8.3. Сгенерированные наборы данных#
Кроме того, scikit-learn включает различные генераторы случайных образцов, которые могут использоваться для создания искусственных наборов данных контролируемого размера и сложности.
8.3.1. Генераторы для классификации и кластеризации#
Эти генераторы создают матрицу признаков и соответствующих дискретных целевых переменных.
8.3.1.1. Одиночная метка#
make_blobs Создать ветку релиза
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(centers=3, cluster_std=0.5, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title("Three normally-distributed clusters")
plt.show()
make_classification также создает мультиклассовые наборы данных, но специализируется на внесении шума путем: коррелированных, избыточных и неинформативных признаков; нескольких гауссовых кластеров на класс; и линейных преобразований пространства признаков.
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
fig, axs = plt.subplots(1, 3, figsize=(12, 4), sharey=True, sharex=True)
titles = ["Two classes,\none informative feature,\none cluster per class",
"Two classes,\ntwo informative features,\ntwo clusters per class",
"Three classes,\ntwo informative features,\none cluster per class"]
params = [
{"n_informative": 1, "n_clusters_per_class": 1, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 2, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 1, "n_classes": 3}
]
for i, param in enumerate(params):
X, Y = make_classification(n_features=2, n_redundant=0, random_state=1, **param)
axs[i].scatter(X[:, 0], X[:, 1], c=Y)
axs[i].set_title(titles[i])
plt.tight_layout()
plt.show()
make_gaussian_quantiles разделяет единый гауссов кластер на классы почти равного размера, разделённые концентрическими гиперсферами.
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
X, Y = make_gaussian_quantiles(n_features=2, n_classes=3, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=Y)
plt.title("Gaussian divided into three quantiles")
plt.show()
make_hastie_10_2 генерирует аналогичную бинарную 10-мерную задачу.
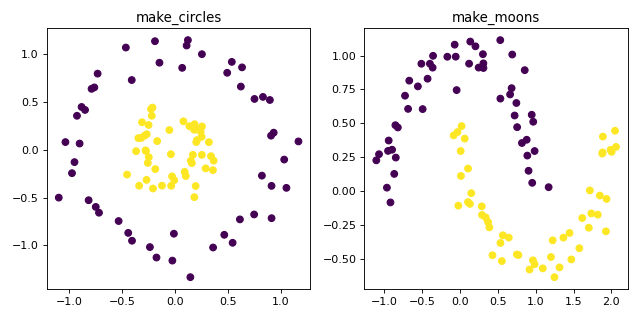
make_circles и make_moons генерировать 2D-наборы данных для бинарной классификации,
которые являются сложными для определенных алгоритмов (например, кластеризации на основе центроидов
или линейной классификации), включая опциональный гауссов шум.
Они полезны для визуализации. make_circles генерирует гауссовские данные со сферической границей решений для бинарной классификации, в то время как
make_moons создаёт два переплетающихся полукруга.
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_moons
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
X, Y = make_circles(noise=0.1, factor=0.3, random_state=0)
ax1.scatter(X[:, 0], X[:, 1], c=Y)
ax1.set_title("make_circles")
X, Y = make_moons(noise=0.1, random_state=0)
ax2.scatter(X[:, 0], X[:, 1], c=Y)
ax2.set_title("make_moons")
plt.tight_layout()
plt.show()
8.3.1.2. Многометочная#
make_multilabel_classification генерирует случайные выборки с несколькими метками, отражая мешок слов, извлеченный из смеси тем. Количество тем для каждого документа извлекается из распределения Пуассона, а сами темы извлекаются из фиксированного случайного распределения. Аналогично, количество слов извлекается из распределения Пуассона, а слова извлекаются из мультиномиального распределения, где каждая тема определяет распределение вероятностей по словам. Упрощения по сравнению с истинными смесями мешка слов включают:
Распределения слов по темам рисуются независимо, хотя в реальности все будут затронуты разреженным базовым распределением и будут коррелированы.
Для документа, сгенерированного из нескольких тем, все темы взвешиваются равномерно при создании его мешка слов.
Документы без меток слов случайным образом, а не из базового распределения.
8.3.1.3. Бикластеризация#
|
Сгенерировать массив структуры постоянного блочного диагоналя для бикластеризации. |
|
Сгенерировать массив с блочной шахматной структурой для бикластеризации. |
8.3.2. Generators for regression#
make_regression генерирует регрессионные цели как случайную линейную комбинацию случайных признаков, возможно разреженную, с шумом. Его информативные признаки могут быть некоррелированными или иметь низкий ранг (несколько признаков объясняют большую часть дисперсии).
Другие генераторы регрессии генерируют функции детерминированно из рандомизированных признаков. make_sparse_uncorrelated генерирует цель как
линейную комбинацию четырех признаков с фиксированными коэффициентами.
Другие явно кодируют нелинейные отношения:
make_friedman1 связано полиномиальными и синусоидальными преобразованиями;
make_friedman2 включает умножение признаков и обращение; и
make_friedman3 похож с arctan-преобразованием целевой переменной.
8.3.3. Генераторы для обучения многообразий#
|
Сгенерировать набор данных S-кривой. |
|
Сгенерировать набор данных 'швейцарский рулет'. |
8.3.4. Генераторы для декомпозиции#
|
Сгенерировать в основном низкоранговую матрицу с колоколообразными сингулярными значениями. |
|
Сгенерировать сигнал как разреженную комбинацию элементов словаря. |
|
Генерирует случайную симметричную, положительно определённую матрицу. |
|
Сгенерировать разреженную симметричную положительно определённую матрицу. |