SGDOneClassSVM#
- класс sklearn.linear_model.SGDOneClassSVM(nu=0.5, fit_intercept=True, max_iter=1000, tol=0.001, перемешивание=True, verbose=0, random_state=None, learning_rate='optimal', eta0=0.01, power_t=0.5, warm_start=False, среднее=False)[источник]#
Решает линейную One-Class SVM с использованием стохастического градиентного спуска.
Эта реализация предназначена для использования с техникой аппроксимации ядра (например,
sklearn.kernel_approximation.Nystroem) для получения результатов, аналогичныхsklearn.svm.OneClassSVMкоторый по умолчанию использует гауссово ядро.Подробнее в Руководство пользователя.
Добавлено в версии 1.0.
- Параметры:
- nufloat, по умолчанию=0.5
Параметр nu One Class SVM: верхняя граница доли ошибок обучения и нижняя граница доли опорных векторов. Должен быть в интервале (0, 1]. По умолчанию принимается 0.5.
- fit_interceptbool, по умолчанию=True
Следует ли оценивать свободный член или нет. По умолчанию True.
- max_iterint, по умолчанию=1000
Максимальное количество проходов по обучающим данным (также называемых эпохами). Это влияет только на поведение в
fitметод, а неpartial_fit. По умолчанию 1000. Значения должны быть в диапазоне[1, inf).- tolfloat или None, по умолчанию=1e-3
Критерий остановки. Если не None, итерации остановятся когда (loss > previous_loss - tol). По умолчанию 1e-3. Значения должны быть в диапазоне
[0.0, inf).- перемешиваниеbool, по умолчанию=True
Следует ли перемешивать обучающие данные после каждой эпохи. По умолчанию True.
- verboseint, по умолчанию=0
Уровень подробности вывода.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Сид генератора псевдослучайных чисел для использования при перемешивании данных. Если int, random_state - это сид, используемый генератором случайных чисел; если экземпляр RandomState, random_state - это генератор случайных чисел; если None, генератор случайных чисел - это экземпляр RandomState, используемый
np.random.- learning_rate{'constant', 'optimal', 'invscaling', 'adaptive'}, по умолчанию='optimal'
Расписание скорости обучения для использования с
fit. (Если используетсяpartial_fit, скорость обучения должна контролироваться напрямую).‘constant’:
eta = eta0‘optimal’:
eta = 1.0 / (alpha * (t + t0))где t0 выбирается эвристикой, предложенной Леоном Ботту.‘invscaling’:
eta = eta0 / pow(t, power_t)‘adaptive’: eta = eta0, пока обучение продолжает уменьшаться. Каждый раз, когда n_iter_no_change последовательных эпох не уменьшают потерю обучения на tol или не увеличивают валидационную оценку на tol, если early_stopping равен True, текущая скорость обучения делится на 5.
- eta0float, по умолчанию=0.01
Начальная скорость обучения для расписаний 'constant', 'invscaling' или 'adaptive'. Значение по умолчанию — 0.0, но обратите внимание, что eta0 не используется по умолчанию для скорости обучения 'optimal'. Значения должны быть в диапазоне
(0.0, inf).- power_tfloat, по умолчанию=0.5
Показатель степени для обратного масштабирования скорости обучения. Значения должны находиться в диапазоне
[0.0, inf).Устарело с версии 1.8: Отрицательные значения для
power_tустарели в версии 1.8 и вызовут ошибку в 1.10. Используйте значения в диапазоне [0.0, inf) вместо этого.- warm_startbool, по умолчанию=False
При установке в True повторно использует решение предыдущего вызова fit в качестве инициализации, в противном случае просто стирает предыдущее решение. См. Глоссарий.
Повторный вызов fit или partial_fit при warm_start=True может привести к другому решению, чем при однократном вызове fit, из-за способа перемешивания данных. Если используется динамическая скорость обучения, она адаптируется в зависимости от количества уже просмотренных образцов. Вызов
fitсбрасывает этот счетчик, в то время какpartial_fitприведет к увеличению существующего счетчика.- среднееbool или int, по умолчанию=False
При установке в True вычисляет усредненные веса SGD и сохраняет результат в
coef_атрибут. Если установлено значение int больше 1, усреднение начнется, как только общее количество увиденных образцов достигнет среднего. Так чтоaverage=10начнет усреднение после просмотра 10 образцов.
- Атрибуты:
- coef_ndarray формы (1, n_features)
Веса, назначенные признакам.
- offset_ndarray формы (1,)
Смещение, используемое для определения решающей функции из исходных оценок. У нас есть соотношение: decision_function = score_samples - offset.
- n_iter_int
Фактическое количество итераций для достижения критерия остановки.
- t_int
Количество обновлений весов, выполненных во время обучения. То же, что и
(n_iter_ * n_samples + 1).- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
sklearn.svm.OneClassSVMОбнаружение выбросов без учителя.
Примечания
Этот оценщик имеет линейную сложность по количеству обучающих образцов и поэтому лучше подходит, чем
sklearn.svm.OneClassSVMреализация для наборов данных с большим количеством обучающих образцов (скажем, > 10 000).Примеры
>>> import numpy as np >>> from sklearn import linear_model >>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) >>> clf = linear_model.SGDOneClassSVM(random_state=42, tol=None) >>> clf.fit(X) SGDOneClassSVM(random_state=42, tol=None)
>>> print(clf.predict([[4, 4]])) [1]
- decision_function(X)[источник]#
Знаковое расстояние до разделяющей гиперплоскости.
Знаковое расстояние положительно для выброса и отрицательно для невыброса.
- Параметры:
- X{array-like, sparse matrix}, форма (n_samples, n_features)
Тестовые данные.
- Возвращает:
- декarray-like, shape (n_samples,)
Значения решающей функции для выборок.
- densify()[источник]#
Преобразовать матрицу коэффициентов в плотный формат массива.
Преобразует
coef_преобразование (обратное) в numpy.ndarray. Это формат по умолчаниюcoef_и требуется для обучения, поэтому вызов этого метода необходим только для моделей, которые ранее были разрежены; в противном случае это пустая операция.- Возвращает:
- self
Обученный оценщик.
- fit(X, y=None, coef_init=None, offset_init=None, sample_weight=None)[источник]#
Обучение линейного одноклассового SVM со стохастическим градиентным спуском.
Это решает эквивалентную задачу оптимизации основной задачи оптимизации One-Class SVM и возвращает вектор весов w и смещение rho, так что решающая функция задаётся как
- Параметры:
- X{array-like, sparse matrix}, форма (n_samples, n_features)
Обучающие данные.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- coef_initмассив, форма (n_classes, n_features)
Начальные коэффициенты для теплого старта оптимизации.
- offset_initмассив, форма (n_classes,)
Начальное смещение для теплого старта оптимизации.
- sample_weightarray-like, форма (n_samples,), опционально
Веса, применяемые к отдельным образцам. Если не указаны, предполагаются равномерные веса. Эти веса будут умножены на class_weight (переданный через конструктор), если class_weight указан.
- Возвращает:
- selfobject
Возвращает обученный экземпляр self.
- fit_predict(X, y=None, **kwargs)[источник]#
Выполнить подгонку на X и вернуть метки для X.
Возвращает -1 для выбросов и 1 для нормальных точек.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные образцы.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- **kwargsdict
Аргументы, передаваемые в
fit.Добавлено в версии 1.4.
- Возвращает:
- yndarray формы (n_samples,)
1 для нормальных объектов, -1 для выбросов.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- partial_fit(X, y=None, sample_weight=None)[источник]#
Обучение линейного одноклассового SVM со стохастическим градиентным спуском.
- Параметры:
- X{array-like, sparse matrix}, форма (n_samples, n_features)
Подмножество обучающих данных.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- sample_weightarray-like, форма (n_samples,), опционально
Веса, применяемые к отдельным выборкам. Если не указаны, предполагаются равномерные веса.
- Возвращает:
- selfobject
Возвращает обученный экземпляр self.
- predict(X)[источник]#
Возвращает метки (1 - нормальный образец, -1 - выброс) для образцов.
- Параметры:
- X{array-like, sparse matrix}, форма (n_samples, n_features)
Тестовые данные.
- Возвращает:
- yмассив, формы (n_samples,)
Метки образцов.
- score_samples(X)[источник]#
Необработанная функция оценки выборок.
- Параметры:
- X{array-like, sparse matrix}, форма (n_samples, n_features)
Тестовые данные.
- Возвращает:
- score_samplesarray-like, shape (n_samples,)
Несдвинутые значения функции оценки для образцов.
- set_fit_request(*, coef_init: bool | None | str = '$UNCHANGED$', offset_init: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') SGDOneClassSVM[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- coef_initstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
coef_initпараметр вfit.- offset_initstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
offset_initпараметр вfit.- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_partial_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SGDOneClassSVM[источник]#
Настроить, следует ли запрашивать передачу метаданных в
partial_fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpartial_fitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpartial_fit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вpartial_fit.
- Возвращает:
- selfobject
Обновленный объект.
- разрежать()[источник]#
Преобразовать матрицу коэффициентов в разреженный формат.
Преобразует
coef_члену разреженной матрицы scipy.sparse, что для моделей с L1-регуляризацией может быть значительно более эффективным по памяти и хранению, чем обычное представление numpy.ndarray.The
intercept_Член не преобразован.- Возвращает:
- self
Обученный оценщик.
Примечания
Для неразреженных моделей, т.е. когда в
coef_, это может фактически увеличить использование памяти, поэтому используйте этот метод с осторожностью. Эмпирическое правило: количество нулевых элементов, которое можно вычислить с помощью(coef_ == 0).sum(), должно быть больше 50%, чтобы это обеспечивало значительные преимущества.После вызова этого метода дальнейшее обучение с помощью метода partial_fit (если он есть) не будет работать, пока вы не вызовете densify.
Примеры галереи#
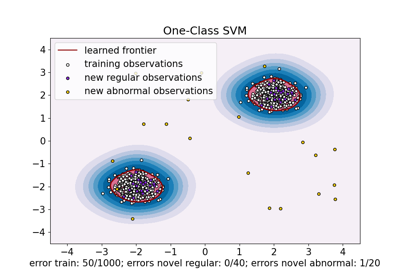
One-Class SVM против One-Class SVM с использованием стохастического градиентного спуска
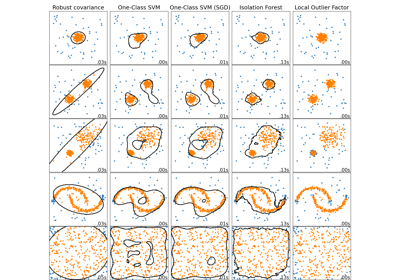
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных