или другой, результат
будет помечен как отсутствующий NaN. Возможность писать код без явного
выравнивания данных предоставляет огромную свободу и гибкость в
интерактивном анализе данных и исследованиях. Интегрированные функции выравнивания данных
в структурах данных pandas отличают pandas от большинства связанных
инструментов для работы с помеченными данными.
Примечание
В целом, мы решили сделать результат операций по умолчанию между объектами с разными индексами дающим union индексов, чтобы избежать потери информации. Наличие метки индекса, даже если данные отсутствуют, обычно является важной информацией в рамках вычислений. Вы, конечно, можете удалить метки с отсутствующими данными с помощью dropna функция.
Атрибут Name#
Series также имеет name attribute:
In [33]: s = pd.Series(np.random.randn(5), name="something")
In [34]: s
Out[34]:
0 -0.494929
1 1.071804
2 0.721555
3 -0.706771
4 -1.039575
Name: something, dtype: float64
In [35]: s.name
Out[35]: 'something'
The Series name может быть назначен автоматически во многих случаях, в частности,
при выборе одного столбца из DataFrame, name будет присвоена метка столбца.
Вы можете переименовать Series с pandas.Series.rename() метод.
In [36]: s2 = s.rename("different")
In [37]: s2.name
Out[37]: 'different'
Обратите внимание, что s и s2 ссылаются на разные объекты.
DataFrame#
DataFrame это двумерная структура данных с метками, где столбцы могут иметь
разные типы. Можно представить её как электронную таблицу или таблицу SQL,
или словарь объектов Series. Это обычно наиболее часто используемый
объект pandas. Как и Series, DataFrame принимает множество различных видов входных данных:
Словарь из 1D ndarrays, списков, словарей или
Series2-D numpy.ndarray
Структурированный или записной ndarray
A
SeriesЕщё один
DataFrame
Вместе с данными вы можете дополнительно передать index (метки строк) и столбцы (метки столбцов) аргументы. Если вы передаете индекс и/или столбцы, вы гарантируете индекс и/или столбцы результирующего DataFrame. Таким образом, словарь Series с указанным индексом отбросит все данные, не соответствующие переданному индексу.
Если метки осей не переданы, они будут построены из входных данных на основе здравых правил.
Из словаря Series или словарей#
Полученный index будет union индексов различных Series. Если есть вложенные словари, они сначала будут преобразованы в Series. Если столбцы не переданы, столбцами будет упорядоченный список ключей словаря.
In [38]: d = {
....: "one": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),
....: "two": pd.Series([1.0, 2.0, 3.0, 4.0], index=["a", "b", "c", "d"]),
....: }
....:
In [39]: df = pd.DataFrame(d)
In [40]: df
Out[40]:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
In [41]: pd.DataFrame(d, index=["d", "b", "a"])
Out[41]:
one two
d NaN 4.0
b 2.0 2.0
a 1.0 1.0
In [42]: pd.DataFrame(d, index=["d", "b", "a"], columns=["two", "three"])
Out[42]:
two three
d 4.0 NaN
b 2.0 NaN
a 1.0 NaN
Метки строк и столбцов можно получить соответственно через доступ к index и столбцы атрибуты:
Примечание
Когда передается определенный набор столбцов вместе со словарем данных, переданные столбцы переопределяют ключи в словаре.
In [43]: df.index
Out[43]: Index(['a', 'b', 'c', 'd'], dtype='object')
In [44]: df.columns
Out[44]: Index(['one', 'two'], dtype='object')
Из словаря ndarrays / списков#
Все ndarrays должны иметь одинаковую длину. Если передан индекс, он также должен быть той же длины, что и массивы. Если индекс не передан, результат будет range(n), где n это длина массива.
In [45]: d = {"one": [1.0, 2.0, 3.0, 4.0], "two": [4.0, 3.0, 2.0, 1.0]}
In [46]: pd.DataFrame(d)
Out[46]:
one two
0 1.0 4.0
1 2.0 3.0
2 3.0 2.0
3 4.0 1.0
In [47]: pd.DataFrame(d, index=["a", "b", "c", "d"])
Out[47]:
one two
a 1.0 4.0
b 2.0 3.0
c 3.0 2.0
d 4.0 1.0
Из структурированного или записного массива#
Этот случай обрабатывается идентично словарю массивов.
In [48]: data = np.zeros((2,), dtype=[("A", "i4"), ("B", "f4"), ("C", "a10")])
In [49]: data[:] = [(1, 2.0, "Hello"), (2, 3.0, "World")]
In [50]: pd.DataFrame(data)
Out[50]:
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'
In [51]: pd.DataFrame(data, index=["first", "second"])
Out[51]:
A B C
first 1 2.0 b'Hello'
second 2 3.0 b'World'
In [52]: pd.DataFrame(data, columns=["C", "A", "B"])
Out[52]:
C A B
0 b'Hello' 1 2.0
1 b'World' 2 3.0
Примечание
DataFrame не предназначен для работы точно так же, как двумерный массив NumPy ndarray.
Из списка словарей#
In [53]: data2 = [{"a": 1, "b": 2}, {"a": 5, "b": 10, "c": 20}]
In [54]: pd.DataFrame(data2)
Out[54]:
a b c
0 1 2 NaN
1 5 10 20.0
In [55]: pd.DataFrame(data2, index=["first", "second"])
Out[55]:
a b c
first 1 2 NaN
second 5 10 20.0
In [56]: pd.DataFrame(data2, columns=["a", "b"])
Out[56]:
a b
0 1 2
1 5 10
Из словаря кортежей#
Вы можете автоматически создать фрейм с MultiIndex, передав словарь кортежей.
In [57]: pd.DataFrame(
....: {
....: ("a", "b"): {("A", "B"): 1, ("A", "C"): 2},
....: ("a", "a"): {("A", "C"): 3, ("A", "B"): 4},
....: ("a", "c"): {("A", "B"): 5, ("A", "C"): 6},
....: ("b", "a"): {("A", "C"): 7, ("A", "B"): 8},
....: ("b", "b"): {("A", "D"): 9, ("A", "B"): 10},
....: }
....: )
....:
Out[57]:
a b
b a c a b
A B 1.0 4.0 5.0 8.0 10.0
C 2.0 3.0 6.0 7.0 NaN
D NaN NaN NaN NaN 9.0
Из Series#
Результатом будет DataFrame с тем же индексом, что и входной Series, и с одним столбцом, имя которого является исходным именем Series (только если не предоставлено другое имя столбца).
In [58]: ser = pd.Series(range(3), index=list("abc"), name="ser")
In [59]: pd.DataFrame(ser)
Out[59]:
ser
a 0
b 1
c 2
Из списка именованных кортежей#
Имена полей первого namedtuple в списке определяют столбцы DataFrame. Оставшиеся namedtuple (или кортежи) просто распаковываются,
и их значения передаются в строки DataFrame. Если любой из этих
кортежей короче первого namedtuple то последующие столбцы в соответствующей строке помечаются как пропущенные значения. Если какие-либо длиннее первого, namedtuple, a ValueError вызывается исключение.
In [60]: from collections import namedtuple
In [61]: Point = namedtuple("Point", "x y")
In [62]: pd.DataFrame([Point(0, 0), Point(0, 3), (2, 3)])
Out[62]:
x y
0 0 0
1 0 3
2 2 3
In [63]: Point3D = namedtuple("Point3D", "x y z")
In [64]: pd.DataFrame([Point3D(0, 0, 0), Point3D(0, 3, 5), Point(2, 3)])
Out[64]:
x y z
0 0 0 0.0
1 0 3 5.0
2 2 3 NaN
Из списка классов данных#
Классы данных, представленные в PEP557можно передать в конструктор DataFrame. Передача списка классов данных эквивалентна передаче списка словарей.
Пожалуйста, учтите, что все значения в списке должны быть классами данных, смешивание типов в списке приведет к TypeError.
In [65]: from dataclasses import make_dataclass
In [66]: Point = make_dataclass("Point", [("x", int), ("y", int)])
In [67]: pd.DataFrame([Point(0, 0), Point(0, 3), Point(2, 3)])
Out[67]:
x y
0 0 0
1 0 3
2 2 3
Отсутствующие данные
Для создания DataFrame с пропущенными данными мы используем np.nan для представления пропущенных значений. Альтернативно, можно передать numpy.MaskedArray
в качестве аргумента data для конструктора DataFrame, и его замаскированные записи будут считаться пропущенными. См. Отсутствующие данные подробнее.
Альтернативные конструкторы#
DataFrame.from_dict
DataFrame.from_dict() принимает словарь словарей или словарь массивоподобных последовательностей
и возвращает DataFrame. Работает аналогично DataFrame конструктор, за исключением orient параметр, который 'columns' по умолчанию, но который может быть
установлен в 'index' чтобы использовать ключи словаря в качестве меток строк.
In [68]: pd.DataFrame.from_dict(dict([("A", [1, 2, 3]), ("B", [4, 5, 6])]))
Out[68]:
A B
0 1 4
1 2 5
2 3 6
Если вы передадите orient='index', ключами будут метки строк. В этом
случае вы также можете передать желаемые имена столбцов:
In [69]: pd.DataFrame.from_dict(
....: dict([("A", [1, 2, 3]), ("B", [4, 5, 6])]),
....: orient="index",
....: columns=["one", "two", "three"],
....: )
....:
Out[69]:
one two three
A 1 2 3
B 4 5 6
DataFrame.from_records
DataFrame.from_records() принимает список кортежей или ndarray со структурированным
dtype. Работает аналогично обычному DataFrame конструктор, за исключением того, что
результирующий индекс DataFrame может быть определённым полем структурированного
типа данных.
In [70]: data
Out[70]:
array([(1, 2., b'Hello'), (2, 3., b'World')],
dtype=[('A', '
In [71]: pd.DataFrame.from_records(data, index="C")
Out[71]:
A B
C
b'Hello' 1 2.0
b'World' 2 3.0
Выбор, добавление и удаление столбцов#
Вы можете обращаться с DataFrame семантически похоже на словарь с аналогично индексированными Series
объекты. Получение, установка и удаление столбцов работает с тем же синтаксисом, что и аналогичные операции со словарем:
In [72]: df["one"]
Out[72]:
a 1.0
b 2.0
c 3.0
d NaN
Name: one, dtype: float64
In [73]: df["three"] = df["one"] * df["two"]
In [74]: df["flag"] = df["one"] > 2
In [75]: df
Out[75]:
one two three flag
a 1.0 1.0 1.0 False
b 2.0 2.0 4.0 False
c 3.0 3.0 9.0 True
d NaN 4.0 NaN False
Столбцы можно удалять или извлекать, как в словаре:
In [76]: del df["two"]
In [77]: three = df.pop("three")
In [78]: df
Out[78]:
one flag
a 1.0 False
b 2.0 False
c 3.0 True
d NaN False
При вставке скалярного значения оно естественным образом распространится для заполнения столбца:
In [79]: df["foo"] = "bar"
In [80]: df
Out[80]:
one flag foo
a 1.0 False bar
b 2.0 False bar
c 3.0 True bar
d NaN False bar
При вставке Series который не имеет того же индекса, что и DataFrame, он
будет приведен к индексу DataFrame:
In [81]: df["one_trunc"] = df["one"][:2]
In [82]: df
Out[82]:
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
c 3.0 True bar NaN
d NaN False bar NaN
Вы можете вставлять сырые ndarrays, но их длина должна соответствовать длине индекса DataFrame.
По умолчанию столбцы вставляются в конец. DataFrame.insert()
вставляет в определённое место в столбцах:
In [83]: df.insert(1, "bar", df["one"])
In [84]: df
Out[84]:
one bar flag foo one_trunc
a 1.0 1.0 False bar 1.0
b 2.0 2.0 False bar 2.0
c 3.0 3.0 True bar NaN
d NaN NaN False bar NaN
Назначение новых столбцов в цепочках методов#
Вдохновлено dplyr's
mutate глагол, DataFrame имеет assign()
метод, который позволяет легко создавать новые столбцы, потенциально производные от существующих столбцов.
In [85]: iris = pd.read_csv("data/iris.data")
In [86]: iris.head()
Out[86]:
SepalLength SepalWidth PetalLength PetalWidth Name
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
In [87]: iris.assign(sepal_ratio=iris["SepalWidth"] / iris["SepalLength"]).head()
Out[87]:
SepalLength SepalWidth PetalLength PetalWidth Name sepal_ratio
0 5.1 3.5 1.4 0.2 Iris-setosa 0.686275
1 4.9 3.0 1.4 0.2 Iris-setosa 0.612245
2 4.7 3.2 1.3 0.2 Iris-setosa 0.680851
3 4.6 3.1 1.5 0.2 Iris-setosa 0.673913
4 5.0 3.6 1.4 0.2 Iris-setosa 0.720000
В примере выше мы вставили предвычисленное значение. Мы также можем передать функцию одного аргумента для вычисления на DataFrame, которому присваивается.
In [88]: iris.assign(sepal_ratio=lambda x: (x["SepalWidth"] / x["SepalLength"])).head()
Out[88]:
SepalLength SepalWidth PetalLength PetalWidth Name sepal_ratio
0 5.1 3.5 1.4 0.2 Iris-setosa 0.686275
1 4.9 3.0 1.4 0.2 Iris-setosa 0.612245
2 4.7 3.2 1.3 0.2 Iris-setosa 0.680851
3 4.6 3.1 1.5 0.2 Iris-setosa 0.673913
4 5.0 3.6 1.4 0.2 Iris-setosa 0.720000
assign() всегда возвращает копию данных, оставляя исходный
DataFrame неизменным.
Передача вызываемого объекта, в отличие от фактического значения для вставки,
полезна, когда у вас нет ссылки на DataFrame под рукой. Это
часто встречается при использовании assign() в цепочке операций. Например,
мы можем ограничить DataFrame только теми наблюдениями, у которых длина чашелистика
больше 5, вычислить соотношение и построить график:
In [89]: (
....: iris.query("SepalLength > 5")
....: .assign(
....: SepalRatio=lambda x: x.SepalWidth / x.SepalLength,
....: PetalRatio=lambda x: x.PetalWidth / x.PetalLength,
....: )
....: .plot(kind="scatter", x="SepalRatio", y="PetalRatio")
....: )
....:
Out[89]: 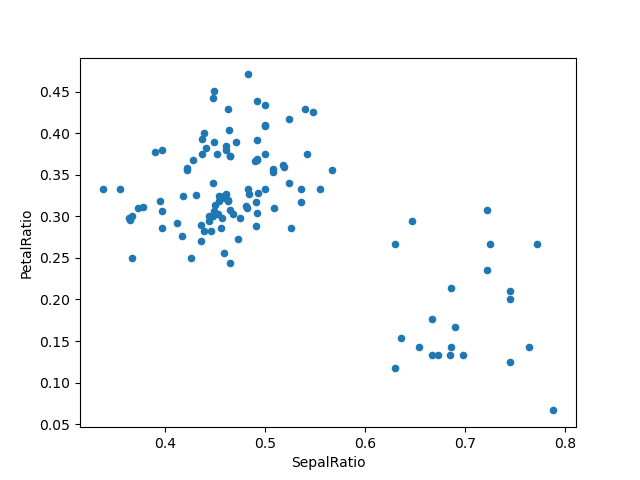
Поскольку передаётся функция, она вычисляется на DataFrame, который присваивается. Важно, что это DataFrame, отфильтрованный по строкам с длиной чашелистика больше 5. Фильтрация происходит первой, а затем вычисления соотношений. Это пример, где у нас не было ссылки на отфильтровано DataFrame доступен.
Сигнатура функции для assign() просто **kwargs. Ключи - это имена столбцов для новых полей, а значения - либо значение для вставки (например, Series или массив NumPy), или функция
одного аргумента, которая будет вызвана на DataFrame. A copy исходного
DataFrame возвращается, с вставленными новыми значениями.
Порядок **kwargs сохраняется. Это позволяет
для зависимый присваивание, где выражение позже в **kwargs может ссылаться
на столбец, созданный ранее в том же assign().
In [90]: dfa = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
In [91]: dfa.assign(C=lambda x: x["A"] + x["B"], D=lambda x: x["A"] + x["C"])
Out[91]:
A B C D
0 1 4 5 6
1 2 5 7 9
2 3 6 9 12
Во втором выражении, x['C'] будет ссылаться на вновь созданный столбец,
равный dfa['A'] + dfa['B'].
Индексирование / выбор#
Основы индексирования следующие:
Операция |
Синтаксис |
Результат |
|---|---|---|
Выбрать столбец |
|
Series |
Выбор строки по метке |
|
Series |
Выбор строки по целочисленной позиции |
|
Series |
Срез строк |
|
DataFrame |
Выбор строк по булевому вектору |
|
DataFrame |
Выбор строк, например, возвращает Series чей индекс - это столбцы
DataFrame:
In [92]: df.loc["b"]
Out[92]:
one 2.0
bar 2.0
flag False
foo bar
one_trunc 2.0
Name: b, dtype: object
In [93]: df.iloc[2]
Out[93]:
one 3.0
bar 3.0
flag True
foo bar
one_trunc NaN
Name: c, dtype: object
Для более исчерпывающего рассмотрения сложного индексирования и срезов по меткам, см. раздел об индексировании. Мы рассмотрим основы переиндексации / соответствия новым наборам меток в раздел о переиндексации.
Выравнивание данных и арифметические операции#
Выравнивание данных между DataFrame объекты автоматически выравниваются по как
столбцы, так и индекс (метки строк). Опять же, результирующий объект будет иметь объединение меток столбцов и строк.
In [94]: df = pd.DataFrame(np.random.randn(10, 4), columns=["A", "B", "C", "D"])
In [95]: df2 = pd.DataFrame(np.random.randn(7, 3), columns=["A", "B", "C"])
In [96]: df + df2
Out[96]:
A B C D
0 0.045691 -0.014138 1.380871 NaN
1 -0.955398 -1.501007 0.037181 NaN
2 -0.662690 1.534833 -0.859691 NaN
3 -2.452949 1.237274 -0.133712 NaN
4 1.414490 1.951676 -2.320422 NaN
5 -0.494922 -1.649727 -1.084601 NaN
6 -1.047551 -0.748572 -0.805479 NaN
7 NaN NaN NaN NaN
8 NaN NaN NaN NaN
9 NaN NaN NaN NaN
При выполнении операции между DataFrame и Series, поведение по умолчанию — выравнивание Series index на DataFrame столбцы, таким образом вещание
построчно. Например:
In [97]: df - df.iloc[0]
Out[97]:
A B C D
0 0.000000 0.000000 0.000000 0.000000
1 -1.359261 -0.248717 -0.453372 -1.754659
2 0.253128 0.829678 0.010026 -1.991234
3 -1.311128 0.054325 -1.724913 -1.620544
4 0.573025 1.500742 -0.676070 1.367331
5 -1.741248 0.781993 -1.241620 -2.053136
6 -1.240774 -0.869551 -0.153282 0.000430
7 -0.743894 0.411013 -0.929563 -0.282386
8 -1.194921 1.320690 0.238224 -1.482644
9 2.293786 1.856228 0.773289 -1.446531
Для явного контроля над поведением сопоставления и трансляции, см. раздел о гибкие бинарные операции.
Арифметические операции со скалярами выполняются поэлементно:
In [98]: df * 5 + 2
Out[98]:
A B C D
0 3.359299 -0.124862 4.835102 3.381160
1 -3.437003 -1.368449 2.568242 -5.392133
2 4.624938 4.023526 4.885230 -6.575010
3 -3.196342 0.146766 -3.789461 -4.721559
4 6.224426 7.378849 1.454750 10.217815
5 -5.346940 3.785103 -1.373001 -6.884519
6 -2.844569 -4.472618 4.068691 3.383309
7 -0.360173 1.930201 0.187285 1.969232
8 -2.615303 6.478587 6.026220 -4.032059
9 14.828230 9.156280 8.701544 -3.851494
In [99]: 1 / df
Out[99]:
A B C D
0 3.678365 -2.353094 1.763605 3.620145
1 -0.919624 -1.484363 8.799067 -0.676395
2 1.904807 2.470934 1.732964 -0.583090
3 -0.962215 -2.697986 -0.863638 -0.743875
4 1.183593 0.929567 -9.170108 0.608434
5 -0.680555 2.800959 -1.482360 -0.562777
6 -1.032084 -0.772485 2.416988 3.614523
7 -2.118489 -71.634509 -2.758294 -162.507295
8 -1.083352 1.116424 1.241860 -0.828904
9 0.389765 0.698687 0.746097 -0.854483
In [100]: df ** 4
Out[100]:
A B C D
0 0.005462 3.261689e-02 0.103370 5.822320e-03
1 1.398165 2.059869e-01 0.000167 4.777482e+00
2 0.075962 2.682596e-02 0.110877 8.650845e+00
3 1.166571 1.887302e-02 1.797515 3.265879e+00
4 0.509555 1.339298e+00 0.000141 7.297019e+00
5 4.661717 1.624699e-02 0.207103 9.969092e+00
6 0.881334 2.808277e+00 0.029302 5.858632e-03
7 0.049647 3.797614e-08 0.017276 1.433866e-09
8 0.725974 6.437005e-01 0.420446 2.118275e+00
9 43.329821 4.196326e+00 3.227153 1.875802e+00
Булевы операторы также работают поэлементно:
In [101]: df1 = pd.DataFrame({"a": [1, 0, 1], "b": [0, 1, 1]}, dtype=bool)
In [102]: df2 = pd.DataFrame({"a": [0, 1, 1], "b": [1, 1, 0]}, dtype=bool)
In [103]: df1 & df2
Out[103]:
a b
0 False False
1 False True
2 True False
In [104]: df1 | df2
Out[104]:
a b
0 True True
1 True True
2 True True
In [105]: df1 ^ df2
Out[105]:
a b
0 True True
1 True False
2 False True
In [106]: -df1
Out[106]:
a b
0 False True
1 True False
2 False False
Транспонирование#
Для транспонирования обратитесь к T атрибут или DataFrame.transpose(),
подобно ndarray:
# only show the first 5 rows
In [107]: df[:5].T
Out[107]:
0 1 2 3 4
A 0.271860 -1.087401 0.524988 -1.039268 0.844885
B -0.424972 -0.673690 0.404705 -0.370647 1.075770
C 0.567020 0.113648 0.577046 -1.157892 -0.109050
D 0.276232 -1.478427 -1.715002 -1.344312 1.643563
Совместимость DataFrame с функциями NumPy#
Большинство функций NumPy можно вызывать непосредственно на Series и DataFrame.
In [108]: np.exp(df)
Out[108]:
A B C D
0 1.312403 0.653788 1.763006 1.318154
1 0.337092 0.509824 1.120358 0.227996
2 1.690438 1.498861 1.780770 0.179963
3 0.353713 0.690288 0.314148 0.260719
4 2.327710 2.932249 0.896686 5.173571
5 0.230066 1.429065 0.509360 0.169161
6 0.379495 0.274028 1.512461 1.318720
7 0.623732 0.986137 0.695904 0.993865
8 0.397301 2.449092 2.237242 0.299269
9 13.009059 4.183951 3.820223 0.310274
In [109]: np.asarray(df)
Out[109]:
array([[ 0.2719, -0.425 , 0.567 , 0.2762],
[-1.0874, -0.6737, 0.1136, -1.4784],
[ 0.525 , 0.4047, 0.577 , -1.715 ],
[-1.0393, -0.3706, -1.1579, -1.3443],
[ 0.8449, 1.0758, -0.109 , 1.6436],
[-1.4694, 0.357 , -0.6746, -1.7769],
[-0.9689, -1.2945, 0.4137, 0.2767],
[-0.472 , -0.014 , -0.3625, -0.0062],
[-0.9231, 0.8957, 0.8052, -1.2064],
[ 2.5656, 1.4313, 1.3403, -1.1703]])
DataFrame не предназначен быть прямой заменой для ndarray, так как его семантика индексирования и модель данных в некоторых местах сильно отличаются от n-мерного массива.
Series реализует __array_ufunc__, что позволяет ему работать с
универсальные функции.
Ufunc применяется к базовому массиву в Series.
In [110]: ser = pd.Series([1, 2, 3, 4])
In [111]: np.exp(ser)
Out[111]:
0 2.718282
1 7.389056
2 20.085537
3 54.598150
dtype: float64
Когда несколько Series передаются в ufunc, они выравниваются перед
выполнением операции.
Как и другие части библиотеки, pandas автоматически выравнивает помеченные входные данные
в рамках ufunc с несколькими входами. Например, используя numpy.remainder()
на двух Series с разным порядком меток выровняются перед операцией.
In [112]: ser1 = pd.Series([1, 2, 3], index=["a", "b", "c"])
In [113]: ser2 = pd.Series([1, 3, 5], index=["b", "a", "c"])
In [114]: ser1
Out[114]:
a 1
b 2
c 3
dtype: int64
In [115]: ser2
Out[115]:
b 1
a 3
c 5
dtype: int64
In [116]: np.remainder(ser1, ser2)
Out[116]:
a 1
b 0
c 3
dtype: int64
Как обычно, берется объединение двух индексов, а непересекающиеся значения заполняются пропущенными значениями.
In [117]: ser3 = pd.Series([2, 4, 6], index=["b", "c", "d"])
In [118]: ser3
Out[118]:
b 2
c 4
d 6
dtype: int64
In [119]: np.remainder(ser1, ser3)
Out[119]:
a NaN
b 0.0
c 3.0
d NaN
dtype: float64
Когда бинарная универсальная функция применяется к Series и Index, Series
реализация имеет приоритет и Series возвращается.
In [120]: ser = pd.Series([1, 2, 3])
In [121]: idx = pd.Index([4, 5, 6])
In [122]: np.maximum(ser, idx)
Out[122]:
0 4
1 5
2 6
dtype: int64
NumPy ufunc безопасно применять к Series поддерживаемые не-ndarray массивами,
например arrays.SparseArray (см. Разреженный расчет). Если возможно, ufunc применяется без преобразования исходных данных в ndarray.
Консольный вывод#
Очень большой DataFrame будут усечены для отображения в консоли.
Вы также можете получить сводку с помощью info().
(В baseball набор данных взят из plyr Пакет R):
In [123]: baseball = pd.read_csv("data/baseball.csv")
In [124]: print(baseball)
id player year stint team lg ... so ibb hbp sh sf gidp
0 88641 womacto01 2006 2 CHN NL ... 4.0 0.0 0.0 3.0 0.0 0.0
1 88643 schilcu01 2006 1 BOS AL ... 1.0 0.0 0.0 0.0 0.0 0.0
.. ... ... ... ... ... .. ... ... ... ... ... ... ...
98 89533 aloumo01 2007 1 NYN NL ... 30.0 5.0 2.0 0.0 3.0 13.0
99 89534 alomasa02 2007 1 NYN NL ... 3.0 0.0 0.0 0.0 0.0 0.0
[100 rows x 23 columns]
In [125]: baseball.info()
Однако, использование DataFrame.to_string() вернёт строковое представление
DataFrame в табличной форме, хотя она не всегда будет соответствовать ширине консоли:
In [126]: print(baseball.iloc[-20:, :12].to_string())
id player year stint team lg g ab r h X2b X3b
80 89474 finlest01 2007 1 COL NL 43 94 9 17 3 0
81 89480 embreal01 2007 1 OAK AL 4 0 0 0 0 0
82 89481 edmonji01 2007 1 SLN NL 117 365 39 92 15 2
83 89482 easleda01 2007 1 NYN NL 76 193 24 54 6 0
84 89489 delgaca01 2007 1 NYN NL 139 538 71 139 30 0
85 89493 cormirh01 2007 1 CIN NL 6 0 0 0 0 0
86 89494 coninje01 2007 2 NYN NL 21 41 2 8 2 0
87 89495 coninje01 2007 1 CIN NL 80 215 23 57 11 1
88 89497 clemero02 2007 1 NYA AL 2 2 0 1 0 0
89 89498 claytro01 2007 2 BOS AL 8 6 1 0 0 0
90 89499 claytro01 2007 1 TOR AL 69 189 23 48 14 0
91 89501 cirilje01 2007 2 ARI NL 28 40 6 8 4 0
92 89502 cirilje01 2007 1 MIN AL 50 153 18 40 9 2
93 89521 bondsba01 2007 1 SFN NL 126 340 75 94 14 0
94 89523 biggicr01 2007 1 HOU NL 141 517 68 130 31 3
95 89525 benitar01 2007 2 FLO NL 34 0 0 0 0 0
96 89526 benitar01 2007 1 SFN NL 19 0 0 0 0 0
97 89530 ausmubr01 2007 1 HOU NL 117 349 38 82 16 3
98 89533 aloumo01 2007 1 NYN NL 87 328 51 112 19 1
99 89534 alomasa02 2007 1 NYN NL 8 22 1 3 1 0
Широкие DataFrame по умолчанию будут выводиться на нескольких строках:
In [127]: pd.DataFrame(np.random.randn(3, 12))
Out[127]:
0 1 2 ... 9 10 11
0 -1.226825 0.769804 -1.281247 ... -1.110336 -0.619976 0.149748
1 -0.732339 0.687738 0.176444 ... 1.462696 -1.743161 -0.826591
2 -0.345352 1.314232 0.690579 ... 0.896171 -0.487602 -0.082240
[3 rows x 12 columns]
Можно изменить количество выводимой информации в одной строке, установив display.width
опция:
In [128]: pd.set_option("display.width", 40) # default is 80
In [129]: pd.DataFrame(np.random.randn(3, 12))
Out[129]:
0 1 2 ... 9 10 11
0 -2.182937 0.380396 0.084844 ... -0.023688 2.410179 1.450520
1 0.206053 -0.251905 -2.213588 ... -0.025747 -0.988387 0.094055
2 1.262731 1.289997 0.082423 ... -0.281461 0.030711 0.109121
[3 rows x 12 columns]
Вы можете настроить максимальную ширину отдельных столбцов, установив display.max_colwidth
In [130]: datafile = {
.....: "filename": ["filename_01", "filename_02"],
.....: "path": [
.....: "media/user_name/storage/folder_01/filename_01",
.....: "media/user_name/storage/folder_02/filename_02",
.....: ],
.....: }
.....:
In [131]: pd.set_option("display.max_colwidth", 30)
In [132]: pd.DataFrame(datafile)
Out[132]:
filename path
0 filename_01 media/user_name/storage/fo...
1 filename_02 media/user_name/storage/fo...
In [133]: pd.set_option("display.max_colwidth", 100)
In [134]: pd.DataFrame(datafile)
Out[134]:
filename path
0 filename_01 media/user_name/storage/folder_01/filename_01
1 filename_02 media/user_name/storage/folder_02/filename_02
Вы также можете отключить эту функцию через expand_frame_repr опция.
Это выведет таблицу одним блоком.
Доступ к атрибутам столбцов DataFrame и автодополнение в IPython#
Если DataFrame если метка столбца является допустимым именем переменной Python, к столбцу можно обращаться как к атрибуту:
In [135]: df = pd.DataFrame({"foo1": np.random.randn(5), "foo2": np.random.randn(5)})
In [136]: df
Out[136]:
foo1 foo2
0 1.126203 0.781836
1 -0.977349 -1.071357
2 1.474071 0.441153
3 -0.064034 2.353925
4 -1.282782 0.583787
In [137]: df.foo1
Out[137]:
0 1.126203
1 -0.977349
2 1.474071
3 -0.064034
4 -1.282782
Name: foo1, dtype: float64
Столбцы также связаны с IPython механизм завершения, чтобы их можно было завершать с помощью табуляции:
In [5]: df.foo<TAB> # noqa: E225, E999
df.foo1 df.foo2