2.7. Обнаружение новизны и выбросов#
Многие приложения требуют возможности определить, принадлежит ли новое наблюдение тому же распределению, что и существующие наблюдения (это выброс), или должны рассматриваться как разные (это выброс). Часто эта возможность используется для очистки реальных наборов данных. Необходимо сделать два важных различия:
- обнаружение выбросов:
Обучающие данные содержат выбросы, которые определяются как наблюдения, далёкие от других. Оценщики обнаружения выбросов пытаются подогнать области, где обучающие данные наиболее сконцентрированы, игнорируя отклоняющиеся наблюдения.
- обнаружение новизны:
Обучающие данные не загрязнены выбросами, и мы заинтересованы в обнаружении, является ли новый наблюдение является выбросом. В этом контексте выброс также называется новизной.
Обнаружение выбросов и обнаружение новизны используются для обнаружения аномалий, где интерес представляет обнаружение ненормальных или необычных наблюдений. Обнаружение выбросов также известно как неконтролируемое обнаружение аномалий, а обнаружение новизны — как частично контролируемое обнаружение аномалий. В контексте обнаружения выбросов, выбросы/аномалии не могут образовывать плотный кластер, так как доступные оценщики предполагают, что выбросы/аномалии находятся в областях с низкой плотностью. Напротив, в контексте обнаружения новизны, новизны/аномалии могут образовывать плотный кластер, если они находятся в области с низкой плотностью обучающих данных, считающихся нормальными в этом контексте.
Проект scikit-learn предоставляет набор инструментов машинного обучения, которые могут использоваться как для обнаружения новизны, так и для выбросов. Эта стратегия реализована с объектами, обучающимися на данных неконтролируемым способом:
estimator.fit(X_train)
новые наблюдения затем могут быть отсортированы как нормальные или выбросы с помощью
predict method:
estimator.predict(X_test)
Выбросы помечены как -1, а нормальные точки — как 1. Метод predict
использует порог для исходной функции оценки, вычисленной
оценщиком. Эта функция оценки доступна через score_samples
метод, в то время как порог может контролироваться contamination
параметр.
The decision_function метод также определяется из функции оценки,
таким образом, что отрицательные значения являются выбросами, а неотрицательные —
внутренними точками:
estimator.decision_function(X_test)
Обратите внимание, что neighbors.LocalOutlierFactor не поддерживает
predict, decision_function и score_samples методы по умолчанию, но только fit_predict метод, так как этот оценщик изначально предназначался для обнаружения выбросов. Оценки аномальности обучающих выборок доступны через negative_outlier_factor_ атрибут.
Если вы действительно хотите использовать neighbors.LocalOutlierFactor для обнаружения новизны, т.е. предсказания меток или вычисления оценки аномальности новых невидимых данных, вы можете создать экземпляр оценщика с novelty параметр
установлен в True перед обучением оценщика. В этом случае, fit_predict недоступен.
Предупреждение
Обнаружение новизны с Local Outlier Factor
Когда novelty установлено в True будьте внимательны, что вы должны использовать только
predict, decision_function и score_samples на новых, невидимых данных, а не на обучающих выборках, так как это приведет к неверным результатам. Т.е., результат predict не будет таким же, как fit_predict.
Оценки аномальности обучающих выборок всегда доступны через negative_outlier_factor_ атрибут.
Поведение neighbors.LocalOutlierFactor обобщен в
следующей таблице.
Метод |
Обнаружение выбросов |
Обнаружение новизны |
|---|---|---|
|
OK |
Недоступно |
|
Недоступно |
Используйте только на новых данных |
|
Недоступно |
Используйте только на новых данных |
|
Используйте |
Используйте только на новых данных |
|
OK |
OK |
2.7.1. Обзор методов обнаружения выбросов#
Сравнение алгоритмов обнаружения выбросов в scikit-learn. Local Outlier Factor (LOF) не показывает границу решения черным цветом, так как у него нет метода predict для применения к новым данным при использовании для обнаружения выбросов.
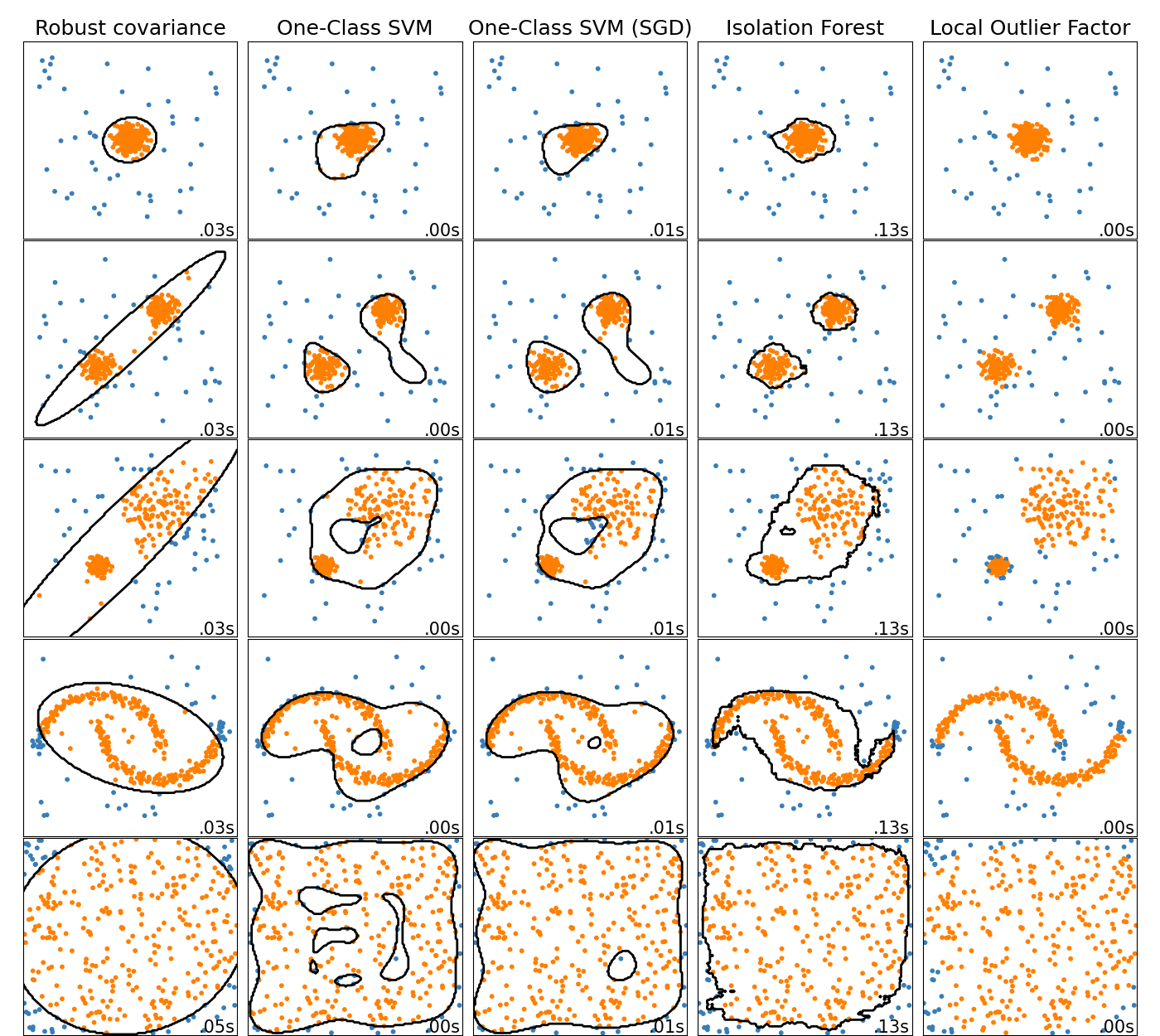
ensemble.IsolationForest и neighbors.LocalOutlierFactor
показывают достаточно хорошие результаты на рассматриваемых наборах данных.
svm.OneClassSVM известен своей чувствительностью к выбросам и поэтому не очень хорошо подходит для обнаружения аномалий. Тем не менее, обнаружение аномалий в высоких размерностях или без каких-либо предположений о распределении нормальных данных является очень сложной задачей. svm.OneClassSVM все еще может использоваться для обнаружения выбросов, но требует тонкой настройки его гиперпараметра
nu для обработки выбросов и предотвращения переобучения.
linear_model.SGDOneClassSVM предоставляет реализацию
линейного One-Class SVM с линейной сложностью по количеству образцов. Эта реализация здесь используется с техникой аппроксимации ядра для получения результатов, аналогичных svm.OneClassSVM который использует гауссово ядро по умолчанию. Наконец, covariance.EllipticEnvelope предполагает, что данные распределены по Гауссу и изучает эллипс. Для более подробной информации о различных оценщиках обратитесь к примеру
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных и
разделы ниже.
Примеры
См. Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных для сравнения
svm.OneClassSVM,ensemble.IsolationForest,neighbors.LocalOutlierFactorиcovariance.EllipticEnvelope.См. Оценка оценщиков обнаружения выбросов для примера, показывающего, как оценивать методы обнаружения выбросов,
neighbors.LocalOutlierFactorиensemble.IsolationForest, используя ROC-кривые изmetrics.RocCurveDisplay.
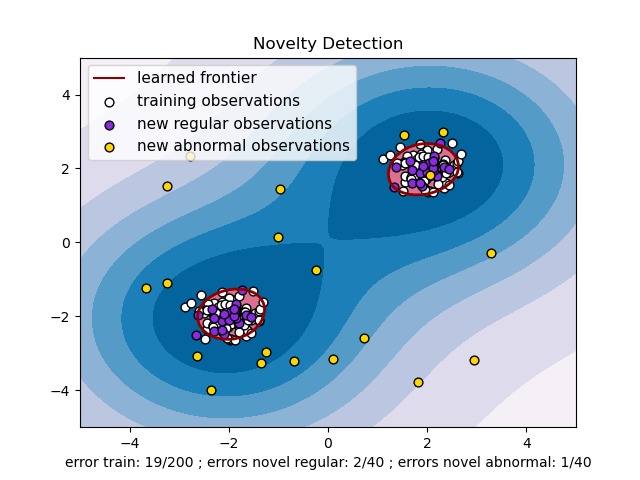
2.7.2. Обнаружение новизны#
Рассмотрим набор данных из \(n\) наблюдения из того же распределения, описываемого \(p\) признаков. Теперь представьте, что мы добавляем еще одно наблюдение в этот набор данных. Настолько ли новое наблюдение отличается от других, что мы можем сомневаться в его регулярности? (т.е. происходит ли оно из того же распределения?) Или, наоборот, настолько ли оно похоже на другие, что мы не можем отличить его от исходных наблюдений? Это вопрос, который решают инструменты и методы обнаружения новизны.
В общем, речь идет об изучении грубой, близкой границы, разграничивающей контур начального распределения наблюдений, построенного во встраивании \(p\)-мерного пространства. Затем, если дальнейшие наблюдения лежат внутри подпространства, ограниченного границей, они считаются принадлежащими той же совокупности, что и исходные наблюдения. В противном случае, если они лежат за пределами границы, можно сказать, что они являются аномальными с заданной уверенностью в нашей оценке.
One-Class SVM был представлен Schölkopf et al. для этой цели и реализован в Метод опорных векторов модуль в
svm.OneClassSVM объект. Он требует выбора ядра и скалярного параметра для определения границы. Обычно выбирается ядро RBF, хотя не существует точной формулы или алгоритма для установки его параметра ширины полосы. Это значение по умолчанию в реализации scikit-learn. nu параметр, также известный как запас One-Class SVM, соответствует вероятности обнаружения нового, но регулярного наблюдения за пределами границы.
Ссылки
Оценка поддержки многомерного распределения Шёлкхоф, Бернхард и др. Neural computation 13.7 (2001): 1443-1471.
Примеры
См. Одноклассовый SVM с нелинейным ядром (RBF) для визуализации границы, изученной вокруг некоторых данных с помощью
svm.OneClassSVMобъект.
2.7.2.1. Масштабирование One-Class SVM#
Онлайн-линейная версия One-Class SVM реализована в
linear_model.SGDOneClassSVM. Эта реализация масштабируется линейно с
количеством образцов и может использоваться с аппроксимацией ядра для
приближённого решения ядризованной svm.OneClassSVM сложность которого в лучшем случае квадратична относительно количества образцов. См. раздел
Онлайн One-Class SVM для получения дополнительной информации.
Примеры
См. One-Class SVM против One-Class SVM с использованием стохастического градиентного спуска для иллюстрации аппроксимации ядерного One-Class SVM с помощью
linear_model.SGDOneClassSVMв сочетании с аппроксимацией ядра.
2.7.3. Обнаружение выбросов#
Обнаружение выбросов похоже на обнаружение новизны в том смысле, что цель состоит в разделении ядра регулярных наблюдений от некоторых загрязняющих, называемых выбросы. Однако в случае обнаружения выбросов у нас нет чистого набора данных, представляющего популяцию регулярных наблюдений, который можно использовать для обучения любого инструмента.
2.7.3.1. Обучение эллиптической оболочки#
Один из распространенных способов обнаружения выбросов заключается в предположении, что обычные данные следуют известному распределению (например, распределены по Гауссу). Исходя из этого предположения, мы обычно пытаемся определить "форму" данных и можем определить выбросы как наблюдения, которые находятся достаточно далеко от подобранной формы.
Scikit-learn предоставляет объект
covariance.EllipticEnvelope который подгоняет робастную оценку ковариации к данным и, таким образом, подгоняет эллипс к центральным точкам данных, игнорируя точки вне центрального режима.
Например, предполагая, что данные выбросов распределены по Гауссу, он оценит местоположение и ковариацию выбросов устойчивым способом (т.е. без влияния аномалий). Расстояния Махаланобиса, полученные из этой оценки, используются для выведения меры аномальности. Эта стратегия проиллюстрирована ниже.
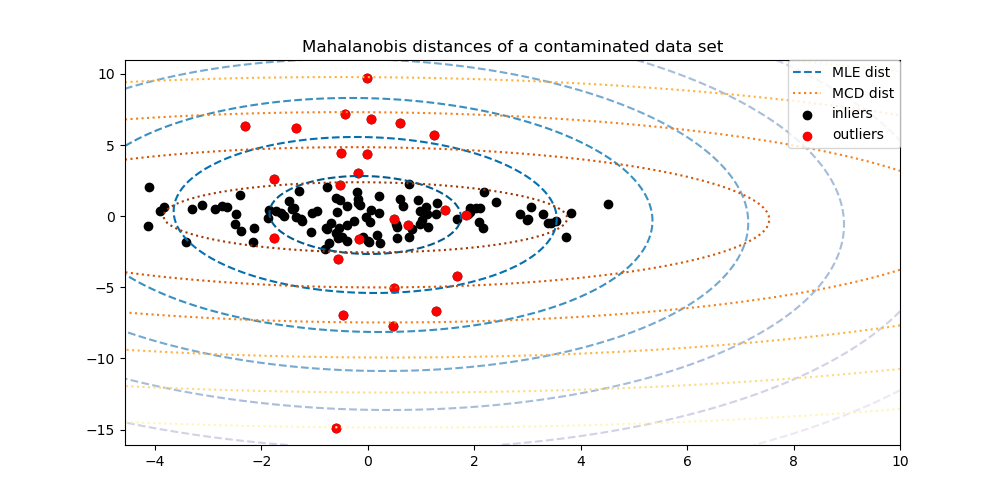
Примеры
См. Робастная оценка ковариации и релевантность расстояний Махаланобиса для иллюстрации разницы между использованием стандартного
covariance.EmpiricalCovariance) или надежная оценка (covariance.MinCovDet) местоположения и ковариации для оценки степени выбросов наблюдения.См. Обнаружение выбросов на реальном наборе данных для примера оценки устойчивой ковариации на реальном наборе данных.
Ссылки
Rousseeuw, P.J., Van Driessen, K. “A fast algorithm for the minimum covariance determinant estimator” Technometrics 41(3), 212 (1999)
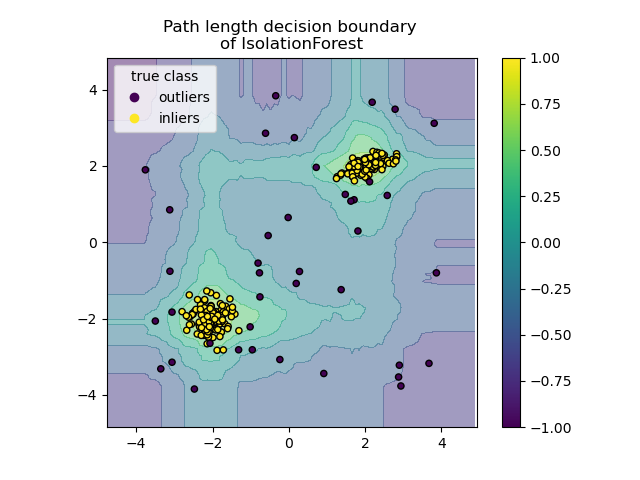
2.7.3.2. Isolation Forest#
Один эффективный способ обнаружения выбросов в многомерных наборах данных
— использование случайных лесов.
ensemble.IsolationForest ‘изолирует’ наблюдения путем случайного выбора
признака, а затем случайного выбора значения разделения между максимальным и
минимальным значениями выбранного признака.
Поскольку рекурсивное разбиение может быть представлено древовидной структурой, количество разделений, необходимых для изоляции образца, эквивалентно длине пути от корневого узла до конечного узла.
Эта длина пути, усредненная по лесу таких случайных деревьев, является мерой нормальности и нашей функцией принятия решений.
Случайное разбиение создает заметно более короткие пути для аномалий. Следовательно, когда лес случайных деревьев коллективно создает более короткие длины путей для определенных образцов, они с высокой вероятностью являются аномалиями.
Реализация ensemble.IsolationForest основан на ансамбле tree.ExtraTreeRegressor. Согласно оригинальной статье Isolation Forest,
максимальная глубина каждого дерева установлена в \(\lceil \log_2(n) \rceil\) где
\(n\) это количество образцов, использованных для построения дерева (см. [1]
для получения дополнительных деталей).
Этот алгоритм проиллюстрирован ниже.
The ensemble.IsolationForest поддерживает warm_start=True который
позволяет добавлять больше деревьев к уже обученной модели:
>>> from sklearn.ensemble import IsolationForest
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [0, 0], [-20, 50], [3, 5]])
>>> clf = IsolationForest(n_estimators=10, warm_start=True)
>>> clf.fit(X) # fit 10 trees
>>> clf.set_params(n_estimators=20) # add 10 more trees
>>> clf.fit(X) # fit the added trees
Примеры
См. Пример IsolationForest для иллюстрации использования IsolationForest.
См. Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных для сравнения
ensemble.IsolationForestсneighbors.LocalOutlierFactor,svm.OneClassSVM(настроенный для работы как метод обнаружения выбросов),linear_model.SGDOneClassSVM, и обнаружение выбросов на основе ковариации сcovariance.EllipticEnvelope.
Ссылки
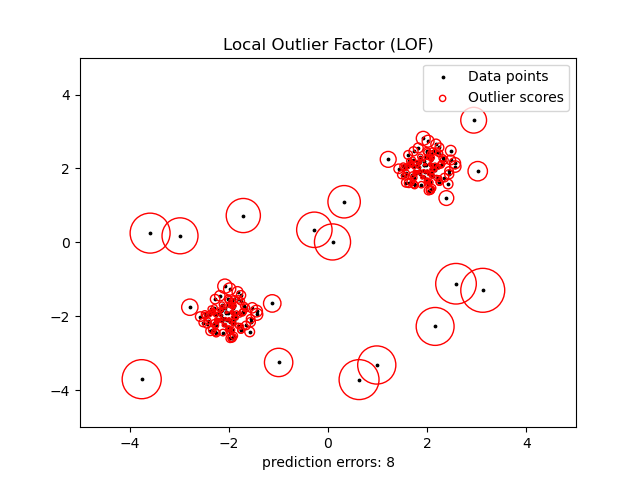
2.7.3.3. Локальный фактор выбросов#
Еще один эффективный способ обнаружения выбросов в данных умеренно высокой размерности - использование алгоритма Local Outlier Factor (LOF).
The neighbors.LocalOutlierFactor (LOF) алгоритм вычисляет оценку (называемую локальным фактором выброса), отражающую степень аномальности наблюдений. Он измеряет отклонение локальной плотности данной точки данных относительно её соседей. Идея заключается в обнаружении образцов, имеющих существенно более низкую плотность, чем их соседи.
На практике локальная плотность получается из k ближайших соседей. Оценка LOF наблюдения равна отношению средней локальной плотности его k ближайших соседей к его собственной локальной плотности: ожидается, что нормальный экземпляр будет иметь локальную плотность, аналогичную плотности его соседей, в то время как аномальные данные, как ожидается, будут иметь гораздо меньшую локальную плотность.
Число k рассматриваемых соседей (псевдоним параметра n_neighbors) обычно выбирается 1) больше минимального количества объектов, которое должен содержать кластер, чтобы другие объекты могли быть локальными выбросами относительно этого кластера, и 2) меньше максимального количества близлежащих объектов, которые потенциально могут быть локальными выбросами. На практике такая информация обычно недоступна, и выбор n_neighbors=20 кажется, хорошо работает в целом. Когда доля
выбросов высока (т.е. больше 10 %, как в примере ниже),
n_neighbors должно быть больше (n_neighbors=35 в примере ниже).
Сила алгоритма LOF заключается в том, что он учитывает как локальные, так и глобальные свойства наборов данных: он может хорошо работать даже в наборах данных, где аномальные образцы имеют различную базовую плотность. Вопрос не в том, насколько изолирован образец, а в том, насколько он изолирован относительно окружающей окрестности.
При применении LOF для обнаружения выбросов нет predict,
decision_function и score_samples методами, но только fit_predict
метода. Оценки аномальности обучающих выборок доступны
через negative_outlier_factor_ атрибут.
Обратите внимание, что predict, decision_function и score_samples может использоваться на новых, невидимых данных, когда LOF применяется для обнаружения новизны, т.е. когда
novelty параметр установлен в True, но результат predict может отличаться от fit_predict. См. Обнаружение новизны с Local Outlier Factor.
Эта стратегия проиллюстрирована ниже.
Примеры
См. Обнаружение выбросов с помощью фактора локальных выбросов (LOF) для иллюстрации использования
neighbors.LocalOutlierFactor.См. Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных для сравнения с другими методами обнаружения аномалий.
Ссылки
Breunig, Kriegel, Ng и Sander (2000) LOF: идентификация локальных выбросов на основе плотности. Proc. ACM SIGMOD
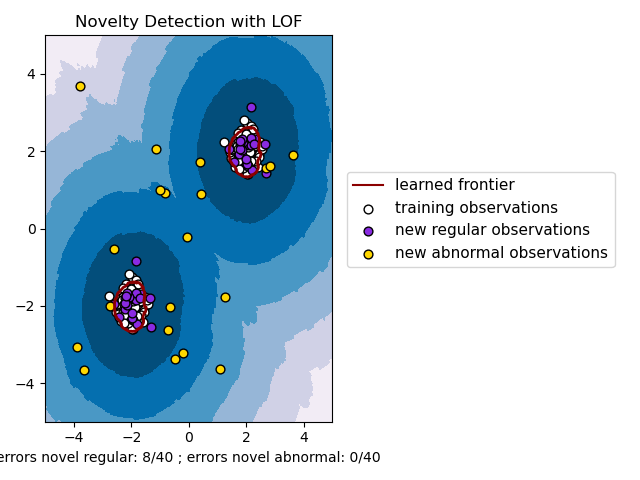
2.7.4. Обнаружение новизны с Local Outlier Factor#
Чтобы использовать neighbors.LocalOutlierFactor для обнаружения новизны, т.е. предсказания меток или вычисления оценки аномальности новых, ранее невиданных данных, необходимо создать экземпляр оценщика с novelty параметр
установлен в True перед подгонкой оценщика:
lof = LocalOutlierFactor(novelty=True)
lof.fit(X_train)
Обратите внимание, что fit_predict недоступен в этом случае, чтобы избежать несоответствий.
Предупреждение
Обнаружение новизны с Local Outlier Factor
Когда novelty установлено в True будьте внимательны, что вы должны использовать только
predict, decision_function и score_samples на новых, невидимых данных, а не на обучающих выборках, так как это приведет к неверным результатам. Т.е., результат predict не будет таким же, как fit_predict.
Оценки аномальности обучающих выборок всегда доступны через negative_outlier_factor_ атрибут.
Обнаружение новизны с neighbors.LocalOutlierFactor проиллюстрировано ниже
(см. Обнаружение новизны с помощью локального фактора выбросов (LOF)).