3.5. Кривые валидации: построение оценок для оценки моделей#
У каждого оценщика есть свои преимущества и недостатки. Его ошибка обобщения может быть разложена на составляющие смещения, дисперсии и шума. смещение оценщика — это его средняя ошибка для различных обучающих наборов. дисперсия оценщика указывает, насколько он чувствителен к различным обучающим наборам. Шум — это свойство данных.
На следующем графике мы видим функцию \(f(x) = \cos (\frac{3}{2} \pi x)\) и некоторые зашумленные выборки из этой функции. Мы используем три различных оценщика для аппроксимации функции: линейную регрессию с полиномиальными признаками степени 1, 4 и 15. Мы видим, что первый оценщик в лучшем случае может дать лишь плохую аппроксимацию выборок и истинной функции, потому что он слишком прост (высокое смещение), второй оценщик аппроксимирует её почти идеально, а последний оценщик идеально аппроксимирует обучающие данные, но плохо соответствует истинной функции, т.е. он очень чувствителен к изменению обучающих данных (высокая дисперсия).
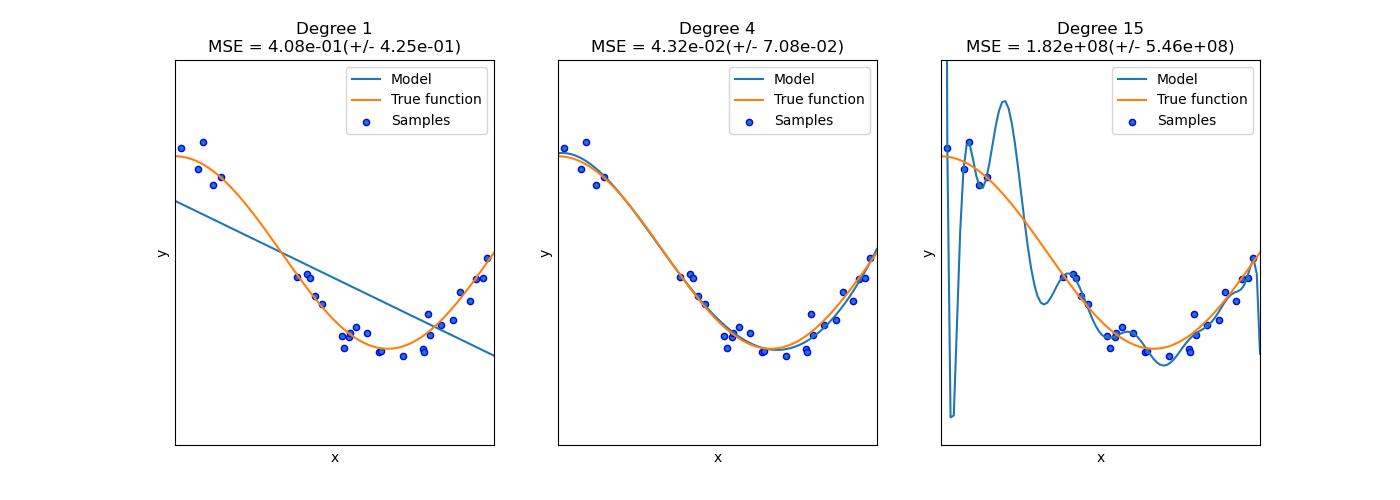
Смещение и дисперсия являются неотъемлемыми свойствами оценщиков, и обычно нам приходится выбирать алгоритмы обучения и гиперпараметры так, чтобы и смещение, и дисперсия были как можно ниже (см. Дилемма смещения-дисперсии). Другой способ уменьшить дисперсию модели — использовать больше обучающих данных. Однако вам следует собирать больше обучающих данных только если истинная функция слишком сложна для аппроксимации оценщиком с меньшей дисперсией.
В простой одномерной задаче, которую мы видели в примере, легко увидеть, страдает ли оценщик от смещения или дисперсии. Однако в многомерных пространствах модели могут стать очень сложными для визуализации. По этой причине часто полезно использовать инструменты, описанные ниже.
Примеры
Влияние регуляризации модели на ошибку обучения и тестирования
Построение кривых обучения и проверка масштабируемости моделей
3.5.1. Кривая валидации#
Для валидации модели необходима функция оценки (см. Метрики и оценка: количественное измерение качества прогнозов), например, точность для классификаторов. Правильный способ выбора нескольких гиперпараметров оценщика, конечно, сеточный поиск или подобные методы (см. Настройка гиперпараметров оценщика) которые выбирают гиперпараметр с максимальной оценкой на валидационном наборе или нескольких валидационных наборах. Обратите внимание, что если мы оптимизируем гиперпараметры на основе валидационной оценки, то валидационная оценка становится смещённой и больше не является хорошей оценкой обобщающей способности. Чтобы получить правильную оценку обобщающей способности, мы должны вычислить оценку на другом тестовом наборе.
Однако иногда полезно построить график влияния одного гиперпараметра на обучающую оценку и валидационную оценку, чтобы выяснить, переобучается или недообучается ли оценщик при некоторых значениях гиперпараметра.
Функция validation_curve может помочь в этом случае:
>>> import numpy as np
>>> from sklearn.model_selection import validation_curve
>>> from sklearn.datasets import load_iris
>>> from sklearn.svm import SVC
>>> np.random.seed(0)
>>> X, y = load_iris(return_X_y=True)
>>> indices = np.arange(y.shape[0])
>>> np.random.shuffle(indices)
>>> X, y = X[indices], y[indices]
>>> train_scores, valid_scores = validation_curve(
... SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 3),
... )
>>> train_scores
array([[0.90, 0.94, 0.91, 0.89, 0.92],
[0.9 , 0.92, 0.93, 0.92, 0.93],
[0.97, 1 , 0.98, 0.97, 0.99]])
>>> valid_scores
array([[0.9, 0.9 , 0.9 , 0.96, 0.9 ],
[0.9, 0.83, 0.96, 0.96, 0.93],
[1. , 0.93, 1 , 1 , 0.9 ]])
Если вы планируете строить только кривые валидации, класс
ValidationCurveDisplay более прямой, чем использование matplotlib вручную на результатах вызова validation_curve.
Вы можете использовать метод
from_estimator аналогично validation_curve для генерации и построения кривой валидации:
from sklearn.datasets import load_iris
from sklearn.model_selection import ValidationCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
ValidationCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 10)
)
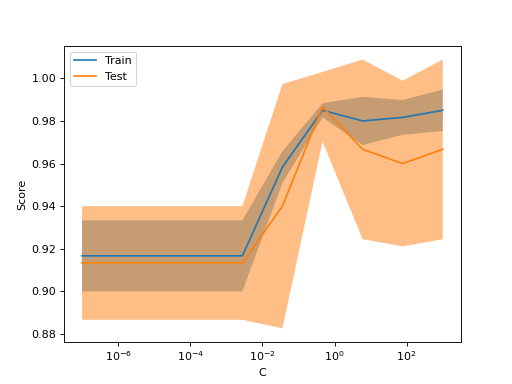
Если оценка обучения и оценка валидации обе низкие, оценщик будет недообучен. Если оценка обучения высокая, а оценка валидации низкая, оценщик переобучен, в противном случае он работает очень хорошо. Низкая оценка обучения и высокая оценка валидации обычно невозможны.
3.5.2. Кривая обучения#
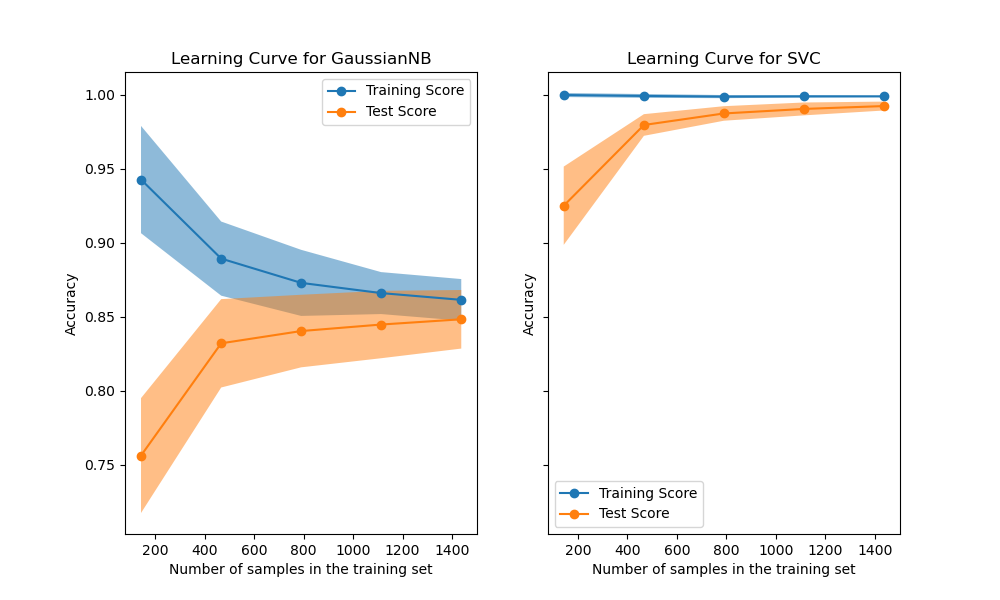
Кривая обучения показывает оценку проверки и обучения для оценщика при различном количестве обучающих выборок. Это инструмент для определения, насколько мы выигрываем от добавления большего количества обучающих данных и страдает ли оценщик больше от ошибки дисперсии или ошибки смещения. Рассмотрим следующий пример, где мы строим кривую обучения наивного байесовского классификатора и SVM.
Для наивного Байеса и валидационная оценка, и оценка обучения сходятся к довольно низкому значению с увеличением размера обучающей выборки. Таким образом, мы, вероятно, не получим большой пользы от дополнительных обучающих данных.
В отличие от этого, для небольших объемов данных оценка обучения SVM намного больше, чем оценка валидации. Добавление большего количества обучающих образцов, скорее всего, увеличит обобщающую способность.
Мы можем использовать функцию learning_curve для генерации значений,
необходимых для построения такой кривой обучения (количество использованных
образцов, средние оценки на обучающих наборах и
средние оценки на валидационных наборах):
>>> from sklearn.model_selection import learning_curve
>>> from sklearn.svm import SVC
>>> train_sizes, train_scores, valid_scores = learning_curve(
... SVC(kernel='linear'), X, y, train_sizes=[50, 80, 110], cv=5)
>>> train_sizes
array([ 50, 80, 110])
>>> train_scores
array([[0.98, 0.98 , 0.98, 0.98, 0.98],
[0.98, 1. , 0.98, 0.98, 0.98],
[0.98, 1. , 0.98, 0.98, 0.99]])
>>> valid_scores
array([[1. , 0.93, 1. , 1. , 0.96],
[1. , 0.96, 1. , 1. , 0.96],
[1. , 0.96, 1. , 1. , 0.96]])
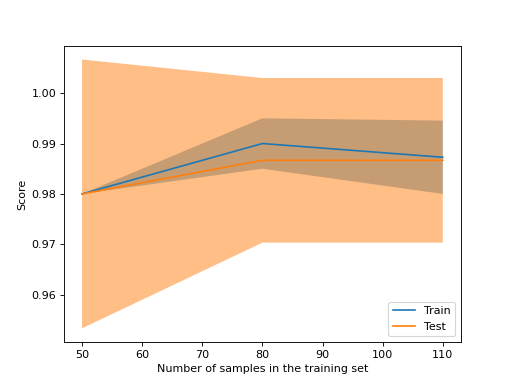
Если вы планируете строить только кривые обучения, класс
LearningCurveDisplay будет проще в использовании.
Вы можете использовать метод
from_estimator аналогично learning_curve для генерации и построения кривой обучения:
from sklearn.datasets import load_iris
from sklearn.model_selection import LearningCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
LearningCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, train_sizes=[50, 80, 110], cv=5)
Примеры
См. Построение кривых обучения и проверка масштабируемости моделей для примера использования кривых обучения для проверки масштабируемости прогнозной модели.