1.3. Ядерная гребневая регрессия#
Ядерная гребневая регрессия (KRR) [M2012] объединяет Ридж-регрессия и классификация (линейные наименьшие квадраты с \(L_2\)-норма регуляризация) с ядерный трюк. Таким образом, он изучает линейную функцию в пространстве, индуцированном соответствующим ядром и данными. Для нелинейных ядер это соответствует нелинейной функции в исходном пространстве.
Форма модели, изученной KernelRidge идентичен регрессии
метода опорных векторов (SVR). Однако используются разные функции
потерь: KRR использует квадратичную ошибку, а регрессия методом опорных векторов
использует \(\epsilon\)-нечувствительная функция потерь, обе объединены с \(L_2\)
регуляризация. В отличие от SVR, обучение
KernelRidge может быть выполнено в замкнутой форме и обычно быстрее для наборов данных среднего размера. С другой стороны, обученная модель не является разреженной и, следовательно, медленнее, чем SVR, который изучает разреженную модель для
\(\epsilon > 0\), во время предсказания.
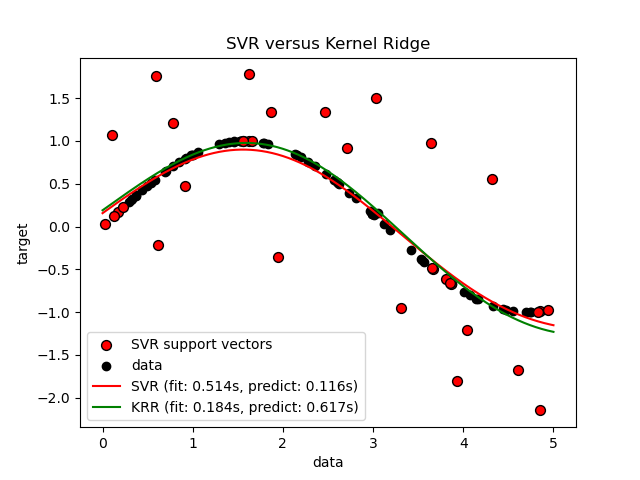
Следующий рисунок сравнивает KernelRidge и
SVR на искусственном наборе данных, который состоит из
синусоидальной целевой функции и сильного шума, добавленного к каждой пятой точке данных.
Изученная модель KernelRidge и SVR отображается,
где как сложность/регуляризация, так и ширина полосы RBF-ядра
были оптимизированы с помощью поиска по сетке. Изученные функции очень
похожи; однако, подгонка KernelRidge примерно в семь раз
быстрее, чем обучение SVR (оба с поиском по сетке).
Однако предсказание 100 000 целевых значений более чем в три раза быстрее с SVR поскольку он обучил разреженную модель, используя только примерно 1/3 из 100 обучающих точек данных в качестве опорных векторов.
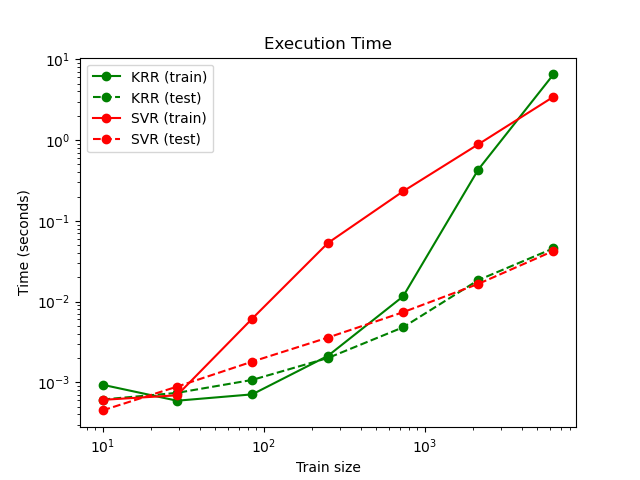
Следующий рисунок сравнивает время обучения и предсказания для
KernelRidge и SVR для различных размеров
обучающего набора. Обучение KernelRidge быстрее, чем
SVR для наборов данных среднего размера (менее 1000 выборок); однако для больших наборов данных SVR масштабируется
лучше. Что касается времени предсказания, SVR быстрее, чем KernelRidge для всех размеров обучающей выборки из-за
изученного разреженного решения. Обратите внимание, что степень разреженности и, следовательно,
время предсказания зависит от параметров \(\epsilon\) и \(C\) из
SVR; \(\epsilon = 0\) будет соответствовать плотной модели.
Примеры
Ссылки
«Машинное обучение: вероятностная перспектива» Мерфи, К. П. — глава 14.4.3, стр. 492-493, The MIT Press, 2012