1.12. Многоклассовые и многомерные алгоритмы#
Этот раздел руководства пользователя охватывает функциональность, связанную с многозадачными проблемами обучения, включая многоклассовый, многометочный, и multioutput классификация и регрессия.
Модули в этом разделе реализуют мета-оценщики, которые требуют предоставления базового оценщика в их конструкторе. Мета-оценщики расширяют функциональность базового оценщика для поддержки многозадачных проблем обучения, что достигается путем преобразования многозадачной проблемы обучения в набор более простых проблем, затем подгонки одного оценщика на проблему.
В этом разделе рассматриваются два модуля: sklearn.multiclass и
sklearn.multioutput. На диаграмме ниже показаны типы задач,
за которые отвечает каждый модуль, и соответствующие мета-оценщики,
которые предоставляет каждый модуль.
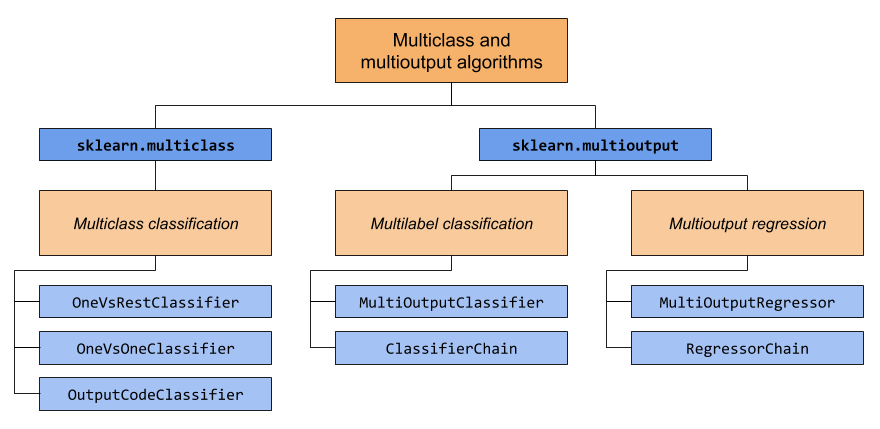
В таблице ниже приведено краткое сравнение различий между типами задач. Более подробные объяснения можно найти в последующих разделах этого руководства.
Количество целевых переменных |
Мощность целевой переменной |
Допустимый
|
|
|---|---|---|---|
Многоклассовая классификация |
1 |
>2 |
'multiclass' |
Многометочная классификация |
>1 |
2 (0 или 1) |
‘multilabel-indicator’ |
Многоклассовая многовариантная классификация |
>1 |
>2 |
‘multiclass-multioutput’ |
Многоклассовая регрессия |
>1 |
Непрерывный |
‘continuous-multioutput’ |
Ниже приведена сводка оценщиков scikit-learn со встроенной поддержкой многозадачного обучения, сгруппированных по стратегиям. Вам не нужны мета-оценщики, предоставляемые этим разделом, если вы используете один из этих оценщиков. Однако мета-оценщики могут предоставить дополнительные стратегии помимо встроенных:
По своей природе многоклассовый:
svm.LinearSVC(установка multi_class=”crammer_singer”)linear_model.LogisticRegression(с большинством решателей)linear_model.LogisticRegressionCV(с большинством решателей)
Многоклассовая классификация как Один-против-Одного:
gaussian_process.GaussianProcessClassifier(установка multi_class = "one_vs_one")
Многоклассовая классификация как One-Vs-The-Rest:
gaussian_process.GaussianProcessClassifier(установка multi_class = "one_vs_rest")svm.LinearSVC(установка multi_class="ovr")linear_model.LogisticRegression(большинство решателей)linear_model.LogisticRegressionCV(большинство решателей)
Поддержка многометочности:
Поддержка многоклассового многомерного вывода:
1.12.1. Многоклассовая классификация#
Предупреждение
Все классификаторы в scikit-learn выполняют многоклассовую классификацию
из коробки. Вам не нужно использовать sklearn.multiclass модуль
если только вы не хотите экспериментировать с различными стратегиями многоклассовой классификации.
Многоклассовая классификация является задачей классификации с более чем двумя классами. Каждый образец может быть помечен только одним классом.
Например, классификация с использованием признаков, извлеченных из набора изображений фруктов, где каждое изображение может быть апельсином, яблоком или грушей. Каждое изображение — это один образец и помечено как один из 3 возможных классов. Многоклассовая классификация предполагает, что каждый образец относится к одной и только одной метке — один образец не может быть, например, одновременно грушей и яблоком.
Хотя все классификаторы scikit-learn способны к многоклассовой классификации, мета-оценщики, предлагаемые sklearn.multiclass
разрешать изменять способ обработки более двух классов, потому что это может повлиять на производительность классификатора (с точки зрения ошибки обобщения или требуемых вычислительных ресурсов).
1.12.1.1. Формат цели#
Допустимый многоклассовый представления для
type_of_target (y) являются:
1d или вектор-столбец, содержащий более двух дискретных значений. Пример вектора
yдля 4 образцов:>>> import numpy as np >>> y = np.array(['apple', 'pear', 'apple', 'orange']) >>> print(y) ['apple' 'pear' 'apple' 'orange']
Плотный или разреженный бинарный матрица формы
(n_samples, n_classes)с одним образцом в строке, где каждый столбец представляет один класс. Пример как плотной, так и разреженной бинарный матрицаyдля 4 образцов, где столбцы, по порядку, — яблоко, апельсин и груша:>>> import numpy as np >>> from sklearn.preprocessing import LabelBinarizer >>> y = np.array(['apple', 'pear', 'apple', 'orange']) >>> y_dense = LabelBinarizer().fit_transform(y) >>> print(y_dense) [[1 0 0] [0 0 1] [1 0 0] [0 1 0]] >>> from scipy import sparse >>> y_sparse = sparse.csr_matrix(y_dense) >>> print(y_sparse)
with 4 stored elements and shape (4, 3)> Coords Values (0, 0) 1 (1, 2) 1 (2, 0) 1 (3, 1) 1
Для получения дополнительной информации о LabelBinarizer, см. Преобразование целевой переменной (y).
1.12.1.2. OneVsRestClassifier#
The один-против-всех стратегия, также известная как one-vs-all, реализована в
OneVsRestClassifier. Стратегия заключается в
обучении одного классификатора на класс. Для каждого классификатора класс обучается
против всех остальных классов. В дополнение к вычислительной эффективности
(только n_classes классификаторы необходимы), одним из преимуществ этого подхода является его интерпретируемость. Поскольку каждый класс представлен одним и только одним классификатором, можно получить знания о классе, исследуя соответствующий ему классификатор. Это наиболее часто используемая стратегия и разумный выбор по умолчанию.
Ниже приведен пример многоклассового обучения с использованием OvR:
>>> from sklearn import datasets
>>> from sklearn.multiclass import OneVsRestClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> OneVsRestClassifier(LinearSVC(random_state=0)).fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
OneVsRestClassifier также поддерживает многометочную классификацию. Чтобы использовать эту функцию, передайте классификатору индикаторную матрицу, в которой ячейка [i, j] указывает наличие метки j в образце i.
Примеры
1.12.1.3. OneVsOneClassifier#
OneVsOneClassifier строит один классификатор на
пару классов. Во время предсказания выбирается класс, получивший наибольшее количество голосов.
В случае ничьей (среди двух классов с равным количеством
голосов) выбирается класс с наивысшей совокупной уверенностью классификации
путем суммирования уровней уверенности попарной классификации,
вычисленных базовыми бинарными классификаторами.
Поскольку требуется подогнать n_classes * (n_classes - 1) / 2 классификаторов, этот метод обычно медленнее, чем one-vs-the-rest, из-за его сложности O(n_classes^2). Однако этот метод может быть преимуществом для алгоритмов, таких как ядерные алгоритмы, которые плохо масштабируются с
n_samples. Это связано с тем, что каждая отдельная задача обучения включает только
небольшое подмножество данных, тогда как при подходе «один против всех» используется полный
набор данных n_classes раз. Функция принятия решений является результатом
монотонного преобразования классификации один-против-одного.
Ниже приведен пример многоклассового обучения с использованием OvO:
>>> from sklearn import datasets
>>> from sklearn.multiclass import OneVsOneClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> OneVsOneClassifier(LinearSVC(random_state=0)).fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
Ссылки
“Pattern Recognition and Machine Learning. Springer”, Кристофер М. Бишоп, страница 183, (Первое издание)
Метка по умолчанию для размещения на оси x. OutputCodeClassifier#
Стратегии на основе кодов с исправлением ошибок довольно сильно отличаются от one-vs-the-rest и one-vs-one. С этими стратегиями каждый класс представлен в евклидовом пространстве, где каждое измерение может быть только 0 или 1. Другими словами, каждый класс представлен двоичным кодом (массивом из 0 и 1). Матрица, которая отслеживает местоположение/код каждого класса, называется книгой кодов. Размер кода — это размерность упомянутого пространства. Интуитивно, каждый класс должен быть представлен кодом как можно более уникальным, и хорошая книга кодов должна быть разработана для оптимизации точности классификации. В этой реализации мы просто используем случайно сгенерированную книгу кодов, как рекомендуется в [3] хотя более сложные методы могут быть добавлены в будущем.
На этапе подгонки подгоняется один бинарный классификатор на каждый бит в кодовой книге. На этапе прогнозирования классификаторы используются для проецирования новых точек в пространство классов, и выбирается класс, ближайший к точкам.
В OutputCodeClassifier, code_size
атрибут позволяет пользователю контролировать количество классификаторов, которые будут использоваться. Это процент от общего количества классов.
Число между 0 и 1 потребует меньше классификаторов, чем
one-vs-the-rest. Теоретически, log2(n_classes) / n_classes достаточно для
однозначного представления каждого класса. Однако на практике это может не привести к
хорошей точности, поскольку log2(n_classes) намного меньше, чем n_classes.
Число больше 1 потребует больше классификаторов, чем метод «один против всех». В этом случае некоторые классификаторы теоретически будут исправлять ошибки, допущенные другими классификаторами, отсюда и название «исправляющий ошибки». Однако на практике этого может не произойти, так как ошибки классификаторов обычно коррелируют. Коды выхода, исправляющие ошибки, имеют эффект, аналогичный бэггингу.
Ниже приведён пример многоклассового обучения с использованием Output-Codes:
>>> from sklearn import datasets
>>> from sklearn.multiclass import OutputCodeClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> clf = OutputCodeClassifier(LinearSVC(random_state=0), code_size=2, random_state=0)
>>> clf.fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 2, 2, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
Ссылки
“Решение многоклассовых задач обучения с помощью кодов с исправлением ошибок”, Dietterich T., Bakiri G., Journal of Artificial Intelligence Research 2, 1995.
"The Elements of Statistical Learning", Хасти Т., Тибширани Р., Фридман Дж., страница 606 (второе издание), 2008.
1.12.2. Многометочная классификация#
Многометочная классификация (тесно связан с multioutput
классификация) — это задача классификации, маркирующая каждый образец с m
метки из n_classes возможные классы, где m может быть от 0 до
n_classes включительно. Это можно рассматривать как предсказание свойств выборки, которые не являются взаимоисключающими. Формально, для каждого класса назначается двоичный выход, для каждой выборки. Положительные классы обозначаются 1, а отрицательные — 0 или -1. Таким образом, это сравнимо с запуском n_classes
задачи бинарной классификации, например, с
MultiOutputClassifier. Этот подход рассматривает каждую метку независимо, тогда как многометочные классификаторы может обрабатывать
несколько классов одновременно, учитывая коррелированное поведение среди
них.
Например, предсказание тем, относящихся к текстовому документу или видео. Документ или видео могут быть об одной из тем 'религия', 'политика', 'финансы' или 'образование', нескольких тематических классов или всех тематических классов.
1.12.2.1. Формат цели#
Допустимое представление многометочный y является плотным или разреженным
бинарный матрица формы (n_samples, n_classes)Каждый столбец
представляет класс. 1в каждой строке обозначают положительные классы, с которыми была помечена выборка. Пример плотной матрицы y для 3
образцов:
>>> y = np.array([[1, 0, 0, 1], [0, 0, 1, 1], [0, 0, 0, 0]])
>>> print(y)
[[1 0 0 1]
[0 0 1 1]
[0 0 0 0]]
Плотные бинарные матрицы также могут быть созданы с использованием
MultiLabelBinarizer. Для дополнительной информации обратитесь к Преобразование целевой переменной (y).
Обратите внимание, что реализации BLAS & LAPACK также могут быть затронуты y в разреженной матричной форме:
>>> y_sparse = sparse.csr_matrix(y)
>>> print(y_sparse)
with 4 stored elements and shape (3, 4)>
Coords Values
(0, 0) 1
(0, 3) 1
(1, 2) 1
(1, 3) 1
1.12.2.2. MultiOutputClassifier#
Поддержку многометочной классификации можно добавить к любому классификатору с
MultiOutputClassifier. Эта стратегия заключается в обучении одного классификатора на каждую цель. Это позволяет классифицировать несколько целевых переменных. Цель этого класса — расширить оценщики, чтобы они могли оценивать серию целевых функций (f1,f2,f3…,fn), которые обучаются на одной матрице предикторов X для предсказания серии ответов (y1,y2,y3…,yn).
Вы можете найти пример использования для
MultiOutputClassifier
в рамках раздела о Многоклассовая многомерная классификация
поскольку это обобщение многометочной классификации на
многоклассовые выходы вместо бинарных выходов.
1.12.2.3. ClassifierChain#
Цепи классификаторов (см. ClassifierChain) — это способ объединения нескольких бинарных классификаторов в единую многометочную модель, способную использовать корреляции между целями.
Для многоклассовой классификации с N классами, N бинарных классификаторов присваивается целое число от 0 до N-1. Эти целые числа определяют порядок моделей в цепочке. Каждый классификатор затем обучается на доступных обучающих данных плюс истинные метки классов, чьи модели были присвоены меньшие номера.
При прогнозировании истинные метки будут недоступны. Вместо этого предсказания каждой модели передаются последующим моделям в цепочке для использования в качестве признаков.
Очевидно, порядок цепочки важен. Первая модель в цепочке не имеет информации о других метках, в то время как последняя модель в цепочке имеет признаки, указывающие на наличие всех других меток. В общем случае неизвестен оптимальный порядок моделей в цепочке, поэтому обычно обучают много случайно упорядоченных цепочек и усредняют их предсказания.
Ссылки
Jesse Read, Bernhard Pfahringer, Geoff Holmes, Eibe Frank, “Classifier Chains for Multi-label Classification”, 2009.
1.12.3. Многоклассовая многомерная классификация#
Многоклассовая многомерная классификация (также известный как многозадачная классификация) — это задача классификации, которая помечает каждый образец набором небинарный свойств. И количество свойств, и количество классов на свойство больше 2. Таким образом, один оценщик обрабатывает несколько совместных задач классификации. Это одновременно обобщение многоклассовойметка задача классификации, которая рассматривает только бинарные атрибуты, а также обобщение многоклассовойкласс задача классификации, где рассматривается только одно свойство.
Например, классификация свойств "тип фрукта" и "цвет" для набора изображений фруктов. Свойство "тип фрукта" имеет возможные классы: "яблоко", "груша" и "апельсин". Свойство "цвет" имеет возможные классы: "зеленый", "красный", "желтый" и "оранжевый". Каждая выборка - это изображение фрукта, метка выводится для обоих свойств, и каждая метка - это один из возможных классов соответствующего свойства.
Обратите внимание, что все классификаторы, обрабатывающие многоклассовые-многомерные (также известные как многозадачные) задачи, поддерживают задачу многометочной классификации как частный случай. Многозадачная классификация похожа на многомерную задачу классификации с различными формулировками моделей. Для получения дополнительной информации см. соответствующую документацию оценщика.
Ниже приведён пример многоклассовой многовариантной классификации:
>>> from sklearn.datasets import make_classification
>>> from sklearn.multioutput import MultiOutputClassifier
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.utils import shuffle
>>> import numpy as np
>>> X, y1 = make_classification(n_samples=10, n_features=100,
... n_informative=30, n_classes=3,
... random_state=1)
>>> y2 = shuffle(y1, random_state=1)
>>> y3 = shuffle(y1, random_state=2)
>>> Y = np.vstack((y1, y2, y3)).T
>>> n_samples, n_features = X.shape # 10,100
>>> n_outputs = Y.shape[1] # 3
>>> n_classes = 3
>>> forest = RandomForestClassifier(random_state=1)
>>> multi_target_forest = MultiOutputClassifier(forest, n_jobs=2)
>>> multi_target_forest.fit(X, Y).predict(X)
array([[2, 2, 0],
[1, 2, 1],
[2, 1, 0],
[0, 0, 2],
[0, 2, 1],
[0, 0, 2],
[1, 1, 0],
[1, 1, 1],
[0, 0, 2],
[2, 0, 0]])
Предупреждение
В настоящее время ни одна метрика в sklearn.metrics
поддерживает задачу многоклассовой многомерной классификации.
1.12.3.1. Формат цели#
Допустимое представление multioutput y является плотной матрицей формы
(n_samples, n_classes) меток классов. Постолбцовое объединение одномерных
многоклассовый переменные. Пример y для 3 образцов:
>>> y = np.array([['apple', 'green'], ['orange', 'orange'], ['pear', 'green']])
>>> print(y)
[['apple' 'green']
['orange' 'orange']
['pear' 'green']]
1.12.4. Многомерная регрессия#
Многомерная регрессия предсказывает несколько числовых свойств для каждой выборки. Каждое свойство — это числовая переменная, и количество свойств, предсказываемых для каждой выборки, больше или равно 2. Некоторые оценщики, поддерживающие многомерную регрессию, быстрее, чем просто запуск n_output
оценщики.
Например, прогнозирование как скорости ветра, так и направления ветра в градусах, используя данные, полученные в определённом месте. Каждый образец будет данными, полученными в одном месте, и как скорость, так и направление ветра будут выходными данными для каждого образца.
Следующие регрессоры изначально поддерживают многомерную регрессию:
1.12.4.1. Формат цели#
Допустимое представление multioutput y является плотной матрицей формы
(n_samples, n_output) чисел с плавающей запятой. Постолбцовое объединение
непрерывный переменные. Пример y для 3 образцов:
>>> y = np.array([[31.4, 94], [40.5, 109], [25.0, 30]])
>>> print(y)
[[ 31.4 94. ]
[ 40.5 109. ]
[ 25. 30. ]]
1.12.4.2. MultiOutputRegressor#
Поддержка многомерной регрессии может быть добавлена к любому регрессору с помощью
MultiOutputRegressor. Эта стратегия заключается в обучении одного регрессора на каждую целевую переменную. Поскольку каждая целевая переменная представлена ровно одним регрессором, можно получить знания о целевой переменной, анализируя соответствующий регрессор. Как
MultiOutputRegressor обучает один регрессор на цель, он не может использовать корреляции между целями.
Ниже приведен пример многомерной регрессии:
>>> from sklearn.datasets import make_regression
>>> from sklearn.multioutput import MultiOutputRegressor
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> X, y = make_regression(n_samples=10, n_targets=3, random_state=1)
>>> MultiOutputRegressor(GradientBoostingRegressor(random_state=0)).fit(X, y).predict(X)
array([[-154.75474165, -147.03498585, -50.03812219],
[ 7.12165031, 5.12914884, -81.46081961],
[-187.8948621 , -100.44373091, 13.88978285],
[-141.62745778, 95.02891072, -191.48204257],
[ 97.03260883, 165.34867495, 139.52003279],
[ 123.92529176, 21.25719016, -7.84253 ],
[-122.25193977, -85.16443186, -107.12274212],
[ -30.170388 , -94.80956739, 12.16979946],
[ 140.72667194, 176.50941682, -17.50447799],
[ 149.37967282, -81.15699552, -5.72850319]])
1.12.4.3. RegressorChain#
Цепи регрессоров (см. RegressorChain) аналогичен ClassifierChain как способ объединения нескольких регрессий в единую многозадачную модель, способную использовать корреляции между целевыми переменными.