make_regression#
- sklearn.datasets.make_regression(n_samples=100, n_features=100, *, n_informative=10, n_targets=1, смещение=0.0, effective_rank=None, tail_strength=0.5, шум=0.0, перемешивание=True, coef=False, random_state=None)[источник]#
Сгенерировать случайную регрессионную задачу.
Входной набор может быть либо хорошо обусловленным (по умолчанию), либо иметь низкий ранг с жирным хвостом сингулярного профиля. См.
make_low_rank_matrixдля более подробной информации.Выходные данные генерируются применением (возможно, смещенной) случайной линейной регрессионной модели с
n_informativeненулевые регрессоры к ранее сгенерированному входу и некоторому гауссову шуму с центром с регулируемым масштабом.Подробнее в Руководство пользователя.
- Параметры:
- n_samplesint, по умолчанию=100
Количество образцов.
- n_featuresint, по умолчанию=100
Количество признаков.
- n_informativeint, по умолчанию=10
Количество информативных признаков, т.е., количество признаков, используемых для построения линейной модели, используемой для генерации выхода.
- n_targetsint, по умолчанию=1
Количество регрессионных целей, т.е. размерность выходного вектора y, связанного с выборкой. По умолчанию выход является скаляром.
- смещениеfloat, по умолчанию=0.0
Смещение в базовой линейной модели.
- effective_rankint, default=None
- Если не None:
Приблизительное количество сингулярных векторов, необходимых для объяснения большей части входных данных линейными комбинациями. Использование такого рода сингулярного спектра во входных данных позволяет генератору воспроизводить корреляции, часто наблюдаемые на практике.
- Если None:
Входной набор хорошо обусловлен, центрирован и имеет гауссово распределение с единичной дисперсией.
- tail_strengthfloat, по умолчанию=0.5
Относительная важность шумного хвоста профиля сингулярных значений, если
effective_rankне является None. Если это число с плавающей точкой, оно должно быть между 0 и 1.- шумfloat, по умолчанию=0.0
Стандартное отклонение гауссовского шума, применяемого к выходу.
- перемешиваниеbool, по умолчанию=True
Перемешать образцы и признаки.
- coefbool, по умолчанию=False
Если True, возвращаются коэффициенты базовой линейной модели.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для создания набора данных. Передайте целое число для воспроизводимого результата при нескольких вызовах функции. См. Глоссарий.
- Возвращает:
- Xndarray формы (n_samples, n_features)
Входные образцы.
- yndarray формы (n_samples,) или (n_samples, n_targets)
Выходные значения.
- coefndarray формы (n_features,) или (n_features, n_targets)
Коэффициент базовой линейной модели. Возвращается только если coef равно True.
Примеры
>>> from sklearn.datasets import make_regression >>> X, y = make_regression(n_samples=5, n_features=2, noise=1, random_state=42) >>> X array([[ 0.4967, -0.1382 ], [ 0.6476, 1.523], [-0.2341, -0.2341], [-0.4694, 0.5425], [ 1.579, 0.7674]]) >>> y array([ 6.737, 37.79, -10.27, 0.4017, 42.22])
Примеры галереи#
Эффект преобразования целей в регрессионной модели

Обучение Elastic Net с предвычисленной матрицей Грама и взвешенными выборками
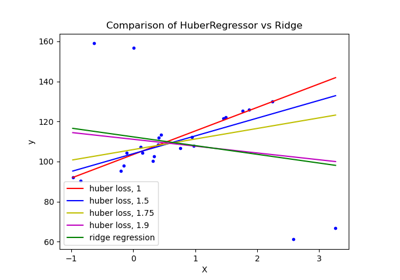
HuberRegressor против Ridge на наборе данных с сильными выбросами

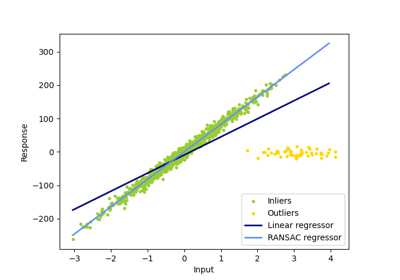
Робастная оценка линейной модели с использованием RANSAC
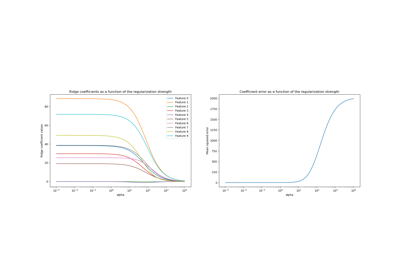

Влияние регуляризации модели на ошибку обучения и тестирования