IsolationForest#
- класс sklearn.ensemble.IsolationForest(*, n_estimators=100, max_samples='auto', contamination='auto', max_features=1.0, bootstrap=False, n_jobs=None, random_state=None, verbose=0, warm_start=False)[источник]#
Алгоритм Isolation Forest.
Возвращает оценку аномальности каждого образца с использованием алгоритма IsolationForest
IsolationForest 'изолирует' наблюдения, случайным образом выбирая признак, а затем случайным образом выбирая значение разделения между максимальным и минимальным значениями выбранного признака.
Поскольку рекурсивное разбиение может быть представлено древовидной структурой, количество разделений, необходимых для изоляции образца, эквивалентно длине пути от корневого узла до конечного узла.
Эта длина пути, усредненная по лесу таких случайных деревьев, является мерой нормальности и нашей функцией принятия решений.
Случайное разбиение создает заметно более короткие пути для аномалий. Следовательно, когда лес случайных деревьев коллективно создает более короткие длины путей для определенных образцов, они с высокой вероятностью являются аномалиями.
Подробнее в Руководство пользователя.
Добавлено в версии 0.18.
- Параметры:
- n_estimatorsint, по умолчанию=100
Количество базовых оценщиков в ансамбле.
- max_samples“auto”, int или float, по умолчанию=”auto”
Количество образцов для выборки из X для обучения каждого базового оценщика.
Если int, то нарисовать
max_samplesвыборки.Если float, то нарисовать
max_samples * X.shape[0]выборки.Если "auto", то
max_samples=min(256, n_samples).
Если max_samples больше, чем количество предоставленных выборок, все выборки будут использованы для всех деревьев (без выборки).
- contamination'auto' или float, по умолчанию='auto'
Уровень загрязнения набора данных, т.е. доля выбросов в наборе данных. Используется при обучении для определения порога на оценках образцов.
Если ‘auto’, порог определяется как в оригинальной статье.
Если float, загрязнение должно быть в диапазоне (0, 0.5].
Изменено в версии 0.22: Значение по умолчанию для
contaminationизменено с 0.1 на'auto'.- max_featuresint или float, по умолчанию=1.0
Количество признаков, выбираемых из X для обучения каждого базового оценщика.
Если int, то нарисовать
max_featuresпризнаков.Если float, то нарисовать
max(1, int(max_features * n_features_in_))признаков.
Примечание: использование числа с плавающей точкой меньше 1.0 или целого числа меньше количества признаков включит субдискретизацию признаков и приведёт к увеличению времени выполнения.
- bootstrapbool, по умолчанию=False
Если True, отдельные деревья обучаются на случайных подмножествах обучающих данных, выбранных с заменой. Если False, выполняется выборка без замены.
- n_jobsint, default=None
Количество параллельно выполняемых задач для
fit.Noneозначает 1 если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет псевдослучайностью выбора признака и значений разделения для каждого шага ветвления и каждого дерева в лесу.
Передайте целое число для воспроизводимых результатов при многократных вызовах функции. См. Глоссарий.
- verboseint, по умолчанию=0
Управляет подробностью вывода процесса построения дерева.
- warm_startbool, по умолчанию=False
При установке значения
True, повторно использовать решение предыдущего вызова fit и добавить больше оценщиков в ансамбль, в противном случае просто обучить полностью новый лес. См. Глоссарий.Добавлено в версии 0.21.
- Атрибуты:
- estimator_
ExtraTreeRegressorэкземпляр Шаблон базового оценщика, используемый для создания коллекции обученных подоценщиков.
Добавлено в версии 1.2:
base_estimator_был переименован вestimator_.- estimators_список экземпляров ExtraTreeRegressor
Коллекция обученных суб-оценщиков.
- estimators_features_list of ndarray
Подмножество выбранных признаков для каждого базового оценщика.
estimators_samples_list of ndarrayПодмножество выбранных выборок для каждого базового оценщика.
- max_samples_int
Фактическое количество образцов.
- offset_float
Смещение, используемое для определения решающей функции из исходных оценок. Мы имеем соотношение:
decision_function = score_samples - offset_.offset_определяется следующим образом. Когда параметр загрязнения установлен в “auto”, смещение равно -0.5, так как оценки нормальных объектов близки к 0, а оценки выбросов близки к -1. Когда предоставлен параметр загрязнения, отличный от “auto”, смещение определяется таким образом, чтобы получить ожидаемое количество выбросов (образцов с функцией решения < 0) при обучении.Добавлено в версии 0.20.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- estimator_
Смотрите также
sklearn.covariance.EllipticEnvelopeОбъект для обнаружения выбросов в наборе данных с гауссовым распределением.
sklearn.svm.OneClassSVMНеконтролируемое обнаружение выбросов. Оценка поддержки многомерного распределения. Реализация основана на libsvm.
sklearn.neighbors.LocalOutlierFactorОбнаружение выбросов без учителя с использованием локального фактора выбросов (LOF).
Примечания
Реализация основана на ансамбле ExtraTreeRegressor. Максимальная глубина каждого дерева установлена в
ceil(log_2(n))где \(n\) это количество образцов, используемых для построения дерева (см. [1] для получения дополнительных деталей).Ссылки
[1]F. T. Liu, K. M. Ting and Z. -H. Zhou. “Isolation forest.” 2008 Eighth IEEE International Conference on Data Mining (ICDM), 2008, стр. 413-422.
[2]F. T. Liu, K. M. Ting and Z. -H. Zhou. «Обнаружение аномалий на основе изоляции.» ACM Transactions on Knowledge Discovery from Data (TKDD) 6.1 (2012): 1-39.
Примеры
>>> from sklearn.ensemble import IsolationForest >>> X = [[-1.1], [0.3], [0.5], [100]] >>> clf = IsolationForest(random_state=0).fit(X) >>> clf.predict([[0.1], [0], [90]]) array([ 1, 1, -1])
Пример использования изолирующего леса для обнаружения аномалий см. в Пример IsolationForest.
- decision_function(X)[источник]#
Средний показатель аномалии X для базовых классификаторов.
Аномальный балл входной выборки вычисляется как средний аномальный балл деревьев в лесу.
Мера нормальности наблюдения для дерева - это глубина листа, содержащего это наблюдение, что эквивалентно количеству разделений, необходимых для изоляции этой точки. В случае нескольких наблюдений n_left в листе добавляется средняя длина пути дерева изоляции для n_left выборок.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные выборки. Внутренне они будут преобразованы в
dtype=np.float32и если разреженная матрица предоставлена, в разреженнуюcsr_matrix.
- Возвращает:
- scoresndarray формы (n_samples,)
Оценка аномальности входных образцов. Чем ниже, тем более аномальным. Отрицательные оценки представляют выбросы, положительные — нормальные точки.
Примечания
Метод decision_function может быть распараллелен путем установки контекста joblib. Это по своей сути НЕ использует
n_jobsпараметр, инициализированный в классе, который используется во времяfit. Это связано с тем, что вычисление оценки может быть быстрее без параллелизации для небольшого количества выборок, например, для 1000 выборок или меньше. Пользователь может установить количество заданий в контексте joblib, чтобы контролировать количество параллельных заданий.from joblib import parallel_backend # Note, we use threading here as the decision_function method is # not CPU bound. with parallel_backend("threading", n_jobs=4): model.decision_function(X)
- fit(X, y=None, sample_weight=None)[источник]#
Обучить оценщик.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные образцы. Используйте
dtype=np.float32для максимальной эффективности. Разреженные матрицы также поддерживаются, используйте sparsecsc_matrixдля максимальной эффективности.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса образцов. Если None, то образцы имеют одинаковый вес.
- Возвращает:
- selfobject
Обученный оценщик.
- fit_predict(X, y=None, **kwargs)[источник]#
Выполнить подгонку на X и вернуть метки для X.
Возвращает -1 для выбросов и 1 для нормальных точек.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные образцы.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- **kwargsdict
Аргументы, передаваемые в
fit.Добавлено в версии 1.4.
- Возвращает:
- yndarray формы (n_samples,)
1 для нормальных объектов, -1 для выбросов.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.5.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать, является ли конкретный образцом выбросом или нет.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные выборки. Внутренне они будут преобразованы в
dtype=np.float32и если разреженная матрица предоставлена, в разреженнуюcsr_matrix.
- Возвращает:
- is_inlierndarray формы (n_samples,)
Для каждого наблюдения указывает, следует ли его считать выбросом (+1) или нет (-1) в соответствии с обученной моделью.
Примечания
Метод predict может быть распараллелен путем установки контекста joblib. Это по сути НЕ использует
n_jobsпараметр, инициализированный в классе, который используется во времяfit. Это связано с тем, что predict может быть быстрее без параллелизации для небольшого количества образцов, например, для 1000 образцов или меньше. Пользователь может установить количество заданий в контексте joblib, чтобы контролировать количество параллельных заданий.from joblib import parallel_backend # Note, we use threading here as the predict method is not CPU bound. with parallel_backend("threading", n_jobs=4): model.predict(X)
- score_samples(X)[источник]#
Противоположность оценки аномалии, определенной в оригинальной статье.
Аномальный балл входной выборки вычисляется как средний аномальный балл деревьев в лесу.
Мера нормальности наблюдения для дерева - это глубина листа, содержащего это наблюдение, что эквивалентно количеству разделений, необходимых для изоляции этой точки. В случае нескольких наблюдений n_left в листе добавляется средняя длина пути дерева изоляции для n_left выборок.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- scoresndarray формы (n_samples,)
Оценка аномальности входных выборок. Чем ниже значение, тем более аномальным является объект.
Примечания
Метод функции оценки может быть распараллелен путем установки контекста joblib. Это по своей сути НЕ использует
n_jobsпараметр, инициализированный в классе, который используется во времяfit. Это связано с тем, что вычисление оценки может быть быстрее без параллелизации для небольшого количества выборок, например, для 1000 выборок или меньше. Пользователь может установить количество заданий в контексте joblib, чтобы контролировать количество параллельных заданий.from joblib import parallel_backend # Note, we use threading here as the score_samples method is not CPU bound. with parallel_backend("threading", n_jobs=4): model.score(X)
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') IsolationForest[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
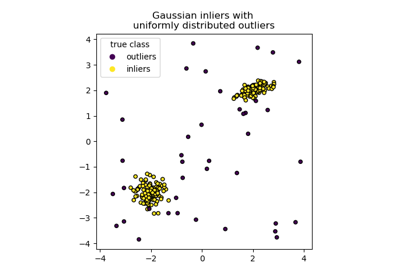
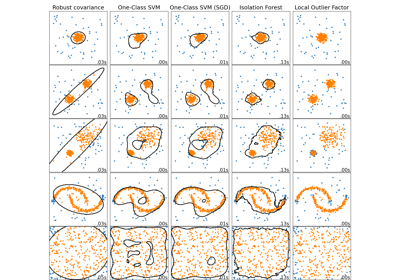
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных