Универсальная выборка случайных чисел с неравномерным распределением в SciPy#
SciPy предоставляет интерфейс ко многим универсальным генераторам неоднородных случайных чисел для выборки случайных величин из широкого спектра одномерных непрерывных и дискретных распределений. Реализации быстрой библиотеки на C под названием UNU.RAN используются для скорости и производительности. Пожалуйста, ознакомьтесь с документация UNU.RAN для подробного объяснения этих методов. На него активно ссылаются при написании этого руководства и документации всех генераторов.
Введение#
Генерация случайных величин — это небольшая область исследований, занимающаяся алгоритмами генерации случайных величин из различных распределений. Обычно предполагается, что доступен генератор равномерных случайных чисел. Это программа, которая производит последовательность независимых и одинаково распределенных непрерывных U(0,1) случайных величин (т.е. равномерных случайных величин на интервале (0,1)). Конечно, реальные компьютеры никогда не могут генерировать идеальные случайные числа и не могут производить числа произвольной точности, но современные генераторы равномерных случайных чисел близки к этой цели. Таким образом, генерация случайных величин занимается проблемой преобразования такой последовательности U(0,1) случайных чисел в неравномерные случайные величины. Эти методы универсальны и работают по принципу черного ящика.
Некоторые методы для этого:
Метод инверсии: Когда обратная \(F^{-1}\) кумулятивной функции распределения известно, то генерация случайных величин проста. Мы просто генерируем равномерно распределённое случайное число U(0,1) U и возвращаем \(X = F^{-1}(U)\). Поскольку аналитические решения для обратной матрицы редко доступны, обычно приходится полагаться на приближения обратной матрицы (например,
scipy.special.ndtri,scipy.special.stdtrit). В целом, реализация специальных функций довольно медленная по сравнению с методами инверсии в UNU.RAN.Метод отбраковки: Метод отбраковки, часто называемый методом принятия-отбраковки, был предложен Джоном фон Нейманом в 1951 году[1]. Он включает вычисление верхней границы для PDF (также называемой функцией-шляпой) и использование метода инверсии для генерации случайной вариации, скажем Y, из этой границы. Затем можно сгенерировать равномерное случайное число между 0 и значением верхней границы в Y. Если это число меньше PDF в Y, вернуть выборку, иначе отклонить её. См.
scipy.stats.sampling.TransformedDensityRejection.Метод отношения равномерных распределений: Это тип метода принятия-отклонения, который использует минимальные ограничивающие прямоугольники для построения функции-шапки. См.
scipy.stats.sampling.RatioUniforms.Инверсия для дискретных распределений: отличие от непрерывного случая заключается в том, что \(F\) теперь является ступенчатой функцией. Для реализации этого на компьютере используется алгоритм поиска, простейшим из которых является последовательный поиск. Генерируется равномерное случайное число из U(0, 1), и вероятности суммируются до тех пор, пока кумулятивная вероятность не превысит равномерное случайное число. Индекс, при котором это происходит, является требуемой случайной величиной и возвращается.
Более подробную информацию об этих алгоритмах можно найти в приложение руководства пользователя UNU.RAN.
При генерации случайных величин распределения два фактора важны для определения скорости генератора: шаг настройки и фактическая выборка. В зависимости от ситуации разные генераторы могут быть оптимальными. Например, если нужно многократно брать большие выборки из заданного распределения с фиксированным параметром формы, медленная настройка допустима, если выборка быстрая. Это называется случаем фиксированного параметра. Если цель — генерировать выборки распределения для разных параметров формы (случай изменяющегося параметра), дорогая настройка, которую нужно повторять для каждого параметра, приведет к очень плохой производительности. В такой ситуации быстрая настройка важна для достижения хорошей производительности. Обзор скорости настройки и выборки для разных методов показан в таблице ниже.
Методы для непрерывных распределений |
Необходимые входные данные |
Необязательные входные данные |
Настройка скорости |
Скорость выборки |
|---|---|---|---|---|
pdf, dpdf |
none |
медленно |
быстро |
|
функция распределения |
pdf, dpdf |
(очень) медленно |
(очень) быстрый |
|
функция распределения |
(очень) медленно |
(очень) быстрый |
||
none |
быстро |
медленно |
где
pdf: функция плотности вероятности
dpdf: производная функции плотности вероятности
cdf: функция распределения
Чтобы применить метод численной инверсии NumericalInversePolynomial к большому
количеству непрерывных распределений в SciPy с минимальными усилиями, посмотрите scipy.stats.sampling.FastGeneratorInversion.
Методы для дискретных распределений |
Необходимые входные данные |
Необязательные входные данные |
Настройка скорости |
Скорость выборки |
|---|---|---|---|---|
pv |
pmf |
медленно |
очень быстрый |
|
pv |
pmf |
медленно |
очень быстрый |
где
pv: вектор вероятностей
pmf: функция вероятности массы
Для получения дополнительной информации о генераторах, реализованных в UNU.RAN, обратитесь к [2] и [3].
Основные концепции интерфейса#
Каждый генератор должен быть настроен перед началом выборки из него.
Это можно сделать путем создания экземпляра объекта этого класса. Большинство
генераторов принимают объект распределения в качестве входных данных, который содержит реализацию
необходимых методов, таких как PDF, CDF и т.д. В дополнение к объекту
распределения можно также передать параметры, используемые для настройки генератора. Также
возможно усечение распределений с помощью domain параметра. Все
генераторы нуждаются в потоке равномерно распределённых случайных чисел, которые преобразуются в
случайные величины заданного распределения. Это делается путём передачи random_state
параметр с NumPy BitGenerator в качестве генератора равномерных случайных чисел.
random_state может быть либо целым числом, numpy.random.Generator,
или numpy.random.RandomState.
Предупреждение
Использование NumPy < 1.19.0 не рекомендуется, так как он не имеет быстрого Cython API для генерации равномерных случайных чисел и может быть слишком медленным для практического использования.
Все генераторы имеют общий rvs метод, который можно использовать для получения выборок из заданного распределения.
Пример этого интерфейса показан ниже:
from scipy.stats.sampling import TransformedDensityRejection
from math import exp
import numpy as np
class StandardNormal:
def pdf(self, x: float) -> float:
# note that the normalization constant isn't required
return exp(-0.5 * x*x)
def dpdf(self, x: float) -> float:
return -x * exp(-0.5 * x*x)
dist = StandardNormal()
urng = np.random.default_rng()
rng = TransformedDensityRejection(dist, random_state=urng)
Как показано в примере, мы сначала инициализируем объект распределения, который содержит реализацию методов, требуемых генератором. В нашем случае мы используем TransformedDensityRejection (TDR) метод, который требует PDF и её производную по x (т.е. вариант).
Примечание
Обратите внимание, что методы распределения (т.е. pdf, dpdf, и т.д.) не обязательно векторизовать. Они должны принимать и возвращать числа с плавающей точкой.
Примечание
Можно также передавать распределения SciPy в качестве аргументов. Однако обратите внимание, что
объект не всегда содержит всю информацию, требуемую некоторыми генераторами,
например производную PDF для метода TDR. Использование распределений SciPy
также может снизить производительность из-за векторизации методов, таких как
pdf и cdf. В обоих случаях можно реализовать пользовательский объект распределения,
который содержит все необходимые методы и не векторизован, как показано в
примере выше. Если нужно применить метод численной инверсии к
распределению, определенному в SciPy, также ознакомьтесь с
scipy.stats.sampling.FastGeneratorInversion.
В приведённом выше примере мы создали объект класса
TransformedDensityRejection метод для выборки из
стандартного нормального распределения. Теперь мы можем начать выборку из нашего
распределения, вызывая rvs method:
rng.rvs()
-0.700496926128699
rng.rvs((5, 3))
array([[-0.96641403, 0.24315257, 0.0567448 ],
[ 0.81096959, -1.86931154, -0.13951906],
[-0.13948349, 0.55313458, 0.03372447],
[ 0.12433227, -0.21613476, -0.16702546],
[-0.56346845, -0.05126207, 1.36709698]])
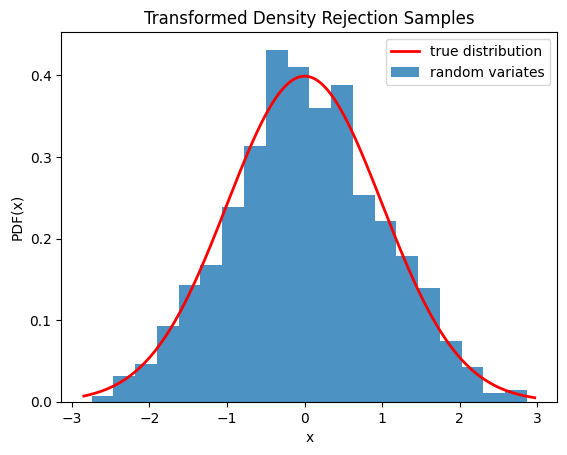
Мы также можем проверить, что выборки взяты из правильного распределения, визуализируя гистограмму выборок:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from scipy.stats.sampling import TransformedDensityRejection
from math import exp
class StandardNormal:
def pdf(self, x: float) -> float:
# note that the normalization constant isn't required
return exp(-0.5 * x*x)
def dpdf(self, x: float) -> float:
return -x * exp(-0.5 * x*x)
dist = StandardNormal()
urng = np.random.default_rng()
rng = TransformedDensityRejection(dist, random_state=urng)
rvs = rng.rvs(size=1000)
x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, num=1000)
fx = norm.pdf(x)
plt.plot(x, fx, 'r-', lw=2, label='true distribution')
plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates')
plt.xlabel('x')
plt.ylabel('PDF(x)')
plt.title('Transformed Density Rejection Samples')
plt.legend()
plt.show()
Примечание
Обратите внимание на разницу между rvs метод распределений, представленных в scipy.stats и тот, который предоставляют эти генераторы. Генераторы UNU.RAN должны считаться независимыми в том смысле, что они обычно производят другой поток случайных чисел, чем тот, который производится эквивалентным распределением в scipy.stats для любого начального значения. Реализация rvs в scipy.stats.rv_continuous обычно полагается
на модуль NumPy numpy.random для известных распределений (например, для нормального распределения, бета-распределения) и преобразований других распределений (например, нормального обратного гауссовского)
scipy.stats.norminvgauss и логнормальное
scipy.stats.lognorm распределения). Если конкретный метод не
реализован, scipy.stats.rv_continuous по умолчанию использует численный метод инверсии CDF, который очень медленный. Поскольку UNU.RAN преобразует равномерные случайные числа иначе, чем SciPy или NumPy, результирующий поток случайных величин отличается даже для одного и того же потока равномерных случайных чисел. Например, поток случайных чисел SciPy scipy.stats.norm и UNU.RAN's
TransformedDensityRejection не будет одинаковым
даже для одного и того же random_state:
from scipy.stats.sampling import norm, TransformedDensityRejection
from copy import copy
dist = StandardNormal()
urng1 = np.random.default_rng()
urng1_copy = copy(urng1)
rng = TransformedDensityRejection(dist, random_state=urng1)
rng.rvs()
# -1.526829048388144
norm.rvs(random_state=urng1_copy)
# 1.3194816698862635
Мы можем передать domain параметр для усечения распределения:
rng = TransformedDensityRejection(dist, domain=(-1, 1), random_state=urng)
rng.rvs((5, 3))
array([[-0.2666037 , -0.05800429, -0.3242368 ],
[ 0.50252884, 0.98036448, 0.35575173],
[ 0.49842834, -0.17478715, 0.03988961],
[ 0.38855882, 0.68590284, 0.09818596],
[ 0.85125706, 0.09221476, -0.11888094]])
Некорректные и ошибочные аргументы обрабатываются либо SciPy, либо UNU.RAN. Последний выбрасывает UNURANError который следует общему формату:
UNURANError: [objid: <object id>] <error code>: <reason> => <type of error>
где:
The
Пример ошибки, сгенерированной UNU.RAN, показан ниже:
UNURANError: [objid: TDR.003] 50 : PDF(x) < 0.! => (generator) (possible) invalid data
Это показывает, что UNU.RAN не удалось инициализировать объект с ID TDR.003
потому что PDF был < 0, т.е. отрицательным. Это относится к типу
«возможные неверные данные для генератора» и имеет код ошибки 50.
Предупреждения, выдаваемые UNU.RAN, также следуют тому же формату.