make_classification#
- sklearn.datasets.make_classification(n_samples=100, n_features=20, *, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, веса=None, flip_y=0.01, class_sep=1.0, гиперкуб=True, shift=0.0, scale=1.0, перемешивание=True, random_state=None, return_X_y=True)[источник]#
Сгенерировать случайную задачу классификации на n классов.
Изначально создаются кластеры точек, нормально распределенных (std=1) вокруг вершин
n_informative-мерный гиперкуб со сторонами длиной2*class_sepи назначает равное количество кластеров каждому классу. Это вводит взаимозависимость между этими признаками и добавляет различные типы дополнительного шума к данным.Без перемешивания,
Xгоризонтально объединяет признаки в следующем порядке: основныеn_informativeпризнаков, за которыми следуетn_redundantлинейные комбинации информативных признаков, за которыми следуетn_repeatedдубликаты, случайно выбранные с возвращением из информативных и избыточных признаков. Остальные признаки заполняются случайным шумом. Таким образом, без перемешивания все полезные признаки содержатся в столбцахX[:, :n_informative + n_redundant + n_repeated].Подробнее в Руководство пользователя.
- Параметры:
- n_samplesint, по умолчанию=100
Количество образцов.
- n_featuresint, по умолчанию=20
Общее количество признаков. Они включают
n_informativeинформативные признаки,n_redundantизбыточные признаки,n_repeatedдублирующиеся признаки иn_features-n_informative-n_redundant-n_repeatedбесполезные признаки, выбранные случайным образом.- n_informativeint, по умолчанию=2
Количество информативных признаков. Каждый класс состоит из нескольких гауссовых кластеров, каждый расположен вокруг вершин гиперкуба в подпространстве размерности
n_informative. Для каждого кластера информативные признаки независимо выбираются из N(0, 1), а затем случайным образом линейно комбинируются внутри каждого кластера для добавления ковариации. Затем кластеры размещаются на вершинах гиперкуба.- n_redundantint, по умолчанию=2
Количество избыточных признаков. Эти признаки генерируются как случайные линейные комбинации информативных признаков.
- n_repeatedint, по умолчанию=0
Количество дублированных признаков, случайно выбранных из информативных и избыточных признаков.
- n_classesint, по умолчанию=2
Количество классов (или меток) задачи классификации.
- n_clusters_per_classint, по умолчанию=2
Количество кластеров на класс.
- весаarray-like формы (n_classes,) или (n_classes - 1,), по умолчанию=None
Доли образцов, отнесенных к каждому классу. Если None, то классы сбалансированы. Обратите внимание, что если
len(weights) == n_classes - 1, тогда вес последнего класса автоматически выводится. Более чемn_samplesобразцы могут быть возвращены, если суммаweightsпревышает 1. Обратите внимание, что фактические пропорции классов не будут точно соответствоватьweightsкогдаflip_yне равно 0.- flip_yfloat, по умолчанию=0.01
Доля выборок, класс которых назначается случайным образом. Большие значения вносят шум в метки и усложняют задачу классификации. Обратите внимание, что настройка по умолчанию flip_y > 0 может привести к менее чем
n_classesв y в некоторых случаях.- class_sepfloat, по умолчанию=1.0
Множитель размера гиперкуба. Большие значения разбрасывают кластеры/классы и упрощают задачу классификации.
- гиперкубbool, по умолчанию=True
Если True, кластеры размещаются в вершинах гиперкуба. Если False, кластеры размещаются в вершинах случайного политопа.
- shiftfloat, ndarray формы (n_features,) или None, по умолчанию=0.0
Сдвиг признаков на указанное значение. Если None, то признаки сдвигаются на случайное значение, выбранное из [-class_sep, class_sep].
- scalefloat, ndarray формы (n_features,) или None, по умолчанию=1.0
Умножьте признаки на указанное значение. Если None, то признаки масштабируются случайным значением, выбранным из [1, 100]. Обратите внимание, что масштабирование происходит после сдвига.
- перемешиваниеbool, по умолчанию=True
Перемешать образцы и признаки.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для создания набора данных. Передайте целое число для воспроизводимого результата при нескольких вызовах функции. См. Глоссарий.
- return_X_ybool, по умолчанию=True
Если True, кортеж
(X, y)вместо объекта Bunch возвращается.Добавлено в версии 1.7.
- Возвращает:
- данные
Bunchifreturn_X_yявляетсяFalse. Объект, подобный словарю, со следующими атрибутами.
- DESCRstr
Описание функции, которая сгенерировала набор данных.
- параметрdict
Словарь, который хранит значения аргументов, переданных в функцию-генератор.
- feature_infoсписок длины n_features
Описание для каждого сгенерированного признака.
- Xndarray формы (n_samples, n_features)
Сгенерированные образцы.
- yndarray формы (n_samples,)
Целочисленная метка принадлежности к классу для каждой выборки.
Добавлено в версии 1.7.
- (X, y)кортеж если
return_X_yравно True Кортеж сгенерированных образцов и меток.
- данные
Смотрите также
make_blobsУпрощённый вариант.
make_multilabel_classificationНесвязанный генератор для многометочных задач.
Примечания
Алгоритм адаптирован из работы Guyon [1] и был разработан для генерации набора данных "Madelon".
Ссылки
[1]I. Guyon, “Design of experiments for the NIPS 2003 variable selection benchmark”, 2003.
Примеры
>>> from sklearn.datasets import make_classification >>> X, y = make_classification(random_state=42) >>> X.shape (100, 20) >>> y.shape (100,) >>> list(y[:5]) [np.int64(0), np.int64(0), np.int64(1), np.int64(1), np.int64(0)]
Примеры галереи#
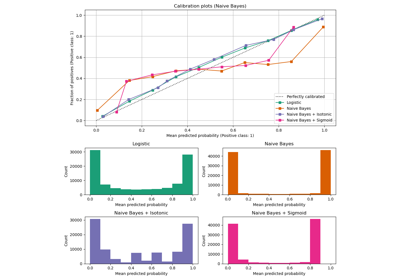
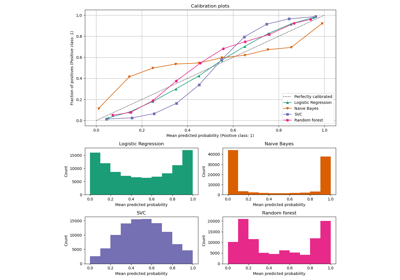

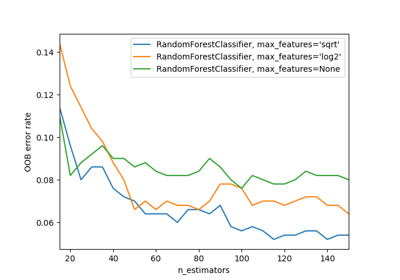
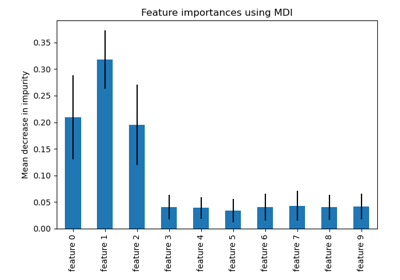

Рекурсивное исключение признаков с перекрестной проверкой

Оценить производительность классификатора с помощью матрицы ошибок
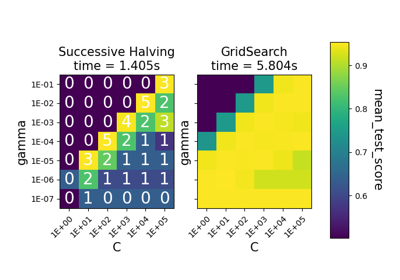
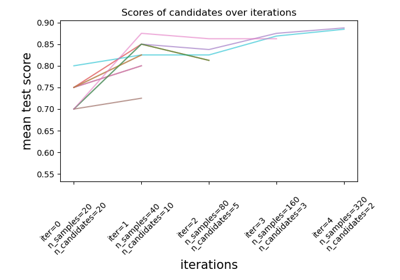
Сравнение между поиском по сетке и последовательным сокращением вдвое
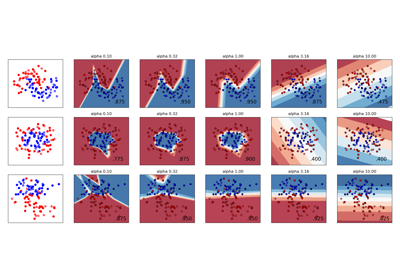
Изменение регуляризации в многослойном перцептроне