make_moons#
- sklearn.datasets.make_moons(n_samples=100, *, перемешивание=True, шум=None, random_state=None)[источник]#
Создайте два переплетающихся полукруга.
Простой игрушечный набор данных для визуализации алгоритмов кластеризации и классификации. Подробнее в Руководство пользователя.
- Параметры:
- n_samplesцелое число или кортеж формы (2,), тип данных=int, по умолчанию=100
Если int, общее количество сгенерированных точек. Если кортеж из двух элементов, количество точек в каждой из двух лун.
Изменено в версии 0.23: Добавлен кортеж из двух элементов.
- перемешиваниеbool, по умолчанию=True
Перемешивать ли образцы.
- шумfloat, по умолчанию=None
Стандартное отклонение гауссовского шума, добавленного к данным.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для перемешивания набора данных и шума. Передайте int для воспроизводимого вывода при множественных вызовах функции. См. Глоссарий.
- Возвращает:
- Xndarray формы (n_samples, 2)
Сгенерированные образцы.
- yndarray формы (n_samples,)
Целочисленные метки (0 или 1) для принадлежности каждого образца к классу.
Примеры
>>> from sklearn.datasets import make_moons >>> X, y = make_moons(n_samples=200, noise=0.2, random_state=42) >>> X.shape (200, 2) >>> y.shape (200,)
Примеры галереи#

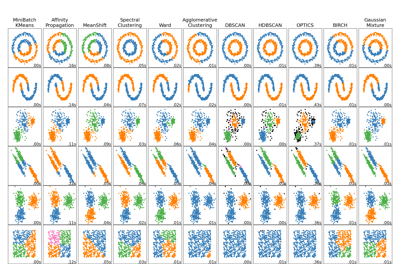
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
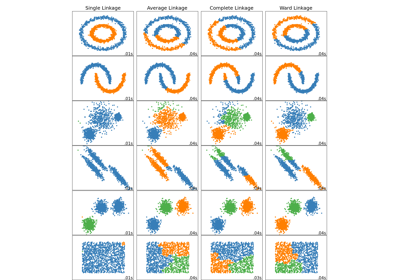
Сравнение различных методов иерархической связи на игрушечных наборах данных
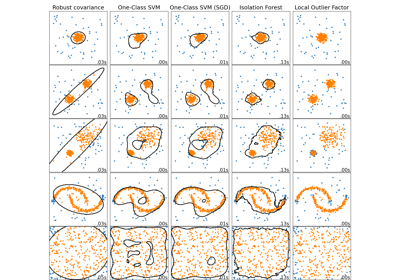
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных
Статистическое сравнение моделей с использованием поиска по сетке
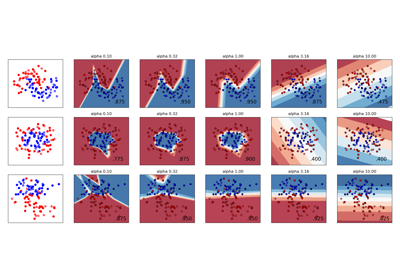
Изменение регуляризации в многослойном перцептроне
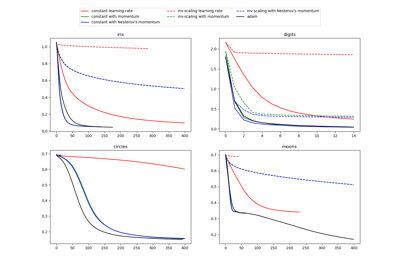
Сравнение стохастических стратегий обучения для MLPClassifier