1.4. Метод опорных векторов#
Метод опорных векторов (SVM) представляют собой набор методов обучения с учителем, используемых для классификация, регрессия и обнаружение выбросов.
Преимущества метода опорных векторов:
Эффективен в пространствах высокой размерности.
Все еще эффективен в случаях, когда количество измерений больше количества образцов.
Использует подмножество обучающих точек в функции принятия решений (называемых опорными векторами), поэтому он также эффективен по памяти.
Универсальный: различные Функции ядра может быть указана для решающей функции. Предоставляются общие ядра, но также можно указать пользовательские ядра.
Недостатки методов опорных векторов включают:
Если количество признаков значительно превышает количество выборок, избегайте переобучения при выборе Функции ядра и регуляризационный член является критическим.
Метод опорных векторов не предоставляет напрямую оценки вероятностей, они вычисляются с использованием дорогостоящей пятикратной перекрестной проверки (см. Оценки и вероятности, ниже).
Методы опорных векторов в scikit-learn поддерживают как плотные (numpy.ndarray и преобразуемы в это с помощью numpy.asarray) и разреженные (любые scipy.sparse) векторы выборок в качестве входных данных. Однако, чтобы использовать SVM для предсказаний по разреженным данным, он должен быть обучен на таких данных. Для оптимальной производительности используйте C-упорядоченные numpy.ndarray (плотный) или
scipy.sparse.csr_matrix (разреженные) с dtype=float64.
1.4.1. Классификация#
SVC, NuSVC и LinearSVC являются классами,
способными выполнять бинарную и многоклассовую классификацию на наборе данных.
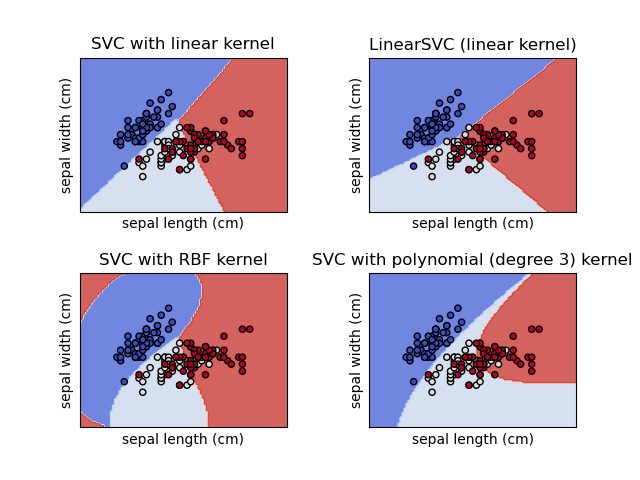
SVC и NuSVC являются похожими методами, но принимают немного разные наборы параметров и имеют разные математические формулировки (см. раздел Математическая формулировка). С другой стороны,
LinearSVC является другой (более быстрой) реализацией метода опорных векторов
для классификации в случае линейного ядра. Он также
не имеет некоторых атрибутов SVC и NuSVC, например
support_. LinearSVC использует squared_hinge потерь и из-за его
реализации в liblinear он также регуляризует свободный член, если он учитывается. Этот эффект, однако, можно уменьшить путем тщательной настройки его
intercept_scaling параметр, который позволяет члену пересечения иметь
другое поведение регуляризации по сравнению с другими признаками. Результаты
классификации и оценка могут поэтому отличаться от двух других
классификаторов.
Как и другие классификаторы, SVC, NuSVC и
LinearSVC принимает на вход два массива: массив X формы
(n_samples, n_features) содержащий обучающие образцы, и массив y меток классов (строк или целых чисел), формы (n_samples):
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC()
После обучения модель может использоваться для предсказания новых значений:
>>> clf.predict([[2., 2.]])
array([1])
функция принятия решений SVM (подробно описана в Математическая формулировка)
зависит от некоторого подмножества обучающих данных, называемых опорными векторами. Некоторые
свойства этих опорных векторов можно найти в атрибутах
support_vectors_, support_ и n_support_:
>>> # get support vectors
>>> clf.support_vectors_
array([[0., 0.],
[1., 1.]])
>>> # get indices of support vectors
>>> clf.support_
array([0, 1]...)
>>> # get number of support vectors for each class
>>> clf.n_support_
array([1, 1]...)
Примеры
1.4.1.1. Многоклассовая классификация#
SVC и NuSVC реализуют подход "один против одного" ("ovo")
для многоклассовой классификации, который строит
n_classes * (n_classes - 1) / 2
классификаторы, каждый обучен на данных из двух классов. Внутренне решатель всегда использует эту стратегию "ovo" для обучения моделей. Однако по умолчанию,
decision_function_shape параметр установлен в "ovr" ("one-vs-rest"), чтобы иметь согласованный интерфейс с другими классификаторами путем монотонного преобразования функции принятия решений "ovo" в функцию принятия решений "ovr" формы (n_samples, n_classes).
>>> X = [[0], [1], [2], [3]]
>>> Y = [0, 1, 2, 3]
>>> clf = svm.SVC(decision_function_shape='ovo')
>>> clf.fit(X, Y)
SVC(decision_function_shape='ovo')
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 6 classes: 4*3/2 = 6
6
>>> clf.decision_function_shape = "ovr"
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes
4
С другой стороны, LinearSVC реализует стратегию "один против всех" ("ovr")
для многоклассовой классификации, таким образом обучая n_classes модели.
>>> lin_clf = svm.LinearSVC()
>>> lin_clf.fit(X, Y)
LinearSVC()
>>> dec = lin_clf.decision_function([[1]])
>>> dec.shape[1]
4
См. Математическая формулировка для полного описания функции принятия решений.
Подробности о стратегиях многоклассовой классификации#
Обратите внимание, что LinearSVC также реализует альтернативную многоклассовую
стратегию, так называемую многоклассовую SVM, сформулированную Crammer и Singer
[16], используя опцию multi_class='crammer_singer'. На практике обычно предпочтительна классификация "один против всех", поскольку результаты в основном схожи, но время выполнения значительно меньше.
Для "один против всех" LinearSVC атрибуты coef_ и intercept_
имеют форму (n_classes, n_features) и (n_classes,) соответственно.
Каждая строка коэффициентов соответствует одному из n_classes
классификаторы "один против остальных" и аналогично для пересечений, в порядке класса "один".
В случае "один против одного" SVC и NuSVC, расположение атрибутов немного сложнее. В случае линейного ядра атрибуты coef_ и intercept_ имеют форму
(n_classes * (n_classes - 1) / 2, n_features) и (n_classes *
(n_classes - 1) / 2) соответственно. Это похоже на расположение для
LinearSVC описанный выше, где каждая строка теперь соответствует
бинарному классификатору. Порядок для классов
от 0 до n: "0 против 1", "0 против 2", … "0 против n", "1 против 2", "1 против 3", "1 против n", . .
. "n-1 против n".
Форма dual_coef_ является (n_classes-1, n_SV) с несколько сложной для понимания структурой. Столбцы соответствуют опорным векторам, участвующим в любом из n_classes * (n_classes - 1) / 2 классификаторы «один против одного». Каждый опорный вектор v имеет двойной коэффициент в каждом из
n_classes - 1 классификаторы, сравнивающие класс v против другого класса.
Обратите внимание, что некоторые, но не все, из этих двойных коэффициентов могут быть нулевыми.
n_classes - 1 записи в каждом столбце являются этими двойными коэффициентами, упорядоченными по противоположному классу.
Это может быть понятнее на примере: рассмотрим задачу с тремя классами, где класс 0 имеет три опорных вектора
\(v^{0}_0, v^{1}_0, v^{2}_0\) и классы 1 и 2 имеют два опорных вектора
\(v^{0}_1, v^{1}_1\) и \(v^{0}_2, v^{1}_2\) соответственно. Для каждого опорного вектора \(v^{j}_i\), есть два двойных коэффициента. Назовём
коэффициент опорного вектора \(v^{j}_i\) в классификаторе между классами \(i\) и \(k\) \(\alpha^{j}_{i,k}\).
Затем dual_coef_ выглядит так:
\(\alpha^{0}_{0,1}\) |
\(\alpha^{1}_{0,1}\) |
\(\alpha^{2}_{0,1}\) |
\(\alpha^{0}_{1,0}\) |
\(\alpha^{1}_{1,0}\) |
\(\alpha^{0}_{2,0}\) |
\(\alpha^{1}_{2,0}\) |
\(\alpha^{0}_{0,2}\) |
\(\alpha^{1}_{0,2}\) |
\(\alpha^{2}_{0,2}\) |
\(\alpha^{0}_{1,2}\) |
\(\alpha^{1}_{1,2}\) |
\(\alpha^{0}_{2,1}\) |
\(\alpha^{1}_{2,1}\) |
Коэффициенты для опорных векторов класса 0 |
Коэффициенты для опорных векторов класса 1 |
Коэффициенты для опорных векторов класса 2 |
||||
Примеры
1.4.1.2. Оценки и вероятности#
The decision_function метод SVC и NuSVC дает оценки для каждого класса для каждого образца (или одну оценку на образец в бинарном случае). Когда опция конструктора probability установлено в True,
оценки вероятности принадлежности к классам (из методов predict_proba и
predict_log_proba) включены. В бинарном случае вероятности
калибруются с использованием масштабирования Платта [9]: логистическая регрессия на оценках SVM,
обученная дополнительной перекрестной проверкой на обучающих данных.
В многоклассовом случае это расширяется в соответствии с [10].
Примечание
Та же процедура калибровки вероятностей доступна для всех оценщиков через CalibratedClassifierCV (см.
Калибровка вероятностей). В случае SVC и NuSVC, эта процедура встроена в libsvm который используется внутри, поэтому он не зависит от
CalibratedClassifierCV.
Кросс-валидация, задействованная в масштабировании Платта, является дорогостоящей операцией для больших наборов данных. Кроме того, оценки вероятности могут быть несогласованными с оценками:
"argmax" оценок может не быть argmax вероятностей
в бинарной классификации, образец может быть помечен как
predictpartial_dependencepredict_probaменьше 0.5; и аналогично, он может быть помечен как отрицательный, даже если выходpredict_probaбольше 0.5.
Метод Платта также известен наличием теоретических проблем.
Если требуются оценки уверенности, но они не обязательно должны быть вероятностями, то рекомендуется установить probability=False
и использовать decision_function вместо predict_proba.
Обратите внимание, что когда decision_function_shape='ovr' и n_classes > 2, в отличие от decision_function, predict метод по умолчанию не пытается разрешать ничьи. Вы можете установить break_ties=True для вывода predict быть таким же, как np.argmax(clf.decision_function(...), axis=1), иначе первый класс среди связанных классов всегда будет возвращаться; но имейте в виду, что это связано с вычислительными затратами. См.
Пример разрешения ничьей в SVM для примера по разрешению ничьих.
1.4.1.3. Несбалансированные задачи#
В задачах, где желательно придать больше важности определенным классам или отдельным образцам, параметры class_weight и
sample_weight может быть использован.
SVC (но не NuSVC) реализует параметр
class_weight в fit метод. Это словарь вида
{class_label : value}, где value — это число с плавающей точкой > 0,
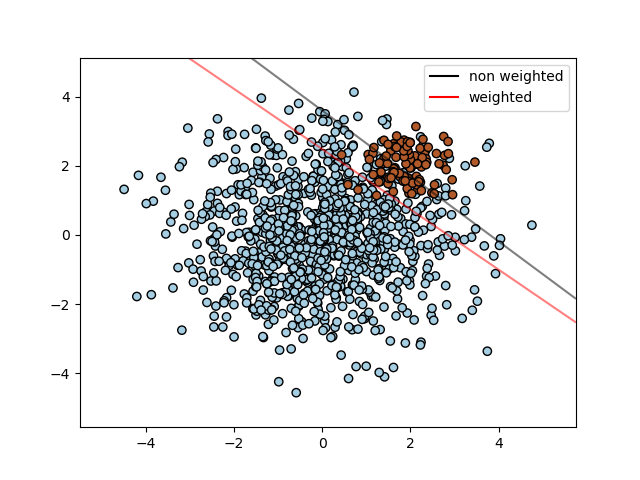
которое устанавливает параметр C класса class_label to C * value. На рисунке ниже показана граница решения несбалансированной задачи с коррекцией весов и без неё.
SVC, NuSVC, SVR, NuSVR, LinearSVC,
LinearSVR и OneClassSVM также реализовать веса для отдельных образцов в fit метод через sample_weight параметр.
Аналогично class_weight, это устанавливает параметр C для i-го примера к C * sample_weight[i], что побудит классификатор
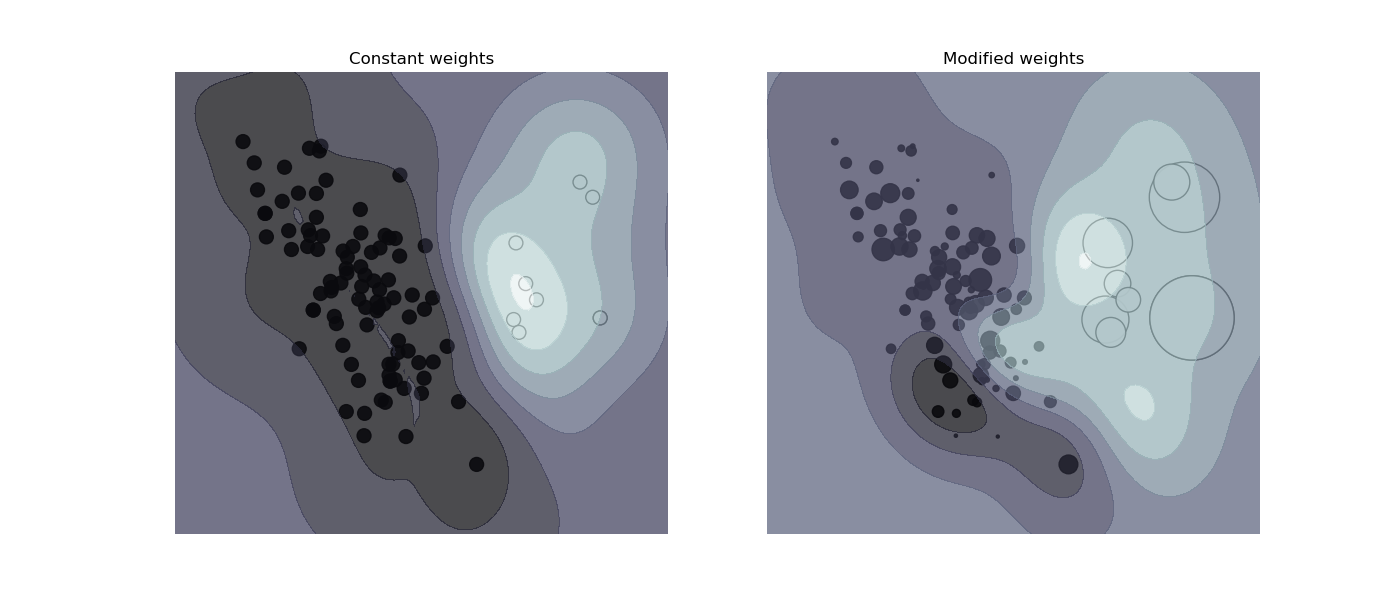
правильно классифицировать эти выборки. На рисунке ниже показано влияние взвешивания
выборок на границу решения. Размер кругов пропорционален
весам выборок:
Примеры
1.4.2. Регрессия#
Метод классификации опорных векторов может быть расширен для решения задач регрессии. Этот метод называется регрессией опорных векторов.
Модель, созданная методом опорных векторов для классификации (как описано выше), зависит только от подмножества обучающих данных, потому что функция стоимости для построения модели не учитывает обучающие точки, лежащие за пределами поля. Аналогично, модель, созданная методом опорных векторов для регрессии, зависит только от подмножества обучающих данных, потому что функция стоимости игнорирует образцы, прогноз которых близок к их целевому значению.
Существует три различные реализации регрессии опорных векторов:
SVR, NuSVR и LinearSVR. LinearSVR
предоставляет более быструю реализацию, чем SVR но рассматривает только линейное ядро, в то время как NuSVR реализует несколько иную формулировку, чем SVR и LinearSVR[callable]: пользовательская функция, которая принимает массив расстояний и возвращает массив той же формы, содержащий веса.
liblinear LinearSVR также регуляризует свободный член, если он учитывается.
Этот эффект, однако, можно уменьшить путем тщательной настройки его
intercept_scaling параметр, который позволяет члену пересечения иметь другое поведение регуляризации по сравнению с другими признаками. Результаты классификации и оценка могут поэтому отличаться от двух других классификаторов. См. Детали реализации для дополнительных деталей.
Как и с классами классификации, метод fit принимает в качестве аргументов векторы X, y, только в этом случае ожидается, что y будет иметь значения с плавающей точкой вместо целочисленных значений:
>>> from sklearn import svm
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> regr = svm.SVR()
>>> regr.fit(X, y)
SVR()
>>> regr.predict([[1, 1]])
array([1.5])
Примеры
1.4.3. Оценка плотности, обнаружение новизны#
Класс OneClassSVM реализует One-Class SVM, который используется в
обнаружении выбросов.
См. Обнаружение новизны и выбросов для описания и использования OneClassSVM.
1.4.4. Сложность#
Методы опорных векторов — это мощные инструменты, но их вычислительные и требования к хранению быстро растут с увеличением количества обучающих векторов. Основой SVM является задача квадратичного программирования (QP), разделяющая опорные векторы от остальных обучающих данных. Решатель QP, используемый libsvm-реализация масштабируется между \(O(n_{features} \times n_{samples}^2)\) и \(O(n_{features} \times n_{samples}^3)\) в зависимости от того, насколько эффективно libsvm кэш используется на практике (зависит от набора данных). Если данные очень разреженные \(n_{features}\) должно быть заменено средним количеством ненулевых признаков в векторе выборки.
Для линейного случая алгоритм, используемый в
LinearSVC с помощью liblinear реализация гораздо более
эффективна, чем его libsvm-основанный SVC аналог и может масштабироваться почти линейно до миллионов образцов и/или признаков.
1.4.5. Советы по практическому использованию#
Избегание копирования данных: Для
SVC,SVR,NuSVCиNuSVR, если данные, передаваемые определенным методам, не являются C-упорядоченными непрерывными и двойной точности, они будут скопированы перед вызовом базовой C-реализации. Вы можете проверить, является ли данный массив numpy C-непрерывным, проверив егоflagsатрибут.Для
LinearSVC(иLogisticRegression) любой ввод, переданный как массив numpy, будет скопирован и преобразован в liblinear внутреннее разреженное представление данных (числа с плавающей запятой двойной точности и индексы int32 ненулевых компонентов). Если вы хотите обучить крупномасштабный линейный классификатор без копирования плотного numpy C-смежного массива двойной точности в качестве входных данных, мы предлагаем использоватьSGDClassifierкласс вместо этого. Целевая функция может быть настроена почти так же, какLinearSVCмодель.Размер кэша ядра: Для
SVC,SVR,NuSVCиNuSVR, размер кэша ядра сильно влияет на время выполнения для больших задач. Если у вас достаточно оперативной памяти, рекомендуется установитьcache_sizeдо более высокого значения, чем значение по умолчанию 200(МБ), например 500(МБ) или 1000(МБ).Установка C:
Cявляется1по умолчанию, и это разумный выбор по умолчанию. Если у вас много зашумленных наблюдений, следует уменьшить его: уменьшение C соответствует большей регуляризации.LinearSVCиLinearSVRменее чувствительны кCкогда он становится большим, и результаты предсказания перестают улучшаться после определенного порога. В то же время, большийCзначения потребуют больше времени для обучения, иногда до 10 раз дольше, как показано в [11].Алгоритмы метода опорных векторов не инвариантны к масштабу, поэтому Настоятельно рекомендуется масштабировать ваши данные. Например, масштабируйте каждый атрибут входного вектора X до [0,1] или [-1,+1], или стандартизируйте его для получения среднего 0 и дисперсии 1. Обратите внимание, что тот же масштабирование должно быть применено к тестовому вектору для получения значимых результатов. Это можно сделать легко, используя
Pipeline:>>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.svm import SVC >>> clf = make_pipeline(StandardScaler(), SVC())
См. раздел Предобработка данных для получения дополнительной информации о масштабировании и нормализации.
Относительно
shrinkingпараметр, цитирование [12]: Мы обнаружили, что если количество итераций велико, то сжатие может сократить время обучения. Однако, если мы слабо решаем задачу оптимизации (например, используя большой допуск остановки), код без использования сжатия может быть намного быстрееПараметр
nuвNuSVC/OneClassSVM/NuSVRприближает долю ошибок обучения и опорных векторов.В
SVC, если данные несбалансированы (например, много положительных и мало отрицательных), установитеclass_weight='balanced'и/или попробуйте разные параметры штрафаC.Случайность базовых реализаций: Базовые реализации
SVCиNuSVCиспользовать генератор случайных чисел только для перемешивания данных для оценки вероятности (когдаprobabilityустановлено вTrue). Эту случайность можно контролировать с помощьюrandom_stateпараметр. Еслиprobabilityустановлено вFalseэти оценщики не являются случайными иrandom_stateне влияет на результаты. БазовыйOneClassSVMреализация похожа на реализацииSVCиNuSVC. Поскольку оценка вероятности не предоставляется дляOneClassSVM, это не случайно.Базовый
LinearSVCреализация использует генератор случайных чисел для выбора признаков при обучении модели с двойным координатным спуском (т.е. когдаdualустановлено вTrue). Поэтому нередко получаются немного разные результаты для одних и тех же входных данных. Если это происходит, попробуйте с меньшимtolпараметр. Эта случайность также может быть контролируема с помощьюrandom_stateпараметр. Когдаdualустановлено вFalseбазовая реализацияLinearSVCне является случайным иrandom_stateне влияет на результаты.Использование L1-штрафа, предоставляемого
LinearSVC(penalty='l1', dual=False)дает разреженное решение, т.е. только подмножество весов признаков отличается от нуля и влияет на функцию решения. УвеличениеCдает более сложную модель (выбирается больше признаков).Cзначение, дающее «нулевую» модель (все веса равны нулю), может быть вычислено с помощьюl1_min_c.
1.4.6. Функции ядра#
The функция ядра может быть одним из следующих:
линейный: \(\langle x, x'\rangle\).
полином: \((\gamma \langle x, x'\rangle + r)^d\), где \(d\) задается параметром
degree, \(r\) bycoef0.rbf: \(\exp(-\gamma \|x-x'\|^2)\), где \(\gamma\) задаётся параметром
gamma, должно быть больше 0.sigmoid \(\tanh(\gamma \langle x,x'\rangle + r)\), где \(r\) задается
coef0.
Различные ядра задаются с помощью kernel параметр:
>>> linear_svc = svm.SVC(kernel='linear')
>>> linear_svc.kernel
'linear'
>>> rbf_svc = svm.SVC(kernel='rbf')
>>> rbf_svc.kernel
'rbf'
Смотрите также Аппроксимация ядра для решения по использованию ядер RBF, которое гораздо быстрее и более масштабируемо.
1.4.6.1. Параметры ядра RBF#
При обучении SVM с Радиальная базисная функция (RBF) ядро, два параметра должны быть учтены: C и gamma. Параметр C, общий для всех ядер SVM, балансирует между ошибочной классификацией обучающих примеров и простотой разделяющей поверхности. Низкое C делает поверхность принятия решений гладкой, в то время как высокое C направлена на корректную классификацию всех обучающих примеров. gamma определяет, насколько сильно влияет один обучающий пример.
Чем больше gamma тем ближе должны быть другие примеры, чтобы быть затронутыми.
Правильный выбор C и gamma критически важен для производительности SVM. Рекомендуется использовать GridSearchCV с
C и gamma экспоненциально разнесены для выбора хороших значений.
Примеры
1.4.6.2. Пользовательские ядра#
Вы можете определить свои собственные ядра, либо задав ядро как функцию Python, либо предварительно вычислив матрицу Грама.
Классификаторы с пользовательскими ядрами ведут себя так же, как и любые другие классификаторы, за исключением того, что:
Поле
support_vectors_теперь пуст, только индексы опорных векторов хранятся вsupport_Ссылка (а не копия) первого аргумента в
fit()метод сохраняется для будущего использования. Если этот массив изменяется между использованиемfit()иpredict()вы получите неожиданные результаты.
Использование функций Python в качестве ядер#
Вы можете использовать свои собственные определённые ядра, передав функцию в
kernel параметр.
Ваше ядро должно принимать в качестве аргументов две матрицы формы
(n_samples_1, n_features), (n_samples_2, n_features)
и возвращает матрицу ядра формы (n_samples_1, n_samples_2).
Следующий код определяет линейное ядро и создает экземпляр классификатора, который будет использовать это ядро:
>>> import numpy as np
>>> from sklearn import svm
>>> def my_kernel(X, Y):
... return np.dot(X, Y.T)
...
>>> clf = svm.SVC(kernel=my_kernel)
Используя матрицу Грама#
Вы можете передавать предварительно вычисленные ядра, используя kernel='precomputed'
опция. Затем вы должны передать матрицу Грама вместо X в fit и
predict методов. Значения ядра между все обучающие векторы и
тестовые векторы должны быть предоставлены:
>>> import numpy as np
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import svm
>>> X, y = make_classification(n_samples=10, random_state=0)
>>> X_train , X_test , y_train, y_test = train_test_split(X, y, random_state=0)
>>> clf = svm.SVC(kernel='precomputed')
>>> # linear kernel computation
>>> gram_train = np.dot(X_train, X_train.T)
>>> clf.fit(gram_train, y_train)
SVC(kernel='precomputed')
>>> # predict on training examples
>>> gram_test = np.dot(X_test, X_train.T)
>>> clf.predict(gram_test)
array([0, 1, 0])
Примеры
1.4.7. Математическая формулировка#
Метод опорных векторов строит гиперплоскость или набор гиперплоскостей в пространстве высокой или бесконечной размерности, которые могут использоваться для классификации, регрессии или других задач. Интуитивно, хорошее разделение достигается гиперплоскостью, имеющей наибольшее расстояние до ближайших точек обучающих данных любого класса (так называемый функциональный зазор), поскольку в целом чем больше зазор, тем меньше ошибка обобщения классификатора. На рисунке ниже показана решающая функция для линейно разделимой задачи, с тремя образцами на границах зазора, называемыми "опорными векторами":
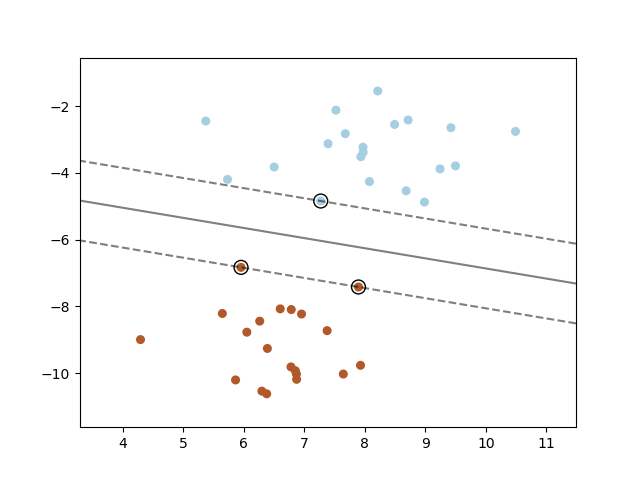
В общем случае, когда задача не является линейно разделимой, опорные векторы представляют собой образцы внутри границы отступа.
Мы рекомендуем [13] и [14] как хорошие справочные материалы по теории и практике SVM.
1.4.7.1. SVC#
Для заданных обучающих векторов \(x_i \in \mathbb{R}^p\), i=1,…, n, в двух классах, и вектор \(y \in \{1, -1\}^n\), наша цель — найти \(w \in \mathbb{R}^p\) и \(b \in \mathbb{R}\) такое, что прогноз, заданный \(\text{sign} (w^T\phi(x) + b)\) верно для большинства образцов.
SVC решает следующую прямую задачу:
Интуитивно, мы пытаемся максимизировать зазор (минимизируя
\(||w||^2 = w^Tw\)), при этом налагая штраф, когда выборка неправильно классифицирована или находится в пределах границы зазора. В идеале значение \(y_i
(w^T \phi (x_i) + b)\) будет \(\geq 1\) для всех выборок, что указывает на идеальный прогноз. Но проблемы обычно не всегда идеально разделимы гиперплоскостью, поэтому мы позволяем некоторым выборкам находиться на расстоянии \(\zeta_i\) от их правильной границы отступа. Штрафной член C контролирует силу этого штрафа и, как следствие, действует как обратный параметр регуляризации (см. примечание ниже).
Двойственная задача к прямой
где \(e\) — это вектор из всех единиц, и \(Q\) является \(n\) by \(n\) полуопределенная положительная матрица, \(Q_{ij} \equiv y_i y_j K(x_i, x_j)\), где \(K(x_i, x_j) = \phi (x_i)^T \phi (x_j)\) является ядром. Термины \(\alpha_i\) называются двойственными коэффициентами и ограничены сверху \(C\). Это двойное представление подчеркивает тот факт, что тренировочные векторы неявно отображаются в пространство более высокой (возможно, бесконечной) размерности функцией \(\phi\): см. ядерный трюк.
После решения задачи оптимизации, выход decision_function для заданного образца \(x\) становится:
и предсказанный класс соответствует его знаку. Нам нужно суммировать только по опорным векторам (т.е. образцам, лежащим внутри границы), потому что двойственные коэффициенты \(\alpha_i\) равны нулю для других образцов.
Эти параметры доступны через атрибуты dual_coef_
который содержит произведение \(y_i \alpha_i\), support_vectors_ который содержит опорные векторы, и intercept_ который содержит независимый
член \(b\).
Примечание
Хотя модели SVM, полученные из libsvm и liblinear использовать C как
параметр регуляризации, большинство других оценщиков используют alpha. Точная эквивалентность между количеством регуляризации двух моделей зависит от точной целевой функции, оптимизируемой моделью. Например, когда используемый оценщик Ridge регрессии,
связь между ними задается как \(C = \frac{1}{\alpha}\).
LinearSVC#
Прямая задача может быть эквивалентно сформулирована как
где мы используем hinge loss. Это форма, которая непосредственно оптимизируется LinearSVC, но в отличие от двойной формы, эта
не включает внутренние произведения между образцами, поэтому знаменитый трюк с ядром
не может быть применен. Вот почему только линейное ядро поддерживается
LinearSVC (\(\phi\) является тождественной функцией).
NuSVC#
The \(\nu\)-SVC формулировка [15] является перепараметризацией \(C\)-SVC и, следовательно, математически эквивалентны.
Мы вводим новый параметр \(\nu\) (вместо \(C\)), который контролирует количество опорных векторов и ошибки отступа: \(\nu \in (0, 1]\) является верхней границей доли ошибок на границе и нижней границей доли опорных векторов. Ошибка на границе соответствует образцу, который лежит на неправильной стороне своей граничной границы: он либо неправильно классифицирован, либо правильно классифицирован, но не лежит за пределами границы.
1.4.7.2. SVR#
Для заданных обучающих векторов \(x_i \in \mathbb{R}^p\), i=1,…, n, и вектор \(y \in \mathbb{R}^n\) \(\varepsilon\)-SVR решает следующую прямую задачу:
Здесь мы штрафуем выборки, предсказание которых составляет не менее \(\varepsilon\) от их истинной цели. Эти образцы штрафуют целевую функцию на \(\zeta_i\) или \(\zeta_i^*\), в зависимости от того, лежат ли их прогнозы выше или ниже \(\varepsilon\) труба.
Двойственная задача —
где \(e\) является вектором из всех единиц, \(Q\) является \(n\) by \(n\) полуопределенная положительная матрица, \(Q_{ij} \equiv K(x_i, x_j) = \phi (x_i)^T \phi (x_j)\) является ядром. Здесь обучающие векторы неявно отображаются в пространство более высокой (возможно, бесконечной) размерности с помощью функции \(\phi\).
Прогноз:
Эти параметры доступны через атрибуты dual_coef_
который содержит разницу \(\alpha_i - \alpha_i^*\), support_vectors_ который содержит опорные векторы, и intercept_ который содержит независимый
член \(b\)
LinearSVR#
Прямая задача может быть эквивалентно сформулирована как
где мы используем эпсилон-нечувствительную потерю, т.е. ошибки менее
\(\varepsilon\) игнорируются. Это форма, которая непосредственно оптимизируется LinearSVR.
1.4.8. Детали реализации#
Внутренне мы используем libsvm [12] и liblinear [11] для обработки всех вычислений. Эти библиотеки обёрнуты с использованием C и Cython. Для описания реализации и деталей используемых алгоритмов, пожалуйста, обратитесь к соответствующим статьям.
Ссылки