LocalOutlierFactor#
- класс sklearn.neighbors.LocalOutlierFactor(n_neighbors=20, *, алгоритм='auto', leaf_size=30, метрика='minkowski', p=2, metric_params=None, contamination='auto', новизна=False, n_jobs=None)[источник]#
Обнаружение выбросов без учителя с использованием фактора локальных выбросов (LOF).
Аномальный балл каждого образца называется локальным фактором выброса. Он измеряет локальное отклонение плотности данного образца относительно его соседей. Он локальный в том смысле, что аномальный балл зависит от того, насколько изолирован объект относительно окружающей окрестности. Более точно, локальность задается k ближайшими соседями, расстояние до которых используется для оценки локальной плотности. Сравнивая локальную плотность образца с локальными плотностями его соседей, можно идентифицировать образцы, имеющие существенно меньшую плотность, чем их соседи. Они считаются выбросами.
Добавлено в версии 0.19.
- Параметры:
- n_neighborsint, по умолчанию=20
Количество соседей для использования по умолчанию для
kneighborsзапросы. Если n_neighbors больше количества предоставленных образцов, будут использованы все образцы.- алгоритм{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, по умолчанию=’auto’
Алгоритм, используемый для вычисления ближайших соседей:
'ball_tree' будет использовать
BallTree'kd_tree' будет использовать
KDTree'brute' будет использовать поиск методом грубой силы.
'auto' попытается определить наиболее подходящий алгоритм на основе значений, переданных в
fitметод.
Примечание: обучение на разреженных входных данных переопределит настройку этого параметра, используя метод грубой силы.
- leaf_sizeint, по умолчанию=30
Лист имеет размер, переданный в
BallTreeилиKDTree. Это может повлиять на скорость построения и выполнения запросов, а также на память, необходимую для хранения дерева. Оптимальное значение зависит от характера задачи.- метрикаstr или callable, по умолчанию='minkowski'
Метрика для вычисления расстояния. По умолчанию “minkowski”, что дает стандартное евклидово расстояние при p = 2. См. документацию scipy.spatial.distance и метрики, перечисленные в
distance_metricsдля допустимых значений метрик.Если метрика "precomputed", X считается матрицей расстояний и должна быть квадратной во время подгонки. X может быть разреженный граф, в этом случае только "ненулевые" элементы могут считаться соседями.
Если metric - вызываемая функция, она принимает два массива, представляющих 1D векторы, в качестве входных данных и должна возвращать одно значение, указывающее расстояние между этими векторами. Это работает для метрик Scipy, но менее эффективно, чем передача имени метрики в виде строки.
- pfloat, по умолчанию=2
Параметр для метрики Минковского из
sklearn.metrics.pairwise_distances. Когда p = 1, это эквивалентно использованию manhattan_distance (l1) и euclidean_distance (l2) для p = 2. Для произвольного p используется minkowski_distance (l_p).- metric_paramsdict, по умолчанию=None
Дополнительные именованные аргументы для метрической функции.
- contamination'auto' или float, по умолчанию='auto'
Степень загрязнения набора данных, т.е. доля выбросов в наборе данных. При обучении это используется для определения порога на оценках образцов.
если 'auto', порог определяется как в оригинальной статье,
если это float, загрязнение должно быть в диапазоне (0, 0.5].
Изменено в версии 0.22: Значение по умолчанию для
contaminationизменено с 0.1 на'auto'.- новизнаbool, по умолчанию=False
По умолчанию LocalOutlierFactor предназначен только для обнаружения выбросов (novelty=False). Установите novelty в True, если хотите использовать LocalOutlierFactor для обнаружения новизны. В этом случае учтите, что вы должны использовать только predict, decision_function и score_samples на новых, ранее невиданных данных, а не на обучающем наборе; и обратите внимание, что результаты, полученные таким образом, могут отличаться от стандартных результатов LOF.
Добавлено в версии 0.20.
- n_jobsint, default=None
Количество параллельных задач для поиска соседей.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.
- Атрибуты:
- negative_outlier_factor_ndarray формы (n_samples,)
Противоположное значение LOF обучающих образцов. Чем выше, тем более нормальным. Выбросы обычно имеют оценку LOF близкую к 1 (
negative_outlier_factor_близко к -1), в то время как выбросы имеют тенденцию иметь больший показатель LOF.Локальный фактор выброса (LOF) образца отражает его предполагаемую 'степень аномальности'. Это среднее значение отношения локальной плотности достижимости образца к таковой у его k ближайших соседей.
- n_neighbors_int
Фактическое количество соседей, используемых для
kneighborsзапросы.- offset_float
Смещение, используемое для получения бинарных меток из исходных оценок. Наблюдения с отрицательным коэффициентом выброса меньше, чем
offset_обнаруживаются как аномальные. Смещение установлено на -1.5 (оценки нормальных объектов около -1), за исключением случаев, когда предоставлен параметр загрязнения, отличный от "auto". В этом случае смещение определяется таким образом, чтобы получить ожидаемое количество выбросов при обучении.Добавлено в версии 0.20.
- effective_metric_str
Эффективная метрика, используемая для вычисления расстояния.
- effective_metric_params_dict
Эффективные дополнительные аргументы ключевых слов для функции метрики.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_samples_fit_int
Это количество образцов в обучающих данных.
Смотрите также
sklearn.svm.OneClassSVMОбнаружение выбросов без учителя с использованием машины опорных векторов.
Ссылки
[1]Breunig, M. M., Kriegel, H. P., Ng, R. T., & Sander, J. (2000, Май). LOF: идентификация локальных выбросов на основе плотности. В материалах 2000 ACM SIGMOD International Conference on Management of Data, стр. 93-104.
Примеры
>>> import numpy as np >>> from sklearn.neighbors import LocalOutlierFactor >>> X = [[-1.1], [0.2], [101.1], [0.3]] >>> clf = LocalOutlierFactor(n_neighbors=2) >>> clf.fit_predict(X) array([ 1, 1, -1, 1]) >>> clf.negative_outlier_factor_ array([ -0.9821, -1.0370, -73.3697, -0.9821])
- decision_function(X)[источник]#
Сдвинутая противоположность локального фактора выбросов X.
Чем больше, тем лучше, т.е. большие значения соответствуют нормальным объектам.
Доступно только для обнаружения новизны (когда novelty установлено в True). Смещение позволяет установить нулевой порог для выброса. Аргумент X предполагается содержащим новые данные: если X содержит точку из обучающей выборки, она учитывает её в своём собственном соседстве. Также выборки в X не учитываются в соседстве любой точки.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Образец или образцы запроса для вычисления фактора локальных выбросов относительно обучающих образцов.
- Возвращает:
- shifted_opposite_lof_scoresndarray формы (n_samples,)
Сдвинутая противоположность локального фактора выбросов для каждого входного образца. Чем ниже, тем более аномальным. Отрицательные значения представляют выбросы, положительные — нормальные точки.
- fit(X, y=None)[источник]#
Обучить детектор локального фактора выбросов на обучающем наборе данных.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples, n_samples) если metric='precomputed'
Обучающие данные.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfLocalOutlierFactor
Обученный детектор локальных выбросов.
- fit_predict(X, y=None)[источник]#
Обучить модель на обучающем наборе X и вернуть метки.
Недоступно для обнаружения новизны (когда novelty установлено в True). Метка равна 1 для выброса и -1 для аномалии в соответствии с оценкой LOF и параметром contamination.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features), по умолчанию=None
Образец или образцы запроса для вычисления фактора локальных выбросов относительно обучающих образцов.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- is_inlierndarray формы (n_samples,)
Возвращает -1 для аномалий/выбросов и 1 для нормальных точек.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- kneighbors(X=None, n_neighbors=None, return_distance=True)[источник]#
Найти K ближайших соседей точки.
Возвращает индексы и расстояния до соседей каждой точки.
- Параметры:
- X{array-like, sparse matrix}, shape (n_queries, n_features), или (n_queries, n_indexed) если metric == 'precomputed', default=None
Точка или точки запроса. Если не указано, возвращаются соседи каждой индексированной точки. В этом случае точка запроса не считается своим собственным соседом.
- n_neighborsint, default=None
Количество соседей, требуемых для каждого образца. По умолчанию используется значение, переданное конструктору.
- return_distancebool, по умолчанию=True
Возвращать ли расстояния.
- Возвращает:
- neigh_distndarray формы (n_queries, n_neighbors)
Массив, представляющий длины до точек, присутствует только если return_distance=True.
- neigh_indndarray формы (n_queries, n_neighbors)
Индексы ближайших точек в матрице популяции.
Примеры
В следующем примере мы создаем класс NearestNeighbors из массива, представляющего наш набор данных, и спрашиваем, какая точка ближе всего к [1,1,1]
>>> samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=1) >>> neigh.fit(samples) NearestNeighbors(n_neighbors=1) >>> print(neigh.kneighbors([[1., 1., 1.]])) (array([[0.5]]), array([[2]]))
Как видите, он возвращает [[0.5]] и [[2]], что означает, что элемент находится на расстоянии 0.5 и является третьим элементом выборок (индексы начинаются с 0). Вы также можете запросить несколько точек:
>>> X = [[0., 1., 0.], [1., 0., 1.]] >>> neigh.kneighbors(X, return_distance=False) array([[1], [2]]...)
- kneighbors_graph(X=None, n_neighbors=None, mode='connectivity')[источник]#
Вычислить (взвешенный) граф k-ближайших соседей для точек в X.
- Параметры:
- X{array-like, sparse matrix} формы (n_queries, n_features), или (n_queries, n_indexed) если metric == ‘precomputed’, default=None
Точка или точки запроса. Если не предоставлено, возвращаются соседи каждой индексированной точки. В этом случае точка запроса не считается своим собственным соседом. Для
metric='precomputed'форма должна быть (n_queries, n_indexed). В противном случае форма должна быть (n_queries, n_features).- n_neighborsint, default=None
Количество соседей для каждой выборки. По умолчанию используется значение, переданное конструктору.
- mode{'connectivity', 'distance'}, по умолчанию='connectivity'
Тип возвращаемой матрицы: 'connectivity' вернет матрицу связности с единицами и нулями, в 'distance' ребра являются расстояниями между точками, тип расстояния зависит от выбранного параметра metric в классе NearestNeighbors.
- Возвращает:
- Aразреженная матрица формы (n_queries, n_samples_fit)
n_samples_fitэто количество образцов в подогнанных данных.A[i, j]дает вес ребра, соединяющегоitoj. Матрица имеет формат CSR.
Смотрите также
NearestNeighbors.radius_neighbors_graphВычислить (взвешенный) граф соседей для точек в X.
Примеры
>>> X = [[0], [3], [1]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=2) >>> neigh.fit(X) NearestNeighbors(n_neighbors=2) >>> A = neigh.kneighbors_graph(X) >>> A.toarray() array([[1., 0., 1.], [0., 1., 1.], [1., 0., 1.]])
- predict(X=None)[источник]#
Предсказать метки (1 - нормальный объект, -1 - выброс) для X согласно LOF.
Доступно только для обнаружения новизны (когда novelty установлено в True). Этот метод позволяет обобщать предсказание на новые наблюдения (не в обучающем наборе). Обратите внимание, что результат
clf.fit(X)затемclf.predict(X)сnovelty=Trueможет отличаться от результата, полученного с помощьюclf.fit_predict(X)сnovelty=False.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Образец или образцы запроса для вычисления фактора локальных выбросов относительно обучающих образцов.
- Возвращает:
- is_inlierndarray формы (n_samples,)
Возвращает -1 для аномалий/выбросов и +1 для нормальных точек.
- score_samples(X)[источник]#
Противоположность локального фактора выбросов для X.
Это противоположно тому, что больше — лучше, т.е. большие значения соответствуют выбросам.
Доступно только для обнаружения новизны (когда novelty установлено в True). Аргумент X должен содержать новые данные: если X содержит точку из обучающей выборки, она рассматривает последнюю в своей собственной окрестности. Также образцы в X не рассматриваются в окрестности любой точки. Из-за этого оценки, полученные через
score_samplesможет отличаться от стандартных оценок LOF. Стандартные оценки LOF для обучающих данных доступны черезnegative_outlier_factor_атрибут.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Образец или образцы запроса для вычисления фактора локальных выбросов относительно обучающих образцов.
- Возвращает:
- opposite_lof_scoresndarray формы (n_samples,)
Противоположность локального фактора выброса для каждого входного образца. Чем ниже, тем более аномальным.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
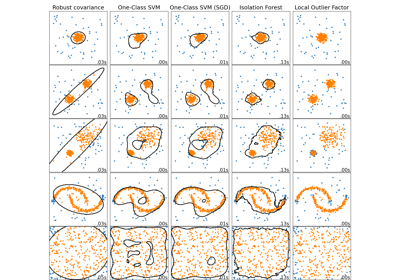
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных

Обнаружение новизны с помощью локального фактора выбросов (LOF)
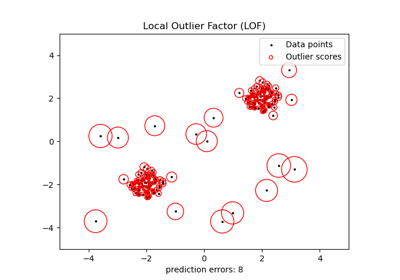
Обнаружение выбросов с помощью фактора локальных выбросов (LOF)