SVR#
- класс sklearn.svm.SVR(*, ядро='rbf', степень=3, gamma='scale', coef0=0.0, tol=0.001, C=1.0, эпсилон=0.1, сжатие=True, cache_size=200, verbose=False, max_iter=-1)[источник]#
Epsilon-Support Vector Regression.
Свободные параметры в модели — это C и epsilon.
Реализация основана на libsvm. Временная сложность обучения более чем квадратична с количеством образцов, что затрудняет масштабирование на наборы данных с более чем парой 10000 образцов. Для больших наборов данных рассмотрите использование
LinearSVRилиSGDRegressorвместо этого, возможно, послеNystroemпреобразователь или другой Аппроксимация ядра.Подробнее в Руководство пользователя.
- Параметры:
- ядро{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} или вызываемый объект, по умолчанию=’rbf’
Определяет тип ядра, используемый в алгоритме. Если не указано, будет использоваться ‘rbf’. Если передан вызываемый объект, он используется для предварительного вычисления матрицы ядра. Для интуитивной визуализации различных типов ядер см. Регрессия на основе метода опорных векторов (SVR) с использованием линейных и нелинейных ядер
- степеньint, по умолчанию=3
Степень полиномиальной ядерной функции ('poly'). Должна быть неотрицательной. Игнорируется всеми другими ядрами.
- gamma{‘scale’, ‘auto’} или float, по умолчанию='scale'
Коэффициент ядра для 'rbf', 'poly' и 'sigmoid'.
if
gamma='scale'(по умолчанию) передается, тогда используется 1 / (n_features * X.var()) в качестве значения gamma,если 'auto', использует 1 / n_features
если float, должно быть неотрицательным.
Изменено в версии 0.22: Значение по умолчанию для
gammaизменено с 'auto' на 'scale'.- coef0float, по умолчанию=0.0
Независимый член в ядерной функции. Значим только для 'poly' и 'sigmoid'.
- tolfloat, по умолчанию=1e-3
Допуск для критерия остановки.
- Cfloat, по умолчанию=1.0
Параметр регуляризации. Сила регуляризации обратно пропорциональна C. Должен быть строго положительным. Штраф - квадрат l2. Для интуитивной визуализации эффектов масштабирования параметра регуляризации C см. Масштабирование параметра регуляризации для SVC.
- эпсилонfloat, по умолчанию=0.1
Эпсилон в модели epsilon-SVR. Он задает эпсилон-трубку, внутри которой не применяется штраф в функции потерь при обучении для точек, предсказанных на расстоянии эпсилон от фактического значения. Должен быть неотрицательным.
- сжатиеbool, по умолчанию=True
Использовать ли эвристику сжатия. См. Руководство пользователя.
- cache_sizefloat, default=200
Укажите размер кэша ядра (в МБ).
- verbosebool, по умолчанию=False
Включить подробный вывод. Обратите внимание, что этот параметр использует настройку времени выполнения на процесс в libsvm, которая, если включена, может работать некорректно в многопоточном контексте.
- max_iterint, по умолчанию=-1
Жесткое ограничение на итерации внутри решателя, или -1 для отсутствия ограничения.
- Атрибуты:
coef_ndarray формы (1, n_features)Веса, присвоенные признакам, когда
kernel="linear".- dual_coef_ndarray формы (1, n_SV)
Коэффициенты опорного вектора в функции принятия решения.
- fit_status_int
0, если модель корректно обучена, 1 в противном случае (будет выдано предупреждение)
- intercept_ndarray формы (1,)
Константы в функции принятия решений.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Количество итераций, выполняемых процедурой оптимизации для обучения модели.
Добавлено в версии 1.1.
n_support_ndarray формы (1,), dtype=int32Количество опорных векторов для каждого класса.
- shape_fit_кортеж int формы (n_dimensions_of_X,)
Размерности массива обучающего вектора
X.- support_ndarray формы (n_SV,)
Индексы опорных векторов.
- support_vectors_ndarray формы (n_SV, n_features)
Support vectors.
Смотрите также
Ссылки
Примеры
>>> from sklearn.svm import SVR >>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> import numpy as np >>> n_samples, n_features = 10, 5 >>> rng = np.random.RandomState(0) >>> y = rng.randn(n_samples) >>> X = rng.randn(n_samples, n_features) >>> regr = make_pipeline(StandardScaler(), SVR(C=1.0, epsilon=0.2)) >>> regr.fit(X, y) Pipeline(steps=[('standardscaler', StandardScaler()), ('svr', SVR(epsilon=0.2))])
- fit(X, y, sample_weight=None)[источник]#
Обучите модель SVM в соответствии с предоставленными обучающими данными.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples, n_samples)
Обучающие векторы, где
n_samplesэто количество образцов иn_features— это количество признаков. Для kernel="precomputed" ожидаемая форма X — (n_samples, n_samples).- yarray-like формы (n_samples,)
Целевые значения (метки классов в классификации, вещественные числа в регрессии).
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого образца. Масштабируют C для каждого образца. Более высокие веса заставляют классификатор уделять больше внимания этим точкам.
- Возвращает:
- selfobject
Обученный оценщик.
Примечания
Если X и y не являются C-упорядоченными и непрерывными массивами np.float64 и X не является scipy.sparse.csr_matrix, X и/или y могут быть скопированы.
Если X является плотным массивом, то другие методы не будут поддерживать разреженные матрицы в качестве входных данных.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Выполнить регрессию на выборках в X.
Для одноклассовой модели возвращается +1 (внутренний) или -1 (выброс).
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Для kernel="precomputed" ожидаемая форма X (n_samples_test, n_samples_train).
- Возвращает:
- y_predndarray формы (n_samples,)
Предсказанные значения.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVR[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVR[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#

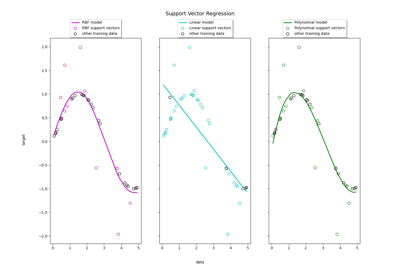
Регрессия на основе метода опорных векторов (SVR) с использованием линейных и нелинейных ядер