Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
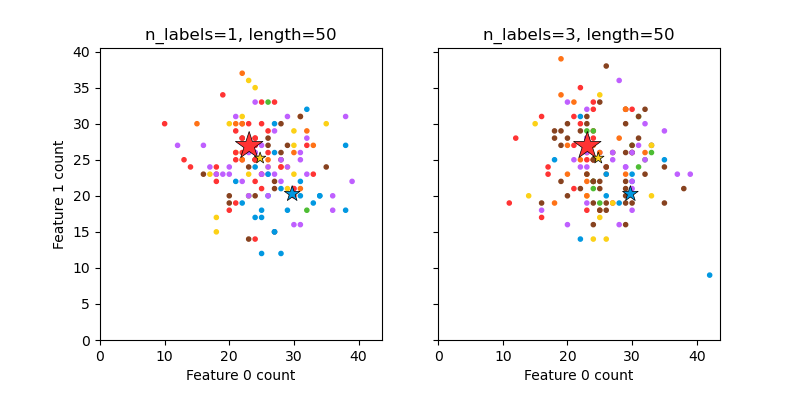
Построение случайно сгенерированного многометочного набора данных#
Это иллюстрирует make_multilabel_classification
генератор набора данных. Каждый образец состоит из подсчетов двух признаков (всего до 50), которые по-разному распределены в каждом из двух классов.
Точки помечены следующим образом, где Y означает присутствие класса:
1 |
2 |
3 |
Цвет |
|---|---|---|---|
Y |
N |
N |
Красный |
N |
Y |
N |
Синий |
N |
N |
Y |
Желтый |
Y |
Y |
N |
Фиолетовый |
Y |
N |
Y |
Orange |
Y |
Y |
N |
Зеленый |
Y |
Y |
Y |
Brown |
Звездочка отмечает ожидаемый образец для каждого класса; её размер отражает вероятность выбора этой метки класса.
Левый и правый примеры подчеркивают n_labels параметр: больше образцов на правом графике имеют 2 или 3 метки.
Обратите внимание, что этот двумерный пример очень вырожден: обычно количество признаков было бы намного больше, чем 'длина документа', тогда как здесь у нас документы намного больше, чем словарь. Аналогично, с n_classes > n_features, гораздо менее вероятно, что
признак отличает конкретный класс.
The data was generated from (random_state=939):
Class P(C) P(w0|C) P(w1|C)
red 0.52 0.46 0.54
blue 0.28 0.59 0.41
yellow 0.19 0.50 0.50
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_multilabel_classification as make_ml_clf
COLORS = np.array(
[
"!",
"#FF3333", # red
"#0198E1", # blue
"#BF5FFF", # purple
"#FCD116", # yellow
"#FF7216", # orange
"#4DBD33", # green
"#87421F", # brown
]
)
# Use same random seed for multiple calls to make_multilabel_classification to
# ensure same distributions
RANDOM_SEED = np.random.randint(2**10)
def plot_2d(ax, n_labels=1, n_classes=3, length=50):
X, Y, p_c, p_w_c = make_ml_clf(
n_samples=150,
n_features=2,
n_classes=n_classes,
n_labels=n_labels,
length=length,
allow_unlabeled=False,
return_distributions=True,
random_state=RANDOM_SEED,
)
ax.scatter(
X[:, 0], X[:, 1], color=COLORS.take((Y * [1, 2, 4]).sum(axis=1)), marker="."
)
ax.scatter(
p_w_c[0] * length,
p_w_c[1] * length,
marker="*",
linewidth=0.5,
edgecolor="black",
s=20 + 1500 * p_c**2,
color=COLORS.take([1, 2, 4]),
)
ax.set_xlabel("Feature 0 count")
return p_c, p_w_c
_, (ax1, ax2) = plt.subplots(1, 2, sharex="row", sharey="row", figsize=(8, 4))
plt.subplots_adjust(bottom=0.15)
p_c, p_w_c = plot_2d(ax1, n_labels=1)
ax1.set_title("n_labels=1, length=50")
ax1.set_ylabel("Feature 1 count")
plot_2d(ax2, n_labels=3)
ax2.set_title("n_labels=3, length=50")
ax2.set_xlim(left=0, auto=True)
ax2.set_ylim(bottom=0, auto=True)
plt.show()
print("The data was generated from (random_state=%d):" % RANDOM_SEED)
print("Class", "P(C)", "P(w0|C)", "P(w1|C)", sep="\t")
for k, p, p_w in zip(["red", "blue", "yellow"], p_c, p_w_c.T):
print("%s\t%0.2f\t%0.2f\t%0.2f" % (k, p, p_w[0], p_w[1]))
Общее время выполнения скрипта: (0 минут 0.118 секунд)
Связанные примеры
Использование KBinsDiscretizer для дискретизации непрерывных признаков
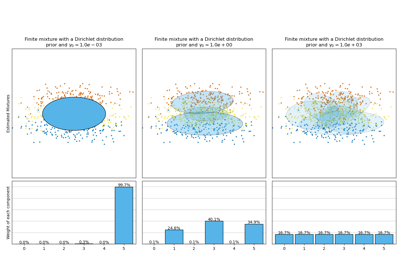
Анализ вариации байесовской гауссовой смеси с априорным типом концентрации