numpy.random.Generator.f#
метод
- random.Generator.f(dfnum, dfden, размер=None)#
Извлечение выборок из распределения Фишера.
Выборки берутся из F-распределения с заданными параметрами, dfnum (степени свободы в числителе) и dfden (степени свободы в знаменателе), где оба параметра должны быть больше нуля.
Случайная величина распределения Фишера (также известного как распределение Фишера) — это непрерывное распределение вероятностей, возникающее в тестах ANOVA и представляющее собой отношение двух хи-квадрат случайных величин.
- Параметры:
- dfnumfloat или array_like из float
Степени свободы в числителе, должны быть > 0.
- dfdenfloat или array_like из float
Степени свободы в знаменателе, должны быть > 0.
- размерint или кортеж ints, опционально
Форма вывода. Если заданная форма, например,
(m, n, k), затемm * n * kобразцы извлекаются. Если size равенNone(по умолчанию), возвращается единственное значение, еслиdfnumиdfdenоба являются скалярами. В противном случае,np.broadcast(dfnum, dfden).sizeвыбираются образцы.
- Возвращает:
- выходndarray или скаляр
Выборки, извлечённые из параметризованного распределения Фишера.
Смотрите также
scipy.stats.fфункция плотности вероятности, распределение или интегральная функция распределения и т.д.
Примечания
F-статистика используется для сравнения внутригрупповых дисперсий с межгрупповыми дисперсиями. Расчет распределения зависит от выборки и поэтому является функцией соответствующих степеней свободы в задаче. Переменная dfnum это количество выборок минус один, степени свободы между группами, в то время как dfden является степенями свободы внутри групп, суммой количества выборок в каждой группе минус количество групп.
Ссылки
[1]Гланц, Стэнтон А. «Primer of Biostatistics.», McGraw-Hill, Пятое издание, 2002.
[2]Википедия, «F-распределение», https://en.wikipedia.org/wiki/F-distribution
Примеры
Пример из Glantz [1], стр. 47-40:
Две группы: дети диабетиков (25 человек) и дети людей без диабета (25 контрольных). Измерялся уровень глюкозы в крови натощак, в группе случаев среднее значение составило 86.1, в контрольной группе — 82.2. Стандартные отклонения были 2.09 и 2.49 соответственно. Согласуются ли эти данные с нулевой гипотезой о том, что диабетический статус родителей не влияет на уровень глюкозы в крови их детей? Расчет F-статистики по данным дает значение 36.01.
Извлечь выборки из распределения:
>>> dfnum = 1. # between group degrees of freedom >>> dfden = 48. # within groups degrees of freedom >>> rng = np.random.default_rng() >>> s = rng.f(dfnum, dfden, 1000)
Нижняя граница для верхних 1% выборок:
>>> np.sort(s)[-10] 7.61988120985 # random
Таким образом, существует около 1% вероятности, что F-статистика превысит 7,62, измеренное значение равно 36, поэтому нулевая гипотеза отвергается на уровне 1%.
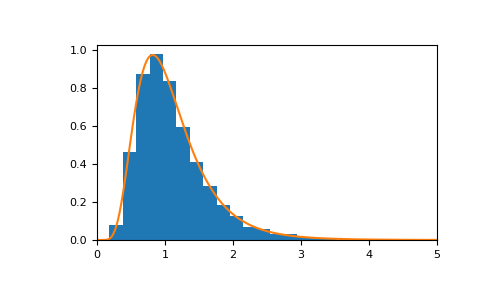
Соответствующая функция плотности вероятности для
n = 20иm = 20равен:>>> import matplotlib.pyplot as plt >>> from scipy import stats >>> dfnum, dfden, size = 20, 20, 10000 >>> s = rng.f(dfnum=dfnum, dfden=dfden, size=size) >>> bins, density, _ = plt.hist(s, 30, density=True) >>> x = np.linspace(0, 5, 1000) >>> plt.plot(x, stats.f.pdf(x, dfnum, dfden)) >>> plt.xlim([0, 5]) >>> plt.show()