make_blobs#
- sklearn.datasets.make_blobs(n_samples=100, n_features=2, *, центры=None, cluster_std=1.0, center_box=(-10.0, 10.0), перемешивание=True, random_state=None, return_centers=False)[источник]#
Сгенерировать изотропные гауссовы сгустки для кластеризации.
Подробнее в Руководство пользователя.
- Параметры:
- n_samplesint или array-like, по умолчанию=100
Если int, это общее количество точек, равномерно распределенных между кластерами. Если массивоподобный, каждый элемент последовательности указывает количество образцов на кластер.
Изменено в версии v0.20: теперь можно передать array-like в
n_samplesпараметр- n_featuresint, по умолчанию=2
Количество признаков для каждого образца.
- центрыint или array-like формы (n_centers, n_features), по умолчанию=None
Количество центров для генерации или фиксированные местоположения центров. Если n_samples — целое число и centers равно None, генерируется 3 центра. Если n_samples — массивоподобный, centers должно быть либо None, либо массивом длины, равной длине n_samples.
- cluster_stdfloat или array-like of float, default=1.0
Стандартное отклонение кластеров.
- center_boxкортеж из float (мин, макс), по умолчанию=(-10.0, 10.0)
Ограничивающий прямоугольник для каждого центра кластера, когда центры генерируются случайным образом.
- перемешиваниеbool, по умолчанию=True
Перемешать образцы.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для создания набора данных. Передайте целое число для воспроизводимого результата при нескольких вызовах функции. См. Глоссарий.
- return_centersbool, по умолчанию=False
Если True, то возвращает центры каждого кластера.
Добавлено в версии 0.23.
- Возвращает:
- Xndarray формы (n_samples, n_features)
Сгенерированные образцы.
- yndarray формы (n_samples,)
Целочисленные метки принадлежности каждого образца к кластеру.
- центрыndarray формы (n_центров, n_признаков)
Центры каждого кластера. Возвращается только если
return_centers=True.
Смотрите также
make_classificationБолее сложный вариант.
Примеры
>>> from sklearn.datasets import make_blobs >>> X, y = make_blobs(n_samples=10, centers=3, n_features=2, ... random_state=0) >>> print(X.shape) (10, 2) >>> y array([0, 0, 1, 0, 2, 2, 2, 1, 1, 0]) >>> X, y = make_blobs(n_samples=[3, 3, 4], centers=None, n_features=2, ... random_state=0) >>> print(X.shape) (10, 2) >>> y array([0, 1, 2, 0, 2, 2, 2, 1, 1, 0])
Примеры галереи#
Калибровка вероятностей для классификации на 3 класса
Нормальный, Ledoit-Wolf и OAS линейный дискриминантный анализ для классификации
Демонстрация алгоритма кластеризации с распространением аффинности
Сравнение производительности биссекционного K-средних и обычного K-средних
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
Выбор количества кластеров с помощью анализа силуэта для кластеризации KMeans
Сравнение различных методов иерархической связи на игрушечных наборах данных
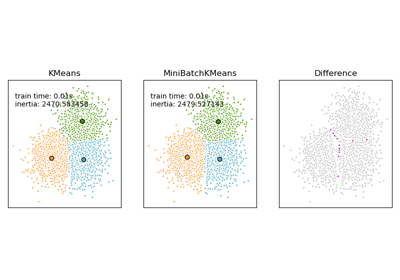
Сравнение алгоритмов кластеризации K-Means и MiniBatchKMeans
Границы решений мультиномиальной и логистической регрессии One-vs-Rest

SGD: Гиперплоскость максимального разделяющего запаса
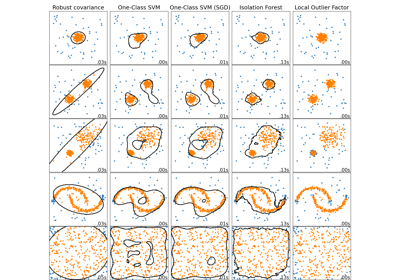
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных
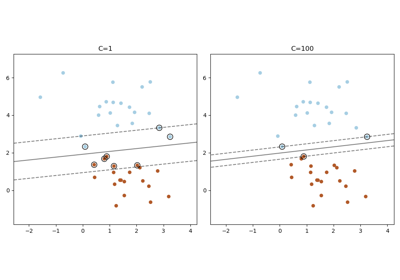
SVM: Разделяющая гиперплоскость с максимальным зазором

SVM: Разделяющая гиперплоскость для несбалансированных классов