9.2. Вычислительная производительность#
Для некоторых приложений производительность (в основном задержка и пропускная способность во время прогнозирования) оценщиков имеет решающее значение. Также может представлять интерес рассмотрение пропускной способности обучения, но это часто менее важно в производственной среде (где оно часто происходит офлайн).
Мы рассмотрим здесь порядки величин, которые можно ожидать от ряда оценщиков scikit-learn в различных контекстах, и предоставим некоторые советы и приемы для преодоления узких мест производительности.
Задержка предсказания измеряется как затраченное время, необходимое для выполнения предсказания (например, в микросекундах). Задержка часто рассматривается как распределение, и инженеры по эксплуатации часто фокусируются на задержке при заданном процентиле этого распределения (например, 90-м процентиле).
Пропускная способность предсказания определяется как количество предсказаний, которое программное обеспечение может выдать за заданное время (например, в предсказаниях в секунду).
Важный аспект оптимизации производительности также заключается в том, что она может ухудшить точность предсказания. Действительно, более простые модели (например, линейные вместо нелинейных или с меньшим количеством параметров) часто работают быстрее, но не всегда способны учитывать те же самые свойства данных, что и более сложные.
9.2.1. Задержка предсказания#
Одной из самых прямых проблем, с которой можно столкнуться при использовании/выборе инструментария машинного обучения, является задержка, с которой можно делать прогнозы в производственной среде.
Основные факторы, влияющие на задержку предсказания:
Количество признаков
Представление входных данных и разреженность
Эквивалентная функция без API оценщика.
Извлечение признаков
Последним важным параметром также является возможность делать предсказания пакетно или по одному.
9.2.1.1. Массовый режим против атомарного режима#
В целом выполнение предсказаний пакетами (много экземпляров одновременно) более эффективно по ряду причин (предсказуемость ветвления, кэш ЦП, оптимизации библиотек линейной алгебры и т.д.). Здесь мы видим в настройке с небольшим количеством признаков, что независимо от выбора оценщика пакетный режим всегда быстрее, а для некоторых из них на 1-2 порядка величины:
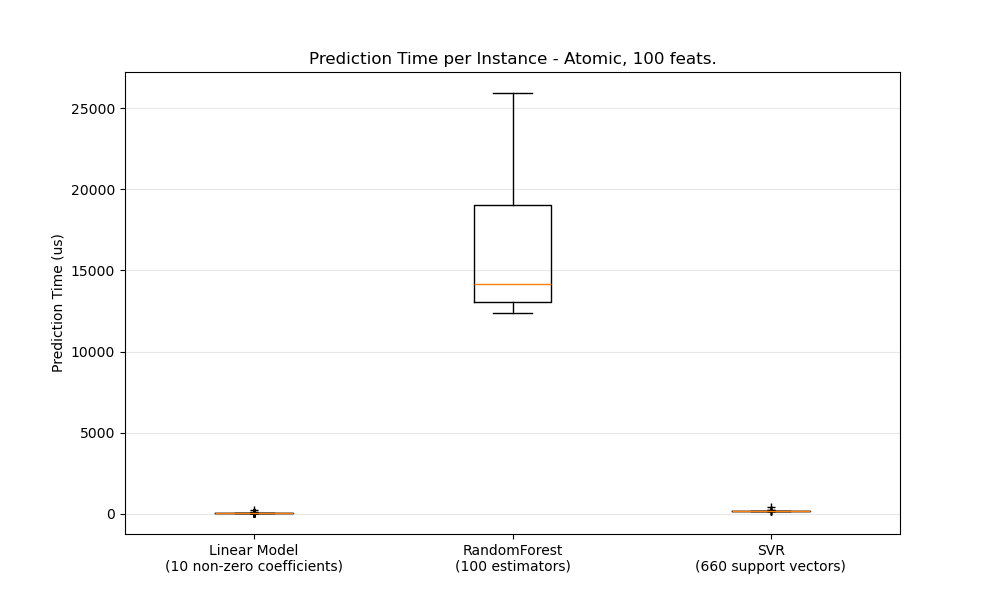
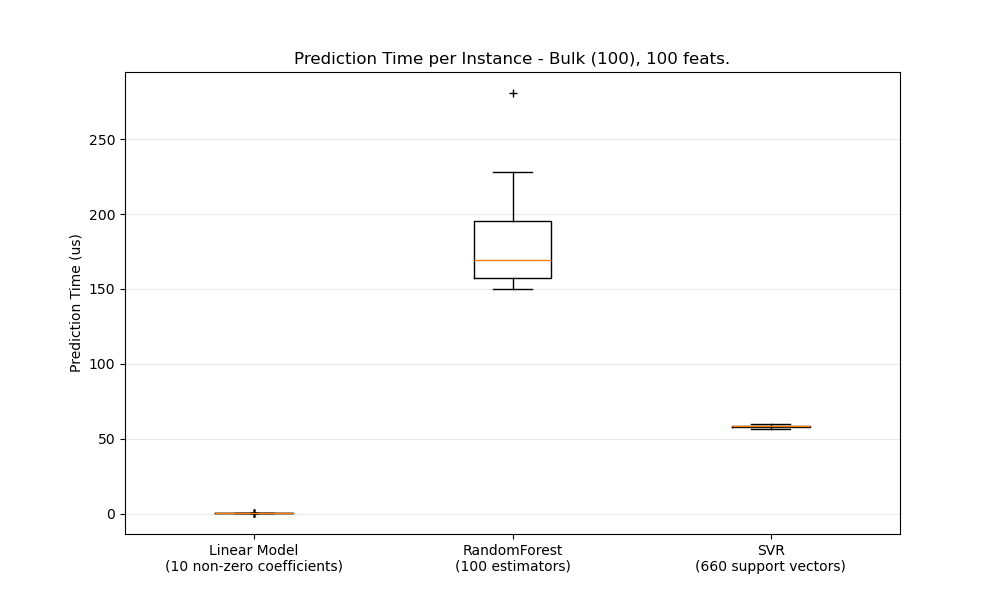
Для сравнения различных оценщиков в вашем случае вы можете просто изменить
n_features параметр в этом примере:
Задержка предсказания. Это должно дать
вам оценку порядка величины задержки прогнозирования.
9.2.1.2. Настройка Scikit-learn для снижения накладных расходов на валидацию#
Scikit-learn выполняет некоторую проверку данных, что увеличивает накладные расходы на
вызов predict и аналогичные функции. В частности, проверка того, что
признаки конечны (не NaN или бесконечны), включает полный проход по
данным. Если вы уверены, что ваши данные приемлемы, вы можете отключить
проверку конечности, установив переменную окружения
SKLEARN_ASSUME_FINITE в непустую строку перед импортом scikit-learn или настроить её в Python с помощью set_config.
Для большего контроля, чем эти глобальные настройки, config_context
позволяет установить эту конфигурацию в указанном контексте:
>>> import sklearn
>>> with sklearn.config_context(assume_finite=True):
... pass # do learning/prediction here with reduced validation
Обратите внимание, что это повлияет на все использования
assert_all_finite в контексте.
9.2.1.3. Влияние количества признаков#
Очевидно, что при увеличении количества признаков увеличивается и потребление памяти для каждого примера. Действительно, для матрицы \(M\) экземпляры с \(N\) признаков, пространственная сложность составляет \(O(NM)\). С вычислительной точки зрения это также означает, что количество базовых операций (например, умножений для векторно-матричных произведений в линейных моделях) увеличивается тоже. Вот график эволюции задержки предсказания в зависимости от количества признаков:
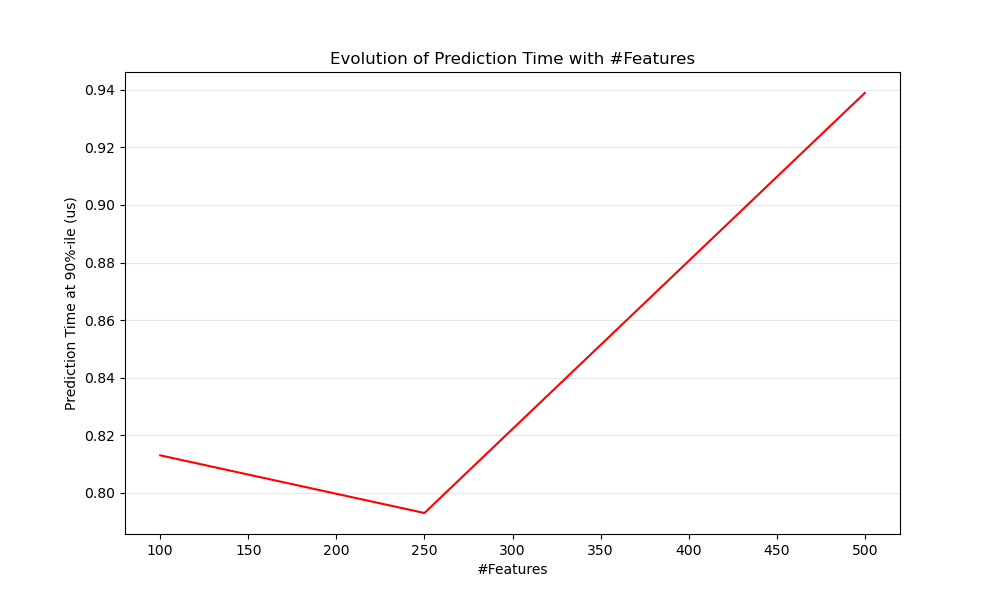
В целом можно ожидать, что время предсказания будет увеличиваться как минимум линейно с количеством признаков (нелинейные случаи могут возникать в зависимости от общего объема памяти и оценщика).
9.2.1.4. Влияние представления входных данных#
Scipy предоставляет структуры данных разреженных матриц, оптимизированные для хранения разреженных данных. Основная особенность разреженных форматов в том, что вы не храните нули, поэтому если ваши данные разрежены, то вы используете гораздо меньше памяти. Ненулевое значение в разреженной (CSR или CSCпредставление будет занимать в среднем только одну 32-битную целочисленную позицию + 64-битное значение с плавающей точкой + дополнительные 32 бита на строку или столбец в матрице. Использование разреженного ввода для плотной (или разреженной) линейной модели может значительно ускорить предсказание, так как только ненулевые признаки влияют на скалярное произведение и, следовательно, на предсказания модели. Таким образом, если у вас есть 100 ненулевых значений в пространстве размерности 1e6, вам нужно только 100 операций умножения и сложения вместо 1e6.
Однако вычисления над плотным представлением могут использовать высокооптимизированные векторные операции и многопоточность в BLAS и обычно приводят к меньшему количеству промахов кэша CPU. Поэтому разреженность обычно должна быть довольно высокой (максимум 10% ненулевых элементов, что следует проверять в зависимости от оборудования), чтобы разреженное входное представление было быстрее плотного на машине со многими CPU и оптимизированной реализацией BLAS.
Вот пример кода для проверки разреженности ваших входных данных:
def sparsity_ratio(X):
return 1.0 - np.count_nonzero(X) / float(X.shape[0] * X.shape[1])
print("input sparsity ratio:", sparsity_ratio(X))
Как правило, если коэффициент разреженности превышает 90%, вы, вероятно, можете извлечь выгоду из разреженных форматов. Проверьте форматы разреженных матриц Scipy документация
для получения дополнительной информации о том, как построить (или преобразовать ваши данные в) разреженные матричные форматы. В большинстве случаев CSR и CSC форматы работают лучше всего.
9.2.1.5. Влияние сложности модели#
Вообще говоря, когда сложность модели увеличивается, прогностическая способность и задержка предположительно увеличиваются. Увеличение прогностической способности обычно интересно, но для многих приложений нам лучше не увеличивать задержку предсказания слишком сильно. Мы теперь рассмотрим эту идею для разных семейств моделей с учителем.
Для sklearn.linear_model (например, Lasso, ElasticNet,
SGDClassifier/Regressor, Ridge & RidgeClassifier, LinearSVC, LogisticRegression…) функция
принятия решений, применяемая во время предсказания, одинакова (скалярное произведение), поэтому
задержка должна быть эквивалентна.
Вот пример использования
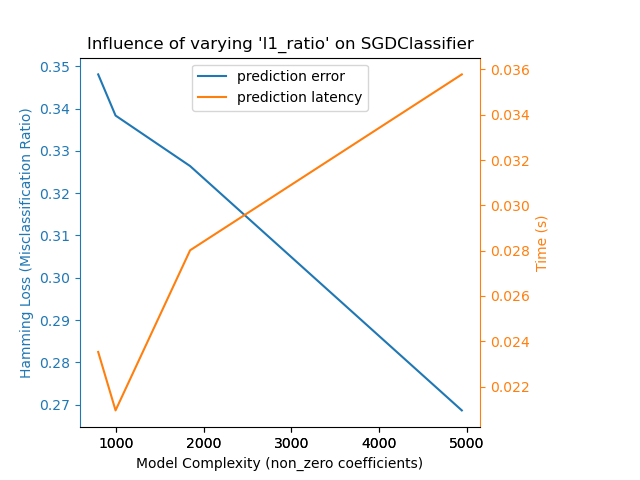
SGDClassifier с
elasticnet штраф. Сила регуляризации глобально контролируется alpha параметр. При достаточно высоком alpha, затем можно увеличить l1_ratio параметр elasticnet для обеспечения различных уровней разреженности в коэффициентах модели. Более высокая разреженность
здесь интерпретируется как меньшая сложность модели, так как нам нужно меньше коэффициентов для
её полного описания. Конечно, разреженность, в свою очередь, влияет на время предсказания,
поскольку разреженное скалярное произведение занимает время, примерно пропорциональное количеству
ненулевых коэффициентов.
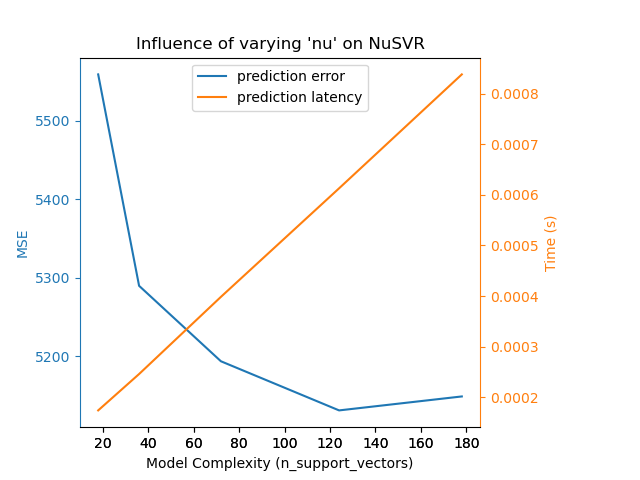
Для sklearn.svm семейство алгоритмов с нелинейным ядром, задержка связана с количеством опорных векторов (чем меньше, тем быстрее). Задержка и пропускная способность должны (асимптотически) расти линейно с количеством опорных векторов в модели SVC или SVR. Ядро также повлияет на задержку, так как оно используется для вычисления проекции входного вектора один раз на каждый опорный вектор. На следующем графике nu параметр
NuSVR использовался для влияния на количество опорных векторов.
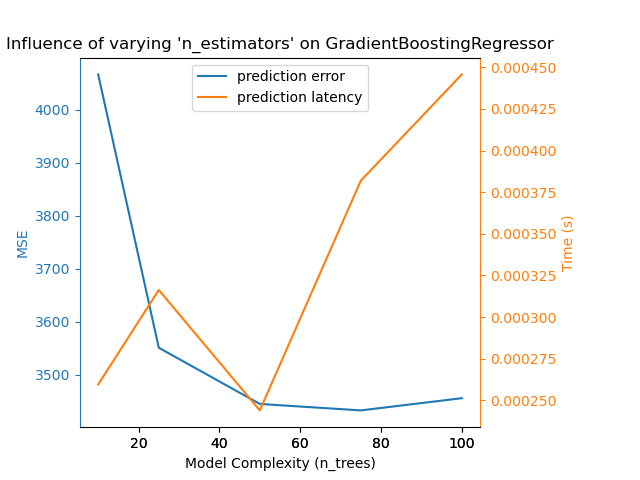
Для sklearn.ensemble деревьев (например, RandomForest, GBT,
ExtraTrees и т.д.) количество деревьев и их глубина играют наиболее
важную роль. Задержка и пропускная способность должны масштабироваться линейно с количеством
деревьев. В данном случае мы использовали непосредственно n_estimators параметр
GradientBoostingRegressor.
В любом случае будьте осторожны, так как уменьшение сложности модели может ухудшить точность, как упоминалось выше. Например, нелинейно разделимую задачу можно обработать с помощью быстрой линейной модели, но предсказательная способность, скорее всего, пострадает в процессе.
9.2.1.6. Задержка извлечения признаков#
Большинство моделей scikit-learn обычно довольно быстры, так как они реализованы либо с помощью скомпилированных расширений Cython, либо с использованием оптимизированных вычислительных библиотек. С другой стороны, во многих реальных приложениях процесс извлечения признаков (т.е. преобразование исходных данных, таких как строки базы данных или сетевые пакеты, в массивы numpy) определяет общее время предсказания. Например, в задаче классификации текстов Reuters вся подготовка (чтение и разбор SGML-файлов, токенизация текста и хеширование его в общее векторное пространство) занимает от 100 до 500 раз больше времени, чем сам код предсказания, в зависимости от выбранной модели.
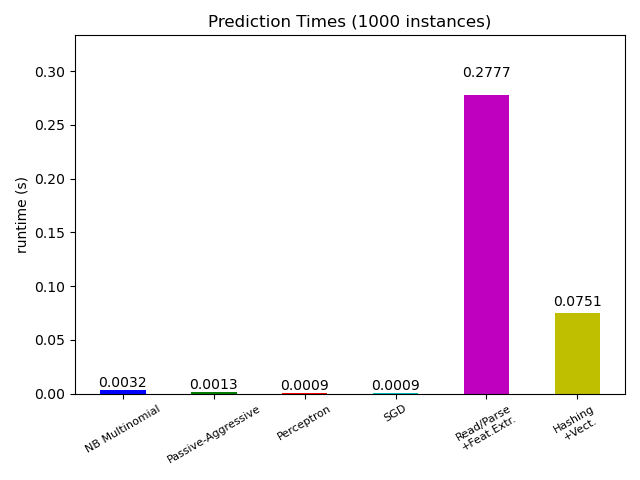
Во многих случаях рекомендуется тщательно измерять время и профилировать ваш код извлечения признаков, так как это может быть хорошим местом для начала оптимизации, когда общая задержка слишком велика для вашего приложения.
9.2.2. Пропускная способность предсказания#
Еще один важный показатель при масштабировании производственных систем - пропускная способность, т.е. количество прогнозов, которые можно сделать за заданное время. Вот тест из Задержка предсказания пример, который измеряет эту величину для ряда оценщиков на синтетических данных:
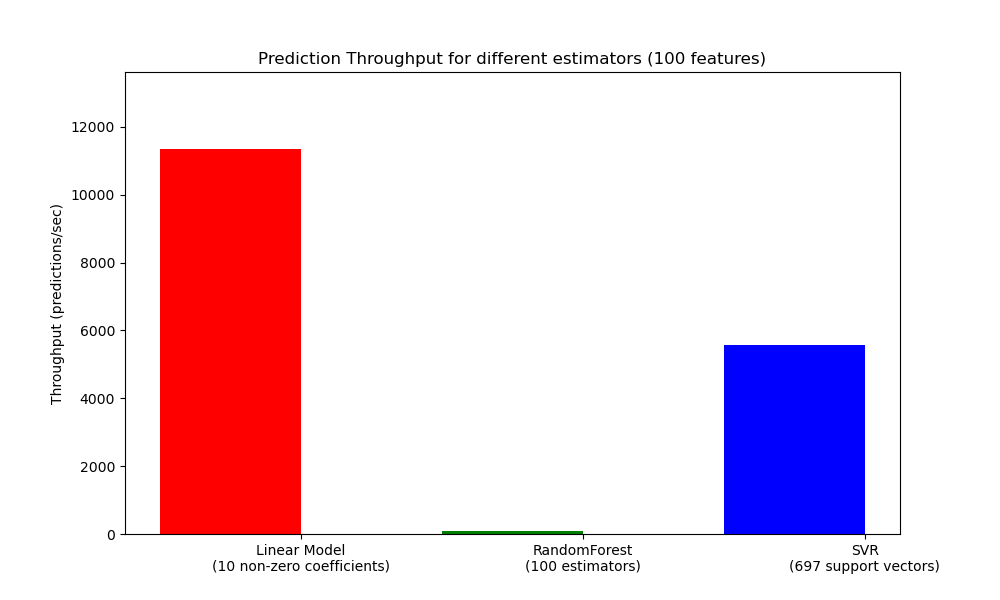
Эти пропускные способности достигаются на одном процессе. Очевидный способ увеличить пропускную способность вашего приложения — запустить дополнительные экземпляры (обычно процессы в Python из-за GIL), которые используют одну и ту же модель. Также можно добавить машины для распределения нагрузки. Подробное объяснение того, как этого достичь, выходит за рамки данной документации.
9.2.3. Советы и рекомендации#
9.2.3.1. Библиотеки линейной алгебры#
Поскольку scikit-learn сильно зависит от Numpy/Scipy и линейной алгебрии в целом, имеет смысл явно заботиться о версиях этих библиотек. В основном, вы должны убедиться, что Numpy собран с использованием оптимизированной BLAS / LAPACK библиотека.
Не все модели выигрывают от оптимизированных реализаций BLAS и Lapack. Например,
модели на основе (рандомизированных) деревьев решений обычно не полагаются на
вызовы BLAS во внутренних циклах, как и ядерные SVM (SVC, SVR,
NuSVC, NuSVR). С другой стороны, линейная модель, реализованная с вызовом BLAS DGEMM (через numpy.dot) обычно значительно выигрывает от настроенной
реализации BLAS и приводит к ускорению на порядки по сравнению с
неоптимизированным BLAS.
Вы можете отобразить реализацию BLAS / LAPACK, используемую вашей установкой NumPy / SciPy / scikit-learn, с помощью следующей команды:
python -c "import sklearn; sklearn.show_versions()"
Оптимизированные реализации BLAS / LAPACK включают:
Atlas (требует аппаратно-специфичной настройки путем пересборки на целевой машине)
OpenBLAS
MKL
Фреймворки Apple Accelerate и vecLib (только для OSX)
Больше информации можно найти на Страница установки NumPy и в этом запись в блоге от Daniel Nouri, где есть хорошие пошаговые инструкции по установке для Debian / Ubuntu.
9.2.3.2. Ограничение рабочей памяти#
Некоторые вычисления при реализации с использованием стандартных векторизованных операций numpy
включают использование большого количества временной памяти. Это может потенциально исчерпать
системную память. Там, где вычисления могут быть выполнены в блоках с фиксированной памятью, мы
пытаемся это сделать и позволяем пользователю указать максимальный размер этой
рабочей памяти (по умолчанию 1 ГБ) с помощью set_config или
config_contextСледующее предлагает ограничить временную рабочую
память до 128 MiB:
>>> import sklearn
>>> with sklearn.config_context(working_memory=128):
... pass # do chunked work here
Пример операции с чанками, соответствующей этой настройке:
pairwise_distances_chunked, что облегчает вычисление
построчных редукций матрицы попарных расстояний.
9.2.3.3. Сжатие модели#
Сжатие моделей в scikit-learn на данный момент касается только линейных моделей. В этом контексте это означает, что мы хотим контролировать разреженность модели (т.е. количество ненулевых координат в векторах модели). Обычно хорошей идеей является сочетание разреженности модели с разреженным представлением входных данных.
Вот пример кода, иллюстрирующий использование sparsify() method:
clf = SGDRegressor(penalty='elasticnet', l1_ratio=0.25)
clf.fit(X_train, y_train).sparsify()
clf.predict(X_test)
В этом примере мы предпочитаем elasticnet штраф, так как он часто является хорошим
компромиссом между компактностью модели и предсказательной силой. Можно также
дальше настраивать l1_ratio параметр (в сочетании с
силой регуляризации alpha) для управления этим компромиссом.
Типичный тест производительности на синтетических данных даёт снижение задержки более чем на 30%, когда и модель, и входные данные разрежены (с соотношением ненулевых коэффициентов 0.000024 и 0.027400 соответственно). Ваши результаты могут варьироваться в зависимости от разреженности и размера ваших данных и модели. Кроме того, разрежение может быть очень полезно для уменьшения использования памяти прогностическими моделями, развёрнутыми на производственных серверах.
9.2.3.4. Изменение формы модели#
Изменение формы модели заключается в выборе только части доступных признаков
для подгонки модели. Другими словами, если модель отбрасывает признаки на этапе
обучения, мы можем затем удалить их из входных данных. Это имеет несколько
преимуществ. Во-первых, это уменьшает затраты памяти (и, следовательно, времени) самой
модели. Это также позволяет отказаться от явных
компонентов отбора признаков в конвейере, как только мы узнаем, какие признаки
сохранять из предыдущего запуска. Наконец, это может помочь сократить время обработки и использование I/O
на более ранних этапах в слоях доступа к данным и извлечения признаков, не
собирая и не создавая признаки, которые отбрасываются моделью. Например,
если исходные данные поступают из базы данных, можно писать более простые
и быстрые запросы или уменьшить использование I/O, заставляя запросы возвращать более легкие
записи.
В настоящее время изменение формы необходимо выполнять вручную в scikit-learn.
В случае разреженных входных данных (особенно в CSR формат), обычно
достаточно не генерировать соответствующие признаки, оставляя их столбцы пустыми.