3.2. Настройка гиперпараметров оценщика#
Гиперпараметры — это параметры, которые не изучаются непосредственно в оценщиках. В scikit-learn они передаются как аргументы конструктору классов оценщиков. Типичные примеры включают C, kernel и gamma
для классификатора опорных векторов, alpha для Lasso и т.д.
Возможно и рекомендуется искать в пространстве гиперпараметров лучший кросс-валидация оценка.
Любой параметр, предоставленный при создании оценщика, может быть оптимизирован таким образом. В частности, чтобы найти имена и текущие значения всех параметров для данного оценщика, используйте:
estimator.get_params()
Поиск состоит из:
оценщик (регрессор или классификатор, такой как
sklearn.svm.SVC());пространство параметров;
метод поиска или выборки кандидатов;
схему перекрестной проверки; и
В scikit-learn предоставлены два общих подхода к поиску параметров: для заданных значений, GridSearchCV исчерпывающе рассматривает все комбинации параметров, в то время как RandomizedSearchCV может выбирать заданное число кандидатов из пространства параметров с заданным распределением. Оба этих инструмента имеют аналоги с последовательным уменьшением вдвое
HalvingGridSearchCV и HalvingRandomSearchCV, что может быть значительно быстрее для поиска хорошей комбинации параметров.
После описания этих инструментов мы подробно рассмотрим лучшие практики применимы к этим подходам. Некоторые модели допускают специализированные, эффективные стратегии поиска параметров, описанные в Альтернативы грубому поиску параметров.
Обратите внимание, что часто небольшое подмножество этих параметров может сильно влиять на прогностическую или вычислительную производительность модели, в то время как другие могут быть оставлены со значениями по умолчанию. Рекомендуется прочитать документацию класса оценщика, чтобы лучше понять их ожидаемое поведение, возможно, прочитав приложенную ссылку на литературу.
3.2.1. Исчерпывающий поиск по сетке#
Поиск по сетке, предоставляемый GridSearchCV исчерпывающе генерирует кандидатов из сетки значений параметров, указанной с помощью param_grid
параметр. Например, следующий param_grid:
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
указывает, что следует исследовать две сетки: одну с линейным ядром и значениями C в [1, 10, 100, 1000], и вторую с ядром RBF и декартовым произведением значений C в диапазоне [1, 10, 100, 1000] и значений gamma в [0.001, 0.0001].
The GridSearchCV экземпляр реализует стандартный API оценщика: при
«обучении» на наборе данных оцениваются все возможные комбинации значений параметров и
сохраняется лучшая комбинация.
Примеры
См. Вложенная и невложенная перекрестная проверка для примера Grid Search в цикле перекрестной проверки на наборе данных iris. Это лучшая практика для оценки производительности модели с поиском по сетке.
См. Примерный пайплайн для извлечения и оценки текстовых признаков для примера связывания параметров Grid Search из средства извлечения признаков текстовых документов (векторизатор n-gram count и преобразователь TF-IDF) с классификатором (здесь линейный SVM, обученный с SGD с либо elastic net, либо L2 penalty) с использованием
Pipelineэкземпляр.
Продвинутые примеры#
См. Вложенная и невложенная перекрестная проверка для примера Grid Search в цикле перекрестной проверки на наборе данных iris. Это лучшая практика для оценки производительности модели с поиском по сетке.
См. Демонстрация многометрической оценки на cross_val_score и GridSearchCV для примера
GridSearchCVиспользуется для оценки нескольких метрик одновременно.См. Баланс сложности модели и кросс-валидационной оценки для примера использования
refit=callableинтерфейс вGridSearchCV. Пример показывает, как этот интерфейс добавляет определенную степень гибкости в определении "наилучшего" оценщика. Этот интерфейс также может использоваться при оценке по нескольким метрикам.См. Статистическое сравнение моделей с использованием поиска по сетке для примера того, как выполнить статистическое сравнение выходных данных
GridSearchCV.
3.2.2. Рандомизированная оптимизация параметров#
Хотя использование сетки настроек параметров в настоящее время является наиболее широко используемым
методом оптимизации параметров, другие методы поиска имеют более
благоприятные свойства.
RandomizedSearchCV реализует рандомизированный поиск по параметрам,
где каждая настройка выбирается из распределения по возможным значениям параметров.
Это имеет два основных преимущества перед исчерпывающим поиском:
Бюджет может быть выбран независимо от количества параметров и возможных значений.
Добавление параметров, которые не влияют на производительность, не снижает эффективность.
Указание того, как параметры должны быть сэмплированы, выполняется с помощью словаря, очень
похожего на указание параметров для GridSearchCV. Кроме того, вычислительный бюджет, определяемый как количество отобранных кандидатов или итераций выборки, задается с помощью n_iter параметр.
Для каждого параметра можно указать либо распределение по возможным значениям, либо список
дискретных вариантов (которые будут выбираться равномерно):
{'C': scipy.stats.expon(scale=100), 'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf'], 'class_weight':['balanced', None]}
Этот пример использует scipy.stats модуль, который содержит много полезных
распределений для выборки параметров, таких как expon, gamma,
uniform, loguniform или randint.
В принципе, можно передать любую функцию, которая предоставляет rvs (случайная
выборка) метод для выборки значения. Вызов rvs функция должна предоставлять независимые случайные выборки из возможных значений параметров при последовательных вызовах.
Предупреждение
Распределения в scipy.stats до версии scipy 0.16 не позволяют указывать случайное состояние. Вместо этого они используют глобальное случайное состояние numpy, которое можно инициализировать через np.random.seed или установить
используя np.random.set_state. Однако, начиная с scikit-learn 0.18,
sklearn.model_selection модуль устанавливает случайное состояние, предоставленное
пользователем, если scipy >= 0.16 также доступен.
Для непрерывных параметров, таких как C выше, важно указать
непрерывное распределение, чтобы в полной мере использовать рандомизацию. Таким образом,
увеличивая n_iter всегда приведет к более детальному поиску.
Непрерывная лог-равномерная случайная величина - это непрерывная версия
параметра с логарифмическим шагом. Например, чтобы задать эквивалент C сверху,
loguniform(1, 100) может использоваться вместо [1, 10, 100].
Повторяя пример выше в поиске по сетке, мы можем указать непрерывную случайную величину, которая распределена логарифмически равномерно между 1e0 и 1e3:
from sklearn.utils.fixes import loguniform
{'C': loguniform(1e0, 1e3),
'gamma': loguniform(1e-4, 1e-3),
'kernel': ['rbf'],
'class_weight':['balanced', None]}
Примеры
Сравнение рандомизированного поиска и поиска по сетке для оценки гиперпараметров сравнивает использование и эффективность рандомизированного поиска и поиска по сетке.
Ссылки
Bergstra, J. и Bengio, Y., Случайный поиск для оптимизации гиперпараметров, The Journal of Machine Learning Research (2012)
3.2.3. Поиск оптимальных параметров с последовательным сокращением вдвое#
Scikit-learn также предоставляет HalvingGridSearchCV и
HalvingRandomSearchCV оценщики, которые могут быть использованы для
поиска пространства параметров с использованием последовательного деления пополам [1] [2]. Последовательное
уполовинивание (SH) похоже на турнир среди кандидатов комбинаций параметров.
SH — это итеративный процесс отбора, где все кандидаты (комбинации
параметров) оцениваются с небольшим количеством ресурсов на
первой итерации. Только некоторые из этих кандидатов выбираются для следующей
итерации, которой будет выделено больше ресурсов. Для настройки параметров
ресурсом обычно является количество обучающих выборок, но это также может быть
произвольный числовой параметр, такой как n_estimators в случайном лесу.
Примечание
Увеличение ресурсов должно быть достаточно большим, чтобы получить значительное улучшение показателей с учетом статистической значимости.
Как показано на рисунке ниже, только подмножество кандидатов 'выживает' до последней итерации. Это кандидаты, которые последовательно занимали места среди лучших по оценкам во всех итерациях. Каждой итерации выделяется увеличивающееся количество ресурсов на кандидата, здесь - количество образцов.
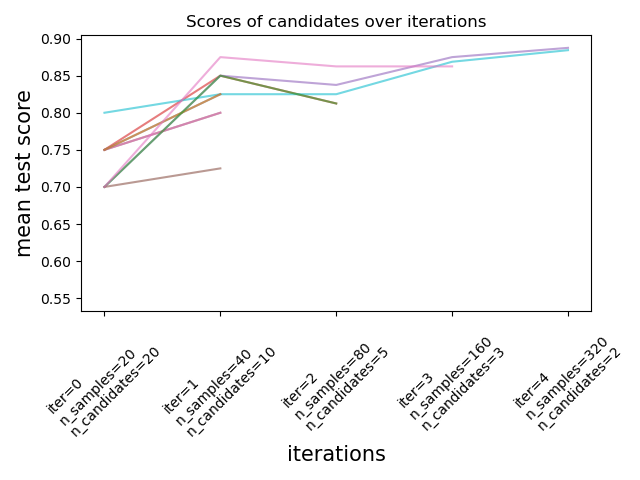
Здесь мы кратко описываем основные параметры, но каждый параметр и их взаимодействия описаны более подробно в раскрывающемся разделе ниже.
factor (> 1) параметр контролирует скорость роста ресурсов и скорость уменьшения количества кандидатов. На каждой итерации количество ресурсов на кандидата умножается на factor и количество кандидатов делится на тот же коэффициент. Вместе с resource и
min_resources, factor является наиболее важным параметром для управления
поиском в нашей реализации, хотя значение 3 обычно работает хорошо.
factor эффективно контролирует количество итераций в
HalvingGridSearchCV и количество кандидатов (по умолчанию) и итераций в HalvingRandomSearchCV. aggressive_elimination=True
также может использоваться, если количество доступных ресурсов мало. Больше контроля доступно через настройку min_resources параметр.
Эти оценщики всё ещё экспериментальный: их предсказания
и их API могут измениться без цикла устаревания. Для их использования
нужно явно импортировать enable_halving_search_cv:
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> from sklearn.model_selection import HalvingRandomSearchCV
Примеры
В следующих разделах рассматриваются технические аспекты последовательного деления пополам.
Выбор min_resources и количество кандидатов#
Помимо factor, два основных параметра, влияющих на поведение поиска с последовательным сокращением, это min_resources параметр, и
количество кандидатов (или комбинаций параметров), которые оцениваются.
min_resources это количество ресурсов, выделенных на первой
итерации для каждого кандидата. Количество кандидатов указывается непосредственно
в HalvingRandomSearchCV, и определяется из param_grid
параметр HalvingGridSearchCV.
Рассмотрим случай, когда ресурсом является количество образцов, и у нас есть 1000 образцов. Теоретически, с min_resources=10 и factor=2, мы можем запустить не более 7 итераций со следующим количеством
образцов: [10, 20, 40, 80, 160, 320, 640].
Но в зависимости от количества кандидатов мы можем выполнить менее 7 итераций: если мы начнем с маленький количество кандидатов, последняя итерация может использовать менее 640 выборок, что означает неиспользование всех доступных ресурсов (выборок). Например, если мы начнём с 5 кандидатов, нам нужны только 2 итерации: 5 кандидатов для первой итерации, затем
5 // 2 = 2 кандидатов на второй итерации, после которой мы знаем, какой
кандидат работает лучше всего (поэтому нам не нужен третий). Мы бы использовали
максимум 20 образцов, что является расточительством, поскольку у нас есть 1000 образцов в нашем
распоряжении. С другой стороны, если мы начнем с высокий количество
кандидатов, мы можем получить много кандидатов на последней итерации,
что не всегда идеально: это означает, что многие кандидаты будут запущены с
полными ресурсами, фактически сводя процедуру к стандартному поиску.
В случае HalvingRandomSearchCV, количество кандидатов устанавливается по умолчанию так, чтобы последняя итерация использовала как можно больше доступных ресурсов. Для HalvingGridSearchCV, пока обучение продолжает уменьшать потери. Каждый раз, когда n_iter_no_change последовательных эпох не уменьшают потери обучения на tol или не увеличивают валидационную оценку на tol, если param_grid параметр. Изменение значения
min_resources повлияет на количество возможных итераций и, как следствие, также повлияет на оптимальное количество кандидатов.
Ещё одно соображение при выборе min_resources заключается в том, легко ли различать хороших и плохих кандидатов с небольшим количеством ресурсов. Например, если вам нужно много выборок, чтобы различить хорошие и плохие параметры, высокий min_resources рекомендуется. С другой стороны, если различие ясно даже при небольшом количестве
образцов, то небольшой min_resources может быть предпочтительнее, поскольку это ускорит вычисления.
Обратите внимание в примере выше, что последняя итерация не использует максимальное количество доступных ресурсов: доступно 1000 образцов, но используется максимум 640. По умолчанию, как HalvingRandomSearchCV и
HalvingGridSearchCV попытаться использовать как можно больше ресурсов на последней итерации с ограничением, что это количество ресурсов должно быть кратно обоим min_resources и factor (это ограничение станет ясно в следующем разделе). HalvingRandomSearchCV достигает этого путем выборки нужного количества кандидатов, в то время как HalvingGridSearchCV
достигает этого путем правильной настройки min_resources.
Количество ресурсов и число кандидатов на каждой итерации#
На любой итерации i, каждому кандидату выделяется заданное количество ресурсов, которое мы обозначаем n_resources_i. Эта величина контролируется
параметрами factor и min_resources следующим образом (factor строго больше 1):
n_resources_i = factor**i * min_resources,
или эквивалентно:
n_resources_{i+1} = n_resources_i * factor
где min_resources == n_resources_0 это количество ресурсов, использованных на
первой итерации. factor также определяет пропорции кандидатов, которые будут выбраны для следующей итерации:
n_candidates_i = n_candidates // (factor ** i)
или эквивалентно:
n_candidates_0 = n_candidates
n_candidates_{i+1} = n_candidates_i // factor
Таким образом, на первой итерации мы используем min_resources ресурсы
n_candidates раз. Во второй итерации мы используем min_resources *
factor ресурсы n_candidates // factor раз. Третий снова умножает ресурсы на кандидата и делит количество кандидатов.
Этот процесс останавливается, когда достигается максимальное количество ресурсов на кандидата или когда мы определили лучшего кандидата. Лучший кандидат определяется на итерации, которая оценивает factor или меньше кандидатов
(объяснение приведено ниже).
Вот пример с min_resources=3 и factor=2, начиная с 70 кандидатов:
|
|
|---|---|
3 (=min_resources) |
70 (=n_candidates) |
3 * 2 = 6 |
70 // 2 = 35 |
6 * 2 = 12 |
35 // 2 = 17 |
12 * 2 = 24 |
17 // 2 = 8 |
24 * 2 = 48 |
8 // 2 = 4 |
48 * 2 = 96 |
4 // 2 = 2 |
Мы можем отметить, что:
процесс останавливается на первой итерации, которая оценивает
factor=2кандидаты: лучший кандидат - лучший из этих 2 кандидатов. Не нужно запускать дополнительную итерацию, так как она будет оценивать только одного кандидата (а именно лучшего, которого мы уже определили). По этой причине, в общем случае, мы хотим, чтобы последняя итерация выполняла не болееfactorкандидатов. Если последняя итерация оценивает болееfactorкандидатов, то эта последняя итерация сводится к обычному поиску (как вRandomizedSearchCVилиGridSearchCV).каждый
n_resources_iявляется кратным обоимfactorиmin_resources(что подтверждается его определением выше).
Количество ресурсов, используемых на каждой итерации, можно найти в
n_resources_ атрибут.
Выбор ресурса#
По умолчанию ресурс определяется в терминах количества образцов. То есть каждая итерация будет использовать увеличивающееся количество образцов для обучения. Однако вы можете вручную указать параметр для использования в качестве ресурса с помощью
resource параметр. Вот пример, где ресурс определён в
терминах количества оценщиков случайного леса:
>>> from sklearn.datasets import make_classification
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid = {'max_depth': [3, 5, 10],
... 'min_samples_split': [2, 5, 10]}
>>> base_estimator = RandomForestClassifier(random_state=0)
>>> X, y = make_classification(n_samples=1000, random_state=0)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, resource='n_estimators',
... max_resources=30).fit(X, y)
>>> sh.best_estimator_
RandomForestClassifier(max_depth=5, n_estimators=24, random_state=0)
Обратите внимание, что невозможно установить бюджет на параметр, который является частью сетки параметров.
Многомерное шкалирование#
Как упоминалось выше, количество ресурсов, используемых на каждой итерации, зависит от min_resources параметр.
Если у вас много доступных ресурсов, но вы начинаете с небольшого их количества, некоторые из них могут быть потрачены впустую (т.е. не использованы):
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid= {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources=20).fit(X, y)
>>> sh.n_resources_
[20, 40, 80]
Процесс поиска будет использовать не более 80 ресурсов, в то время как наше максимальное количество доступных ресурсов составляет n_samples=1000. Здесь у нас есть
min_resources = r_0 = 20.
Для HalvingGridSearchCV, по умолчанию, min_resources параметр
установлен в 'exhaust'. Это означает, что min_resources автоматически устанавливается
так, чтобы последняя итерация могла использовать как можно больше ресурсов, в пределах max_resources предел:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources='exhaust').fit(X, y)
>>> sh.n_resources_
[250, 500, 1000]
min_resources был автоматически установлен в 250, что приводит к использованию всех ресурсов на последней итерации. Точное значение зависит от количества кандидатных параметров, от max_resources и на factor.
Для HalvingRandomSearchCVисчерпание ресурсов может быть выполнено двумя способами:
установкой
min_resources='exhaust', так же как дляHalvingGridSearchCV;установкой
n_candidates='exhaust'.
Оба варианта взаимоисключающие: использование min_resources='exhaust' требует знания количества кандидатов, и симметрично n_candidates='exhaust'
требует знания min_resources.
В целом, исчерпание общего количества ресурсов приводит к лучшему конечному кандидату параметра и является немного более затратным по времени.
3.2.3.1. Агрессивное исключение кандидатов#
Используя aggressive_elimination параметр, вы можете принудительно завершить
процесс поиска с менее чем factor кандидатов на последней
итерации.
Пример кода агрессивного исключения#
В идеале мы хотим, чтобы последняя итерация оценивала factor кандидатов. Затем нам просто нужно выбрать лучшего. Когда количество доступных ресурсов мало по сравнению с количеством кандидатов, последняя итерация может потребовать оценки более чем factor кандидаты:
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid = {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, max_resources=40,
... aggressive_elimination=False).fit(X, y)
>>> sh.n_resources_
[20, 40]
>>> sh.n_candidates_
[6, 3]
Поскольку мы не можем использовать более чем max_resources=40 ресурсов, процесс должен остановиться на второй итерации, которая оценивает более factor=2
кандидаты.
При использовании aggressive_elimination, процесс исключит столько
кандидатов, сколько необходимо, используя min_resources ресурсы:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2,
... max_resources=40,
... aggressive_elimination=True,
... ).fit(X, y)
>>> sh.n_resources_
[20, 20, 40]
>>> sh.n_candidates_
[6, 3, 2]
Обратите внимание, что мы заканчиваем с 2 кандидатами на последней итерации, так как мы
исключили достаточно кандидатов во время первых итераций, используя n_resources =
min_resources = 20.
3.2.3.2. Анализ результатов с помощью cv_results_ атрибут#
The cv_results_ атрибут содержит полезную информацию для анализа
результатов поиска. Его можно преобразовать в pandas dataframe с помощью df =
pd.DataFrame(est.cv_results_). cv_results_ атрибут
HalvingGridSearchCV и HalvingRandomSearchCV похож
на GridSearchCV и RandomizedSearchCVс
дополнительной информацией, связанной с процессом последовательного деления пополам.
Пример (усеченного) выходного датафрейма:#
iter |
n_resources |
mean_test_score |
params |
|
|---|---|---|---|---|
0 |
0 |
125 |
0.983667 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 9, ‘min_samples_split’: 5} |
1 |
0 |
125 |
0.983667 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 8, ‘min_samples_split’: 7} |
2 |
0 |
125 |
0.983667 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 10} |
3 |
0 |
125 |
0.983667 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 6, ‘min_samples_split’: 6} |
… |
… |
… |
… |
… |
15 |
2 |
500 |
0.951958 |
{'criterion': 'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10} |
16 |
2 |
500 |
0.947958 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 10} |
17 |
2 |
500 |
0.951958 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 4} |
18 |
3 |
1000 |
0.961009 |
{'criterion': 'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10} |
19 |
3 |
1000 |
0.955989 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 4} |
Каждая строка соответствует заданной комбинации параметров (кандидату) и заданной итерации. Итерация задается iter столбец. The n_resources
столбец показывает, сколько ресурсов было использовано.
В приведенном выше примере наилучшая комбинация параметров {'criterion':
'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10}
поскольку достигнута последняя итерация (3) с наивысшим показателем: 0.96.
Ссылки
3.2.4. Советы по поиску параметров#
3.2.4.1. Задание целевой метрики#
По умолчанию поиск параметров использует score функции оценщика для оценки настройки параметров. Это
sklearn.metrics.accuracy_score для классификации и
sklearn.metrics.r2_score для регрессии. Для некоторых приложений другие
функции оценки лучше подходят (например, в несбалансированной классификации,
оценка точности часто неинформативна), см. Какую функцию оценки мне следует использовать?
для некоторых рекомендаций. Альтернативная функция оценки может быть указана через
scoring параметр большинства инструментов поиска параметров, см.
Параметр scoring: определение правил оценки модели для получения дополнительной информации.
3.2.4.2. Указание нескольких метрик для оценки#
GridSearchCV и RandomizedSearchCV позволяет указать несколько метрик для scoring параметр.
Многометрическая оценка может быть указана либо как список строк с предопределёнными именами оценок, либо как словарь, сопоставляющий имя оценщика с функцией оценщика и/или предопределённым именем оценщика. См. Использование оценки по нескольким метрикам для получения дополнительной информации.
При указании нескольких метрик refit параметр должен быть установлен в метрику (строку), для которой best_params_ будет найден и использован для построения best_estimator_ на всем наборе данных. Если поиск не должен быть переобучен, установите refit=False. Оставляя refit значением по умолчанию None приведёт
к ошибке при использовании нескольких метрик.
См. Демонстрация многометрической оценки на cross_val_score и GridSearchCV для примера использования.
HalvingRandomSearchCV и HalvingGridSearchCV не поддерживают
многомерное оценивание.
3.2.4.3. Композитные оценщики и пространства параметров#
GridSearchCV и RandomizedSearchCV позволяет выполнять поиск по
параметрам составных или вложенных оценщиков, таких как
Pipeline,
ColumnTransformer,
VotingClassifier или
CalibratedClassifierCV используя специальный
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.calibration import CalibratedClassifierCV
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_moons
>>> X, y = make_moons()
>>> calibrated_forest = CalibratedClassifierCV(
... estimator=RandomForestClassifier(n_estimators=10))
>>> param_grid = {
... 'estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(calibrated_forest, param_grid, cv=5)
>>> search.fit(X, y)
GridSearchCV(cv=5,
estimator=CalibratedClassifierCV(estimator=RandomForestClassifier(n_estimators=10)),
param_grid={'estimator__max_depth': [2, 4, 6, 8]})
Здесь, estimator.
Если мета-оценщик построен как коллекция оценщиков, как в
pipeline.Pipeline, затем
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.feature_selection import SelectKBest
>>> pipe = Pipeline([
... ('select', SelectKBest()),
... ('model', calibrated_forest)])
>>> param_grid = {
... 'select__k': [1, 2],
... 'model__estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(pipe, param_grid, cv=5).fit(X, y)
Пожалуйста, обратитесь к Конвейер: объединение оценщиков для выполнения поиска параметров по конвейерам.
3.2.4.4. Выбор модели: разработка и оценка#
Выбор модели путём оценки различных настроек параметров можно рассматривать как способ использования размеченных данных для «обучения» параметров сетки.
При оценке полученной модели важно делать это на удержанных выборках, которые не были видны во время процесса поиска по сетке: рекомендуется разделить данные на развивающий набор (чтобы передать в GridSearchCV экземпляра) и оценочный набор
для вычисления метрик производительности.
Это можно сделать с помощью train_test_split
функция полезности.
3.2.4.5. Параллелизм#
Инструменты поиска параметров оценивают каждую комбинацию параметров на каждом сгибе данных независимо. Вычисления могут выполняться параллельно с использованием ключевого слова
n_jobs=-1. См. сигнатуру функции для подробностей, а также запись в Глоссарии
для n_jobs.
3.2.4.6. Robustness to failure#
Некоторые настройки параметров могут привести к невозможности fit одной или нескольких частей данных. По умолчанию оценка для этих настроек будет np.nan. Это можно
контролировать, установив error_score="raise" вызывать исключение, если одно обучение не удалось, или, например, error_score=0 для установки другого значения балла для неудачных комбинаций параметров.
3.2.5. Альтернативы грубому поиску параметров#
3.2.5.1. Перекрестная проверка, специфичная для модели#
Некоторые модели могут обучаться на данных для диапазона значений некоторого параметра почти так же эффективно, как обучение оценщика для одного значения параметра. Эту возможность можно использовать для выполнения более эффективной кросс-валидации, применяемой для выбора модели по этому параметру.
Наиболее распространённый параметр, поддающийся этой стратегии, — это параметр, кодирующий силу регуляризатора. В этом случае мы говорим, что вычисляем регуляризационный путь оценщика.
Вот список таких моделей:
|
Модель Elastic Net с итеративной подгонкой вдоль пути регуляризации. |
|
Кросс-валидированная модель регрессии наименьшего угла. |
|
Лассо линейная модель с итеративной подгонкой вдоль пути регуляризации. |
|
Лассо с кросс-валидацией, использующий алгоритм LARS. |
|
Логистическая регрессия CV (также известная как logit, MaxEnt) классификатор. |
|
Многозадачный L1/L2 ElasticNet со встроенной кросс-валидацией. |
|
Многозадачная модель Lasso, обученная с регуляризацией смешанной нормы L1/L2. |
Кросс-валидированная модель Orthogonal Matching Pursuit (OMP). |
|
|
Ридж-регрессия со встроенной кросс-валидацией. |
|
Ридж-классификатор со встроенной перекрестной проверкой. |
3.2.5.2. Информационный критерий#
Некоторые модели могут предложить информационно-теоретическую замкнутую формулу оптимальной оценки параметра регуляризации путем вычисления одного пути регуляризации (вместо нескольких при использовании перекрестной проверки).
Вот список моделей, использующих Информационный Критерий Акаике (AIC) или Байесовский Информационный Критерий (BIC) для автоматического выбора модели:
|
Модель Lasso, обученная с помощью Lars с использованием BIC или AIC для выбора модели. |
3.2.5.3. Оценки Out of Bag#
При использовании ансамблевых методов, основанных на бэггинге, т.е. генерации новых обучающих наборов с использованием выборки с возвращением, часть обучающего набора остается неиспользованной. Для каждого классификатора в ансамбле, разная часть обучающего набора исключается.
Эта оставленная часть может быть использована для оценки ошибки обобщения без необходимости полагаться на отдельный валидационный набор. Эта оценка получается «бесплатно», так как не требуются дополнительные данные, и может быть использована для выбора модели.
В настоящее время это реализовано в следующих классах:
Классификатор случайного леса. |
|
Регрессор случайного леса. |
|
Классификатор extra-trees. |
|
|
Экстра-деревья регрессор. |
|
Градиентный бустинг для классификации. |
|
Градиентный бустинг для регрессии. |