Тест на нормальность#
The scipy.stats.normaltest функция проверяет нулевую гипотезу о том, что
выборка происходит из нормального распределения. Она основана на тесте Д’Агостино и
Пирсона [1] [2] тест, который объединяет асимметрию и эксцесс для создания комплексного
теста на нормальность.
Предположим, мы хотим сделать вывод из измерений, отличаются ли веса взрослых мужчин
в медицинском исследовании от нормального распределения [3]. Веса (фунты)
записываются в массив x ниже.
import numpy as np
x = np.array([148, 154, 158, 160, 161, 162, 166, 170, 182, 195, 236])
Тест на нормальность scipy.stats.normaltest of [1] и [2] начинается с
вычисления статистики на основе асимметрии и эксцесса выборки.
from scipy import stats
res = stats.normaltest(x)
res.statistic
np.float64(13.034263121192582)
(Тест предупреждает, что в нашей выборке слишком мало наблюдений для выполнения теста. Мы вернемся к этому в конце примера.) Поскольку нормальное распределение имеет нулевую асимметрию и нулевой ("избыточный" или "Фишеровский") эксцесс, значение этой статистики обычно низкое для выборок, взятых из нормального распределения.
Тест выполняется путем сравнения наблюдаемого значения статистики с нулевым распределением: распределением значений статистики, полученным при нулевой гипотезе о том, что веса были взяты из нормального распределения. Для этого теста на нормальность нулевое распределение для очень больших выборок — это распределение хи-квадрат с двумя степенями свободы.
import matplotlib.pyplot as plt
dist = stats.chi2(df=2)
stat_vals = np.linspace(0, 16, 100)
pdf = dist.pdf(stat_vals)
fig, ax = plt.subplots(figsize=(8, 5))
def plot(ax): # we'll reuse this
ax.plot(stat_vals, pdf)
ax.set_title("Normality Test Null Distribution")
ax.set_xlabel("statistic")
ax.set_ylabel("probability density")
plot(ax)
plt.show()
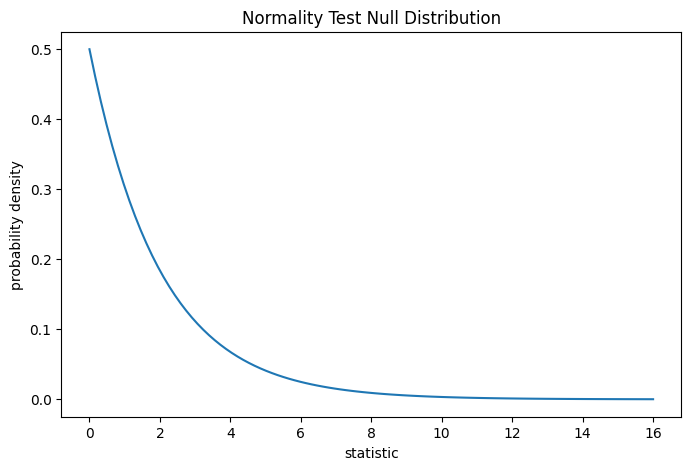
Сравнение количественно выражается через p-значение: доля значений в нулевом распределении, больших или равных наблюдаемому значению статистики.
fig, ax = plt.subplots(figsize=(8, 5))
plot(ax)
pvalue = dist.sf(res.statistic)
annotation = (f'p-value={pvalue:.6f}\n(shaded area)')
props = dict(facecolor='black', width=1, headwidth=5, headlength=8)
_ = ax.annotate(annotation, (13.5, 5e-4), (14, 5e-3), arrowprops=props)
i = stat_vals >= res.statistic # index more extreme statistic values
ax.fill_between(stat_vals[i], y1=0, y2=pdf[i])
ax.set_xlim(8, 16)
ax.set_ylim(0, 0.01)
plt.show()
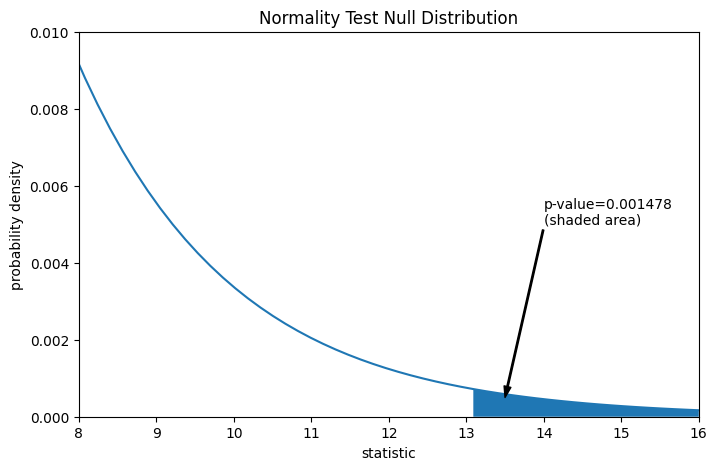
res.pvalue
np.float64(0.0014779023013100172)
Если p-значение «маленькое» - то есть если существует низкая вероятность выборки данных из нормально распределенной совокупности, которая дает такое экстремальное значение статистики - это может быть принято как свидетельство против нулевой гипотезы в пользу альтернативы: веса не были взяты из нормального распределения. Обратите внимание, что:
Обратное неверно; то есть тест не используется для предоставления доказательств в пользу нулевой гипотезы.
Порог для значений, которые будут считаться «малыми», — это выбор, который следует сделать до анализа данных [4] с учетом рисков как ложноположительных (ошибочное отклонение нулевой гипотезы), так и ложноотрицательных (неспособность отклонить ложную нулевую гипотезу).
Обратите внимание, что распределение хи-квадрат предоставляет асимптотическое приближение
нулевого распределения; оно точно только для выборок с большим количеством наблюдений.
Это причина, по которой мы получили предупреждение в начале примера; наша
выборка довольно мала. В этом случае
scipy.stats.monte_carlo_test может дать более точное, хотя и стохастическое, приближение точного p-значения.
def statistic(x, axis):
# Get only the `normaltest` statistic; ignore approximate p-value
return stats.normaltest(x, axis=axis).statistic
res = stats.monte_carlo_test(x, stats.norm.rvs, statistic,
alternative='greater')
fig, ax = plt.subplots(figsize=(8, 5))
plot(ax)
ax.hist(res.null_distribution, np.linspace(0, 25, 50),
density=True)
ax.legend(['asymptotic approximation (many observations)',
'Monte Carlo approximation (11 observations)'])
ax.set_xlim(0, 14)
plt.show()
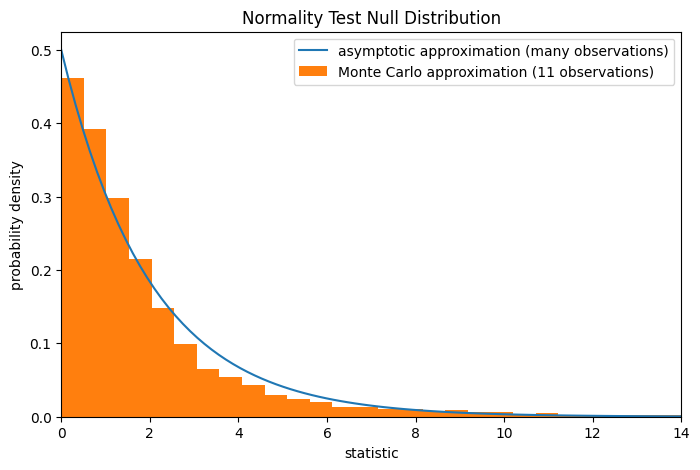
res.pvalue
np.float64(0.007)
Более того, несмотря на их стохастическую природу, p-значения, вычисленные таким образом, могут быть использованы для точного контроля уровня ложных отклонений нулевой гипотезы [5].